
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Лекция №1. Введение
Архитектура ЭВМ – это многоуровневая иерархия аппаратно-программных средств, из которых строится ЭВМ. Каждый из уровней допускает многовариантное построение и применение. Конкретная реализация уровней определяет особенности структурного построения ЭВМ.
ЭВМ принято делить на поколения.
Первое поколение. е годы
Компьютеры на электронных вакуумных лампах (диодах и триодах), а в качестве оперативных запоминающих устройств использовались электронно-лучевые трубки, в качестве внешних запоминающих устройств применялись накопители на магнитных лентах, перфокартах, перфолентах и штекерные коммутаторы.
Программирование работы ЭВМ этого поколения выполнялось в двоичной системе счисления на машинном языке, то есть программы были жестко ориентированы на конкретную модель машины.
Машины предназначались для решения сравнительно несложных научно-технических задач. Они были значительных размеров, потребляли большую мощность, имели невысокую надежность работы.
Быстродействие их не превышало 2-3 тысяч операций в секунду, емкость оперативной памяти - 2048 машинных слов длиной 48 двоичных знаков. Использовались в основном для научных расчетов.
В конце этого периода стали выпускаться устройства памяти на магнитных сердечниках.
ЭНИАК, МЭСМ, БЭСМ и первые модели ЭВМ "Минск" и "Урал".
Второе поколение ЭВМ. е годы
Элементной базой машин этого поколения были полупроводниковые элементы (транзисторы). Транзисторы (твердые диоды и триоды) заменили электронные лампы в процессорах, а ферритовые (намагничиваемые) сердечники – электронно-лучевые трубки в оперативных запоминающих устройствах. Машины предназначались для решения различных трудоемких научно-технических задач, а также для управления технологическими процессами в производстве.
Появление полупроводниковых элементов в электронных схемах существенно увеличило емкость оперативной памяти, надежность и быстродействие ЭВМ. Уменьшились размеры, масса и потребляемая мощность.
Скорость ЭВМ возросла до сотен тысяч операций в секунду, а память – до десятков тысяч машинных слов. Создаются долговременные запоминающие устройства на магнитных лентах. Начали применять языки программирования высокого уровня, такие как Фортран.
В 1964 году появился первый монитор для компьютеров - IBM 2250. Это был монохромный дисплей с экраном 12 × 12 дюймов и разрешением 1024 × 1024 пикселов. Он имел частоту кадровой развертки 40 Гц.
Третье поколение ЭВМ: е годы
Элементная база ЭВМ - малые интегральные схемы (МИС), что привело к дальнейшему увеличению скорости до миллиона операций в секунду и памяти до сотен тысяч слов. Машины предназначались для широкого использования в различных областях науки и техники.
ЭВМ третьего поколения также характеризуется крупнейшими сдвигами в архитектуре ЭВМ, их программном обеспечении, организации взаимодействия человека с машиной. Это, прежде всего наличие развитой конфигурации внешних устройств (алфавитно-цифровые терминалы, графопостроители, магнитные диски (30 см в диаметре) и т. п.), развитая операционная система.
В период машин третьего поколения произошел крупный сдвиг в области применения ЭВМ. Если раньше ЭВМ использовались в основном для научно-технических расчетов, то в 60-70-е годы первое место стала занимать обработка символьной информации, в основном экономической.
IV поколение. е годы
Переход к машинам четвертого поколения – ЭВМ на больших интегральных схемах (БИС) – происходил во второй половине 70-х годов и завершился приблизительно к 1980 г. Теперь на одном кристалле размером 1 см2 стали размещаться сотни тысяч электронных элементов. Скорость и объем памяти возросли в десятки тысяч раз по сравнению с машинами первого поколения и составили примерно 109 операций в секунду и 107 слов соответственно.
Наиболее крупным достижением, связанным с применением БИС, стало создание микропроцессоров, а затем на их основе микро-ЭВМ. Если прежние поколения ЭВМ требовали для своего расположения специальных помещений, системы вентиляции, специального оборудования для электропитания, то требования, предъявляемые к эксплуатации микро-ЭВМ, ничем не отличаются от условий эксплуатации бытовых приборов. При этом они имеют достаточно высокую производительность, экономичны в эксплуатации и дешевы.
Микро-ЭВМ используются в измерительных комплексах, системах числового программного управления, в управляющих системах различного назначения.
Дальнейшее развитие микро-ЭВМ привело к созданию персональных компьютеров (ПК), широкое распространение которых началось с 1975 г., когда фирма IBM выпустила свой первый персональный компьютер IBM PC.
В период машин четвертого поколения стали также серийно производиться супер-ЭВМ. В нескольких серийных моделях была достигнута производительность свыше 1 млрд. операций в секунду.
К числу наиболее значительных разработок четвертого поколения относится ЭВМ «Крей-3».
Примером отечественной суперЭВМ является многопроцессорный вычислительный комплекс «Эльбрус».
V поколение. 1990-настоящее время
С 90-х годов в истории развития вычислительной техники наступила пора пятого поколения. Высокая скорость выполнения арифметических вычислений дополняется высокими скоростями логического вывода.
Сверхбольшие интегральные схемы повышенной степени интеграции, использование оптоэлектронных принципов (лазеры, голография).
Способны воспринимать информацию с рукописного или печатного текста, с бланков, с человеческого голоса, узнавать пользователя по голосу, осуществлять перевод с одного языка на другой. Используются модели и средства, разработанные в области искусственного интеллекта. Архитектура содержит несколько блоков: блок общения – обеспечивает интерфейс между пользователем и ЭВМ на естественном языке; база знаний – хранятся знания, накопленные человечеством в различных предметных областях; решатель - организует подготовку программы решения задачи на основании знаний, получаемых из базы знаний и исходных данных, полученных из блока общения. Ядро вычислительной системы составляет ЭВМ высокой производительности.
В связи с появлением новой базовой структуры ЭВМ в машинах пятого поколения широко используются модели и средства, разработанные в области искусственного интеллекта.
Классификация ЭВМ
Существует достаточно много систем классификации по различным признакам.
I. Классификация по назначению:
1) СуперЭВМ предназначены для решения крупномасштабных вычислительных задач, для обслуживания крупнейших информационных банков данных. Это очень мощные компьютеры с производительностью свыше 100 мегафлопов (1 мегафлоп — миллион операций с плавающей точкой в секунду). Они называются сверхбыстродействующими. Эти машины представляют собой многопроцессорные и (или) многомашинные комплексы, работающие на общую память и общее поле внешних устройств. Различают суперкомпьютеры среднего класса, класса выше среднего и переднего края (high end).
2) Большие ЭВМ - для комплектования ведомственных, территориальных и региональных вычислительных центров. Мэйнфреймы предназначены для решения широкого класса научно-технических задач и являются сложными и дорогими машинами. Их целесообразно применять в больших системах при наличии не менее 200 — 300 рабочих мест.
3) Средние ЭВМ - широкого назначения для управления сложными технологическими производственными процессами. ЭВМ этого типа могут использоваться и для управления распределенной обработкой информации в качестве сетевых серверов.
4) Персональные и профессиональные ЭВМ, позволяющие удовлетворять индивидуальные потребности пользователей. На базе этого класса ЭВМ строятся автоматизированные рабочие места (АРМ) для специалистов различного уровня.
5) Встраиваемые микропроцессоры, осуществляющие автоматизацию управления отдельными устройствами и механизмами.
II. Классификация ПК по типоразмерам:
1) Настольные (desktop) - используются для оборудования рабочих мест, отличаются простотой изменения конфигурации. Наиболее распространены.
2) Портативные – удобны для транспортировки, можно работать при отсутствии рабочего места.
Основные разновидности портативных компьютеров:
III. Классификация по условиям эксплуатации:
По условиям эксплуатации компьютеры делятся на два типа:
1) офисные (универсальные) – на их основе можно собирать вычислительные системы произвольного состава;
2) специализированные – предназначены для решения конкретного круга задач (например, бортовые компьютеры автомобилей, самолетов).
Лекция №2. Арифметические основы ЭВМ
В позиционных системах счисления один и тот же числовой знак (цифра) в записи числа имеет различные значения в зависимости от того места (разряда), где он расположен. Изобретение позиционной нумерации, основанной на поместном значении цифр, приписывается шумерам и вавилонянам; развита была такая нумерация индусами и имела неоценимые последствия в истории человеческой цивилизации. К числу таких систем относится современная десятичная система счисления, возникновение которой связано со счётом на пальцах. В средневековой Европе она появилась через итальянских купцов, в свою очередь заимствовавших её у мусульман.
Под позиционной системой счисления обычно понимается b-ричная система счисления, которая определяется целым числом b > 1, называемым основанием системы счисления. Целое число x в b-ричной системе счисления представляется в виде конечной линейной комбинации степеней числа b:
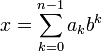 ,
,
где ak — это целые числа, называемые цифрами, удовлетворяющие неравенству 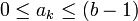 .
.
Каждая степень bk в такой записи называется весовым коэффициентом разряда. Старшинство разрядов и соответствующих им цифр определяется значением показателя k (номером разряда). Обычно для ненулевого числа x требуют, чтобы старшая цифра an − 1 в b-ричном представлении x была также ненулевой.
Если не возникает разночтений (например, когда все цифры представляются в виде уникальных письменных знаков), число x записывают в виде последовательности его b-ричных цифр, перечисляемых по убыванию старшинства разрядов слева направо:
![]()
Например, число сто три представляется в десятичной системе счисления в виде:
![]()
Наиболее употребляемыми в настоящее время позиционными системами являются:
Лекция №3
Основными, базовыми операциями, которые обязательно должен «уметь» выполнять процессор компьютера над двоичными кодами данных, являются логические операции отрицания, дизъюнкции, конъюнкции, арифметического сложения, а также сдвига кода. Используемые для реализации этих и других операций устройства принято называть вентилями.
3.2.3. Вентиль «НЕ»
Рассмотрим поведение схемы, изображенной на рис. 3.4, а, при различных значениях входного бита р. Пусть на вход схемы подано значение р = 0. Тогда транзистор заперт, он ведет себя в цепи как дополнительный резистор с сопротивлением, гораздо большим, чем сопротивление резистора, через который транзистор подключен к источнику питания схемы. В силу того что падение напряжения на участке цепи пропорционально сопротивлению этого участка, напряжение в точке выхода будет мало отличаться от высокого напряжения источника питания. Другими словами, на выходе схемы в этом случае формируется значение 1.
|
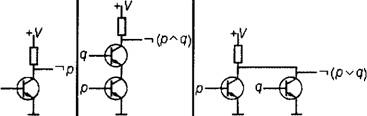
3.2.4. Вентили «НЕ И» и «НЕ ИЛИ»
Рассмотрим логику работы схемы, изображенной на рис. 3.4, б. Она состоит из двух соединенных последовательно транзисторов. У этой схемы два входа, обозначенных на рисунке буквами р и q, и один выход. Если на входы поступают единичные значения (р=1и<7=1), то оба транзистора открыты, участок цепи с ними имеет очень маленькое сопротивление и, следовательно, как и в вентиле «НЕ», на выходе формируется значение 0. Во всех остальных случаях хотя бы один из транзисторов оказывается запертым и участок цепи с транзисторами обладает высоким сопротивлением, что приводит к формированию на выходе значения 1. Анализируя таблицу истинности работы этой схемы (табл. 3.1, четвертый столбец), приходим к выводу, что она описывается выражением По
этому такая схема называется вентилем «НЕ И». Эта операция известна также под названием «штрих Шеффера». Ее обозначают значком «|»
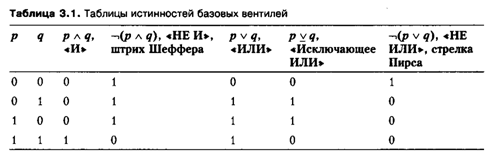
В схеме, изображенной на рис. 3.4, в, транзисторы соединены параллельно. Следовательно, участок цепи с транзисторами обладает высоким сопротивлением только в том случае, когда оба транзистора закрыты одновременно. Поэтому ес ли на оба входа поступают нулевые значения (р = 0 и q = 0), на выходе формируется значение 1. Во всех остальных случаях хотя бы один из транзисторов открыт и, следовательно, весь содержащий их параллельное соединение участок цепи обладает маленьким сопротивлением. Это значит, что на выходе схемы формируется значение 0. Анализируя таблицу истинности работы этой схемы (табл. 3.1, седьмой столбец), приходим к выводу, что она описывается выражением - i(p v q}. Поэтому такая схема называется вентилем «НЕ ИЛИ». Эта операция известна также под названием «стрелка Пирса». Ее обозначают значком
«>U: -.(р vg) = piq.
Вентили «НЕ», «НЕ И» и «НЕ ИЛИ», используемые для построения других вентилей и произвольных схем, считаются базовыми, а схемы, которые получаются с помощью всевозможных комбинаций базовых вентилей, принято называть цифровыми логическими схемами. Важным частным случаем цифровых схем являются комбинационные схемы, в которых значения, получаемые на выходах схемы, зависят только от значений, поступающих на ее входы. Такие схемы классифицируются также как схемы без памяти.
Использование в комбинационных схемах стандартных обозначений транзистора и других показанных на рис. 3.4, б обязательных элементов (значков земли, питания и т. д.) приводит к излишней громоздкости и затрудненному восприятию схем. Поэтому в комбинационных схемах используются условные обозначения для каждого из базовых вентилей в целом. Условные обозначения трех рассмотренных ранее вентилей приведены в нижней части рис. 3.4 под соответствующими им схемами.
Вентили «И» и «ИЛИ»
Теоретически для задания любой логической функции можно обойтись только одной операцией — стрелкой Пирса или штрихом Шеффера. Таким образом, вентили «НЕИ»и«НЕ ИЛИ» могут рассматриваться как универсальные, из которых можно составить схему, соответствующую любому логическому выражению. Но получаемые при этом логические выражения и соответствующие им цифровые схемы оказываются чрезвычайно громоздкими и малопонятными. В то же время известно, что логические функции удобно задавать, используя три основные логические операции: отрицание, дизъюнкцию и конъюнкцию. В связи с этим целесообразно использовать в комбинационных схемах вентили, соответствующие этим операциям.
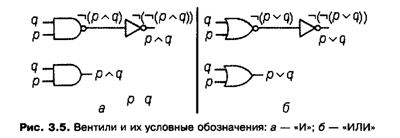
Способ построения вентилей для операций конъюнкции и дизъюнкции вытекает из очевидных соотношений -.(-.(р д <7)) = pA<7H-.(-i(pv q)) = pvq. Следовательно, соединив выходы вентилей «НЕ И» и «НЕ ИЛИ» со входом вентиля «НЕ», получим удобные для построения любых цифровых схем вентили «И» и «ИЛИ» операций конъюнкции и дизъюнкции соответственно. Схемы этих вентилей и их обозначения приведены на рис. 3.5. Вентили «И» и «ИЛИ» также относятся к базовым. Отметим, что для реализации вентиля «НЕ» достаточно одного транзистора, для вентилей «НЕ И» и «НЕ ИЛИ» требуется по два транзистора, а для вентилей «И» и «ИЛИ» необходимо уже по три транзистора на каждую схему.
Построение дизъюнктивной нормальной формы

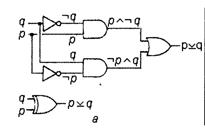
Вентиль «Исключающее ИЛИ»
Рассмотренная в предыдущем разделе операция «Исключающее ИЛИ» оказывается полезной во многих случаях построения комбинационных схем. Опираясь на полученную ДНФ этой операции (pyq) = (->pAq)v(pA-lq) и используя базовые вентили «НЕ», «И» и «ИЛИ», довольно легко построить соответствующую схему. Для реализации выражения в первой паре скобок выход вентиля «НЕ» следует соединить с одним из входов вентиля «И». Значения pnq подаются на оставшийся свободным вход вентиля «И» и на вход вентиля «НЕ» соответственно. Таким образом, на выходе вентиля «И» получится значение выражения р л ->q. Подключив вентиль «НЕ» к другому в^оду еще одного вентиля «И» при том же порядке подсоединения р и q, на его выходе получим выражение, находящееся во второй паре скобок, - i р л q. Теперь осталось выходы вентилей «И» соединить со входами вентиля «ИЛИ». Полученная схема вентиля «Исключающее ИЛИ» и его условное обозначение приведены на рис. 3.6, а. Для реализации этого вентиля требуется 11 транзисторов.
Комбинационная схема сумматора
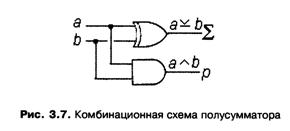
Теперь рассмотрим комбинационные схемы, с помощью которых может быть реализовано арифметическое сложение. Анализ алгоритма сложения двоичных кодов показывает, что сложение младших битов и сложение всех остальных битов слагаемых производится по-разному. Различие обусловлено необходимостью учитывать биты переносов для всех битов слагаемых, кроме первого. Комбинационная схема, которая реализует сложение только для двух младших битов слагаемых, называется полусумматором, а схема, реализующая сложение для всех остальных битов слагаемых, называется сумматором, иногда используется также название полный сумматор.

Введем следующие обозначения. Пусть а и b — участвующие в операции биты слагаемых, X — бит результата, а р — бит переноса в следующий разряд. Основываясь на правилах сложения двоичных кодов, получим, что работа полусумматора может быть описана табл. 3.2. Видно, что для бита переноса справедливо соотношение р = алЬ, а бит суммы X получаете я как результат операции «Исключающее ИЛИ», X = я У Ь. Схема полусумматора должна иметь два входа, на которые подаются складываемые биты а и и два выхода, на которых формируются бит суммы и бит переноса. Эти соображения приводят к изображенной на рис. 3.7 схеме полусумматора. Для ее реализации требуется 14 транзисторов.
При сложении каждой следующей пары битов слагаемых необходимо учитывать бит переноса из предыдущего разряда. Следовательно, эта операция зависит от трех аргументов, а соответствующая комбинационная схема должна иметь три входа. В результате сложения текущей пары битов получаете n бит текущего разряда суммы и бит переноса в следующий разряд. Поэтому схема должна иметь два выхода. Пусть, как и ранее, а и Ь обозначают биты слагаемых, а I - бит результата. Пусть далее рт — бит переноса из предыдущего разряда, a pout — бит переноса в следующий разряд. Тогда суммирование с учетом переносов можно описать в табл. 3.3.
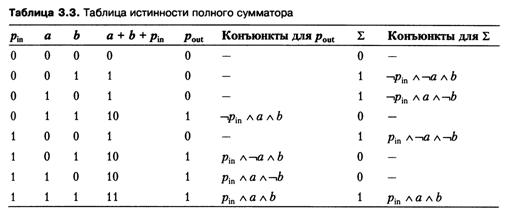
Применим технику построения ДНФ для каждого из результирующих битов операции. В табл. 3.3 приведены конъюнкты только для тех строк, которые участвуют в построении соответствующей нормальной формы. Вначале построим выражение для бита X (скобки проставлены для упрощения восприятия конъюнктов, из которых образована ДНФ):
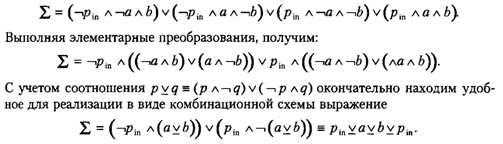
Эта схема может быть построена на базе двух последовательно соединенных вентилей «Исключающее ИЛИ». На входы первого вентиля следует подать суммируемые биты, а на входы второго вентиля — выход с первого вентиля и бит переноса.
Построим теперь ДНФ для бита переноса в следующий разряд:
![]()
Группируя первую и последнюю, а также вторую и третью скобки и вынося общие множители, получим удобное для реализации в виде комбинационной схемы выражение
Комбинационная схема полного сумматора приведена на рис. 3.8. Отметим, что для ее реализации требуется 31 транзистор.
Комбинационная схема сдвига
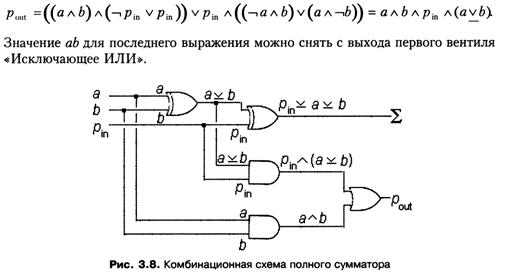
Во время обсуждения умножения в двоичной системе счисления выяснилось, что эта операция, в принципе, сводится к сложению и сдвигу кода. Различают несколько разновидностей сдвига. Сдвиг кода влево означает, что каждый его бит перемещается на соседнюю слева позицию, при этом освободившийся младший (самый правый) разряд поля заполняется нулем, а самый левый бит кода теряется. Про такой бит говорят, что он выталкивается за разрядную сетку. Например, сдвиг кода влево дает в результате код (рис. 3.9, a). Сдвиг вправо осуществляется в противоположном направлении: каждый бит кода занимает соседний справа разряд, при этом освободившийся старший (самый левый) разряд поля заполняется нулем, а младший бит кода выталкивается за разрядную сетку, теряется. Сдвиг того же самого кода вправо дает в результате код (рис. 3.9, б). Существуют еще и так называемые циклические сдвиги кода, в которых выталкиваемый бит кода не теряется, а записывается в освободившийся слева или справа разряд поля.
Внимательный анализ результатов обычного сдвига двоичного кода показывает, что сдвиг влево эквивалентен умножению на два, а сдвиг вправо эквивалентен целочисленному делению на два. Так, в приведенных ранее примерах коду , рассматриваемому как код в формате с фиксированной точкой, соответствует число 4510. Сдвиг этого кода влево дает в результате код числа 9010, а сдвиг вправо — код числа 2210. Для получения корректного результата в случае умножения необходимо, чтобы поле было достаточной для получаемого кода длины, — точнее, чтобы выталкиваемые влево биты не были равны единице.
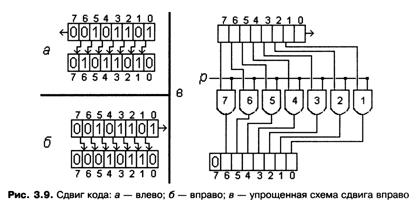
В рассмотренных ситуациях сдвиг осуществлялся на одну позицию вправо или влево. Имеет смысл рассматривать также сдвиги вправо и влево на несколько позиций, что отвечает умножению или делению на соответствующую степень двойки. Таким образом, сдвиг кода может использоваться не только как вспомогательное действие при реализации общей операции умножения двоичных кодов, но и как самостоятельная операция умножения или целочисленного деления на числа вида 2п для целых п > 0. Отметим, что операция сдвига выполняется процессорами компьютеров гораздо быстрее, чем общая операция умножения или деления.
На рис. 3.9, в представлена упрощенная комбинационная схема, реализующая сдвиг восьмибитного кода вправо на одну позицию. Каждому биту сдвигаемого кода, кроме выталкиваемого младшего бита, соответствует отдельный вентиль «И». На рис. 3.9, в эти вентили имеют те же номера, что и соответствующие им биты кода. Каждый бит кода соединен со входом соответствующего ему вентиля, а на второй вход каждого вентиля через единую линию поступает управляющий бит р. Если р = 1, то на выходе каждого вентиля дублируется связанный с ним бит кода. Эти выходы соединены с разрядами поля, предназначенного для хранения результата. Обратите внимание: выход каждого вентиля соединен с разрядом поля, номер которого на единицу меньше, чем номер вентиля, что, собственно говоря, и приводит к нужному сдвигу кода. В крайнем слева разряде, для которого нет соответствующего вентиля, автоматически формируется нуль.
Сдвиг кода влево можно организовать с помощью симметричной схемы; в ней выходы вентилей «И» соединены с разрядами поля, номера которых на единицу больше, чем номера соответствующих им вентилей. В более общих схемах оба варианта, которые обеспечивают сдвиги вправо и влево, объединяются в одну схему с единым управляющим битом, поступающим в две управляющие линии, причем в одну из них через вентиль «НЕ». Таким образом, значение р = 1 запускает сдвиг в одну сторону, а значение р = 0 обеспечивает сдвиг в другую сторону. В такой схеме сдвига используется 2n вентилей «И», где n — количество сдвигаемых разрядов, и один вентиль «НЕ». Следовательно, для ее реализации требуется бn + 1 транзисторов.
Компаратор
Еще одной важной операцией, которую, безусловно, должен «уметь» выполнять процессор, является сравнение двух кодов на совпадение. Для ее реализации можно использовать комбинационную схему компаратора, восьмибитный вариант которой изображен на рис. 3.10.
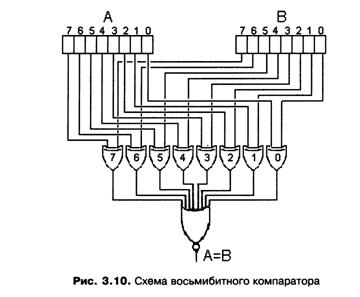
Биты сравниваемых кодов А и В, имеющие один и тот же номер, присоединяются ко входам одного и того же вентиля «Исключающее ИЛИ». На рис. 3.10 вентили обозначены номерами, которые совпадают с номерами подключенных к ним битов. Выходы всех вентилей «Исключающее ИЛИ» присоединены к многовходовому вентилю «НЕ ИЛИ». Таким образом, если все биты кодов А и В совпадают, то все вентили «Исключающее ИЛИ» сформируют на своих выходах значение 0, попадающее затем на многовходовый вентиль «НЕ ИЛИ». А если на его входах все нули, то на выходе всей схемы формируется 1. В то же время, если в кодах А и В не совпадает хотя бы одна пара битов, то соответствующий вентиль «Исключающее ИЛИ» выдаст на выходе значение 1. Появление на входах вентиля «НЕ ИЛИ» хотя бы одной единицы приведет к формированию на его выходе значения 0. Таким образом, на выходе компаратора всегда формируется значение логического выражения А = В. Отметим, что для реализации компаратора, осуществляющего сравнение двух «-битовых кодов, необходимо п вентилей «Исключающее ИЛИ» и один n-входовый вентиль «НЕ И», следовательно, требуется 11/2 + 2 (n — 1) = 13n - 2 транзисторов.
Декодер и мультиплексор
Выполнение над двоичными кодами таких операций, как дизъюнкция, конъюнкция, сложение и т. д., целесообразно осуществлять с помощью только одной комбинационной схемы, обеспечивающей возможность не только выполнения, но и выбора нужной операции. Выбор одного из нескольких вариантов осуществляется с помощью схемы, которая называется декодером.
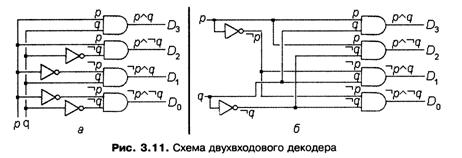
В общем случае в декодере за каждым из рассматриваемых вариантов закрепляется поступающий на входные линии схемы n-разрядный двоичный код. Очевидно, что с его помощью можно закодировать 2^n различных вариантов. Каждому из них в схеме соответствует отдельный n-входовый вентиль «И», входы которого соединяются с входами схемы либо напрямую, либо через вентиль «НЕ» (рис. 3.11, а). Таким образом, все входы отдельно взятого вентиля «И» в совокупности соответствуют конъюнкту, зависящему от n аргументов. Для любого значения поступившего на вход схемы двоичного кода только для одного из вентилей «И» значение конъюнкта оказывается равным 1, и, следовательно, только на его выходе формируется значение 1. На выходах всех остальных вентилей формируется значение 0. Появление на одном из выходов схемы значения 1 трактуется как выбор варианта, который соответствует поступившему на вход управляющему коду.
В качестве примера рассмотрим двухвходовый декодер, изображенный на рис. 3.11, а. Этот декодер управляется двухбитовым кодом, обеспечивающим выбор одного из четырех вариантов. В схеме использованы следующие обозначения: р и q — входы, принимающие управляющий код, a D0-D3 — выбираемые выходы. Закрепим за выходами схемы управляющие коды: 002 —> D0, 012 —> Du 102 —> D3, 112 -> D3, — и составим конъюнкты, которые определяют подсоединяемые к вентилям входы схемы или их отрицания. В результате за каждым вентилем закрепляется один из четырех возможных конъюнктов. На рис. 3.11 эти конъюнкты приведены над соответствующими им выходами схемы. При подаче на входы схемы любого из двухбитовых кодов только один из вентилей сформирует на своем выходе 1. Именно этот выход считается выбранным. Пусть, например, р = 0 и q = 1. Тогда значение 1 имеет только конъюнкт, которому соответствует выход Dx, а на всех остальных выходах формируется 0. Таким образом, декодер по поступившей на входные линии комбинации битов 012 выбирает выход Д.
Для создания n-входового декодера, изображенного на рис. 3.11, а, необходимо 2^n вентилей «И» и в 2 раза меньше вентилей «НЕ», — следовательно, всего требуется 3 • 2n + 2n"1 = 7 • 2п~1 транзисторов. На рис. 3.11, б изображена эквивалентная схема, то есть схема, описываемая точно такой же таблицей истинности, что и схема на рис. 3.11, а. Видно, что для реализации правой схемы требуется меньше вентилей «НЕ», чем для реализации левой. Это связано с тем, что отрицания одного и того же входа схемы снимаются с одной и той же линии, а не формируются по отдельности для каждого вентиля «И». Для создания такой схемы необходимо всего п вентилей «НЕ», следовательно, на схему требуется только 3 • 2n + n транзисторов. Приведенный пример показывает, что одной и той же цели можно достичь с помощью различных цифровых схем, обладающих разными требованиями к ресурсам, в частности, к количеству требующихся для их реализации вентилей.
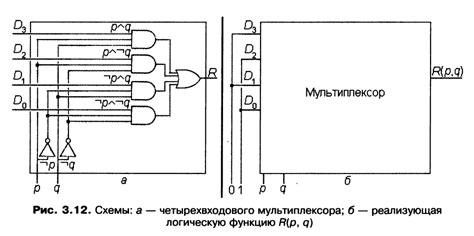
Задача выбора одного из нескольких входных значений и передачи его на выход схемы решается похожим образом с помощью устройства, которое называется мультиплексором. В общем случае мультиплексор содержит 2n основных входных линий, n входных линий управления и один выход. Схема состоит из 2n многовходовых вентилей «И» и одного также многовходового вентиля «ИЛИ». В качестве примера на рис. 3.12, а приведена схема четырехвходового мультиплексора, способного выбрать один из четырех входных битов и передать выбранный бит на единственную выходную линию устройства R. Для выбора нужного варианта в четырехвходовом мультиплексоре используются две линии управления, р и q.
Схема работает следующим образом. Один из входов каждого вентиля «И» считается основным. Он соединяется с одним из выбираемых входов схемы. Каждый из оставшихся n входов вентиля «И» так же, как в декодере, соединяется с одной из управляющих линий схемы либо напрямую, либо через вентиль «НЕ». Таким образом, эти входы вентиля «И» в совокупности соответствуют конъюнкту, зависящему от п аргументов. На рис. 3.12 конъюнкты изображены над соответствующей им линией основного входа вентиля. На управляющие линии схемы подается n-разрядный двоичный код, на котором только один из конъюнктов принимает единичное значение. На выходе соответствующего этому коду вентиля «И» дублируется бит его основной входной линии, а на выходах всех остальных вентилей формируется значение 0. Затем бит из выбранной входной линии через вентиль «ИЛИ» подается на выход мультиплексора.
Обсуждаемая схема может быть использована и в других целях. В частности, на базе мультиплексора можно создать схему, моделирующую любую логическую функцию от n аргументов. Для этого нужно построить таблицу истинности этой функции и подать 1 на все основные входы схемы, соответствующие конъюнктам со значением 1, а на все остальные основные входы подать значение 0. Тогда при поступлении на управляющие входы схемы конкретных значений аргументов на ее выходе получится значение моделируемой логической функции от этих аргументов.

Обсудим еще одно важное применение схемы мультиплексора. Она используется для преобразования п битов, одновременно передаваемых по разным линиям, в последовательность из п битов, передаваемых друг за другом по одной линии (рис. 3.13). Такое преобразование приходится выполнять, например, при передаче данных от одного компьютера к другому по линиям связи в компьютерных сетях, поскольку внутри компьютера биты одного или нескольких байтов обычно передаются между устройствами компьютера одновременно — параллельно, в то время как по внешним линиям связи данные, как правило, передаются последовательно.
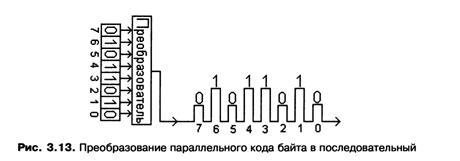
Для выполнения обсуждаемого преобразования нужно подсоединить к основным входам мультиплексора все линии, по которым одновременно передаются биты. А на его управляющие входы подавать последовательность двоичных кодов, которые осуществляют выбор основных входных линий в желательном порядке. Например, подача на управляющие линии четырехвходового мультиплексора кода 002, то есть р = 0 и q = 0, приведет к выбору основного входа D0 и передаче находящегося на нем бита на выход схемы. Если немного позднее подать на входы управляющий код 012, то на выход попадет бит с основного входа Dx. Последующая подача кодов 102 и 112 передаст на выход биты сначала со входа D2, а затем и со входа D3. Таким образом, параллельно передаваемый код окажется преобразованным в код, передаваемый последовательно. Нужно только своевременно фиксировать или же передавать дальше биты, последовательно попадающие на выход схемы.
Арифметико-логическое устройство
Все функции процессора, связанные с выполнением тех или иных действий над данными, сосредоточены в его внутреннем блоке, который принято называть арифметико-логическим устройством (АЛУ).
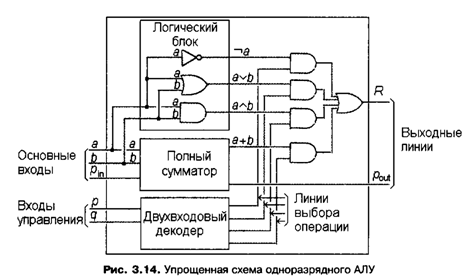 Обычно АЛУ, обеспечивающие выполнение действий над n-разрядными данными, состоят из n одинаковых схем, которые выполняют эти действия над двумя битами. Такие схемы называются одноразрядными АЛУ. На рис. 3.14 приведена упрощенная схема одноразрядного АЛУ, которое может выполнять логические операции отрицания, конъюнкции, дизъюнкции и арифметического сложения над двумя битами данных.
Обычно АЛУ, обеспечивающие выполнение действий над n-разрядными данными, состоят из n одинаковых схем, которые выполняют эти действия над двумя битами. Такие схемы называются одноразрядными АЛУ. На рис. 3.14 приведена упрощенная схема одноразрядного АЛУ, которое может выполнять логические операции отрицания, конъюнкции, дизъюнкции и арифметического сложения над двумя битами данных.
В схему по трем основным входным линиям поступают два бита данных, аиb, а также бит переноса из предыдущего разряда pin. Кроме того, в схему поступают два управляющих бита, р и q, значения которых определяют выбор желательной операции. На выходах схема формирует бит результата R и бит переноса в следующий разряд pont. Одноразрядное АЛУ содержит блок выполнения логических операций, отвечающий за операции отрицания, дизъюнкции и конъюнкции, полный сумматор, отвечающий за арифметическое сложение, и декодер, организующий выбор требуемой операции.
На входы логического блока и полного сумматора поступают биты данных а и b, а на вход полного сумматора еще и бит переноса pin. Результаты выполнения операции одновременно формируются на трех выходах вентилей «НЕ», «ИЛИ», «И» логического блока и двух выходах полного сумматора. Бит переноса в следующий разряд pout сразу попадает на выход АЛУ, а результирующие биты операций подаются сначала в подсистему выбора нужного результата. В этой подсистеме для каждой из четырех операций предусмотрен отдельный вентиль «И», на один из входов которого поступает результат этой операции, второй его вход соединен с выходной линей декодера. Декодер, получив на входах некоторую комбинацию управляющих битов р и q, формирует значение 1 на выходе, который соответствует этой комбинации. Таким образом, только тот вентиль «И», который подсоединен к этому выходу декодера, дублирует на своем выходе результат выбранной операции, остальные вентили формируют на выходе нулевое значение. Чтобы не организовывать несколько отдельных выходных линий из АЛУ, выходы всех вентилей «И» соединены четырехвходовым вентилем «ИЛИ», выход которого является выходом R всей схемы АЛУ.
Простой подсчет показывает, что для реализации описанного одноразрядного АЛУ требуется 67 транзисторов, а для аналогичного арифметико-логического устройства, обеспечивающего действия над n-разрядными данными, 67n транзисторов. Например, для шестнадцатибитного АЛУ нужно 1072 транзистора. Следует иметь в виду, что в учебных целях здесь рассмотрен значительно упрощенный вариант схемы, который отражает только некоторые принципы устройства АЛУ. Реальные АЛУ процессоров могут выполнять значительно большее количество операций, устроены более сложно и, естественно, требуют гораздо большего количества транзисторов.
Схема памяти на базовых вентилях
 Схемы, состоящие из базовых вентилей, применяются не только для создания устройств, выполняющих действия над данными. Они используются также и для реализации одной из разновидностей памяти в компьютере. Но схемы памяти не могут быть отнесены к группе комбинационных схем, так как получаемый на их выходах результат зависит не только от поступивших на вход данных, но и от текущего состояния схемы. Собственно говоря, эта зависимость и обеспечивает принципиальную возможность запоминания данных. Схемы, обладающие такими свойствами, относятся к группе последовательных схем. Кроме того, для них используется название «автоматы с памятью».
Схемы, состоящие из базовых вентилей, применяются не только для создания устройств, выполняющих действия над данными. Они используются также и для реализации одной из разновидностей памяти в компьютере. Но схемы памяти не могут быть отнесены к группе комбинационных схем, так как получаемый на их выходах результат зависит не только от поступивших на вход данных, но и от текущего состояния схемы. Собственно говоря, эта зависимость и обеспечивает принципиальную возможность запоминания данных. Схемы, обладающие такими свойствами, относятся к группе последовательных схем. Кроме того, для них используется название «автоматы с памятью».
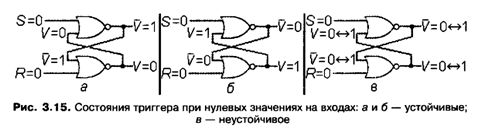
Устройство на базовых вентилях, которое можно использовать для хранения одного бита данных, называется триггером, или SR-защелкой.
ВНИМАНИЕ ------
Триггером (от trigger — защелка, спусковой крючок) называется устройство, которое может сколь угодно долго находиться в одном из двух состояний устойчивого равновесия и переключается из одного состояния в другое скачком по сигналу или воздействию извне. Триггер может быть реализован, в частности, на электровакуумных лампах накаливания и на полупроводниковых устройствах.
Триггер состоит из двух вентилей «НЕ ИЛИ», выход каждого из которых соединен с одним из входов другого (рис. 3.15). Для управления работой триггера используются свободные входы вентилей, которые обычно называют входом S (от setting — установка) и входом R (от resetting — сброс). От названий входов образовано иногда используемое название этого устройства — SR-защелка. Выходы вентилей V и ![]() считаются соответственно основным и дополнительным выходами всего триггера в целом. Поскольку выходы вентилей V и
считаются соответственно основным и дополнительным выходами всего триггера в целом. Поскольку выходы вентилей V и ![]() одновременно являются их же входами, в дальнейшем они называются «входами/выходами» вентилей.
одновременно являются их же входами, в дальнейшем они называются «входами/выходами» вентилей.
Рассмотрим принцип действия этого устройства. Теоретически возможны 16 различных состояний триггера, соответствующих всем возможным комбинациям значений на входах S и R, а также на входах/выходах V и ![]() . Однако, как мы увидим далее, некоторые комбинации значений приводят к возникновению неустойчивых состояний триггера, которые тут же самопроизвольно переходят в устойчивые состояния, способные сохраняться в неизменном виде сколь угодно долго.
. Однако, как мы увидим далее, некоторые комбинации значений приводят к возникновению неустойчивых состояний триггера, которые тут же самопроизвольно переходят в устойчивые состояния, способные сохраняться в неизменном виде сколь угодно долго.
Рассмотрим поведение триггера при поступлении на входы значений S = 0 и R = 0. Вначале допустим, что при этом на входах/выходах уже находятся значения V = 0 и V = 1 (рис. 3.15, а). Тогда за один такт работы схемы верхний вентиль сформирует на дополнительном выходе ![]() значение
значение ![]() (S v V) = 1 а нижний вентиль сформирует на основном выходе V значение
(S v V) = 1 а нижний вентиль сформирует на основном выходе V значение ![]() (R v
(R v ![]() )= 0. Поскольку эти значения совпадают с исходными, такое состояние триггера является состоянием устойчивого равновесия, или просто устойчивым.
)= 0. Поскольку эти значения совпадают с исходными, такое состояние триггера является состоянием устойчивого равновесия, или просто устойчивым.
Аналогичная ситуация наблюдается, если в момент поступления на входы триггера S и R нулевых значений на входах/выходах находятся значения V = 1 и ![]() = 0 (рис. 3.15, 6). Тогда верхний вентиль за такт сформирует на выходе V значение
= 0 (рис. 3.15, 6). Тогда верхний вентиль за такт сформирует на выходе V значение ![]() (S v V) = 0, а нижний — на выходе V значение
(S v V) = 0, а нижний — на выходе V значение ![]() (R v
(R v ![]() ) = 1 Эти значения также совпадают с исходными, и, следовательно, такое состояние также устойчиво.
) = 1 Эти значения также совпадают с исходными, и, следовательно, такое состояние также устойчиво.
Пусть теперь оба входа/выхода находятся в начальном нулевом состоянии V = 0 и ![]() = 0 (рис. 3.15, б). Тогда и нижний, и верхний вентили сформируют на выходах Vи
= 0 (рис. 3.15, б). Тогда и нижний, и верхний вентили сформируют на выходах Vи![]() значения
значения ![]() (R v
(R v ![]() ) = 1 и
) = 1 и ![]() (S v
(S v ![]() ) = 1 которые, вновь поступая на входы вентилей, сформируют на их выходах новые значения
) = 1 которые, вновь поступая на входы вентилей, сформируют на их выходах новые значения ![]() (R v
(R v ![]() ) = 0 и
) = 0 и ![]() (S v
(S v ![]() ) = 0. Очевидно, что такое состояние триггера является неустойчивым, так как он циклически переходит из состояния, при котором V = 0 и
) = 0. Очевидно, что такое состояние триггера является неустойчивым, так как он циклически переходит из состояния, при котором V = 0 и ![]() = 0, в состояние, когда V = 1 и
= 0, в состояние, когда V = 1 и ![]() =1 Теоретически, этот циклический процесс может продолжаться сколь угодно долго. Но для этого необходимо, чтобы одинаковые значения появлялись на выходах строго одновременно. На практике в этой ситуации один из вентилей срабатывает немного быстрее, чем другой, и тогда триггер случайным образом переходит либо в состояние а, либо в состояние б.
=1 Теоретически, этот циклический процесс может продолжаться сколь угодно долго. Но для этого необходимо, чтобы одинаковые значения появлялись на выходах строго одновременно. На практике в этой ситуации один из вентилей срабатывает немного быстрее, чем другой, и тогда триггер случайным образом переходит либо в состояние а, либо в состояние б.
Итак, устойчивыми при S = 0 и R = 0 являются два состояния, когда на входах/выходах V и ![]() находятся различные значения, и неустойчивым — одно состояние, когда на них находятся одинаковые значения. Значение, находящееся на основном выходе триггера V в любом из устойчивых состояний, считается значением, хранящимся в триггере. Таким образом, на рис. 3.15, а изображен триггер, сохраняющий значение 0, а на рис. 3.15, б — триггер, сохраняющий значение 1.
находятся различные значения, и неустойчивым — одно состояние, когда на них находятся одинаковые значения. Значение, находящееся на основном выходе триггера V в любом из устойчивых состояний, считается значением, хранящимся в триггере. Таким образом, на рис. 3.15, а изображен триггер, сохраняющий значение 0, а на рис. 3.15, б — триггер, сохраняющий значение 1.
Рассмотрим поведение триггера при поступлении на его вход S значения 1, которое заменяет обычное его нулевое состояние. Пусть при этом на другом входе R находится нуль, R = 0. Допустим, что триггер в это время хранит значение 0. При этом V = 0 и ![]() = 1 (рис. 3.16, а). Тогда при срабатывании вентилей на выходах получаются нулевые значения
= 1 (рис. 3.16, а). Тогда при срабатывании вентилей на выходах получаются нулевые значения ![]() (R v
(R v ![]() ) = 0 и
) = 0 и ![]() (S v V) = 0. Следовательно, единица на дополнительном выходе
(S v V) = 0. Следовательно, единица на дополнительном выходе ![]() заменяется нулем (рис. 3.16, б), после чего срабатывает нижний вентиль
заменяется нулем (рис. 3.16, б), после чего срабатывает нижний вентиль ![]() (R v V)=1 и на основном выходе V формирует
(R v V)=1 и на основном выходе V формирует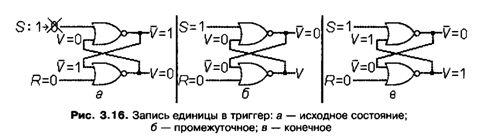 ся 1 (рис. 3.16, в). Появление единицы на основном выходе не приведет к дальнейшему изменению состояния триггера, так как
ся 1 (рис. 3.16, в). Появление единицы на основном выходе не приведет к дальнейшему изменению состояния триггера, так как ![]() (S v V) = 0 и значение на дополнительном выходе остается тем же самым. Следовательно, триггер переходит в устойчивое состояние, в котором на основном выходе V находится 1. Другими словами, установка входа S в состояние 1 переводит триггер из состояния 0 в состояние 1. Если же триггер при поступлении 1 на вход S уже хранит единицу, то есть V = 1 и
(S v V) = 0 и значение на дополнительном выходе остается тем же самым. Следовательно, триггер переходит в устойчивое состояние, в котором на основном выходе V находится 1. Другими словами, установка входа S в состояние 1 переводит триггер из состояния 0 в состояние 1. Если же триггер при поступлении 1 на вход S уже хранит единицу, то есть V = 1 и ![]() = 0, то срабатывание его вентилей дает
= 0, то срабатывание его вентилей дает ![]() (S v V) = 0 и
(S v V) = 0 и![]() (R v
(R v ![]() ) = 1, поэтому его состояние не изменится.
) = 1, поэтому его состояние не изменится.
Аналогичным образом можно убедиться в том, что при S=1иR = 0и исходных состояниях входов/выходов V = 0 и ![]() =0, а также V = 1 и
=0, а также V = 1 и ![]() = 1 триггер переходит в то же самое устойчивое состояние, при котором V = 1 и
= 1 триггер переходит в то же самое устойчивое состояние, при котором V = 1 и ![]() = 0. Следовательно, при любом исходном состоянии триггера появление 1 на входе S (при сохранении R = 0) переводит его в состояние 1. Можно считать, что эта ситуация эквивалентна записи значения 1 в триггер.
= 0. Следовательно, при любом исходном состоянии триггера появление 1 на входе S (при сохранении R = 0) переводит его в состояние 1. Можно считать, что эта ситуация эквивалентна записи значения 1 в триггер.
Пусть теперь значение 1 поступает на вход R, на входе S сохраняется значение 0, а триггер в это время находится в состоянии 0, то есть V = 0 и ![]() =1 Видно, что текущее состояние триггера эта управляющая комбинация не изменяет, так как срабатывание вентилей дает в результате
=1 Видно, что текущее состояние триггера эта управляющая комбинация не изменяет, так как срабатывание вентилей дает в результате ![]() (R v
(R v ![]() ) = 0 и
) = 0 и ![]() (S v V) = 1 Если же в начальном состоянии триггер хранит единицу (v = 1 и
(S v V) = 1 Если же в начальном состоянии триггер хранит единицу (v = 1 и ![]() = 0), то на дополнительном выходе формируется
= 0), то на дополнительном выходе формируется ![]() (S v V) = 1, последующее поступление которой на нижний вентиль дает
(S v V) = 1, последующее поступление которой на нижний вентиль дает ![]() (R v
(R v ![]() )= 0, то есть триггер переходит в состояние 0. Аналогичным образом можно показать, что при S=0 и R=1 и исходных V = 0 и
)= 0, то есть триггер переходит в состояние 0. Аналогичным образом можно показать, что при S=0 и R=1 и исходных V = 0 и ![]() = 0, а также V = 1 и
= 0, а также V = 1 и ![]() = 1 триггер также переходит в состояние 0. Следовательно, при любом исходном состоянии триггера появление 1 на входе R (при сохранении S = 0) переводит триггер в состояние 0. Можно считать, что эта ситуация эквивалентна записи 0 в триггер. Итак, триггер запоминает, на каком его входе S или R в последний раз было единичное значение. На основе этого свойства конструируются некоторые реальные схемы памяти компьютера.
= 1 триггер также переходит в состояние 0. Следовательно, при любом исходном состоянии триггера появление 1 на входе R (при сохранении S = 0) переводит триггер в состояние 0. Можно считать, что эта ситуация эквивалентна записи 0 в триггер. Итак, триггер запоминает, на каком его входе S или R в последний раз было единичное значение. На основе этого свойства конструируются некоторые реальные схемы памяти компьютера.
 Легко убедиться в том, что при поступлении на входы значений S=1 и R = 1 триггер может находиться только в одном устойчивом состоянии. При этом оба его выхода равны нулю одновременно, V = 0 и
Легко убедиться в том, что при поступлении на входы значений S=1 и R = 1 триггер может находиться только в одном устойчивом состоянии. При этом оба его выхода равны нулю одновременно, V = 0 и ![]() = 0. Любые другие состояния при этом неустойчивы и случайным образом переходят в указанное устойчивое. В £амом деле, пусть, например, в исходном состоянии V = 0 и
= 0. Любые другие состояния при этом неустойчивы и случайным образом переходят в указанное устойчивое. В £амом деле, пусть, например, в исходном состоянии V = 0 и ![]() = 1 тогда
= 1 тогда ![]() (R v
(R v ![]() ) = 0 и
) = 0 и ![]() (S v V) = 0, и триггер переходит в устойчивое состояние, V = 0 и
(S v V) = 0, и триггер переходит в устойчивое состояние, V = 0 и ![]() =0. Такой же результат получается и для остальных вариантов исходных значений на входах/выходах V и
=0. Такой же результат получается и для остальных вариантов исходных значений на входах/выходах V и![]() . Поскольку для S = 1 и R=1 триггер обладает только одним устойчивым состоянием, эта комбинация для управления его работой не используется.
. Поскольку для S = 1 и R=1 триггер обладает только одним устойчивым состоянием, эта комбинация для управления его работой не используется.
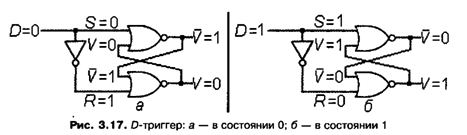
Чтобы избежать одновременного появления на входах единичных значений S = 1 и R = 1, которое приводит триггер в неиспользуемое состояние, схему триггера немного модифицируют, оставляя у него только один вход, который принято называть входом D (рис. 3.17). Значение с входа D триггера подается на входы S и R верхнего и нижнего вентилей «НЕ ИЛИ», но на один из входов значение попадает через вентиль «НЕ». Таким образом, значения на входах S и R этих вентилей всегда не совпадают. При этом значение на основном выходе триггера V, то есть хранимое в триггере значение всегда совпадает со значением на входе D. Такую схему принято называть D-триггером. На рис. 3.17, а показан D-триггер, хранящий значение 0, а на рис. 3.17, б — этот же триггер со значением 1.
Итак, описанное устройство позволяет записывать и сохранять сколь угодно долго одну из двоичных цифр, то есть представляет собой одну из возможных физических реализаций элемента памяти компьютера объемом в 1 бит. Чтобы обеспечить удобный способ записи и чтения, а также минимизировать количество необходимых для реализации схемы транзисторов, на практике в качестве бита памяти используются более совершенные схемы D-триггеров, для реализации которых требуется только 6 транзисторов.
Лекция № 4 (Основы построения ЭВМ – 2 часа)
В настоящее время наибольшее распространение в ЭВМ получили 2 типа архитектуры: принстонская (неймановская) и гарвардская. Обе они выделяют 2 основных узла ЭВМ: центральный процессор и память компьютера. Различие заключается в структуре памяти: в принстонской архитектуре программы и данные хранятся в одном массиве памяти и передаются в процессор по одному каналу, тогда как гарвардская архитектура предусматривает отдельные хранилища и потоки передачи для команд и данных.
По перечисленным признакам и их сочетаниям среди архитектур выделяют:
§ По разрядности интерфейсов и машинных слов: 8-, 16-, 32-, 64-, 128- разрядные (ряд ЭВМ имеет и иные разрядности);
§ По особенностям набора регистров, формата команд и данных: CISC, RISC, VLIW;
§ По количеству центральных процессоров: однопроцессорные, многопроцессорные, суперскалярные;
§ многопроцессорные по принципу взаимодействия с памятью: симметричные многопроцессорные (SMP), масcивно-параллельные (MPP), распределенные.
Принципы фон Неймана (Архитектура фон Неймана)
В 1946 году Д. фон Нейман, Г. Голдстайн и А. Беркс в своей совместной статье изложили новые принципы построения и функционирования ЭВМ. В последствие на основе этих принципов производились первые два поколения компьютеров. В более поздних поколениях происходили некоторые изменения, хотя принципы Неймана актуальны и сегодня.
По сути, Нейману удалось обобщить научные разработки и открытия многих других ученых и сформулировать на их основе принципиально новое.
Принципы фон Неймана
1. Использование двоичной системы счисления в вычислительных машинах. Преимущество перед десятичной системой счисления заключается в том, что устройства можно делать достаточно простыми, арифметические и логические операции в двоичной системе счисления также выполняются достаточно просто.
2. Программное управление ЭВМ. Работа ЭВМ контролируется программой, состоящей из набора команд. Команды выполняются последовательно друг за другом. Созданием машины с хранимой в памяти программой было положено начало тому, что мы сегодня называем программированием.
3. Память компьютера используется не только для хранения данных, но и программ. При этом и команды программы и данные кодируются в двоичной системе счисления, т. е. их способ записи одинаков. Поэтому в определенных ситуациях над командами можно выполнять те же действия, что и над данными.
4. Ячейки памяти ЭВМ имеют адреса, которые последовательно пронумерованы. В любой момент можно обратиться к любой ячейке памяти по ее адресу. Этот принцип открыл возможность использовать переменные в программировании.
5. Возможность условного перехода в процессе выполнения программы. Не смотря на то, что команды выполняются последовательно, в программах можно реализовать возможность перехода к любому участку кода.
Самым главным следствием этих принципов можно назвать то, что теперь программа уже не была постоянной частью машины (как например, у калькулятора). Программу стало возможно легко изменить. А вот аппаратура, конечно же, остается неизменной, и очень простой.
Для сравнения, программа компьютера ENIAC (где не было хранимой в памяти программы) определялась специальными перемычками на панели. Чтобы перепрограммировать машину (установить перемычки по-другому) мог потребоваться далеко не один день. И хотя программы для современных компьютеров могут писаться годы, однако они работают на миллионах компьютеров после несколько минутной установки на жесткий диск.
Как работает машина фон Неймана
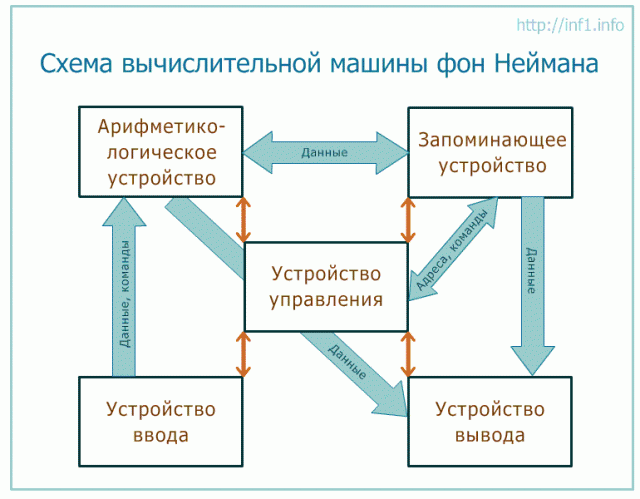
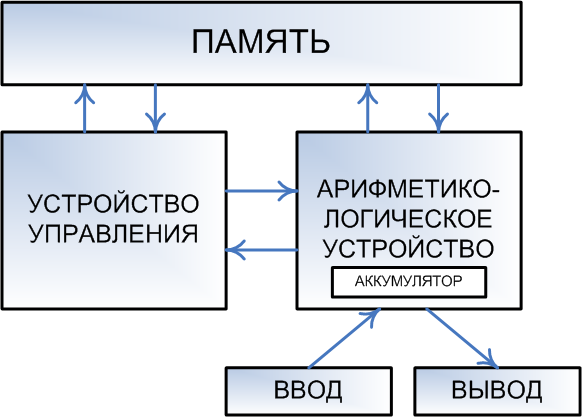
Машина фон Неймана состоит из запоминающего устройства (памяти) - ЗУ, арифметико-логического устройства - АЛУ, устройства управления – УУ, а также устройств ввода и вывода.
Программы и данные вводятся в память из устройства ввода через арифметико-логическое устройство. Все команды программы записываются в соседние ячейки памяти, а данные для обработки могут содержаться в произвольных ячейках. У любой программы последняя команда должна быть командой завершения работы.
Команда состоит из указания, какую операцию следует выполнить (из возможных операций на данном «железе») и адресов ячеек памяти, где хранятся данные, над которыми следует выполнить указанную операцию, а также адреса ячейки, куда следует записать результат (если его требуется сохранить в ЗУ).
Арифметико-логическое устройство выполняет указанные командами операции над указанными данными.
Из арифметико-логического устройства результаты выводятся в память или устройство вывода. Принципиальное различие между ЗУ и устройством вывода заключается в том, что в ЗУ данные хранятся в виде, удобном для обработки компьютером, а на устройства вывода (принтер, монитор и др.) поступают так, как удобно человеку.
УУ управляет всеми частями компьютера. От управляющего устройства на другие устройства поступают сигналы «что делать», а от других устройств УУ получает информацию об их состоянии.
Управляющее устройство содержит специальный регистр (ячейку), который называется «счетчик команд». После загрузки программы и данных в память в счетчик команд записывается адрес первой команды программы. УУ считывает из памяти содержимое ячейки памяти, адрес которой находится в счетчике команд, и помещает его в специальное устройство — «Регистр команд». УУ определяет операцию команды, «отмечает» в памяти данные, адреса которых указаны в команде, и контролирует выполнение команды. Операцию выполняет АЛУ или аппаратные средства компьютера.
В результате выполнения любой команды счетчик команд изменяется на единицу и, следовательно, указывает на следующую команду программы. Когда требуется выполнить команду, не следующую по порядку за текущей, а отстоящую от данной на какое-то количество адресов, то специальная команда перехода содержит адрес ячейки, куда требуется передать управление.
Гарвардская архитектура — архитектура ЭВМ, отличительным признаком которой является раздельное хранение и обработка команд и данных. Архитектура была разработана Говардом Эйкеном в конце 1930-х годов в Гарвардском университете.
Классическая гарвардская архитектура
Типичные операции (сложение и умножение) требуют от любого вычислительного устройства нескольких действий: выборку двух операндов, выбор инструкции и её выполнение, и, наконец, сохранение результата. Идея, реализованная Эйкеном, заключалась в физическом разделении линий передачи команд и данных. В первом компьютере Эйкена «Марк I» для хранения инструкций использовалась перфорированная лента, а для работы с данными — электромеханические регистры. Это позволяло одновременно пересылать и обрабатывать команды и данные, благодаря чему значительно повышалось общее быстродействие.
Гибридные модификации с архитектурой фон Неймана
Существуют гибридные модификации архитектур, сочетающие достоинства как Гарвардской, так и фон Неймановской архитектур. Современные CISC-процессоры обладают раздельной кэш-памятью 1-го уровня для инструкций и данных, что позволяет им за один такт получать одновременно как команду, так и данные для её выполнения, то есть процессорное ядро, формально, является гарвардским, но с программной точки зрения выглядит как фон Неймановское, что упрощает написание программ. Обычно в данных процессорах одна шина используется и для передачи команд, и для передачи данных, что упрощает конструкцию системы. Современные варианты таких процессоров могут иногда содержать встроенные контроллеры сразу нескольких разнотипных шин для работы с различными типами памяти — например, DDR RAM и Flash. Тем не менее, и в этом случае шины, как правило, используются и для передачи команд, и для передачи данных без разделения, что делает данные процессоры еще более близкими к фон Неймановской архитектуре при сохранении плюсов Гарвардской архитектуры.
Лекция № 5 (Внутренняя организация процессора – 6+2 часов)
Структура микропроцессора
Упрощенно структуру микропроцессора можно представить в следующем виде:
| ||
Внутренняя структура микропроцессора. |
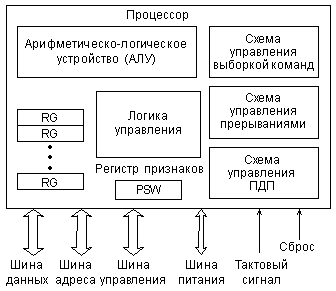
Основные функции показанных узлов следующие:
Схема управления выборкой команд выполняет чтение команд из памяти и их дешифрацию. В первых микропроцессорах было невозможно одновременное выполнение предыдущей команды и выборка следующей команды, так как процессор не мог совмещать эти операции. Но уже в 16-разрядных процессорах появляется так называемый конвейер (очередь) команд, позволяющий выбирать несколько следующих команд, пока выполняется предыдущая. Два процесса идут параллельно, что ускоряет работу процессора. Конвейер представляет собой небольшую внутреннюю память процессора, в которую при малейшей возможности (при освобождении внешней шины) записывается несколько команд, следующих за исполняемой. Читаются эти команды процессором в том же порядке, что и записываются в конвейер (это память типа FIFO, First In — First Out, первый вошел — первый вышел). Правда, если выполняемая команда предполагает переход не на следующую ячейку памяти, а на удаленную (с меньшим или большим адресом), конвейер не помогает, и его приходится сбрасывать. Но такие команды встречаются в программах сравнительно редко.
Развитием идеи конвейера стало использование внутренней кэш-памяти процессора, которая заполняется командами, пока процессор занят выполнением предыдущих команд. Чем больше объем кэш-памяти, тем меньше вероятность того, что ее содержимое придется сбросить при команде перехода. Понятно, что обрабатывать команды, находящиеся во внутренней памяти, процессор может гораздо быстрее, чем те, которые расположены во внешней памяти. В кэш-памяти могут храниться и данные, которые обрабатываются в данный момент, это также ускоряет работу. Для большего ускорения выборки команд в современных процессорах применяют совмещение выборки и дешифрации, одновременную дешифрацию нескольких команд, несколько параллельных конвейеров команд, предсказание команд переходов и некоторые другие методы.
Арифметико-логическое устройство (или АЛУ, ALU) предназначено для обработки информации в соответствии с полученной процессором командой. Примерами обработки могут служить логические операции (типа логического «И», «ИЛИ», «Исключающего ИЛИ» и т. д.) то есть побитные операции над операндами, а также арифметические операции (типа сложения, вычитания, умножения, деления и т. д.). Над какими кодами производится операция, куда помещается ее результат — определяется выполняемой командой. Если команда сводится всего лишь к пересылке данных без их обработки, то АЛУ не участвует в ее выполнении.
Быстродействие АЛУ во многом определяет производительность процессора. Причем важна не только частота тактового сигнала, которым тактируется АЛУ, но и количество тактов, необходимое для выполнения той или иной команды. Для повышения производительности разработчики стремятся довести время выполнения команды до одного такта, а также обеспечить работу АЛУ на возможно более высокой частоте. Один из путей решения этой задачи состоит в уменьшении количества выполняемых АЛУ команд, создание процессоров с уменьшенным набором команд (так называемые RISC-процессоры). Другой путь повышения производительности процессора — использование нескольких параллельно работающих АЛУ.
Что касается операций над числами с плавающей точкой и других специальных сложных операций, то в системах на базе первых процессоров их реализовали последовательностью более простых команд, специальными подпрограммами, однако затем были разработаны специальные вычислители — математические сопроцессоры, которые заменяли основной процессор на время выполнения таких команд. В современных микропроцессорах математические сопроцессоры входят в структуру как составная часть.
Арифметическо-логическое устройство
АЛУ-это устройство предназначенное для арифметической и логической обработки данных. В общем случае выглядит так
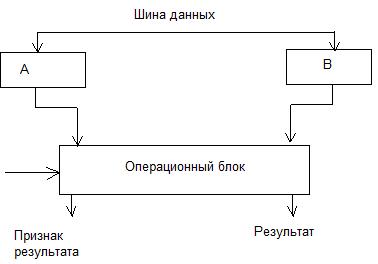
Операционный блок представляет ту часть АЛУ, которая выполняет арифметические и логические операции. Выбор конкретной операции из возможного списка операций выполняется кодом операции команды, хранящейся в данный момент в регистре команд. После преобразования кода операции в микропрограммном автомате последний управляющий сигнал поступает в операционный блок АЛУ. Операционный блок строится как совокупность комбинационных схем т. е. эти операционные блоки не обладают внутренней памятью. А это значит, что до момента сохранения результата операнды (входные данные) должны присутствовать на входе блока.
Рег А хранит первый операнд, В – второй операнд до записи их в оперативную память.
Различают 2 типа операционных блоков: )
1)Параллельный(все разряды обрабатываются одновременно и внутренние переносы реализуются внутренними схемами операционного блока)
2) Последовательный(существуют одноразрядные процессы). )
Обобщенная схема операционного блока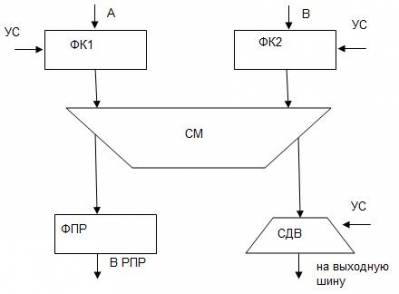
ФК – формирователь кода
СМ – сумматор
ФПР – формирователь признака результата
СДВ – сдвигатель УС – управляющие сигналы
Сумматор выполняет операции арифметического сложения, сложения по модулю, логического сложения, логического умножения
ФПР вырабатывает осведомительные сигналы, передаваемые в УУ: признак знака, признак переполнения, признак нулевого значения.
Сдвигатель служит для выполнения микроопераций сдвига на выходе сумматора, если это необходимо.
|
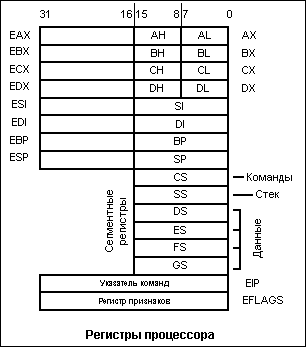
Регистры процессора представляют собой по сути ячейки очень быстрой памяти и служат для временного хранения различных кодов: данных, адресов, служебных кодов. Операции с этими кодами выполняются предельно быстро, поэтому, в общем случае, чем больше внутренних регистров, тем лучше. Кроме того, на быстродействие процессора сильно влияет разрядность регистров. Именно разрядность регистров и АЛУ называется внутренней разрядностью процессора, которая может не совпадать с внешней разрядностью.
По отношению к назначению внутренних регистров существует два основных подхода. Первого придерживается, например, компания Intel, которая каждому регистру отводит строго определенную функцию. С одной стороны, это упрощает организацию процессора и уменьшает время выполнения команды, но с другой — снижает гибкость, а иногда и замедляет работу программы. Например, некоторые арифметические операции и обмен с устройствами ввода/вывода проводятся только через один регистр — аккумулятор, в результате чего при выполнении некоторых процедур может потребоваться несколько дополнительных пересылок между регистрами. Второй подход состоит в том, чтобы все (или почти все) регистры сделать равноправными, как, например, в 16-разрядных процессорах Т-11 фирмы DEC. При этом достигается высокая гибкость, но необходимо усложнение структуры процессора. Существуют и промежуточные решения, в частности, в процессоре MC68000 фирмы Motorola половина регистров использовалась для данных, и они были взаимозаменяемы, а другая половина — для адресов, и они также взаимозаменяемы.
В первую группу входят регистры общего назначения. В процессорах 386 и выше имеются восемь 32-битовых регистров общего назначения EAX, EBX, ECX, EDX, ESI, EDI, EBP, и ESP. Процессоры 386 и выше могут обращаться к 16-битовым половинам 32-битовых регистров. При необходимости возможна работа с половинами регистров, поскольку они разделены на старшую и младшую половину, называемые AH и AL, BH и BL и т. д. Такое разделение регистров имеется во всех процессорах. Значительная часть внутренних операций компьютеров производится с использованием регистров общего назначения.
Следующая группа из шести регистров помогает процессору обращаться к памяти. Они называются сегментными регистрами и каждый из них помогает обращаться к области (или сегменту) памяти. В прежних процессорах размер сегментов составлял 64 Кбайт, а в новых процессорах длина сегмента переменная и варьируется от одного байта до 4 Гбайт.
Регистр CS сегмента кода (программы) показывает, в каком месте памяти находится программа. Регистр DS сегмента данных локализует используемые программой данные. Регистр ES дополнительного сегмента дополняет сегмент данных. Регистр SS сегмента стека определяет стек компьютера. В процессорах 386 и выше имеются еще два сегментных регистра: FS и GS, предназначенных для адресации памяти.
Если сегментные регистры обеспечивают доступ к большим блокам памяти, то последняя группа используется совместно с сегментным регистром для локализации в памяти конкретных байтов. Регистр указателя команды IP определяет ту точку, где выполняется программа. Регистры указателя стека SP иуказателя базы BP помогают следить за информацией в стеке (стек — это область памяти, где хранится информация о текущих действиях компьютера). Регистры индекса источника SI и индекса получателя DI помогают программам пересылать большие блоки данных из одного места в другое.
Регистр признаков (регистр состояния) занимает особое место, хотя он также является внутренним регистром процессора. Содержащаяся в нем информация — это не данные, не адрес, а слово состояния процессора (ССП, PSW — Processor Status Word).
Каждый бит этого слова (флаг) содержит информацию о результате предыдущей команды. Например, есть бит нулевого результата, который устанавливается в том случае, когда результат выполнения предыдущей команды — нуль, и очищается в том случае, когда результат выполнения команды отличен от нуля. Эти биты (флаги) используются командами условных переходов, например, командой перехода в случае нулевого результата. В этом же регистре иногда содержатся флаги управления, определяющие режим выполнения некоторых команд.
Назначение битов регистра флагов |

Схема управления прерываниями обрабатывает поступающий на процессор запрос прерывания, определяет адрес начала программы обработки прерывания (адрес вектора прерывания), обеспечивает переход к этой программе после выполнения текущей команды и сохранения в памяти (в стеке) текущего состояния регистров процессора. По окончании программы обработки прерывания процессор возвращается к прерванной программе с восстановленными из памяти (из стека) значениями внутренних регистров.
Схема управления прямым доступом к памяти служит для временного отключения процессора от внешних шин и приостановки работы процессора на время предоставления прямого доступа запросившему его устройству.
Логика управления организует взаимодействие всех узлов процессора, перенаправляет данные, синхронизирует работу процессора с внешними сигналами, а также реализует процедуры ввода и вывода информации.
Таким образом, в ходе работы процессора схема выборки команд выбирает последовательно команды из памяти, затем эти команды выполняются, причем в случае необходимости обработки данных подключается АЛУ. На входы АЛУ могут подаваться обрабатываемые данные из памяти или из внутренних регистров. Во внутренних регистрах хранятся также коды адресов обрабатываемых данных, расположенных в памяти. Результат обработки в АЛУ изменяет состояние регистра признаков и записывается во внутренний регистр или в память (как источник, так и приемник данных указывается в составе кода команды). При необходимости информация может переписываться из памяти (или из устройства ввода/вывода) во внутренний регистр или из внутреннего регистра в память (или в устройство ввода/вывода).
Внутренние регистры любого микропроцессора обязательно выполняют две служебные функции:
· определяют адрес в памяти, где находится выполняемая в данный момент команда (функция счетчика команд или указателя команд);
· определяют текущий адрес стека (функция указателя стека).
В разных процессорах для каждой из этих функций может отводиться один или два внутренних регистра. Эти два указателя отличаются от других не только своим специфическим, служебным, системным назначением, но и особым способом изменения содержимого. Их содержимое программы могут менять только в случае крайней необходимости, так как любая ошибка при этом грозит нарушением работы компьютера, зависанием и порчей содержимого памяти.
Содержимое указателя (счетчика) команд изменяется следующим образом. В начале работы системы (при включении питания) в него заносится раз и навсегда установленное значение. Это первый адрес программы начального запуска. Затем после выборки из памяти каждой следующей команды значение указателя команд автоматически увеличивается (инкрементируется) на единицу (или на два в зависимости от формата команд и типа процессора). То есть следующая команда будет выбираться из следующего по порядку адреса памяти. При выполнении команд перехода, нарушающих последовательный перебор адресов памяти, в указатель команд принудительно записывается новое значение — новый адрес в памяти, начиная с которого адреса команд опять же будут перебираться последовательно. Такая же смена содержимого указателя команд производится при вызове подпрограммы и возврате из нее или при начале обработки прерывания и после его окончания.
Генератор тактовых импульсов (internal clock) генерирует последовательность электрических импульсов, частота которых определяет тактовую частоту микропроцессора - электронные часы реального времени, обеспечивающие при необходимости автоматический съем текущего момента времени.
Такт работы процессора - промежуток времени между соседними импульсами (tick of the internal clock) генератора тактовых импульсов, частота которых есть тактовая частота процессора. Такт процессора (такт синхронизации) - квант времени, в течение которого осуществляется элементарная операция - выборка, сравнение, пересылка данных. Выполнение короткой команды - арифметика с ФТ, логические операции, обычно занимает пять тактов:
§ выборка команды;
§ расшифровка кода операции (декодирование);
§ генерация адреса и выборка данных из памяти;
§ выполнение операции;
§ запись результата в память.
Процедура, соответствующая такту, реализуется определенной логической цепью (схемой) процессора, обычно именуемой микропрограммой.
Цикл команды
Цикл выполнения короткой команды может выглядеть следующим образом.
1. В соответствии с содержимым СчАК (адрес очередной команды) УУ извлекает из ОП очередную команду и помещает ее в РК. Некоторые команды УУ обрабатывает самостоятельно, без привлечения АЛУ (например, по команде «перейти по адресу 2478» величина 2478 сразу заносится в СчАК, и процессор переходит к выполнению следующей команды).
Типичная команда содержит:
§ код операции (КОП), характеризующий тип выполняемого действия;
§ номера индексного (ИР) и базисного (БР) регистров;
§ адреса операндов A1, А2 и так далее
2. Осуществляется расшифровка (декодирование) команды.
3. Адреса A1, А2 и пр. помещаются в регистры адреса.
4. Если в команде указаны ИР или БР, то их содержимое используется для модификации РА - фактически выбираются числа или команды, смещенные в ту или иную сторону по отношению к адресу, указанному в команде.
5. По значениям РА осуществляется чтение чисел (строк) и помещение их в РЧ.
6. Выполнение операции и помещение результата в PP.
7. Запись результата по одному из адресов (если необходимо).
8. Увеличение содержимого СчАК на единицу (переход к следующей команде).
Очевидно, что за счет увеличения числа регистров возможно распараллеливание, перекрытие операций. Например, при считывании команды СчАК можно автоматически увеличить на 1, подготовив выборку следующей команды. После расшифровки текущей команды РК освобождается и в него может быть прочитана следующая команда. При выполнении операции возможна расшифровка следующей команды и так далее Все это является предпосылкой построения так называемых конвейерных структур (pipeline). Однако все это хорошо только при последовательном (естественном) порядке выполнения команд. Появление переходов (особенно по не определенному заранее условию) нарушает эту картину. Поэтому современные процессоры пытаются предсказывать переходы в программе (branch prediction).
Системы команд и соответствующие классы процессоров
Основные команды ЭВМ классифицируются вкратце следующим образом: по функциям (выполняемым операциям), направлению приема-передачи информации, адресности.
Классы команд
1. Команды обработки данных, в том числе (01 - первый операнд, 02 - второй):
1.1. Короткие операции (один такт).
1.1.1. Логические:
- логическое сложение (для каждого бита 01 и 02 осуществляется операция ИЛИ;
- логическое умножение (для каждого бита О! и 02 осуществляется операция И;
- инверсия (в O1 все единицы заменяются на нули, и наоборот);
- сравнение логическое (если O1 = 02, то некий регистр устанавливается в 1, иначе - в 0).
1.1.2. Арифметические:
- сложение или вычитание операндов;
- сравнение арифметическое (если O1 > O2, или O1 = O2, или O1 < O2, то некий регистр устанавливается в 1, иначе - в 0).
1.2. Длинные операции (несколько тактов):
- сложение/вычитание с фиксированной точкой;
- умножение/деление с фиксированной точкой.
2. Операции управления:
- безусловный переход (ветвление, branch);
- условный переход (по условию, результатам вычислений (conditional branch)).
3. Операции обращения к внешним устройствам (требование на запись или считывание информации).
Естественно, могут существовать и другие операции - десятичная арифметика, обработкасимвольной информации, работа с числами половинной (полуслово, например 16 бит) или двойной(двойное слово, например 64 бит) длины.
Кроме того, команды различаются по типу выборки и пересылок данных: регистр-регистр; память-регистр (регистр-память); память-память.
Далее, известны одно-, двух - и трехадресные машины (системы команд). Очевидна связь таких параметров ЦУ, как длина адресного пространства, адресность, разрядность. Увеличение разрядности позволяет увеличить адресность команды и длину адреса (то есть объем памяти, доступной данной команде). Увеличение адресности, в свою очередь, приводит к повышению быстродействия обработки (за счет снижения числа требуемых команд).
В трехадресной машине, например, сложение двух чисел требует одной команды (извлечь число по А1, число по А2, сложить и записать результат по A3). В двухадресной необходимы две команды (первая - извлечь число по А1 и поместить в РЧ (или сумматор), вторая - извлечь число по А1, сложить с содержимым РЧ и результат записать по А2). Легко видеть, что одноадресная машина потребует три команды. Поэтому неудивительно, что основная тенденция в развитии ЦУ ЭВМ состоит в увеличении разрядности.
Наибольшее применение нашли двухадресные системы команд.
Классы процессоров
В зависимости от набора и порядка выполнения команд процессоры подразделяются на два основных класса, отражающих также последовательность развития ЭВМ. Ранее других появились процессоры CISC. Затем с целью повышения быстродействия процессоров были разработаны процессоры RISC, которые характеризуются сокращенным набором быстровыполняемых команд. Ряд редко встречающихся команд процессора CISC выполняется последовательностями команд процессора RISC.
CISC (complex instruction set computer)
CISC (complex instruction set computer) есть традиционная архитектура, в которой ЦП использует микропрограммы для выполнения исчерпывающего набора команд. В течение долгих лет производители компьютеров разрабатывали и воплощали в изделиях все более сложные и полные системы команд. Однако анализ работы процессоров показал, что примерно 80 % времени выполняется лишь 20 % большого набора команд. Поэтому была поставлена задача оптимизации выполнения небольшого по числу, но часто используемых команд.
RISC (Redused Instruction Set Computer)
RISC (Redused Instruction Set Computer) - процессор, функционирующий с сокращенным набором команд. Так, в процессоре CISC для выполнения одной команды необходимо в большинстве случаев 10 и более тактов. Что же касается процессоров RISC, то они близки к тому, чтобы выполнять по одной команде в каждом такте. Первый процессор RISC был создан корпорацией IBM в 1979 году и имел шифр IBM 801. В настоящее время процессоры RISC получили широкое распространение. Современные процессоры RISC имеют следующие характеристики:
§ упрощенный набор команд, имеющих одинаковую длину;
§ большинство команд выполняются за один такт процессора;
§ отсутствуют макрокоманды, усложняющие структуру процессора и уменьшающие скорость его работы;
§ взаимодействие с оперативной памятью ограничивается операциями пересылки данных;
§ уменьшено число способов адресации памяти (не используется косвенная адресация);
§ создан конвейер команд, позволяющий обрабатывать несколько из них одновременно;
§ используется высокоскоростная память.
Новый подход к архитектуре процессора значительно сократил площадь, требуемую для него на чипе. Это позволило резко увеличить число регистров. В современном процессоре RISC уже используется более 100 регистров. В результате процессор на 20-30 % реже обращается к оперативной памяти, что также повысило скорость обработки данных.
Начиная с процессора Pentium, корпорация Intel начала внедрять элементы RISC-технологий в свои изделия.
Кроме того, известны процессоры MISC (работающие с минимальным набором длинных команд) и VLIW (с системой команд сверхбольшой разрядности).
Процессор VL1W
Процессор VL1W - процессор, работающий с системой команд сверхбольшой разрядности.
Идея технологии VLIW (Very large instruction word) заключается в том, что создается специальный компилятор планирования, который перед выполнением прикладной программы проводит ее анализ и по множеству ветвей последовательности операций определяет группу команд, которые могут выполняться параллельно. Каждая такая группа образует одну сверхдлинную команду. Это позволяет решать две важные задачи: во-первых, в течение одного такта выполнять группу коротких («обычных») команд, во-вторых, упростить структуру процессора. Этим технология VLIW отличается от суперскалярности. В последнем случае отбор групп одновременно выполняемых команд происходит непосредственно в ходе выполнения прикладной программы (а не заранее), что усложняет структуру процессора и замедляет его скорость.
Процессор MISC
Процессор MISC - MISC processor, - работающий с минимальным набором длинных команд.
Увеличение разрядности процессоров привело к идее укладки нескольких команд в одно слово (связку, bound) размером 128 бит. Оперируя с одним словом, процессор получил возможность обрабатывать сразу несколько команд. Это позволило использовать возросшую производительность компьютера и его возможность обрабатывать одновременно несколько потоков данных.
