


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Министерство образования и науки РФ
Иркутский государственный технический университет
Системное программное обеспечение
Программа, методические указания и задания
к выполнению лабораторной работы
(для студентов заочной формы обучения)
Специальность 220100 – Вычислительные машины, системы и сети
Направление 654600 – Информатика и вычислительная техника
Издательство Иркутского государственного
технического университета
2011
Системное программное обеспечение: Программа, метод. указания и задания к выполнению лабораторной работы и курсового проекта/ сост. Иркутск : Изд-во ИрГТУ, 2011, 45 с.
Рабочая программа разработана в соответствии с требованиями государственного стандарта высшего профессионального образования по направлению 65.4600 «Информатика и вычислительная техника», специальност 220100 – Вычислительные машины, системы и сети.
Направлены на освоение принципов построения компилятора; описаны алгоритмы реализации основных блоков компилятора, приводятся индивидуальные задания.
Предназначены для студентов заочной формы обучения.
Рецензент: канд. техн. наук, зав кафедрой вычислительной техники, доцент
ПРОГРАММА
1. Структура и состав системного программного обеспечения (СПО)
2. Пользовательский интерфейс операционной системы.
3. Таблицы как способ хранения системной информации. Виды таблиц (неупорядоченные, упорядоченные, прямого доступа). Разрешение конфликтов в таблицах прямого доступа.
4. Системы программирования. Виды трансляторов (ассемблеры, макрогенераторы, компиляторы, интерпретаторы)
5. Структура компилятора. Функции его основных блоков.
6. Конечные автоматы как модель лексического блока компилятора. Способы хранения конечного автомата в памяти.
7. Формальные языки и грамматики. Восходящие и нисходящие методы вывода. Классификация грамматик по Хомскому.
8. Виды синтаксических анализаторов.
9. Генератор кода, формирование постфиксной записи и объектного кода для арифметических выражений; распределение памяти, виды переменных.
10. Функции загрузчика; настраивающий и динамический загрузчики; подключение библиотек.
11. Пакеты программ, входной язык пакета, граф предметной области, транслятор с входного языка пакета.
После изучения тем курса студент-заочник должен выполнить лабораторную работу на тему: «Разработка блоков компилятора» согласно общему заданию, которое выполняется по индивидуальному варианту.
Задание к лабораторной работе. Для заданной конструкции заданного языка:
1. Составление списка лексем для примера цепочки (вручную)
2. Составление регулярных выражений (вручную)
3. Составление КА (jflap)
4. Проверка цепочки по КА (jflap)
5. Разработка блока лексического анализа (jaccie)
6. Разработка КС-грамматики (jflap)
7. Проверка цепочки с помощью КС-грамматики (Jflap)
8. Разработка блока синтаксического анализа (jaccie)
9. Преобразование арифметического выражения в префиксную и постфиксную (ПОЛИЗ) формы с помощью различных способов обхода дерева
10. Вычисление значения выражения по ПОЛИЗу
11. Описание примера цепочки языка командами абстрактной стековой машины
Затем студент-заочник должен выполнить курсовой проект на тему: «Разработка элементов транслятора для учебного языка» согласно общему заданию, которое выполняется по индивидуальному варианту.
Задание к курсовому проекту:
1. Разработайте словесное описание лексики и синтаксиса заданного варианта языка. Напишите простую тестовую программу, содержащую все заданные конструкции языка. Вручную выполните интерпретацию программы в код абстрактной стековой машины.
2. Разработайте систему регулярных выражений, определяющую лексику заданного варианта языка. Постройте КА в форме матрицы для описания лексического блока. Реализуйте лексический блок с помощью программы Jaccie.
3. Разработайте формальную грамматику, определяющую синтаксис заданного еязыка. Используя программу Jaccie, постройте синтаксичекий вывод в грамматике.
5. Оформите расчетно-пояснительную записку
Индивидуальные варианты к лабораторной работе:
Вариант задания имеет код вида: LK, где
L - код обрабатываемого языка;
К - конструкция языка
Варианты обрабатываемого языка:
1 - Паскаль;
2 - Фоpтpан;
3 - Бейсик;
4 - С;
5 - Java.
Варианты конструкции языка:
1 - опеpатоp присваивания;
2 - условный оператор;
3 - опеpатоp разветвления в нескольких направлениях;
4 - опеpатоp цикла типа while;
5 - опеpатоp цикла типа for;
6 - опеpатоp цикла типа until;
7 - опеpатоp ввода-вывода.
Краткое описание учебного языка, варианты заданий.
Ключевые слова (выделены жирным шрифтом, например: число, строка, данные, …) должны быть нечувствительны к регистру.
Обозначения:
[ ] – необязательная часть
… – часть, повторяющаяся произвольное количество раз
< > – описание конструкции
<Б>|<Ц>|<пБ>|<пЦ>|<пБЦ> – буква | цифра | последовательность букв | последовательность цифр | последовательность букв и/или цифр или пусто
<И> – <имя объекта>
<В> – <выражение>
<ЛВ> – <ЛогическоеВыражение>
<ОБ> – <ОператорИлиБлок> (<О> - одиночный оператор)
<К> –<константа>
Индивидуальные варианты для курсового проекта
Вариант задания имеет вид: ICTPUSL
Расшифровка цифр варианта задания:
I – вид идентификатора:
1 – <Б><пЦ><Б>
2 – <пБ><Ц>
3 – <пБ><пЦ>
4 – <Б><Ц><пБЦ>
C –константы:
1 – целые, вещественные, символьные, 4-ричные, true/ false
2 – целые, вещественные, символьные, 5-ричные, yes/ no
3 – целые, вещественные, символьные, 6-ричные, L_1 / L_0
4 – целые, вещественные, символьные, 7-ричные, L_T/ L_F
T – объявления (целое, вещественное, символьное, булево):
1 – int[e[g[e[r]]]], float, char, bool
2 – card[i[n[a[l]]]], real, symbol, logical
3 – long, doub[l[e]], litera, bool[e[a[n]]]
4 – number, real, char[a[c[t[e[r]]]]], bool
P – вид оператора присваивания:
1 – <И> := <В>;
2 – <И> <- <В>;
3 – <И> = <В>;
4 – <И> <=<В>;
U – условный оператор:
1 – by <ЛВ> do <ОБ> [otherwise <ОБ>]
2 – when <ЛВ> then <ОБ> [else <ОБ>]
3 – ? <ЛВ> #<ОБ> [: <ОБ>]
4 – if<ЛВ> <ОБ> [else<ОБ>]
S – переключатель:
1 – select <В> case(<К>) <ОБ> … end
2 – switch<В> {by <К>:<ОБ> …}
3 – case <В> when <К> then <ОБ> … end
4 – with<В> {?<К>:<ОБ> …}
L – оператор цикла:
1 – while(<ЛВ>) do <ОБ>
2 – repeat <ОБ>when <ЛВ>
3 – for<И>from<К>to<К> [step<К>] <ОБ>
4 – cycle([<О>];[<ЛВ>];[<О>]) <ОБ>
МЕТОДИЧЕСКИЕ УКАЗАНИЯ К ЛАБОРАТОРНОЙ РАБОТЕ
1. ЯЗЫКИ, ОСНОВНЫЕ ПОНЯТИЯ
В общем случае язык – это заданный набор символов и правил, устанавливающих способы комбинации этих символов для записи правильных цепочек.
Основой любого языка является алфавит, то есть множество допустимых символов V. Цепочка символов, принадлежащих множеству символов V, обозначается α(V) . Пустая цепочка обозначается ε ; она может принадлежать или не принадлежать языку:
V+ – множество всех α(V) без ε ;
V* – множество всех α(V) вместе с ε .
Длина цепочки a обозначается |a|.
Обращение цепочки a (обозначение aR) – это цепочка, в которой порядок символов изменен на обратный.
Итерация (повторение) цепочки a (обозначение an) – это конкатенация цепочки с самой собой n раз.
Языком L(V) над алфавитом V называется некоторое подмножество цепочек конечной длины из множества всех цепочек.
Для любого языка справедливо L(V)€V*.
Способы описания языка
· Перечислением всех допустимых цепочек языка
· Указанием способа порождения цепочек языка, то есть заданием грамматики языка.
· Определением метода распознавания цепочек языка.
Первый способ малореалистичен.
Второй способ предусматривает описание некоторого набора правил, с помощью которых строятся цепочки языка.
Третий способ предусматривает построение некоторого логического устройства (распознавателя) – автомата, на вход которого поступает некоторая цепочка, и автомат на выходе делает вывод о принадлежности или не принадлежности этой цепочки языку.
Состав языка
Лексика – совокупность слов (лексем) языка.
Синтаксис – набор правил, определяющих допустимые конструкции языка.
Семантика – раздел языка, определяющий содержание языка, то есть значение предложений языка.
Виды трансляторов
Транслятор – программа, обеспечивающая перевод исходной программы пользователя на внутренний язык компьютера. Напомним, что ни один из существующих языков программирования не является «родным» для компьютера. Он воспринимает программы, написанные только на своем машинном языке.
На практике используются трансляторы с различными принципами работы. Первый вид транслятора обеспечивает поочередный перевод каждого оператора исходной программы на машинный язык и немедленное выполнение его с одновременной проверкой правильности. Трансляторы такого типа называются интерпретаторами.
Второй вид транслятора – компилятор. В отличие от интерпретатора он осуществляет сначала перевод всей исходной программы на машинный язык, одновременно проверяя ее правильность; в полученную программу компилятор включает подпрограммы и функции, которые увязываются со всей программой. Результатом работы компилятора является загрузочная программа.
Третий вид транслятора — ассемблер для перевода на машинный язык программ с машинно-ориентированного языка.
Если классифицировать трансляторы по количеству просмотров исходной программы (проходов), то можно выделить однопроходные и многопроходные. В частности, ассемблер является, как правило, двухпроходным, так как при первом проходе создается таблица меток, а при втором – генерируется машинный код.
Структура компилятора, назначение его блоков
Компилятор состоит из шести блоков (рис. 1):
Лексический блок разбивает текст исходной программы на лексемы.
Лексема – неделимая единица языка. Как правило, различают 4 типа лексем (идентификаторы, константы, ключевые слова, разделители). Входная цепочка записывается списком лексем вида:
вид лексемы номер лексемы в соответствующей таблице.
Такое кодирование позволяет перейти от лексем во входной цепочке, имеющих разную длину, к лексемам фиксированной длины, что облегчает дальнейшую обработку.
В процессе построения лексем формируются таблицы идентификаторов и констант и используются заранее заданные таблицы разделителей и ключевых слов.
На этапе лексического анализа также выявляются лексические ошибки (недопустимые символы, неправильная запись чисел, идентификаторов и др.).
Пример лексического анализа показан на рис. 2.
Синтаксический блок строит дерево разбора цепочки в соответствии с грамматикой языка. Если дерево не удается построить, выдаются сообщения об ошибках.
Семантический блок в соответствии с семантикой языка определяет соответствие описаний переменных выражениям, в которых они участвуют (например, сложение имеет смысл, если операнды и результат – числа).
Кроме того, при выполнении операций часто нужны преобразования результатов.


Рис.1. Структура компилятора
Блок генерации кода по дереву разбора строит атрибутированное дерево разбора, снабжая вершины дерева свойствами (атрибутами). Это позволяет сгенерировать объектный код программы.
Блок оптимизации кода делает объектный код более эффективным за счет удаления общих подвыражений или выноса их за пределы цикла и т. д.
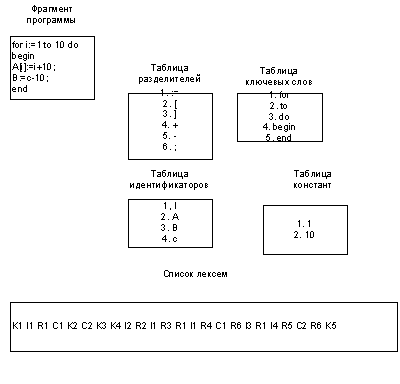
Рис. 2.Пример лексического анализа
Распознаватели, их виды
Блоки компилятора являются распознавателями, то есть определяют принадлежность цепочки символов определенному языку. В состав распознавателя входят входная цепочка символов, рабочая память и устройство управления (УУ). Схема действия распознавателя показана на рис. 3
Входная цепочка
 |
Считывающая головка
 |
 |
Рис. 3. Структура распознавателя
УУ координирует работу распознавателя, может иметь некоторый набор состояний и рабочую память. Работа распознавателя состоит из шагов или тактов. В каждом такте состояние распознавателя определяется его конфигурацией. Конфигурация определяется следующими параметрами:
§ содержимое входной цепочки и положение считывающей головки
§ состояние УУ
§ содержимое рабочей памяти
У распознавателя всегда имеется начальная конфигурация и одна или несколько конечных конфигураций. Распознаватель допускает входную цепочку a символов, если, находясь в начальной конфигурации и получив на вход эту цепочку, он может проделать последовательность шагов, заканчивающуюся одной из его конечных конфигураций.
По видам считывающего устройства распознаватели могут быть односторонними, чаще всего левосторонними (головка перемещается только в одном направлении на заданное число позиций либо остается на месте) или двусторонними (возможность возвращения к уже прочитанным символам).
По видам УУ распознаватели делятся на детерминированные и недетерминированные. Распознаватель называется детерминированным, если для каждой допустимой конфигурации распознавателя существует единственная возможная конфигурация, в которую он перейдет в следующем такте. Если таких возможных конфигураций несколько, то автомат называется недетерминированным.
По видам рабочей памяти распознаватели бывают:
· без памяти;
· с ограниченной памятью;
· с неограниченной памятью.
Кроме того, рабочая память может быть определенным образом организована (в виде стека, очереди и т. д.).
2. РЕГУЛЯРНЫЕ ВЫРАЖЕНИЯ
Регулярное выражение в алфавите T и обозначаемое им регулярное множество в алфавите T определяются рекурсивно следующим образом:
· Ø — регулярное выражение, обозначающее пустое множество ;
· ε — регулярное выражение, обозначающее множество { ε };
· a — регулярное выражение, обозначающее множество {a};
· если p и q — регулярные выражения, обозначающие регулярные множества P и Q соответственно, то
· (p|q) — регулярное выражение, обозначающее регулярное множество P ƯQ,
· (pq) — регулярное выражение, обозначающее регулярное множество PQ,
§ (p*) — регулярное выражение, обозначающее регулярное множество P*;
§ ничто другое не является регулярным выражением в алфавите T.
Кроме того, мы будем пользоваться записью p+ для обозначения pp*. Таким образом, запись (a|((ba)(ba)*)) эквивалентна a|(ba)+.
Примеры
1. Регулярное выражение для множества идентификаторов
Letter = a|b|c|...|x|y|z |
Digit = 0|1|...|9 |
Identifier = Letter(Letter|Digit)*. |
2. Регулярное выражение для множества чисел
Digit = 0|1|...|9 |
Integer = Digit+ |
sign = (+|-|e) |
Number = sign Integer |
3. Конечные автоматы
Для распознавания регулярных множеств служат конечные автоматы (рис. 4).
| - |
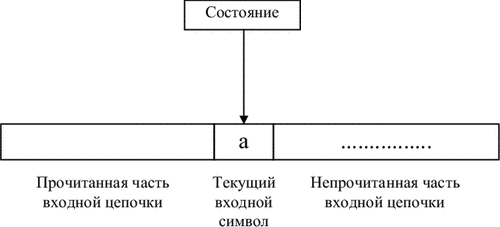
Рис. 4. Поведение конечного автомата
Детерминированный конечный автомат (ДКА) – это пятерка M = (Q, T, D, q0, F), где
§ Q — конечное множество состояний;
§ T — конечное множество допустимых входных символов (входной алфавит);
§ D — функция переходов D(q, a)=p, где q, p€Q, a €T, определяющая поведение управляющего устройства;
§ q0 € Q — начальное состояние управляющего устройства;
§ F€ Q — множество заключительных состояний.
D(q, ε) = для любого q€ Q,
D(q, a) содержит не более одного элемента для любых q €Q и a€ T.
Конечный автомат может быть изображен в виде диаграммы, представляющей собой ориентированный граф, в котором каждому состоянию соответствует вершина, а дуга, помеченная символом a ![]() T
T ![]() {ε}, соединяет две вершины p и q, если p
{ε}, соединяет две вершины p и q, если p ![]() D(q, a). На диаграмме выделяются начальное и заключительные состояния (в примерах ниже, соответственно, входящей стрелкой и двойным контуром).
D(q, a). На диаграмме выделяются начальное и заключительные состояния (в примерах ниже, соответственно, входящей стрелкой и двойным контуром).
Второй способ представления КА – в виде матрицы, строки которой помечаются состояниями, а столбцы – входными символами. Первая строка соответствует начальному состоянию. К матрице справа добавляется столбец, в котором допустимые конечные состояния помечаются 1, а недопустимые - 0.
Пример конечного автомата для оператора языка Фортран определения переменной или массива (в предположении, что слово INTEGER уже поступило).
Вид оператора языка:
INTEGER P, K(4),B(4,M),A(N,2),С(L)$ (символ конца оператора).
Входные символы: {id, const,(,),,,$}
Состояния автомата:
S0 - поступление ключевого слова INTEGER;
S1 - поступление идентификатора – объекта описания;
S2 - поступление идентификатора – размерности массива;
S3 - поступление константы;
S4 - поступление открывающей круглой скобки;
S5 - поступление закрывающей круглой скобки;
S6 - поступление запятой – разделителя объектов описания;
S7 - поступление запятой – разделителя размерностей;
S8 - поступление символа конца оператора.
Конечный автомат в виде матрицы показан в табл. 1
Таблица 1
Входные символы | id | const | ( | ) | , | $ | Допустимое конечное состояние |
Состояния | |||||||
S0 | S1 | 0 | |||||
S1 | S4 | S6 | S8 | 0 | |||
S2 | S5 | S7 | 0 | ||||
S3 | S5 | S7 | 0 | ||||
S4 | S2 | S3 | 0 | ||||
S5 | S6 | S8 | 0 | ||||
S6 | S1 | 0 | |||||
S7 | S2 | S3 | 0 | ||||
S8 | 1 |
Конечный автомат в виде графа показан на рис. 5.

Рис.5. Граф КА для примера
4.
4. ПРОГРАММА JFLAP
Программа предоставляет графические средства для работы с различными видами автоматов. При вызове программы появляется меню:

Описание КА с помощью Jflap
Выбираем пункт Finite Automation (КА)
На рис. 6 показано пустое окно редактора:



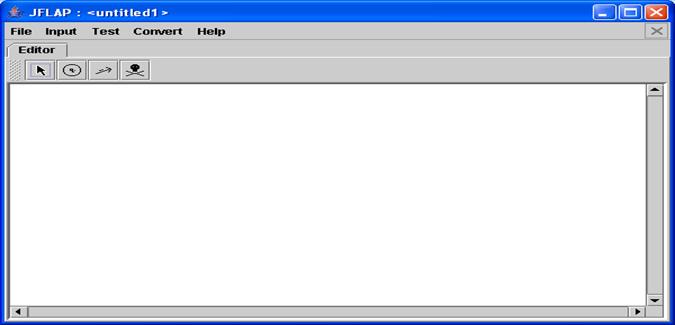
Рис 6. Окно редактора jflap
Пример КА показан на рис. 7
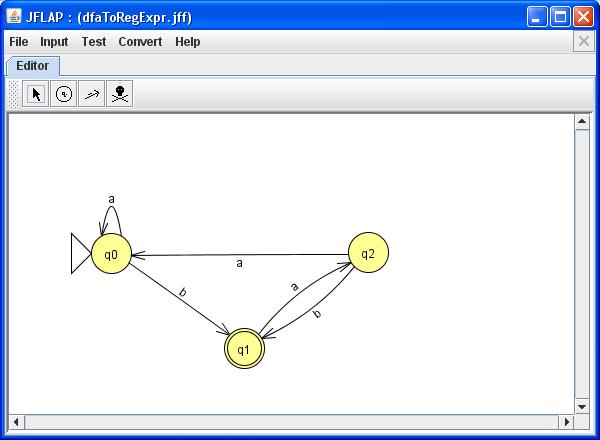
Рис. 7. Пример КА
5. ПРОВЕРКА ПРАВИЛЬНОСТИ ЦЕПОЧКИ
Можно проверить правильность составленного автомата, вводя цепочку и проходя по состояниям. Для этого выбирается пункт меню Input – Step With Closure. Появляется окно для ввода цепочки:

При нажатии кнопки Ok появляется окно, в котором можно проследить последовательность шагов (рис. 8)
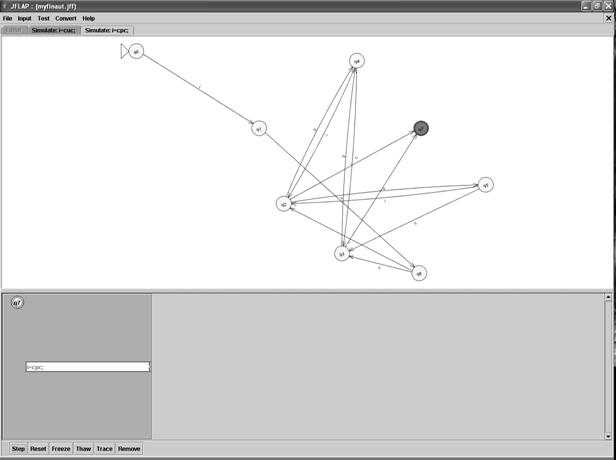

Рис. 8. Окно проверки правильности цепочки
Если цепочка завершается переходом в заключительное состояние, то окно окрашивается в зеленый цвет; если нет, то в красный.
6. ЛЕКСИЧЕСКИЙ БЛОК, РЕАЛИЗОВАННЫЙ С ПОМОЩЬЮ
ПАКЕТА JACCIE
Jaccie (Java based compiler compiler in an interactive environment) – интерактивный компилятор компиляторов – предназначен для анализа цепочек языка программирования на основе их описаний на лексическом, синтаксическом уровнях и синтеза путем построения текста объектной программы.
Основное окно Jaccie имеет вид (рис.9):



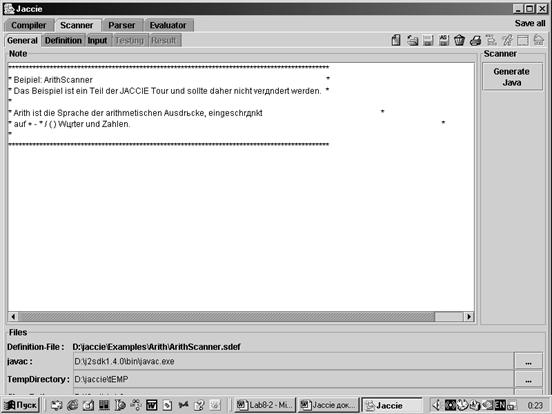
Рис. 9. Главное окно JACCIE
С помощью разделов можно переключаться между компилятором и его компонентами.
Для каждого раздела можно выбрать одну из его страниц:
· Определение (Definition) компоненты или всего компилятора.
· Загрузка и / или редактирование (Input) компоненты.
· Тестирование (Testing) компоненты.
· Просмотр (Result) результатов исполнения компоненты.
Выбранная комбинация раздела и страницы определяет содержимое текущей рабочей области.
Для каждой рабочей области имеется множество локальных функций, которые оперируют с ее данными. Они различны для каждой комбинации раздел/страница. Локальные кнопки доступны через кнопки или через меню.
Кроме этого имеются глобальные функции, которые одни и те же для любого раздела / страницы. Глобальные функции доступны через кнопки или через меню.
Имеются следующие глобальные функции:
· New : Создать новый файл.
· Open : Загрузить файл.
· Save : Сохранить файл.
· Save as : Сохранить файл с другим именем.
· Cancel: Отменить текущее состояние.
· Print : Печатать.
· Run : Выполнить компоненту.
Раздел Compiler содержит все данные, организованные как проекты.
Новые проекты (или сканеры, или синтаксические анализаторы, или генераторы) создаются с использованием глобальной функции New.
Лексический блок определяется с использованием регулярных выражений для каждого класса лексем.
Определение сканера в Jaccie имеет набор разделов, из которых обязательны Separators, Pattern, Token.
Определение сканера создается в рабочем пространстве Scanner /Definition (рис. 10).
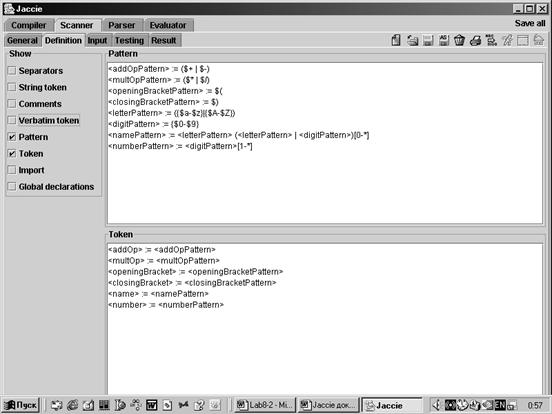
Рис. 10. Пример сканера в Jaccie
Раздел Separatots содержит служебное слово Standard.
Раздел Pattern содержит регулярные выражения.
Jaccie использует следующий синтаксис для регулярных выражений (табл. 2).
Таблица 2
Регулярное выражение | Название | Назначение |
<Имя> | Переменная | Имена шаблонов и лексем |
(a | b | c) | Альтернатива | Альтернативы содержат любое число регулярных подвыражений вида a, b, c соединенных знаками | ("или"). Круглые скобки не могут быть опущены! |
$a | Символ | Определяет один символ. |
ab | Объединение | Объединение регулярных подвыражений a и b. |
"abc" | Слово | Сокращение $a $b $c |
a[минимум-максимум] | Итерация 1 | t копий a где минимум <= t <= максимум. Минимум и максимум – натуральные числа (включая 0). |
a[минимум] | Итерация 2 | В точности минимум копий a. |
#xxx | ASCII код | xxx является ASCII кодом символа. |
#xxxx | Unicode | xxxx является Unicode символа. |
{x-y} | Множество | Диапазон символов, где x и могут быть символом, ASCII кодом или Unicode. |
( a ) | Скобки | Скобки обозначают приоритет. |
Каждое регулярное выражение должно располагаться на одной строке в следующем формате:
<Переменная>:= Регулярное выражение.
Важное замечание: только переменные, определенные в предыдущих строках, могут встречаться справа от знака :=.
Ниже показаны регулярные выражения для сканера арифметических выражений:
Definition of Patterns:
<addOpPattern> := ($+ | $-)
<multOpPattern> := ($* | $/)
<openingParenthesisPattern> := $(
<closingParenthesisPattern> := $)
<letterPattern> := ({$a-$z} | {$A-$Z})
<digitPattern> := {$0-$9}
<namePattern> := <letterPattern> ( <letterPattern> | <digitPattern> )[0-*]
<numberPattern> := <digitPattern>[1-*]
Лексемы (token) – это имена тех регулярных выражений, которые должны распознаваться сканером; остальные являются вспомогательными, которые служат для определения лексем. В случае одноименных регулярных выражений (например, ключевые слова и идентификаторы в языках программирования) определение, записанное ранее, имеет приоритет.
Ниже показаны лексемы лексического блока арифметических выражений:
Defiinition of Tokens: <addOp> := <addOpPattern> <multOp> := <multOpPattern> <openingParenthesis> := <openingParenthesisPattern> <closingParenthesis> := <closingParenthesisPattern> <name> := <namePattern> <number> := <numberPattern> |
В области Input вводится цепочка примера (рис. 11).
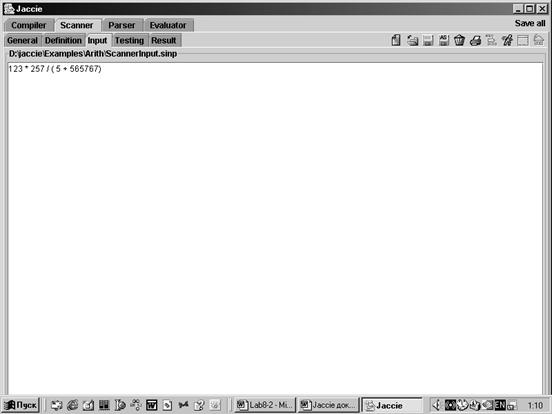
Рис. 11. Цепочка примера
Используя пиктограмму запуска (![]() ), применим лексический блок для входной цепочки. Ожидаемая последовательность лексем появляется в области Result (Рис. 12).
), применим лексический блок для входной цепочки. Ожидаемая последовательность лексем появляется в области Result (Рис. 12).
.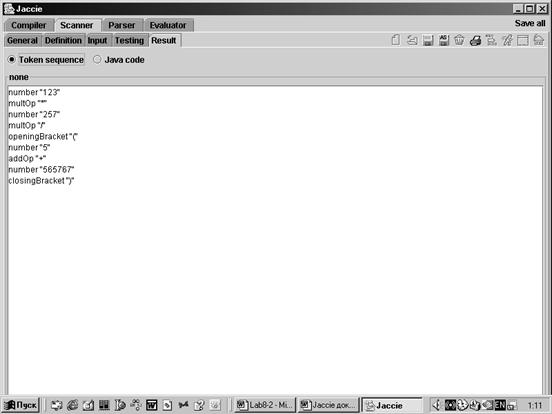
Рис. 12. Результаты работы сканера
В результатах работы сканера каждая лексема размещается в отдельной строке. Для того, чтобы понаблюдать работу сканера, используем область отладки (область Testing). Используя клавиши Action слева, можно управлять работой сканера, двигаясь в определенном направлении (вперед или назад) и темпом (по одному символу или по одной лексеме или до конца) (рис. 13).
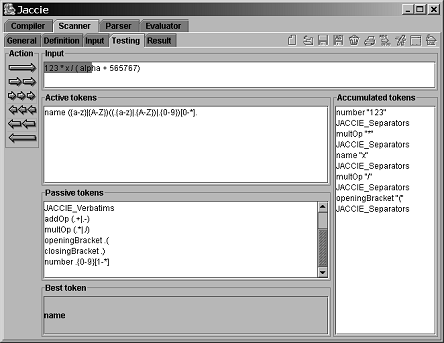
Рис. 13. Область отладки
В конце обработки входной цепочки вся последовательность лексем показана в области справа.
При возникновении ошибок в процессе сканирования появляется окно с сообщением(рис. 14).
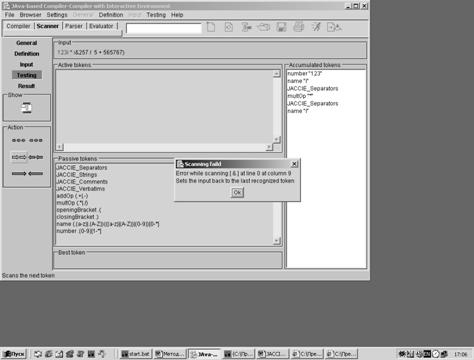
Рис. 14. Ошибка сканера
Нажатием кнопки ![]() (Save) можно сохранить исходный текст.
(Save) можно сохранить исходный текст.
7.. СИНТАКСИЧЕСКИЙ АНАЛИЗ
Формальной грамматикой G называется следующая совокупность четырех объектов: G = { Vт, VN, V40 ÎVN, P },
где Vт – терминальный алфавит; буквы этого алфавита называются терминальными символами; из них строятся цепочки, порождаемые грамматикой;
VN – нетерминальный, вспомогательный алфавит; буквы этого алфавита используются при построении цепочек; они могут входить в промежуточные цепочки, но не должны входить в результат порождения;
V0 – начальный нетерминальный символ грамматики
P – множество правил вывода или порождающих правил вида a®b, где a и b — цепочки, построенные из букв алфавита VтÈVN, который называют полным алфавитом грамматики Г.
В множество правил грамматики могут также входить правила с пустой правой частью вида a®e.
Символы из Vт встречаются только в правых частях правил; символы из VN могут встречаться и в левых, и в правых частях правил, но каждый символ из этого множества должен появиться в левой части хотя бы одного правила.
Среди правил может быть несколько правил с одинаковой левой частью вида a®b1, a®b2, …, a®bn. Такие правила записываются вместе в виде:
a®b1|b2|…|bn
Здесь записано n правил.
Такую форму записи правил называют формой Бэкуса-Наура. Нетерминальные символы, как правило, заключаются в угловые скобки.
При формальном описании цепочек принято нетерминальные символы обозначать заглавными латинскими буквами, а терминальные – малыми латинскими.
Пример грамматики для целых десятичных чисел со знаком:
Vт={8 9 - + $}
VN={<число>, <чс>, <цифра>}
V0=<число>
P:<число>®<чс>$|+<чс>$|-<чс> $
<чс>®<цифра>|<чс><цифра>
<цифра>®0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Использование правил с рекурсией позволяет конечным набором правил описать практически бесконечное множество цепочек языка. Рекурсия выражается в том, что один из нетерминальных символов определяется сам через себя. Чтобы рекурсия не была бесконечной, для определяемого ею нетерминального символа должны быть правила (хотя бы одно) без рекурсии.
Вывод в грамматиках и правила построения дерева вывода
Выводом называют процесс порождения цепочек языка на основе правил грамматики. Цепочка b=d1gd2 называется непосредственно выводимой из цепочки b=d1wd2 , если в грамматике существует правило w®g. Непосредственная выводимость обозначается aÞb.
Цепочка b называется выводимой из a (обозначение aÞ*b), если выполняется одно из двух условий:
§ aÞb
§ существует цепочка g такая, что aÞ*g и gÞb
Множество конечных цепочек терминального алфавита Vт грамматики G, выводимых из начального символа V0, называется языком, порождаемым грамматикой G и обозначается L(G).
Пример вывода:
G9:
Vт = { i, +, * , (, ) }, VN = {E, T, F} V0 = E
P ={ E ®E +T, E®T, T®T*F, T® F, F® (E), F® i },
Вывод E ÞE +T Þ T +TÞ T *F +TÞF *F +T Þ i * F +T Þ i * i +TÞi * i +F Þ i * i + i
Если в процессе построения вывода появляются промежуточные цепочки, содержащие несколько нетерминальных символов, то можно продолжать вывод, заменяя любой из них. Таким образом, одни и те же правила могут быть использованы при выводе цепочки в разном порядке.
Например, вывод цепочки i + i в грамматике G может быть получен десятью различными способами.
Правило вида A®aA, где AÎVN, aÎ(VтÈVN)*, называется праворекурсивным, а правило вида A ® Aa – леворекурсивным.
Для каждой КС-грамматики G, содержащей леворекурсивные правила, можно построить эквивалентную грамматику G', не содержащую леворекурсивных правил.
Правило вида A ® e называется аннулирующим правилом.
Чтобы сделать процесс вывода наглядным, его изображают в виде дерева, которое называют деревом вывода. Учитывая, что вывод любой цепочки языка, принадлежащей языку, порождаемому заданной грамматикой, должен начинаться с начального символа, правила построения дерева можно сформулировать так:
1) В качестве начальной вершины или корня дерева возьмем вершину, которую обозначим начальным символом грамматики S0; эта вершина образует нулевой ярус дерева;
2) Если при выводе цепочки на очередном шаге используется правило грамматики A®a и вершина, помеченная нетерминалом A, расположена на ярусе с номером k-1, то к построенному дереву нужно добавить столько вершин, сколько содержится символов в цепочке a, расположить эти вершины на ярусе k, обозначить их символами цепочки a и соединить эти вершины дугами с вершиной A.
Результатом вывода является множество конечных узлов – листьев, которые выписываются при обходе дерева слева – вниз – направо – вверх. Рассмотрим, например, грамматику:
Vт = {a, b}, VN = { S0},
P = { S0 ® a S0b, S0 ® ab }.
Вывод цепочки с помощью правил этой грамматики имеет вид
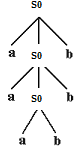
Следует отметить, что различным выводам цепочки в грамматике соответствует одно и то же синтаксическое дерево.
Вывод цепочки с помощью правил грамматики может быть задан не только в виде синтаксического дерева. Если пронумеровать правила грамматики, то последовательность номеров используемых правил также задает вывод.
Последовательность номеров правил грамматики G, применение которых позволяет построить вывод рассматриваемой цепочки a из начального символа грамматики, называется синтаксическим разбором a.
Например, в грамматике G, правила которой пронумерованы,
G:
Vт = { i, +, * , (, ) }, VN = {E, T, F} V0 = E
P ={ (1) E ®E +T, (2) E ®T, (3) T ® T *F, (4) T ®F, (5) F ® (E), (6) F ® i },
вывод
E® E +T® T +T® T *F +T® F*F +T® i * F +T® i * i +T ® i * i +F ® i * i + i
имеет синтаксический разбор [1,2,3,4,6,6,4,6].
Левый и правый вывод
Среди всевозможных выводов наибольший интерес представляют следующие два типа выводов:
Если при построении вывода цепочки a при каждом применении правила заменяется самый левый нетерминальный символ, то такой вывод называется левым выводом a.
Если при построении вывода a всегда заменяется самый правый нетерминальный символ промежуточной цепочки, то вывод называется правым выводом a.
Например, приведенный выше вывод цепочки i * i + i является левосторонним выводом.
Способ построения дерева по заданной цепочке от корня к листьям называется нисходящим.
В основе восходящего способа построения дерева лежит операция свертки, которая применяется к цепочке, полученной с помощью правого вывода. Эта операция является противоположной выводу. Она заключается в том, что правая часть правила заменяется левой частью. При работе восходящий распознаватель переносит символы входной цепочки в стек и, когда в нем оказывается правая часть какого-либо правила, осуществляет операцию свертки. Эту операцию можно определить следующим образом: каждый шаг рассмотренной процедуры связан с выделением в цепочке правой части какого-либо правила и заменой его левой частью правила.
В последовательности сверток правые части правил называются основой рассматриваемой цепочки.
Задача распознавания принадлежности данной цепочки языку, порождаемому грамматикой G, может быть сформулирована следующим образом: если из заданной цепочки с помощью операции свертки можно получить начальный символ грамматики, то такая цепочка может быть построена с помощью правил заданной грамматики, и, следовательно, она принадлежит языку, порождаемому этой грамматикой.
Например, свертка цепочки, полученной с помощью правого вывода и правил следующей грамматики
G:
Vт = { a, (, ) }, VN = {E, R} V0 = E
P =(1) E ®a (2) E® (ER (3) R® ,ER, (4) R ® )
можно представить так:
(a,a) <= 1(E,a) <= 1 (E, E) <= 4(E, ER <= 3 (ER <= 2 E
(основа подчеркнута)
8. СИНТАКСИЧЕСКИЙ АНАЛИЗ С ПОМОЩЬЮ JFLAP
Выбрав пункт основного меню Grammar, мы попадаем в окно редактора грамматик (рис. 15).

Рис. 15. Редактор правил jflap
Каждая строка таблицы соответствует одному правилу. Стрелка появляется автоматически. Каждый символ грамматики изображается одним символом, заглавные буквы – нетерминалы, малые – терминалы. Нетерминал левой части первого правила считается начальным нетерминальным символом.
В примере грамматика имеет множество нетерминалов {E, T, F}и множество терминалов {i,*,+,(,)}. Начальный нетерминал E.
После набора в редакторе пустая правая часть правила заменяется символом λ.
Вид окна редактора набора правил после набора грамматики (рис. 16).
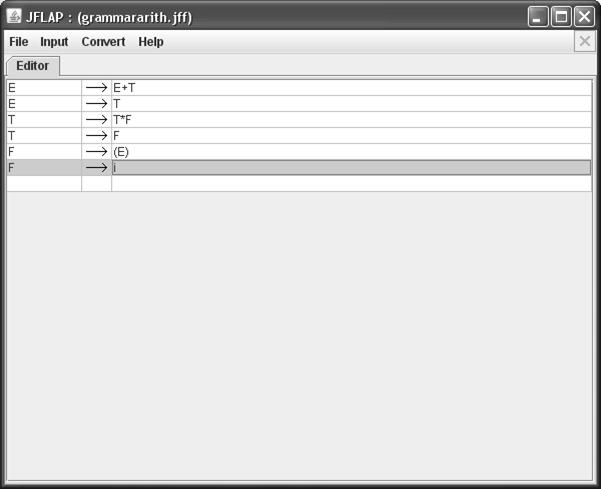
Рис. 16. Окно jflap после ввода грамматики
После набора грамматика может быть сохранена в файле.
9. ПРОВЕРКА ПРАВИЛЬНОСТИ ЦЕПОЧКИ
Можно проверить выводимость цепочки с помощью пункта меню Input, Brute Force Parser
При этом попадаем в окно (рис 17).
В поле Input набирается пример цепочки грамматики. При нажатии кнопки Start делается полный перебор по грамматике и, если цепочка недопустима, она отвергается. Если же цепочка допустима, начинается построение дерева вывода. Нажатие кнопки Step позволяет выстраивать его по уровням (рис. 18). :
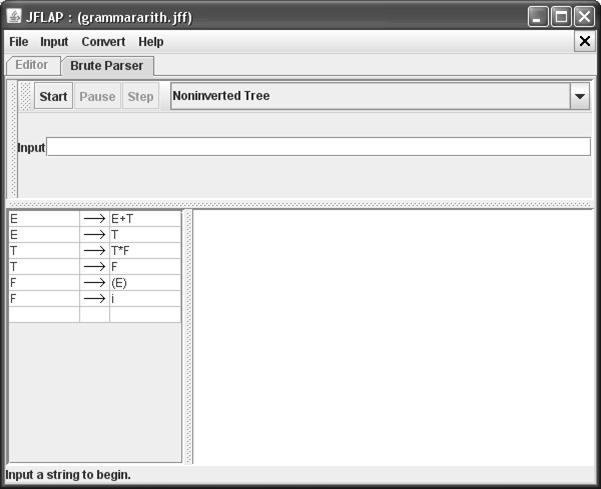
Рис. 17. Окно для проверки цепочки по грамматике
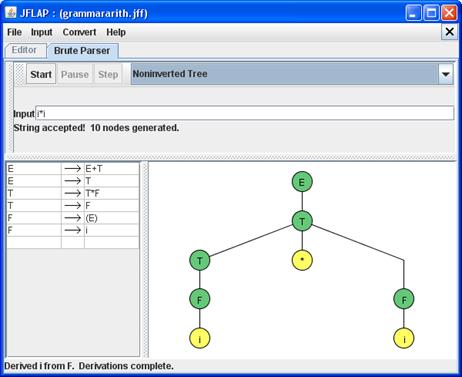
Рис. 18. Дерево вывода для цепочки
9. СИНТАКСИЧЕСКИЙ АНАЛИЗ В JACCIE
В окне Parser/Definition определяется контекстно-свободная (КС) грамматика языка (рис. 20).

Рис. 20. Окно определения КС-грамматики
Поля Nonterminals и Terminals грамматики содержат список терминалов и нетерминалов. Терминалы совпадают с лексемами из блока лексического анализа. Для работы с каждым полем используется контекстное меню.
Так, контекстное меню для нетерминалов содержит пункты:
· New nonterminal. Ввод имени нового нетерминала
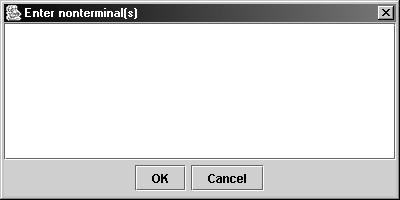
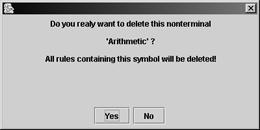
· Delete. Удаление текущего нетерминала (и всех правил, содержащих этот нетерминал – поэтому будьте внимательны!)
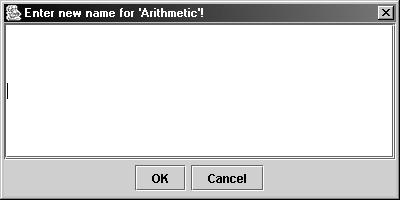
· Rename. Переименование нетерминала:
· Use as startsymbol Определение текущего нетерминала как начального нетерминального символа грамматики. Начальный нетерминал помечается зеленым кружком.
Подобное контекстное меню есть у поля Terminals:
· New terminal. Ввод имени нового терминала
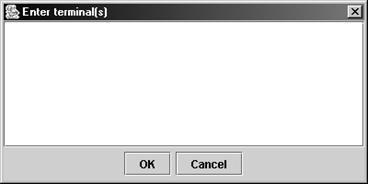
· Delete. Удаление текущего терминала (и всех правил, содержащих этот терминал – поэтому будьте внимательны!)
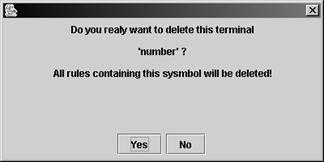
· Rename. Переименование терминала:
Правила вывода для всех нетерминалов видны в поле Rules (рис. 21).





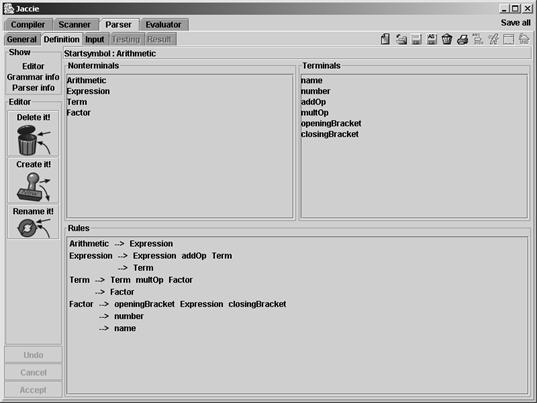
Рис. 21. Окно Parser программы Jaccie
Альтернативы сгруппированы в порядке записи нетерминалов (левая xасть правила показана только для первой альтернативы). Нетерминалы и терминалы могут быть переупорядочены с помощью перетаскивания. Таким же образом могут быть переупорядочены альтернативы.
Подобным образом можно использовать перетаскивание для переименования символов и для создания и удаления символов и альтернатив. Переименование автоматически применяется для вхождения символа во все правила.
Простейший способ запустить детерминированный парсер – переместиться в область Parser-Input, загрузить некоторую входную цепочку (результат работы сканера) и затем нажать пиктограмму Run (![]() ). Результат работы синтаксического блока – синтаксическое дерево в текстовом представлении – появится в области Parser-Result (рис. 22).
). Результат работы синтаксического блока – синтаксическое дерево в текстовом представлении – появится в области Parser-Result (рис. 22).

Рис. 23. Синтаксическое дерево в текстовом представлении
В текстовом представлении каждый узел дерева показан в отдельной строке. Структура дерева визуализируется с помощью сдвигов: ниже любого узла размещается его (слева направо) поддеревья (сверху вниз).
Справа от любого терминального символа (соответствующего лексеме) показана исходная строка, например, за лексемой number следует - string: "8".
Так как в этом режиме показаны только входная последовательность лексем и выходное дерево, перейдем в область Parser-Testing, где можно контролировать и просматривать процесс анализа в деталях.
Элементы управления в левой стороне окна позволяют изменять уровень пошагового выполнения. Основные элементы управления – кнопки на панели Action, которые позволяют направлять анализ вперед или назад, или на один шаг, или до конца. Те части дерева, которые были уже построены, изобразятся графически на панели Tree.
10. ТРАНСЛЯЦИЯ АРИФМЕТИЧЕСКИХ ВЫРАЖЕНИЙ/
БЕССКОБОЧНЫЕ ВЫРАЖЕНИЯ
На практике трансляция арифметических выражений происходит в два этапа:
· Преобразование арифметического выражения в постфиксную запись;
· Вычисление постфиксных выражений.
Обычные арифметические выражения, содержащие скобки, называют инфиксными выражениями, поскольку знак операции располагается между операндами. Порядок выполнения действий в таких выражениях определяется старшинством операций и скобками. Вычисление и компиляция таких выражений подразумевает их предварительный анализ с целью выявления порядка выполнения операций. Существуют формы записи арифметических выражений без скобок, в которых порядок действий задается порядком знаков операций в выражении. Такие формы записи называются польской или бесскобочной записью. Польская запись может быть префиксной, в которой знак операции предшествует операндам, и постфиксной, в которой знак операции следует за операндом. Вычисление и компиляция бесскобочных выражений оказывается проще, чем выражений со скобками, поскольку операции должны выполняться в порядке описания и предварительный анализ не требуется.
Рассмотрим выражение ((( A - В) * С )+(D / ( Е**F ))).![]()
Возможно описание арифметического выражения с помощью двоичного дерева (рис. 24). Заметим, что все конечные вершины этого дерева соответствуют операндам (переменным или константам), а все внутренние вершины соответствуют арифметическим операциям.

Рис. 24. Двоичное дерево для примера
Интересно заметить, что три различных способа обхода деревьев приводят к трем различным способам записи соответствующих выражений в виде линейной последовательности символов.
Рассмотрим дерево простого арифметического выражения (А+В).
Если мы начнем с корня или верхней точки (Т) этого дерева и напечатаем +, затем перейдем к левой (L) нижней вершине и напечатаем А, а далее перейдем обратно в корень и спустимся вправо (R) и напечатаем В, мы пройдем дерево в прямом порядке.
Последовательность напечатанных символов +АВ называется префиксной формой арифметического выражения; знак операции (+) предшествует операндам А и В.
Более привычная форма арифметического выражения (А+В) называется инфиксной формой; она получается при прохождении дерева в обратном порядке, обозначаемом LTR.
Постфиксная форма арифметического выражения – та, в которой знак операции следует за операндами, например АВ+, получается при концевом порядке (LRT) прохождения дерева (рис. 25).

Рис. 25. Три различных обхода двоичного дерева
и соответствующие выражения
Здесь будет поучительно рассмотреть снова вышеприведенное дерево.
Для прохождения этого дерева в прямом порядке мы начнем с самой верхней вершины ТОР (помеченной +). Затем пройдем в прямом порядке левое поддерево (с корнем, помеченным *) и далее правое поддерево в прямом порядке (с корнем, помеченным /). Прохождение левого поддерева в прямом порядке начинается с корня (помеченного *), затем следует прямое прохождение левого его поддерева (порождающее последовательность -АВ) и далее правого поддерева (последовательность С). Поэтому вся последовательность, порождаемая прохождением левого поддерева вершины ТОР, будет *— АВС. Аналогично прохождение в прямом порядке правого поддерева с корнем, помеченным /, порождает последовательность /D**EF. Таким образом, прохождение всего дерева в прямом порядке порождает последовательность
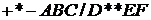 .
.
Прохождение этого дерева в обратном и концевом порядках порождает последовательности соответственно
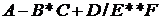 (инфиксная);
(инфиксная);
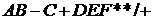 (постфиксная).
(постфиксная).
Заметим, что во всех трех выражениях порядок вхождения переменных совпадает; меняется только порядок знаков операций. Заметим также, что ни одно из этих выражений не имеет скобок, и, таким образом, если не заданы правила приоритета, значение приведенного выше выражения в инфиксной форме нельзя вычислить однозначно.
Постфиксная запись
Постфиксная запись выражения Е индуктивно определяется следующим образом:
1. Если Е – переменная или константа, то постфиксная запись Е есть Е.
2. Если Е – выражение типа Е1 op Е2 (op – произвольный бинарный оператор), то постфиксная запись Е есть Е11 Е21 op, где Е11 и Е21 – постфиксные записи для Е1 и Е2.
3. Если Е – выражение вида (Е1), то постфиксная запись Е есть постфиксная запись для Е1.
Например, по входной цепочке (a+b) * (c-d) будет построена выходная цепочка ab+cd-*
Вычисление постфиксных выражений.
Этот этап состоит из следующих шагов:
1. Прочитать очередной символ входной цепочки.
2. Если входной символ — операнд, то выполнить его запись в стек.
Если входной символ — операция, то прочитать два операнда из стека, выполнить операцию и результат занести в стек как операнд.
3. Повторять п.1, пока во входной цепочке не будут прочитаны все символы.
Последовательность вычислений продемонстрируем на примере входной цепочки ab+cd-* и изобразим ее в виде следующей схемы:
Вход Стек Операция
ab+cd-*
1. b+cd-* a
2. +cd-* ab
3. cd-* R1 a+b=R1
4. d-* R1c
5. -* R1cd c-d=R2
6. * R1R2 R1*R2 = R3
7. $ R3
12. АБСТРАКТНАЯ СТЕКОВАЯ МАШИНА
Такая машина выполняет операции промежуточного языка. Она имеет память и стек. Все арифметические выражения вычисляются над значениями в стеке. Операции делятся на 6 групп:
1. Целая арифметика.
2. Работа со стеком.
3. Управление исполнением.
4. Логические выражения.
5. Ввод-вывод.
6. Размещение переменных.
Целая арифметика
Вычисление производится путем просмотра постфиксного представления слева направо, при этом каждый операнд помещается в стек. Если встречается k-арный оператор, то k значений извлекаются из стека и над ними производится операция, результат которой помещается в стек.
Арифметические операции:
ADD, SUB, DIV, MULT
При рассмотрении оператора присваивания вида
A:=B
левая часть является l-значением (адресом памяти), а правая часть – r-значением (значение)
Работа со стеком
Операции:
PUSH V Поместить V в стек.
POP Взять значение с вершины стека.
RVALUE L Поместить в стек содержимое памяти по адресу L.
LVALUE L Поместить в стек адрес ячейки памяти L.
:= Значение из вершины стека размещается по адресу, представленному l-значением, следующим за ним в стеке; обе величины после этого удаляются из стека.
Например, выражение
(1461*y)/4 +(153-m+2)/5+d
транслируется в код:
PUSH 1461 | DIV | PUSH 2 | RVALUE D |
RVALUE Y | PUSH 153 | ADD | ADD |
MULT | RVALUE M | PUSH 5 | |
PUSH 4 | SUB | DIV |
Управление исполнением
Операции:
LABEL L Вставка метки в стек.
GOTO L Следующая выполняемая команда – по адресу L.
GOFALSE L Взять значение с вершины стека и осуществить переход по адресу L, если оно нулевое.
GOTRUE L Взять значение с вершины стека и осуществить переход по адресу L, если оно единичное.
HALT Прекратить выполнение.
Логические выражения
Операции:
<.<=,>,>=,=,<> AND, OR, NOT
Ввод-вывод
IN ввод с клавиатуры в стек
OUT вывод из стека на экран
Размещение переменных
Операторы
Имя DW значение размешает в памяти целое число длиной в слово.
Имя DB значение размешает в памяти целое число длиной в байт.
Имя DD значение размешает в памяти вещественное число длиной в двойное слово.
Имя число DB значение размешает в памяти строку указанной длины
Пример. Необходимо для примера цепочки заданной конструкции записать последовательность команд стековой машины. Так, например, для цепочки
do { op1; op2;} while (a * b + 3 >= c);
получаем следующую последовательность команд:
LABEL 1:
PUSH OP
PUSH OP
POP
POP
RVALUE a
RVALUE b
MUL
PUSH 3
ADD
RVALUE c
>=
GOTRUE LABEL 1
HALT
Список используемой литературы
1. Трансляция языков программирования: синтаксис, семантика, перевод. Режим доступа:
http://public. uic. *****/~skritski/scourses/Transl/index. html
2. Языки и трансляции. - Петербургского университета. Режим доступа:
http://www. math. *****/htmlsources/user/mbk/TUTORY/LT. html
3. Формальные языки, грамматики и автоматы. Режим доступа: http://www. *****/misc/edu/section1/Course1.htm
Учебное издание
Системное программное обеспечение
Сосинская
Программа, методические указания
Редакторы
