

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
По принципу работы запоминающих элементов ОЗУ ЦВМ делят на:
- динамические ОЗУ, где для сохранения записанной информации необходимо периодическое проведение процесса регенерации, во время которого происходит восстановление хранимой информации;
- статические ОЗУ, где записанная в запоминающих элементах информация хранится в течение всего времени, пока к ним приложено напряжение питания, вне зависимости от частоты обращения.
В большинстве случаев ЗУ ЭВМ строятся по иерархическому принципу, при котором организация передачи информации в пределах ЗУ производится таким образом, что все вместе взятые типы ЗУ ЭВМ выступают в виде единого ЗУ, имеющего большую информационную емкость ВЗУ и высокое быстродействие СОЗУ. Такое абстрактное ЗУ ЭВМ называют виртуальным ЗУ.
По способу доступа к числам ЗУ ЭВМ различают:
- ЗУ с произвольной выборкой (ЗУПВ), в котором время обращения (время записи и считывания информации) не зависит от адреса числа;
- ЗУ с последовательным доступом, в котором для выборки числа по конкретному адресу необходимо последовательно просмотреть все адреса, предшествующие заданному, что приводит к зависимости времени выборки от адреса;
- ЗУ с ассоциативным доступом, в котором поиск и считывание информации происходят не по ее адресу, а по некоторому признаку самой информации, хранящемуся в слове.
Основные характеристики запоминающих устройств
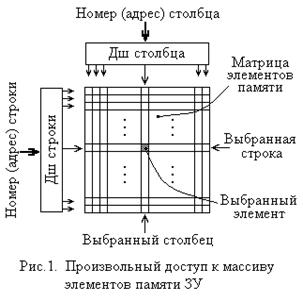
Запоминающие устройства (ЗУ) характеризуются рядом параметров, определяющих возможные области применения различных типов таких устройств. К основным параметрам, по которым производится наиболее общая оценка ЗУ, относятся их информационная емкость (E), время обращения (T) и стоимость (C).Под информационной емкостью ЗУ понимают количество информации, измеряемое в байтах, килобайтах, мегабайтах или гигабайтах, которое может храниться в запоминающем устройстве. Время обращения к ЗУ различных типов определяется по-разному. В качестве примера можно рассмотреть оперативные ЗУ и жесткие диски. Оперативные ЗУ обычно реализуются как ЗУ с произвольным доступом. Это означает, что доступ к данным, физически организованным в виде двумерного массива (матрицы элементов памяти), производится с помощью схем дешифрации, выбирающих нужные строку и столбец массива по их номерам (адресам), как показано на рис.1. Поэтому время Tобр обращения к ним определяется, в случае отсутствия дополнительных этапов (таких, например, как передача адреса за два такта), временем срабатывания схем дешифрации адреса и собственно временами записи или считывания данных.
|
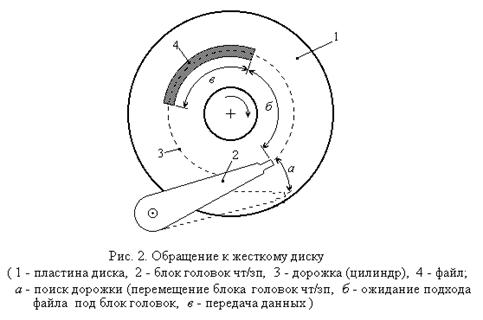
Время перемещения блока головок, обычно называемое изготовителями дисков временем поиска (seek time), зависит от количества дорожек, на которое надо переместить блок головок. Минимальное время затрачивается на перемещение блока головок на соседнюю дорожку (цилиндр). Это время составляет порядка 1-2 мс. Максимальное время требуется на перемещение блока головок от крайней дорожки к центральной или наоборот. Это время может составлять порядка 15-20 мс. Среднее время поиска (перемещения головок) составляет порядка 8-10 мс.
Стоимость запоминающих устройств также представляет собой важную характеристику. Именно она является одной из причин иерархической организации памяти ЭВМ. Действительно, хорошо иметь быструю и емкую память. Нужно, чтобы она была и относительно дешевой. Понятно, что эти параметры противоречивы. Поэтому в ЭВМ и строят иерархию памяти, на вершине которой (ближе всего к процессору) находятся маленькие быстродействующие, но дорогие ЗУ, а внизу – большие, дешевые, но медленные.
СТРУТУРА ПАМЯТИ ЭВМ
Системы памяти современных ЭВМ представляют собой совокупность аппаратных средств, предназначенных для хранения используемой в ЭВМ информации. К этой информации относятся обрабатываемые данные, прикладные программы, системное программное обеспечение и служебная информация различного назначения. К системе памяти можно отнести и программные средства, организующие управление ее работой в целом, а также драйверы различных видов запоминающих устройств. Память представляет собой одну из важнейших подсистем ЭВМ, во многом определяющую их производительность.
18.Способы организации оперативной памяти ЭВМ
Основная (оперативная ) память ЭВМ обычно является адресной. Это значит, что каждой хранимой в ОП единице информации (байту, слову) ставится в соответствие специальное число – адрес, определяющий место ее хранения в памяти. Минимальной адресуемой в памяти единицей информации является байт.
В машинах общего назначения нумерация бит и байт в слове и других единицах
информации производится слева направо. В обоих случаях адресом слова служит адрес их байта с наименьшим номером, но в машинах общего назначения им является крайний левый байт в представлении числа (команды, и т. п.), а в малых ЭВМ, микроЭВМ и микропроцессорах – крайний правый (младший байт).
ОП организована как массив или как многоблочная память.
1. Возможность наращивания “Живучесть больше”
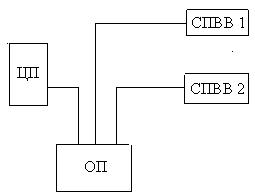 |
2. Многопортовая память
 |
Внутри многопортовой памяти должен быть арбитр или приоритетная схема.
Наибольший приоритет отдается медленным устройствам.
3. ОП с расслоением обращений
CPU не ждет, когда слева будет записано в память, а записывает только в регистр. Расслоение обращений между блоками ОП. Каждый блок должен иметь свой регистр адреса, данных, свое устройство управления (флаг свободен/занят). Расслоение реализуется через расслоение адресов. Коэффициент расслоения – среднее количество запросов, которое может принять память в целом “одновременно”.
Абсолютный коэффициент, Относительный коэффициент.
Относительный коэффициент – количество запросов, деленное на количество блоков.
N/K=0.5
Если быстродействие памяти в 4-е раза меньше быстродействия CPU, то необходимо 4-е блока.
Ассоциативная память.
Адрес указывает на физическое местоположение запоминающих элементов.
Ассоциативный поиск. Каждой единице информации ставится в соответствии какой-то признак и поиск осуществляется по этому признаку. Ассоциативный поиск может быть реализован программно и аппаратно.
 |
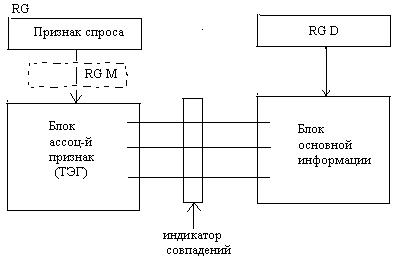 |
Степень ассоциации – равенство кодов.
Ассоциативное запоминающее устройство :
Отличия от адресного:
1.Суммарная емкость ЗУ больше на величину блоков емкости (ТЭГ).
2.Возможность получения многозначного ответа.
Особенности многозначного ответа:
1.Ошибка – недопустима.
2.Последовательное считывание основы информации
3.Выключенные ответы
4.Упорядоченная выборка
19.Назначение, структурная организация Кэш – памяти. Место Кэша в структуре процессора
Кэш – память. Кэш – память для пользователя не видна. Кэш – память не увеличивает память CPU. Кэш – память – ассоциативная память (не требующая регенерации). Кэш – память – внутренняя память CPU. CPU общается с Кэш – памятью напрямую, а не через системную шину.
Есть кэш – память 1 - уровня
2 – уровня
3 – уровня
Кэш может быть - объединенной (хранятся команды и данные)
-данных
-команд.
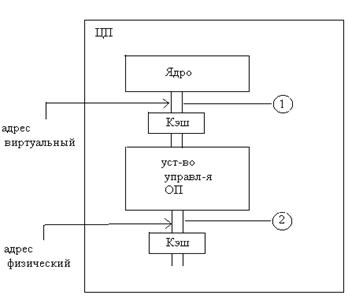 |
Расположение Кэш (CPU)
1)Время доступа меньше, не тратятся на преобразование адреса.
При частых исполнениях программ использования КЭША неэффективно. В зависимости от работы ЭВМ нужно ставить КЭШ в (1)(если переключение между программами нечастое) или (2) (если частое).
Структурная организация КЭША.
Пусть выполняется линейный участок программы. Если КЭШ пустой, то CPU обращается к ОП через SYS. BUS. При обращении к ОП, считываем команду, записываем ее в КЭШ. В КЭШе информация хранится не словами, а блоками
![]()
Слова располагаются по связным адресам.
Классика: размер блоков в КЭШе 4-е слова.
В качестве ТЭГА исполняется адрес. ТЭГ является неотъемлемым признаком информации. Кроме ассоциативной памяти, никакой другой памяти для построения КЭШ использовать нельзя.
Эффективность:
Если КЭША нет, то время обращения к ОП t1.
t1 – обращение к ОП
t2 – поиск КЭШ
t3 – обр. к КЭШ
P1 – вероятность удачного обращения
Если есть
T = t2 + P1*tP1)*t1
Информация из любой ячейки ОП может располагаться в любой ячейке КЭШа.
Назначения КЭШ: уменьшить количество обращений к ОП. КЭШ – внутренняя память процессора
20. Алгоритмы свопинга и замещения информации в КЭШе.
Свопинг
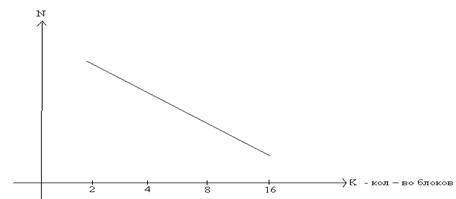
Разновидностью виртуальной памяти является свопинг. На рисунке 26 показан график зависимости коэффициента загрузки процессора в зависимости от числа одновременно выполняемых процессов и доли времени, проводимого этими процессами в состоянии ожидания ввода-вывода.
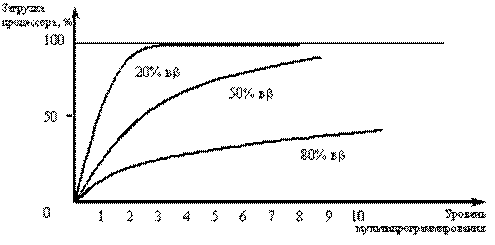
Рис. 26. Зависимость загрузки процессора от числа задач и интенсивности ввода-вывода
Из рисунка видно, что для загрузки процессора на 90% достаточно всего трех счетных задач. Однако для того, чтобы обеспечить такую же загрузку интерактивными задачами, выполняющими интенсивный ввод-вывод, потребуются десятки таких задач. Необходимым условием для выполнения задачи является загрузка ее в оперативную память, объем которой ограничен. В этих условиях был предложен метод организации вычислительного процесса, называемый свопингом. В соответствии с этим методом некоторые процессы (обычно находящиеся в состоянии ожидания) временно выгружаются на диск. Планировщик операционной системы не исключает их из своего рассмотрения, и при наступлении условий активизации некоторого процесса, находящегося в области свопинга на диске, этот процесс перемещается в оперативную память. Если свободного места в оперативной памяти не хватает, то выгружается другой процесс.
При свопинге, в отличие от рассмотренных ранее методов реализации виртуальной памяти, процесс перемещается между памятью и диском целиком, то есть в течение некоторого времени процесс может полностью отсутствовать в оперативной памяти. Существуют различные алгоритмы выбора процессов на загрузку и выгрузку, а также различные способы выделения оперативной и дисковой памяти загружаемому процессу.
Алгоритм простого свопинга
Данный алгоритм не сложнее алгоритма сквозной записи. Обращения к основной памяти имеют место в тех случаях, когда в быстром буфере не обнаруживается нужное слово. Эта схема свопинга повышает производительность системы памяти, так как в ней обращения к основной памяти не происходят при каждом запросе на запись, что имеет место при использовании алгоритма сквозной записи. Однако в связи с тем, что содержимое основной памяти не поддерживается в постоянно обновленном состоянии, если необходимого слова в быстром буфере не обнаруживается, из буфера в основную память надо возвратить какое-либо устаревшее слово, чтобы освободить место для нового необходимого слова. Поэтому из буфера в основную память сначала пересылается какое-то слово, место которого занимает в буфере нужное слово. Таким образом, происходят две пересылки между быстрым буфером и основной памятью.
Алгоритм свопинга с флагами
Данный алгоритм является улучшением алгоритма простого свопинга. В алгоритме простого свопинга когда в кэш-памяти не обнаруживается нужное слово происходит два обращения к основной памяти - запись удаляемого значения из кэша и чтение нового значения в кэш. Если слово с того момента, как оно попало в буфер из основной памяти, не подвергалось изменениям, т. е. по его адресу не производилась запись (оно использовалось только для чтения), то нет необходимости пересылать его обратно в основную память, потому что в ней и так имеется достоверная его копия; это обстоятельство позволяет в ряде случаев обойтись без обращений к основной памяти. Если, однако, слово подвергалось изменениям с тех пор, когда его копия была в последний раз записана обратно в основную память, то приходится перемещать его в основную память. Отслеживать изменения слова можно пометив слово (блок) дополнительным флаговым битом. Изменяя значение флагового бита при изменении слова, можно сформировать информацию о состоянии слова; пересылать в основную память необходимо лишь те слова, флаги которых оказываются в установленном состоянии.
Алгоритм регистрового свопинга с флагами
Повышение эффективности алгоритма свопинга с флагами возможно за счет уменьшения эффективного времени цикла, что можно получить при введении регистра (регистров) временного хранения между кэш-памятью и основной памятью. Теперь, если данные должны быть переданы из быстрого буфера в основную память, они сначала пересылаются в регистр (регистры) временного хранения; новое слово сразу же пересылается в буфер из основной памяти, а уже потом слово, временно хранившееся в регистре, записывается в основную память. Действия в ЦП начинают опять выполняться, как только для этого возникает возможность. Алгоритм обеспечивает совмещение операций записи в основную память с обычными операциями над буфером, что обеспечивает еще большее повышение производительности.
1°. Случайный алгоритм замещение информации в Кэше
Именно на ситуации такого рода ориентирован алгоритм RAND. Идея его состоит в том, что при необходимости отбросить какую либо ячейку из кэша, эта ячейка выбирается случайным образом, причем выбор может пасть с равной вероятностью на любую ячейку из числа находящихся в кэш-памяти.
В аппаратной реализации алгоритма RAND схема управления должна была бы содержать датчик случайной или квазислучайной величины с равномерным законом распределения.
Поэтому случайный алгоритм используется иногда в исследовательских работах для сравнения с ним различных практических алгоритмов, но не используется на практике.
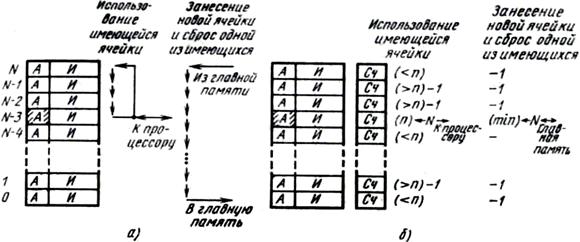
2°. Алгоритм FIFO замещение информации в КэШе
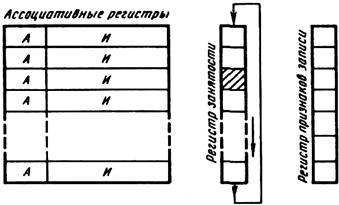
Рис. 1. Аппаратная реализация алгоритма FIFO
3. Алгоритм замещения LRU(Least Recently Used).
|
Алгоритмы LRU исходят из концепции локального характера использования информации программой, т. е. из предположения о том, что на каждом участке своего прохождения программа обращается к ограниченному подмножеству ячеек памяти, принадлежащих ограниченному подмножеству страниц.
Идея алгоритмов LRU, как показывает название, состоит в том, что при необходимости освободить место в высшей ступени памяти, из нее изгоняется та информация, которая менее всего использовалась в последнее время.
23. Защита информации в ЭВМ. Защита ОП.
Разграничение доступа к ЭВМ и её блокам (ОП, винчестер,…)
Аппаратная защита надёжнее, чем программная.
Защита делится на защиту от несанкционированного доступа и защиту от сбоев (это больше относится к надёжности). Будем говорить о первом виде защиты.
Несанкционированный доступ делится: на шпионаж (прочитать и не изменять) и диверсию.
Диверсия: на изменение и добавление. Самое надёжное – не подпускать никого к машине. Надёжнее нет.
Аппаратные средства защиты – это защита ОП.
Защита ОП.
Если однопрограммная машина, то ОП защищать не надо, надо защищать ОС. Но сейчас таких машин нет.
Защита
1) В CPU вводятся два граничных регистра. При любом запуске программы адрес сравнивается с содержимым регистров: если адрес > одного регистра и < другого, то разрешается обращение, иначе – прерывание и сообщение. А в регистрах – границы разрешённого участка ОП. Эти граничные регистры пользователю не доступны.
2) Защита по ключам (удобно для блочной структуры и для страниц)
Память разбита на блоки (или страницы). Каждой программе при запуске присваивается код (ключ). Существует регистр ключа. В соответствие каждому блоку/странице ставится код (замок). При обращении к блоку ключ и замок сравниваются. Обращение разрешается, если они равны, либо ключ = 0, либо замок = 0.
Ключ = 0 можно присвоить программам ОС или для программы тестирования ОП (чтобы можно было получить доступ ко всем блокам ). Замок = 0 – для общедоступных участков ОП. Эта защита очень удобна. Единственная проблема – это разрядность ключа. (4 разряда – только 15 программ может идти).
Т. е. «-» жёсткая связь между разрядностью ключа и количеством программ.
3) Защита у INTEL (и AMD).
Основана на том, что все системные объекты описываются с помощью дескрипторов. А в каждом дескрипторе существует двухбитовое поле DPL – уровень привилегий дескриптора. Содержимое этого поля и определяет доступ. Так как только два бита, то существует только 4 уровня привилегий:
 |
0-й уровень самый защищённый.
Данные и коды защищены по-разному. Не разрешается считывание данных, имеющих более высокий уровень привилегий, чем команда, к ним обращающаяся.
Программе не разрешается передавать управление другой программе, если уровень привилегий той не равен текущему. Только на своём уровне может происходить передача управления.
Существует два варианта передачи на другие уровни:
1) Использование подчинённых сегментов.
2) Использование специальных дескрипторов – шлюзов вызова.
Физический уровень управления в/в – это привилегированный уровень (очень сильно защищён).

Дескриптор сегмента имеет длину двойного слова.
G - если G=0, то размер сегмента = 1 Мбайт, иначе – 4 Гб.
D – для совместимости с предыдущим (16–ти разрядн. ) CPU (Если D =0, то операнды 16-ти разр., иначе 32 разр.). U – user, P - присутствие, DPL - уровень привилегий дескриптора, S - система или сегмент.
Тип - эти 3 разряда определяют дополнительные операции сегмента и тип сегмента.
![]()
![]() 000 - DR – чтение сегмент данных (DS)
000 - DR – чтение сегмент данных (DS)
001 - DR-W – чтение-запись
![]() 010 – R SS
010 – R SS
011 – R-W
![]() 100 – только исполнение CS
100 – только исполнение CS
101 – исполнение и чтение
![]() 110 – исполнение подчинённый сегмент кода
110 – исполнение подчинённый сегмент кода
111 - исполнение и чтение
A – тип подчинённости: если он равен 1, то сегмент кода не имеет защиты по уровням.
CPL – текущий уровень привилегий, это тоже двухбитовое поле, текущий уровень задаётся в RPL.
Доступ к данным.
Основное правило доступа к данным имеет следующий вид: (1) CPL £ DPL, CPL – это DPL для CS. DPL - DPL для iS. i= S, D,E, F,G i=C.
Другими словами, программа не должна быть менее привилегированна, чем данные.
Контроль доступа осуществляется дважды: 1. При загрузке селектора в сегментные регистры, и если не выполняется условие (1), то она ничего не загружает. 2. После успешной загрузки селектора, когда он используется для фактического обращения, осуществляется контроль, ЧТО разрешать: 1) чтение; 2) запись и т. д.
Некоторая особенность есть с сегментом стека: загрузка селектора в сегмент стека разрешается только при CPL=DPLss, где SS-сегмент стека.
Защита сегмента кода(CS).
Запрещается передача управления сегменту кода, который находится на другом уровне привилегий. Передача управления – это, по сути, изменение содержимого CS и …………., поэтому CPU должен прове-рить, ЧТО загружается в CS:
1. Проверяется дескриптор сегмента, которому передаётся управление: должен быть атрибут «Исполняемый»;
2. Сравнивается на равенство уровень привилегий дескриптора загружаемого сегмента и текущего уровня привилегий: он не должен превышать текущий уровень;
3. Вызываемый сегмент должен быть отмечен как присутствующий, а новое значение содержимого указателя команд EIP не должно выходить за пределы сегмента, в противном случае:
- либо сигнал нарушения защиты:
- либо сигнал нарушения присутствия.
Передача управления.
1. использование шлюза вызова – это косвенный вызов CS.
2. Через подчинённый сегмент.
3. При передаче управления подчинённому CS, текущий уровень привилегий не меняется. Кроме защиты на уровне сегмента существует защита на уровне страниц ( только два уровня привилегий ):
1) U / S (USER / SUPERVISOR: 0-USER, 1-SUPERVISOR);
2) R / W (R - чтение, W - чтение и запись).
Если CPL =0,1,2, то CPU работает на уровне S, а если CPL = 3, то на уровне U.
Существует 2 страничных таблицы, т. е. одной стр. соответствует 2 дескриптора страниц, то есть на 2 бита, а 4 бита защиты дают 16 вариантов защиты. Защита работает не всегда, только когда включено постраничное преобразование.
Программные методы защиты.
Основной вариант – защита доступа через пароли. Пароли бывают 6-ти типов:
I. По типу идентифицируемых объектов:
I1- пароли терминалов; I2- пароль пользователя; I3-пароль программ; I4- пароль данных.
II. По структуре:
II1- цифровые;
II2- буквенные: II2.1- слова естественного языка: II2.2- произвольные наборы;
II3- смешаннные;
II4- фиксированной длины;
II5-переменной длины.
III. По способам ввода:
III1- формируемые аппаратно; III2- вводимые с идентификационных карт; III3- вводимые с клавиатуры.
IV. По способам получения:
IV1- классические; IV2- процедурные (задаётся не сам пароль, а процедура формирования слова пароль).
V. По местоположению в тексте запроса:
V1-внешние;
V2- внутренние:
V2.1-фиксированные;
V2. 2-плавающие.
VI. По времени использования:
VI1-с неопределённым временем; VI2- периодически заменяемые; VI3-разовые.
24. Архитектура и организация ввода-вывода в ЭВМ; виды ввода-вывода.
С точки зрения организации в/в различают способы:
1.условный (программно-управляемый)
2.по прерыванию
3.dma (применимо по отношению к системной шине).
Варианты:
1.процессор имеет 2 адресных прерывания одинакового размера: пространство адресов ОП и пространство в/в. (размер 2n n – размерность шины адреса). Различение адресных пространств происходит с помощью бита M/IO в шине управления. Этот сигнал = 0 для, например, команд OUT и =1 для MOVE
2.С отображением в память. Часть адресов ОП используются как адреса ПУ (примерно 4к адресов).
Как осуществляется i/o при программно управляемом способе.
В каждом ПУ имеется 3 регистра :
1. Команд (что нужно: ввод или вывод )
2. Состояния
3. Данных
Адрес попадая в ПУ поступает на селектор, который представляет собой ПЗУ (программируемое или нет), схему или другое, построенное на определенные адреса.
Следует различать ввод/вывод и обмен. Ввод/вывод – это общая операция, а обмен это процесс пересылки данных (или ссылка команды на обмен и возврат к расчетам). Устройство, как только оно готово к обмену, посылает в ЦП прерывание. Остальное – то же.
Устройство должно уметь формировать вектор прерывания и посылать запрос. Это дополнительные аппаратные затраты по сравнению с предыдущим способом. Есть и затраты по времени на обработку прерываний. Кроме этого, по сравнению с условным В/В, скорость обмена будет ниже.
25. Ввод-вывод с прямым доступом к памяти.
 |
Прямой доступ к памяти (ПДП) – это способ пересылки данных, при использовании которого устанавливается непосредственная связь между устройством ввода-вывода и памятью, без участия ЦП, т. е. периферийное устройство может пересылать данные непосредственно в память или получать их из памяти. ЦП при этом освобождается от функций управления обменом данными и может выполнять в это время другие задачи. Кроме того скорость обмена с ПДП намного выше, чем с участием ЦП.
Блок –схема системы ввода-вывода с ПДП
Видно, что ЦУ и периферийные устройства (ПУ) используют одну шину (SYS BUS) для связи с памятью, т. е. они не могут обращаться к памяти в одном цикле.
Система с ПДП может осуществлять пересылки данных между различными областями памяти и различными ПУ.
Существует несколько вариантов реализации ПДП:
- ПДП с блокировкой ЦП. ЦП отключается от общей шины на время выполнения пересылки с ПДП. Это наиболее простая реализация системы с ПДП, но отключение и подключение ЦП к шине требует довольно много времени. Кроме того, в это время ЦП не может выполнять никаких операций.
- ПДП с квантованием цикла памяти. Каждый цикл памяти разбивается на два временных интервала – один для ЦП, другой для ПДП. Этот метод обеспечивает большую скорость как для выполнения операций ЦП, так и для ПДП. При этом в каждом цикле обеспечивается возможность обращения к памяти и ЦП, и ПУ в ходе ПДП. Недостаток: необходимость применения быстродействующих и дорогостоящих ЗУ.
- ПДП с «захватом цикла». Наиболее выгоден по соотношению стоимость/производительность. ПУ, осуществляющее ПДП, «отнимает» у ЦП цикл памяти, но ЦП не блокируется и может выполнять программу, т. е. работа ЦП и пересылка с ПДП совмещаются во времени. Если цикл памяти нужен одновременно ЦП и ПУ, то приоритет отдается последнему, а ЦП ожидает окончания цикла ПДП. Производительность ЦП снижается только в том случае, когда ЦП использует весь диапазон адресов памяти. Таким образом, достигается удовлетворительная производительность за счет относительно невысоких затрат.
26. Структура и функции контроллера ПДП.
Поскольку ЦП не участвует в обмене с ПДП, а обменом нужно управлять, в состав системы вводится контроллер прямого доступа к памяти (КПДП), который и вырабатывает необходимые управляющие сигналы и адреса ОП.
КПДП выполняет следующие функции:
1. Управление инициируемой ЦП или ПУ передачей данных между ОП и ПУ.
2. Задание размера блока данных, который подлежит передаче, и области памяти, используемой при передаче.
3. Формирование адресов ячеек ОП, участвующих в передаче.
4. Подсчет числа единиц данных (байт, слов), передаваемых от ОП к ПУ или обратно, и определение момента завершения операции ввода-вывода.
|
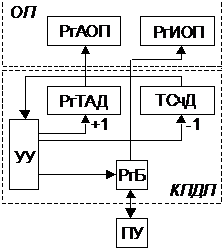 |
КПДП может быть как один на несколько ПУ, так и каждое ПУ может иметь свой КПДП.
При инициализации операции ввода-вывода в ТСчД заносится размер подлежащего передаче блока (число байт или слов), а в РгТАД – начальный адрес области памяти, используемой при передаче. При передаче каждого байта содержимое РгТАД увеличивается на 1, при этом формируется адрес очередной ячейки ОП, участвующей в передаче. Одновременно уменьшается на 1 содержимое ТСчД. Обнуление ТСчД указывает на завершение передачи.
27. Назначение, классификация сопроцессоров ввода-вывода. Управление сопроцессорами. Понятие программы управления сопроцессором ввода-вывода.
Сопроцессор ввода-вывода (СПВВ) предназначен для обеспечения ПДП. Выполняет следующие функции:
- задание размеров массива данных и области памяти, участвующих в обмене
- формирование адресов последовательных ячеек ОП, используемых в передаче
- подсчет числа единиц данных, прошедших через канал
- определение момента завершения передачи массива данных
При этом СПВВ должен обеспечивать буферизацию и преобразование данных для согласования работы ОП и ПУ.
Кроме того, для минимизации участия ЦПУ в операциях ввода-вывода может выполнять: организацию цепочки данных; организацию пропуска информации; организацию цепочки операций; формирование запросов на прерывание; блокировку контроля неправильной длины.
СПВВ в отличие от КПДП, имеет средства, позволяющие ему самостоятельно извлечь из памяти управляющее слово, получив команду от ЦПУ. Если управляющее слово выполнено нормально, то он не дает никакого запроса на прерывание, этот запрос будет только после последнего управляющего слова. Если он подает запрос на прерывание в ЦПУ после каждого выполненного управляющего слова, то он похож на КПДП + СА + Чт. УС., эти запросы необходимы лишь как сообщения о том, что слово выполнено нормально, и можно переходить к другому.
СПВВ | |||
КПДП | Средства адресации и чтения управляющих слов | ||
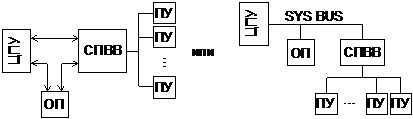 |
Изначально СПВВ был ориентирован на другую структуру:
СПВВ четко делятся по обмену с ЦПУ на селекторные и мультиплексные.
Программное управление СПВВ
Каждая операция или совокупность операций производится под управлением соответствующей программы канала. Программа канала представляет собой некоторую последовательность УС, обеспечивающую выполнение определенной операции ввода-вывода. Обычно канальные программы хранятся в ОП.
Система команд ЭВМ содержит небольшое число универсальных по отношению к разным типам ПУ команд ввода-вывода.
28. Структура и работа сопроцессора ввода-вывода в селекторном режиме.
СПВВ, работая в селекторном режиме, может вести обмен только с одним ПУ, при этом могут одновременно работать несколько ПУ, но обмен СПВВ будет вести только с одним.
|
 |
Структура:
КОП | GR TA | RG УС | RG TA – регистр текущего адреса RG УС – счетчик УС RG ПВУС – регистр предварительного УС | |
RG ПВУС | ||||
Если текущее УС не является последним, то RG УС … 8-4, инициируется процедура чтения следующего УС и оно в RG ПВУС, т. е. это можно рассматривать как дополнительную память размером в 1 УС.
1) Адрес 1-го УС содержится в команде, которая последует из СПВВ.
SIO | № СПВВ | № ПУ | Адрес 1-го УС |
2) Независимо от количества СПВВ в ОП выдается одна фиксированная ячейка, наделенная адресом, содержимое этой ячейки – адресное слово.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
