
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
REVOKE INSERT ON Сотрудники FROM USER
БИЛЕТ 9
1. Системы, основанные на знаниях. Схема и цикл функционирования. Отличительные особенности. Область применения.
2. Язык SQL Выборка данных из нескольких таблиц. Соединение равенства; соединение неравенства. Внешние соединения: левое, правое, полное.
1. Системы, основанные на знаниях. Схема и цикл функционирования. Отличительные особенности. Область применения.
Разработка систем, основанных на знаниях, является составной частью исследований по искусственному интеллекту и имеет целью создание компьютерных, методов решения проблем, обычно требующих привлечения специалистов.
В любой момент времени в системе содержится три типа знаний:
* Структурированные знания - статические знания о предметной области. После того как эти знания выявлены, они уже не изменяются.
* Структурированные динамические знания - изменяемые знания о предметной области. Они обновляются по мере выявления новой информации.
* Рабочие знания - знания, применяемые для решения конкретной задачи или проведения консультации
Все перечисленные выше знания хранятся в базе знаний. Для се построения требуется провести опрос специалистов, являющихся экспертами в конкретной предметной области, а затем систематизировать, организовать и снабдить эти знания указателями, чтобы впоследствии их можно было легко извлечь из базы знаний.
Системы, основанные на знаниях, имеют свои особенности, отличающие их от систем других типов.
Экспертиза может проводиться только в одной конкретной области. Так, программа, предназначенная для определения конфигурации систем ЭВМ, не может ставить медицинские диагнозы.
База знаний и механизм вывода являются различными компонентами. Действительно, часто оказывается возможным сочетать механизм вывода с другими базами знаний для создания новых экспертных систем. Например, программа анализа инфекции в крови может быть применена в пульманологии путем замены базы знаний, используемой с тем же самым механизмом вывода.
Наиболее подходящая область применения - решение задач дедуктивным методом. Например, правила или эвристики выражаются в виде пар посылок и заключений типа "если - то" (см. следующую главу).
Эти системы могут объяснять ход решения задачи понятным пользователю способом. Обычно мы не принимаем ответ эксперта, если на вопрос "Почему?" не можем получить логичный ответ. Точно так же мы должны иметь возможность спросить систему, основанную на знаниях, как было получено конкретное заключение.
Выходные результаты являются качественными (а не количественными).
Системы, основанные на знаниях, строятся по модульному принципу, что позволяет постепенно наращивать их базы знаний.
Области применения систем, основанных на знаниях, могут быть сгруппированы в несколько основных классов: медицинская диагностика, прогнозирование, планирование, интерпретация, контроль и управление, диагностика неисправностей в механических и электрических устройствах, обучение.
2. Язык SQL Выборка данных из нескольких таблиц. Соединение равенства; соединение неравенства. Внешние соединения: левое, правое, полное.
Выборка данных из нескольких таблиц
Как правило, информация, хранящаяся в базе данных, содержится в нескольких связанных между собой таблицах. Язык SQL позволяет создавать запросы, извлекающие данные из нескольких таблиц. При этом выполняется операция соединения, состоящая в объединении нескольких таблиц с целью поиска в них запрошенных данных.
Существует несколько способов соединения таблиц. Наиболее часто встречаются следующие:
Q соединение равенства; О соединение неравенства; Q внешние соединения.
Для задания вида соединения используется предложение WHERE, в котором вид соединения указывается с помощью операторов сравнения или логических операторов.
Соединение равенства
Данное соединение является наиболее часто используемым. Соединение равенства обычно производится по общему для нескольких таблиц полю (которое, как правило, является первичным ключом).
Синтаксис оператора выборки для этого способа соединения таблиц будет следующим:
SELECT tablel. fieldl. table2.field2 {. ... . tableN. fieldN} FROM tablel. table2 {,.... tableN} WHERE mon_fieldl - table2.common_fieldl {AND mon_field2 - table2.common_field2}
При формировании запроса на выборку из нескольких таблиц в списке полей после слова SELECT перед именем поля обычно указывается имя таблицы, к которой это поле относится. Такое действие называется квалификацией полей запроса. Квалификация обязательна только для полей, имеющих одинаковые имена в разных таблицах, из которых производится выборка.
Рассмотрим пример выборки из двух таблиц с использованием соединения равенства. Выберем из таблицы «Клиенты» поля, содержащие сведения об именах клиентов, а из таблицы «Продажи» — поля, в которых содержатся сведения о покупках, сделанных клиентами. Для связывания таблиц воспользуемся общим для обеих таблиц полем «Код клиента»:
SELECT Клиенты. Фамилия. Клиенты. Имя.
Клиенты. Отчество. Продажи. Продано
FROM Клиенты. Продажи
WHERE Клиенты.[Код клиента]=Продажи.[Код клиента]
При связывании таблиц можно использовать предложение группировки. Изменим рассмотренный выше запрос таким образом, чтобы результаты были сгруппированы по полям «Фамилия», «Имя», «Отчество» и для каждого клиента выводилось суммарное количество покупок:
SELECT Клиенты. Фамилия. Клиенты. Имя, Клиенты Отчество,
Зимспродажи. Продано) AS [Количество покупок]
FROM Клиенты. Продажи
WHERE Клиенты.[Код клиента]=Продажи.[Код клиента]
GROUP BY Клиенты. Фамилия. Клиенты. Имя. Клиенты Отчество
Выборка из трех таблиц проводится аналогичным образом, только в предложении WHERE необходимо указать условие связи с третьей таблицей. Для примера дополним предыдущий запрос таким образом, чтобы в выборку была включена информация о наименовании товара из таблицы «Товары»:
SELECT Клиенты. Фамилия, Клиенты. Имя, Клиенты. Отчество,
511М(Продажи. Продано) AS [Количество покупок].
Товары. Наименование
FROM Клиенты. Продажи. Товары
WHERE (Клиенты.[Код клиента]=Продажи.[Код клиента]) AND
(Продажи.[Код товара]=Товары.[Код товара])
GROUP BY Клиенты. Фамилия, Клиенты. Имя. Клиенты. Отчество.
Товары. Наименование
SELECT Клиенты Фамилия, Клиенты Имя, Клиенты Отчество, >11М(Продажи Продано) AS [Количество покупок], 'овары Наименование :ROM Клиенты, Продажи, Товары
WHERE (Клиенты [Код клиента]-Продажи [Код клиента]) AND Продажи [Код товара)-Товары [Код товара]] 3ROUP BY Клиенты Фамилия. Клиенты Имя, Клиенты Отчество, 'овары Наименование
Соединение неравенства
В случае применения соединения неравенства информация из двух таблиц объединяется таким образом, чтобы значения в заданном поле одной таблицы не совпадали со значениями соответствующего ему поля в другой таблице.
Синтаксис запроса при соединении неравенства аналогичен предыдущему случаю, только вместо оператора «=» в предложении WHERE используются операторы «<>», «<», «>» и т. п.
SELECT tablel. fneldl, table2.field2 {...., tab! eN. fieldN} FROM tabl el. table2 {..... tableN} WHERE mon_fieldl <> table2.common_fieldl {AND mon_field2 > table2.common_field2}
Соединения неравенства используются довольно редко. В частности, для базы данных, используемой нами в качестве практической модели, довольно трудно привести осмысленный пример такого соединения.
Внешние соединения
При использовании внешнего соединения результат запроса будет содержать все записи одной из таблиц, даже в том случае, если в связанной с ней таблице отсутствуют совпадающие значения. Этот тип соединения реализуется с помощью оператора OUTER JOIN.
Внешние соединения подразделяются на три группы:
Q левое внешнее соединение, LEFT OUTER JOIN — выборка будет содержать все записи таблицы, имя которой указано слева от оператора OUTER JOIN;
О правое внешнее соединение, RIGHT OUTER JOIN — выборка будет содержать все записи таблицы, имя которой указано справа от оператора OUTER JOIN;
О полное внешнее соединение, FULL OUTER JOIN — в выборку включаются все записи из правой и левой таблицы.
Для внешнего соединения условие соединения указывается не с помощью предложения WHERE, а входит в оператор OUTER JOIN после ключевого слова ON:
SELECT tablel. fieldl, table2.field2 {. ... . tableN. fieldN} FROM tablel
LEFT | RIGHT | FULL {OUTER} JOIN table2
ON условие
{LEFT | RIGHT | FULL {OUTER} JOIN table3
ON условие}.
БИЛЕТ 10
1. Метод сущность – связь. Основные понятия метода;
2. Язык SQL Язык запросов DQL. Простейшая форма оператора SELECT.
1. Метод сущность-связь. Основные понятия метода.
Метод сущность-связь называют также методом «ER-диаграмм»: во-первых, ER - аббревиатура от слов Essence (сущность) и Relation (связь), во-вторых, метод основан на использовании диаграмм, называемых соответственно диаграммами ER-экземпляров и диаграммами ER-типа.
Основными понятиями метода сущность-связь являются следующие:
• сущность,
• атрибут сущности,
• ключ сущности,
• связь между сущностями,
• степень связи,
• класс принадлежности экземпляров сущности,
• диаграммы ER-экземпляров,
• диаграммы ER-типа.
Сущность представляет собой объект, информация о котором хранится в БД. Экземпляры сущности отличаются друг от друга и однозначно идентифи шруются. Ыа-званиями сущностей являются, как правило, существительные, например: ПРЕПОДАВАТЕЛЬ, ДИСЦИПЛИНА, КАФЕДРА, ГРУППА.
Атрибут представляет собой свойство сущности. Это понятие аналогично понятию атрибута в отношении. Так, атрибутами сущности ПРЕПОДАВАТЕЛЬ может быть его Фамилия, Должность, Стаж (преподавательский) и т. д.
Ключ сущности - атрибут или набор атрибутов, используемый для идентификации экземпляра сущности. Как видно из определения, понятие ключа :ущности аналогично понятию ключа отношения.
Связь двух или более сущностей - предполагает зависимость между атрибутами этих сущностей. Название связи обычно представляется глаголом. Примерами связей между сущностями являются следующие: ПРЕПОДАВАТЕЛЬ. В.ЁДЕТДИСЦИПЛИ-НУ (Иванов ВЕДЕТ «Базы данных»), ПРЕПОДАВАТЕЛЬ ПРЕПОДАЕТ-В ГРУППЕ (Иванов ПРЕПОДАЕТ-В 256 группе), ПРЕПОДАВАТЕЛЬ РАБС ТАЕТ-НА КАФЕДРЕ (Иванов РАБОТАЕТ-НА 25 кафедре).
Приведенные определения сущности и связи не полностью формализованы, но приемлемы для практики. Следует иметь в виду, что в результате проектирования могут быть получены несколько вариантов одной БД. Так, два разных npoei. тировщи-ка, рассматривая одну и ту же проблему с разных точек зрения, могут пол /чить различные наборы сущностей и связей. При этом оба варианта могут быть рг бочими, а выбор лучшего из них будет результатом личных предпочтений.
С целью повышения наглядности и удобства проектирования для пред :тавлеиия сущностей, экземпляров сущностей и связей между ними используются с тедующие графические средства:
• диаграммы ER-экземпляров,
* диаграммы ER-muna, или ER-диаграммы.
На начальном этапе проектирования БД выделяются атрибуты, составляющие ключи сущностей.
На основе анализа диаграмм ER-типа формируются отношения проектируемой БД. При этом учитывается степень связи сущностей и класс их принадлежности, которые, в свою очередь, определяются на основе анализа диаграмм er-э]. земпляров соответствующих сущностей.
Степень связи является характеристикой связи между сущностями, которая может быть типа: 1:1, 1:М, М:1, М:М.
Класс принадлежности (КП) сущности может быть: обязательным и необязательным. Класс принадлежности сущности является обязательным, если все экземпляры этой сущности обязательно участвуют в рассматриваемой связи, в протш ном случае класс принадлежности сущности является необязательным.
Варьируя классом принадлежности сущностей для каждого из названных типов связи, можно получить несколько вариантов диаграмм ER-типа. Рассмотрим примеры некоторых из них.
2. Язык SQL-запросов DQL; простейшая форма оператора SELECT.
Язык запросов DQL
Язык запросов, являющийся одной из категорий языка SQL, состоит всего из одной команды SELECT Эта команда вместе с множеством опций и предложений используется для формирования запросов к базе данных
Запросы формируются для извлечения из таблиц базы данных информации, соответствующей некоторым требованиям, задаваемым пользователем.
Оператор SELECT не используется автономно, вместе с ним обязательно должны задаваться уточняющие предложения. Предложения, используемые совместно с командой SELECT, могут быть обязательными и дополнительными. Обязательным является только одно предложение — FROM, без которого оператор SELECT не может использоваться.
Простейшая форма оператора SELECT
Оператор SELECT вместе с предложением FROM используется для получения информации из базы данных. Синтаксис простейшей формы оператора SELECT приведен ниже:
SELECT {* | ALL | DISTINCT fieldl, field2. . . fieldN} FROM tablel {. tab1e2. ... . tableN}
Здесь за ключевым словом SELECT следует список полей, которые возвращаются в результате выполнения запроса:
· имена полей в списке разделяются через запятую;
· для выборки всех полей таблицы (таблиц) используется символ подстановки «*»;
· опция ALL (задана по умолчанию) означает, что результат выборки будет содержать все записи, включая дублирующие друг друга;
· при использовании опции DISTINCT результат запроса не будет содержать дублирующихся строк.
Совместно с командой SELECT всегда используется предложение FROM, с помощью которого указывается имя таблицы (таблиц), из которой производится выборка. Если в предложении FROM указывается несколько таблиц, то их имена разделяются запятыми.
Выше мы уже рассмотрели пример использования оператора SELECT для выборки всей информации, содержащейся в таблице «Товары». Чтобы выбрать не все поля, а лишь некоторые, необходимо после слова SELECT указать имена полей, которые будут включены в результат выборки. В качестве примера ниже приведен запрос, возвращающий значения только трех полей: «Код товара», «Наименование» и «Цена»:
SELECT [что] FROM [откуда]; .
БИЛЕТ 11
1. Метод сущность – связь. Правила формирования отношений.
2. Язык SQL Логические операторы: Is null, BETWEEN...AND, IN, LIKE, EXISTS, UNIQUE, ALL, ANY.
1. Метод сущность-связь. Правила формирования отношений.
Правила формирования отношений основываются на учете следующего:
• степени связи между сущностями (1:1, 1:М, М:1, М:М);
• класса принадлежности экземпляров сущностей (обязательный и необя зательный).
Рассмотрим формулировки шести правил формирования отношений на основе диаграмм ER-типа.
Формирование отношений для связи 1:1
Правило 1. Если степень бинарной связи 1:1 и класс принадлежности обеих сущностей обязательный, то формируется одно отношение. Первичным клочом этого отношения может быть ключ любой из двух сущностей.

Па рисунке используются следующие обозначения:
Cl, C2 - сущности 1 и 2;
Kl, K2 - ключи первой и второй сущности соответственно;
R1 - отношение 1, сформированное на основе первой и второй сущностей;
K1vK2,... означает, что ключом сформированного отношения может быть либо К1,либоК2.
Правило 2. Если степень связи 1:1 и класс принадлежности одной сущностей обязательный, а второй - необязательный, то под каждую из сущностей формируется по отношению с первичными ключами, являющимися ключами соответствую!! их сущностей. Далее к отношению, сущность которого имеет обязательный КП, добавляется в качестве атрибута ключ сущности с необязательным КП.
На рисунке приведены диаграмма ER-типа и отношения, сформированные по правилу 2 на ее основе.

Правило 3. Если степень связи 1:1 и класс принадлежности обеих сущностей является необязательным, то необходимо использовать три отношения. Дг а отношения соответствуют связываемым сущностям, ключи которых являются первичными в этих отношениях. Третье отношение является связным между первыми двумя, поэтому его ключ объединяет ключевые атрибуты связываемых отношений.
![]()
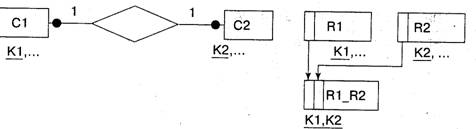
Правило 4. Если степень связи между сущностями 1:М (или М:1) и класс принадлежности М-связной сущности обязательный, то достаточно формирована • двух отношений (по одному на каждую из сущностей). При этом первичными ключам, i этих отношений являются ключи их сущностей. Кроме того, ключ 1-связной сущности добавляется как атрибут (внешний ключ) в отношение, соответствующее М-связной сущности.
На рисунке приведены диаграмма ER-типа и отношения, сформированные по правилу 4.

Правило 5. Если степень связи 1:М (М:1) и класс принадлежности М-связной сущности является необязательным, то необходимо формирование трех отношений 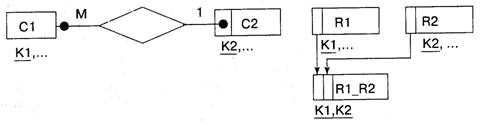
Два отношения соответствуют связываемым сущностям, ключи которых являются первичными в этих отношениях. Третье отношение является связным между первыми двумя (его ключ объединяет ключевые атрибуты связываемых отношений).
В результате применения правила 5 к рассматриваемому отношению с содержащимися в нем данные распределяются по трем отношениям.
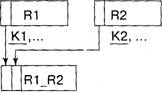
Правило 6. Если степень связи М:М, то независимо от класса принад. гежности сущностей формируются три отношения. Два отношения соответствуют связываемым сущностям и их ключи являются первичными ключами этих отношенк и. Третье отношение является связным между первыми двумя, а его ключ объединяс т ключевые атрибуты связываемых отношений.
На рисунке приведены диаграмма ER-типа и отношения, сформированные по правилу 6.
|
К1,... |
К2,... |
|
К1,К2.
2. Язык SQL. Логические оперваторы Is null, BETWEEN...AND, IN, LIKE, EXISTS, UNIQUE, ALL, ANY.
Логические операторы
К логическим относятся операторы, в которых для задания ограничений на отбор данных используются специальные ключевые слова. В SQL определены следующие логические операторы: Is null, BETWEEN...AND, IN, LIKE, EXISTS, UNIQUE, ALL, ANY.
Оператор IS NULL
Оператор IS NULL предназначен для сравнения текущего значения поля со значением NULL. Он используется для отбора записей, в некоторое поле которых не занесено никакое значение.
Для иллюстрации использования этого оператора воспользуемся таблицей «Клиенты». С помощью приведенного ниже запроса произведем выборку из нее записей клиентов, у которых не указано название предприятия, которое они представляют:
SELECT Фамилия. Имя. Отчество. Телефон. Город, Адрес
FROM Клиенты
WHERE Предприятие IS NULL
Оператор BETWEEN...AND
Оператор BETWEEN..AND применяется для отбора записей, в которых значения поля находятся внутри заданного диапазона. Границы диапазона включаются в условие отбора.
Чтобы продемонстрировать работу этого оператора, вернемся к таблице «Товары» и выберем в ней товары, цена которых находится в диапазоне от 200 до 2000. Для этого сформируем следующий запрос:
SELECT *
FROM Товары
WHERE Цена BETWEEN 200 AND 2000
данных
Оператор IN
Оператор IN используется для выборки записей, в которых значение некоторого поля соответствует хотя бы одному из значений заданного списка.
Выберем из таблицы «Клиенты» список клиентов, которые живут в Беларуси, Украине или Казахстане:
SELECT Фамилия. Иня. Отчество. Страна
FROM Клиенты
WHERE Страна IN ('Беларусь','Украина'.'Казахстан')
Оператор LIKE
Оператор LIKE применяется для сравнения значения поля со значением, заданным при помощи шаблонов. Для задания шаблонов используются два символа:
Q знак процента «£» — заменяет последовательность символов любой (в том числе и нулевой) длины;
Q символ подчеркивания «_» — заменяет любой единичный символ.
Найдем в таблице «Клиенты» записи, в которых фамилия клиента начинается с буквы «М»:
SELECT Фамилия, Имя, Отчество. Телефон
FROM Клиенты
WHERE Фамилия LIKE 'МГ
А теперь найдем в этой же таблице записи, для которых номер телефона начинается на цифры (816)025-61, а две последние цифры неизвестны:
SELECT Фамилия. Имя. Отчество. Телефон
FROM Клиенты
WHERE Телефон LIKE Ч816)025-61_'
Оператор EXISTS
Оператор EXISTS используется для отбора записей, соответствующих заданному критерию.
Для иллюстрации его работы рассмотрим следующий пример. Из таблицы «Товары» требуется отобрать список товаров, количество продаж которых превышает 10. Сведения о продажах содержатся в таблице «Продажи» в поле «Продано». Для получения необходимой выборки воспользуемся оператором
EXISTS:
SELECT Наименование Цена
FROM Товары
WHERE EXISTS (SELECT [Код товара]
FROM Продажи
WHERE (Продажи Продано>10) AND
Товары [Код товара]=Продажи [Код товара])
В этом запросе после ключевого слова EXISTS следует оператор SELECT, отбирающий из таблицы «Продажи» записи, для которых количество продаж превышает 10.
Оператор EXISTS отбирает из таблицы «Товары» записи, в которых значение поля «Код товара» соответствует отобранным из таблицы «Продажи».
Оператор UNIQUE
Оператор UNIQUE используется для проверки записи таблицы на уникальность. По своему действию он аналогичен оператору EX ISTS. Единственное отличие заключается в том, что подзапрос, задаваемый после ключевого слова UNIQUE, не должен возвращать более одной записи.
Оператор ALL
Оператор ALL используется для сравнения исходного значения со всеми другими значениями, входящими в некоторый набор данных.
Например, для того чтобы выбрать из таблицы «Товары» те товары, которые имеют цену большую, чем цена всех товаров, проданных в количестве более 10, используется следующий запрос:
SELECT *
FROM Товары
WHERE LleHa>ALL (SELECT Продажи. Цена
FROM Продажи
WHERE Продажи. Продано>10)
Оператор ANY
Оператор ANY применяется для сравнения заданного значения с каждым из значений некоторого набора данных. Если в предыдущем примере заменить оператор ALL на ANY, то будет возвращен список товаров, цена которых больше, чем хотя бы у одного из товаров, проданных в количестве больше 10.
БИЛЕТ 12
1. Метод нормальных форм.
2. Язык SQL. Операторы отрицания. IS NOT NULL NOT BETWEEN NOT IN NOT LIKE NOT EXISTS NOT UNIQUE. Упорядочение данных. Предложение ORDER BY.
1. Метод нормальных форм.
Проектирование БД является одним из этапов жизненного цикла информационной системы. Основной задачей, решаемой в процессе проектирования БД, является задача нормализации ее отношений. Рассматриваемый ниже метод нормальных форм является классическим методом проектирования реляционных БД. Этот метод основан на фундаментальном в теории реляционных баз данных понятии зависимости между атрибутами отношений.
Зависимости между атрибутами
Рассмотрим основные виды зависимостей между атрибутами отношений: функциональные, транзитивные и многозначные.
Понятие функциональной зависимости является базовым, так как на его основе формулируются определения всех остальных видов зависимостей.
Атрибут В функционально зависит от атрибута А, если каждому значению А соответствует в точности одно значение В. Математически функциональная зависимость В от А обозначается записью А—>В. Это означает, что во всех кортежах с одинаковым значением атрибута А атрибут В будет иметь также одно и то же значение. Отметим, что А и В могут быть составными - состоять из двух и более атрибутов.
Функциональная взаимозависимость. Если существует функциональная зависимость вида А->В и В-»А, то между А и В имеется взаимно однозначное соответствие, или функциональная взаимозависимость. Наличие функциональной взаимозависимости между атрибутами А и В обозначим как А<->В или В<->А.
Если отношение находится в 1НФ, то все не ключевые атрибуты функционально зависят от ключа с различной степенью зависимости.
Частичной зависимостью (частичной функциональной зависимостью) называется зависимость не ключевого атрибута от части составного ключа. В рассматриваемом отношении атрибут ДОЛЖН находится в функциональной зависимости от атрибута ФИО, являющегося частью ключа. Тем самым атрибут ДОЛЖН находится в частичной зависимости от ключа отношения.
Альтернативным вариантом является полная функциональная зависимость неключевого атрибута от всего составного ключа. Атрибут С зависит от атрибута А транзитивно (существует транзитивная зависимость), если для атрибутов А, В, С выполняются условия А—>В и В—>С, но обратная зависимость отсутствует.
В отношении R атрибут В многозначно зависит от атрибута А, если каждому значению А соответствует множество значений В, не связанных с другими атрибутами из R.
Многозначные зависимости могут быть «один ко многим» (1:М), «многие к одному» (М: 1) или «многие ко многим» (М:М), обозначаемые соответственно: А=>В, А<=В и А<=>В.
Взаимно независимые атрибуты. Два или более атрибута называются взаимно независимыми, если ни один из этих атрибутов не является функционально зависимым от других атрибутов.
В случае двух атрибутов отсутствие зависимости атрибута А от атрибута В можно обозначить так: А-.->В. Случай, когда А-.->В и B-i->A, можно обозначить А-.=В.
Выявление зависимостей между атрибутами
Выявление зависимостей между атрибутами необходимо для выполнения проектирования БД методом нормальных форм, рассматриваемого далее.
Основной способ определения наличия функциональных зависимостей — внимательный анализ семантики атрибутов. Для каждого отношения существует, но не всегда, определенное множество функциональных зависимостей между атрибутами. Причем если в некотором отношении существует одна или несколько функциональных зависимостей, можно вывести другие функциональные зависимости, существующие в этом отношении.
2. Язык SQL. Операторы отрицания. IS NOT NULL NOT BETWEEN NOT IN NOT LIKE NOT EXISTS NOT UNIQUE. Упорядочение данных. Предложение ORDER BY.
Оператор отрицания
Для каждого из рассматриваемых операторов может быть выполнена операция отрицания, меняющая результат выполнения оператора на противоположный. Для реализации этой используется оператор NOT. Ниже приведены примеры использования этого оператора с логическими операторами:
IS NOT NULL NOT BETWEEN NOT IN NOT LIKE NOT EXISTS NOT UNIQUE
БИЛЕТ 13
1. Продукционные экспертные системы. Структура.
2. Язык SQL. Использование вычисляемых полей. Арифметические операторы,
математические функции. Псевдонимы полей
1. Продукционные экспертные системы. Структура.
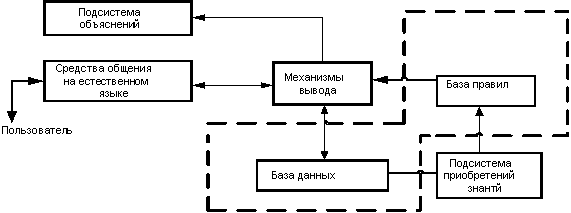
Продукционная система включает три основных составляющих: базу правил, база данных и механизм вывода. В дополнение к ним для поддержки работы системы и реализации интеллектуального взаимодействия с пользователем в нее обычно входят еще и подсистема приобретения знаний, средства общения на естественном языке, а также подсистема объяснения.
 |
2. Использование вычисляемых полей. Арифметические операторы, математические функции, псевдонимы полей.
Использование вычисляемых полей
Язык SQL позволяет создавать вычисляемые поля в тексте запроса. Для реализации этой функции в запросе просто приводится выражение, в котором используются арифметические и математические операторы, а также имена полей в качестве переменных. В результате выполнения запроса с вычисляемыми полями выборка будет содержать не только ту информацию, которая содержится в таблицах базы данных, но и дополнительную информацию, полученную в результате вычисления заданного выражения.
При создании вычисляемого поля можно использовать следующие арифметические операторы:
· оператор сложения «+»;
· оператор вычитания «-»;
· оператор умножения «*»;
· оператор деления «/».
Приоритет перечисленных операторов соответствует общепринятому: умножение и деление, затем сложение и вычитание. Порядком выполнения операторов можно управлять с помощью круглых скобок.
Рассмотрим пример использования вычисляемых полей. Для этого на основании данных таблицы «Продажи» вычислим для каждого товара сумму денег, полученных за проданный товар (произведение цены на количество проданного товара), и сумму, на которую заказано товаров (произведение цены на количество заказанного товара), а также разность между ними:
SELECT [Код товара]. Цена. Заказано. Продано. Цена*Продано. Цена*3аказано. Цена*Заказано-Цена*Продано FROM Продажи
Данный запрос содержит три вычисляемых поля.
Кроме арифметических операторов допускается использование ряда математических функций, например:
· ABS — вычисление абсолютного значения;
· ROUND — округление;
· SQR — извлечение квадратного корня;
· ЕХР — экспонента;
· LOG — натуральный логарифм;
· SIN, COS, TAN — тригонометрические функции.
Арифметические операторы и математические функции можно использовать как в списке полей после ключевого слова SELECT, так и в предложении, задающем условие выборки (WHERE).
Псевдонимы полей
В запросах SQL можно изменять имена полей. Задаваемые при этом новые имена называются псевдонимами (aliases). Их удобно применять при задании в запросе вычисляемых полей. С помощью псевдонимов этим полям можно присваивать осмысленные имена. Псевдоним помещается после имени поля или после вычисляемого выражения через ключевое слово AS.
В качестве примера воспользуемся предыдущим запросом, задав в нем псевдонимы для вычисляемых полей:
SELECT [Код товара]. Цена. Заказано, Продано. Цена*Продано AS [Сумма продажи]. Цена*3аказано AS [Сумма заказа]. Цена*Заказано-Цена*Продано AS [Разность] FROM Продажи;
БИЛЕТ 14
1. Механизм вывода (интерпретатор правил)
2. Язык SQL Функции агрегирования: COUNT, SUM, МАХ, AVG, опция DISTINCT.
Группировка данных, предложение GROUP BY
1. Механизм вывода (интерпретатор правил).
Механизм вывода (интерпретатор правил) выполняет две функции: во-первых, просмотр существующих фактов из базы данных и правил из базы знаний и добавление (по мере возможности) в базу данных новых фактов и, во-вторых, определение порядка просмотра и применения правил. Этот механизм управляет процессом консультации, сохраняя для пользователя информацию о полученных заключениях, и запрашиваем у него информацию, когда для срабатывания очередного правила в базе данных оказывается недостаточно данных.
Механизм вывода включает в себя два компонента - один из них реализует собственно вывод, другой управляет этим процессом. Компонент вывода выполняет первую задачу, просматривая имеющиеся правила и факты из рабочей памяти и добавляя в последнюю новые факты при срабатывании какого-нибудь правила. . ,тыкнно же часть заанных на знаниях, механизм вывода представляет собой небольшой по объёму программу. Управляющий компонент определяет порядок применения правил. Рассмотрим каждый из этих компонентов более подробно.
Компонент вывода. Его действие основано на применении правила вывода, суть которого состоит в следующем: пусть известно, что истинно утверждение А и существует правило вида "ЕСЛИ А, ТО В", тогда утверждение В также истинно. Правила срабатывают, когда находятся факты, удовлетворяющие их левой части: если истинна посылка, то должно быть истинно и заключение.
Компонент вывода должен обладать способностью функционировать в условиях недостатка информации.
Управляющий компонент. Этот компонент определяет порядок применения правил, а также устанавливает, имеются ли еще факты, которые могут быть изменены в случае продолжения консультации (вспомните обсуждение монотонного и немонотонного выводов). Управляющий компонент выполняет четыре функции:
- Сопоставление - образец правила сопоставляется с имеющимися фактами. Выбор - если в конкретной ситуации могут быть применены сразу несколько правил, то из них выбирается одно, наиболее подходящее, по заданному критерию (разрешение конфликта). Срабатывание - если образец правила при сопоставлении совпал с какими-либо фактами из рабочей памяти, то правило срабатывает. Действие - база данных подвергается изменению путем добавления в нее заключения сработавшего правила. Если в правой части правила содержится указание на какое-либо действие, то оно выполняется (как, например, в системах обеспечения безопасности информации).
Интерпретатор продукций работает циклически. В каждом цикле он просматривает все правила, чтобы выявить среди них те, посылки которых совпадают с известными на данный момент фактами из рабочей памяти. Интерпретатор определяет также порядок применения правил. После выбора правило срабатывает, его заключение заносится в рабочую память, и затем цикл повторяется сначала.
В одном цикле может сработать только одно правило. Если несколько правил успешно сопоставлены с фактами, то интерпретатор производит выбор по определенному критерию единственного правила, которое и сработает в данном цикле.
Подсистема объяснения
Компонент экспертной системы, который отвечает на вопросы пользователя о том, как именно получено решение, называется подсистемой объяснения. Во время проведения консультации эта подсистема должна быть способна в любой момент привести обоснования принятого решения.
Продукционная система или система или система, основанная на правилах, работает циклически. В каждом цикле продукции (правила) из базы знаний просматриваются интерпретатором правил в определенном порядке, который устанавливается его управляющим компонентом. Если обнаруживается правило, посылка которого при сопоставлении совпала с некоторыми фактами из базы данных, то правило срабатывает и его заключение добавляется в базу данных. Затем цикл повторяется. Цикл имеет четыре фазы: сопоставление, выбор (разрешение конфликта), срабатывание и выполнение действия (изменение состояния базы данных).
БИЛЕТ 15
1. Метод сущность – связь. Этапы проектирования;
2. Язык SQL Операторы сравнения и объединения:
1.Метод сущность – связь, этапы проектирования.
Процесс проектирования базы данных является итерационным - допу( кающим возврат к предыдущим этапам для пересмотра ранее принятых решений и нключает следующие этапы:
1. Выделение сущностей и связей между ними.
2. Построение диаграмм ER-типа с учетом всех сущностей и их связей.
3. Формирование набора предварительных отношений с указанием пре/ полагаемого первичного ключа для каждого отношения и использованием диаграмм ER-типа.
4. Добавление неключевых атрибутов в отношения.
5. Приведение предварительных отношений к нормальной форме Боне а-Кодда, например, с помощью метода нормальных форм.
6. Пересмотр ER-диаграмм в следующих случаях:
• некоторые отношения не приводятся к нормальной форме Бойса-Ко тда;
• некоторым атрибутам не находится логически обоснованных мест в предварительных отношениях.
После преобразования ER-диаграмм осуществляется повторное выполнение предыдущих этапов проектирования (возврат к этапу 1).
Одним из узловых этапов проектирования является этап формирования отношений. Рассмотрим процесс формирования предварительных отношений, i'-оставляющих первичный вариант схемы БД.
2. Операторы сравнения и объединения.
Операторы сравнения
Операторы сравнения используются в запросах SQL для наложения ограничений на информацию, возвращаемую в результате выполнения запроса. Это типичные операторы, существующие во всех алгоритмических языках:
· оператор равенства «=» используется для отбора записей, в которых значение определенного поля точно соответствует заданному;
· оператор неравенства «<>» возвращает значение true, если значение поля не совпадает с заданным значением;
· операторы «меньше» и «больше» (соответственно, «<» и «>») позволяют отбирать записи, в которых значение определенного поля меньше или больше некоторой заданной величины;
· операторы «меньше или равно» и «больше или равно» (соответственно, «<=» и «>=») представляют собой объединение операторов «меньше» и «равно», «больше» и «равно». В отличие от операторов «<» и «>» операторы «<=» и «>=» возвращают значение true, если значение поля совпадает с заданным значением.
В качестве примера рассмотрим запрос, выбирающий из таблицы «Товары» только те записи, категория товаров в которых равна 2:
SELECT * FROM Товары WHERE Категория-2
Операторы объединения
Часто при написании запроса на выборку данных требуется задать сложное условие, для которого недостаточно использовать только один оператор. В этом случае используется объединение нескольких условий с помощью специальных операторов. В SQL определены два таких оператора:
· Оператор AND используется в тех случаях, когда необходимо отобрать записи, соответствующие нескольким условиям. Причем для каждой записи, включаемой в результат выборки, должны выполняться все заданные ограничения. Оператор AND объединяет несколько условий путем выполнения операции логического умножения результатов всех заданных ограничений. Результат true, соответственно, будет получен только в том случае, если все объединяемые условия принимают значение true.
· Оператор OR выполняет операцию логического сложения результатов всех заданных условий. При использовании данного оператора запись включается в результирующую выборку в случае выполнения хотя бы одного из заданных ограничений.
При использовании операторов объединения каждое логическое выражение следует заключать в круглые скобки. Для примера произведем выборку данных о товарах, цена которых больше 50, но меньше 1000:
SELECT *
FROM Товары
WHERE (Цена>50) AND (Цена<1000)
Синтаксические правила использования оператора OR такие же, как и для оператора AND. Следующий запрос:
SELECT *
FROM Товары
WHERE (Цена<50) OR (Цена>1000)
БИЛЕТ 16
1. Представления знаний в виде фреймов.
2. Язык SQL Подзапросы Составные запросыв Операторы UNION, UNION ALL
Упорядочение и группировка данных в составных запросах.
1. Представление знаний в виде фреймов.
Представление знаний с использованием фреймов
В области искусственного интеллекта термин фрейм относится к специальному методу представления общих концепций и ситуаций. Марвин Минский, первый, кто предложил идею фреймов, описывает его следующим образом:
«Фрейм — это структура данных, представляющая стереотипную ситуацию, вроде нахождения внутри некоторого рода жилой комнаты, или сбора на вечеринку по поводу дня рождения ребенка. К каждому фрейму присоединяется несколько видов информации. Часть этой информации — о том, как использовать фрейм. Часть о том, чего можно ожидать далее. Часть о том, что следует делать, если эти ожидания не подтвердятся.»
Фрейм по своей организации во многом похож на семантическую сеть (фактически мы рассматриваем и семантические сети, и фреймы как системы, основанные на фреймах). Фрейм является сетью узлов и отношений, организованных иерархически, где верхние узлы представляют общие понятия, а нижние узлы более частные случаи этих понятий.
Пока что это выглядит точно так же, как семантическая сеть. Но в системе, основанной на фреймах, понятие в каждом узле определяется набором атрибутов (например, имя, цвет, размер) и значениями этих атрибутов (например, Смит, красный, маленький), а атрибуты называются слотами. Каждый слот может быть связан с процедурами (произвольными машинными программами), которые выполняются, когда информация в слотах (значения атрибутов) меняется.
С каждым слотом можно связать любое число процедур. Три типа процедур, чаще всего связываемых со слотами, перечислены ниже:
Процедура если добавлено | Выполняется, когда новая информация помещается в слот. |
Процедура если удалено | Выполняется, когда информация удаляется из слота. |
Процедура если нужно | Выполняется, когда запрашивается информация из слота, а он пустой. |
Эти процедуры могут следить за приписыванием информации к данному узлу и проверять, что при изменении значения производятся соответствующие действия. Как ясно из их структуры, системы, основанные на фреймах, хороши в тех предметных областях, где ожидания относительно формы и содержания данных играют важную роль.
2. Язык SQL Подзапросы Составные запросыв Операторы UNION, UNION ALL
Упорядочение и группировка данных в составных запросах.
Подзапросы
Подзапрос представляет собой запрос, помещенный внутри другого запроса. Подзапросы применяются для получения данных, которые затем используются другим запросом.
Запрос, содержащий подзапрос, называется сложным. В процессе его выполнения сначала выполняется подзапрос, а затем — основной запрос. При создании сложного запроса необходимо следовать следующему набору правил:
· подзапросы должны заключаться в круглые скобки;
· предложение ORDER BY может быть использовано только в основном запросе;
· подзапросы, возвращающие более одной записи, могут использоваться только
· с многозначными операторами;
· в основном запросе нельзя использовать оператор BETWEEN.
Объединение запросов
Язык SQL позволяет объединять несколько запросов с помощью специальных операторов. Запросы, включающие в себя несколько операторов SELECT, принято называть составными.
Составные запросы формируют один набор данных на основе результатов, полученных при выполнении каждого отдельного запроса, входящего в объединение. Во многих случаях составные запросы целесообразно использовать вместо простых запросов со сложным условием выборки. Это связано с тем, что разбиение сложного условия на несколько более простых запросов делает текст запроса более понятным. Как правило, проще написать составной запрос, чем аналогичный простой запрос со сложным условием отбора данных.
Для объединения запросов наиболее часто используются операторы UNION и UNION ALL.
При объединении запросов, независимо от типа используемых операторов объединения, необходимо следовать следующим правилам:
· каждый из запросов, входящих в объединение, должен возвращать одинаковое
· количество полей (в том числе и вычисляемых);
· типы полей, возвращаемых в результате выполнения каждого запроса, должны
· совпадать.
Оператор UNION
При использовании оператора UNION результаты выполнения отдельных запросов объединяются. При этом дублирующие друг друга записи исключаются из результирующего набора данных.
SELECT * FROM Товары WHERE Цена<200 UNION SELECT * FROM Товары WHERE Цена>=2000
Оператор UNION ALL
Данный оператор аналогичен оператору UNION, за исключением того, что в результирующую выборку включаются дублирующие записи. Если в предыдущем примере заменить UNION на UNION ALL, то результат не изменится, так как в нем не содержится дублирующих записей. Однако если задать запрос таким образом, что одни и те же записи попадут в результаты обоих запросов, входящих в объединение, то в результирующей выборке они также будут присутствовать два раза. Например, при выполнении запроса:
SELECT * FROM Товары WHERE Цена>100 UNION ALL SELECT * FROM Товары WHERE Цена<1000
Упорядочение и группировка данных в составных запросах
В составном запросе для упорядочения данных допускается использован предложения ORDER BY. Независимо от того, сколько запросов входит в объед нение, можно использовать только одно предложение ORDER BY. Для указан; полей, по которым производится сортировка, в этом предложении допускает использование как имен полей, так и их порядковых номеров в списке операт pa SELECT.
В отличие от ORDER BY, предложение GROUP BY можно применять в каждом из запр сов, входящих в объединение. Вместе с GROUP BY допускается применение операт pa HAVING. Предложение GROUP BY можно применять и для группировки результат выполнения составного запроса.
БИЛЕТ 17
1. Представления знаний в виде семантической сети.
2. Язык SQL. Работа с представлениями данных Создание, удаление представлений.
1. Представление знаний в виде семантической сети.
Термин семантическая сеть применяется для описания метода представления знаний, основанного на сетевой структуре. Семантические сети были первоначально разработаны для использования их в качестве психологических моделей человеческой памяти, но теперь это стандартный метод представления знаний в ИИ и в экспертных системах. Семантические сети состоят из точек, называемых узлами, и связывающих их дуг, описывающих отношения между узлами. Узлы в семантической сети соответствуют объектам, концепциям или событиям. Дуги могут быть определены разными методами, зависящими от вида представляемых знаний. Обычно дуги, используемые для представления иерархии, включают дуги типа isa (является) и has-part (имеет часть). Семантические сети, используемые для описания естественных языков, используют дуги типа агент, объект, реципиент.
Остальное в файле «представл. знаний в ЭС. doc».
2. Язык SQL. Работа с представлениями данных. Создание, удаление представлений.
Работа с представлениями данных
Представление (view) — это предопределенный запрос, который хранится в ба данных. Представление можно рассматривать как виртуальную таблицу, которая формируется из одной или нескольких реальных таблиц базы данных (и/или ранее созданных представлений). Работа с представлением после его создания полностью аналогична работе с таблицей. Представления обычно используются в дв случаях:
для объединения данных, хранящихся в нескольких таблицах (разбиение таблицы обычно производится при нормализации базы данных) с целью представления в удобном для просмотра и редактирования виде;
для разграничения доступа к информации — с помощью представлений можно разрешить пользователю доступ только к части информации, хранящейся в таблице базы данных.
Создание представлений
Для создания представления используется оператор CREATE VIEW. Поскольку представление всегда создается на основе таблиц и/или ранее созданных представлений, то оператор CREATE VIEW отличается от оператора создания таблицы — вместо указания имен и типов полей данный оператор должен содержать запрос:
CREATE VIEW имя_представления AS SELECT...
После создания представления с ним можно работать как с обычной таблицей. Например, можно вызвать следующий запрос:
SELECT * FROM Test
При создании представлений допускается использование вычисляемых полей.
Удаление представлений
Для удаления представлений используется оператор DROP VIEW, синтаксис которого представлен ниже:
DROP VIEW viewjiame
Команды, удаляющие созданные нами представления, имеют следующий вид:
DROP VIEW Test DROP VIEW Test2
БИЛЕТ 18
1. Метод сущность – связь;
2. Язык SQL. Использование параметров в SQL-запросах.
1. Метод сущность-связь.
См. билет 10, 11, 15.
2. Язык SQL. Использования параметров в SQL-запросах.
Использование параметров в SQL-запросах
При задании SQL-запроса можно использовать параметры — переменные, включаемые в оператор SQL, значения которых определяются во время выполнения программы. Использование параметров в значительной степени повышает гибкость SQL-запросов, обеспечивая возможность запрашивать у пользователя численные значения критериев отбора данных.
Запросы с параметрами поддерживаются как в классе TQuery, так и в классе TADOQuery, причем свойства и методы, используемые при работе с параметрами, имеют много общего.
Параметры задаются в тексте SQL-запроса. Для определения параметра перед его именем указывается символ «:», например:
SELECT *
FROM tablejname
WHERE fieldl<:PARAMl
В данном запросе задан один параметр с именем PARAM1.
После ввода текста запроса в свойство SQL автоматически производится заполнение массива в свойстве Parameters (Params). Одновременно значение свойства Parameters. Count (Params. Count) устанавливается равным количеству заданных в запросе параметров. Последовательность заполнения массива Parameters (Params) соответствует порядку следования параметров в тексте запроса.
Свойства определенных в SQL-запросе параметров доступны для редактирования как во время разработки, так и во время выполнения программы:
· для редактирования свойств параметров во время разработки программы используется специальный редактор, который вызывается щелчком на кнопке с многоточием в поле ввода свойства Parameters (Params) в инспекторе объектов;
· для задания значения параметра во время разработки программы вначале необходимо определить его тип с помощью свойства DataType класса TParameter (TParam);
· для доступа к свойствам параметров SQL-запроса во время выполнения программы можно либо воспользоваться свойством Items класса TParameters (TParams), либо методом ParamByName этого же класса. Свойство Items предоставляет доступ к объектам параметров по их порядковым номерам, что не очень удобно. Обычно гораздо проще обращаться к параметрам по их именам с помощью метода ParamByName, возвращающего объект параметра, имя которого задается в качестве аргумента при вызове данного метода;
· в зависимости от значения свойства ParamCheck при изменении текста запроса во время выполнения программы список параметров в свойстве Parameters (Params) может либо автоматически обновляться (ParamCheck = true), либо оставаться прежним (ParamCheck = false).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
