

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Подход Шепли к измерению и декомпозиции бедности
Методы разложения агрегированных показателей, представляющих собой результат суммирования нескольких составляющих его показателей, используются во многих областях экономики для определения количественной меры воздействия различных факторов на изучаемое явление. Использование таких методов особенно широко распространено в изучении бедности и неравенства.[1] В контексте неравенства дохода, методы разложения позволяют исследователям отличить межгрупповой эффект, возникающий из-за различий в средних доходах между подгруппами (например, мужчинами и женщинами), от внутригруппового эффекта, появляющегося из-за неравенства в пределах подгрупп населения. Методы разложения были развиты также для того, чтобы измерить важность таких компонент дохода как заработок или трансфертные платежи (выплаты населению по программам социального страхования, пособия и льготы).
Несмотря на достаточно широкое распространение, эти процедуры имеют недостатки, связанные с тем, что сложные эконометрические модели должны учитывать характер распределения моделируемого явления. Можно выделить четыре широких категории проблем.
Во-первых, вклад, определенного фактора, не всегда поддаётся ясной интерпретации, либо не может быть строго точна. Вторая проблема с обычными процедурами состоит в том, что они часто имеют ограничения на используемые виды бедности и индексы неравенства. Только некоторые формы индексов позволяют аддитивное разложение вкладов в общую величину бедности или неравенства. Подобные методы, приложенные к другим индексам, требуют введения неясно определенного остатка или термина "взаимодействие", для поддержки идентичности разложения.
Весьма серьезная проблема касается ограничений, наложенных на типы делающих взнос факторов. Чаще всего по подгруппам обрабатываются ситуации, в которых совокупность разделена на основе единственного признака. И при этом нет методов имеющих дело со смесями факторов, например, одновременного разложения по подгруппам (по, скажем, мужчинам и женщинам) и компонентам дохода (скажем, факторному и трансфертному доходам).
Решающее в критике современных методов разложения - то, что отдельные применения рассматриваются как различные проблемы, требующие различных решений. Это - главная причина, по которой невозможно в настоящее время скомбинировать разложение по компонентам дохода и по подгруппам.
Цель данной статьи состоит в том, чтобы рассмотреть решение общей проблемы разложения, которое было предложено А. Шороксом в 1982г.[2]
Предлагаемое решение разложения (оценка I) состоит в определении предельной оценки эффекта. Оно заключается в последовательном устранении каждого из делающих взнос факторов, и затем нахождении для каждого фактора среднего числа его предельных вкладов во всех возможных последовательностях устранения. Эта процедура приводит к точному совокупному разложению I в m вкладов.
Предложенное решение основной проблемы разложения сводится формально к эквиваленту оценки Шепли, и упоминается, поэтому как разложение Шепли.[3] Процедура Шепли может использоваться во всех областях прикладной экономики всякий раз, когда необходимо оценить относительную важность объясняющих переменных, так как она предлагает объединенную структуру, способную к обработке любого типа разложения.
Рассмотрим статистический индикатор I, чья оценка полностью определена набором т вносящих вклад факторов Xk , пронумерованных как :
, (1)
где f(∙) описывает основу модели.
Предположим, что индикатор I представляет полный уровень бедности или неравенства населения, или изменения в бедности через какое-то время, а фактор Xk - скалярная или векторная переменная.
Поскольку каждый из факторов является или присутствующим или отсутствующим, его удобно характеризовать с помощью модельной структуры ![]() , в терминах набора факторов (или, более точно, "индексов фактора"), K, и функции
, в терминах набора факторов (или, более точно, "индексов фактора"), K, и функции ![]() . Также будет удобно принять, что : другими словами, I – ноль, когда все факторы устранены.[4]
. Также будет удобно принять, что : другими словами, I – ноль, когда все факторы устранены.[4]
Разложение является набором действительных значений Ck , ![]() , показывающих вклад каждого из факторов. Правило разложения – функция, которая приводит к набору вкладов фактора
, показывающих вклад каждого из факторов. Правило разложения – функция, которая приводит к набору вкладов фактора
, (2)
для любой возможной модели ![]() .
.
При построении правила разложения необходимо, чтобы выполнялись некоторые требования.
Первое – разложение должно быть симметрическим в смысле, что вклад, назначенный на любой данный фактор не должен зависеть от пути, которым факторы маркированы или внесены в список. Во-вторых, разложение должно быть точно (и аддитивно), так, чтобы
, для всех ![]() . (3)
. (3)
Когда условие (3) выполняется, то ![]() отражает долю, приписываемую фактору k в наблюдаемом неравенстве или в бедности.
отражает долю, приписываемую фактору k в наблюдаемом неравенстве или в бедности.
Также желательно, чтобы вклады факторов могли интерпретироваться наглядным способом. В этом отношении, наиболее естественным является введение правила, которое приравнивает вклад каждого фактора к его предельному воздействию
(4)
Это правило разложения является симметрическим, но не будет обычно приводить к точному разложению.
Вторая возможность состоит в рассмотрении предельного воздействия каждого из факторов в последовательности их устранения. Пусть ![]() указывают порядок, в котором удалены факторы. И пусть , будет набором факторов, которые остаются после устранённого фактора
указывают порядок, в котором удалены факторы. И пусть , будет набором факторов, которые остаются после устранённого фактора ![]() . Тогда предельные воздействия задаются
. Тогда предельные воздействия задаются
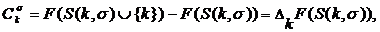
![]() , (5)
, (5)
где
(6)
есть предельное воздействие фактора k из набора S. Используя тот факт, что 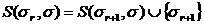 для, мы выводим формулу
для, мы выводим формулу
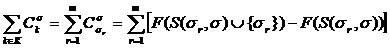 (7)
(7)
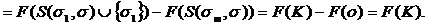
Разложение (5) - точно. Однако, оценка вклада, назначенного на любой данный фактор, зависит от порядка, в котором факторы появляются в последовательности устранения σ, так что факторы не рассматриваются симметрично. Эта проблема "зависимости пути" может быть исправлена рассмотрением возможных последовательностей устранения, обозначенных здесь набором ∑, и вычисляющих ожидаемую оценку C , когда последовательности в ∑ выбраны наугад. Это позволяет выработать правило разложения Cs, задаваемое формулой
![]() (8)
(8)

Используя ![]() для указания подходящей вероятности[5], уравнения (8) можно выразить более кратко
для указания подходящей вероятности[5], уравнения (8) можно выразить более кратко
![]()
![]() (9)
(9)
где ![]() - математическое ожидание, взятое относительно поднаборов L.
- математическое ожидание, взятое относительно поднаборов L.
Из (7) следует, что является точным правилом разложения, рассматривающим факторы симметрично. Кроме того, вклады могут интерпретироваться как ожидаемое предельное воздействие каждого фактора, когда математическое ожидание взято по всем возможным путям устранения.
Выражение (8) соответствует оценке Шепли для кооперативной игры, в которой "продукция" или "излишек" разделён среди набора К "вкладов" или "агентов".[6] Применение к дистрибутивному анализу весьма отличается от контекста, в котором оценка Шепли была задумана, и поэтому результатам нужно дать иное толкование. Однако такое применение кажется удобным и подходящим, поэтому будем относиться к (8) как к правилу разложения Шепли.[7]
Для того чтобы проиллюстрировать, как разложение Шепли работает практически, рассмотрим одно из простых приложений к анализу бедности – разложение индексов бедности.
При назначении вкладов по подгруппам населения такие индексы позволяют написать полную степень бедности, P
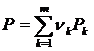 , (10)
, (10)
где ![]() и соответственно указывают долю населения и уровень бедности в k-ой подгруппе,
и соответственно указывают долю населения и уровень бедности в k-ой подгруппе, ![]() .
.
Индексы с этим свойством – особенное семейство мер, предложенных Фостером, Гриром и Торбеком.[8] В настоящее время они обычно используются для того, чтобы изучить как различия по регионам, размерам домашнего хозяйства, возрасту, и образованию отражаются на вносимом ими вкладе в полный уровень бедности.
Во многих отношениях, это – самое простое и наиболее четкое применение методов разложения. Предположим, например, что население разделено на т регионов. Тогда фактор k может интерпретироваться как "бедность в пределах региона k ", и соответственно интересующий нас вопрос – вклад, который этот фактор делает в бедность по стране в целом. Принимая во внимание сказанное выше, модельная структура определена как
![]() (11)
(11)
так 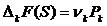 для всех
для всех ![]() . (12)
. (12)
Начиная с устранения бедности в k-ом регионе, совокупная бедность уменьшается на величину ![]() независимо от порядка, в котором рассматриваются регионы. Это следует из (4) и (9). Эти оценки приводят и к первым округлённым предельным эффектам и к пределам (условиям) в разложении Шепли. Другими словами
независимо от порядка, в котором рассматриваются регионы. Это следует из (4) и (9). Эти оценки приводят и к первым округлённым предельным эффектам и к пределам (условиям) в разложении Шепли. Другими словами
(13)
Не удивительно, что это распределение вкладов бедности по подгруппам населения точно согласуется с обычной практикой.
Более сложная ситуация возникает, если мы желаем выполнить одновременное разложение больше чем по одному признаку. Фактически в настоящее время нет никакой признанной процедуры для рассмотрения этой проблемы. Предположим, например, что население подразделено на m1 регионов индексированных К и m2 возрастных групп индексированных L. Это приводит к общему количеству m1m2 ячеек регион – возраст, которые, если рассматриваются отдельно, могут быть, как и прежде назначенными вкладами. При этом уравнение (10) заменится на
(14)
где нижние индексы kl относятся к региону k и возрастной группе l.
Однако, если необходимо исследовать воздействие на полную бедность в регионе k, или в возрастной группе l, а не вклад подгруппы, приписывающийся региону k и возрастной группе l, то необходимо найти – ![]() вклады, связанные с региональными факторами и факторами возраста.
вклады, связанные с региональными факторами и факторами возраста.
Процедура Шепли предлагает решение этой проблемы, через модельную структуру 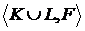 , где
, где
, . (15)
Устранение бедности в регионе k теперь
, (16)
В отличие от (12), рассмотренного выше, уравнение (16) показывает, что факторы больше не используются независимо: предельное воздействие устранения бедности в регионе k зависит от того, была ли уже устранена бедность в одной или больше возрастных групп.
Чтобы получить вклады Шепли для регионов, сначала обратим внимание, что 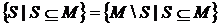 и
и 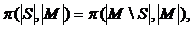 тогда
тогда
![]() . (17)
. (17)
Следует учесть, что (16) подразумевает
![]() , (18)
, (18)
для всего .
Тогда, выбирая любое ![]() и полагая
и полагая ![]() , получим
, получим
![]() (19)
(19)
![]() ,
,
или, эквивалентно формуле (10),
![]() (20)
(20)
Таким образом, при разложении по двум признакам на каждый регион назначена точно половина вклада, который был бы получен при разложении только по регионам. Подобный результат выполняется и для факторов возрастной группы. Более широко – при одновременном разложении по n признакам, каждый фактор определён одним n-м вкладом, полученным в отдельном разложении признака.
Этот результат показывает, что ничто не теряется при рассмотрении каждого признака по отдельности; результаты разложений агрегированного признака могут быть немедленно рассчитаны по ряду результатов для отдельного признака, и значения индексов различных подгрупп остаются теми же самыми, независимо от числа рассматриваемых признаков.
Индексы разложения бедности могут также использоваться для установления того, как изменяются вклады подгруппы в бедность с течением времени. Если и представляют собой долю населения и уровень бедности в k-ой подгруппе, ![]() , во время t , то уравнение (10) приводится к виду
, во время t , то уравнение (10) приводится к виду
![]() . (21)
. (21)
Цель данного уравнения – объяснять полное изменение в бедности, ![]() , в терминах изменений в бедности в пределах подгрупп,
, в терминах изменений в бедности в пределах подгрупп, 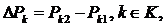 и терминах перемещения населения между подгруппами,
и терминах перемещения населения между подгруппами, ![]()
Оценки бедности для подгруппы могут изменяться независимо, т. е. факторы изменения бедности могут быть индексированы набором 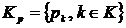 . Однако все перемещения населения в сумме обязательно дают нуль. Чтобы избегать осложнений в этой стадии, факторы перемещения населения будем рассматривать как отдельный сложный фактор и обозначим его Ks. Модельная структура тогда задаётся как
. Однако все перемещения населения в сумме обязательно дают нуль. Чтобы избегать осложнений в этой стадии, факторы перемещения населения будем рассматривать как отдельный сложный фактор и обозначим его Ks. Модельная структура тогда задаётся как
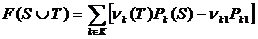 ,
, 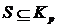 ,
, 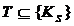 , (22)
, (22)
где
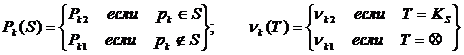 (23)
(23)
Для каждого 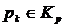 мы имеем
мы имеем
(24)
и полагая ![]() , получим, что
, получим, что
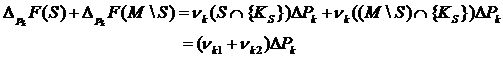 (25)
(25)
для всех S M.
Тогда, используя (17), можно связать вклад Шепли с изменением в бедности в пределах подгруппы k и написать
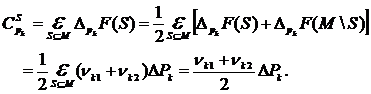 (26)
(26)
И наоборот
![]() ,
, ![]() . (27)
. (27)
Тогда
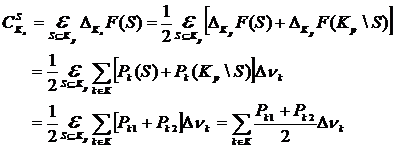 (28)
(28)
Это – естественное распределение вкладов факторов по искомому разложению, так как оно рассматривает факторы симметрическим способом, и выражение (21) может быть переписано в виде
![]() (29)
(29)
Несмотря на свои привлекательные свойства, разложение Шепли имеет один главный недостаток для дистрибутивного анализа: вклад, назначенный на любой заданный фактор обычно чувствителен к последовательности рассмотрения других факторов. Во многих применениях, некоторые группы факторов естественно группировать вместе. Это ведет к иерархической структуре, включающей набор первичных факторов, каждый из которых подразделен на (возможно отдельный элемент) группу вторичных факторов. Например, когда неравенство дохода расчленено по источникам дохода, можно, например, сначала расценить доход как сумму трудового дохода, инвестиционного дохода и трансфертов. Тогда инвестиционный доход, скажем, мог бы быть раздроблен на проценты, дивиденды, доходы от прироста капитала и арендную плату. Но разложение Шепли не гарантирует, что вклад, назначенный на доход, будет один и тот же, если инвестиционный доход рассматривать как отдельный объект и если рассматривать его в терминах отдельных компонентов инвестиционного дохода. И при этом разложение Шепли также не гарантирует, что вклады неравенства, назначенные на компоненты инвестиционной суммы дохода во вклад инвестиционного дохода, рассматриваются как отдельные единицы.
Чтобы изучить эту проблему более подробно, рассмотрим иерархическую модель 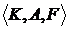 , состоящую из набора т вторичных факторов, индексированных K, и К разделенo в набор первичных факторов . Чистый (то есть вторичный фактор), структуры модели обозначен
, состоящую из набора т вторичных факторов, индексированных K, и К разделенo в набор первичных факторов . Чистый (то есть вторичный фактор), структуры модели обозначен ![]() . При замене каждого набора вторичных факторов на его соответствующий первичный фактор получается совокупная модель
. При замене каждого набора вторичных факторов на его соответствующий первичный фактор получается совокупная модель ![]() , определенная следующим образом
, определенная следующим образом
, , (30)
где 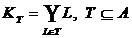 , (31)
, (31)
обозначает набор вторичных факторов, охваченных поднабором Т первичных факторов. Более широко – при замене поднабора первичных факторов, для их соответствующих групп вторичных факторов получается частично совокупная модель 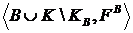 , определенная как
, определенная как
. (32)
Правило разложения для иерархических моделей – функция C*, которая назначает вклад на каждый вторичный фактор ![]() , и вклад каждый первичный фактор
, и вклад каждый первичный фактор ![]() . Рассмотрим данное правило для последовательного объединения модели , если
. Рассмотрим данное правило для последовательного объединения модели , если
![]() (33)
(33)
или другими словами, если вклад каждого первичного фактора – сумма вкладов его элементов.
Применяя разложение Шепли и к чистой модельной структуре , и к совокупной модели 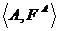 , получаем иерархическое правило разложения
, получаем иерархическое правило разложения
![]() (34)
(34)
Как уже упомянуто, эта процедура не гарантирует последовательное объединение. Однако, проблема может быть преодолена, применяя последовательный подход Шепли по стадиям, предложенным Оуэном.[9]
Сначала, вклады размещены как выше – на каждый из первичных факторов, используя разложение Шепли совокупной модели . Из этого следует, что
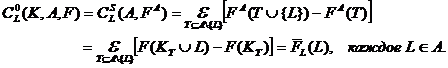 (35)
(35)
где
![]() (36)
(36)
Вклад каждого первичного фактора L тогда распределён среди его элементов, применяя разложение Шепли к :
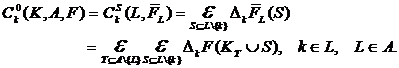 (37)
(37)
Поскольку разложение Шепли точно, то, следовательно
![]() (38)
(38)
Так что эта процедура с двумя стадиями – всегда последовательное объединение.[10]
Хотя иерархическая форма правила Шепли – обычно не последовательное объединение, есть одно важное исключение.
Пусть функция 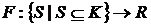 отделима на если
отделима на если
![]() (39)
(39)
другими словами, предельный вклад каждого фактора не зависит от других факторов в L. Заметим, что, если функция F отделима на L, то F также отделима по любому поднабору L. Заметим также, что, если Т представимо в виде ![]() , то, учитывая (39) получим, что
, то, учитывая (39) получим, что
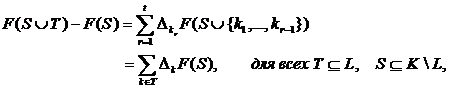 (40)
(40)
так что предельный эффект от введения любой группы Т факторов из поднабора L – сумма предельных эффектов от введения каждого фактора отдельно.
Из всего вышесказанного вытекают три утверждения.
Утверждение 1: Рассмотрим модель , и предположим, что F отделима на L K. Тогда
![]() (41a)
(41a)
![]() (41b)
(41b)
![]() (41c)
(41c)
где F{L} определено в (32).
Утверждение 2: Рассмотрим иерархическую модель ![]() , и предположим, что F отделима на каждом L
, и предположим, что F отделима на каждом L![]() A. Тогда, для всех L A и всех k L, мы имеем
A. Тогда, для всех L A и всех k L, мы имеем
![]() (42)
(42)
Так что разложение Шепли и разложение Оуэна совпадают, и разложение Шепли представляет собой последовательное объединение.
Утверждение 3: Для иерархической модели , предположим, что F отделима на каждом L![]() A, и что каждое L
A, и что каждое L![]() А является достаточным. Тогда
А является достаточным. Тогда
![]() (43)
(43)
Таким образом, в описанном контексте, вклады Шепли определены исключительно числом первичных факторов, |A|, и первыми округлёнными предельными эффектами, Mk(K, F).
Литература:
1. Grootaert, C. (1995): Structural change and poverty in Africa: a decomposition analysis for
Cote d'Ivoire, Journal of Development Economics, 47, 375-402.
2. Szekely, M. (1995): Poverty in Mexico During Adjustment, Review of Income and Wealth, 1995, No.3, Pp.331-348.
3. Thorbecke, E. and H. S. Jung (1996): A multiplier decomposition method to analyze poverty alleviation, Journal of Development Economics, 48, 279-300.
4. Shorrocks, A. F. (1982): Inequality decomposition by factor components, Econometrica, 50, 193-211.
5. Shapley, L. (1953): A value for n-person games, in: H. W. Kuhn and A. W. Tucker, eds., Contributions to the Theory of Games, Vol. 2 (Princeton University Press).
6. Foster, J. E., J. Greer and E. Thorbecke (1984): A class of decomposable poverty indices, Econometrica, 52, 761-765.
7. Moulin, H. (1988): Axioms of Cooperative Decision Making. Cambridge University Press.
8. Owen, G. (1977): Values of games with priori unions, in: R. Heim and O. Moeschlin, eds., Essays in Mathematical Economics and Game Theory (Springer Verlag, New York).
[1] Примеры такого анализа можно найти в работах [1] – [3].
[2] Shorrocks, A. F. (1982): Inequality decomposition by factor components, Econometrica, 50, 193-211.
[3] Shapley, L. (1953): A value for n-person games, in: H. W. Kuhn and A. W. Tucker, eds., Contributions to the Theory of Games, Vol. 2 (Princeton University Press).
[4] если F (∙) получен из эконометрической модели, это ограничение будет обычно подразумевать, что один из факторов представляет необъясненные остатки. Когда ограничение не удовлетворено автоматически, I можно всегда повторно нормализовать так, чтобы этот фактор измерил "излишек", возникший из-за идентификации факторов.
[5] ∙ (׀S׀, ׀M׀) - вероятность случайного отбора поднабора S из М, при условии, что все поднаборы размеров от 0 до ׀ М׀ одинаково вероятны.
[6] Moulin, H. (1988): Axioms of Cooperative Decision Making. Cambridge University Press.
[7] Некоторые характеристики оценки Шепли могут быть по иному истолкованы в существующей структуре. Например, (8) - единственное симметрическое и аддитивное правило разложения, которое по каждому k приводит к вкладам , которые зависят только от набора предельных эффектов касающихся фактора k (Young, 1985).
[8] Foster, J. E., J. Greer and E. Thorbecke (1984): A class of decomposable poverty indices, Econometrica, 52, 761-765.
[9] Owen, G. (1977): Values of games with priori unions, in: R. Heim and O. Moeschlin, eds., Essays in Mathematical Economics and Game Theory (Springer Verlag, New York).
[10] Разложение с двумя стадиями можно продлить на многоступенчатую процедуру, если вторичные факторы разделить на третичные факторы, и так далее.
