


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Булдакова Галина гр. 4201
Система извлечения фактографических данных из документов на основе формальной структуры текста
Введение в проблемную область
Исследования ведущих аналитиков показывает, что совокупный объем цифровой информации в 2006 году составил 161 миллионов гигабайт. Предполагается, что за период с 2006 по 2010 год объем информации увеличится более чем в шесть раз. В более чем 80% случаев такая информация является неструктурированной - это тексты естественного языка. Человеку становится все труднее ориентироваться в потоках поступающей информации. В связи с этим при обработке информации требуются новые инновационные подходы, ориентированные на задачи конкретных пользователей.
Большая категория пользователей имеют определенные служебные обязанности, и соответственно, постоянные интересы. Им необходима вполне конкретная информация. Например, сотрудники информационно-аналитических подразделений выбирают из СМИ информацию об интересующих их событиях, катастрофах, террористических актах, персоналиях и др. Следователю важны фигуранты, места их жительства, телефоны, криминальные события, даты и др. Сотруднику кадровой службы нужно знать организации, где, кем и в какое время кандидат работал.
Для обеспечения подобных пользователей нужной информацией требуются средства автоматического извлечения фактов из текстов с их представлением в формах, удобных для восприятия или последующей обработки. Это проблемная область, которая находится в сфере внимания исследователей. Ее актуальность постоянно растет.
К наиболее актуальным средствам интеллектуального анализа текстов относятся технологии выделения фактографической информации об объектах с учетом анафорических ссылок на них; нечеткий поиск; тематическое и тональное (точное и полное) рубрицирование; кластерный анализ хранилищ и подборок документов; выделение ключевых тем; построение аннотаций; построение многомерных частотных распределений документов; использование методов интеллектуального анализа текста для определения направления исследования больших подборок документов и извлечения новых знаний.
В современных системах используется двухфазная технология аналитической обработки. В первой фазе производится автоматизированный анализ отдельных документов, структуризация их контента и формирование хранилищ исходной и аналитической информации. Во второй фазе – извлечение в оперативном режиме знаний из хранилища или из полученной по запросу подборки документов.
Описание системы
В качестве решения поставленной задачи было предложено построить систему из четырех основных блоков:
§ Блок редактирования, в котором эксперт заранее редактирует необходимые для работы данные;
§ Блок, обеспечивающий работу со словарем (словарная подсистема);
§ Блок, отвечающий за работу с базой данных информационных объектов;
§ Блок сборки фактов.
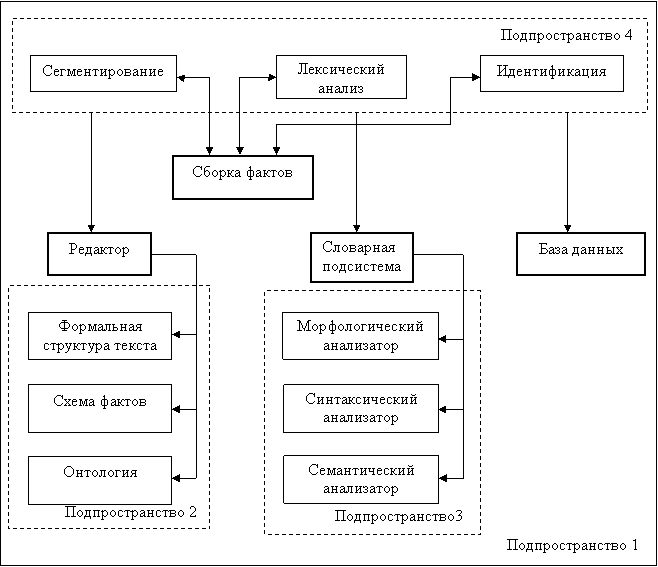 Эти блоки выделены в отдельное подпространство «Подпространство1». Объекты, при помощи которых осуществляется связь между компонентами Подпространства1 выделены в «Подпространство4».
Эти блоки выделены в отдельное подпространство «Подпространство1». Объекты, при помощи которых осуществляется связь между компонентами Подпространства1 выделены в «Подпространство4».
Рис.1 Общая схема системы автоматического извлечения фактов.
В данной системе работу инициирует блок сборки фактов, поэтому в качестве активного элемента или субъекта будет выступать именно он. А словарная подсистема и редактор выступают в качестве объектов.
Объект «Сборка фактов» используется для генерации исполняемых правил, созданных на основе схем фактов, для организации очереди этих правил, поиска фактов в заданном сегменте, создания и редактирования информационных объектов, а так же для вывода результатов.
Объект «Редактор» нужен для редактирования формальной структуры текста входного документа, схем фактов, онтологии, проверки корректности сделанных описаний.
Объект «Словарная подсистема» обеспечивает создание словаря и предварительную обработку текста (морфологический, синтаксический и семантический анализы).
Объект «База данных» используется для корректного взаимодействия с базой данных информационных объектов (добавление, удаление, изменение, поиск элементов).
В подпространство 2 выделены объекты, входящие в состав «Редактор»:
§ «Формальная структура текста» - объект, основными функциями которого является получение информации о стиле документа, о его строках, абзацах, предложениях, жанре;
§ «Схема факта» - объект, который нужен для определения структуры факта (типа факта, информационных объектов документа, понятия онтологии) и условий его выявления;
§ «Онтология» - объект, который определяет, какие данные необходимо извлечь из документа и поместить в базу данных системы.
В подпространство 3 выделены объекты, входящие в состав «Словарная подсистема»:
§ «Морфологический анализатор» - определение нормальных форм отдельных слов, получение набора значений словоизменительных морфологический признаков для них;
§ «Синтаксический анализатор» - определение синтаксической структуры предложений;
§ «Семантический анализатор» - выделение информационных объектов, их характеристик, определение связей между ними.
В подпространстве 4 находятся следующие объекты:
§ «Сегментирование» - на основе формальной структуры текста, схемы фактов и онтологии, созданных с помощью редактора, происходит сегментирование входного текста на отдельные компоненты (строковые объекты), упорядоченные по мере их встречаемости;
§ «Лексический анализ» - осуществляет извлечение словарных объектов (лексических конструкций, слов или словокомплексов, заданных в словаре) из набора упорядоченных строковых объектов. Лексический анализ осуществляется на основе информации, полученной из словарной системы после проведения предварительных анализов;
§ «Идентификация» - поиск в базе данных и идентификация объекта, найденного в тексте документа, разрешение омонимии, возникающей, когда в базе данных найдено несколько информационных объектов соответствующих объекту, найденному в тексте.
Так как данная система состоит из нескольких отдельных компонент, можно выделить протоколы взаимодействия между компонентами:
- Протокол взаимодействия с базой данных – отправление запросов, получение результатов;
- Протокол взаимодействия с пользователем (экспертом) – редактирование формальной структуры текста, схем фактов, онтологии при помощи графического интерфейса;
- Протокол взаимодействия с объектами «Сегментация» и «Лексический анализ» - запросы о результатах работы на предварительных этапах объектов «Редактор» и «Словарная подсистема соответственно».
- Протокол взаимодействия с работающей системой – запуск системы, выключение системы.
Система извлечения фактографических данных из документов на основе формальной структуры текста является информационно замкнутой, поскольку ее действия не затрагивают другие компоненты системы, в рамках которой она работает, а так же не вносят изменений в состояния объектов, внешних по отношению к данной системе.
