


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Анализ и прогнозирование тенденций
развития научно-технических решений.
,
Работа посвящена одному подходу к выявлению тенденций развития научно-технических решений, а также их моделированию и прогнозированию. Изложены конкретные методы сбора информации для моделирования, методы подбора подходящей модели и интерпретации результатов моделирования. Проиллюстрированы типичные случаю ошибок выбора модели. Подробно разобран вопрос моделирования тенденций, описанных малопредста-вительными временными рядами.
Введение
За последние два десятилетия темпы развития технологий во всех областях промышленности возросли многократно. Не секрет, во многих сферах конкурентная борьба приобрела чрезвычайную остроту и любое, даже незначительно преимущество может вывести коммерческую фирму в лидеры, позволяя обойти конкурентов. Возможность же выявлять и анализировать перспективы развития новых и уже существующих технических и технологических решений является мощнейшим фактором, определяющим успех фирмы. Необходимо также заметить, что и для государства в целом определение и прогнозирование тенденций в технике и технологии играет важную роль в оптимизации выбора единой научно-технической политики.
Наиболее проработанной методикой информационных исследований, позволяющих вести деятельность по выявлению и анализу тенденций развития научно-технических решений, является исследование и анализ патентной информации.
Работы в области создания научных методов обработки патентной информации в целях оценки и прогнозирования тенденций научно-технического прогресса были начаты еще в конце 60-х годов [3-4].
Инструментарий методов патентного анализа весьма богат. Еще в начале 80-х издан ГОСТ, определяющий формальный состав исследования технического уровня и тенденций развития объектов техники на основании патентной информации (ГОСТ 15.011-82). Однако, только в последние годы уровень развития вычислительной техники, а также накопление патентными ведомствами ведущих стран (в первую очередь, РОСПАТЕНТом и Американским Патентным Ведомством) оцифрованные патентные фонды, создали предпосылки для построения комплексных систем автоматизации деятельности аналитиков-экспертов. Ясно, что компьютерная система не может полностью заменить эксперта: формализация предмета поиска, выбор исходных массивов для анализа, определение смежных областей активности, учёт вторичных признаков предмета исследования и многих других обстоятельств, влияющих на постановку задачи, все это не поддаётся не только полной, но и частичной автоматизации. Кроме того, сами методы могут значительно отличаться в реализации в зависимости от предметной области. Тем не менее, у них есть общее «ядро»: мониторинг, анализ и прогнозирование изобретательской активности относительно исследуемого объекта.
В этой статье мы рассмотрим базовые алгоритмы, касающиеся последних двух процессов: анализа и прогнозирования.
2. Основные определения и базовые понятия
2.1 Динамические и статические ряды
Мы рассматриваем некоторую базу патентов или документов B, используемую для выборок по тем или иным запросам. Каждый документ состоит из тела документа и набора реквизитов. Документ, размеченный тем или иным набором реквизитов мы будем обозначать ![]() , где i – мультииндекс, n – число реквизитов, в дальнейшем i будет называться просто индексом. Любой поисковый запрос к базе B представляет собой некоторую выборку из базы подмножества документов, индексы которых удовлетворяют условию запроса
, где i – мультииндекс, n – число реквизитов, в дальнейшем i будет называться просто индексом. Любой поисковый запрос к базе B представляет собой некоторую выборку из базы подмножества документов, индексы которых удовлетворяют условию запроса 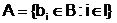 , число документов в множестве A обозначается |A|. Условие запроса I, в свою очередь, представляет собой набор условий по отдельным индексам, связанных операциями «и» и «или». Например,
, число документов в множестве A обозначается |A|. Условие запроса I, в свою очередь, представляет собой набор условий по отдельным индексам, связанных операциями «и» и «или». Например,
![]()
Пусть, например, первый реквизит представляет собой название фирмы и I1 -условие того, что реквизит содержит в качестве подстроки строку Microsoft. Тогда результатом запроса по условию ![]() будет множество всех документов от фирмы Microsoft:
будет множество всех документов от фирмы Microsoft:
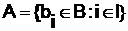 .
.
Для документа bi значение k-го реквизита будем обозначать через rk(bi), время поступления патента bi обозначим t(bi),. Для анализа изобретательской активности фирм (ИА) введем понятия статического и динамического ряда.
Предположим, что второй реквизит представляет собой дату публикации патента. Для последовательности запросов 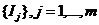 и временного промежутка [t1,t2] статическим рядом называется последовательность j1, j2,…, jm, удовлетворяющая следующим свойствам:
и временного промежутка [t1,t2] статическим рядом называется последовательность j1, j2,…, jm, удовлетворяющая следующим свойствам:
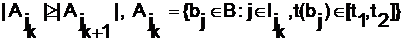 .
.
На практике статическим рядом называют также само распределение ![]() , представляющее собой убывающую функцию. Если, например, последовательность запросов сформирована на реквизите названия фирм, то данное распределение расставляет выбранные фирмы в порядке их изобретательской активности. При построении динамических рядов ИА существуют различные подходы. Рассмотрим простейший случай. Для последовательности запросов
, представляющее собой убывающую функцию. Если, например, последовательность запросов сформирована на реквизите названия фирм, то данное распределение расставляет выбранные фирмы в порядке их изобретательской активности. При построении динамических рядов ИА существуют различные подходы. Рассмотрим простейший случай. Для последовательности запросов ![]() и временного промежутка [t1,t2,…,tp] динамическим рядом называется последовательность распределений по годам для каждого из запросов:
и временного промежутка [t1,t2,…,tp] динамическим рядом называется последовательность распределений по годам для каждого из запросов:
![]()
Таким образом, Akp представляет собой множество документов, удовлетворяющих k-ому условию (полученных при k-ом запросе), датированных tp годом.
2.2 Этапы исследования
Вся аналитико-прогностическая деятельность ведется относительно так называемого информационного объекта.
Под информационным объектом (ИО) мы понимаем описание объекта реального мира, тенденции развития которого мы хотим исследовать. Это описание с одной стороны должно отражать сферу интересов заказчика в данной предметной области, с другой стороны должно быть достаточно формализованным для того, чтобы с ним можно было работать с помощью математических методов. В нашем контексте, ИО в реальном мире соответствует некоторому набору технических и технологических решений, которые определяют развитие данного ИО. Поэтому, возможно, правильнее было бы называть его ИО НТС, однако для краткости ограничимся сокращением ИО.
Например, поставлена задача, исследовать перспективы использования никеля в автомобильных аккумуляторах и выбрать наиболее перспективную технологию такого использования. Информационном объектом в таком исследовании будет «технология использования никеля при изготовлении автомобильных аккумуляторов».
Задачу исследования тенденций, определяющих развитие ИО можно разделить на три этапа:
§ сбор информации об ИО;
§ первичный анализ;
§ прогнозирование;
§ интерпретация результатов анализа.
3. Сбор информации
3.1. Патенты, как источник информации для анализа в НТС.
В разделе «Введение» патентная информация была расценена, как наиболее подходящий источник научно-технической информации (далее - НТИ). Даже методы анализа, которые a priori применимы и к другим видам НТИ, были названы именно методами патентных исследований.
Перечислим свойства массива патентной информации, которые делают ее наиболее предпочтительной для целей анализа тенденций в научно-технической сфере (НТС).
Во-первых, это полнота. Подавляющее большинство новых научно-технических идей описаны в патентных документах. Патентный фонд охватывает всю научно-техническую деятельность человека.
Во-вторых, оперативность. В соответствии с международным юридическим статусом патентных документов они являются первыми опережающими публикациями.
В-третьих, достоверность. Реальная осуществимость предлагаемого в патенте технического решения и возможность получения обещанного эффекта подтверждаются вневедомственной экспертизой, и за них несет юридическую и материальную ответственность патентовладелец.
В-четвертых, формализованность. Патентный фонд всех основных стран классифицирован по единой для них международной классификации изобретений.
Согласно теоретическим положениям информатики, научным документом считается материальный объект, содержащий закрепленную научную информацию, предназначенный для ее передачи во времени и пространстве и используемый в общественной практике. Как видно из вышеуказанных пунктов, это определение может быть полностью отнесено к патентной информации.
3.2. Сбор информации для анализа
Перед началом анализа, необходимо:
§ формализовать описание ИО;
§ собрать информацию, на основании которой будет вестись анализ.
Прежде всего, полагаем, что у нас имеется доступ к репрезентативному хранилищу патентной документации, на основании которой мы будет вести анализ.
Тогда под формализацией ИО мы понимаем, в первую очередь, подбор таких запросов к хранилищу, которые позволили бы нам получить множества патентов, описывающих тот или иной аспект ИО. Простейшим способом формулирования таких запросов является выявление списка ключевых слов, а также индексов МПК, соответствующих ИО. Эта работа проводится экспертом по предметной области с использованием поискового механизма над хранилищем.
После того, как необходимые запросы сформулированы (в наших терминах - произведена формализация ИО) с их помощью из хранилища «высекается» массив документов, на которых будет вестись сбор информации для анализа. Этот массив назовем генеральной совокупностью. Именно с ней будет вестись работа на этапе статического и динамического анализа, одной из процедур первичного анализа, к описанию которой мы сейчас переходим.
4. Процедуры первичного анализа
Процедура первичного анализа состоит из следующих этапов:
§ системный анализ;
§ подготовка данных для построения временных рядов;
§ статический и динамический анализ поведения построенных для этого ИО рядов; процедура анализа является также «поставщиком входной информации» для процедуры прогнозирования.
4.1. Системный анализ
Данный этап необходим для того, чтобы сформулировать комплексное многоаспектное представление об информационном объекте с целью установления наиболее полного списка возможных состояний как объекта в целом, так и отдельных его частей.
Вначале проводят логический анализ сущности исследуемого объекта и выявляют возможные аспекты, по которым его можно классифицировать. Эти аспекты – основания деления классификации данного ИО. Данная классификация строится с целью более подробно формализовать ИО, и получить, тем самым информационную модель объекта исследования. Ее построение подчиняется обычным правилам построения морфологически классификаторов (см., например, [10]). Так, например, как основания деления могут быть приняты на верхних уровнях классификации – качественные формулировки целей развития, на нижних – решаемые технические задачи.
Будем далее обозначать основания деления (аспекты) как ![]() . Они не должны пересекаться, то есть при их выборе должны соблюдаться условия:
. Они не должны пересекаться, то есть при их выборе должны соблюдаться условия: ![]() при
при ![]() . и т. д. По каждому из выбранных оснований деления необходимо определить все возможные варианты выполнения (направления развития) объекта. Они представляют собой классы mij, на которые подразделяется совокупность объектов, подобных исследуемому по данному основанию деления. Полученная совокупность оснований деления и классов внутри них может быть описана матрицей типа:
. и т. д. По каждому из выбранных оснований деления необходимо определить все возможные варианты выполнения (направления развития) объекта. Они представляют собой классы mij, на которые подразделяется совокупность объектов, подобных исследуемому по данному основанию деления. Полученная совокупность оснований деления и классов внутри них может быть описана матрицей типа:
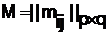 (1),
(1),
в которой каждая строка ![]() соответствует основанию деления. На данном этапе в содержательном плане под mij – можно понимать количество документов отвечающих рубрикам i, j за некоторый фиксированный год. Индекс j определяет j-й класс деления i-го аспекта. Частным случаем такой матрицы может служить матрица цели-средства, где в одном из входов матрицы перечислены цели изобретения, а во втором входе производится разбивка по средствам достижения этих целей.
соответствует основанию деления. На данном этапе в содержательном плане под mij – можно понимать количество документов отвечающих рубрикам i, j за некоторый фиксированный год. Индекс j определяет j-й класс деления i-го аспекта. Частным случаем такой матрицы может служить матрица цели-средства, где в одном из входов матрицы перечислены цели изобретения, а во втором входе производится разбивка по средствам достижения этих целей.
Следующей стадией анализа является сопоставление каждого из документом данной выборки классам информационной модели объекта. Для ряда объектов в качестве информационно поисковой системы используется библиография патентных документов. Соответствие документа тому или иному классу информационной модели может быть определено по индексам стандартной классификации изобретений (чаще всего, МКИ). Для этого каждому классу информационной модели сопоставляется рубрики МКИ. Эта операция носит название «составление рубрикатора проблемы в терминах МКИ». С помощью информационной модели каждый документ кодируется набором ячеек матрицы (1) к которым он относится:
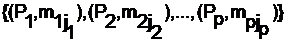
Здесь предполагается, что если документ не попадает ни в один из классов основания деления ![]() , то ji=0. Таким образом, каждый из документов может быть индексирован по каждому основанию деления. Индекс документа удобно записывать в суперпозиционной системе записи индекса документа по отношению к выбранной информационной модели:
, то ji=0. Таким образом, каждый из документов может быть индексирован по каждому основанию деления. Индекс документа удобно записывать в суперпозиционной системе записи индекса документа по отношению к выбранной информационной модели:
(j1 j2 … jp).
Пример.
Документ ![]() имеет индекс
имеет индекс
(
Глубина классификации должна определяться количеством получаемых подклассов. В случае, если число классов велико, следует произвести дополнительную кластеризацию полученного множества классов. В ряде случаев полезным является построение круговых диаграмм по выделенным подмножествам суперпозиционных индексов. Одной из задач исследования на данном этапе является выявление всех подклассов МПК по интересующему объекту (количество таких подклассов может доходить до нескольких сотен).
4.2. Подготовка данных для построения временных рядов и их
Итак, мы имеем информационная модель исследуемого объекта, состоящую из:
- описания генеральной совокупности;
- классификации ИО (в виде некоего рубрикатора; если документом является патенты – то рубрикаторы в терминах МКИ).
Далее необходимо провести процедуры построения временных рядов по данным этой модели для выполнения конкретных аналитических задач.
4.2.1. Динамический анализ
Динамический анализ предназначен для выявления и исследования закономерностей и тенденций в изобретательском интереса к различным аспектам развития ИО. Выявленные тенденции сравниваются (оценивается динамика роста изобретательского интереса к ИО) и на основании этого делаются выводы о перспектива развития того или иного аспекта ИО.
Аспекты, в данном случае, соответствуют классам mij.
Для каждого аспекта строится динамический временной ряд (см. п. 2.1).
Для построения временного ряда для аспекта применяется следующая процедура.
1. Для каждого mij формулируется запрос, «высекающий» некоторое подмножество генеральной совокупности (будем обозначать это подмножество также mij);
2. Далее это подмножество распределятся по годам по одному из реквизитов с типом «дата»; для патентов – это обычно бывает «дата публикации патента» или «дата публикации заявки»;
3. Строится динамический временной ряд на основании соответствия:
![]()
где «|1999(mij)|» количество документов из класса mij за 1999 год
Напомним, что mij является j-м классом основания деления ![]() . Физический смысл этого факта в том, что динамический временной рад, построенный по классу mij, отражает динамику изобретательского интереса по j-ой альтернативе i аспекта исследования нашего информационного объекта.
. Физический смысл этого факта в том, что динамический временной рад, построенный по классу mij, отражает динамику изобретательского интереса по j-ой альтернативе i аспекта исследования нашего информационного объекта.
Итак, временные ряды построены.
Что же дальше? Об этом - в п. 4.2.3.
А пока посмотрим, что представляет собой статический анализ.
4.2.2. Статический анализ
Статический анализ предназначен для выявления структуры изобретательского интереса к ИО.
Рассмотрим несколько типичных задач, решаемых в рамках статического анализа.
1) Статический анализ может проводиться, например, с целью конкурентной разведки для выявления списка активных в этой области фирм, ранжированных по убыванию их заявок или патентов.
Полученные в результате ранжирования статические ряды, позволяют оценить структуру рынка данной предметной области.
2) Оценка изобретательской активности первой, второй и т. д. пятерки фирм, с разбивкой по годам требуемого временного интервала позволяет определить степень устойчивости интересов фирм в данной предметной области.
Компоненты статистического ряда здесь распределяются по годам, превращаясь в серию временных рядов, каждый из которых описывает динамику изменения интереса отдельной фирмы в данной предметной области
3) Определение технической области, находящейся в сфере основных интересов фирмы.
Данный аспект оценивается изучением статического временного ряда на предмет определения количества преобладающих патентных документов.
4) Определение доли каждого из направлений разработок в данной технической области.
Производится ранжирование по реквизитам, отражающим техническую область (как правило, это индекс МПК). Полученный статический ряд позволяет определить искомое (долю). Параметризация этого ряда временем (переход к динамическому ряду) позволяет оценить устойчивость данного направления во времени.
Итак, решения задач сводятся к построению рядов – статических или динамических (временных).
Что же дальше? Об этом - в п. 4.2.3.
4.2.3. Что же дальше?
В пунктах 4.2.1 и 4.2.2 мы показали, как перейти от постановки задач анализа, касающихся разных аспектов анализа ИО, к рядам, которые можно подвергать статистическому анализу и интерпретации.
Временной ряд позволяет выполнить две задачи:
§ мониторинг исследуемого явления (на основании исторических данных) ;
§ будущее развитие исследуемого явления (на основании построенной статистической модели поведения временного ряда).
И данные мониторинга, и данные интерполированного поведения ряда в будущем необходимо подвергнуть интерпретации, для перехода от формальной модели к процессам реального мира.
Интерпретация является финалом нашего анализа. Но перед тем, как перейти к описанию интерпретации, затронем вопросы прогнозирования поведения временного ряда.
5. Процедуры прогнозирования
Прогнозированием мы называем процесс, включающий в себя:
§ выбор математической модели на основании информации полученной на этапе анализа;
§ подбор параметров модели.
Рассмотрим вопрос прогнозирования более подробно.
5.1. Выбор модели
При составлении прогнозов временных рядов наибольшее распространение получил алгоритм авторегрессии и интегрального скользящего среднего АРИСС – ARIMA. Вопрос о применимости данной модели для анализа временных рядов мы оставим за рамками данной статьи. Этот вопрос подробно изучен в раде работ(см., например, [11]).
Для применения этого алгоритма временной ряд, подлежащий прогнозированию, вначале должен быть идентифицирован на принадлежность одной из моделей АРИСС-ы. Эта задача имеет важное значение для достоверности выходных прогнозов. В приложении 1 и 2 приводятся примеры прогнозов при неудачном выборе модели. Следует отметить, что подобная предварительная классификация исходного временного ряда к сожалению не может быть выполнена формально и требует определенных знаний. Нивелировать этот пробел можно, перебирая некоторые из основных вариантов выбора параметров, характеризующих ту или иную модель, с последующей эвристической оценкой получаемых при этом результатов. Одним из способов «проверки» выбранной модели на состоятельность является сравнение результатов прогноза, построенных для усеченных справа рядов, с имеющимся реальным продолжением ряда. Особенно важны такие проверки для случаев, когда существуют близкие по оценкам сходящиеся модели АРИСС-ы (это, кстати, наиболее часто встречающаяся на практике ситуация). Модель с худшими формальными оценками, выставляемыми системой, может оказаться более подходящей для данного ряда. Необходимо реально смотреть на это, кажущееся вначале странным, положение вещей. Дело в том, что в алгоритмах, реализованных в статистических пакетах, делается некоторое количество предположений о вероятностном характере изучаемого ряда и законах распределений, участвующих в формировании временной последовательности. Наконец, наиболее жесткими, на самом деле, являются предположения о структуре и составляющих временного ряда, причем именно эти базовые предположения, лежащие в основе используемой теории, и не подлежат никакому обсуждению в силу естественного отсутствия, каких либо соображений по этому поводу. Важным моментом при построении прогнозов является повышение «представительности» имеющихся временных выборок. В этом документе предлагается использовать известный и хорошо зарекомендовавший себя аппарат кубических сплайн функций для повышения деталировки временных выборок. Не вдаваясь в детали обоснования использования сплайнов, отметим такие их свойства, как свойство минимальности кривизны и минимальности нормы, позволяющие «восстанавливать» дискретно заданные функции до их «аналитически заданных родителей». В приложении 2 приводятся результаты прогнозирования с использованием такой предварительной деталировки на примере временных рядов изобретательской активности в мотоциклостроении по шести ведущим фирмам за период гг.
В классе параметрических моделей временных рядов известное распространение получила общая линейная модель. В пакете STATISTICA рассматривается один из простейших случаев, когда тип модели алгоритма авторегрессии и интегрированного скользящего среднего ( АРИСС ) определяется тремя параметрами: d – порядок разности, p – порядок авторегрессии, q – порядок скользящего среднего. Ряды такой модели имеют вид
![]()
где ![]() - белый шум, т. е. последовательность независимых и одинаково распределенных случайных величин с конечной дисперсией и математическим ожиданием, равным нулю.
- белый шум, т. е. последовательность независимых и одинаково распределенных случайных величин с конечной дисперсией и математическим ожиданием, равным нулю. ![]() - некоторые коэффициенты. Реально в программе удается получать результаты лишь в случаях, когда указанные параметры принимают значения 0 ,1 и очень редко 2.
- некоторые коэффициенты. Реально в программе удается получать результаты лишь в случаях, когда указанные параметры принимают значения 0 ,1 и очень редко 2.
5.2. Процедура подбора параметров.
5.2.1. Преобразование ряда к стационарному виду
Формально, построение прогноза должно производиться для стационарного ряда. Первым шагом исследования данного ряда является визуальный анализ графика на предмет выделения простейших, хорошо просматриваемых трендов (составляющих). Из визуально наблюдаемых трендов отметим стационарность, линейность, квадратичный тренд, логарифмический, экспоненциальный. Наличие тренда свидетельствует о нестационарности ряда. Обнаруженный явный тренд необходимо удалить. Под этим термином, в данном случае, понимается вычитание соответствующей составляющей, параметры которой автоматически определяются программой Статистика, из исходного ряда. После удаления тренда, полученный преобразованный ряд проверяется на стационарность, как это описывается ниже. Забегая вперед, сделаем несколько замечаний по поводу использования тренда в дальнейшем, если таковой был обнаружен. Для исходного ряда и ряда, полученного вычитанием тренда, проводятся построения автокорреляционной функции и нахождение оценок достоверности результатов анализа. В том случае, если для трансформированного ряда результаты такого анализа будут более качественными, то прогноз строится для трансформированного ряда, после чего производится обратная операция по прибавлению тренда к полученному в результате ряду.
5.2.2. Проверка стационарности ряда
Стационарность ряда можно выявить, рассматривая автокорреляционную функцию. Для выявления стационарности следует для последовательности сдвигов (lags) в просмотреть графики автокорреляции. О стационарности ряда говорит тенденция к затуханию автокорреляционной функции. Рассмотри ряды на рис. 1,3. Примеры соответствующих затухающих автокорреляционных функций приведены на рис. 2,4.
Как известно, нестационарные ряды преобразовываются в стационарные путем перехода от исходного ряда к его разностям порядка d : 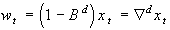 , где B - оператор сдвига назад:
, где B - оператор сдвига назад: 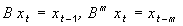 .
.
Для стационарного ряда должно d = 0.
Тем самым нам необходимо определить d, для того что бы преобразовать ряд к стационарному.
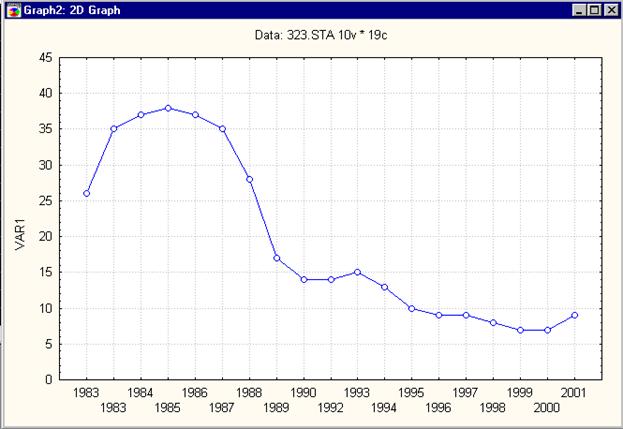
Рис.1. Пример ряда.
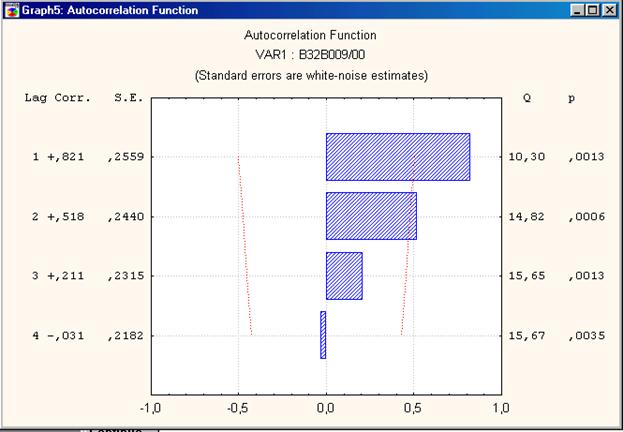
Рис.2. Автокорреляционная функция для ряда, представленного на рис.1, лаг = 4.
Рис.3. Еще один пример ряда.
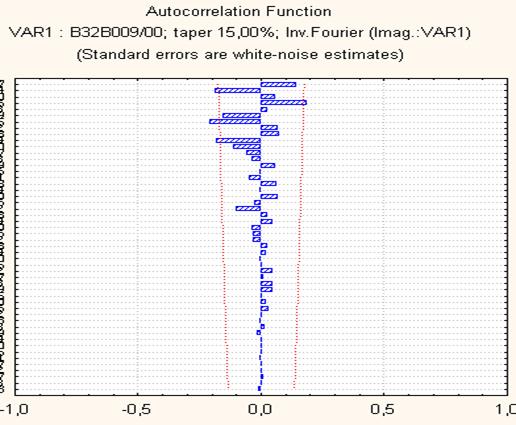
Рис.4. Автокорреляционная функция для ряда, представленного на рис.3, лаг = 50.
5.2.3. Определение параметра d с помощью конечных разностей
Если k-я разность исходного ряда является стационарным рядом, то d = k. Определение порядка разностей приводящих ряд к стационарному виду носит не строгий характер. Возможность работы с несколькими альтернативными значениями параметра d вполне допустима. На практике редко используются порядки выше второго.
5.2.4. Работа со стационарными рядами или рядами, приведенными к стационарному виду
Имеются следующие эвристические «закономерности», связывающие порядок авторегрессии p и порядок скользящего среднего q.
Для процесса авторегрессии порядка p его частная автокорреляционная функция становится равной нулю на лаге p и частная автокорреляционная функция монотонна.
Для процесса скользящего среднего порядка q его частная автокорреляционная функция становится равной нулю на лаге q и частная автокорреляционная функция монотонна.
Для моделей с p и q, не равными нулю одновременно, автокорреляционная функция равна сумме экспонент и затухающих синусоид. Из практических наблюдений известно, что большинство наблюдаемых рядов, описываемых смешанной моделью авторегрессии и скользящего среднего, могут быть отнесены с достаточной степенью точности к одному из следующих классов:
АР(1):Авторегрессия первого порядка: p=1,q=0;
АР(2):Авторегрессия второго порядка: p=2,q=0;
СС(1):Скользящее среднее первого порядка: p=0,q=1;
СС(2):Скользящее среднее второго порядка: p=0,q=2;
АРСС(1,1):Авторегрессия и скользящее среднее порядка 1: p=1,q=1.
Имеются следующие эвристические критерии определения модели по автокорреляционным или частным автокорреляционным функциям (Pankratz (1983), Бокс, Дженкинс (1974)):
АР(1)-автокорреляционная функция экспоненциально затухает (по модулю), частная автокорреляционная функция имеет выброс на лаге 1;
АР(2)-автокорреляционная функция синусоидально затухает или экспоненциально затухает, частная автокорреляционная функция имеет выброс на лаге 1,2;
СС(1)-автокорреляционная функция имеет выброс на сдвиге 1, частная автокорреляционная функция экспоненциально затухает по модулю;
СС(2)- автокорреляционная функция имеет выбросы на сдвигах 1,2, частная автокорреляционная функция синусоидальна, либо экспоненциально затухает;
АРСС(1,1)- автокорреляционная функция экспоненциально затухает, начиная с первого лага (первое значение не нулевое), затухание либо монотонное, либо колебательное, частная автокорреляционная функция имеет либо экспоненциальную составляющую, либо монотонную, либо осциллирующую (первое значение не нулевое).
Заметим, что эти критерии позволяют проводить работу по формальному статистическому анализу человеку, не обладающему значительным экспертным опытом в приложениях математической статистики.
5.2.5. Малопредставительные ряды
Прогнозирование для временных рядов содержащих незначительное число членов (меньше 50) практически невозможно. Решить эту проблему позволяют интерполяционные методы. В силу ряда своих свойств, хорошим аппаратом для таких целей могут служить кубические сплайны, обеспечивающие интерполяцию в данных точках временного ряда и необходимую гладкость получаемой в результате интерполяции аналитически заданных функции. Их преимуществом по сравнению с некоторыми другими типами сплайнов является то, что будучи построенными на некотором временном отрезке для интерполяции табличных данных они имеют носители, выходящими за пределы этого временного отрезка. На основе этого может быть предложена следующая методика прогнозирования за пределами заданного временного промежутка:
1. По заданному распределению {tk , yk},k=0,...,n строится кумулятивное распределение.
2. Строится интерполирующий кубический сплайн для кумулятивной таблицы (прототип).
3. На основе метода наименьших квадратов подбирается B-сплайн, удовлетворяющий поставленным условиям оптимальности. В последнем случае таким условием является минимизация уклонения В-сплайна от прототипа. Параметрами варьирования при поиске оптимального В-сплайна помимо "моментов" служат краевые условия.
4. Значения построенного В-сплайна за пределами заданного временного интервала.
Замечание. В пункте 3 можно рассматривать различные критерии выбора оптимального В-сплайна. Сам выбор этого критерия также может быть адаптирован под данное распределение ИА. Простейшая методика состоит в следующем. Пункты 1, 2, 3 выполняются не для всего распределения {tk , yk},k=0,...,n, а для усеченного распределения {tk, yk},k=0,...,n-1. Табличное значение yn используется для контроля выбора методики оптимизации (точнее выбирается та из имеющихся методик оптимизации, которая обеспечивает наибольшую близость, полученного в результате экстраполяции значения zn к имеющемуся значению yn). Из методик выбора В-сплайна отметим "метод усреднения", когда хвосты В-сплайнов правее исходного временного промежутка усредняются средними арифметическими значениями, а в качестве самих сплайнов берутся В-сплайны, построенные по различным выборкам временных узлов из заданного промежутка { t0 , t1 , ... , tn }. Отметим, что вполне допустимы и выборки с не равноотстоящими узлами.
На рис. 5 приведен пример, как из ломанной построенной по малопредставительному ряду (реальные значения ряда – точки пересечения синей и красной линий).
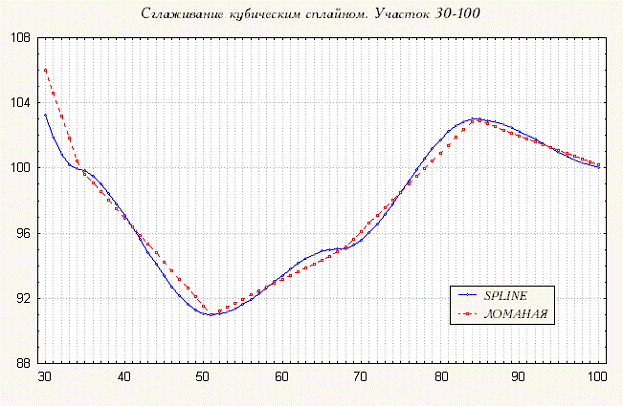
Рис.5. Пример сглаживания кубическими сплайнами.
Пример такой интерполяции приводится в приложении 3, где приводится листинг программы сплайн-интерполяции, позволяющий производить построение сплайнов в рамках программы. Программа написана на внутреннем языке одного из пакетов статистического анализа (Statistica).
6. Интерпретация результатов.
Итак, тенденции управляющие поведением нашего информационного объекта смоделированы. Для направления его развития по каждому аспекту (в терминах п. 4.1 - основанию деления классификации) мы имеем как графики, отражающее динамику изобретательского интереса к данному направлению в прошлом, так и прогноз динамики на будущее.
По интервалам монотонности графиков и экстремумам полученных кривых можно провести анализ, и выявить такие основные моменты, как
§ фазу жизненного цикла, на которой находится данный ИО;
§ перспективность того или иного направления развития данного аспекта ИО;
§ провести сравнительный анализ различных направлений развития.
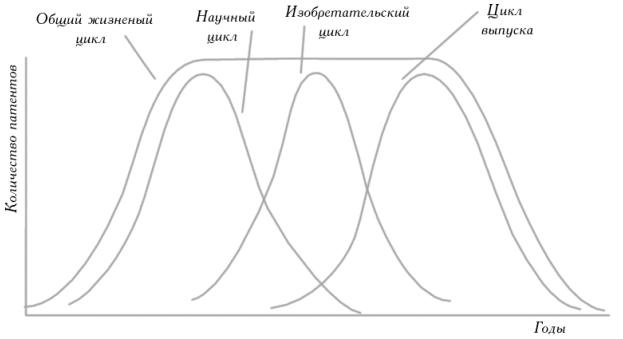
Рис.6. Фазы жизненного цикла, которые проходит ИО НТС.
С другой стороны, воспользовавшись статическими рядами, построенными в рамках статического анализа, представив их в виде круговых диаграмм, графиков и таблиц, можно наглядно проиллюстрировать результаты решения задач, изложенных в п. 4.2.2. Приложение 2 показывает применение анализа и моделирования развития мотоциклостроения для конкретного набора фирм.
7. Заключение.
Очевидно, что подход, описанный в данной работе может, основан не только на массиве патентов. Другие источники научно-технической информации также могут быть использованы для целей, сформулированных выше, таких как определение технологической политики, конкурентной разведки и т. п. Это – специальная литература, касающаяся данной предметной области, реферативные журналы и т. п. Более того, даже такое слабо структурированный источник информации, как новостные ленты может быть базисом для работы классификационно-статистических методов, описанных в статье. Однако в упомянутых случаях всегда необходимо проводить обоснование правомерности использования каждого конкретного массива информации по признаками полноты, оперативности, достоверности (см. 3.1). Только в этом случае можно строить адекватные оценки ошибок прогнозирования.
Методы выявления, анализа, прогнозирования, описанные в статье, могут быть применены при создании автоматизированных информационно-аналитических систем. Авторы участвовали в подобном проекте, проводившимся под эгидой ИСА РАН в рамках проекта РФФИ.
Приложение 1. Зависимость качества прогноза от правильности выбора параметров.
В этом приложении приведены примеры построения прогнозов в случае правильного и неправильного выбора модели (конкретно – ее параметров).
Зеленая линия на рисунке показывает 90% доверительный интервал.
Красная – предсказанное поведение ряда.
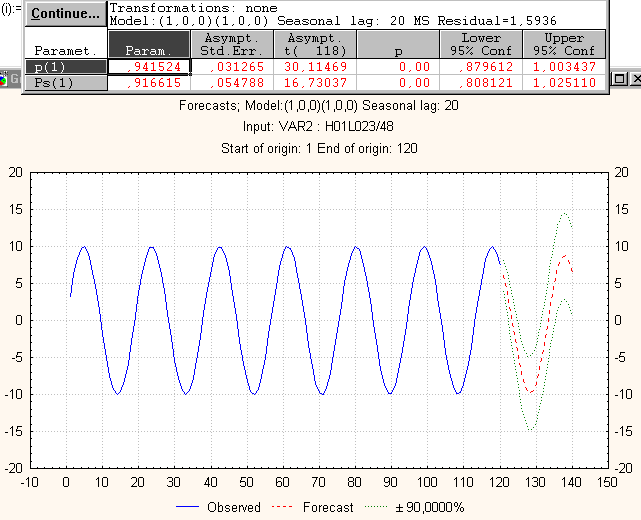
Рис П1.1. Пример правильно выбранной модели АРИСС-ы, с предварительным подсчетом сезонности спектральными методами
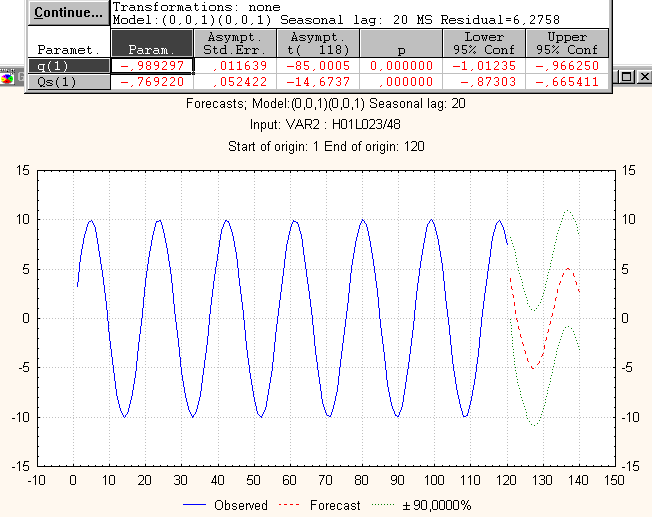
Рис П1.2. Пример неудачно выбранной модели АРИСС-ы с правильно подсчитанной сезонностью.
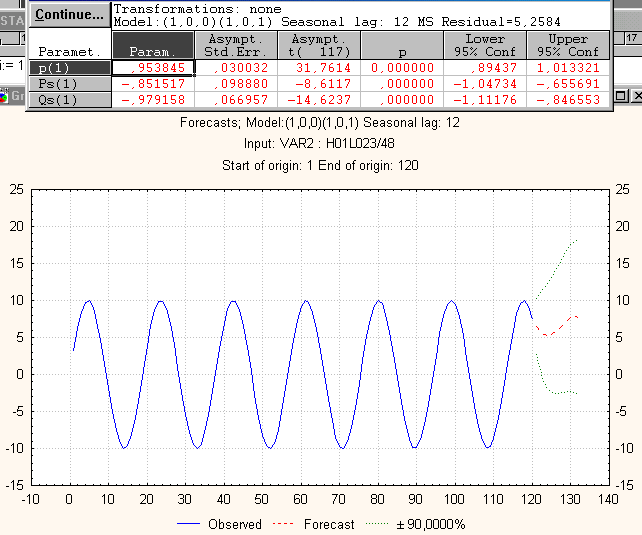
Рис П1.3. Пример неправильно выбранной модели АРИСС-ы с неправильно подобранной сезонностью
Приложение 2. Прогнозы временных рядов ИА в мотоциклостроении по ведущим фирмам
В данном приложении приводятся результаты прогнозов ИА по фирмам представленным в таблице 1. В качестве «предсказывающего» взято сужение данных временных рядов на периоде гг., т. е. без последних трех лет. Это сделано для того, чтобы сравнить результаты прогнозов с действительным развитием избирательской активности. Прогноз делался на три года, . Для удобства на графиках показан только участок прогнозируемого периода. На каждом графике показаны: кривая прогноза и две границы доверительного интервала, кривая действительного состояния дел, которая в прогнозе, естественно, не участвовала. Выбор модели АРИСС-ы и оценки прогнозов показаны на рисунках перед графиками. Перед каждым прогнозом произведена интерполяция временного ряда с детализацией по 36 дней (каждый год разбит на 10 временных участков).
Годы | Количество патентов фирмы | |||||
Ямаха | Хонда | Сузуки | Кавасаки | Харлей Девидсон | ||
1981 | 299 | 253 | 153 | 95 | 161 | 25 |
1982 | 345 | 314 | 197 | 71 | 53 | 27 |
1983 | 415 | 295 | 144 | 88 | 76 | 34 |
1984 | 391 | 347 | 201 | 101 | 67 | 17 |
1985 | 401 | 387 | 165 | 98 | 99 | 11 |
1986 | 375 | 281 | 177 | 111 | 75 | 21 |
1987 | 419 | 440 | 113 | 95 | 80 | 33 |
1988 | 407 | 451 | 205 | 193 | 65 | 39 |
1989 | 388 | 421 | 265 | 121 | 51 | 48 |
1990 | 393 | 409 | 207 | 155 | 68 | 54 |
1991 | 417 | 434 | 200 | 105 | 69 | 49 |
Таб. П2.1. Динамика патентной активности производителей мотоциклов.
Ниже приведены описания параметров моделей, описывающих научно-техническое развитие фирм-производителей мотоциклов и графики прогнозов.
1. Ямаха
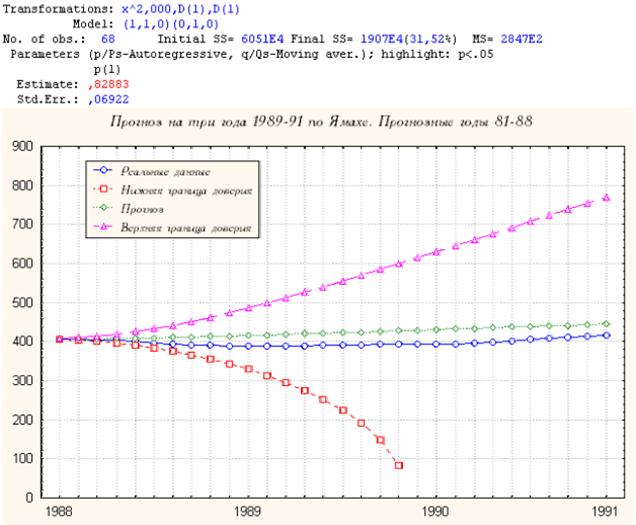
Рис. П2.1. Прогноз на три года по фирм Ямаха
Резкий спад нижней границы доверительного интервала говорит о том, что прогноз на второй половине выбранного трех летнего интервала не оправдан.
2. Хонда
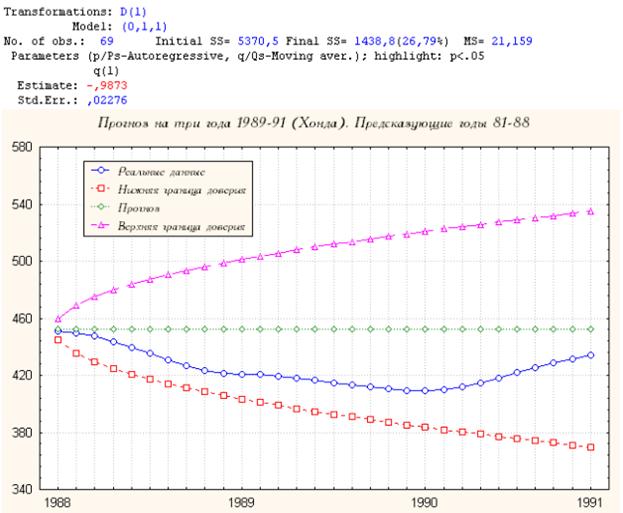
Прогноз приемлем на весь период.
3. Сузуки
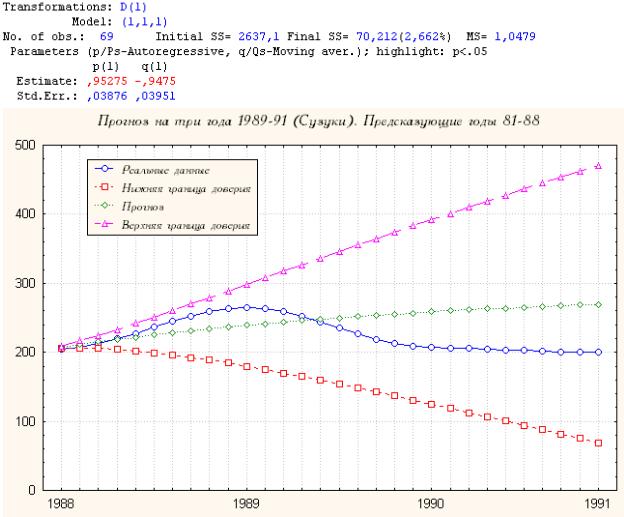
Как мы видим, прогноз хорошо приближает случайные данные даже в конце трехлетнего периода. Однако в данном случае это просто совпадение.
Стандартная ошибка для третей части периода () достаточно велика(~ 0.038).
4. Кавасаки
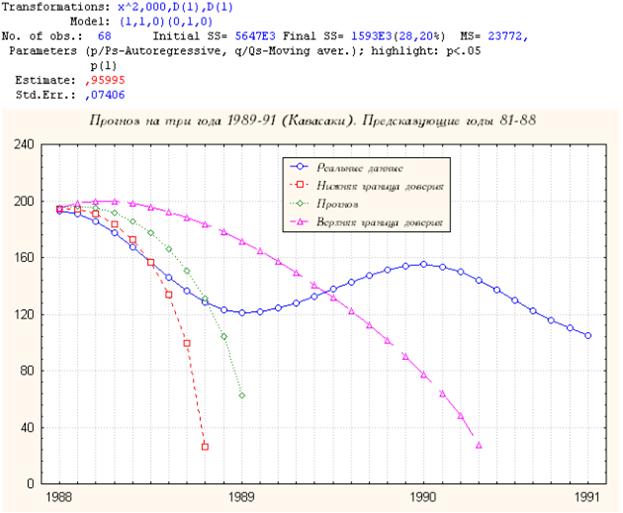
Пример неудачного прогноза: прогнозная кривая - вне конуса. Величина стандартного отклонения – достаточно велика: ~0.07.
5.BMW
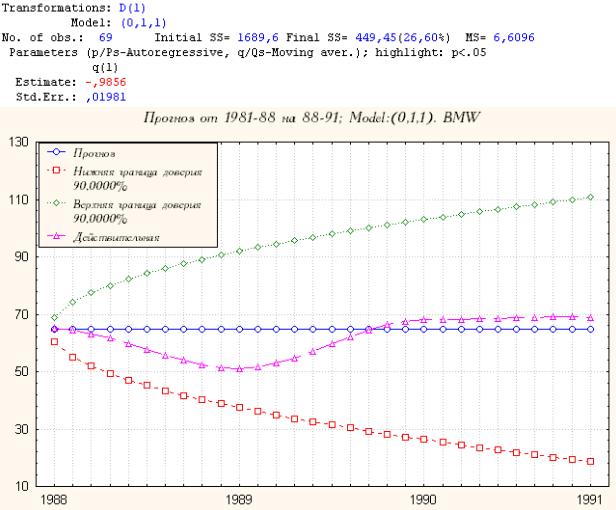
Также как и для Сузуки прогноз случайно очень хорошо приближает реальные данные. Впрочем, стандартная ошибка весьма низкая в данном случае: ~ 0.02.
Харлей Девидсон
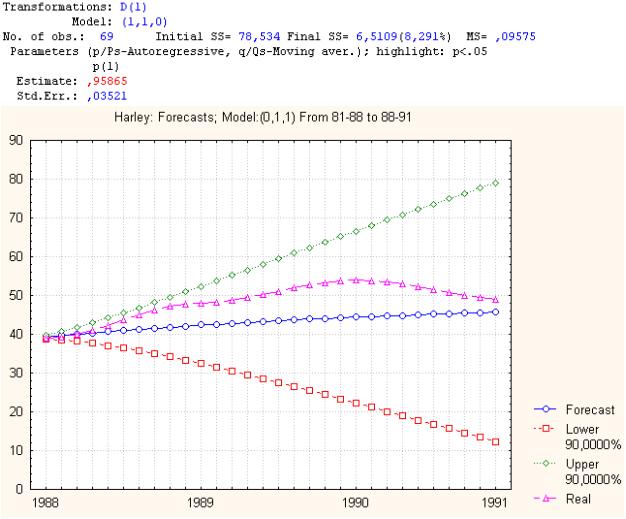
Приложение 3. Сглаживание. Программа построения кубического сплайна.
Dim y(1);
Dim y100(1);
Dim c(1);
Dim m(1);
Dim x0(1);
Dim x(1);
Dim Matrix(1,20);
Function Spline(xxx);
begin
j:= Trunc(xxx)+1;
A2:=(j-xxx)*(j-xxx);
B2:=(xxx-j+1)*(xxx-j+1);
yyy:=m(j)*A2*(xxx-j+1);
yyy:=yyy+m(j+1)*(j-xxx)*B2;
yyy:=yyy+y(j)*A2*(2*(xxx-j+1)+1);
yyy:=yyy+y(j+1)*B2*(2*(j-xxx)+1);
Spline:=yyy;
end;
n:=0;
j:=1;
beg:
n:=n+1;
if(v1(j) <> 11111) then begin j:=j+1; goto beg; end;
n:=n-2;
n1:= n+1;
n2:= n+2;
n100:=100;
n101:=n100+1;
ReDim y (n1);
ReDim y100 (n101);
ReDim c (n1);
ReDim m (n2);
ReDim x0 (n2);
ReDim x (n1);
WriteLn ('The protocol of cubic spline approximation:');
WriteLn ('Points number = ',n1,'');
WriteLn ('Output points number = ',n100,'');
WriteLn('Start values of function: ');
for j:= 1 to n1 do
begin
y(j):= v1(j);
Write(' ',Str(y(j),8,2),';');
end;
WriteLn;
for j:= 2 to n do c(j):= 1.5*(y(j+1)-y(j-1))/n;
c(1):=c(2);
c(n1):=c(n);
x(n1):=1;
x(n):=-4*x(n1);
for k:= 1 to n-1 do x(n-k):=-4*x(n-k+1)-x(n-k+2);
x0(n1):=0;
x0(n):=2*c(n1)-4*x0(n1);
for k:= 1 to n-1 do x0(n-k):=2*c(n-k+1)-4*x0(n-k+1)-x0(n-k+2);
cc0:=(2*c(1)-4*x0(1)-x0(2))/(4*x(1)+x(2));
WriteLn('The moments: ');
for k:= 1 to n1 do
begin
m(k):=cc0*x(k)+x0(k);
Write(' ',Str(m(k),8,2),';');
end;
WriteLn;
WriteLn('The results: (x0:Spline(x0)) (x1:Spline(x1)) (x2:Spline(x');
count:=0;
for j:=0 to n100-1 do
begin
xx:=j*n/n100;
v2(j+1):= Spline(xx);
Write('(',Str(j+1,3,0),':');
Write('',Str(v2(j+1),8,2),') ');
count:=count+1; if(count=5) then begin count:=0; WriteLn; end;
end;
v2(n101):= v1(n1);
Write('(',Str(n101,3,0),':');
Write('',Str(v2(n101),8,2),') ');
WriteLn;
i:=1;
vv1:=v1(i);
vv2:=v1(i+1);
for j:=0 to n100-1 do
begin
xx:=1+j*n/n100;
if(xx > i+1) then
begin
i:=i+1;
vv1:=v1(i);
vv2:=v1(i+1);
end;
v3(j+1):= (xx-i)*vv2+(i+1-xx)*vv1;
end;
v3(n101):= v1(n1);
WriteLn('========================= ','16.06.2001 A. Loginov',' =========================');
Литература.
1. , Прогнозирование научно-технической политики предприятия на базе патентной документации (Обзор), Патентный центр «Ориентир», Москва, 1992.
2. Алберг Дж.,Уолш Дж., Теория сплайнов и её приложения, Издательство «Мир», Москва,1972.
3. Зборовский развития техники по патентным материалам. – В сб.: Анализ тенденций и прогнозирование НТП. – Киев: Наукова думка, 1967.
4. Васильев дополнительных сведений при анализе патентов. – М.: ЦНИИПИ, 1967
5. , , Сплайны в вычислительной математике, Наука, Москва,1976.
6. Бокс Дж., Анализ временных рядов. Прогноз и управление, вып. 1,2,-М., Мир, 1974.
7. Распределенные лаги. Проблема выбора и оценивания модели,-М., Финансы и статистика, 1982.
8. , Приближение дискретных функций на равномерной сетке алгебраическими многочленами, Известия высших учебных заведений, сер. Математика, т.12,1986, 42-45.
9. , Наилучшие приближения непрерывных функций кусочно-монотонными, Известия АН СССР, сер. Математическая, т. 38, 1974, .
10. , Картавов анализ систем. – Киев; Наукова Думка, 1977
11. Бокс Дж., Анализ временных рядов. Прогноз и управление, вып. 1,2,-М., Мир, 1974.
