

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
3.Документальные БД
Часто И для БД представлена не в виде структурированных массивов данных, а в виде текстовых документов. Вследствие этого документальные БД (полнотекстовые) сразу выделялись в особый тип баз данных. Применяется также термин информационно-поисковые системы (ИПС). Хотя, точнее - документальными ИПС (ДИПС), поскольку традиционные СУБД также являются ИПС, только фактографическими (ФИПС).
Основной функцией любой ДИПС является информационное обеспечение потребителей на основе выдачи ответов на их запросы. Осуществление выдачи данных реализуется главной операцией ДИПС - информационным поиском. Информационный поиск - процедура отыскания документов, содержащих ответ на заданные потребителем вопросы. ДИПС в результате проведения информационного поиска предоставляет потребителю совокупность документов, смысловое содержание которых соответствует его запросу. ДИПС ориентированы на частичное, приближенное представление данных, имеющих значительно более сложную смысловую структуру, чем в ФИПС, поэтому результатом поиска служат тексты, которые в какой-то мере соответствуют запросам, представленным на входе в форме текста.
Информационный поиск в системе проводится на основе поступившего от потребителя запроса на отыскание необходимой ему информации. Информационная потребность людей постоянно изменяется и трансформируется. Частное значение информационной потребности потребителя в определенные моменты времени, выраженное на естественном языке (ЕЯ) - информационный запрос (ИЗ), с которым пользователь обращается к системе.
 Однако запрос может быть неправильно сформулирован потребителем (не отражать инф. потр.), и при проведении информационного поиска рассматривается не информационная потребность пользователя, а только информационный запрос. Для выражения данных отношений в теории ДИПС введены два фундаментальных понятия: пертинентность и релевантность. Пертинентность - соответствие смыслового содержания документа информационной потребности потребителя. Релевантность - соответствие содержания документа информационному запросу в том виде, в каком он сформулирован. Автоматизация процесса информационного поиска потребовала формализации представления смыслового содержания ИЗ и документов в виде соответственно поискового предписания (ПП) и поисковых образов документов (ПОД). Для записи ПП и ПОД применяются специальные языки, называемые информационно-поисковыми.
Однако запрос может быть неправильно сформулирован потребителем (не отражать инф. потр.), и при проведении информационного поиска рассматривается не информационная потребность пользователя, а только информационный запрос. Для выражения данных отношений в теории ДИПС введены два фундаментальных понятия: пертинентность и релевантность. Пертинентность - соответствие смыслового содержания документа информационной потребности потребителя. Релевантность - соответствие содержания документа информационному запросу в том виде, в каком он сформулирован. Автоматизация процесса информационного поиска потребовала формализации представления смыслового содержания ИЗ и документов в виде соответственно поискового предписания (ПП) и поисковых образов документов (ПОД). Для записи ПП и ПОД применяются специальные языки, называемые информационно-поисковыми.
В процессе проведения информационного поиска в ДИПС определяется степень соответствия содержания документов и запроса пользователя путем сопоставления ПОД с ПП. На основе такого сопоставления принимается решение о выдаче документа (признается релевантным) или его невыдаче (нерелевантным).
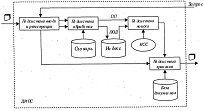
Общая функциональная структура ДИПС
В состав типичной ДИПС входят, как правило, четыре основные подсистемы:
подсистема ввода и регистрации, подсистема обработки, подсистема хранения. подсистема поиска.
Подсистема ввода и регистрации решает следующие основные задачи:
· создание электронных копий бумажных документов (сканирование, распознавание);
· обеспечение подключения к каналам доставки электронных документов;
· распознавание, а при необходимости и преобразование формата электронных документов;
· присвоение электронным документам уникальных идентификаторов (регистрация), а также ведение таблицы синхронизации имен.
Все поступающие документы без внесения в них каких-либо изменений направляются в подсистему хранения для сохранения в базе документов. Для хранения документов применяют средства сжатия и быстрого поиска информации. В этом случае подсистема хранения представляет собой совокупность стандартных или специализированных средств архивации, СУБД и т. п. Далее документы поступают на вход подсистемы обработки, задачей которой является формирование для каждого документа его ПОД.
ПОД сохраняются в индексе. Логически индекс представляет собой таблицу, строки которой соответствуют документам, а столбцы - информационным признакам, на основе которых строится ПОД. В ячейках таблицы могут храниться либо 1, либо 0-в зависимости от наличия или отсутствия данного признака в данном документе. В качестве набора признаков может использоваться набор слов. В этом случае в индексе в строке, соответствующей тексту, единицы будут в столбцах, соответствующих словам, встречающимся в тексте.
Очевидно, что такая таблица будет сильно разреженной, и хранить все значения не имеет смысла. Поэтому на практике используют свертку таблицы по строкам или столбцам. Вместо строки или столбца из единиц и нулей хранятся номера столбцов, содержащих 1, или номера строк, в которых рассматриваемый столбец имеет значение 1. Такую форму хранения называют прямой или инверсной соответственно.
При поступлении на вход системы запроса пользователя, запрос преобразуется в ПП и передается в подсистему поиска, задачей которой является отыскание в индексе ПОД, удовлетворяющих ПП с точки зрения критерия смыслового соответствия. Идентификаторы релевантных документов подаются с выхода подсистемы поиска на вход подсистемы хранения, которая осуществляет выдачу пользователю самих релевантных документов.
Информационно-поисковые языки
Информационно-поисковым языком (ИПЯ) называется специализированный искусственный язык, предназначенный для описания основного смыслового содержания поступающих в систему сообщений с целью обеспечения возможности последующего их поиска ЕЯ для этого плохо подходит из-за наличия синонимии и пр. смысловых проблем. ИПЯ создается на базе ЕЯ, отличается компактностью, наличием четких грамматических правил и отсутствием семантической неоднозначности.
ИПЯ принято разбивать на два основных типа:
· классификационные языки; (1)
· дескрипторные языки. (2)
Принципиальная разница между данными типами языков заключена в процедуре построения предложений языка. В (1) в лексический состав наряду со словами, выражающими простые понятия, заранее включены также словосочетания и фразы, выражающие сложные понятия. Таким образом, с помощью таких языков производится классификация сообщений, т. е. отнесение их к классам, обозначенным лексическими единицами (ЛЕ) ИПЯ.
Частным случаем (1) является рубрикатор, ЛЕ которого являются названия тематических рубрик. В целом под рубрикатором Побл. понимается ориентированный граф, состоящий из независимых деревьев. Листья деревьев будем называть рубриками - объектами, инкапсулирующими знания о конкретных фрагментах ПОбл. Все нелистовые вершины являются классификационными родово-видовыми обобщениями и используются лишь при ведении поиска. Обычно формируется группой экспертов.
Другой тип языков составляют (2), в которых ЛЕ заранее не связаны никакими текстуальными отношениям. Сложные синтаксические конструкции - предложения или фразы - создаются в этих языках путем объединения ЛЕ во время процедуры представления смыслового содержания документов.
Различают (2) с грамматикой и без грамматики. Первые ИМЕЮТ ряд жестких правил формирования синтаксических конструкций.
В (2) без грамматики такие правила отсутствуют, и порядок следования ЛЕ в ПОД или ПП не играет роли. Кроме того, различают дескрипторные ИПЯ с контролируемой и со свободной лексикой.
Лексический состав первых строго ограничен и зафиксирован в словаре ИПЯ, на лексический состав вторых не налагается никаких ограничений.
1. Обработка входящей текстовой информации
Поступающие документы в ДИПС должны проводиться с ЕЯ на ИПЯ. В случае применения ИПЯ дескрипторного типа - индексирование, при использовании рубрикатора - рубрицирование.
На сегодняшний день среди дескрипторных ИПЯ наибольшее получили языки без грамматики и без контроля по словарю. При их использовании говорят о полнотекстовом индексировании.
В операции перевода можно выделить два этапа:
1. Анализ смыслового содержания текста с целью выделения из него сведений об известных системе объектах, их свойствах, а также отношениях между ними.
2. Выражение этих сведений на ИПЯ, т. е. принятие решения о приписывании данному сообщению выражений на ИПЯ.
Лингвистический анализ текста может состоять из двух этапов:
1. Морфологического анализа.
2. Синтаксического анализа.
Цель морфологического анализа состоит в получении основ (словоформа без окончания) со значениями грамматических категорий (род, число, падеж).
Задачей синтаксического анализа является осуществление грамматического разбора предложений, на основе информации, заложенной в словаре. На этом этапе выделяется подлежащее, сказуемое, дополнение и т. п., между которыми указываются связи по управлению в виде дерева зависимостей.
Автоматическое индексирование
Автоматическое индексирование документов может основываться на простых, однословных или многословных составных терминах (фразах). Простые, однословные термины далеко не идеальны для индексирования, поскольку смысл слов вне контекста нередко бывает неоднозначным. Термины-фразы более осмысленны, обладают большей дискриминирующей мощью.
Автоматическое рубрицирование
В современных исследованиях по данной проблеме выделяют два основных подхода: рубрицирование, основанное на знаниях, и рубрицирование, основанное на обучении по примерам.
В первом случае используются заранее сформированные БЗн, в которых описываются языковые выражения, соответствующие рубрике, правила выбора между рубриками. Наиболее распространены две модели представления знаний: модель семантической сети (МСС) и продукционная модель (ПМ). В МСС знания о предметной области описываются независимо от рубрикатора в специального вида тезаурусе. Основу методов, использующих ПМ представления знаний, составляет выделение из текста концепций (или понятий), заранее описанных экспертом. Преимуществами данного подхода являются высокое качество рубрицирования и высокое быстродействие на тех текстовых потоках, для которых они проектировались. Основными недостатками обоих систем являются:
· высокая трудоемкость и значительные затраты, необходимые для разработки системы;
· жесткая привязка БЗн и алгоритмов к ПОбл, конкретному рубрикатору, а также размеру и формату рубрицируемых текстов.
Системы основанные на обучении по примерам, рассматривают в качестве понятий, которым нужно обучиться, рубрики. Машинное обучение производится на основе примеров текстов, которые были заранее отрубрицированы экспертом вручную.
2. Поиск текстовой информации
Модель поиска текстовой информации характеризуется четырьмя параметрами:
• представлением документов и запросов;
• критерием смыслового соответствия; методами ранжирования результатов запроса;
• механизмами обратной связи, обеспечивающими оценку релевантности пользователем.
Булева модель, Модель нечетких множеств, Пространственно-векторная модель, Вероятностная модель
