

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Вариант решения домашнего задания №5.
Задача 1.
Пусть даны отношения R(x, y) и S(y, z). Главное предположение, которое требуется учитывать при построении таких алгоритмов следующее:
Предположение. Если ![]() , то все значения атрибута y, встречающиеся в отношении S, встречаются в кортежах отношения R, т. е. каждый кортеж отношения S обязательно соединится хотя бы с одним кортежем отношения R.
, то все значения атрибута y, встречающиеся в отношении S, встречаются в кортежах отношения R, т. е. каждый кортеж отношения S обязательно соединится хотя бы с одним кортежем отношения R.
а) Оценим количество кортежей, полученных в результате антисоединения отношений R и S. Рассмотрим два случая.
1. Пусть ![]() . Количество различных значений атрибута y отношения R, которые не встречаются в отношении S =
. Количество различных значений атрибута y отношения R, которые не встречаются в отношении S = ![]() . Доля этих кортежей в отношении R при условии равномерного распределения значений атрибута по кортежам = =
. Доля этих кортежей в отношении R при условии равномерного распределения значений атрибута по кортежам = =![]() .
.
Таким образом, количество кортежей в результате = 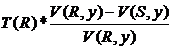 .
.
2. Пусть теперь ![]() . Тогда в силу предположения все значения атрибута y, встречающиеся в отношении R, встречаются в отношении S, т. е. все кортежи отношения R соединяются с кортежами отношения S. Таким образом, количество кортежей в результате=0.
. Тогда в силу предположения все значения атрибута y, встречающиеся в отношении R, встречаются в отношении S, т. е. все кортежи отношения R соединяются с кортежами отношения S. Таким образом, количество кортежей в результате=0.
В общем виде получим:
Количество кортежей, полученных в результате проведения антисоединения отношений R и S = 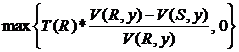 .
.
б) внешнее соединение отношений R и S.
Результат внешнего соединения отношений состоит из:
- Кортежей, полученных в результате естественного соединения отношений (количество = a). Для каждого кортежа
Таким образом, количество кортежей, полученных в результате внешнего соединения = a+b+c. Следует заметить, что в силу предположения либо b=0 (если 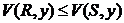 ), либо с=0 (если
), либо с=0 (если ![]() ).
).
Первое слагаемое известно: ![]() .
.
Значение b можно оценить посредством антисоединения отношений R и S. Действительно, так как формируется по одному кортежу для каждого кортежа ![]() , который не соединяется ни с одним из кортежей отношения S, получим, что b равно числу кортежей, полученных в результате антисоединения R и S, т. е.
, который не соединяется ни с одним из кортежей отношения S, получим, что b равно числу кортежей, полученных в результате антисоединения R и S, т. е. 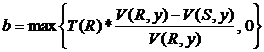 (из решения пункта а)).
(из решения пункта а)).
Аналогично, с – число кортежей, полученное в результате антисоединения отношений S и R, т. е. 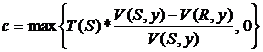 .
.
Таким образом, число кортежей, полученных в результате внешнего соединения = = ![]() .
.
Задача 2.
Очевидно, что при расчетах могут получиться нецелые числа. В этих случаях принято рассматривать случай, когда получается большее число кортежей, т. е. нецелые результаты принято округлять в большую сторону.
![]()
![]()
![]() a) A= W X Y Z.
a) A= W X Y Z.
![]() T(A1)=T(W X) =
T(A1)=T(W X) = 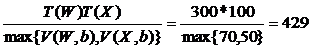 кортежей.
кортежей.
Так как V(X, c)=20, то так как оценка размера отношения A1 составляет 429 кортежа, то можно ожидать, что все 20 различных значений атрибута c попадут в отношение A1. Таким образом, принимается V(A1, c) = 20.
![]() T(A2) =T(A1 Y) =
T(A2) =T(A1 Y) = ![]() кортежа.
кортежа.
Так как V(Y, d)=100 и оценка размера отношения A2 составляет 5363 кортежа, то принимается V(A2, d) = 100.
![]() T(A)=T(A2 Z) =
T(A)=T(A2 Z) = 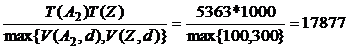 кортежей.
кортежей.
![]() б) A=sd=30 (Y) se<50 AND d>10 (Z).
б) A=sd=30 (Y) se<50 AND d>10 (Z).
T(A1)=T(sd=30 (Y))= ![]() кортежей.
кортежей.
T(A2)=T(se<50 AND d>10 (Z)) = ![]() кортежей. (дважды делим на 3, поскольку оба условия имеют форму неравенства).
кортежей. (дважды делим на 3, поскольку оба условия имеют форму неравенства).
Соединение производится по атрибуту d. Очевидно, что ![]() . Следует ожидать также, что так как атрибут d являлся атрибутом выборки при определении A2, то количество различных значений этого атрибута также сократится в 3 раза, т. е.
. Следует ожидать также, что так как атрибут d являлся атрибутом выборки при определении A2, то количество различных значений этого атрибута также сократится в 3 раза, т. е. ![]() .
.
![]() Т(А)=Т(A1 A2) =
Т(А)=Т(A1 A2) = ![]() кортежей.
кортежей.
в) A = sd=5 OR e=10 (Z).
Количество кортежей отношения Z(d=5) = ![]() кортежа.
кортежа.
Количество кортежей отношения Z(e=10)= ![]() кортежей.
кортежей.
Пусть p1 – вероятность того, что первое условие не будет выполнено;
![]() p2 – вероятность того, что второе условие не будет выполнено.
p2 – вероятность того, что второе условие не будет выполнено.
![]() p1=
p1=![]() , p2=
, p2=![]() .
.
Пусть p – вероятность того, что оба условия не будут выполнены.
p = p1* p2=0.996*0.99=0.98604.
Вероятность того, что выполняется хотя бы одно условие составляет 1- p. Таким образом, T(A)=![]() кортежей.
кортежей.
![]() г) A= sb=5 OR d >10 ( X Y) = sb=5 OR d >10 (
г) A= sb=5 OR d >10 ( X Y) = sb=5 OR d >10 (![]() ).
).
X. c<Y. c
T(A1)=T(![]() )=
)=![]() кортежей.
кортежей.
![]() кортежей.
кортежей.
Очевидно, что в отношении A2 атрибут b в худшем случае принимает столько же значений, что и в отношении X, т. е. 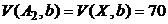 .
.
Количество кортежей отношения A2 (b=5) = ![]() кортежей.
кортежей.
Количество кортежей отношения A2 (d>10)=![]() кортежей.
кортежей.
Пусть p1 – вероятность того, что первое условие не будет выполнено;
p2 – вероятность того, что второе условие не будет выполнено.
![]() p1=
p1=![]() , p2=
, p2=![]() .
.
Пусть p – вероятность того, что оба условия не будут выполнены.
p = p1* p2=0.98566*0.6666=0.65704.
Вероятность того, что выполняется хотя бы одно условие составляет 1- p. Таким образом, T(A)=![]() кортежей.
кортежей.
Задача 3.
Пусть требуется получить список студентов из двух заданных групп (например, 9001 и 9002) и список несданных ими экзаменов.
Текст запроса может быть следующим:
SELECT Students. Name, Exams. Name FROM Students NATURAL JOIN Stud_Exam NATURAL JOIN Exams WHERE (Mark=”неудовлетворительно” OR Mark=”не явился”) AND (Group=”9001” OR Croup=”9002”).
Для оптимизации выполнения данного запроса потребуются следующие статистические характеристики:
1. V(Students, Group) = 250.
2. V(Stud_Exams, Mark) = 5 (отлично, хорошо, удовлетворительно, неудовлетворительно, не явился).
В качестве начальных логических планов запроса согласно различным порядкам соединения отношений можно принять:
План 1.
![]() pStudents. Name, Exams. Name
pStudents. Name, Exams. Name
s(Mark=”неудовлетворительно” OR Mark=”не явился”) AND (Group=”9001” OR Group=”9002”)
 |  |
Students Stud_Exam Exams
План 2.
![]() pStudents. Name, Exams. Name
pStudents. Name, Exams. Name
s(Mark=”неудовлетворительно” OR Mark=”не явился”) AND (Group=”9001” OR Group=”9002”)
| |
Exams Stud_Exam Students
План 3.
![]() pStudents. Name, Exams. Name
pStudents. Name, Exams. Name
s(Mark=”неудовлетворительно” OR Mark=”не явился”) AND (Group=”9001” OR Group=”9002”)
| |
Stud_Exam Students Exams
Для улучшения логических планов запроса нужно переместить выборку на более низкие уровни дерева, разбив условие выборки на 2: условие (Mark=”неудовлетворительно” OR Mark=”не явился”) должно переместиться в ветвь, соответствующую отношению Stud_Exam, условие (Group=”9001” OR Croup=”9002”) – в ветвь, соответствующую отношению Students.
Таким образом, получим:
План 1.
![]() pStudents. Name, Exams. Name
pStudents. Name, Exams. Name
![]()
 s(Group=”9001” OR Group=”9002”)
s(Group=”9001” OR Group=”9002”)
s(Mark=”неудовлетворительно” OR Mark=”не явился”)
Students Stud_Exam Exams
Заметим, что в результирующем множестве соединения отношений Stud_Exam и Exams нас интересует только поля StudID, Exams. Name. Следовательно, можно при формировании результирующих кортежей соединения сразу осуществлять проекцию (конвейерным способом). Это не потребует никаких дополнительных затрат, а количество блоков, которое займет спроектированное отношение, будет значительно меньше.
План 2.
![]() pStudents. Name, Exams. Name
pStudents. Name, Exams. Name
 |
![]()
![]()
s(Mark=”неудовлетворительно” OR Mark=”не явился”) s(Group=”9001” OR Group=”9002”)
Exams Stud_Exam Students
В этом случае выполнение оператора проекции после соединения отношений Stud_Exam и Students также возможно, но проектировать нужно будет уже два поля ExamID и Students. Name.
План 3.
![]() pStudents. Name, Exams. Name
pStudents. Name, Exams. Name
 |

![]()
s(Mark=”неудовлетворительно” OR Mark=”не явился”)
![]() s(Group=”9001” OR Group=”9002”)
s(Group=”9001” OR Group=”9002”)![]()
Stud_Exam Students Exams
В этом случае после соединения отношений Students и Exams можно конвейерным способом выполнить проекцию атрибутов StudID, Students. Name, ExamID и Exams. Name. Заметим также, что в плане 3 соединение отношений Students и Exams фактически является их декартовым произведением, поскольку общих атрибутов у этих двух отношений нет.
Оценка размеров промежуточных отношений.
План 1.
![]() pStudents. Name, Exams. Name 64
pStudents. Name, Exams. Name 64
![]() 64
64
![]() s(Group=”9001” OR Group=”9002”)
s(Group=”9001” OR Group=”9002”)
s(Mark=”неудовлетворительно” OR Mark=”не явился”) 8000
Students 5000 Stud_Exam 20000 Exams 500
Размер выборки из отношения Students по группе = ![]() . Здесь два условия, объединенные логическим оператором OR, являются взаимоисключающими. Поэтому количество кортежей, которые удовлетворяет общему условию, выражает как количество студентов одной группы, умноженное на 2.
. Здесь два условия, объединенные логическим оператором OR, являются взаимоисключающими. Поэтому количество кортежей, которые удовлетворяет общему условию, выражает как количество студентов одной группы, умноженное на 2.
Аналогично, размер выборки из отношения Stud_Exams по оценке = =![]() .
.
Очевидно, что после выборки студентов по заданным группам количество различных значений атрибута StudID будет 40. После выборки из отношения Stud_Exam по заданным оценкам количество различных значений атрибута StudID будет 5000, поскольку в худшем случае возможно возникновение информации о всех 5000 студентах базы в 8000 кортежах выборки из Stud_Exam. В этих же 8000 кортежах может содержаться информация обо всех 500 экзаменах, которые сдавались студентами. Поэтому количество различных значений атрибута ExamID после выборки из Stud_Exam будет 500.
Размер соединения Stud_Exam и Exams = 8000*500/max{500,500}=8 000 кортежей.
Так как число различных значений StudID в выборке отношения Stud_Exam было равно 5 000, учитывая размер соединения отношений Stud_Exam и Exams, можно ожидать, что количество различных значений атрибута StudID по правой ветке составит 5 000. Тогда размер окончательного соединения = 40*8000/max{40; 5000}=64 кортежа.
Очевидно, проекция имеет тот же размер.
План 2.
 pStudents. Name, Exams. Name 64
pStudents. Name, Exams. Name 64
![]() 64
64
![]()
![]() 64
64
![]()
![]()
s(Mark=”неудовлетворительно” OR Mark=”не явился”) 8000 s(Group=”9001” OR Group=”9002”) 40
Exams 500 Stud_ExamStudents 5 000
Размер соединения отношений Stud_Exam и Students с учетом выборки составляет 8000*40/max{5000,40}=64 кортежа, причем так как V(Stud_Exam, ExamID)=500, то можно ожидать, что число различных значений атрибута ExamID в результате соединения будет также равно 64, т. е. в результате соединение отношений Stud_Exam и Students в худшем случае будет содержаться информация о 64 различных экзаменах.
Поэтому размер окончательного соединения = 500*64/max{500,64}=64 кортежа.
План 3.
![]() pStudents. Name, Exams. Name 64
pStudents. Name, Exams. Name 64
![]() 64
64
![]()
![]()
s(Mark=”неудовлетворительно” OR Mark=”не явился”) 8000
![]() s(Group=”9001” OR Group=”9002”)
s(Group=”9001” OR Group=”9002”)![]() 40
40
Stud_ExamStudents 5 000 Exams 500
Поскольку соединение отношений Students и Exams является по своей сути декартовым произведением, размер отношения = 40*500=20 000 кортежей, причем в нем количество различных значений атрибута StudID=40, а атрибута ExamID=500.
Соединение с отношением Stud_Exam теперь будет проходить по двум атрибутам StudID и ExamID. Размер окончательного соединения = 20000*8000/(max{40, 5000}*max{500,500})=64 кортежа.
Сейчас уже очевидно, что план 3 продуцирует наибольшие по размеру промежуточные отношения и, следовательно, менее удобен для выполнения запроса. Если сравнивать планы 1 и 2, то предпочтительнее с точки зрения размеров промежуточных отношений использовать план 2.
Построим физический план запроса для выбранного плана 2. Относительно использования алгоритмов нужно решить несколько вопросов. Во-первых, требуется выбрать алгоритм, по которому проводить выборку. Если и существуют индексы по атрибутам выборок, то эти индексы являются вторичными и, следовательно, некластеризованными. В этом случае можно ожидать, что при использовании физического оператора IndexScan потребуется прочитать приблизительно столько же блоков, сколько кортежей в результате выборки. Судя по размеру отношения Stud_Exam использование индекса здесь абсолютно неэффективно. Поэтому для чтения и проведения выборки из отношения Stud_Exam будем использовать цепочку физических операторов TableScan(Stud_Exam)->Filter(Mark=”неудовлетворительно” OR Mark=”не явился”). В случае выборки из отношения Students, судя по размерам отношения и результата выборки, может оказаться, что использование индекса будет более эффективным. Для этого только требуется, чтобы B(Students)>40, что вполне вероятно. Здесь можно использовать индекс, т. е. физический оператор IndexScan(Students, Group).
Для выбора алгоритма соединения также можно заметить, что во всех операторах соединения плана 2 один из операндов имеет малый размер. Можно ожидать, что его можно поместить в оперативной памяти. Следовательно, можно использовать алгоритм однопроходного соединения. Причем, поскольку результат промежуточного соединения невелик, при относительно реальных требованиях на используемую оперативную память можно обрабатывать результат промежуточного соединения конвейерным способом, сохраняя его в оперативной памяти и затем подгружая по одному блоку отношение Exams.
Физический план 2.
![]() [Proj(Students. Name, Exams. Name)]
[Proj(Students. Name, Exams. Name)]
![]() [One-Pass Join]
[One-Pass Join]
 |
 |
[One-Pass Join]
 |
[Filter(Mark=”неудовлетворительно”
![]() OR Mark=”не явился”)]
OR Mark=”не явился”)]
[TableScan(Exams)] [TableScan(Stud_Exam)] [IndexScan(Students, Group)]
