
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
2.2. Неалгоритмические методы
цифрового моделирования.
Скорость решения ряда сложных задач программно-алгоритмическим методом на ЦВМ общего назначения недостаточна и не удовлетворяет потребностям инжененрных систем автоматизированного проектирования (САПР). Одним из таких классов задач, широко применяемых в инженерной практике при исследовании динамики (переходных процессов) сложных систем автоматизации, являются системы нелинейных дифференциальных уравнений высоких порядков в обыкновенных производных. Для ускорения решения названных задач в состав программно-технических комплексов САПР могут включаться в дополнение к главной (ведущей) ЦВМ общего назначения ГВМ, проблемно-ориентированные на решение нелинейных дифференциальных уравнений. Они организуются на основе цифрового математического моделирования неалгоритмическим методом. Последний позволяет повысить производительность САПР за счет присущего ему параллелизма вычислительного процесса, а дискретный (цифровой) способ представления математических величин – достичь точности обработки не хуже, чем в ЦВМ. В этих ГВМ применяются два метода цифрового моделирования:
1. Конечно-разностное моделирование;
2. Разрядное моделирование.
Первый метод, используемый в ГВМ типа цифровых дифференциальных анализаторов (ЦДА) и цифровых интегрирующих машин (ЦИМ), – это известный метод приближенных (пошаговых) вычислений в конечных разностях. Цифровые операционные блоки ГВМ, построенные на цифровой схемотехнике, обрабатывают достаточно малые дискретные приращения математических величин, передаваемые по линиям связи между операционными блоками. Вводимые и выводимые математические величины представляются, хранятся и накапливаются из приращений в цифровых n-разрядных кодах в риверсивных счетчиках или регистрах накапливающих сумматоров.
Приращения всех величин обычно кодируются одной единицей младшего разряда: D:=1мл. р. Это соответствует квантованию по уровню всех обрабатываемых величин с постоянным шагом квантования D=1. Следовательно, ограничивается скорость нарастания всех машинных величин: |dS/dx|£1.
Знаки одноразрядных приращений кодируются методом знакового кодирования на двухпроводных линиях связи между операционными блоками:
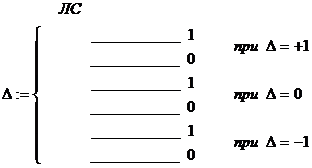
Операционные блоки строятся в основном на одноразрядных цифровых функциональных узлах последовательного действия. n-разрядные величины передаются между функциональными узлами в последовательном коде передачи младшими разрядами вперед.
Основной операционный блок – цифровой интегратор, основан на приближенном вычислении интеграла по методу прямоугольников:
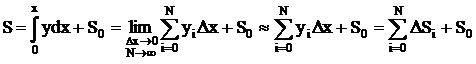 ,
,
где DSi=yiDx – приращение интеграла в i-м шаге интегрирования, а i-я ордината подинтегральной функции y(x) – yi вычисляется путем накопления её приращений:
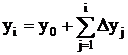
Приращение интеграла DSi в i-м шаге интегрирования образуется как единица переполнения накопленной интегральной суммы :
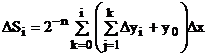
с введением постоянного нормирующего коэффициента кн = 2-n приращения на выходах интеграторов образуются последовательно и обрабатываются в следующих интеграторах также последовательно. Исключением является интегрирование суммы нескольких подинтегральных функций
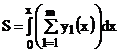
или в приращениях:
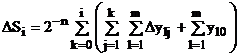
Тогда по нескольким m входным линиям l-е приращения могут поступать синхронно в каком-то j-м шаге. Для последовательного сложения их разносят в пределах шага с помощью линий задержек, увеличивая в m раз тактовую частоту работы входного накапливающего сумматора. Поэтому число суммируемых подинтегральных функций обычно ограничивают до двух.: m=2.
Структурная организация цифрового интегратора-сумматора весьма проста. Он строится в виде последовательного соединения следующих функциональных узлов :
· схема 2ИЛИ с линией задержки tз=0,5t на одном из входов
· входной накапливающий сумматор приращений подинтегральных функций, выполняющий накопление n-разрядных их ординат по входным приращениям :
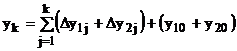
и хранящий накопленные числа yк в регистре сдвига (туда же загружаются начальные значения ординат : y20 + y20), и построенный, например, по схеме одноразрядного накапливающего сумматора :
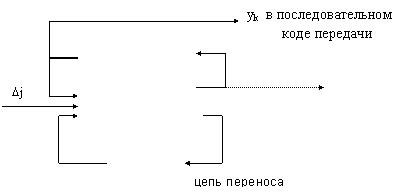
0...n-1 РС |
ОСМ |
T |
· блок умножения на одноразрядное приращение yk*Dx, который с учетом знака Dх выполняет прямое или обратное преобразование кодов отрицательных чисел yk, например из прямого в обратный, или наоборот :
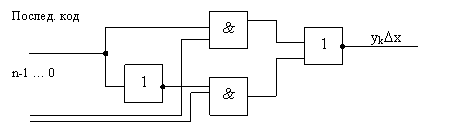
yк
|
При Dх:=(10) код yk передается без изменений, а при Dх:=(01) на выходе образует код, обратный входному коду yk.
·
Выходной накапливающий сумматор, который в каждом к-ом шаге интенрирования прибавляет к своему старому содержимому содержание регистра сдвига РС входного НСМ (в последовательном коде передачи этот шаг выполняется за n тактов):
· формирователь выходного приращения интеграла : DSi := единица переполнения Si, преобразующий признак переполнения в биполярный код приращения (наиболее просто он реализуется, если отрицательные накопленные числа Si представить в модифицированном коде: прямом, обратном или дополнительном). Соответствующая структурная схема цифрового интегратора приведена на рис. 9.14 (с.260) учебника [4]. В схемах цифровых моделей применяется следующее условное обозначение цифрового сумматора-интегратора :
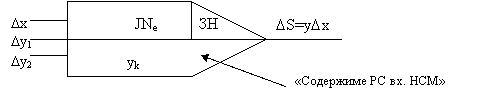
«Зн.» указывает признак инверсии (-), если она требуется. Важным преимуществом данного метода конечно-разностного цифрового моделирования является то, что один и тот же цифровой интегратор без изменения его схем используется для выполнения линейных и нелинейных операций, необходимых для решения обыкновенных дифференциальных уравнений. Это объясняется тем, что при программировании ЦДА и ЦИМ исходные уравнения в производных преобразуются к уравнениям в дифференциалах. Рассмотрим простейшие программы цифровых моделей :
1. умножение переменной х на константу к:
S = кх
Перейдя к дифференциалам dS=кdx, убедимся в том, что эта операция выполняется одним интегратором при соответствующей его начальной установке :
 |
Значения коэффициента к загружается в качестве начального значения y0 в регистр РС входного НСМ цифрового интегратора;
2. возведение в квадрат S=x2, или в дифференциалах dS=2xdx
 |
3. Умножение S=xy, или в дифференциалах dS=xdy+ydx.
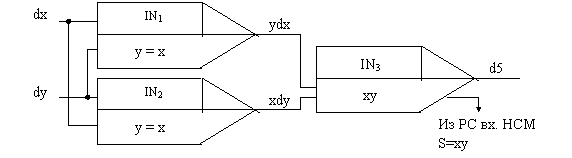 |
4. Генерация аналитических функций как решений, соответствующих им дифференциальных уравнений;
4.1. экспоненциальная функция S=e-х, которая является решением простейшего дифференциального уравнения 1-го порядка. dS/dx = - S при начальных условиях : S(0)=1, или в дифференциалах dS = - Sdx
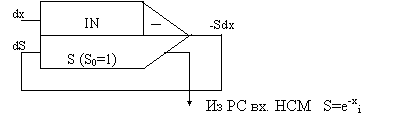 |
4.2. тригонометрические функции, например y=sinx, которая является решением дифференциального уравнения второго порядка ![]() (так как
(так как ![]() ), или в дифференциалах
), или в дифференциалах
 |
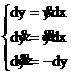
Интересно, что могут быть генерированы функции как от любой входной зависимой переменной х(t), где хi(ti) – её дискретные ординаты, так и от независимой, например по времени : Si = e-ti, yi = sinti. В последнем случае достаточно в качестве приращений Dx » Dt:=1,1,1,…,1,1, т. е. последовательность тактовых синхроимпульсов.
Таким образом, принцип составления и функционирования неалгоритмических цифровых моделей совпадает с принципами аналогового моделирования с тем лишь отличием, что за счет цифровой реализации операционных блоков достигается более высокая точность, но при этом примерно в n раз при n-разрядной сетке снижается скорость решения задач. Правда, это снижение скорости частично компенсируется за счет параллелизма. НПВ. в итоге скорость получения результатов решения дифференциальных уравнений у ЦДА в 10 раз выше, чем у ЦВМ общего назначения.
Дальнейшее повышение производительности ГВМ связано с существенным увеличением аппаратной сложности. Например, разрядное моделирование путем установления поразрядного соответствия между математическими описаниями сложной многослойной структурной схемы модели. Число слов равно разрядности n цифрового представления обрабатываемых математических величин. Каждый слой – это неалгоритмическая аналоговая или цифровая модели уравнений одного разряда решаемой задачи. Слои объединяются между собой цепями межразрядных переносов. В каждом разряде выполняются вычисления по рассмотренным выше неалгоритмическим принципам, а точность решения задач повышается благодаря многоразрядному принципу построения схемы модели. Скорость решения задач – максимально возможная из-за высокой степени распараллеливания вычислительного процесса : в каждом разряде параллельные неалгоритмические вычисления и в n разрядных слоях вычисления выполняются также параллельно. Однако аппаратная сложность таких ГВМ очень велика. Поэтому они не применяются в составе технических средств САПР, а используются в некоторых системах автоматизации, когда предъявляются очень высокие требования к производительности в реальном масштабе времени, например, в авиационных тренажерах и в системах обработки выходных данных аэродинамической трубы. В учебнике [4] с.253-258 рассмотрен один из видов таких ГВМ, так называемых разрядно-аналоговых вычислительных устройств, в разрядных слоях которых применяется аналоговое моделирование (выдвигается на самостоятельную проработку).
Учитывая то, что создание названных проблемно-ориентированных ГВМ требует существенных дополнительных затрат, при построении технических средств САПР чаще используется более простой способ их организации путем объединения в вычислительный комплекс серийно производимых ЦВМ общего назначения и электронных аналоговых вычислительных машин (АВМ), построенных на операционных усилителях. ЦВМ и АВМ объединяются с помощью типового устройства преобразования и сопряжения (УПС), состоящего в основном из АЦП и ЦАП. Сложная решаемая задача рационально распределяется на 2 части между аналоговыми и цифровыми процессорами при программировании комплекса. Причем аналоговая часть чаще всего проблемно ориентируется на решение дифференциальных уравнений и используется в общем вычислительном процессе как быстрая подпрограмма.
2.3 Архитектура гибридных вычислительных комплексов (ГВК).
2.3.1. структура аналого-цифрового вычислительного комплекса (АЦВК)
ГВК или АЦВК – это вычислительный комплекс, состоящий из ЦВМ и АВМ общего назначения, объединенных с помощью УПС, и содержащей в цифровой части дополнительное программное обеспечение для автоматизации программирования аналоговой части, управления обменом информацией между аналоговой и цифровой частями, конотроля и тестирования аналоговой части, автоматизации процедур ввода-вывода.
Рассмотрим структурную схему АЦВК с простейшим УПС, построенном на одноканальных коммутируемых АЦП и ЦАП. Для создания предпосылок автоматизации программирования АВМ под управлением ЦВМ в составе технических средств АВМ вводятся следующие дополнительные блоки:
1. Вручную регулируемые переменные сопротивления (потенциометры) на входах операционных усилителей в наборе операционных блоков (НОБ), известные Вам из лабораторных работ по ТАУ, заменяются на цифроуправляемые сопротивления (ЦУС), в качестве которых используются интегральные схемы ЦАП;
2.
 |
Для долговременного хранения кодов настройки ЦУС применяется блок буферных регистров (БФР), загружаемых при программировании АВМ цифровыми кодами коэффициентов передачи (КП) операционных блоков, вычисляемыми в ЦВМ по методике, изложенной в пункте 2.1; используя масштабные уравнения аналоговой модели;
3. Автоматическое соединение операционных блоков в соответствии с составленной в ЦВМ схемой аналоговой модели (п. 2.1) осуществляется схемой автоматической коммутации (САК) по двоичному вектору коммутации ключей САК, образованному в ЦВМ и хранящемуся в течении решения задачи в регистре настроечной информации (РН) в УПС.
Режимы работы АВМ: подготовка, пуск, останов, возврат в начальное состояние, вывод резудьтатов на аналоговые периферийные устройства (самописцы, двухкоординатные планшетные регистрирующие приборы – ДРП) задаются со стороны ЦВМ через блок управления УПС (БУ УПС).
БУ УПС осуществляет также взаимную синхронизацию работы ЦВМ и АВМ : передает сигналы внешнего прерывания из аналоговой модели в цифровые программы ЦВМ, под управлением программ цифровой части синхронизует опрос точек в аналоговой модели, преобразование напряжений в этих точках в цифровые коды и передачу последних через БСК и канал ввода–вывода в оператиыную память ЦВМ; или аналогично обратное преобразование цифровых кодов в электрические напряжения и подачу последних в требуемые точки на входы операционных блоков аналоговой модели. Такой принцип функциональной организации взаимодействия цифровой и аналоговой частей аппаратно поддерживаемо блоками УПС : АЦП и ЦАП, АМ и АДМ – аналоговыми мультиплексором и демультиплексором, МЛ – входным и выходным блоками аналоговой памяти, построенными на множестве однотипных схем выборки хранения (СВХ). Входы входных СВХ (слева) подключаются к требуемым точкам схемы аналоговой модели (выходам соответствующих операционных блоков). В необходимые дискретные моменты времени под управлением ЦВМ с аналоговой модели снимаются отдельные выборочные ординаты аналоговых сигналов (электрических напряжений) и запоминаются в СВХ. Затем выходы СВХ опрашиваются мультиплексором АМ и их выходные напряжения преобразуются в АЦП в цифровые коды, которые в режиме прямого доступа как блок чисел (линейный массив) записываются в ОП ЦВМ.
При обратном преобразовании выходы СВХ второй группы выходной аналоговой памяти МЛ (справа) подключаются под управлением ЦВМ к требуемым входам операционных блоков аналоговой модели, а входы СВХ – к выходам аналогового демультиплексора, на вход которого подается выходное напряжение ЦАП. В режиме прямого доступа из ОП ЦВМ считывается блок чисел. Каждое из чисел преобразуется в ЦАП в электрическое напряжение, которое под управлением ЦВМ с помощью обегающего АДМ записывается на хранение в одну из СВХ. Полученный набор нескольких напряжений хранится в нескольких СВХ в течение заданного по программе ЦВМ интервала времени (например, во время решения задачи в аналоговой части) и обрабатывается аналоговыми операционными блоками.
2.3.2. Методы организации аналого –
цифровых вычислений.
Принцип чередования режимов работы ЦВМ и АВМ, снижающий сложность УПС.
АЦВК применяются для аналого – цифрового моделирования сложгых систем автоматизации, содержащих управляющие ЦВМ, а также для ускорения решения сложных математических задач, требующих чрезмерного расхода ресурсов памяти и машинного времени ЦВМ. В первом случае на ЦВМ программно имитируются алгоритмы управления, а в АВМ программируется аналоговая математическая модель объекта управления, и АЦВК используется как комплекс для отладки и верификации алгоритмов управления с учетом нелинейности и динамики объекта управления, которые очень трудно учесть при разработке алгоритмов, если при этом постоянно не решать дифференциальные уравнения объекта для определения его реакции на каждое новое управляющее воздействие.
Во втором случае, например, при решении дифференциальных уравнений, общую громоздкую задачу приближенных вычислений разбивают на две части, помещая обычно в аналоговую часть вычислительно емкие расчеты для которых допустима погрешность 0.1…1%.
По принципу названного разделения задачи на две части и способу организации взаимодействия между АВМ и ЦВМ современные АЦВК подразделяются по 4 классам аналого–цифровых вычислений

Классы 1,2,3 могут быть реализованы на основе рассмотренной структурной организации АЦВК с упрощенным УПС, построенном наодноканальных АЦП и ЦАП.
Класс 1 наиболее простой по организации взаимодействия между АВМ и ЦВМ. Цифровая и аналоговая части работают в разное время, и поэтому не предъявляется высоких требований к синхронизации работы АВМ и ЦВМ и быстродействию ЦВМ и УПС.
Класс 2 требует особой организации чередования режимов работы АВМ, ЦВМ и УПС в каждом цикле вычислений и взаимодействия
Цикл | 1 | 2 | 3 | ||
Фаза | А | В | А | В | – // – |
АЧ | Вычисление | Останов. | Вычисл | Останов. | – // – |
УПС | – | Передача данных | – | Передача данных | – // – |
ЦЧ | Прерывание | Вычисление | Прерывание | Вычисление | – // – |
Так как АЧ и ЦЧ одновременно не работают, нет проблем с их синхронизацией и не предъявляется высоких требований к быстродействию УПС и ЦВМ. Классы решаемых задач: оптимизация параметров аналоговой модели, параметрическая идентификация, моделирование случайных процессов методом Монте–Карло, аналого–цифровое моделирование САУ не в реальном масштабе времени, интегральные уравнения.
Класс 3 требует другой организации чередования режимов работы АВМ, ЦВМ и УПС.
Цикл | 1 | 2 | 3 | ||
Фаза | А | В | А | В | – // – |
АЧ | Вычисление | Останов. | Вычисл | Останов. | – // – |
УПС | – | Передача данных | – | Передача данных | – // – |
ЦЧ | Вычисление | Прерывание | Вычисление | Прерывание | – // – |
В фазе А в АЧ и ЦЧ одновременно выполняются 2 частные задачи одной сложной задачи, совместимые по времени. В ЦЧ в фазе В чаще всего принимаются из АЧ и запоминаются дискретные величины аргументов функций, затем в фазе А по ним вычисляются, заготавливаются для АЧ, ординаты сложных функций, которые в следующей фазе В передаются в АЧ, где заносятся на хранение в аналоговые ЗУ (СВХ), а затем используются в следующей фазе А в аналоговых вычислениях, и т. д. Классы решаемых задач: итеративные вычисления, решение обыкновенных дифуров с заданными граничными условиями, динамических задач с чистым запаздыванием аргументов, интегральных уравнений, дифференциальных уравнений в частных производных. В классе 3 не предъявляется высоких ьребований к быстродействию ЦВМ и УПС, но требуется точная синхронизация работы АВМ и ЦВМ в фазе В, так как из–за останова цифрового процессора асинхронное управление передачи данных невозможно, а осуществляется синхронная передача блоков данных под управление контроллера прямого доступа в память (КПДП) через канал ввода–вывода ЦВМ.
Класс 4 – это чаще всего аналого–цифровое моделирование цифровых САУ в реальном масштабе времени для проверки и отладки программ управляющей ЦВМ в динамике. Он наиболее сложен по организации взаимодействия и синхронизации работы АВМ и ЦВМ, тпк как здесь фазы А и В совмещены, происходит постоянный взаимный обмен данными в процессе вычислений, и поэтому требуется применение ЦВМ и УПС максимального быстродействия.
Структурная организация УПС, приведенная выше и пригодная для классов 1,2,3, в классе 4 неприменима. В последнем классе требуется многоканальная организация АЦП и ЦАП без мультиплексирования с дополнительным включением на входе м выходе БСК файла параллельных буферных регистров, обменивающихся с ОП ЦВМ в режиме прямого доступа. Содержимые каждого из регистров либо преобразуются отдельными параллельно включенными ЦАП при передаче данных в АВМ, либо формируются отдельными параллельно включенными АЦП при передаче данных из АВМ в ЦВМ.
2.3.3 Особенности программного обеспечения АЦВК.
Для автоматизации программирования АВМ с помощью ЦВМ и полной автоматизации аналого–цифрового вычислительного процесса традиционное ПО ЦВМ общего назначения (см. рис. 13.2 с.398 в учебнике [3]) дополняется следующими программными модулями:
1. В состав обрабатывающих программ входят дополнительные трансляторы со специальных языков аналого–цифрового моделирования, например Фортран-IV, дополненного подпрограммами на расширенном Ассемблере, содержащем специальные аналого–цифровые команды, например, для управления аналоговой частью по программе ЦВМ, организации передачи данных между ЦЧ и АЧ, обработки прерываний программ ЦЧ, инициализируемых аналоговой частью; создается аналого–цифровая компилирующая система;
2. В состав рабочих, отладочных и обслуживающих программ вводят драйвер межмашинного обмена для управления аналоговой частью как периферийным процессором, программы графического дисплея, регистрации и анализа результатов;
3. В состав библиотеки прикладных программ вводят программы вычисления функций и стандартные математические аналого–цифровые программы;
4. В состав диагностических программ технического обслуживания вводят тесты УПС, тесты операционных блоков АВМ;
5. В состав управляющих программ ОС вводят целый комплекс дополнительных управляющих модулей:
· Система автоматизации аналогового программирования (СААП), состоящая из лексического анализатора; синтаксического анализатора (проверка соответствия введенной на алгоритмическом языке аналоговой программы правилам синтаксиса записи); генераторы структурных схем (составление и кодирование схем аналоговых моделей методом понижения порядка и неявных функций также, как и в п.2.1); блока расчетных программ (масштабирование аналоговой модели как в п.2.1, цифровое программное моделирование аналоговой части на ЦВМ с однократным просчетом для расчета ожидаемых максимальных значений переменных и уточнения масштабирования аналоговой модели, а также создание файла статического и динамического контроля аналоговой части после её программирования); программы представления выходной информации (вывод на дисплей и графопостроитель синтезированной структуры аналоговой модели, контрольная распечатка кодов аналоговой программы, масштабных коэффициентов, файла статического и динамического контроля);
· Служба синхронизации и взаимодействия АВМ и ЦВМ (реализация чередования режимов работы);
· Служба обработки прерываний, инициализируемых аналоговой частью;
· Программа управления обменом данными между АВМ и ЦВМ;
· Программа управления загрузкой кодов схемы аналоговой модели в САК (в РН);
· Программа управления режимом статического и динамического контроля (отладка загруженной в АВМ аналоговой программы).
По результатм автоматизации аналого–цифрового программирования на магнитном диске ведущей ЦВМ, кроме традиционных цифровых файлов, создаются следующие дополнительные файлы данных, используемые названными выше дополнительными модулями ПО АЦВК: файл аналоговых блоков, файл коммутации (для САК), файл статического контроля, файл динамического контроля, файл подготовки аналоговых функциональных преобразователей, библиотека подключаемых стандартных аналого–цифровых программ.
2.3.4. Языки аналого–цифрового моделирования.
Рассмотренная архитектура АЦВК позволяет описывать и вводить аналого–цифровые программы только в ведущую ЦВМ на алгоритмических языках высокого уровня. Для этого традиционные языки цифрового программирования дополняются специальными операторами описания объекта аналогового моделирования, организации передачи данных между АЧ и ЦЧ, управления аналоговой частью по программе ЦВМ, обработки прерываний со стороны аналоговой части, задание параметров аналоговой модели, контроля аналоговой части, задания служебной информации и т. п.
Применяются универсальные языки, транслируемые путем компиляции (Фортран IV) или интерпретации (Бейсик, Гибас, Фокал, HOI), дополняемые специальными подпрограммами на Ассемблере, обычно выызваемыми оператором Call… с указанием идентификатора нужной подпрограммы.
С целью повышения скорости работы СААП она обычно описывается и использует на входе специализированные языки аналого–цифрового моделирования: CSSL, HLS, SL – 1, APSE, а для внутренней интерпретации язык Полиз (обратная польская запись).
В универсальные языки компилируемого типа могут вводиться следующие аналого–цифровые макрокоманды:
1. SPOT AA x – установить потенциометр (ЦУС) в аналоговой части с адресом АА в положение (величину сопротивления), соответствующее значению цифрового кода, хранящемуся в ОП ЦВМ по адресу х;
2. MLWJ AA x – считать аналоговую величину на выходе операционного блока в АЧ с адресом АА, подвергнуть её аналого–цифровому преобразованию, а результирующий цифровой код записать в ОП ЦВМ по адресу х. Взаимодействие аналоговой частии цифровой части можно описать как вызов процедуры:
Call JSDA AA x, где JSDA – это идентификатор соответствующий, подключаемой подпрограммы на Ассемблере, например, процедуры установки – установить значение х с выхода ЦАП по адресу АА в аналоговой части.
В диалоговом режиме, например, при отладке аналоговой модели, обычно применяются языки интерпретирующего типа, чаще всего расширенный Бейсик. Идентификаторы переменных и массивов дополняются идентификаторами аналоговых операционных блоков и аналоговых операций. Они составляются из мнемонического обозначения операционного блока или операции и их индексов в квадратных скобках. Чтобы отличать их от традиционных идентификаторов Бейсика, запись их начинается с восклицательоного знака:
!JN[2] – интегратор 1,
!SU[5] – сумматор 5,
!FN[1] – функциональный блок (формирователь функции) 1,
!DP[0] – потенциометр (ЦУС) 0,
!CD[3] – коэффициент передачи потенциометра 3 (умножение на постоянный регулируемый коэффициент),
!DE[1] – значение производной 1 (первобразной на входе JN[1]).
Рассмотрим фрагмент программы на расширенном Бейсике, предназначенный для его ввода в ЦВМ, последующей интерпретации в ЦВМ, составления в ЦВМ программы аналоговой части, ввода её в АЧ и финального контроля цифровой частью правильностью ввода аналоговой программы в АВМ путем соответствующего опроса контрольных точек схемы аналоговой модели. Рассмотрим названные программные коды процедур на примере простого нелинейного дифференциального уравнения:
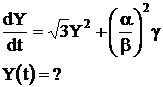
g – внешняя переменная;
Исходные данные:
1. Начальные условия : Y(0)=0.382;
2. Значения констант: a=4.5 b=5;
3. Значение входной переменной: g:=0.5.

NORMAL
ONL
COSUB 100
MODE, PG
COSUB 200
MODE, IC
VERIFY, .05
COSUB 200
Подпрограммы :
100 Установка параметров
101 LET ALFA = 4.5
102 LET BETA = 5
103 LET GAMA = .5
104 Начальные условия
105 Y=.382
106 RETURN
200 Установка коэффициентов и присваивания
201 LET !CD[0]=(ALFA/BETA)2
202 LET !CD[1]=SQR(3)/10
203 LET !CD[2]=.382
204 LET !IN[1]=CD[2] (начальное условие)
205 LET !FN[1]=IN[1]*IN[1]
206 LET !DE[1]= – (CD[0]*GAMA) – (CD[1]*FN[1]*10)
207 RETURN
300 Выходы потенциометров
301 LET !DP[0]=CD[0]*GAMA
302 LET !DP[1]=CD[1]*FN[1]
303 LET !DP[2]=CD[2]*1
В программе имеется особый оператор VERIFY,0.05 , который задает режим проверки аналоговой части. Проверка выполняется в подпрограммах, следующих за ним. В последних при этом изменяется смысл оператора присваивания : LET A=B. Он интерпретируется как сравнение А с В с точностью 0.05. если 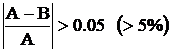 , то интерпретирующий транслятор печатает сообщение об ошибке.
, то интерпретирующий транслятор печатает сообщение об ошибке.
NORMAL – оператор, анулирующий действие оператора VERIFY; следовательно вначале до оператора VERIFY оператор LET в подпрограммах 100 и 200 имеет смысл присваивания.
ONL – оператор, задающий режим работы ЦВМ во взаимодействии с АВМ.
MODE <параметр> – оператор задания рабочего режима аналоговой части.
параметр : PG – составление аналоговой программы (кодирование схемы аналоговой модели и её параметров).
IC – ввод начальных условий в интеграторы;
ОР – пуск аналоговой модели и получение однократного решения.
Таким образом, в соответствии с приведенным фрагментом аналого–цифровой программы вначале по основной подпрограмме COSUB 200 ЦВМ вводит в аналоговую часть структуру связей аналоговой модели и коэффициенты передачи аналоговых операционных блоков и по MODE, IC вводит в интегратор IN1 значение начального условия, определяемого присваиваниями 203, 204 (как предварительный заряд его конденсатора в обратной связи операционного усилителя). Затем по оператору VERIFY осуществляется статический контроль правильности ввода аналоговой програмы в АВМ, вызывая соответствующие точки аналоговой схемы в АВМ мультиплексором АМ, подвергая напряжения в этих точках аналого–цифровому преобразованию с помощью УПС, а затем сравнивая эти цифровые коды в ЦВМ с результатами цифрового вычисления правых частей всех LET : 201 – 206 и 301 – 303.
В специализированных входных языках системы СААП ведущей ЦВМ для аналого–цифрового моделирования решаемае в АВМ дифференциальные уравнения вводятся в ЦВМ ещё проще в форме описания, очень близкой к естественной математической записи. Например, в языке APSE применяются следующие операторы языка описания объекта моделирования :
Исходное уравнение :
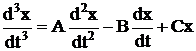
вводится в ЦВМ в виде :
DER3(x) = A*DER2(x) – B*DER1(x) + C*x.
Названные языки и принципы программирования АЦВК даны в книге: , «Программное обеспечение аналого–цифровых ВС.» – М.: Машиностроение, 1985. –184с.
2.3.5 Примеры составления схем аналого–
цифровых моделей.
Процесс разбиения общей сложной задачи на её цифровую и аналоговую части при программировании на АЦВК, выбор класса аналого–цифровых вычислений и способа организации чередования режимов ЦВМ, УПС и АВМ в инженерной практике упрощают и делают наглядным путем составления дополнительной структурной схемы программы, называемой схемой аналого–цифровой модели. В ней детализируется до уровня операционных блоков аналоговая часть и до уровня используемых АЦП, ЦАП, АМ и АДМ, аналоговой памяти (СВХ) – устройство преобразования и сопряжения, а ЦВМ не детализируется, так как цифровая часть достаточно хорошо описывается программой на входном алгоритмическом языке. На основании этой схемы и вычислительного алгоритма решения задачи подбирается подходящий класс аналого–цифровых вычислений, выполняются аналитические оценки степени повышения скорости решения на АЦВК по сравнению с ЦВМ.
Рассмотрим принципы составления схем аналого–цифровых моделей на примерах программирования следующих двух характерных сложных задач.
2.3.5.1. Повышение скорости параметрической оптимизации систем автоматического управления.
При синтезе САУ, например, следящих систем, требуется так подобрать их параметры {ai}, чтобы среднеквадратичное значение ошибки e = y(t) - x(t), где x(t) – входная переменная САУ, y(t) – выходная переменная САУ, достигало минимально возможного значения по критерию (целевой функции):
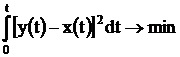
Поэтому в состав САПР САУ целесообразно включить итеративную аналого–цифровую модель параметрической оптимизации. Если САУ описывается дифференциальным уравнением:
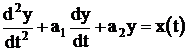
при начальных условиях ![]() то требуется определить оптимальные значения постоянных коэффициентов a1 и a2 при заданном входном сигнале x(t) путем минимизации целевой функции:
то требуется определить оптимальные значения постоянных коэффициентов a1 и a2 при заданном входном сигнале x(t) путем минимизации целевой функции:
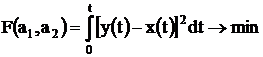
a1, a2 = ?
Эта сложная задача достаточно быстро решается на АЦВК итеративным методом. В каждом цикле итераций дифференциальное уравнение при a1=const и a2=const решается на АВМ, и на АВМ вычисляется одно значение целевой функции F(a1, a2) и передается в ЦВМ.
ЦВМ организует итерационный процесс, в ходе итераций по последовательности значений F(a1, a2) на основе алгоритма оптимизации, например методом скорейшего спуска, варьирует величины коэффициентов а1 и а2 и в начале каждого цикла итераций передает новые их значения в АВМ, по которым последняя образует новое значение F(a1, a2) и передает его в ЦВМ, и так далее циклы итерации продолжаются до тех пор, пока ЦВМ не отыщет координаты а1opt, a2opt экстремума неявно заданной функции F(a1, a2).
При программировании задачи на АЦВК полезно составить схему аналого–цифровой модели.
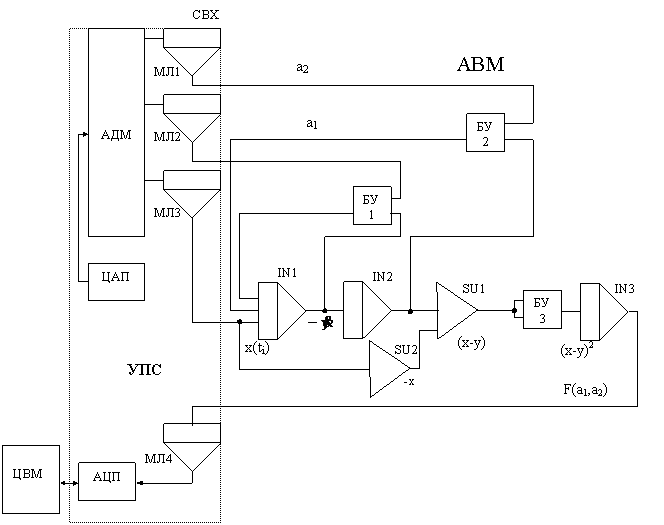 МЛ – аналоговая память (СВХ);
МЛ – аналоговая память (СВХ);
БУ – блок умножения.
Для организации итеративных аналого–цифровых вычислений необходимо составить таблицу чередования режимов работы АВМ, УПС и ЦВМ.
Цикл | к | к+1 | ||
Фаза | А (m тактов) | В (3 такта) | А | В |
АВМ | Однократное решение y(t) при a1=const, a2=const вычисл. значен. F(a1,a2) | Исходное положение, хранение F(a1,a2) приём новых а1, а2 | – /// – | – /// – |
УПС | Передача в АВМ x(t)={x(ti)}1m поординатно | Передача в АВМ а1 и а2, в ЦВМ F(a1,a2) | – /// – | – /// – |
ЦВМ | Шаг итеративной оптимизации по F(a1,a2)®min, вычисл. новых а1 и а2 псевдопаралл. с программой управления передачей мультипрогр. | прерывание | – /// – | – /// – |
В фазе А АДМ фиксируется в третьем положении и через него из ОП ЦВМ с постоянным шагом во времени передаются в АВМ величины ординат x(ti), i=1..m известной функции правой части x(t). В фазе В в аналоговые памяти заносятся величины новых коэффициентов а1 и а2, вычисленные в предыдущей фазе А в ЦВМ. Очевидно, что данная задача относится к 3-му классу аналого–цифровых вычислений.
После составления приведенных выше схемы и таблицы принимается решение о разделении задачи на 2 части : аналоговую и цифровую и о составе прикладных программ ЦВМ, которые в данном случае должны состоять из :
· Программы пошаговой итеративной оптимизации по критерию F(a1,a2)®min : а1, а2 = ?;
· Программы управления режимами работы УПС и АВМ в соответствии с таблицей их чередования.
Значительное повышение скорости решения данной задачи на АЦВК по сравнению с решением только на ЦВМ очевидно, так как в АЦВК цифровая часть полностью освобождается от вычислительно сложного решения дифференциального уравнения и от интегрирования в целевой функции.
2.3.5.2 Повышение скорости решения
интегральных уравнений.
Интегральные уравнения часто используются в САПР для математического описания моделей сложных динамических систем, а также для упрощения решения задач в частных производных, большинство из которых могут быть преобразованы к интегральным уравнениям.
Рассмотрим методику ускоренного их решения на АЦВК на примере уравнения Фредгольма :
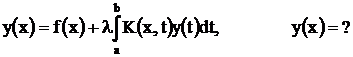
где l, а, b – известные коэффициенты;
K(x, t) – известная функция одной переменной, называемая функцией первого приближения.
На АЦВК этоуравнение решается приближенно итерационным параллельно–последовательным методом:
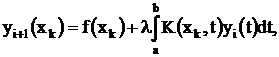 (1)
(1)
где к=0…m; i=0…n; m=const; n=var; n – число итераций; m – число шагов квантования интервала [a, b].
Дискретные значения xk вычисляются по формуле:
![]() (2)
(2)
Условие сходимости итерационного вычислительного процесса:
![]() (3)
(3)
где i – номер итерации;
e – мера точности решения задачи.
Каждая i–я итерация выполняется за m шагов. Общее число шагов n во всех n итерациях до выполнения неравенства (3) равно Nш = mn. В каждом к-ом шаге итерации по формуле (1) вычисляется одна к-я ордината функции следующего приближения уi+1(xk) по одной ординате f(xk) функции первого приближения и следующим двум функциям одной переменной:
1) yi(t) – функция предыдущего i-го приближения как совокупность m ординат {yi(xk)}, найденных за m шагов в предыдущей i-й итерации;
2) K(xk, t) – к-я функция семейства m функций одной переменной, приближенно аппроксимирующего функции двух переменных ядра K(x, t).
Требуется выполнить достаточно большое число шагов вычислений по (1). Например, при допустимой погрешности решения dn=e/ymax»1% требуются m=100 и n»20, т. е. Nш=2000 шагов вычислений по выражению (1).
При решении задачи на АЦВК разумно принять следующее разделение задачи на аналоговую и цифровую части:
1) Выражение (1) обрабатывается в АВМ: умножение K(xk, t)yi(t), интегрирование и сложение в каждом к-м шаге;
2) Вычисления по (2) и (3), программа алгоритма итераций реализуются в ЦВМ.
Так как в АВМ всегда имеется избыток однотипных операционных блоков, это можно использовать для дополнительного повышения скорости решения задачи на АЦВК на основе организации параллельно–последовательной обработки в АВМ. В одном цикле работы АЦВК в АВМ можно организовать вычисление не одного шага вида (1), а параллельно и одновременно нескольких S шагов вида (1): S<m. В АВМ создается S параллельных однотипных моделей выражения (1) для нескольких к-х шагов: к=jS…(j+1)S, j=0…l-1, где l=m/S – число параллельно–последовательных шагов работы АВМ. Максимальное число S параллельных ветвей определяется количеством наличных блоков умножения, которое в АВМ обычно меньше, чем количество интеграторов и сумматоров. Таким образом число шагов итеративного процесса вычислений в АЦВК уменьшится в S раз:
![]()
Оценим возможный выигрыш в скорости решения на АЦВК по сравнению с решением задачи только на ЦВМ.
В ЦВМ для вычислений по выражению (1) необходимо выполнить m умножений под интегралом двух квантованных с шагом Dt ординат функций одной переменной, m сложений для вычисления интеграла методом прямоугольников, умножение на l и сложение с f(xk), т. е. в каждом к-м из Nш=mn шагов – (m+1)(Ny+Nl) тактов, где Ny, Nl – число тактов работы АЛУ для умножения и сложения соответственно.
В каждой i-й итерации требуется m сложений по формуле (2) и m сложений, m операций нахождения модуля и m сравнений по формуле (3). На весь итеративный процесс в ЦВМ требуется следующее число тактов: NЦВМ»mn(m+1)(Ny+Nl)+4mnNc»mn[(m+1)(Ny+Nl)+4Nl]»2000[101*12+8]» 2.44*106 тактов, где Ny=10, Nl=2.
В АЦВК один параллельно–последовательный шаг из Nl=20mn/S шагов выполняются в УПС и АВМ примерно за (m(S+1)+2S) эквивалентных ЦВМ тактов с учетом АДМ и АМ, а в каждой i-й итерации, как и выше, за 4Nlm выполняются вычисления в ЦВМ по формулам (2), (3). Причем основные потери времени m(S+1) тактов обусловлены последовательным чтением ОЗУ ЦВМ в режиме прямого доступа. Поэтому число эквивалентных тактов итераций в АЦВК:

Тогда выигрыш по скорости решения интегрального уравнения
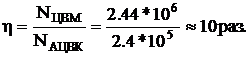
Если бы в ЦВМ были параллельная (S+1)-модульная ОП, то выигрыш достиг бы »100 раз.
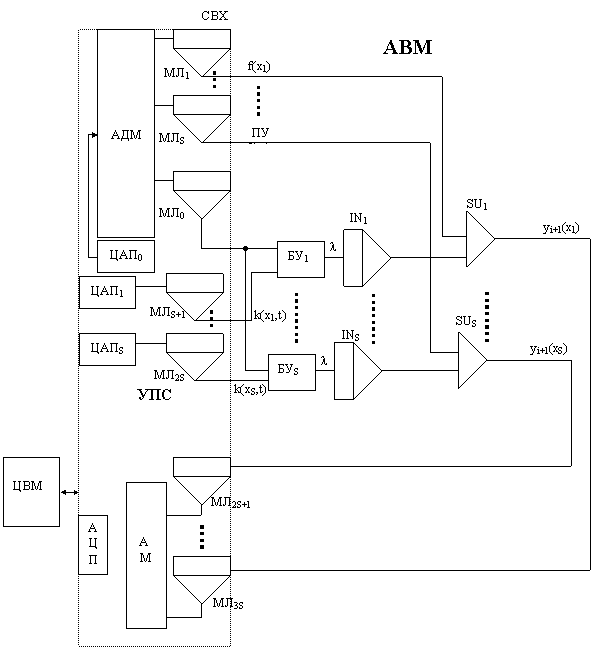 Схема аналого-цифровой модели интегрального уравнения:
Схема аналого-цифровой модели интегрального уравнения:
Для организации параллельной обработки в АВМ одновременно S выражений (1) для нескольких разных к-х шагов : к=jS…(j+1)S, j=0…l-1 требуется параллельный ввод в АВМ (S+1)-й функций одной переменной yi(t), k(x1,t),…,k(xS, t).
Поэтому в УПС для повышения производительности АЦВК вводится избыток интегральных схем ЦАП и СВХ (МЛ), например в данном случае – это ЦАП1…ЦАПS и МЛS+1…МЛ2S, или 2S БИС: ЦАП и СВХ.
Ординаты всех (m+3) квантованных функций одной переменной: семейство ядра:{K(xk, t)}1m, функция первого приближения f(x), искомые функции в двух соседних итерациях yi(x) и yi+1(x), хранятся в ОЗУ ЦВМ. Функция следующего приближения yi+1(x) вычисляется поординатно на основании функции предыдущего приближения yi(x) за l=m/S циклов работы АЦВК. Широкое применение в УПС схем аналоговой памяти МЛ(СВХ) существенно упрощает организацию чередования режимов работы АВМ, УПС и ЦВМ, которая в данном случае близка к таблице 2-го класса аналого-цифровых вычислений:
Цикл | j (j=0…l-1) | J+1 | ||
Фаза | А (m(S+1) тактов) | В (2S тактов) | А | В |
АВМ | Вычисление, в конце запись ординат yi+1(x1)…yi+1(xS) в МЛ2S+1…МЛ3S | Исходное положение | – /// – | – /// – |
УПС | АДМ в положении 0, передача в АВМ через ЦАП0, ЦАП1…ЦАПS поординатно (S+1)-й функции каждую за m тактов | Взаимная передача за 2S тактов в АВМ ординаты f(x1)…f(xS) и в ЦВМ yi+1(x1)…yi+1(xS) | – /// – | – /// – |
ЦВМ | Прерывание, работает КПДП и выгружает в канал вв/выв ординаты функций yi(tk), {K(x, tk)} | Вычисление по ф.(2,3), подготовка буферов вывода : yi+1(t), k(x(j+1)S, t)… k(x(j+1)S, t) | – /// – | – /// – |
Требования к взаимной синхронизации АВМ и ЦВМ невысокие :
1) В фазе В она вообще не нужна;
2) В фазе А работа КПДП и канала вв/выв ЦВМ синхронизуется с УУ АВМ так, чтобы совместить «пуск» АВМ с началом передачи в АВМ m(S+1)-й ординат функций yi(t) и {k(xk, t)}k=1k=S, а окончание их передачи – со стробом записи результирующих ординат yi+1(x1)…yi+1(xS) из АВМ в МЛ2S+1…МЛ3S в УПС и последующим возвратом АВМ в режим «исходное положение» для подготовки к фазе В.
Масштаб времени в АВМ и длительность фазы А определяется скоростью работы КПДП и канала вв/выв ЦВМ.
АЦВК рассмотренных принципов организации применяются при проектировании и отладке цифровых САУ сложных объектов: тепловозов, электровозов, самолетов, космических ракет, реакторов: тепловых, химических и ядерных; роботов и т. п.
Недостатки АЦВК очевидны:
Ø Возрастание погрешности решения из-за АВМ;
Ø Необходимость разворачивания производства АВМ и УПС с более сложной и дорогой технологией производства и метрологией, чем ЦВМ;
Ø Существенное усложнение системного ПО по сравнению с базовым ПО ЦВМ;
Ø Ограниченный класс математических задач, ускорение решения которых возможно в АЦВК при значительных дополнительных затратах.
Поэтому интенсивно ищутся способы организации ВМ, которые позволили бы добиться такого же или более существенного повышения скорости решения сложных задач путем чисто цифрового моделирования и на типовой универсальной цифровой элементной базе и схемотехнике. Основная тенденция развития этой новой организации ЦВМ – массовый параллелизм процессоров в аппаратно избыточных системах с потоковым или алгоритмическим программированием элементарных машин и программированием перестратваемой структуры сложной вычислительной сети элементарных вычислительных машин. Типичный представитель такой организации средств ИВТ – это транспьютерная сеть, где транспьютер – элементарная однокристальная машина, снабженная локальной ОП и не менее, чем четырьмя последовательными портами вв/выв (линками) для передачи команд и данных соседним транспьютерам. На их базе уже создаются командно-алгоритмически (или потоково) и структурно программируемые микропроцессорные платформы (суперкристаллы, большие пластины, ультрабольшие ИС), интегрирующие до 10…100 млн. транзисторов, на которых размещается 256…1000 транспьютеров.
В США уже 10…20 лет в научных и проектных центрах эксплуатируются несуперинтегральные гиперкубовые суперЭВМ типа СМ – 1,2,3 (Connection Machine – соединительная машина), содержащие 65536 элементарных последовательных машин (одноразрядных процессоров), размещенных в 212 кластерных СБИС, каждая из которых содержит 16 элементарных машин и по гиперкубовому принципу соединяется 12-ю линками с 12-ю непосредственными соседями. Опыт их эксплуатации показал, что такие суперЭВМ, организованные по принципу массового параллелизма, могут превзойти по возможностям рассмотренные АЦВК. Например, на СМ – 1 удалось построить цифровую модель всех переходных процессов проектируемой БИС, содержащей до 8000 транзисторов.
Поэтому остальную часть данной дисциплины мы посвятим изучению основ архитектуры параллельных ЦВМ, а завершим её рассмотрение в следующей дисциплине «Специализированные процессоры, машины и сети».
3. Основы архитектуры параллельных
ЭВМ и систем.
3.1 Типы параллелизма в задачах обработки
информации и принципы их использования
для повышения производительности ВС.
Параллельная обработка информации, наряду с повышением быстродействия элементной базы, является эффективным методом увеличения производительности ЦВМ. Правительства всех развитых стран мира рассматривают высокопроизводительные параллельные вычисления в ЦВМ как стратегически важнейшую задачу, решение которой обеспечивает не только техническое лидерство в области ВТ, но и конкурентноспособность экономики страны на мировом рынке XXI века. В программы создания параллельных ВС вкладываются миллиарды долларов с тем, чтобы к 2000 году достичь производительности 104 Гфлопс (млрд. операций с плавающей запятой в секунду).
Применяются следующие способы организации параллельной обработки информации:
1) Совмещение во времени различных этапов обработки разных задач (псевдопараллелизм на основе мультипрограммирования и разделения времени процессора);
2) Одновременное решение разных задач или параллельных частей одной и той же сложной задачи на нескольких процессорах или ЭВМ;
3) Конвеерная обработка как наиболее важный вид обработки по второму способу.
Вся история развития современных однопроцессорных ЭВМ и микропроцессорных систем – это постепенное введение и усовершенствование методов параллельной обработки:
1) Параллельные многоразрядные сумматоры и АЛУ;
2) Многомодульные параллельные многопортовые ОЗУ;
3) Конвеерные АЛУ и конвеевные блоки управления процессоров с блоками опережающей выборки команд;
4) Кэш-память;
5) Сверхпараллельная аппаратно избыточная арифметика (матричные однотактные сдвигатели, блоки умножения и деления);
6) Псевдопараллелизм на уровне устройств ЭВМ на основе мультипрограммной обработки и обработкив режиме разделения времени центрального процессора.
Дальнейшая тенденция введения параллелизма – это организация параллельной одновременной работы нескольких процессоров и прочих устройств ЭВМ: модулей ОЗУ, процессоров (каналов) ввода-вывода, периферийных устройств. С целью экономии расхода технических средств в настоящее время структурную и функциональную организацию параллельной ВС приспосабливают под определенный наиболее распространенный вид параллелизма, встречающийся в задачах обработки информации, с тем, чтобы получить максимальный выигрыш в повышении скорости решения определенного класса задач при минимальных затратах. Строятся параллельные ВС, проблемно-ориентированные на какой-либо достаточно широкий класс задач, но являющиеся машинами широкого назначения в своем классе задач.
В будущем при переходе на новую многопроцессорную ультрабольшую интегральную элементную базу (например, большие пластины транспьютерных сетей), т. е. после перехода к «мелкозернистым» ВС станет экономически выгодным крупносерийное производство универсальных параллельных ВС. Однако в любом случае тип параллелизма решаемой задачи оказывает существенное влияние на способ организации паралелльной ВС и на основные элементы её архитектуры: техническое, программное и информационное обеспечение.
Поэтому очень важно понять как тип параллелизма решаемой задачи влияет на способ оргпнизации параллельной ЭВМ.
3.1.1 Естественный параллелизм
независимых задач.
Он наблюдается, если в ВС поток не связанных между собой задач. В этом случае повышение производительности сравнительно легко достигается путем введения в «крупнозернистую» ВС ансамбля независимо функционирующих процессоров, подключенных к интерфейсам многомодульной ОП и инициализации процессоров ввода/вывода (ПВВ).
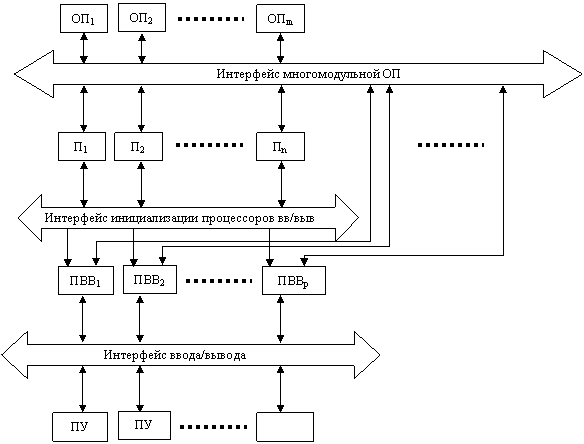
Число модулей ОП m>n+p c тем, чтобы обеспечить возможность параллельного обращения в памятьвсех обрабатывающих процессоров и всех ПВВ и повысить отказоустойчивость ВС. Резервные (m-n-p) модули ОП необходимы для быстрого восстановления при отказе рабочего модуля и для хранения в них ССП процессоров и процессов в контрольных точках программ, необходимых для рестарта при отказе процессора или модуля ОП.
Создается возможность под каждую из решаемых задач временно объединять пару: Пi+ОПj как автономно функционирующую ЭВМ. Предварительно этот же модуль ОП работал в паре: ПВВк+ОПj, и в ОПj в буфер ввода была занесена программа и данные. По окончании обработки в ОПj организуется и заполняется буфер вывода, а затем модуль ОПj вводится в пару ОПj+ПВВr для обмена с периферийным устройством.
Основная задача организации вычислительных процессов, решаемая системной программой «диспетчер», – оптимальное распределение задач между параллельными процессорами по критерию максимальной их загрузки, или минимизации времени их простоев. В этом смысле оптимальным является асинхронный принцип загрузкм задач в процессоры, не ожидая, пока закончится обработка задач в других занятых процессорах.
Если пакет входных задач, накопленный за определенный интервал времени, хранится в ВЗУ, проблема оптимальной асинхронной диспетчирезации сводится к составлению оптимального расписания моментов запуска задач на разных процессорах. Основные исходные данные, требуемые для этого, – множество известных ожидаемых времен счета, процессорной обработки всех задач накопленного пакета, которые обычно указываются в управляющих картах их заданий.
Несмотря на независимый характер задач в совокупности их асинхронных вычислительных процессов возможны конфликты между ними за общие ресурсы ВС:
1) Услуги общей мультисистемной ОС, например обработка прерываний по вводу-выводу, или обращений к общей ОС надежности при отказах и рестартах;
2) Обращения в общую базу данных (базу знаний), хранящуюся на одном ВЗУ большой ёмкости.
Конфликты разрешаются с помощью механизмов МОС:
1) Приоритетных очередей;
2) Синхропримитивов синхронизации асинхронных процессов, например семафоров (см.[3])
Программы МОС обычно выполняются одной ведущей парой: П1+ОП1, которая называется ведущим процессором. Такой принцип организации МОС называется «ведущий-ведомый».
С целью повышения производительности в критические интервалы конфликтов многих ведомых процессов за услуги МОС обработка одинаковых и разных запросов к МОС может распараллеливаться также, как и по прикладным программам. Для этого МОС из копий своих управляющих модулей создаёт комплект независимых задач максимального уровня приоритетов, которые на время обработки обращений к МОС временно вытесняют из обрабатывающих процессов П1…Пn наименее приоритетные прикладные задачи.
3.1.2. Естественный параллелизм операций
в одной задаче.
Данный тип параллелизма характерен для обработки векторной, матричной, текстовой и графической многомерной информации. Классический пример – приближенное решение дифференциальных уравнений в частных производных методом сеток (конечных разностей).
Плоская задача Пуассона:
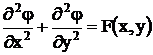
с заданными граничными условиями:
![]() , где
, где ![]() – уравнение контура границы области определения, по методу сеток сводится к системе линейных алгебраических уравнений высокого порядка:
– уравнение контура границы области определения, по методу сеток сводится к системе линейных алгебраических уравнений высокого порядка:
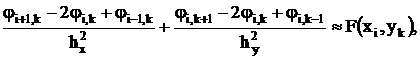
i=0…n, k=0…m,
где hx, hy – шаги декартовой сетки квантования непрерывной области определения по осям х и у соответственно;
i, k – номер узла двумерной сетки квантования;
ji, k – дискретные значения искомой функции j(x, y), определяемые только в узлах сетки;
N£(n+1)(m+1) – порядок аппроксимирующей системы алгебраических уравнений.
Требуется решать систему уравнений достаточно высокого порядка. Например, для достижения принципиальной погрешности dn£3%:
![]()
Так как уравнения всех N узлов сетки ik-х одинаковы, можно организовать параллельно-последовательный итеративный процесс решения таких систем высокого порядка по следующему вычислительному алгоритму. Поставим в соответствие каждому ik-му узлу одинаковые параллельно работающие вычислители, определяющие искомое значение jik(j) в данном j-м шаге итераций по известным значениям j(j-1) предыдущего (j-1)-го шага итерации в четырех соседних узлах:
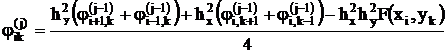
при условии сходимости итеративного процесса:
![]() i=0…n; k=0…m,
i=0…n; k=0…m,
где Dn – абсолютная допустимая и методически достижимая погрешность решения.
Каждый j-й шаг итерации начинается с передачи в каждый ik-й вычислитель из четырех соседних вычислителей значений j(j-1). Затем в каждом из них одновременно выполняется одинаковая операция, вычисляется jik(j) и проверяется условие сходимости. Признаки его выполнения со всех узловых вычислителей передаются в общее устройство управления (в ведущую ЭВМ). Если хотя бы в одном из N узлов сетки условие сходимости не выполняется, во всех N узловых вычислителях инициализируется аналогичный следующий шаг итерации и и. д. до выполнения условия сходимости во всех N вычислителях.
Таким образом возникла необходимость матричной организации структуры множества однотипных обрабатывающих устройств с близкодействующими связями только с ближайшими соседями:
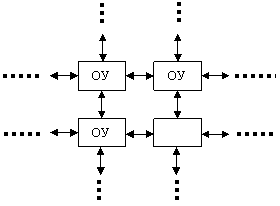 |
Для подобных рассмотренной выше задач в каждом командном цикле все ОУ выполняют одну и ту же команду или макрокоманду. В качестве ОУ могут быть применены типовые микропроцессоры с сокращенным набором команд. Промышленно производятся такие параллельные матричные ВС с общим управлением. В России к ним относятся параллельные системы ПС-2000, ПС-3000, которые нашли экономически выгодное применение для оперативной обработки информации при разведке полезных ископаемых. По результатам космической и сейсмической (взрывной) разведки оперативно решается объёмная задача Пуассона (трехмерная) и в результате оперативно определяется конфигурация и объем подземного пласта залегания.
Матричная организация с близкодействующими связями позволяет существенно ускорить выполнение операций над матрицами высокого порядка. Например, умножение двух квадратных матриц nxn:
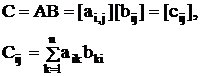
в параллельной матричной ВС выполняется n2 шагов, или n одинаковых циклов по n шагов каждый умножения одного столбца на n строк другой матрицы. В каждом шаге все n2 требуемых параллельных ОУ выполняют одинаковую команду:
1) В первом шаге цикла элементы столбца одновременно умножаются на элементы всех строк другой матрицы;
2) Затем за (n-1) шагов осуществляется в каждой из строк промежуточных произведений образование n-местной их суммы путем последовательной свертки с передачей промежуточных парных сумм ближайшему соседу.
Во второй фазе этого цикла вычисления выполняются (одинаковые) только в одном из столбцов ОУ, накапливая сумму двух слагаемых: элементов данного столбца и предыдущего. Поэтому в каждом из (n-1)-го шагов второй фазы цикла, к сожалению, простаивают n(n-1) ОУ. Для преодоления этого недостатка требуется особый ненакопительный принцип организации вычисления многоместной суммы, который мы рассмотрим позже.
Естественный параллелизм операций характерен не только для названных многомерных задач. Он встречается в большинстве математических задач, например в решении квадратного уравнения:
Естественный параллелизм операций характерен не только для названных многомерных задач. Он встречается в большинстве математических задач, например в решении квадратного уравнения:
![]()
Для анализа параллелизма операций применяют построение специального графического документа, который называется граф операндов, или граф передачи данных (ГПД), вершины которого соответствуют обозначениям необходимых операций, а направленные дуги – направлениям передачи операндов (данных) между операциями. Для квадратного уравнения с учетом знака дискриминанта D=B2-4AC граф операндов имеет следующий вид:
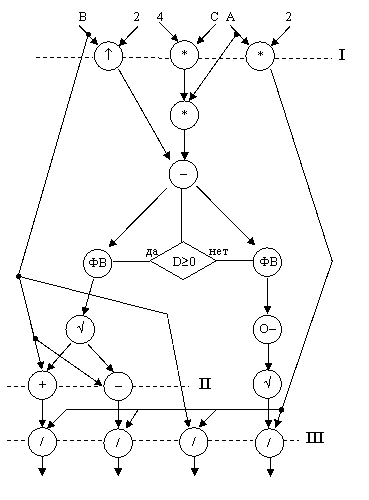 |
![]()
ФВ – флаговый вентиль;
(О–) – ®О-Д – изменение знака D.
При операции в I слое и по две операции во II и III слоях могли бы выполняться параллельно, если бы в составе АЛУ имелся соответствующий избыток операционных блоков.
Рассмотренный выше параллелизм операций в решении дифференциальных уравнений и при обработке матриц относится к классу регулярного, так как там одна и та же операция многократно повторяется над разными данными. Последний пример квадратного уравнения имеет нерегулярный параллелизм операций, когда над разными данными возможно одновременное выполнение разных типов операций.
Как показано выше, для использования регулярного параллелизма операций при повышении производительности подходит матричная организация ВС с общим управлением.
В общем случае нерегулярного параллелизма операций более подходящим способом повышения производительности считается потоковая организация ЭВМ и ВС. В потоковых ВС вместо традиционного фон Неймановского программного управления вычислительным процессом в соответствии с порядком следования команд, определяемого алгоритмом, применяется обратный принцип программного управления по степени готовности операндов, или потоком данных (потоком операндов), определяемой не алгоритмом, а графом операндов (графом передачи данных).
Если в параллельном процессоре имеется достаточный избыток обрабатывающих устройств, или в ВС – ансамбль избыточных микропроцессоров, то естественно и автоматически (без специальной диспетчирезации и составления расписания запуска) будут одновременно выполняться те параллельные операции, операнды которых подготовлены предыдущими вычислениями.
Вычислительный процесс начинается с тех операций, операндами которых являются исходные данные, как, например, в I слое ГПД квадратного уравнения одновременно выполняются три операции, а далее он развивается по мере готовности операндов. Послеэтого вызывается команда умножения, затем вычитания и проверки логического условия, потом макрооператор(Ö) и лишь после этого – одновременно две команды: сложения и вычитания, а после них – две одинаковых команды деления.
Техническая реализация потоковой организации ВС возможна тремя путями:
1) Созданием особых потоковых микропроцессоров, которые относятся к классу специализированных и будут рассмотрены в следующем семестре;
2) Специальной организацией вычислительного процесса и модификацией машинного языка низкого уровня в мультимикропроцессорных ансамблевых ВС, построенных на типовых микропроцессорах фон Неймана;
3) Созданием процессоров с избытком однотипных операционных блокови дополнением операционных систем потоковым способом организации вычислительного процесса (реализовано в отечественных потоковом процессоре ЕС2703 и суперЭВМ Эльбрус-2).
