

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
1.
2. Виды структур баз данных.
Базой данных является специальным образом организованные один либо группа файлов.
Для работы с ними используется Система Управления Базой Данных (СУБД).
БД определена по схеме, не зависящей от программ, которые к ней обращаются. БД характеризуется ее концепцией - совокупностью требований, определяемых представлениями пользователей о необходимой им информации.
На основе БД создаются разнообразные информационные системы.
Информационные системы предназначены для хранения и обработки больших объемов информации. Работающая информационная система подразумевает использование модели предметной области. Модель формируют объекты и отношения между ними.
По модели представления данных БД классифицируются:
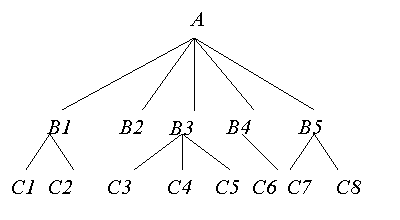
§ Иерархические. Простейший пример – система FAT и XML. Информация хранится в древовидной стр-ре и доступ осуществляется через путь. Недостатки – долгий поиск при неизвестном пути и плохая устойчивость к повреждениям стр-ры. Такие базы данных могут быть представлены как дерево, состоящее из объектов различных уровней (узлов) и связей между ними (ветвей). Верхний уровень занимает один объект (корень), второй — объекты второго уровня и т. д. Иерарх. стр-ра всегда удовлетворяет след. условиям: 1. Иерархия начинается с корневого узла. 2. Каждый узел состоит из одного или нескольких атрибутов 3. На низших уровнях могут находиться зависимые узлы. Они могут добавляться в вертикальном и горизонтальном направлениях 4. Каждый узел уровня 2 соединен только с одним узлом уровня 1 5.Исходный узел может иметь один или более порожденных узлов 6. Доступ к каждому узлу происходит через исходный узел
|
|
|
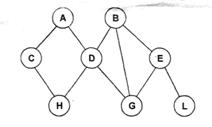
§ Сетевые. Простейший пример – интернетВ сетевой структуре данных потомок может иметь любое число предков. Сетевая БД состоит из набора записей(экземпляров каждого типа из заданного в схеме БД набора типов записи) и набора связей(экземпляров каждого типа из заданного набора типов связи) между этими записями. Недостаток – очень сложный поиск, возможность неполного представления информации. Преимущество – очень легко добавлять любую информацию, высокая стабильность.
§ Реляционные. База данных, представляющая собой набор двумерных простых таблиц. Недостатки – хранение только однородной информации, сложности в добавлении новых стр-р, информация должна быть всегда в нужной степени абстрагирована. Преимущество – высокая скорость поиска, стабильность, обилие софта для поддержки и разработки, возможность использования для широкого круга задач.
Каждая таблица имеет свою структуру, которую образуют следующие элементы:
- описание полей;
- ключи;
- индексы;
- ограничения на значения полей;
- ограничения ссылочной целостности между таблицами;
- права доступа.
В терминологии реляционной модели таблица называется отношением. Столбец таблицы – атрибут, домен – множество значений атрибута, строка таблицы – кортеж. Свойства отношения: 1. Отсутствуют одинаковые кортежи 2. Порядок строк, столбцов несуществен 3. Все значение имеют атомарный характер.
Процесс выявления объектов и их взаимосвязей с помощью концепции рел. модели называется нормализацией, теория норм-ии основана на том, что определенные наборы отношений в процессе выполнения обновлений обнаруживают лучшие свойства по сравнению с любыми другими наборами отношений, содержащими те же данные. Связь между таблицами осуществляется за счет того, что они имеют общие атрибуты.
§ Объектно-ориентированные. База данных, в которой данные оформлены в виде моделей объектов, включающих прикладные программы, которые управляются внешними событиями. Любая сущность реального мира в объектно-ориентированных языках и системах моделируется в виде объекта. Каждый объект имеет состояние и поведение. Состояние объекта - набор значений его атрибутов. Значение атрибута объекта - это тоже некоторый объект или множество объектов. К достоинствам ООМД можно отнести широкие возможности моделирования предметной области, выразительный язык запросов и повышенную производительность. Эти модели обычно применяются для сложных предметных областей, для моделирования которых не хватает функциональности реляционной модели (например, систем автоматизации проектирования, издательских систем и т. п.). Среди недостатков ООМД следует отметить отсутствие универсальной модели, недостаток опыта создания и эксплуатации ООБД, сложность использования и недостаточность средств защиты данных.
3. Понятие реляционных баз данных и требования к ним.
(Общую инф-ю смотри в вопросе 1)
База данных, представляющая собой набор двумерных простых таблиц, называется реляционной.
В терминологии реляционной модели таблица называется отношением.
Основными понятиями реляционных баз данных являются тип данных, домен, атрибут, кортеж, первичный ключ и отношение.
Любые данные, используемые в программировании, имеют свои типы данных. Типы данных делятся на три группы: простые типы данных; структурированные типы данных; ссылочные типы данных. Простые, или атомарные, типы данных не обладают внутренней структурой. Данные такого типа называют скалярами. К простым типам данных относятся следующие типы: логический; строковый; численный. Различные языки программирования могут расширять и уточнять этот список, добавляя такие типы как: целый; вещественный; дата; время; денежный; перечислимый; интервальный. Понятие атомарности относительно. Так, строковый тип данных можно рассматривать как одномерный массив символов, а целый тип данных - как набор битов. Важно лишь то, что при переходе на такой низкий уровень теряется семантика (смысл) данных. Если строку, выражающую, например, фамилию сотрудника, разложить в массив символов, то при этом теряется смысл такой строки как единого целого.
Структурированные типы данных предназначены для задания сложных структур данных. Структурированные типы данных конструируются из составляющих элементов, называемых компонентами, которые, в свою очередь, могут обладать структурой. В качестве структурированных типов данных можно привести массивы. Общим для структурированных типов данных является то, что при работе с массивами или записями можно манипулировать массивом или записью и как с единым целым (создавать, удалять, копировать целые массивы или записи), так и поэлементно. Для структурированных типов данных есть специальные функции - конструкторы типов, позволяющие создавать массивы или записи из элементов более простых типов.
Ссылочный тип данных (указатели) предназначен для обеспечения возможности указания на другие данные. Ссылочный тип данных предназначен для обработки сложных изменяющихся структур, например деревьев, графов, рекурсивных структур. Собственно, для реляционной модели данных тип используемых данных не важен.
Требование, чтобы тип данных был простым, в реляционных операциях не должна учитываться внутренняя структура данных. Должны быть описаны действия, которые можно производить с данными как с единым целым, например, данные числового типа можно складывать, для строк возможна операция конкатенации и т. д.и С этой точки зрения, если рассматривать массив, например, как единое целое и не использовать поэлементных операций, то массив можно считать простым типом данных. Более того, можно создать свои, сколь угодно сложные типы данных, описать возможные действия с этими типами данных, и, если в операциях не требуется знание внутренней структуры данных, то такие типы данных также будет простым с точки зрения реляционной теории.
В реляционной модели данных с понятием тип данных тесно связано понятие домена, которое можно считать уточнением типа данных.
Домен - это семантическое понятие. Домен можно рассматривать как подмножество значений некоторого типа данных имеющих определенный смысл. Домен характеризуется следующими свойствами: имеет уникальное имя (в пределах базы данных); определен на некотором простом типе данных или на другом домене; может иметь некоторое логическое условие, позволяющее описать подмножество данных, допустимых для данного домена; несет определенную смысловую нагрузку.
Например, домен D, имеющий смысл "возраст сотрудника" можно описать как следующее подмножество множества натуральных чисел: D={n}
![]()
Если тип данных можно считать множеством всех возможных значений данного типа, то домен напоминает подмножество в этом множестве.
Отличие домена от понятия подмножества состоит именно в том, что домен отражает семантику, определенную предметной областью. Может быть несколько доменов, совпадающих как подмножества, но несущие различный смысл. Например, домены "Вес детали" и "Имеющееся количество" можно одинаково описать как множество неотрицательных целых чисел, но смысл этих доменов будет различным, и это будут различные домены.
Отношения
Фундаментальным понятием реляционной модели данных является понятие отношения. Атрибут отношения есть пара вида <Имя_атрибута : Имя_домена>.
Имена атрибутов должны быть уникальны в пределах отношения. Часто имена атрибутов отношения совпадают с именами соответствующих доменов.
Отношение ![]() , определенное на множестве доменов
, определенное на множестве доменов ![]() (не обязательно различных), содержит две части: заголовок и тело.
(не обязательно различных), содержит две части: заголовок и тело.
Заголовок отношения содержит фиксированное количество атрибутов отношения:
![]()
Тело отношения содержит множество кортежей отношения. Каждый кортеж отношения представляет собой множество пар вида <Имя_атрибута : Значение_атрибута>:
![]()
таких что значение ![]() атрибута
атрибута ![]() принадлежит домену
принадлежит домену ![]()
Отношение обычно записывается в виде:
![]() ,
,
или короче
![]() ,
,
или просто
![]() .
.
Число атрибутов в отношении называют степенью отношения.
Реляционной базой данных называется набор отношений.
Схемой реляционной базы данных называется набор заголовков отношений, входящих в базу данных.
Хотя любое отношение можно изобразить в виде таблицы, нужно четко понимать, что отношения не являются таблицами. Это близкие, но не совпадающие понятия.
Термины, которыми оперирует реляционная модель данных, имеют соответствующие "табличные" синонимы: база данных – набор таблиц, схема базы данных – набор заголовков таблиц, Отношение – таблица, Заголовок отношения – Заголовок таблицы, Тело отношения – тело таблицы, атрибут отношения – наименование столбца таблицы, кортеж отношения – строка таблицы, Степень отношения – кол-во столбцов, мощность отношения – кол-во строк, домены и типы данных – типы данных в ячейках.
Свойства отношений
Свойства отношений непосредственно следуют из приведенного выше определения отношения. В этих свойствах в основном и состоят различия между отношениями и таблицами.
1. В отношении нет одинаковых кортежей.
2. Кортежи не упорядочены (сверху вниз). Причина та же - тело отношения есть множество, а множество не упорядочено. Это вторая причина, по которой нельзя отождествить отношения и таблицы - строки в таблицах упорядочены.
3. Атрибуты не упорядочены (слева направо). Т. к. каждый атрибут имеет уникальное имя в пределах отношения, то порядок атрибутов не имеет значения. Это также третья причина, по которой нельзя отождествить отношения и таблицы - столбцы в таблице упорядочены. Одно и то же отношение может быть изображено разными таблицами, в которых столбцы идут в различном порядке.
4. Все значения атрибутов атомарны. Это следует из того, что лежащие в их основе атрибуты имеют атомарные значения. Это четвертое отличие отношений от таблиц - в ячейки таблиц можно поместить что угодно - массивы, структуры, и даже другие таблицы.
4. Этапы построения баз данных.
Этапы ЖЦ системы с базой данных:
1.Установление требований. Задачей определения требований является определение, анализ и обсуждение требований с заказчиками. На этом этапе применяются различные методы сбора информации от заказчиков. Результатом этапа установления требований является документ, содержащий изложение требований. Это большей частью текстовый документ с некоторыми неформальными диаграммами и таблицами.
2.Спецификация требований. Этап спецификации требований начинается с того момента, когда разработчики приступают к моделированию требований с использованием определенного метода (например, такого как UML). CASE-средства используются для ввода, анализа и документирования модели. В результате документ описания требований дополняется графическими моделями и отчетами, сгенерированными с помощью CASE-средств. По существу, документ, излагающий требования, заменяется документом, содержащим спецификацию требований.
3.Проектирование архитектуры. Проект архитектуры включает выбор стратегических решений по клиентской и серверной частям системы.
4.Детализированное проектирование. Архитектурный проект описывает программный продукт с точки зрения составляющих его модулей. Детализированный проект описывает каждый модуль. При разработке типичной ИС модули реализуются либо в виде клиентской компоненты, либо серверной компоненты. За первые отвечают проектировщики прикладной части, вторую должны разрабатывать проектировщики баз данных.
5.Реализация. Реализация информационной системы включает инсталляцию приобретенного ПО и программирование ПО, разрабатываемого под заказ. Кроме того, реализация подразумевает осуществление некоторых других важных мероприятии, таких как загрузка тестовых и производственных баз данных, тестирование, обучение пользователем, вопросы, связанные с аппаратным обеспечением, и т. д. Как раз в духе итеративной и наращиваемой разработки проект пользователыких интерфейсов подвергается значительным изменениям на этапе реализации.
6.Интеграция. Интеграция модулей должна быть тщательно спланирована в самом начале жизненного цикла ПО. Программные компоненты, подлежащие отдельной реализации, должны быть идентифицированы на ранних стадиях анализа системы. К этому вопросу необходимо постоянно возвращаться, уточняя детали во время архитектурного проектирования. Порядок реализации должен позволять как можно более плавную наращиваемую интеграцию. (пояснение: на рабоче-крестьянском наращиваемая интеграция – это когда во время разработки появляются новые версии ПО (новые версии=итерации), каждый раз выставляются новые требования и с учетом требований версии корректируются)
7.Сопровождение. Этап сопровождения наступает после успешной передачи заказчику каждого последующего программного модуля и, в конечном счете, всего программного продукта. Сопровождение — не только неотъемлемая часть жизненного цикла ПО, оно составляет его большую часть, если речь идет о времени и усилиях персонала ИТ-подразделений, приходящихся на сопровождение, 67% времени ЖЦ приходится на сопровождение ПО.
Сопровождение состоит из трех различных стадий.
1. Поддержка эксплуатации.
2. Адаптивное сопровождение.
3. Улучшающее сопровождение.
Поддержка эксплуатации связана с рутинными задачами сопровождения, необходимыми для поддержания системы в состоянии готовности к применению пользователями и эксплуатационным персоналом. Адаптивное сопровождение связано с отслеживанием и анализом работы системы, настройкой ее функциональных возможностей применительно к изменениям внешней среды и адаптацией системы для достижения заданной производительности и пропускной способности. Под улучшающим сопровождением понимают перепроектирование и модификацию системы для удовлетворения новых или существенно изменившихся требований.
В конечном итоге продолжение сопровождения системы становится нецелесообразным и ее следует свернуть.
Вообще непонятно что в вопросе нужно, м. б. вообще нужно что-то типа этого:
Разработка, утверждение ТЗ и подборка под него готовых частей Первым делом нужно определить, для чего вообще нужна эта база и четко сформулировать ее задачи Создание предварительного тех. задания на разработку Поиск и анализ уже существующего готового решения других разработчиков По мере уточнения ТЗ начнет формироваться перечень необходимых данных. Зная это, можно определить, какие фактические данные следует сохранять в базе данных и по каким темам распределяются эти данные. Темам должны соответствовать таблицы, а данным — поля (столбцы) в этих таблицах. На основании полученного ТЗ, определяем время разработки в чел/час После окончательного согласования ТЗ с заказчиком – составление и подписание договора обеими сторонами Определение необходимых таблиц и связей между ними, полей таблиц и ключевых полей в БД Согласно ТЗ вся информация разбивается на группы и на минимальные логические компоненты Согласно списку необходимых полей и групп данных создаются требуемые таблицы с соответствующими им полями Определяются ключевые поля таблиц (внутренние и внешние ключи) Устанавливаются связи между таблицами, строится схема данных Таблицы заполняются минимально необходимым для анализа структуры БД объемом демо-данных Проводится анализ полученной структуры БД, исправляются возможные недочеты Проектирование интерфейса приложения Согласно ТЗ и п.2 создаются необходимые объекты базы данных — запросы, формы, отчеты, модули. Проводится анализ (предварительное тестирование) работы приложения и при необходимости исправляются недочеты В случае оказавшейся невозможности реализации каких либо пунктов ТЗ и прочих отступлений от него, этот вопрос уточняется с заказчиком. Тестирование, создание документации, сдача проекта и расчет В случае поэтапной оплаты работы, по мере выполнения п.3 заказчику периодически отдается на изучение, предварительное тестирование и утверждение, отдельные части приложения в демо-режиме, и согласно договору происходит оплата частей проекта. После окончательного создания проекта проводится его полное тестирование Создается документация (справка) на программу При успешном прохождении всех тестов программа отправляется заказчику в демо-режиме для окончательного ознакомления. Производится окончательный расчет согласно договору, после которого заказчику отправляется полная версия программы без каких либо ограничений.4. Уровни проектирования баз данных.
Предметная область - часть реального мира, подлежащая изучению с целью организации управления и, в конечном счете, автоматизации. Предметная область представляется множеством фрагментов, например, предприятие - цехами, дирекцией, бухгалтерией и т. д. Каждый фрагмент предметной области харакетризуется множеством объектов и процессов, использующих объекты, а также множеством пользователей, характеризуемых различными взглядами на предметную область.
В теории проектирования информационных систем предметную область принято рассматривать в виде трех представлений:
1. представление предметной области в том виде, как она реально существует
2. как ее воспринимает человек (имеется в виду проектировщик базы данных)
3. как она может быть описана с помощью символов.
Т. е. говорят, что мы имеем дело с реальностью, описанием (представлением) реальности и с данными, которые отражают это представление.
Данные, используемые для описания предметной области, представляются в виде трехуровневой схемы (так называемая модель ANSI/SPARC):

Внешнее представление (внешняя схема) данных является совокупностью требований к данным со стороны некоторой конкретной функции, выполняемой пользователем. Концептуальная схема является полной совокупностью всех требований к данным, полученной из пользовательских представлений о реальном мире. Внутренняя схема - это сама база данных.
Отсюда вытекают основные этапы, на которые разбивается процесс проектирования базы данных информационной системы:
1. Концептуальное проектирование - сбор, анализ и редактирование требований к данным. Для этого осуществляются следующие мероприятия:
o обследование предметной области, изучение ее информационной структуры
o выявление всех фрагментов, каждый из которых харакетризуется пользовательским представлением, информационными объектами и связями между ними, процессами над информационными объектами
o моделирование и интеграция всех представлений
По окончании данного этапа получаем концептуальную модель, инвариантную к структуре базы данных. Часто она представляется в виде модели "сущность-связь".
2. Логическое проектирование - преобразование требований к данным в структуры данных. На выходе получаем СУБД-ориентированную структуру базы данных и спецификации прикладных программ. На этом этапе часто моделируют базы данных применительно к различным СУБД и проводят сравнительный анализ моделей.
3. Физическое проектирование - определение особенностей хранения данных, методов доступа и т. д.
Различие уровней представления данных на каждом этапе проектирования имеет следующий вид:
Концептуальный уровень (представление аналитика) · сущности · атрибуты · связи |
Логический уровень (представление программиста) · записи · элементы данных · связи между записями |
Физический уровень (представление администратора) · группирование данных · индексы · методы доступа |
5. Примеры используемых баз данных и СУБД.
Система управления базами данных (СУБД) — специализированная программа (чаще комплекс программ), предназначенная для организации и ведения базы данных. Для создания и управления информационной системой СУБД необходима в той же степени, как для разработки программы на алгоритмическом языке необходим транслятор.
Основные функции СУБД
§ управление данными во внешней памяти (на дисках);
§ управление данными в оперативной памяти с использованием дискового кэша;
§ журнализация изменений, резервное копирование и восстановление базы данных после сбоев;
§ поддержка языков БД (язык определения данных, язык манипулирования данными).
Обычно современная СУБД содержит следующие компоненты:
§ ядро, которое отвечает за управление данными во внешней и оперативной памяти и журнализацию,
§ процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода,
§ подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД
§ а также сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
Классификация СУБД
По модели данных
По типу управляемой базы данных СУБД разделяются на:
§ Иерархические (система FAT, Серверы каталогов)
§ Сетевые (интернет)
§ Реляционные (MS Access)
§ Объектно-реляционные ( Oracle Database, Microsoft SQL Server 2005, PostgreSQL)
§ Объектно-ориентированные (IBM Lotus Notes/Domino)
По архитектуре организации хранения данных
§ локальные СУБД (все части локальной СУБД размещаются на одном компьютере)
§ распределенные СУБД (части СУБД могут размещаться на двух и более компьютерах)
По способу доступа к БД
§ Файл-серверные
В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере. Ядро СУБД располагается на каждом клиентском компьютере. Доступ к данным осуществляется через локальную сеть. Синхронизация чтений и обновлений осуществляется посредством файловых блокировок. Преимуществом этой архитектуры является низкая нагрузка на ЦП сервера, а недостатком — высокая загрузка локальной сети.
На данный момент файл-серверные СУБД считаются устаревшими.
Примеры: Microsoft Access (Microsoft Access — реляционная СУБД корпорации Microsoft. Имеет широкий спектр функций, включая связанные запросы, сортировку по разным полям, связь с внешними таблицами и базами данных. Благодаря встроенному языку VBA, в самом Access можно писать приложения, работающие с базами данных. Основные компоненты MS Access:просмотр таблиц; построитель экранных форм; построитель SQL-запросов (язык SQL в MS Access не соответствует стандарту ANSI); построитель отчётов, выводимых на печать.), Borland Paradox.
§ Клиент-серверные
Такие СУБД состоят из клиентской части (которая входит в состав прикладной программы) и сервера. Клиент-серверные СУБД, в отличие от файл-серверных, обеспечивают разграничение доступа между пользователями и мало загружают сеть и клиентские машины. Сервер является внешней по отношению к клиенту программой, и по надобности его можно заменить другим. Недостаток клиент-серверных СУБД в самом факте существования сервера (что плохо для локальных программ — в них удобнее встраиваемые СУБД) и больших вычислительных ресурсах, потребляемых сервером.
Примеры: Firebird, Interbase, MS SQL Server, Sybase, Oracle, PostgreSQL, MySQL, ЛИНТЕР.
§ Встраиваемые
Встраиваемая СУБД — библиотека, которая позволяет унифицированным образом хранить большие объёмы данных на локальной машине. Доступ к данным может происходить через SQL либо через особые функции СУБД. Встраиваемые СУБД быстрее обычных клиент-серверных и не требуют установки сервера, поэтому востребованы в локальном ПО, которое имеет дело с большими объёмами данных (например, геоинформационные системы).
Примеры: OpenEdge, SQLite, BerkeleyDB, один из вариантов Firebird, один из вариантов MySQL, Sav Zigzag, Microsoft SQL Server Compact, ЛИНТЕР.
6. Виды нормализации (1-3-нормальная форма).
Нормальная форма(НФ) — свойство отношения в реляционной модели данных, характеризующее его с точки зрения избыточности, которая потенциально может привести к логически ошибочным результатам выборки или изменения данных. Нормальная форма определяется как совокупность требований, которым должно удовлетворять отношение.
Процесс преобразования базы данных к виду, отвечающему нормальным формам, называется нормализацией. Нормализация предназначена для приведения структуры базы данных к виду, обеспечивающему минимальную избыточность, то есть нормализация не имеет целью уменьшение или увеличение производительности работы или же уменьшение или увеличение объёма БД. Конечной целью нормализации является уменьшение потенциальной противоречивости хранимой в БД информации.
Устранение избыточности производится, как правило, за счёт декомпозиции отношений таким образом, чтобы в каждом отношении хранились только первичные факты (то есть факты, не выводимые из других хранимых фактов).
Всего в реляционной теории насчитывается 6 НФ:
1. 1-я НФ (обычно обозначается также 1НФ).
2. 2НФ.
3. 3НФ.
4. НФ Бойса-Кодда (НФБК).
5. 4НФ.
6. 5НФ.
1НФ
Таблица находится в первой нормальной форме, если каждый её атрибут атомарен. Под выражением «атрибут атомарен» понимается, что атрибут может содержать только одно значение. Таким образом, не существует 1NF таблицы, в полях которых могут храниться списки значений. Для приведения таблицы к 1NF обычно требуется разбить таблицу на несколько отдельных таблиц.
Замечание: в реляционной модели отношение всегда находится в 1 (или более высокой) нормальной форме в том смысле, что иные отношения не рассматриваются в реляционной модели. То есть само определение понятия отношение заведомо подразумевает наличие 1NF.
Пример
Сотрудник | Номер телефона |
Сотрудник | Номер телефона |
Атрибут атомарен, если его значение теряет смысл при любом разбиении на части или переупорядочивании. И наоборот, если какой-либо способ разбиения на части не лишает атрибут смысла, то атрибут неатомарен. Одно и то же значение может быть атомарным или неатомарным в зависимости от смысла этого значения. Например, значение «4286» является
§ атомарным, если его смысл — «пин-код кредитной карты» (при разбиении на части или переупорядочивании смысл теряется)
§ неатомарным, если его смысл — «четные цифры» (при разбиении на части или переупорядочивании смысл не теряется)
2НФ
Таблица находится во второй нормальной форме, если она находится в первой нормальной форме, и при этом любой её атрибут, не входящий в состав первичного ключа, функционально полно зависит от первичного ключа. Функционально полная зависимость означает, что атрибут функционально зависит от всего первичного составного ключа, но при этом не находится в функциональной зависимости от какой-либо из входящих в него атрибутов(частей). Или другими словами: в 2NF нет неключевых атрибутов, зависящих от части составного ключа (+ выполняются условия 1NF).
Пример
Пример приведения таблицы ко второй нормальной форме
Пусть Начальник и Должность вместе образуют первичный ключ в такой таблице:
Начальник | Должность | Зарплата | Наличие компьютера |
Гришин | Кладовщик | 20000 | Нет |
Васильев | Программист | 40000 | Есть |
Васильев | Кладовщик | 25000 | Нет |
Зарплату сотруднику каждый начальник устанавливает сам, но её границы зависят от должности. Наличие же компьютера у сотрудника зависит только от должности, то есть зависимость от первичного ключа неполная.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 |
