

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Московский государственный институт электроники и математики
(технический университет)
Кафедра ИКТ
Курсовая работа
по дисциплине “Информатика”
на тему:
“Написать программу на любом языке программирования, которая архивирует файл по алгоритму Хаффмана.”
Выполнил:
студент группы С-15
Проверил:
Москва – 2009
Содержание:
1. Аннотация.
2. Теоретические сведения:
а) Избыточность информации.
б) Сжатие информации.
в) Обратимые алгоритмы сжатия информации. Алгоритм Хаффмана.
3. Программа.
4. Описание работы программы.
5. Список литературы.
Аннотация.
В данной курсовой работе рассматриваются вопросы, связанные с избыточностью информации и методах ее сжатия. Представлены алгоритмы сжатия информации и описана программа, архивирующая файл по алгоритму Хаффмана.
Теоретические сведения.
Избыточность информации.
Существенной характеристикой информации является её полнота и избыточность. Полноту обычно определяют как оптимальное соотношение между необходимой и полученной информацией. От полноты информации зависит качество принимаемых на её основе решений.
Следует различать полноту и избыточность информации. Избыточная информация – это повторяющаяся, дублирующая информация. Она отнимает время у потребителя, отрицательно сказывается на эффективности управления.
По имеющимся данным, излишним является в среднем около трети всего объёма информации. Подсчитано, что в среднем 60% научных и административных документов потребителю не нужно прочитывать целиком. Мало того, он попросту не успеет прочитать всё для выполнения его профессиональных обязанностей, если будет читать всё подряд. Однако с избыточностью информации дело обстоит далеко не так просто, как это может показаться на первый взгляд. Установлено, что в целом ряде случаев избыточная информация приносит даже пользу. Это свойство, полезность которого мы ощущаем очень часто. Нередко избыточность информации человек чисто психологически воспринимает как ее качество, потому что она позволяет ему меньше напрягать свое внимание и меньше утомляться. В частности, избыточными являются существующие алфавиты и языки. К примеру, в русском языке избыточность составляет 40 %, во французском - 55 % .

Без некоторой избыточности человек не в состоянии длительное время воспринимать информацию. Это потребовало бы от него постоянного напряжённого внимания, что приводит к быстрому утомлению и потере способности к восприятию. Обычный текст, напечатанный на русском языке, имеет избыточность порядка 20-25%. Попробуйте отбросить каждую пятую букву, и вы увидите, что получить информацию из печатного текста все же можно, хотя читать его будет очень утомительно.
Например, получив по телеграфу сообщение из букв - ТЬС, можно безошибочно догадаться, что дальше следует - Я. Почти с полной уверенностью можно утверждать, что если в сообщении было слово ЯЩИК, а потом пришло сочетание ГРОМОЗД-, то вполне очевидно, что следом появится - СКИЙ.
Именно принцип избыточности языка позволило ученому Г. Гротефенду, не знавшему персидского языка, расшифровать надписи персидских царей - начать дешифровку египетских иероглифов. Целиком на наблюдениях над правилами сочетания буквенных знаков и слов он построил свою работу над дешифровкой.
Типичный бытовой пример-телеграмма, из текста которой мы в целях экономии выбрасываем не только предлоги и соединительные союзы, но и неполнозначные слова. Экономно построено так же общение человека с компьютерными программами. Компьютер общается с пользователем с помощью набора стандартных клавише команд, сообщений, запросов и подсказок. В этих случаях избыточность равняется нулю.
Нам нередко приходится иметь дело с небрежным рукописным почерком. Избыточность информации, заключенной в тексте, оказывает добрую службу, позволяя догадываться о значении неразборчивых символов. Визуальная информация, которую мы получаем органами зрения, имеет очень большую избыточность - более 90%. Это означает, что, даже потеряв значительную часть визуальной информации, мы все-таки можем понимать ее содержание, хотя и не без концентрации внимания. Люди, лишенные большой доли зрения, продолжают оставаться полноценными членами общества, но испытывают повышенное утомление. Еще большую избыточность имеет видеоинформация (до 98-99%). Эта избыточность позволяет нам рассеивать внимание, что часто воспринимается как отдых при просмотре кинофильма.
С избыточностью информации связаны и другие свойства. Чем выше избыточность данных, тем шире диапазон методов, с помощью которых из них можно получить адекватную информацию. Расшифровка шумерской клинописи не могла произойти до тех пор, пока в результате археологических раскопок не был накоплен достаточный объем (более 5000) глиняных табличек.
Избыточность информации позволяет повышать ее достоверность за счет применения специальных методов, в том числе и основанных на теории вероятностей и математической статистике. Общий принцип здесь такой: в результате отсева объем данных сокращается, но их достоверность увеличивается.
Особое значение избыточность информации имеет в информационных технологиях, ориентированных на автоматическую обработку данных. С одной стороны, это свойство рассматривается как негативное, потому что если информация занимает больший объем, чем могла бы, то это ведет к прямым затратам на ее хранение и, главное, на транспортировку. Для этого есть специальные программные методы сжатия данных.
Сжатие информации.
Сжатие информации - проблема, имеющая достаточно давнюю историю, гораздо более давнюю, нежели история развития вычислительной техники, которая (история) обычно шла параллельно с историей развития проблемы кодирования и шифровки информации.
Сжатие в основном имеет две основных области применения – хранение и передача информации. Причем применение сжатия обусловлено в основном экономическими соображениями рационального использования ресурсов. Но цель сжатия - хранить и передавать не конкретные символы/пиксели, а ту смысловую информацию, которую они описывают. А ее конкретное представление (символы/пиксели) обусловлено текущей технологией. Целью процесса сжатия, как правило, есть получение более компактного выходного потока информационных единиц из некоторого изначально некомпактного входного потока при помощи некоторого их преобразования.
Сжатие информации является одним из способов ее кодирования. Все алгоритмы сжатия оперируют входным потоком информации, минимальной единицей которой является бит, а максимальной - несколько бит, байт или несколько байт. Коды, предназначенные для сжатия информации, делятся, на коды без потерь и коды с потерями. Кодирование без потерь (обратимые) подразумевает абсолютно точное восстановление данных после декодирования и может применяться для сжатия любой информации. Сжатие без потерь - это однозначное кодирование, такое что закодированные сообщения в среднем занимают меньше места. Кодирование с потерями (не обратимое) имеет обычно гораздо более высокую степень сжатия, чем кодирование без потерь, но допускает некоторые отклонения декодированных данных от исходных. Задачу сжатия с потерями можно сформулировать так: требуется отобразить множество возможных сообщений на множество, содержащее меньшее количество элементов, так, чтобы исходные сообщения и их отображения были в определенном смысле близки (например, неразличимы на глаз), т. е. малозначительная информация просто отбрасывается. Сжатие с потерями применяется в основном для графики (JPEG), звука (MP3), видео (MPEG), то есть там, где мелкие отклонения от оригинала незаметны или несущественны, а степень сжатия в силу огромных размеров файлов очень важна. Сжатие без потерь применяется во всех остальных случаях - для текстов, исполняемых файлов, высококачественного звука и графики и т. д. и т. п.
Ни один метод сжатия не может сжать любые данные, поскольку кодирование должно быть однозначным. Задача состоит в том, чтобы построить правило кодирования, по которому наиболее часто встречающимся сообщениям соответствовали бы сообщения меньшей длины. Поэтому любой метод сжатия должен быть основан на каких-либо предположениях о вероятностной структуре сжимаемых данных. Например, для текста на определенном языке известны частоты букв. Наиболее часто используемое предположение заключается в том, что с большей вероятностью в сообщении будут встречаться одинаковые цепочки символов. Например, в тексте этой статьи чаще всего встречается слово "сжатие". Если же ничего не знать о вероятностной структуре сжимаемых данных и считать все сообщения одной длины равновероятными, то мы вообще ничего не сожмем.
Кроме того методы сжатия делятся на статистические и словарные. Словарные методы заключаются в том, чтобы в случае встречи подстроки, которая уже была найдена раньше, кодировать ссылку, которая занимает меньше места, чем сама подстрока. Классическим словарным методом является метод Лемпела-Зива (LZ). Все используемые на сегодняшний день словарные методы являются лишь модификациями LZ. Статистическое кодирование заключается в том, чтобы кодировать каждый символ, но использовать коды переменной длины. Примером таких методов служит метод
Хаффмана (Huffman). Обычно словарные и статистические методы комбинируются, поскольку у каждого свои преимущества.
Обратимые алгоритмы сжатия информации.
Существует много разных практических методов сжатия без потери информации, которые, как правило, имеют разную эффективность для разных типов данных и разных объемов. Однако, в основе этих методов лежат три теоретических алгоритма:
-алгоритм RLE (Run Length Encoding);
-алгоритмы группы KWE(KeyWord Encoding);
-алгоритм Хаффмана.
1. Сжатие способом кодирования серий (RLE)
Наиболее известный простой подход и алгоритм сжатия информации обратимым путем - это кодирование серий последовательностей (Run Length Encoding - RLE).
Суть методов данного подхода состоит в замене цепочек или серий повторяющихся байтов или их последовательностей на один кодирующий байт и счетчик числа их повторений.
Например:
4411FFисходная последовательность
0301 03 FFсжатая последовательность
Первый байт указывает сколько раз нужно повторить следующий байт
Если первый байт равен 00, то затем идет счетчик, показывающий сколько за ним следует неповторяющихся данных.
Данные методы, как правило, достаточно эффективны для сжатия растровых графических изображений (BMP, PCX, TIF, GIF), т. к. последние содержат достаточно много длинных серий повторяющихся последовательностей байтов.
Недостатком метода RLE является достаточно низкая степень сжатия.
2. Алгоритмы группы KWE
В основе алгоритма сжатия по ключевым словам положен принцип кодирования лексических единиц группами байт фиксированной длины. Примером лексической единицы может быть обычное слово. На практике, на роль лексических единиц выбираются повторяющиеся последовательности символов, которые кодируются цепочкой символов (кодом) меньшей длины. Результат кодирования помещается в таблице, образовывая так называемый словарь.
Существует довольно много реализаций этого алгоритма, среди которых наиболее распространенными являются алгоритм Лемпеля-Зіва (алгоритм LZ) и его модификация алгоритм Лемпеля-Зіва-Велча (алгоритм LZW).Данный алгоритм отличают высокая скорость работы как при упаковке, так и при распаковке, достаточно скромные требования к памяти и простая аппаратная реализация. Недостаток - низкая степень.
Предположим, что у нас имеется словарь, хранящий строки текста и содержащий порядка от 2-х до 8-ми тысяч пронумерованных гнезд. Запишем в первые 256 гнезд строки, состоящие из одного символа, номер которого равен номеру гнезда.
Алгоритм просматривает входной поток, разбивая его на подстроки и добавляя новые гнезда в конец словаря. Прочитаем несколько символов в строку s и найдем в словаре строку t - самый длинный префикс s.
Пусть он найден в гнезде с номером n. Выведем число n в выходной поток, переместим указатель входного потока на length(t) символов вперед и добавим в словарь новое гнездо, содержащее строку t+c, где с - очередной символ на входе (сразу после t). Алгоритм преобразует поток символов на входе в поток индексов ячеек словаря на выходе.
При практической реализации этого алгоритма следует учесть, что любое гнездо словаря, кроме самых первых, содержащих одно-символьные цепочки, хранит копию некоторого другого гнезда, к которой в конец приписан один символ. Вследствие этого можно обойтись простой списочной структурой с одной связью.
Пример: ABCABCABCABCABCABC 7 7
1 A
2 B
3 C
4 AB
5 BC
6 CA
7 ABC
8 CAB
9 BCA
3. Алгоритм Хаффмана.
В основе алгоритма Хаффмана лежит идея кодирования битовыми группами. Сначала проводится частотный анализ входной последовательности данных, то есть устанавливается частота вхождения каждого символа, встречающегося в ней (определение вероятности появления символов в файле ). После этого, символы сортируются по уменьшению частоты вхождения (нахождение оптимального префиксного кода). Префиксные коды – это коды, в которых никакое кодовое слово не
является префиксом любого другого кодового слова. Эти коды имеют
переменную длину. Иными словами, префиксным кодом является тот, в котором для любого слова a не существует слова ab, где b любая последовательность символов. К префиксным кодам так же относятся: Юникод, телефонные номера, Код Фибоначчи и мн. другие.
Основная идея алгоритма состоит в следующем: чем чаще встречается символ, тем меньшим количеством бит он кодируется. Результат кодирования заносится в словарь, необходимый для декодирования. Рассмотрим простой пример, иллюстрирующий работу алгоритма Хаффмана..
Пример:
Сжимая файл по алгоритму Хаффмана первое что мы должны сделать - это необходимо прочитать файл полностью и подсчитать сколько раз встречается каждый символ из расширенного набора ASCII. Если мы будем учитывать все 256 символов, то для нас не будет разницы в сжатии текстового и EXE файла. После подсчета частоты вхождения каждого символа, необходимо просмотреть таблицу кодов ASCII и сформировать
бинарное дерево.
Мы имеем файл длинной в 100 байт и имеющий 6 различных символов в себе. Мы подсчитали вхождение каждого из символов в файл и получили следующее :
![]()
Теперь мы берем эти числа, и будем называть их частотой вхождения для каждого символа.
![]()
Мы возьмем из последней таблицы 2 символа с наименьшей частотой. В нашем случае это D (5) и какой либо символ из F или A (10), можно взять любой из них например A.
Сформируем из "узлов" D и A новый "узел", частота вхождения для которого будет равна сумме частот D и A :

Рассматриваем таблицу снова для следующих двух символов ( B и E ).
Мы продолжаем в этот режим пока все "дерево" не сформировано, т. е. пока все не сведется к одному узлу.
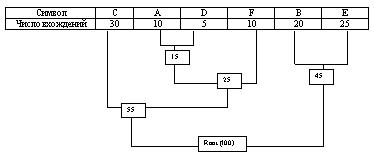
Теперь когда наше дерево создано, мы можем кодировать файл. Мы должны всегда начинать из корня ( Root ). Кодируя первый символ (лист дерева С) Мы прослеживаем вверх по дереву все повороты ветвей и если мы делаем левый поворот, то запоминаем 0-й бит, и аналогично 1-й бит для правого поворота. Так для C, мы будем идти влево к 55 ( и запомним 0 ), затем снова влево (0) к самому символу. Код Хаффмана для нашего символа C - 00. Для следующего символа ( А ) у нас получается – лево ,право, лево, лево, что выливается в последовательность 0100.
Выполнив выше сказанное для всех символов, получим :
C =бита )
A = 0бита )
D = 0бита )
F = бита )
B =бита )
E =бита )
При кодировании заменяем символы на данные последовательности.
Каждый символ изначально представлялся 8-ю битами ( один байт ), и так как мы уменьшили число битов необходимых для представления каждого символа, мы следовательно уменьшили размер выходного файла. Сжатие складывется следующим образом :
Частота первоначально уплотненные биты| уменьшено на
Cx 8 = x 2 =
Ax 8 =x 3 = 30 50
D 5 5 x 8 = 40 5 x 4 =|
Fx 8 =x 4 = 40 40
Bx 8 = x 2 =
Ex 8 = x 2 =
Первоначальный размер файла : 100 байт - 800 бит;
Размер сжатого файла : 30 байт - 240 бит;
% из 800 , так что мы сжали этот файл на 70%.
Алгоритм Хаффмана универсальный, его можно применять для сжатия данных любых типов, но он малоэффективен для файлов маленьких размеров (за счет необходимости сохранение словаря).
Программа на языке СИ, архивирующая файл
по алгоритму Хаффмана.
#include<stdio. h>
void main( )
{
char filename[20],filename_com[20];
FILE *fp1,*fp2;
int c, i,k, offset, diff, min1,min2,kmax;
struct nod{
unsigned long weight; /*число повторений символов*/
struct nod *left;/*указатель на структуру weight*/
struct nod *right;/*-----*/
int state;/* переменная состояния: 0-структура выведена из списка для расчета узлов,1-в списке*/
unsigned int cod; /* код символа, ограничен 16 битами*/
unsigned char lng; /*длина кода*/
}list[512],*pntstr;/*название массива структур и указательна структуру*/
union{ /* объединение для байтового вывода*/
unsigned int cod;
struct {
unsigned int l:8;
unsigned int h:8;
}byte;
}un;
/*инициализация начальных данных*/
for(i=0;i<=511;i++)
{
list[i].weight=0;
list[i].left=NULL;
list[i].right=NULL;
list[i].state=1;
list[i].cod=0; /*запись во все разряды 0 */
list[i].lng=0;
}
/*открытие сжимаемого файла*/
printf("\n Input file name \n");
gets(filename);
printf( "File name is:%s\n", filename );
if((fp1=fopen(filename,"rb"))==NULL)
{
perror("error open file\n");
exit(0);
}
while((c=getc(fp1))!=EOF)
{
i=c;
list[i].weight=list[i].weight+1;
}
/*построение бинарного дерева*/
for(k=256;k<=511;k++)
{
/*выделение двух наименьших элементов по весу (weight) */
min1=-1;
min2=-1;
for(i=0;i<=511;i++)
{
if(list[i].weight==0) continue;
if(list[i].state==0) continue;
if(min1<0)
{
min1=i;
continue;
}
if(min2<0)
{
if(list[min1].weight<list[i].weight)
min2=i;
else
{
min2=min1;
min1=i;
}
continue;
}
if(list[i].weight<list[min1].weight)
{
min2=min1;
min1=i;
}
else
if(list[i].weight<list[min2].weight) min2=i;
}
if(min2<0)/*в списке остается один элемент, корневой узел*/
{ kmax=k;
break;/*выход из цикла по к*/
}
/*создание нового узла и выведение двух элементов из списка*/
list[k].weight=list[min1].weight+list[min2].weight;/*вес нового узла*/
list[min1].left=&list[k];/*указатель на новый узел*/
list[min1].state=0;/*выводим из списка*/
list[min2].right=&list[k];/*указатель на новый узел*/
list[min2].state=0;/*выводим из списка*/
}
/*бинарное дерево построено*/
/*запись кода*/
for(i=0;i<=255;i++)
{
if(list[i].weight==0) continue;
if(list[i].left!=NULL)
{
pntstr=list[i].left;
list[i].lng+=1;/*длина кода увеличивается на единицу*/
list[i].cod>>=1; /*сдвиг вправо, в высшем разряде 0 */
}
else
{
pntstr=list[i].right;
list[i].lng+=1;
list[i].cod=(list[i].cod>>1)+32768;/* сдвиг вправо с записью в высшем разряде 1*/
}
while(pntstr!=NULL)
{
if(list[i].lng >16)
{
perror("code length >16\n");
exit(0);
}
if(pntstr->left!=NULL)
{
list[i].lng+=1;/*длина кода увеличивается на единицу*/
list[i].cod>>=1; /*сдвиг вправо, в высшем разряде 0 */
pntstr=pntstr->left;/*указатель на следующую структуру*/
}
else
{
list[i].lng+=1;
list[i].cod=(list[i].cod>>1)+32768;/* сдвиг вправо с записью в высшем разряде 1*/
pntstr=pntstr->right;
}
}
}
/*конец записи кода*/
/* Создание сжатого бинарного файла*/
printf("\n Input compress file name \n");
gets(filename_com);
printf("File name is:%s\n", filename_com );
if((fp2=fopen(filename_com,"w+b"))==NULL) /**/
{
perror("error open compress file\n");
exit(0);
}
/*Запись таблицы кодов и их длин в сжатый бинарный файл*/
for(i=0;i<=255;i++)
{
un. cod=list[i].cod;
putc(te. h,fp2); /*записывает высший байт в сжатый файл*/
putc(te. l,fp2); /*записывает низший байт в сжатый файл*/
putc(list[i].lng, fp2);/*записывает длину кода*/
}
/*Запись кода в сжатый файл*/
offset=0;/*начальное смещение равно 0*/
un. cod=0; /*начальный код все 0*/
fseek(fp1,0L, SEEK_SET);/*перемещает текущею позицию в файле в начало*/
while((c=getc(fp1))!=EOF)
{
for(i=0;i<=255;i++)
{
if(c==i)
{
un. cod=un. cod+(list[i].cod>>offset); /*запись со смещением вправо на offset*/
offset=offset+list[i].lng;/* смещение равно длине кода + предыдущее*/
if(offset>=16)
{
putc(te. h,fp2); /*записывает высший байт в сжатый файл*/
putc(te. l,fp2); /*записывает низший байт в сжатый файл*/
offset=offset-16; /*смещение для следующей записи*/
diff=16-list[i].lng;/*количество бит, кот. нужно записать в новое слово*/
un. cod=(list[i].cod>>diff)-((list[i].cod>>(diff+offset))<<offset);/*код, кот. должен стоять в этих битах*/
un. cod<<=(16-offset); /*перемещение кода в высшие разряды, начало новой записи*/
}
break;
}
}
}
/*запись последних двух байтов*/
if(offset>0) putc(te. h,fp2); /*записывает высший байт в сжатый файл*/
if(offset>8) putc(te. l,fp2); /*записывает низший байт в сжатый файл*/
fclose(fp1);
fclose(fp2);
}
Список литературы:
, , Ракитина и информационные процессы. Омск, 1999.
, Степанюк информационной защиты объектов и компьютерных сетей. М., 2000.
http://*****/arctest/descript/inf-comp. htm
http://www. *****/progr/alg/huffman. php
http://www. thl. *****/tehnologia/informatika/lecture9.htm
