
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
1. Анализ данных
Анализ данных – это совокупность действий осуществляемых исследователем в процессе изучения первичных данных с целью формирования определенных представлений о тех явлениях, которые описываются этими данными. Это система математических методов, позволяющая представлять, обрабатывать интерпретировать полученные эмпирические данные.
Социологическая информация – это любые эмпирические данные, которые содержат информацию о социальной реальности, соц. явлениях, соц. процессах, соц. общностях, соц. институтах, соц. системах, соц. группах и др. соц. феноменах.
Эмпирические данные бывают видов:
- совокупность чисел, характеризующих те или иные объекты; это множество индикаторов определенных отношений между рассматриваемыми объектами; это результаты попарных сравнений респондентами каких-либо объектов; это способ построения каких-либо шкал, отражающих усредненное отношение респондентов к каким-либо объектам; в виде совокупностей определенных высказываний;
· это тексты документов, аудио-, видеозаписей;
· зафиксированные результаты наблюдения за поведением людей;
Математические методы вводятся в социологию для выделения «жестких» логических конструкций из «потока сознания» респондента.
Признак – это некоторое общее для всех объектов качество, конкретные проявления которого могут меняться от объекта к объекту. Например, возраст: есть у всех, но у всех разный; профессия, образование, отношение к чему-либо.
Эмпирическая закономерность – это эмпирически установленные факты, которые в простом случае представляют собой описание. Например, поведение людей отличается по образу жизни.
Эмпирический индикатор – это наблюдаемый признак. Например, в поведении и образе жизни, цель узнать зависимость между доходом, образованием и образом жизни. В качестве эмпирического индикатора будут выступать образование и доход.
Эмпирическая интерпретация – процедура перехода от теоретических понятий к эмпирическим индикаторам. Операционализации – это разделение изучаемой стороны на понятия, детали. Процесс перевода теории в практику: сначала описываем в работе теорию, затем переходим к практике.
Этапы исследования и взаимосвязь с анализом.
Этапы исследования
1. Концептуальная схема исследования
- Операционализация выстраивание эмпирических закономерностей, предположения, основанные на каких-то фактах, схема проверки гипотезы, решения задач и тд.
2. Методика сбора эмпирических данных
- методы получения данных: анкета, интервью и тд
3. Методика обработки данных
- применение математических методов; различных методов анализа; расчеты индексов, показателей и тд.
Два основных подхода к изучению социального через индивида
1. Статистический подход. Индивид признается представителем некой общности, носителем информации о социальном феномене. (Считается, что мы все примерно одинаково мыслим, и явление можно изучать исходя из взаимосвязи между людьми).
В этом подходе появляется значение выборки, генеральной совокупности (N), выборочной совокупности (n) и тд. Любая выборка должна отвечать репрезентативности).
Статистические операции:
Сбор первичной статистической информации Статистическая сводка и обработка информации Обработка, обобщение, интерпретация и представление статистической информации.Статистический показатель – это количественно-качественная обобщающая характеристика, какого-либо свойства группы единиц или совокупности в целом.
- Абсолютный (то, что изменяется в целом количестве – тонны, штуки, кг и тд.) Относительный (доля, %, индексы, коэффициенты и тд) Средний (среднеарифметический и средневзвешанный) Первичные (абсолютные) Вторичные (относительные и средние)
Статистическое наблюдение – это метод получения информации через отслеживание основных статистических показателей в результате проведенного исследования.
Виды статистического наблюдения:
· по охвату: сплошным (например перепись населения) и не сплошным (какая-то выбранная часть);
· По систематичности: непрерывное, прерывное (периодическое, единовременное)
· По источнику сведений: - непосредственное (я смотрю, я фиксирую), документальное (из документов), опрос (сведения со слов опрашиваемых)
Генеральная совокупность (N) – это весь объект исследования в целом.
Выборочная совокупность (n) – это часть генеральной совокупности, изучив которую можно представить параметры генеральной совокупности.
Основной массив – часть, которая изучается полностью из генеральной совокупности
Виды выборки:
· Зависимая и независимая – при отображении зависимости каких то показателей.
· Вероятностные – это наугад извлеченное необходимое количество респондентов из генеральной совокупности.
ü Механическая (Систематическая) – это вероятностная выборка но с заданным интервалом «извлечения» респондентов.
ü Серийная (гнездовая) выборка – единицами отбора становятся статистические серии
ü Стратифицированная (Районированная) выборка – использование вероятностной выборки с предварительным разделением неоднородной генеральной совокупности на однородные части.
ü Удобная выборка – установление в качестве респондентов удобной группы – одноклассники, спортивная команда и тд.
· Невероятностные – выборки с условиями
ü Квотная выборка – выборка строится как модель, воспроизводящая генеральную совокупность в виде пропорций (квот) изучаемых признаков. Доля пропорций в выборке соответствует доли пропорций в генеральной совокупности.
ü Метод снежного кома – У первого респондента просят контакты его друзей, знакомых, родственников и так далее.
ü Стихийная выборка – выборка «первого встречного»
ü Маршрутный опрос – улицы населенного пункта нумеруются, с помощью генератора случайных чисел отбираются бОльшие числа, каждое большое число рассматривается как номер улицы, номер дома, номер квартиры.
ü Районированная выборка с выбором типичных объектов – после районирования отбирается типичный объект, т. е. объект который по большинству изучаемых в исследовании характеристик приближается к средним показателям.
Репрезентативность – это свойство выборки, когда все эмпирические закономерности полученные по ней, могут распространяться на всю генеральную совокупность.
Чем меньше генеральная совокупность, тем больше выборка. (100 чел – 100 выбока; 200 чел – 150 выборка; 10000 – 1000).
Доверительный интервал – это интервал, в котором с заданной доверительной вероятностью, находится истинное значение этой изучаемой характеристики.
На практике используются 95%, 99% и 99,9% доверительные интервалы. Это значит что отклонения значения должны быть не более чем 0,05%, 0,01% и 0,001%.
Ошибки выборки – это расхождения между оценкой некоторого показателя по выборке от истинного значения генеральной совокупности.
· Статистические, которые зависят от размера выборки;
· Систематические, это результат неправильного формирования выборки
2. Качественный подход. Когда индивид признается неповторимым, он не проявление социального, а сам социальное.
Проблема соотношения выборки и генеральной совокупности
1. На практике не редко нарушаются условия вероятностного порождения данных. В выборку включают только тех, кто нужен, а не всех тех, кто есть.
2. Не всегда бывает ясно, какая генеральная совокупность, не понятно. Например, стратификационная выборка, но неизвестно какие слои существуют в генеральной совокупности.
3. Для многих методов исследования отсутствуют разработанные способы перенесения результатов их применения с выборки на генеральную совокупность. Нет возможности рассчитать репрезентативность. Например, экспертный опрос, введение налога на бездетность, опрос экспертов, как перенести результат на все общество?
4. Перенос результатов с выборки на генеральную совокупность может быть затруднен из-за осуществления «ремонта» выборки. Респонденты часто не до конца отвечают на анкеты, приходится добирать еще респондентов, получается перевешивание, выборка расширяется, а генеральная совокупность остается прежней.
Эти проблемы призван решать анализ данных.
Социологические шкалы
Выделяется два типа шкал:
1. Низкого типа:
· 
![]() Номинальная шкала – отражение в числах некоторое отношение равенства и неравенства между изучаемыми объектами. Например:
Номинальная шкала – отражение в числах некоторое отношение равенства и неравенства между изучаемыми объектами. Например:
 1 2
1 2
1 – учитель, 2 – слесарь, и тд. Т. е. просто упорядочивание, между значениями нет разницы.
· Порядковая шкала – отражает не только отношение равенства-неравенства, но и содержательное отношение порядка между ними. Например:
1 2 3
Удовлетворены ли качеством обучения, 1 – да, 2 – не полностью, 3 – нет. Т. е. отношение выстраивается по порядку, между значениями есть разница.
2. Высокого типа
· Интервальная шкала – отношения выстраивается к интервалам. Например, возраст – «от 10 до 20», «от 20 до 30» и тд.
· Шкала отношений – используется в качественных исследованиях и отражает суждения.
Требования к выборкам
Репрезентативность; Объем выборки должен быть достаточным (чем меньше генеральная совокупность, тем больше выборка); Выборка должна быть однородной. Для этого существует два этапа обеспечения однородности:- I этап. Создание такой ситуации, чтобы во-первых, все элементы генеральной совокупности обладали интересующими исследователя свойствами (если качество жизни в общаге, то все респонденты должны жить в общаге); во-вторых, для всех них был адекватен один и тот же инструмент измерения (не имеет значения живет ли респондент в общежитие кемгу или политеха); в-третьих, чтобы была возможность одинаковой интерпретации результатов измерения (например, бюджет времени в среднем 4 часа – для сельской местности это нормально, а для города – много. т. е. разная интерпретация для разных категорий) II этап. Обеспечение самого существования для рассматриваемого множества закономерностей подлежащих изучению с помощью данного метода. (например, изучать зависимость досуга от доходов у чукчей и кочевых народов – это неправильно. Т. е. предполагаемая закономерность должна существовать в генеральной совокупности, или соответствие инструментария)
Статистическая закономерность
Статистическая закономерность – это форма причинной связи, при которой данное состояние системы определяет все ее последующие состояния не однозначно, а лишь с определенной вероятностью. Это результат взаимодействия большого числа элементов, составляющих совокупность, и характеризующих не столько поведение отдельного элемента совокупности, сколько всю совокупность в целом.
Статистическая закономерность характерна для достаточно большого числа наблюдений.
Виды закономерностей:
Закономерности развития и динамики явлений. Например, увеличение среднего возраста рождения первого ребенка. Закономерности структурных сдвигов. Например, старение населения, изменение состава всего населения. Закономерности распределения элементов совокупности. Например, распределять семьи по количеству детей. Закономерности связей между явлениями. Например, чем хуже погода, тем лучше успеваемость студентов.Выборочные оценки параметров генеральной совокупности.
Корректировка возможных ошибок выборки.
Мода - это наиболее часто встречающееся значение у элементов данной совокупности. Медиана – значение признака, которое делит элементы вариационного ряда на две равные части. (Например, при пяти вариантах ответа, отвечены 1, 2, 3, 5, 6. При данном ответе – 3 – это медиана. Если четное количество, то серединные два значения среднеарифметическое: 1,2,5,6 – (2+5)/2 =3,5 Среднеарифметическое – сумма всех значений, деленная на количество значений. Дисперсия – значение случайной величины, отражающее математическое ожидание квадрата отклонения случайной величины от ее математического ожидания. (т. е. рассеивание значение признака). Среднеквадратическое отклонение – это корень квадратный из дисперсии.Выборочные оценки параметров генеральной совокупности позволяют обеспечить репрезентативность выборки и ее упорядоченность, однородность.
Описательная статистика
Описательная статистика - это представление признаков в исследовании.
Данные соц. исследований могут быть представлены в виде:
Одномерные частотные таблицы.Например: признак профессия, всего 5 профессий, количество людей встречающихся этой профессии.
1 | 2 | 3 | 4 | 5 | 6 |
10 | 13 | 25 | 30 | 17 | Всего 100 |
Например, распределение профессий по полу, возраст и какое-либо суждение.
Профессии | пол | |
м | ж | |
1 | 20 | - |
2 | 5 | 15 |
Изображение интервалов
Проблема выбора интервала
Точность измерения. Например, интервал до25 лет, а человеку завтра 26, куда его отнести? Выделение величины интервала. Например между 10 и 20 годами есть разница, А между 70 и 80 уже нет. К какому интервалу относить объект, для которого значение рассматриваемого признака, лежит на стыке двух интервалов. Например, с возрастом: 15-20 интервал, значение 20 – куда поставить точку на графике. Это решается включительный и не включительный интервал. Как поступить с правым концом самого правого интервала. Например, «65 и выше” , а для последнего вводится дополнительный интервал, значение которого ставится при уже известных результатах.Кумулята – это полигон, каждая вершина которого отвечает относительной частоте того, что признак принимает значение не превышающее того, над которым эта вершина находится. График накопленных частот, каждое предыдущее значение плюсуется с последующим.
Коэффициенты, использующиеся в анализе данных
Фи-коэффициент – используется для измерения тесноты связи при анализе таблиц с двумя строками и двумя колонками.Например, принимаете ли вы сожительство как форму брака?
Муж | Жен | |
Да | - | |
Нет | - |
Если Фи2=0, то связь отсутствует
Если Фи2=1, то связь присутствует.
F-коэффициент Крамера – используется для измерения меры тесноты связи в таблицах больших, чем два на два. Коэффициент-Лямбда – используется только при номинальной шкале и показывает ассиметрию. tay b, tay с, гамма – эти коэффициенты измеряют связь между значениями признаков, но не учитывают ранги и размеры Коэффициент корреляции – измеряется от -1 до +1. Если 0 – то связи (корреляции) нет, если -1, то отрицательная, если +1 – положительная. t-критерий – разделяется для независимых выборок и для зависимых.Например, для независимых выборок: изучить качество нового лекарства: выборки – с плацебо и лекарством. Сравниваем лечение этих двух групп. Т. е. постановка двух групп в разные условия.
Зависимые выборки, предполагают, что на одной и той же группе проверяются оба условия.
Критерий показывает влияют ли условия на результат.
От -1 до +1. Если связь есть, то t-критерий=1, если связь отсутствует, то t-критерий ближе к -1.
Основные способы организации выборки
простой случайный отбор, при котором объектов случайно извлекаются из генеральной совокупности объектов (например с помощью таблицы или датчика случайных чисел), причем каждая из возможных выборок имеют равную вероятность. простой отбор с помощью регулярной процедуры осуществляется с помощью механической составляющей (например, даты, дня недели, номера квартиры, буквы алфавита и др.). стратифицированный отбор заключается в том, что генеральная совокупность объема подразделяется на подсовокупности или слои (страты) объема так что. Страты представляют собой однородные объекты с точки зрения статистических характеристик (например, население делится на страты по возрастным группам или социальной принадлежности; предприятия — по отраслям). методы серийного отбора используются для формирования серийных или гнездовых выборок. Они удобны в том случае, если необходимо обследовать сразу "блок" или серию объектов (например, партию товара, продукцию определенной серии или население при территориально-административном делении страны). Отбор серий можно осуществить собственно-случайным или механическим способом. При этом проводится сплошное обследование определенной партии товара, или целой территориальной единицы (жилого дома или квартала); комбинированный (ступенчатый ) отбор может сочетать в себе сразу несколько способов отбора (например, стратифицированный и случайный или случайный и механический);Виды отбора
ü индивидуальный (отбираются отдельные единицы генеральной совокупности)$
ü групповой (качественно однородные группы (серии) единиц);
ü комбинированный (сочетание первого и второго видов)
Методы отбора:
ü повторную (котором попавшая в выборку единица не возвращается в исходную совокупность и в дальнейшем выборе не участвует, при этом численность единиц генеральной совокупности N сокращается в процессе отбора);
ü бесповторную (попавшая в выборку единица после регистрации возвращается в генеральную совокупность и таким образом сохраняет равную возможность наряду с другими единицами быть использованной в дальнейшей процедуре отбора; при этом численность единиц генеральной совокупности N остается неизменной)
Анализ сопряженности номинальных и дихотомических признаков
Номинальные признаки – главный вид исходной информации, встречающийся в каждом исследование. Т. е. это значения эмпирических индикаторов.
Роль номинальных признаков:
- Чаще всего используются, так как просты для получения и интерпретации; Они более надежны, позволяют построить математические модели;
Анализ сопряженности номинальных признаков заключается в построении таблиц сопряженности.
Дихотомический признак – это признак имеющие только два значения. Например, пол – жен, муж, либо вопросы требующие ответа да/нет, или разделение понятий на две части.
Анализ дихотомических признаков осуществляется в таблицах сопряженности два на два.
Нормальный закон распределения
Вывел немецкий математик Гаусс. Этому закону подчиняется свойств самовоспроизводимости, которое заключается в том, что сумма любого числа нормально распределенных случайный величин тоже подчиняется нормальному закону распределения.
Этот закон начинает действовать в группе людей больше двух, чем больше людей тем больше проявляется этот закон.
Например, среди опрошенных 3,5% будут полностью недовольны образованием, и 3,5% будут полностью довольны.
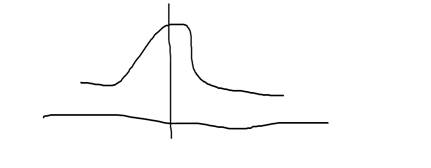
3,5 % 3,5%
Стандартизация данных
Стандартизация данных – это установление единообразных процедур, расчет обобщающих показателей в целях исключения влияния внешних факторов и приведения данных к сопоставимому виду.
Стандартизация данных позволяет наглядно представить нормальный закон распределения.
Статистические гипотезы
Гипотеза – это предположение, которое необходимо либо доказать либо опровергнуть.
В анализе данных используют простую гипотезу – нулевую H0, помимо этого проверяют альтернативную H1.
Статистическая гипотеза может быть сложной, то есть включающей некоторое множество распределений, обладающих определенным свойством.
Статистическая гипотеза обязательно требует проверки, в ходе которой возможны ошибки первого и второго рода.
Ошибка первого рода – гипотеза отвергается, но на самом деле верна.
Ошибка второго рода – гипотеза принимается, но она не верна.
Проверка статистических гипотез:
Формулировка в виде статистической гипотезы задачи исследования. Предположение о свойстве генеральной совокупности, которое можно проверить по выборке. (Например, зависимость успеваемости студентов от качества преподавания). Выбирается статистическая характеристика гипотезы. (Зависимость есть, или зависимости нет) Выбирается нулевая и альтернативная гипотеза, на основе анализа возможных ошибочных решений и их последствий. По соответствующим математическим (справочным) таблицам определяется область допустимых значений, критическая область, а также критическое значение статистического критерия. Вычисляется фактическое значение статистического критерия (который мы задаем сами, зная генеральную и выборочную совокупность). Выдвинутая гипотеза проверяется на основе сравнения фактического и критического значения критерий. И либо принимается, либо отклоняется.Критическая область – это область, попадание значения статистического критерия в которую приводит к отклонению нулевой гипотезы (H0).
Область допустимых значений – дополняет критическую область и если значения критерия попадают в нее, то выдвинутая гипотеза не противоречит фактическим данным.
Индекс
Индекс – это обобщенный производный показатель, сформированный из исходных показателей, посредством математических операций.
Выделяют:
- Индексы для равнения групп. Эти индексы характеризуют группы респондентов по шкале порядков.
Например, насколько вы уверены в трудоустройстве?
n+ n0 n-

Уверен уверен не верен Не уверен
I=n+-n-
n++n0+n-
Если индекс 1 – все уверены, 0 – уверены не уверены равны, -1 – все не уверены. То есть чем ближе к единице больше уверенных/
 na nb nc nd ne
na nb nc nd ne
Уверен скорее увер уверен не верен скорее не ув. Не уверен
I=na+0,5nb-0,5nd-ne
na+nb+nc+nd+ne
Индексы также используются для изучения социальных установок.
Социальные установки – осознание, оценка, готовность действовать или ценностное отношение к социальному объекту, психологически выражающееся в готовности положительной или отрицательной реакции на него.
Социальные установки носят латентный характер и требуют уточнения.
Социальные установки можно изучать с помощью:
ü Логического квадрата
Например: Выяснить удовлетворены ли вы обучением?
1. Ушли бы в другой ВУЗ, если представилась бы возможность?
Да/Нет/Затрудняюсь ответить
2. Пришли бы вы снова?
Да/Нет/Затрудняюсь ответить
2 | Да | Нет | Затрудняюсь ответить |
Да | f | a | b |
Нет | e | f | d |
Затрудняюсь ответить | d | b | c |
Самая неблагоприятная a
Середина c
Самая благоприятная e
Выстраивается линейка ситуаций.
a›b›c›d›e
ü Логический прямоугольник
Используется для изучения качества.
Например: Оценить качество преподавания предметов, которое складывается из:
Содержания знания Интерес ПониманиеСодержание | Интерес | Понимание | ||
1 | + | + | + | отлично |
2 | + | + | - | хорошо |
3 | + | - | + | хорошо |
4 | - | + | + | плохо |
5 | + | - | - | удовлетворит. |
6 | - | + | - | плохо |
7 | - | - | + | плохо |
8 | - | - | - | плохо |
Каждая оценка соответствующая цифра: 5,4,3,2
a›b›c›d
Изменение социальных установок
ü Шкала суммарных оценок
Разработал Лайкерт (или Ликерт).
Дается суждение (обычно 10), которые оцениваются от 1 до 5. Все суммируется: мин 10, макс. 50.
ü Шкала равнокажущихся интервалов Луи Терстоуна
С помощью эксперта выбирается суждение, эти суждения расставляются по качественной шкале, на концах которой находятся крайние суждения – от сугубо отрицательного, до крайне положительного.
ü Шкала социальной дистанции Эмори Богардуса
Изучает отношение близости социальных статусов. Например, изучить отношение к лицам кавказской национальности. Вопрос: приемлемо ли для вас впустить в семью, иметь таких друзей, жить с ними на одной улице, работать вместе, жить на одной земле, жить в одной семье. В качестве ответа выбирается один вариант.
ü Шкалограмный анализ Гутмана
Предполагает выбор определенным образом упорядоченных суждений, выстраивание их в шкалу и отбор этих суждений.
Ранжирование
Ранжирование – это процедура упорядочивания любых объектов, по возрастанию или убыванию некоторых их свойств, при условии, что они этим свойством обладают.
Ранжирование бывает прямым – когда предлагается список объектов и предлагается их упорядочить. Например, какие напитки вы предпочитаете: пиво, минералка, простая вода, сок и тд. необходимо выставить их в порядки принятия.
По результатам обязательно рассчитывается мода, медиана и выставляется итоговый ранг предпочтений.
Парное сравнение – когда идет попарное сравнение объектов ранжирования по заданному свойству. Например: что выберете пиво или сок, сок или минералка, сок или чай и тд. Каждый элемент сравнивается с каждым.
Метод попарных сравнений дает более точные ответы, больше информации.
Язык анализа данных
Язык анализа данных - это составная часть языка социологического исследования, а математика это составная часть любого языка анализа.
От выбранного языка анализа данных зависит, какой эмпирический материал будет нужен, и какие приемы и объяснения будут использоваться.
Выделяют три основных языка:
Язык типологического анализа данных. Предполагает поиск знания о реально существующих типах, формах, видах изучаемого социального феномена. Язык причинного анализа. Это поиск причинно-следственных отношений между социальными феноменами.Может быть одна причина и несколько следствий, или наоборот – одно следствие и несколько причин. Гипотезы строятся при определении априорных представлений о причинно-следственных отношениях.
Выделяют зависимые и независимые признаки и соответственно используют коэффициенты связи между ними.
Язык факторного анализа. Это поиск знания о существовании социальных факторов, объясняющие и описывающие социальные явления.Все языки анализа используются одновременно, но один из них является основным.
Типологический анализ
Цель: интерпретация типов, как объектов социально управления, проверка гипотезы о существовании этих типов.
Тип:
- это типовое, то есть стандартное, модальное, часто встречающееся; типическое, то есть специфическое, антимодальное, редковстречающееся; типологическое, то есть особенное, общее, объединяющее связывающее.
Типологический анализ – это нахождение чего-то всегда социально значимого, чего-то специфического, часто встречающегося, объединяющего и разъединяющего.
В ходе типологического анализа мы определяем основание типологии, то есть совокупность суждений о похожести, близости, схожести и однородности объекта.
Этапы типологического анализа
Построение априорной типологии, то есть предположение о том, что выстраивать; Выбор основания типологии; Формирование типообразующих признаков; Формирование классифицируемой совокупности объектов; Формирование совокупности эмпирических индикаторов; Анализ свойств эмпирических индикаторов; Формирование классификационных признаков; Определение принципов и способов интерпретации классов; Формирование однотипных групп объектов; Содержательная интерпретация типов.Например, классы по образу жизни. Выделяем особенное общее, типологическое, затем выделяем генеральную совокупность, затем выделяем признаки, по которым относим к типам, соотносим совокупность с признаками, выводим, что есть люди с вот такими образами жизни. И интерпретируем, например, что есть люди, которые не могут жить без природы, есть горожане, которые никогда не покидают города.
Типологический анализ очень хорош для социального управления.
Дисперсионный анализ
Дисперсионный анализ - это метод позволяющий анализировать влияние различных факторов на зависимую переменную. Суть этого анализа заключается в разложении общей дисперсии случайной величины на независимые слагаемые, каждое из которых характеризует влияние того или иного фактора или их взаимодействия. (влияние условий на один и тот же штук)
Концепция дисперсионного анализа была предложена Фишером в 1920 году.
В ходе дисперсионного анализа из общей вариативности признака можно выделить три частные вариативности:
Вариативность, обусловленная действием каждой из исследуемых независимых переменных. Независимые – это те, которые влияют, Зависимые – это те, на которые влияют. Вариативность, обусловленная взаимодействием исследуемых независимых переменных. Вариативность случайная, обусловленная взаимодействием неучтенных обстоятельств.Виды дисперсионного анализа:
по количеству факторов:- однофакторный; многофакторный.
· одномерные;
· многомерные.
по тому как соотносятся с друг другом выборки значений· анализ несвязанных выборок;
· анализ связанных выборок.
Кластерный анализ
Впервые был применен в 1939 году Трион.
Кластер – от англ. «гроздь», «вставление».
Цель: разбиение множества исследуемых объектов и признаков на однородные в соответствующем понимании группы или кластера.
Кластерный анализ позволяет производить разбиение объектов по целому набору признаков. Рассматривать большой объем информации и сжимать его. Его можно сжимать циклически.
В кластерном анализе считается, что:
1. Выбранные характеристики допускают в принципе желательное разделение на кластеры.
2. Единицы измерения выбраны правильно.
Методы кластерного анализа:
Метод полных связей. Суть которого в том, что два объекта, принадлежащих одной и той же группе, имеют коэффициент сходства, который меньше некоторого порогового значения. Метод максимального локального расстояния. Когда два кластера объединяются, если максимальное расстояние между точками одного кластера и точками другого минимальны. Каждый объект рассматривается как одноточечный кластер. Метод Ворда. В этом методе в качестве целевой функции применяют внутригрупповую сумму квадратов отклонений, которая есть ничто иное как сумма квадратов расстояний между каждой точкой и средней по кластеру, содержащему этот объект. Центроидный метод (метод взвешенных групп). Определяется расстояние между двумя кластерами как расстояние между центрами, то есть средними, этих кластеров.Регрессионный анализ
Регрессионный анализ - это метод, используемый для исследования отношений между двумя величинами.
Цель: Регрессионный анализ используется для определения общего вида уравнения регрессии, оценки параметров этого уравнения, а также проверки различных статистических гипотез относительно регрессии.
Задача: выбор формы связи, установление степени влияния независимых переменных на зависимую и определение расчетных значений в зависимой переменной.
Связи бывают:
- Прямые. Когда увеличивается независимая, и увеличивается зависимая. Обратные. Когда увеличивается независимая и уменьшается зависимая. Прямолинейные и криволинейные. Линейная связь определяется и представляется уравнением прямой, или криволинейная – гипербола, парабола и тд. Однофакторные и многофакторные. По количеству влияющих факторов на объект.
Факторный анализ
Изначально возник как психологический метод. Его разработал Чарлз Спирмен.
Факторный анализ – это группа методов, которые позволяют представить в компактной форме обобщенную информацию по структуре связей между наблюдаемыми признаками изучаемого социального объекта на основе выделения некоторых скрытых, непосредственно не наблюдаемых факторов.
Задачи (этапы):
Отбор факторов, которые определяют исследуемые результативные показатели. Классификация и систематизация их, с целью обеспечения возможностей системного подхода. Определение формы зависимости между факторными и результативными показателями. Моделирование взаимосвязей между результативными и факторными показателями. Расчет влияния факторов и оценка роли каждого из них в изменении величины результативного показателя. Работа с факторной моделью.Типы факторного анализа:
- Детерминированный (функциональный); Стохастический (корреляционный); Прямой (дедуктивный) Обратный (индуктивный) Одноступенчатый Многоступенчатый Статический Динамический Ретроспективный Перспективный (прогнозный)
