
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Про циклы в одну строку
Первым номером нашей программы выступает код добавления (копирования) строк из одной таблицы значений в другую ТЗ или из одной табличной части в другую ТЧ. Ну, и т. д. Т. е. строки из обоих источников объединяются, совпадающие по имени колонки заполняются.
Для каждого СтрокаТЗ Из Таблица1 Цикл ЗаполнитьЗначенияСвойств(Таблица2.Добавить(), СтрокаТЗ) КонецЦикла;
Соответственно код добавления элементов из массива в массив будет такой.
Для каждого ЭлементМассива Из Массив1 Цикл Массив2.Добавить(ЭлементМассива) КонецЦикла;
Всего одна команда в цикле - что может быть проще?
Наверное, вы уже обратили внимание на запись циклов в одну строку. Так программный код выполняется несколько быстрее. Всё дело в том, что в строках есть дополнительные данные, которые используются, например, при отладке. Меньше строк - меньше дополнительных данных. Это прекрасно видно, если смотреть замер производительности в режиме отладки - цикл в строке Для из 10000 повторов записанный обычной структурой будет выполнен 10001 раз, а записанный в 1 строку будет выполнен 1 раз. Разумеется, что при этом результат выполнения программного кода будет абсолютно одинаковый, а вот время выполнения будет разное. Смотрим "Пример 1".
Скачать Пример 1...
Следует заметить, что править такую форму записи очень сложно. Поэтому, если команды отрабатываются 1 раз, то нет особого смысла записывать их в 1 строку друг за другом.
Также "тонким" моментом будет использование команды ОбработкаПрерыванияПользователя(). Если в цикле, записанном в 1 строку, используется данная команда, то вероятность срабатывания прерывания выполнения программы по Ctrl+Break становится не четким. Ну, может за исключением тех случаев, когда в цикле кроме этой других команд нет. ![]()
Хочу сразу обратить ваше внимание на комментарии awa к этой статье. Всё сразу станет понятнее.
Про быстрые массивы
Теперь посмотрим что-нибудь простенькое. Например, разбор строки с разделителями в массив элементов. В типовых конфигурациях есть функция РазложитьСтрокуВМассивПодстрок(). Предлагаю рассмотреть альтернативное решение. Вот код для строковых значений.
// РазбираемаяСтрока - строка исходного текста
// Разделитель - разделитель элементов строки
ЗначениеИзСтрокиВнутр("{""#"",51e7a0d2-530b-11d4-b98a-008048da3034,{0,{""S"",""" + СтрЗаменить(СтрЗаменить(РазбираемаяСтрока, """", """"""), Разделитель, """},{""S"",""") + """}}}");
Вот код для числовых значений.
ЗначениеИзСтрокиВнутр("{""#"",51e7a0d2-530b-11d4-b98a-008048da3034,{0,{""N""," + СтрЗаменить(РазбираемаяСтрока, Разделитель, "},{""N"",") + "}}}");
Посмотреть, как это работает можно здесь, здесь и здесь.
В одном из комментариев к статье было высказано предположение, что данный метод не эффективен, поэтому был добавлен "Пример 7".
Скачать Пример 7...
Так, так, так. А вот довольно шустренький программный код для сворачивания элементов массива. Результат записывается в НовыйМассив.
НовыйМассив = Новый Массив; Соответствие = Новый Соответствие;
Для каждого ЭлементМассива Из Массив Цикл Соответствие. Вставить(ЭлементМассива) КонецЦикла;
Для каждого КлючИЗначение Из Соответствие Цикл НовыйМассив. Добавить(КлючИЗначение. Ключ) КонецЦикла;
Для сравнения в "Пример 4" приведено 4 варианта реализации сворачивания массива: через массив, через таблицу значений, через соответствие и вариант, реализованный в типовых конфигурациях 1С. Поэкспериментируйте и выберите тот, что вам больше понравится.
Скачать Пример 4...
Если вдруг понадобится отсортировать элементы в массиве, то это можно сделать так:
СписокЗначений = Новый СписокЗначений;
СписокЗначений. ЗагрузитьЗначения(Массив);
СписокЗначений. СортироватьПоЗначению();
Массив = СписокЗначений. ВыгрузитьЗначения();
В некоторых случаях больше подойдет сортировка не по значению, а по представлению.
Про длинные строки
Получить строку из пробелов нужной длины можно собирая пробелы в цикле. Но можно использовать следующую конструкцию:
// Получаем строку пробелов длиной 10000 символов
СтрокаПробелов = СтрЗаменить(Формат(0, "ЧЦ=100; ЧН=; ЧВН=; ЧГ="), "0",
СтрЗаменить(Формат(0, "ЧЦ=100; ЧН=; ЧВН=; ЧГ="), "0", " "));
Интересное наблюдение при работе со строками большой длины можно сделать в "Пример 5". Использование трехуровневой буферизации может дать ускорение в десятки и даже тысячи раз. Код может выглядеть так:
Данные = "";
Результат = "";
Результат1 = "";
Результат2 = "";
// Получаем Данные и записываем в Результат
Пока ПолучитьДанные(Данные) Цикл
Результат2 = Результат2 + Данные;
Если СтрДлина(Результат2) > 100 Тогда
Результат1 = Результат1 + Результат2;
Результат2 = "";
Если СтрДлина(Результат1) > 10000 Тогда
Результат = Результат + Результат1;
Результат1 = "";
КонецЕсли;
КонецЕсли;
КонецЦикла;
Результат = Результат + Результат1 + Результат2;
Конечно, и здесь цикл можно записать в одну строку, но это не сделано только для сохранения читаемости программного кода в статье.
Скачать Пример 5...
Если вы подумали, что эта статья об оптимизации производительности, то это не так. Точнее не совсем так. Статья об оптимизации производительности здесь, и не смотря на то, что статья посвящена 7.7, многие приемы оптимизации работают и в 8.х.
Про хитрые запросы
А что сейчас? А сейчас запросы. Не все конечно, а несколько каких-нибудь простеньких и интересненьких. Например, построение запросом двухуровневого дерева структуры задолженности для формы элемента справочника Контрагенты. Исходим из того, что чем меньше команд, тем быстрее работает. Ну, обычно быстрее. Ведь 1С это все-таки интерпретатор.
Итак, строим запросом дерево по структуре задолженности как на картинке ниже, смотрим закладку Задолженность. На закладке добавлено табличное поле с деревом значений Задолженность.
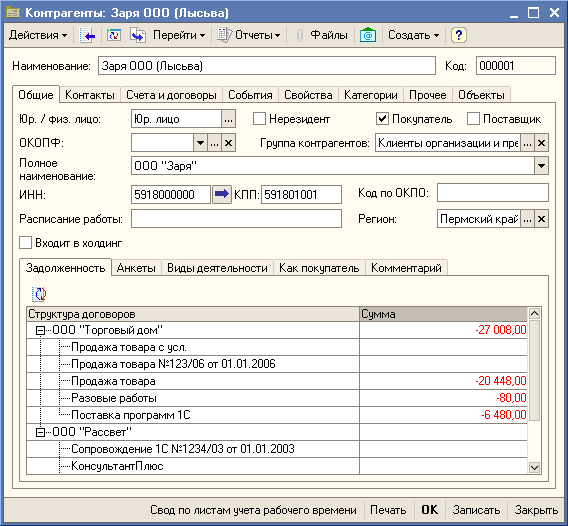
Получаем в детальных строках договоры контрагентов, а в итоговых строках организации. Приведенный ниже в качестве примера программный код будет работать в УТ и УПП. Для остальных конфигураций код запроса нужно немного подправить.
Запрос = Новый Запрос(
"ВЫБРАТЬ РАЗРЕШЕННЫЕ
| ДоговорыКонтрагентов. Организация КАК Организация,
| ДоговорыКонтрагентов. Ссылка КАК СтруктураДоговоров,
| - ЕСТЬNULL(ВзаиморасчетыОстатки. СуммаВзаиморасчетовОстаток, 0) КАК Сумма
|ИЗ
| Справочник. ДоговорыКонтрагентов КАК ДоговорыКонтрагентов
| ЛЕВОЕ СОЕДИНЕНИЕ РегистрНакопления. ВзаиморасчетыСКонтрагентами. Остатки(
| , Контрагент = &Контрагент) КАК ВзаиморасчетыОстатки
| ПО ДоговорыКонтрагентов. Ссылка = ВзаиморасчетыОстатки. ДоговорКонтрагента
|ГДЕ
| ДоговорыКонтрагентов. Владелец = &Контрагент
|
|УПОРЯДОЧИТЬ ПО
| Организация,
| СтруктураДоговоров
|ИТОГИ
| Организация КАК СтруктураДоговоров,
| СУММА(Сумма)
|ПО
| Организация");
Запрос. УстановитьПараметр("Контрагент", Ссылка);
Задолженность = Запрос. Выполнить().Выгрузить(ОбходРезультатаЗапроса. ПоГруппировкам);
Получилось простенько и симпатично.
В итогах Организация используется без агрегатной функции - это возможно потому, что по Организации выполняется группировка. Ещё примеры построения двухуровневого дерева можно посмотреть здесь.
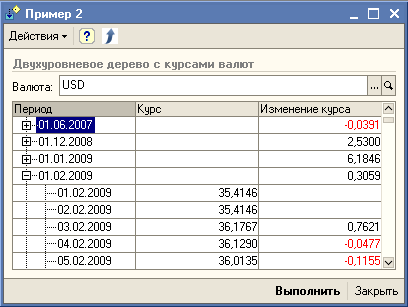
Кажется тема с запросами получилась интересной. Тогда ещё один примерчик "Пример 2", который можно подержать в руках - изменение курсов валют с группировкой по месяцам.
Запрос = Новый Запрос(
"ВЫБРАТЬ РАЗРЕШЕННЫЕ
| КурсыВалют. Период КАК Период1,
| МАКСИМУМ(ЕСТЬNULL(КурсыВалют1.Период, КурсыВалют. Период)) КАК Период2
|ПОМЕСТИТЬ Соединения
|ИЗ
| РегистрСведений. КурсыВалют КАК КурсыВалют
| ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений. КурсыВалют КАК КурсыВалют1
| ПО КурсыВалют. Валюта = КурсыВалют1.Валюта
| И КурсыВалют. Период > КурсыВалют1.Период
| И (КурсыВалют1.Валюта = &Валюта)
|ГДЕ
| КурсыВалют. Валюта = &Валюта
|
|СГРУППИРОВАТЬ ПО
| КурсыВалют. Период
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ РАЗРЕШЕННЫЕ
| КурсыВалют. Период КАК Период,
| НАЧАЛОПЕРИОДА(КурсыВалют. Период, МЕСЯЦ) КАК ПериодДляИтогов,
| КурсыВалют. Курс,
| КурсыВалют. Курс - КурсыВалют1.Курс КАК ИзменениеКурса
|ИЗ
| РегистрСведений. КурсыВалют КАК КурсыВалют
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ Соединения КАК Соединения
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений. КурсыВалют КАК КурсыВалют1
| ПО Соединения. Период2 = КурсыВалют1.Период
| И (КурсыВалют1.Валюта = &Валюта)
| ПО КурсыВалют. Период = Соединения. Период1
| И (КурсыВалют. Валюта = &Валюта)
|ИТОГИ
| ПериодДляИтогов КАК Период,
| СУММА(ИзменениеКурса)
|ПО
| ПериодДляИтогов");
Запрос. УстановитьПараметр("Валюта", Валюта);
КурсыВалют = Запрос. Выполнить().Выгрузить(ОбходРезультатаЗапроса. ПоГруппировкам);
Аналогично можно построить и другие запросы, в которых отслеживается изменение значений показателей, например, изменение цен.
Скачать Пример 2...
"Продолжаем разговор". В качестве ещё одного примера работы с запросами добавлен "Пример 3", в котором реализовано получение периодов действия установленных значений периодических регистров сведений. Перечитал предыдущее предложение - получилось немного тяжеловато, ну, да ладно. Предложенное решение в "Пример 3" может быть использовано, например, при решении задач по расчету заработной платы или при начислениях в ЖКХ.
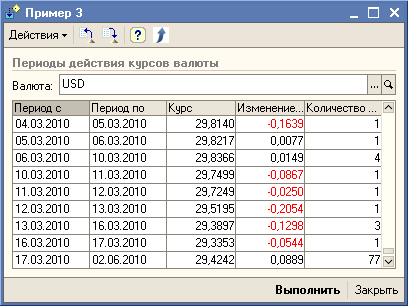
Фишка этого запроса в том, чтобы убрать повторяющиеся данные из цепочки, а оставить только точки перехода с датами, когда данный переход был выполнен.
Т. е. для цепочки значений 0, 0, 1, 1, 1, 0, 0, 0, 1
должны остаться только значения 0, 1, 0, 1 и соответственно даты, когда значения в цепочке поменялись.
И несколько слов об оптимизации. Во вложении 4 варианта реализации с использованием запросов, поэтому в статье текстов этих запросов нет - очень объемно получается. При больших объемах информации оптимизированный вариант запросов дает значительное ускорение, особенно в файловой версии. Это собственно и не удивительно, оптимизатор SQL сервера делает своё дело. Автором одного из вариантов является Ish_2 - это вариант "Гостинец".
Скачать Пример 3 без оптимизации...
Скачать Пример 3 с оптимизацией...
Скачать Гостинец от Ish_2...
Скачать Пример 3_3 (оптимизированный Гостинец)...
Суть оптимизации сводится к уменьшению количества записей используемых в соединениях, аналогами которых являются нарастающие итоги. Подробнее про подобный подход можно почитать здесь.
Также интересный эффект получается при использовании индексов для временных таблиц. Попробуйте поиграть с объемами данных и галочками "Использовать индексы в запросе". Обещаю весьма неожиданный результат. ![]()
Так уж получилось, что большинство комментариев к данной статье посвящено именно этому запросу. Видимо в нем есть тайное знание доступное теперь всем желающим.
Ещё про запросы можно посмотреть здесь, а про запросы с датами можно посмотреть здесь.
Про СКД и запросы с итогами
В комментариях к публикациям Как выгрузить итоги запроса в одну колонку? и Запросики для восьмерочки развернулась настоящая битва между Ish_2 и tango. Просто жуть какая-то. Но вопросы были подняты очень интересные. Я очень внимательно следил за ходом обсуждения и после очередного комментария с примером обработки от Ish_2, появилась обработка, которая демонстрирует построение многоуровнего дерева в одной колонке "Поле4" с использованием как запроса с итогами, так и СКД. За основу была взята обработка, приложенная к комментарию.

Ах, да. "В чем же фишка?" - спросите вы. Всё просто. Из СКД сложное многоуровневое дерево в дерево значений выгружается быстрее. На контрольном примере разница составила в 30 раз. При использовании запроса сам запрос выполняется сравнительно быстро, а вот скорость выгрузки результата запроса в дерево значений оставляет желать лучшего.
Так как программного кода как такового при использовании СДК нет, то не совсем очевиден способ реализации. Куда смотреть? Смотреть нужно в пользовательских полях.
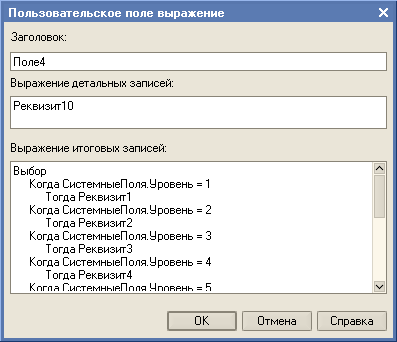
Собственно весь вывод данных в обработке при использовании СКД построен на пользовательских полях. Это сделано для того, чтобы сохранить нужную последовательность колонок в дереве значений. Если порядок следования реквизитов не важен или реквизиты не нужны в результирующем дереве значений, то и добавлять реквизиты в пользовательские поля не нужно.
Скачать Пример 8...
Но как вы, наверное, догадываетесь, "Пример 8" это не единственный вариант реализации многоуровневого дерева в одной колонке с использованием СКД. Поэтому был добавлен "Пример 9", в котором "Поле4" строится не через пользовательские поля, а через ресурсы. Чем он лучше варианта в "Пример 8"? Работает немного быстрее предыдущего примера и названия колонок в результирующем дереве значений получаются более "ожидаемые".
Особенностью реализации "Пример 9" является расположение ресурсов в группировках. Это сделано только для того, чтобы управлять порядком следования колонок в результирующем дереве значений. Иначе колонки с группировками будут расположены впереди, а уже за ними колонка "Поле4". Чтобы можно было управлять порядком расположения реквизитов необходимо вначале сформировать группировки по реквизитам, а затем реквизиты описать как ресурсы. При необходимости формирования определенного порядка следования колонок в результирующем дереве необходимо для некоторых группировок заменить состав выбранных полей с Авто на требуемый. Если порядок следования реквизитов не важен или реквизиты не нужны в результирующем дереве значений, то и добавлять реквизиты в ресурсы не нужно.
Скачать Пример 9...
Возможность выбора варианта реализации многоуровнего дерева в одной колонке дерева значений есть. В данной публикации приведено 4 способа. Выбирайте. Реализуйте.
Про работу с COMОбъект("V81.Application") или как разогнать 1С в 100 раз
Очень интересная публикация OLE - монитор автора ghostishe, в которой приложена обработка COM MONITOR. Мне как раз необходимо было сверить справочники в двух базах данных. В предложенной обработке всё понятно, но скорость получения данных из подключенной базы мне показалась крайне низкой. После небольшого эксперимента удалось получить такие же данные как в этой обработке, только в 30 раз быстрее, а после небольшой модификации удалось поднять скорость получения данных из подключенной базы ещё в 5 раз. Добавил "Пример 6". В предлагаемом примере разница во времени выполнения по сравнению с исходным образцом может составить от 50 до 200 раз - это зависит от состояния базы данных и от объема получаемых данных. Чем больше данных нужно получить, тем больше может получиться разница.
Итак, что и как сравниваем. Во вложении 2 обработки: COM MONITOR и Пример 6 для COM Monitor.
COM MONITOR - во вложении, это почти оригинальная обработка, в которую добавлены команды для выполнения замера времени получения данных из подключенной базы. COM MONITOR работает в двух режимах: с закрытым окном подключенной базы данных и с открытым. Т. к. с открытым окном обработка работает очень медленно, то для сравнения берем только замер с закрытым окном.
Пример 6 для COM Monitor - эта обработка построена на основе COM MONITOR, ну, или почти так. Пример 6 для COM Monitor работает в двух режимах: с использованием дополнительной обработки и без неё. При установке соответствующего флажка используется дополнительная внешняя обработка, которая запускается в подключенной базе данных. Данные внешней обработке передаются через COMSafeArray, который она легко преобразует в обычный массив. Обратно данные передаются аналогичным образом. Ни каких внешних компонент, всё по честному. AutoIt используется только чтобы вернуть фокус в 1С:Предприятие, а WScript для замера времени выполнения.
Скачать COM MONITOR от ghostishe...
Скачать Пример 6 для COM Monitor...
А теперь главный вопрос: за счет чего получается столь значительное ускорение? Ответ прост: за счет снижения количества разыменований. Да, да. На такой пустяковой операции как разыменование можно добиться столь значительного ускорения. Чем меньше точек в тексте модуля, тем выше скорость его выполнения. Разница особенно заметна при использовании COMОбъект(), т. к. кроме разыменования здесь немаловажную роль играет передача данных между приложениями.
