

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Лабораторная работа №6 (6)
Тема: Ввод-вывод, работа с файлами и сериализация
Цели работы:
1. Изучить применение классов пакета java. io для организации ввода-вывода данных в приложениях на языке Java.
2. Освоить работу с текстовыми и бинарными файлами.
3. Изучить и освоить возможности классов пакета java. nio.
4. Изучить и освоить механизм сериализации-десериализации объектов классов.
Порядок выполнения работы:
Ориентируясь на собственный вариант задания на курсовую работу:
1. Разработать структуру текстового файла конфигурации приложения.
2. Разработать и реализовать совокупность классов для чтения файла конфигурации и использования прочитанных данных для настройки приложения при его запуске.
3. Разработать и реализовать совокупность классов для сохранения данных о настройке приложения в файл конфигурации при закрытии приложения.
4. Разработать структуру бинарного файла состояния приложения для сохранения совокупности объектов.
5. Разработать и реализовать совокупность классов для сохранения состояния совокупности объектов приложения в указанный пользователем бинарный файл с использованием пакета java. nio.
6. Разработать и реализовать совокупность классов для чтения выбранного пользователем бинарного файла состояния с использованием пакета java. nio.
7. Реализовать стандартный механизм сериализации/десериализации совокупности объектов приложения, изучить различия между собственным бинарным файлом и файлом, созданным с использованием стандартного механизма.
Требования к содержанию отчета:
Отчет готовится в электронном виде и должен содержать:
- цель работы;
- описание разработанной иерархии классов и интерфейсов заданной предметной области;
- листинги классов и интерфейсов;
- документацию, подготовленную с использованием утилиты javadoc;
- выводы и заключение.
Контрольные вопросы (примерный перечень):
1. Что такое потоки ввода-вывода и для чего они нужны?
2. Какие классы Java являются базовыми для работы с потоками?
3. В чем разница между байтовыми и символьными потоками?
4. Как получить свойства файла? Какие свойства файла можно узнать?
5. Какие стандартные потоки ввода-вывода существуют в Java, каково их назначение? На базе каких классов создаются стандартные потоки?
6. Чем являются потоки System. in, System. out, System. err?
7. Как создать файловый поток для чтения и записи данных?
8. В чем заключается особенность создания потока, связанного с локальным файлом?
9. Как создать поток для форматированного обмена данными, связанного с локальным файлом?
10. Как добавить буферизацию для потока форматированного обмена данными, связанного с локальным файлом?
11. За счет чего буферизация ускоряет работу приложений с потоками ввода/вывода?
12. Что такое каналы обмена информацией?
13. Когда применяется принудительный сброс буферов?
14. Для выполнения каких операций применяется класс File?
15. Какие классы используются для управления потоками ввлода/вывода?
16. Для чего предназначен класс RandomAccessFile? Чем он отличается от потоков ввода и вывода?
17. Какие средства позиционирования могут использоваться при прямом доступе к содержимому файла
18. Какие средства пакета java. io могут использоваться для передачи данных между потоками в многопоточном приложении?
19. Для чего используются потоки DataOutputStream и DataInputStream?
20. Как организовать передачу объектов через потоки ввода-вывода?
21. Что такое сериализация объектов? Что такое десериализация объектов?
22. Как объявить класс сериализуемым?
23. Какие поля класса не сериализуются?
24. Какие усовершенствования реализованы в пакете java. nio?
25. Какие виды буферов используются в пакете java. nio?
26. Что такое порядок следования байт в данных примитивного типа? Как следует настраивать буфер для правильного выполнения операций ввода/вывода на разных платформах?
27. Какие индексы буфера файла могут использоваться приложением и для чего?
28. Что такое отображение файла в память?
29. Что такое частичная блокировка файла?
Краткие справочные сведения
Организация ввода-вывода в Java
Для того чтобы отвлечься от особенностей конкретных устройств ввода/вывода, в Java употребляется понятие потока (stream). Считается, что в программу идет входной поток (input stream) символов Unicode или просто байтов, воспринимаемый в программе методами read(). Из программы методами write(), print(), println() выводится выходной поток (output stream) символов или байтов. При этом неважно, куда направлен поток: на консоль, на принтер, в файл или в сеть.
Конечно, полное игнорирование особенностей устройств ввода/вывода сильно замедляет передачу информации. Поэтому в Java все-таки выделяется файловый ввод/вывод, вывод на печать, сетевой поток.
В классе system определены три потока статическими полями in, out и err. Они называются соответственно стандартным вводом (stdin), стандартным выводом (stdout) и стандартным выводом сообщений (stderr). Эти стандартные потоки могут быть соединены с разными конкретными устройствами ввода и вывода.
Потоки out и err — это экземпляры класса PrintStream, организующего выходной поток байтов. Эти экземпляры выводят информацию на консоль методами print(), println() и write(), которых в классе PrintStream имеется около двадцати для разных типов аргументов.
Поток err предназначен для вывода системных сообщений программы: трассировки, сообщений об ошибках или, просто, о выполнении каких-то этапов программы. Такие сведения обычно заносятся в специальные журналы, log-файлы, а не выводятся на консоль. В Java есть средства переназначения потока, например, с консоли в файл.
Поток in — это экземпляр класса InputStream. Он назначен на клавиатурный ввод с консоли методами read(). Класс InputStream абстрактный, поэтому реально используется какой-то из его подклассов.
Понятие потока оказалось настолько удобным и облегчающим программирование ввода/вывода, что в Java предусмотрена возможность создания потоков, направляющих символы или байты не на внешнее устройство, а в массив или из массива, т. е. связывающих программу с областью оперативной памяти. Более того, можно создать поток, связанный со строкой типа string, находящейся, опять-таки, в оперативной памяти. Кроме того, можно создать канал (pipe) обмена информацией между подпроцессами.
Еще один вид потока — поток байтов, составляющих объект Java. Его можно направить в файл или передать по сети, а потом восстановить в оперативной памяти. Операция записи состояния объекта называется сериализацией (serialization), обратная ей, т. е. восстановление состояния объекта из потока - десериализацией.
Методы организации потоков собраны в классы пакета java. io.
Кроме классов, организующих поток, в пакет java. io входят классы с методами преобразования потока, например, можно преобразовать поток байтов, образующих целые числа, в поток этих чисел.
Еще одна возможность, предоставляемая классами пакета java. io, — слить несколько потоков в один поток.
Классы потоков ввода-вывода
Итак, в Java есть целых четыре иерархии классов для создания, преобразования и слияния потоков. Во главе иерархии четыре класса, непосредственно расширяющих класс Object:
Reader — абстрактный класс, в котором собраны самые общие методы символьного ввода;
Writer — абстрактный класс, в котором собраны самые общие методы символьного вывода;
InputStream — абстрактный класс с общими методами байтового ввода;
OutputStream — абстрактный класс с общими методами байтового вывода.
Классы входных потоков Reader и InputStream определяют по три метода ввода:
read() — возвращает один символ или байт, взятый из входного потока, в виде целого значения типа int; если поток уже закончился, возвращает -1;
read(char[] buf) — заполняет заранее определенный массив buf символами из входного потока; в классе Inputstream массив типа byte[]; метод возвращает фактическое число взятых из потока элементов или -1, если поток уже закончился;
read (char[] buf, int offset, int len) — заполняет часть символьного или байтового массива buf, начиная с индекса offset, число взятых из потока элементов равно len; метод возвращает фактическое число взятых из потока элементов или -1.
Эти методы выбрасывают IOException, если произошла ошибка ввода/вывода.
Четвертый метод skip (long n) "проматывает" поток с текущей позиции на n символов или байтов вперед. Эти элементы потока не вводятся методами read(). Метод возвращает реальное число пропущенных элементов, которое может отличаться от n, например поток может закончиться.
Текущий элемент потока можно пометить методом mark(int n), а затем вернуться к помеченному элементу методом reset, но не более чем через n элементов. Не все подклассы реализуют эти методы, поэтому перед расстановкой пометок следует обратиться к методу marksupported(), который возвращает true, если реализованы методы расстановки и возврата к пометкам.
Классы выходных потоков Writer и OutputStream определяют по три почти одинаковых метода вывода:
· write (char[] buf) — выводит массив в выходной поток, в классе Outputstream массив имеет тип byte[];
· write (char[] buf, int offset, int len) — выводит len элементов массива buf, начиная с элемента с индексом offset;
· write (int elem) в классе Writer - выводит 16, а в классе Outputstream 8 младших битов аргумента elem в выходной поток,
В классе Writer есть еще два метода:
· write (string s) — выводит строку s в выходной поток;
· write (String s, int offset, int len) — выводит len символов строки s, начиная с символа с номером offset.
Многие подклассы классов Writer и OutputStream осуществляют буферизованный вывод. При этом элементы сначала накапливаются в буфере, в оперативной памяти, и выводятся в выходной поток только после того, как буфер заполнится. Это удобно для выравнивания скоростей вывода из программы и вывода потока, но часто надо вывести информацию в поток еще до заполнения буфера. Для этого предусмотрен метод flush().
Наконец, по окончании работы с потоком его необходимо закрыть методом close().
Иерархия классов потоков ввода-вывода
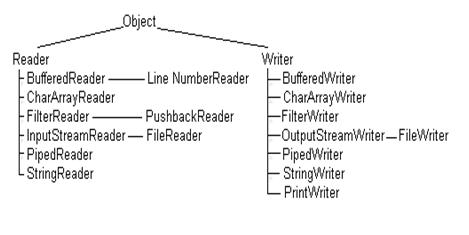
Рис. 1. Иерархия символьныx потоков
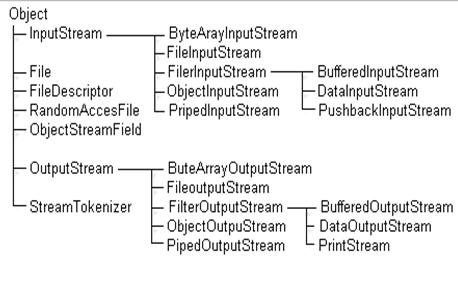
Рис. 2. Классы байтовых потоков
Все классы пакета java. io можно разделить на две группы: классы, создающие поток (data sink), и классы, управляющие потоком (data processing).
Классы, создающие потоки, в свою очередь, можно разделить на пять групп:
1. классы, создающие потоки, связанные с файлами:
FileReader | FileInputStream |
FileWriter | FileOutputStream |
RandomAccessFile |
2. классы, создающие потоки, связанные с массивами:
CharArrayReader | ByteArrayInputStream |
CharArrayWriter | ByteArrayOutputStream |
3. классы, создающие каналы обмена информацией между подпроцессами:
PipedReader | PipedInputStream |
PipedWriter | PipedOutputStream |
4. классы, создающие символьные потоки, связанные со строкой:
StringReader |
StringWriter |
5. классы, создающие байтовые потоки из объектов Java:
ObjectInputStream |
ObjectOutputStream |
Слева перечислены классы символьных потоков, справа — классы байтовых потоков.
Классы, управляющие потоком, получают в своих конструкторах уже имеющийся поток и создают новый, преобразованный поток.
Четыре класса созданы специально для преобразования потоков:
FilterReader FilterInputStream
FilterWriter FilterOutputStream
Сами по себе эти классы бесполезны — они выполняют тождественное преобразование. Их следует расширять, переопределяя методы ввода/вывода.
Четыре класса выполняют буферизованный ввод/вывод:
BufferedReader BufferedInputStream
BufferedWriter BufferedOutputStream
Два класса преобразуют поток байтов, образующих восемь простых типов Java, в эти самые типы:
DataInputStream DataOutputStream
Два класса содержат методы, позволяющие вернуть несколько символов или байтов во входной поток:
PushbackReader PushbackInputStream
Два класса связаны с выводом на строчные устройства — экран дисплея, принтер:
PrintWriter PrintStream
Два класса связывают байтовый и символьный потоки:
InputStreamReader — преобразует входной байтовый поток в символьный поток;
OutputStreamWriter — преобразует выходной символьный поток в байтовый поток.
Класс StreamTokenizer позволяет разобрать входной символьный поток на отдельные элементы (tokens) подобно тому, как класс StringTokenizer разбираeт строку.
Из управляющих классов выделяется класс SequenceInputStream, сливающий несколько потоков, заданных в конструкторе, в один поток, и класс LineNumberReader, "умеющий" читать выходной символьный поток построчно. Строки в потоке разделяются символами '\n' и/или '\r'.
Консольный ввод/вывод
Для вывода на консоль используется метод println() класса PrintStream. Вместо System. out. println(), то вы можете определить новую ссылку на System. out, например:
PrintStream pr = System. out; и писать просто pr. println().
Консоль является байтовым устройством, и символы Unicode перед выводом на консоль должны быть преобразованы в байты.
Трудности с отображением кириллицы возникают, если вывод на консоль производится в кодировке, отличной от локали. Именно так происходит в русифицированных версиях MS Windows. Обычно в них устанавливается локаль с кодовой страницей СР1251, а вывод на консоль происходит в кодировке СР866.
В этом случае надо заменить PrintStream, который не может работать с символьным потоком, на PrintWriter и вставить "переходное кольцо" между потоком символов Unicode и потоком байтов System. out, выводимых на консоль, в виде объекта класса OutputStreamWriter. В конструкторе этого объекта следует указать нужную кодировку, в данном случае, СР866. Все это можно сделать одним оператором:
PrintWriter pw = new PrintWriter(new OutputStreamWriter(System.out, "Cp866"), true);
Класс PrintStream буферизует выходной поток. Второй аргумент true его конструктора вызывает принудительный сброс содержимого буфера в выходной поток после каждого выполнения метода println(). Но после print() буфер не сбрасывается! Для сброса буфера после каждого print() надо писать flush(), как это сделано в примере 1.
После этого можно выводить любой текст методами класса PrintWriter, которые просто дублируют методы класса PrintStream, и писать, например,
pw. println("Это русский текст");
как показано в примере 1.
Однако, обратите внимание, что если вы пользуетесь окном Output в Netbeans 7 как консолью (так происходит в Netbeans 7 по умолчанию), то кодировку менять не нужно, там сразу используется локаль.
Ввод с консоли производится методами read() класса InputStream с помощью статического поля in класса System. С консоли идет поток байтов, полученных из scan-кодов клавиатуры. Эти байты должны быть преобразованы в символы Unicode такими же кодовыми таблицами, как и при выводе на консоль. Преобразование идет по той же схеме — для правильного ввода кириллицы удобнее всего определить экземпляр класса BufferedReader, используя в качестве "переходного кольца" объект класса InputStreamReader:
BufferedReader br = new BufferedReader(new InputStreamReader(System. in, "Cp866"));
Класс BufferedReader переопределяет три метода read() своего суперкласса Reader. Кроме того, он содержит метод readLine().
Метод readLine() возвращает строку типа string, содержащую символы входного потока, начиная с текущего, и заканчивая символом '\n' и/или '\r'. Эти символы-разделители не входят в возвращаемую строку. Если во входном потоке нет символов, то возвращается null.
Пример 1. Консольный ввод/вывод
import java.io.*;
class PrWr {
public static void main(String[] args) {
try {
boolean use866 = args. length > 0 ?
Boolean. valueOf(args[0].toLowerCase()) : false;
BufferedReader br = new BufferedReader(use866 ?
new InputStreamReader(System. in, "Cp866") :
new InputStreamReader(System. in));
PrintWriter pw = new PrintWriter(use866 ?
new OutputStreamWriter(System. out, "Cp866") :
new OutputStreamWriter(System. out), true);
String s = "Это строка с русским текстом";
System. out. println("System. out puts: " + s);
pw. println("PrintWriter puts: " + s) ;
int c = 0;
pw. println("Посимвольный ввод:");
while((c = br. read()) != -1) {
if ((char)c == 'q') break;
pw. println((char)c);
}
pw. println("Построчный ввод:");
do {
s = br. readLine();
pw. println(s);
} while(!s. equals("q"));
}
catch(Exception e) { System. out. println(e); }
}
}
Файловый ввод/вывод
Поскольку файлы в большинстве современных операционных систем понимаются как последовательность байтов, для файлового ввода/вывода создаются байтовые потоки с помощью классов FileInputStream и FileOutputStream. Это особенно удобно для бинарных файлов, хранящих байт-коды, архивы, изображения, звук.
Но очень много файлов содержат тексты, составленные из символов. Несмотря на то, что символы могут храниться в кодировке Unicode, эти тексты чаще всего записаны в байтовых кодировках. Поэтому и для текстовых файлов можно использовать байтовые потоки. В таком случае со стороны программы придется организовать преобразование байтов в символы и обратно.
Чтобы облегчить это преобразование, в пакет java. io введены классы FileReader и FileWriter. Они организуют преобразование потока: со стороны программы потоки символьные, со стороны файла — байтовые. Это происходит потому, что данные классы расширяют классы InputStreamReader и OutputStreamWriter, соответственно, значит, содержат "переходное кольцо" внутри себя.
Несмотря на различие потоков, использование классов файлового ввода/вывода очень похоже.
В конструкторах всех четырех файловых потоков задается имя файла в виде строки типа String или ссылка на объект класса File. Конструкторы не только создают объект, но и отыскивают файл и открывают его. Например:
FileInputStream fis = new FileInputStream("PrWr.Java");
FileReader fr = new FileReader("D:\\jdkl.5\\src\\PrWr.Java");
При неудаче выбрасывается исключение класса FileNotFoundException, но конструктор класса FileWriter выбрасывает более общее исключение IOException.
После открытия выходного потока типа FileWriter или FileQutputStream содержимое файла, если он был не пуст, стирается. Для того чтобы можно было делать запись в конец файла, и в том и в другом классе предусмотрен конструктор с двумя аргументами. Если второй аргумент равен true, то происходит дозапись в конец файла, если false, то файл заполняется новой информацией. Например:
FileWriter fw = new FileWriter("ch8.txt", true);
FileOutputstream fos = new FileOutputStream("D:\\samples\\newfile. txt");
Теперь можно читать файл:
fis. read(); fr. read();
или записывать:
fos.write((char)с); fw.write((char)с);
Преобразование потоков в классах FileReader и FileWriter выполняется по кодовым таблицам установленной на компьютере локали. Для правильного ввода кириллицы надо применять FileReader, a нe FileInputStream. Если файл содержит текст в кодировке, отличной от локальной кодировки, то придется вставлять "переходное кольцо" вручную, как это делалось для консоли, например:
InputStreamReader isr = new InputStreamReader(fis, "KOI8_R"));
Байтовый поток fis определен выше.
Получение свойств файла
Получить сведения о файле можно от предварительно созданного экземпляра класса File. В конструкторе этого класса File(String filename) указывается путь к файлу или каталогу, записанный по правилам операционной системы. Конструктор не проверяет, существует ли файл с таким именем, поэтому после создания объекта следует это проверить логическим методом exists().
Класс File содержит около 40 методов, позволяющих узнать различные свойства файла или каталога.
Прежде всего, логическими методами isFile(), isDirectory() можно выяснить, является ли путь, указанный в конструкторе, путем к файлу или каталогу.
Для каталога можно получить его содержимое — список имен файлов и подкаталогов — методом list(), возвращающим массив строк String[]. Можно получить такой же список в виде массива объектов класса File[] методом listFiles(). Можно выбрать из списка только некоторые файлы, реализовав интерфейс FileNameFiiter и обратившись к методу list(FileNameFilter filter).
Если каталог с указанным в конструкторе путем не существует, его можно создать логическим методом mkdir(). Этот метод возвращает true, если каталог удалось создать. Логический метод mkdirs() создает еще и все несуществующие каталоги, указанные в пути.
Пустой каталог удаляется методом delete().
Для файла можно получить его длину в байтах методом length(), время последней модификации в секундах с 1 января 1970 г. методом lastModified(). Если файл не существует, эти методы возвращают нуль.
Логические методы canRead(), canWrite() показывают права доступа к файлу.
Файл можно переименовать логическим методом renameTo(File newName) или удалить логическим методом delete(). Эти методы возвращают true, если операция прошла удачно.
Если файл с указанным в конструкторе путем не существует, его можно создать логическим методом createNewFile(), возвращающим true, если файл не существовал, и его удалось создать, и false, если файл уже существовал.
Статическими методами :
createTempFile(String prefix, String suffix, File tmpDir) ;
createTempFile(String prefix, String suffix);
можно создать временный файл с именем prefix и расширением suffix в каталоге tmpDir или каталоге, указанном в системном свойстве java. io. tmpdir. Имя prefix должно содержать не менее трех символов. Если suffix = null, то файл получит суффикс. tmp.
Перечисленные методы возвращают ссылку типа File на созданный файл. Если обратиться к методу deieteOnExit (), то по завершении работы JVM временный файл будет уничтожен.
Несколько методов getxxx() возвращают имя файла, имя каталога и другие сведения о пути к файлу. Эти методы полезны в тех случаях, когда ссылка на объект класса File возвращается другими методами и нужны сведения о файле. Наконец, метод toURL() возвращает путь к файлу в форме URL.
В примере 2 показан пример использования класса File.
Пример 2. Определение свойств файла и каталога
import java. io.*;
class FileTest {
public static void main(String[] args) throws IOException {
File f = new File("FileTest. java");
System. out. println();
System. out. println("File \"" + f. getName() +
"\" " +(f. exists()? "is " : "isn't ") + "existed");
System. out. println("You can" + (f. canRead()? " " : "'t ") + "read this file");
System. out. println("You can " + (f. canWrite()? " " : "'t ") + "write to this file");
System. out. println("File size is " + f. length() + " B");
System. out. println();
File d = new File("C:");
System. out. println("Content of " + d. getPath());
if (d. exists() && d. isDirectory()) {
String[] s = d. list();
for (int i = 0; i < s. length; i++)
System. out. println(s[i]);
}
}
}
Буферизованный ввод/вывод
Операции ввода/вывода по сравнению с операциями в оперативной памяти выполняются очень медленно. Для компенсации в оперативной памяти выделяется некоторая промежуточная область — буфер, в которой постепенно накапливается информация. Когда буфер заполнен, его содержимое быстро переносится процессором, буфер очищается и снова заполняется информацией.
Классы файлового ввода/вывода не занимаются буферизацией. Для этой цели есть четыре специальных класса BufferedXХХ, перечисленных выше. Они присоединяются к потокам ввода/вывода как "переходное кольцо", например:
InputStreamReader isr = new InputStreamReader(fis, "KOI8_R"));
FileWriter fw = new FileWriter("ch8.txt", true);
BufferedReader br = new BufferedReader(isr);
BufferedWriter bw = new BufferedWriter(fw);
Поток простых типов Java
Класс DataOutputstream позволяет записать данные простых типов Java в выходной поток байтов методами writeBoolean(boolean b), writeByte(int b), writeShort(int h), writeChar(int c), writeInt(int n), writeLong(long 1), writeFloat(float f), writeDouble(double d).
Кроме того, метод writeBytes(string s) записывает каждый символ строки s в один байт, отбрасывая старший байт кодировки каждого символа Unicode, а метод writeChars(string s) записывает каждый символ строки s в два байта, первый байт — старший байт кодировки Unicode, так же, как это делает метод writeChar ().
Класс DataInputStream преобразует входной поток байтов типа InputStream, составляющих данные простых типов Java, в данные этого типа. Такой поток, как правило, создается методами класса DataOutputStream. Данные из этого потока можно прочитать методами readBoolean(), readByte(), readShort(), readChar(), readlnt(), readLong(), readFloat(), readDouble(), возвращающими данные соответствующего типа.
Кроме того, методы readUnsignedByte() и readUnsignedShort () возвращают целое типа int, в котором старшие три или два байта нулевые, а младшие один или два байта заполнены байтами из входного потока.
Программа в примера 3 записывает в файл fib. txt числа Фибоначчи, а затем читает этот файл и выводит его содержимое на консоль. Для контроля записываемые в файл числа тоже выводятся на консоль.
Пример 3. Ввод/вывод данных
import java.io.*;
class DataPrWr {
public static void main(String[] args) throws IOException {
DataOutputStream dos = new DataOutputStream(
new FileOutputStream("fib. txt"));
int a = 1, b = 1, с = 1;
for (int k = 0; k < 40; k++) {
System. out. print(b + " ");
dos. writeInt(b);
a = b; b = с; с = a + b;
}
dos. close();
System. out. println("\n");
DataInputStream dis = new DataInputStream(
new FileInputStream("fib. txt"));
while(true) {
try {
a = dis. readInt();
System. out. print(a + " ");
}
catch(IOException e) {
dis. close();
System. out. println("\nEnd of file");
System. exit (0);
}
}
}
}
Обратите внимание на то, что попытка чтения за концом файла выбрасывает исключение класса IOException, его обработка заключается в закрытии файла и окончании программы.
Прямой доступ к файлу
Если необходимо интенсивно работать с файлом, записывая в него данные разных типов Java, изменяя их, отыскивая и читая нужную информацию, то лучше всего воспользоваться методами класса RandomAccessFile.
В конструкторах этого класса
RandomAccessFile(File file, String mode);
RandomAccessFile(String fileName, String mode);
вторым аргументом mode задается режим открытия файла. Это может быть строка "r" — открытие файла только для чтения, или "rw" — открытие файла для чтения и записи.
Этот класс собрал все полезные методы работы с файлом. Он содержит все методы классов DataInputStream и DataOutputStream, кроме того, позволяет прочитать сразу целую строку методом readLine() и отыскать нужные данные в файле.
Байты файла нумеруются, начиная с 0, подобно элементам массива. Файл снабжен неявным указателем (file pointer) текущей позиции. Чтение и запись производится, начиная с текущей позиции файла. При открытии файла конструктором указатель стоит на начале файла, в позиции 0. Текущую позицию можно узнать методом getFilePointer(). Каждое чтение или запись перемещает указатель на длину прочитанного или записанного данного. Всегда можно переместить указатель в новую позицию, роз методом seek(long pos). Метод seek(0) перемещает указатель на начало файла.
В классе нет методов преобразования символов в байты и обратно по кодовым таблицам, поэтому он не приспособлен для работы с кириллицей.
Каналы обмена информацией
В пакете java. io есть четыре класса Pipedxxx, обеспечивающие возможность достаточно просто передавать данные между разными потоками в многопотоном приложении.
В одном подпроцессе-потоке — источнике информации — создается объект класса PipedWriter или PipedOutputStream, в который записывается информация методами write() этих классов.
В другом. подпроцессе-потоке —приемнике информации — формируется объект класса PipedReader или PipedInputStream. Он связывается с объектом-источником с помощью конструктора или специальным методом connect(), и читает информацию методами read().
Источник и приемник можно создать и связать в обратном порядке.
Так создается однонаправленный канал (pipe) информации. На самом деле это некоторая область оперативной памяти, к которой организован совместный доступ двух или более подпроцессов. Доступ синхронизируется, записывающие процессы не могут помешать чтению.
Если надо организовать двусторонний обмен информацией, то создаются два канала.
В примере 4 метод run () класса Source генерирует информацию, для простоты просто целые числа k, и передает ее в канал методом pw. write (k). Метод run() класса Target читает информацию из канала методом pr. read(). Концы канала связываются с помощью конструктора класса Target.
Пример 4. Канал обмена информацией
import java. io.*;
class Target extends Thread {
private PipedReader pr;
Target(PipedWriter pw) {
try {
pr = new PipedReader(pw);
}
catch(IOException e) {
System. err. println("From Target(): " + e);
}
}
PipedReader getStream(){ return pr; }
public void run() {
while(true) {
try {
System. out. println("Reading: " + pr. read());
}
catch(IOException e) {
System. out. println("The job's finished.");
System. exit(0);
}
}
}
}
class Source extends Thread {
private PipedWriter pw;
Source() {
pw = new PipedWriter();
}
PipedWriter getStream(){ return pw;}
public void run() {
for (int k = 0; k < 10; k++) {
try {
pw. write(k);
System. out. println("Writing: " + k);
}
catch(Exception e) {
System. err. println("From *****n(): " + e) ;
}
}
}
}
public class Main {
public static void main(String[] args) throws IOException {
Source s = new Source();
Target t = new Target(s. getStream());
s.start();
t.start();
}
}
Сериализация объектов
Методы классов ObjectInputStream и ObjectOutputStream позволяют прочитать из входного байтового потока или записать в выходной байтовый поток данные сложных типов — объекты, массивы, строки — подобно тому, как методы классов DataInputStream и DataOutputStream читают и записывают данные простых типов.
Сходство усиливается тем, что классы Objectxxx содержат методы как для чтений, так и записи простых типов. Впрочем, эти методы предназначены не для использования в программах, а для записи/чтения полей объектов и элементов массивов.
Процесс записи объекта в выходной поток получил название сериализации (serialization), а чтения объекта из входного потока и восстановления его в оперативной памяти — десериализации (deserialization).
Сериализация объекта нарушает его безопасность, поскольку процесс может сериализовать объект в массив, переписать некоторые элементы массива, представляющие private-поля объекта, обеспечив себе, например, доступ к секретному файлу, а затем десериализовать объект с измененными полями и совершить с ним недопустимые действия.
Поэтому сериализации можно подвергнуть не каждый объект, а только тот, который реализует интерфейс Serializable. Этот интерфейс не содержит ни полей, ни методов. Реализовать в нем нечего. По сути дела запись
class A implements Serializabie{...}
это только пометка, разрешающая сериализацию объектов класса А.
Как всегда в Java, процесс сериализации максимально автоматизирован. Достаточно создать объект класса ObjectOutputStream, связав его с выходным потоком, и выводить в этот поток объекты методом writeObject():
MyClass me = new MyClass("abc", -12, 5.67e-5);
int[] arr = {10, 20, 30};
ObjectOutputStream oos = new ObjectOutputStream(
new FileOutputStream("myobjects. ser"));
oos. writeObject(me);
oos. writeObject(arr);
oos. writeObject("Some string");
oos. writeObject (new Date());
oos. flush();
В выходной поток выводятся все нестатические поля объекта, независимо от прав доступа к ним, а также сведения о классе этого объекта, необходимые для его правильного восстановления при десериализации. Байт-коды методов класса не сериализуются.
Если в объекте присутствуют ссылки на другие объекты, то они тоже сериализуются, а в них могут быть ссылки на другие объекты, которые опять-таки сериализуются, и получается целое множество связанных между собой сериализуемых объектов. Метод writeObject() распознает две ссылки на один объект и выводит его в выходной поток только один раз. К тому же, он распознает ссылки, замкнутые в кольцо, и избегает зацикливания.
Все классы объектов, входящих в такое сериализуемое множество, а также все их внутренние классы, должны реализовать интерфейс Serializable, в противном случае будет выброшено исключение класса NotSerializableException и процесс сериализации прервется. Многие классы J2SDK реализуют этот интерфейс. Учтите также, что все потомки таких классов наследуют реализацию. Например, класс java. ponent реализует интерфейс Serializable, значит, все графические компоненты можно сериализовать. Не реализуют этот интерфейс обычно классы, тесно связанные с выполнением программ, например, java. awt. Toolkit. Состояние экземпляров таких классов нет смысла сохранять или передавать по сети. Не реализуют интерфейс Serializable и классы, содержащие внутренние сведения Java "для служебного пользования".
Десериализация происходит так же просто, как и сериализация:
ObjectlnputStream ois = new ObjectInputStream(
new FilelnputStream("myobjects. ser"));
MyClass mcl = (MyClass)ois. readObject();
int[] a = (int[])ois. readObject();
String s = (String)ois. readObject();
Date d = (Date)ois. readObject();
Нужно только соблюдать порядок чтения элементов потока. В примере 5 мы создаем объект класса GregorianCalendar с текущей датой и временем, сериализуем его в файл date. ser, через три секунды десериализуем и сравниваем с текущим временем.
Пример 5. Сериализация объекта
import java.io.*;
import java. util.*;
class SerDatef {
public static void main(String[] args) throws Exception {
GregorianCalendar d = new GregorianCalendar();
ObjectOutputStream oos = new ObjectOutputStream(
new FileOutputStream("date. ser"));
oos. writeObject(d);
oos. flush();
oos. close();
Thread. sleep(3000);
ObjectInputStream ois = new ObjectInputStream(
new FileInputStream("date. ser"));
GregorianCalendar oldDate = (GregorianCalendar)ois. readObject();
ois. close();
GregorianCalendar newDate = new GregorianCalendar();
System. out. println("Old time = " + oldDate. get(Calendar. HOUR) +
":" + oldDate. get(Calendar. MINUTE) +
":" + oldDate. get(Calendar. SECOND) +
"\nNew time = " + newDate. get(Calendar. HOUR) +
":" + newDate. get(Calendar. MINUTE) +
":" + newDate. get(Calendar. SECOND));
}
}
Если не нужно сериализовать какое-то поле, то достаточно пометить его служебным словом transient, например:
transient MyClass me = new MyClass("abc", -12, 5.67e-5);
Метод writeObject() не записывает в выходной поток поля, помеченные static и transient. Впрочем, это положение можно изменить, переопределив метод writeObject() или задав список сериализуемых полей.
Вообще процесс сериализации можно полностью настроить под свои нужды, переопределив методы ввода/вывода и воспользовавшись вспомогательными классами. Можно даже взять весь процесс на себя, реализовав не интерфейс Serializable, а интерфейс Externalizable, но тогда придется реализовать методы readExternal() и writeExternal(), выполняющие ввод/вывод.
Новый ввод/вывод (java. nio)
При создании библиотеки «нового ввода/вывода» Java, появившейся в JDK-1.4 в пакетах java. nio.*, ставилась единственная цель: скорость. Более того, «старые» пакеты ввода/вывода были переписаны с учетом достижений nio, с намерением использовать преимущества повышенного быстродействия, поэтому улучшения вы получите, даже если не будете писать явный nіо-код. Подъем производительности просматривается как в файловом вводе/выводе, который мы здесь рассматриваем, так и в сетевом вводе/выводе.
Увеличения скорости удалось достичь с помощью структур, близких к средствам самой операционной системы: каналов (channels) и буферов (buffers). Канал можно сравнить с угольной шахтой, вырытой на угольном пласте (данные), а буфер — с вагонеткой, которую вы посылаете в шахту. Тележка возвращается доверху наполненная углем, который вы из нее выгружаете. Таким образом, прямого взаимодействия с каналом у вас нет, вы работаете с буфером и «посылаете» его в канал. Канал либо извлекает данные из буфера, либо помещает их в него.
Напрямую взаимодействует с каналом только буфер ByteBuffer, то есть буфер, хранящий простые байты. Если вы просмотрите документацию JDK для класса java. teBuffer, то увидите что он достаточно прост: вы создаете его, указывая, сколько места надо выделить под данные. Класс содержит набор методов для получения и помещения данных в виде последовательности байтов или в виде примитивов. Однако возможности записать в него объект или даже простую строку нет. Буфер работает на достаточно низком уровне, поскольку обеспечивается более эффективная совместимость с большинством операционных систем.
Три класса из «старой» библиотеки ввода/вывода были изменены так, чтобы они позволяли получить канал FileChannel: это FileInputStream, FileOutputStream и RandomAccessFile. Заметьте, что эти классы манипулируют байтами, что согласуется с низкоуровневой направленностью nio. Классы для символьных данных Reader и Writer не образуют каналов, однако вспомогательный класс java. nio. channels. Channels имеет набор методов, позволяющих получить объекты Reader и Writer для каналов.
Простой пример использования всех трех типов потоков. Создаваемые каналы поддерживают запись, чтение/запись и только чтение:
//: io/GetChannel. java
// Получение каналов из потоков
import java. nio.*;
import java. nio. channels.*;
import java. io.*;
public class GetChannel {
private static final int BSIZE = 1024;
public static void main(String[] args) throws Exception {
// Write a file:
FileChannel fc =
new FileOutputStream("data. txt").getChannel();
fc. write(ByteBuffer. wrap("Some text ".getBytes()));
fc. close();
// Add to the end of the file:
fc =
new RandomAccessFile("data. txt", "rw").getChannel();
fc. position(fc. size()); // Move to the end
fc. write(ByteBuffer. wrap("Some more".getBytes()));
fc. close();
// Read the file:
fc = new FileInputStream("data. txt").getChannel();
ByteBuffer buff = ByteBuffer. allocate(BSIZE);
fc. read(buff);
buff. flip();
while(buff. hasRemaining())
System. out. print((char)buff. get());
}
}
Для любого из рассмотренных выше классов потоков метод getChannel() выдает канал FileChannel. Канал довольно прост: ему передается байтовый буфер ByteBuffer для чтения и записи, и вы можете заблокировать некоторые участки файла для монопольного доступа (этот процесс будет описан чуть позже).
Для помещения байтов в буфер ByteBuffer используется один из нескольких методов для записи данных (put); данные записываются в виде одного или нескольких байтов или значений примитивов. Впрочем, как было показано в примере, можно «заворачивать» уже существующий байтовый массив в буфер ByteBuffer, используя метод wrap(). Когда вы так делаете, байтовый массив не копируется, а используется как хранилище для полученного буфера ByteBuffer. В таких случаях говорят, что буфер ByteBuffer создается на базе массива.
Файл data. txt заново открывается с помощью класса RandomAccessFile. Заметьте, что канал FileChannel может перемещаться внутри файла; в нашем примере он сдвигается в конец файла так, чтобы дополнительные записи присоединялись за существующим содержимым.
Чтобы доступ к файлу ограничивался только чтением, следует явно получить байтовый буфер ByteBuffer статическим методом allocate(). Предназначение nio — быстрое перемещение большого количества данных, поэтому размер буфера имеет значение: на самом деле установленный в примере размер в 1 килобайт меньше, чем обычно требуется (поэкспериментируйте с работающим приложением, чтобы найти оптимальное решение).
Можно получить еще большее быстродействие, используя вместо метода allocate() метод allocateDirect(). Он производит буфер «прямого доступа», еще теснее привязанный к низкоуровневой работе операционной системы. Однако такой буфер требует больше ресурсов, а реализация его различается в различных операционных системах. Опять же, поэкспериментируйте со своим приложением и выясните, дадут ли буферы прямого доступа лучшую производительность.
После вызова метода read() буфера FileChannel для сохранения байтов в буфере ByteBuffer также необходимо вызвать для буфера метод flip(), позволяющий впоследствии извлечь из буфера его данные (да, все это выглядит немного неудобно, но помните, что расчет делался на высокое быстродействие, поэтому все делается на низком уровне). И если затем нам снова понадобится буфер для чтения, придется вызывать перед каждым методом read() метод clear(). В этом нетрудно убедиться на примере простой программы копирования файлов:
//: io/ChannelCopy. java
// Копирование файла с использованием каналов и буферов
// {Параметры Channel Copy java test txt}
import java. nio.*;
import java. nio. channels.*;
import java. io.*;
public class ChannelCopy {
private static final int BSIZE = 1024;
public static void main(String[] args) throws Exception {
if(args. length!= 2) {
System. out. println("arguments: sourcefile destfile");
System. exit(1);
}
FileChannel
in = new FileInputStream(args[0]).getChannel(),
out = new FileOutputStream(args[1]).getChannel();
ByteBuffer buffer = ByteBuffer. allocate(BSIZE);
while(in. read(buffer) != -1) {
buffer. flip(); // Prepare for writing
out. write(buffer);
buffer. clear(); // Prepare for reading
}
}
}
В программе создаются два канала FileChannel: для чтения и для записи. Выделяется буфер ByteBuffer, а когда метод FileChannel. read() возвращает -1, это значит, что мы достигли конца входных данных (без сомнения, пережиток UNIX и С). После каждого вызова метода read(), помещающего данные в буфер, метод flip() подготавливает буфер так, чтобы информация из него могла быть извлечена методом write(). После вызова write() информация все еще хранится в буфере, поэтому метод clear() перемещает все его внутренние указатели, чтобы буфер снова был способен принимать данные в методе read(). Впрочем, рассмотренная программа не лучшим образом выполняет копирование файлов. Специальные методы, transferTo() и transferFrom(), позволяют напрямую присоединить один канал к другому:
//: io/TransferTo. java
// Использование метода transferToO для соединения каналов
// {Параметры TransferTo java TransferTo txt}
import java. nio. channels.*;
import java. io.*;
public class TransferTo {
public static void main(String[] args) throws Exception {
if(args. length!= 2) {
System. out. println("arguments: sourcefile destfile");
System. exit(1);
}
FileChannel
in = new FileInputStream(args[0]).getChannel(),
out = new FileOutputStream(args[1]).getChannel();
in. transferTo(0, in. size(), out);
// Or:
// out. transferFrom(in, 0, in. size());
}
}
Часто такую операцию выполнять не придется, но знать о ней полезно.
Преобразование данных
В программе GetChannel. java для вывода информации из файла приходилось считывать из буфера по одному байту и преобразовывать его от типа byte к типу char. Такой подход явно примитивен — если посмотреть на класс java. nio. CharBuffer, то можно увидеть, что в нем есть метод toString(), который возвращает строку из символов, находящихся в данном буфере. Байтовый буфер ByteBuffer можно рассматривать как символьный буфер CharBuffer, как это делается в методе asCharBuffer(), почему бы так и не поступить?
//: io/BufferToText. java
// Получение текста из буфера ByteBuffers и обратно
import java. nio.*;
import java. nio. channels.*;
import java. nio. charset.*;
import java. io.*;
public class BufferToText {
private static final int BSIZE = 1024;
public static void main(String[] args) throws Exception {
FileChannel fc =
new FileOutputStream("data2.txt").getChannel();
fc. write(ByteBuffer. wrap("Some text".getBytes()));
fc. close();
fc = new FileInputStream("data2.txt").getChannel();
ByteBuffer buff = ByteBuffer. allocate(BSIZE);
fc. read(buff);
buff. flip();
// Doesn't work:
System. out. println(buff. asCharBuffer());
// Decode using this system's default Charset:
buff. rewind();
String encoding = System. getProperty("file. encoding");
System. out. println("Decoded using " + encoding + ": "
+ Charset. forName(encoding).decode(buff));
// Or, we could encode with something that will print:
fc = new FileOutputStream("data2.txt").getChannel();
fc. write(ByteBuffer. wrap(
"Some text".getBytes("UTF-16BE")));
fc. close();
// Now try reading again:
fc = new FileInputStream("data2.txt").getChannel();
buff. clear();
fc. read(buff);
buff. flip();
System. out. println(buff. asCharBuffer());
// Use a CharBuffer to write through:
fc = new FileOutputStream("data2.txt").getChannel();
buff = ByteBuffer. allocate(24); // More than needed
buff. asCharBuffer().put("Some text");
fc. write(buff);
fc. close();
// Read and display:
fc = new FileInputStream("data2.txt").getChannel();
buff. clear();
fc. read(buff);
buff. flip();
System. out. println(buff. asCharBuffer());
}
}
Буфер содержит обычные байты, следовательно, для превращения их в символы мы должны либо кодировать их по мере помещения в буфер, либо декодировать их при извлечении из буфера. Это можно сделать с помощью класса java. nio. charset. Charset, который предоставляет инструменты для преобразования многих различных типов в наборы символов:
//: io/AvailableCharSets. java
// Перечисление кодировок и их символических имен
import java. nio. charset.*;
import java. util.*;
import static net. mindview. util. Print.*;
public class AvailableCharSets {
public static void main(String[] args) {
SortedMap<String, Charset> charSets =
Charset. availableCharsets();
Iterator<String> it = charSets. keySet().iterator();
while(it. hasNext()) {
String csName = it. next();
printnb(csName);
Iterator aliases =
charSets. get(csName).aliases().iterator();
if(aliases. hasNext())
printnb(": ");
while(aliases. hasNext()) {
printnb(aliases. next());
if(aliases. hasNext())
printnb(", ");
}
print();
}
}
}
Вернемся к программе BufferToText. java. Если вызвать для буфера метод rewind() (чтобы вернуться к его началу), а затем использовать кодировку по умолчанию в методе decode(), то данные буфера CharBuffer будут правильно выведены на консоль. Чтобы узнать кодировку по умолчанию вызовите метод System. getProperty("fiLe. encoding"), который возвращает строку с названием кодировки. Передавая эту строку методу Charset. forName(), можно получить объект Charset, с помощью которого и декодируется строка.
Другой подход — кодировать данные методом encode() так, чтобы при чтении файла выводились данные, пригодные для вывода на печать (пример представлен в программе BufferToText. java). Здесь для записи текста в файл используется кодировка UTF-16BE, и при последующем чтении вам остается лишь преобразовать данные в буфер CharBuffer и вывести его содержимое. Наконец, мы видим, что происходит, когда вы записываете в буфер ByteBuffer через CharBuffer (мы узнаем об этом чуть позже). Заметьте, что для байтового буфера выделяется 24 байта. На каждый символ (char) отводится два байта, соответственно, буфер вместит 12 символов, а у нас в строке Some Text их только девять. Оставшиеся нулевые байты все равно отображаются в строке, образуемой методом toString() класса CharBuffer, что и показывают результаты.
Извлечение примитивов
Несмотря на то что в буфере ByteBuffer хранятся только байты, он поддерживает методы для выборки любых значений примитивных типов из этих байтов. Следующий пример демонстрирует вставку и выборку из буфера разнообразных значений примитивных типов:
//: io/GetData. java
//Получение различных данных из буфера ByteBuffer
import java. nio.*;
import static net. mindview. util. Print.*;
public class GetData {
private static final int BSIZE = 1024;
public static void main(String[] args) {
ByteBuffer bb = ByteBuffer. allocate(BSIZE);
// Allocation automatically zeroes the ByteBuffer:
int i = 0;
while(i++ < bb. limit())
if(bb. get() != 0)
print("nonzero");
print("i = " + i);
bb. rewind();
// Store and read a char array:
bb. asCharBuffer().put("Howdy!");
char c;
while((c = bb. getChar()) != 0)
printnb(c + " ");
print();
bb. rewind();
// Store and read a short:
bb. asShortBuffer().put((short)471142);
print(bb. getShort());
bb. rewind();
// Store and read an int:
bb. asIntBuffer().put();
print(bb. getInt());
bb. rewind();
// Store and read a long:
bb. asLongBuffer().put();
print(bb. getLong());
bb. rewind();
// Store and read a float:
bb. asFloatBuffer().put();
print(bb. getFloat());
bb. rewind();
// Store and read a double:
bb. asDoubleBuffer().put();
print(bb. getDouble());
bb. rewind();
}
}
После выделения байтового буфера мы убеждаемся в том, что его содержимое действительно заполнено нулями. Проверяются все 1024 значения, хранимые в буфере (вплоть до последнего, индекс которого (размер буфера) возвращается методом limit()), и все они оказываются нулями.
Простейший способ вставить примитив в ByteBuffer основан на получении подходящего «представления» этого буфера методами asCharBuffer(), asShortBuffer() и т. п., и последующем занесении в это представление значения методом put(). В примере мы так поступаем для каждого из простейших типов. Единственным исключением из этого ряда является использование буфера ShortBuffer, требующего приведения типов (которое усекает и изменяет результирующее значение). Все остальные представления не нуждаются в преобразовании типов.
Представления буферов
«Представления буферов» дают вам возможность взглянуть на соответствующий байтовый буфер «через призму» некоторого примитивного типа. Байтовый буфер все так же хранит действительные данные и одновременно поддерживает представление, поэтому все изменения, которые вы сделаете в представлении, отразятся на содержимом байтового буфера. Как было показано в предыдущем' примере, это удобно для вставки значений примитивов в байтовый буфер. Представления также позволяют читать значения примитивов из буфера, по одному (раз он «байтовый» буфер) или пакетами (в массивы). Следующий пример манипулирует целыми числами (int) в буфере ByteBuffer с помощью класса IntBuffer:
//: io/IntBufferDemo. java
// Работа с целыми числами в буфере ByteBuffer
// посредством буфера IntBuffer
import java.nio.*;
public class IntBufferDemo {
private static final int BSIZE = 1024;
public static void main(String[] args) {
ByteBuffer bb = ByteBuffer. allocate(BSIZE);
IntBuffer ib = bb. asIntBuffer();
// Store an array of int:
ib. put(new int[]{ 11, 42, 47, 99, 143, 811, 1016 });
// Absolute location read and write:
System. out. println(ib. get(3));
ib. put(3, 1811);
// Setting a new limit before rewinding the buffer.
ib. flip();
while(ib. hasRemaining()) {
int i = ib. get();
System. out. println(i);
}
}
}
Перегруженный метод put() первый раз вызывается для помещения в буфер массива целых чисел int. Последующие вызовы put() и get() обращаются к конкретному числу int из байтового буфера ByteBuffer. Заметьте, что такие обращения к простейшим типам по абсолютной позиции также можно осуществить напрямую через буфер ByteBuffer.
Как только байтовый буфер ByteBuffer будет заполнен целыми числами или другими примитивами через представление, его можно передать для непосредственной записи в канал. Настолько же просто считать данные из канала и использовать представление для преобразования данных к конкретному простейшему типу. Вот пример, который трактует одну и ту же последовательность байтов как числа short, int, float, long и double, создавая для одного байтового буфера ByteBuffer различные представления:
//: io/ViewBuffers. java
import java. nio.*;
import static net. mindview. util. Print.*;
public class ViewBuffers {
public static void main(String[] args) {
ByteBuffer bb = ByteBuffer. wrap(
new byte[]{ 0, 0, 0, 0, 0, 0, 0, 'a' });
bb. rewind();
printnb("Byte Buffer ");
while(bb. hasRemaining())
printnb(bb. position()+ " -> " + bb. get() + ", ");
print();
CharBuffer cb =
((ByteBuffer)bb. rewind()).asCharBuffer();
printnb("Char Buffer ");
while(cb. hasRemaining())
printnb(cb. position() + " -> " + cb. get() + ", ");
print();
FloatBuffer fb =
((ByteBuffer)bb. rewind()).asFloatBuffer();
printnb("Float Buffer ");
while(fb. hasRemaining())
printnb(fb. position()+ " -> " + fb. get() + ", ");
print();
IntBuffer ib =
((ByteBuffer)bb. rewind()).asIntBuffer();
printnb("Int Buffer ");
while(ib. hasRemaining())
printnb(ib. position()+ " -> " + ib. get() + ", ");
print();
LongBuffer lb =
((ByteBuffer)bb. rewind()).asLongBuffer();
printnb("Long Buffer ");
while(lb. hasRemaining())
printnb(lb. position()+ " -> " + lb. get() + ", ");
print();
ShortBuffer sb =
((ByteBuffer)bb. rewind()).asShortBuffer();
printnb("Short Buffer ");
while(sb. hasRemaining())
printnb(sb. position()+ " -> " + sb. get() + ", ");
print();
DoubleBuffer db =
((ByteBuffer)bb. rewind()).asDoubleBuffer();
printnb("Double Buffer ");
while(db. hasRemaining())
printnb(db. position()+ " -> " + db. get() + ", ");
}
}
Байтовый буфер ByteBuffer создается как «обертка» для массива из восьми байтов, который затем и просматривается с помощью представлений для различных простейших типов.
О порядке байтов
Различные компьютеры могут хранить данные с различным порядком следования байтов. Прямой порядок big_endian располагает старший байт по младшему адресу памяти, а для обратного порядка little_endian старший байт помещается по высшему адресу памяти. При хранении значения, занимающего более одного байта, такого как число int, float и т. п., вам, возможно, придется учитывать различные варианты следования байтов в памяти. Буфер ByteBuffer укладывает данные в порядке big_endian, такой же способ всегда используется для данных, пересылаемых по сети. Порядок следования байтов в буфере можно изменить методом order(), передав ему аргумент ByteOrder. BIG_ENDIAN или ByteOrder. LITTLE_ENDIAN. Рассмотрим двоичное представление байтового буфера, содержащего следующие два байта:
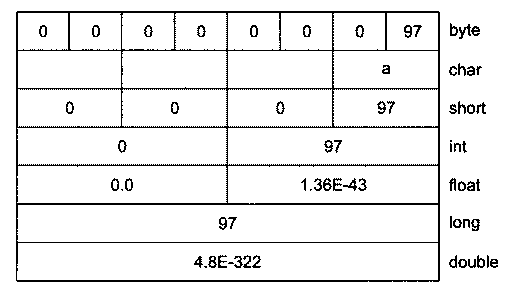
Если прочитать эти данные как тип short (ByteBuffer. asShortBuffer()), то получится число100001), но при другом порядке следования байтов будет получено число1 ).
Следующий пример показывает, как порядок следования байтов отражается на символах в зависимости от настроек буфера:
//: io/Endians. java
// Endian differences and data storage.
import java. nio.*;
import java. util.*;
import static net. mindview. util. Print.*;
public class Endians {
public static void main(String[] args) {
ByteBuffer bb = ByteBuffer. wrap(new byte[12]);
bb. asCharBuffer().put("abcdef");
print(Arrays. toString(bb. array()));
bb. rewind();
bb. order(ByteOrder. BIG_ENDIAN);
bb. asCharBuffer().put("abcdef");
print(Arrays. toString(bb. array()));
bb. rewind();
bb. order(ByteOrder. LITTLE_ENDIAN);
bb. asCharBuffer().put("abcdef");
print(Arrays. toString(bb. array()));
}
}
В буфере ByteBuffer достаточно места для хранения всех байтов символьного массива, поэтому для вывода байтов подходит метод аrrау(). Метод аrrау() является необязательным, и вызывать его следует только для буфера, созданного на базе существующего массива; в противном случае произойдет исключение UnsupportedOperationException. Символьный массив помещается в буфер ByteBuffer посредством представления CharBuffer. При выводе содержащихся в буфере байтов мы видим, что настройка по умолчанию совпадает с режимом big_endian, в то время как атрибут little_endian переставляет байты в обратном порядке.
Буферы и операции с данными
Диаграмма на следующей странице демонстрирует отношения между классами пакета nio; она поможет разобраться, как можно перемещать и преобразовывать данные. Например, если вы захотите записать в файл байтовый массив, то сначала вложите его в буфер методом ByteBuffer. wrap(), затем получите из потока FileOutputStream канал методом getChannel(), а потом запишите данные буфера ByteBuffer в полученный канал FileChannel. Отметьте, что перемещать данные каналов («из» и «в») допустимо только с помощью байтовых буферов ByteBuffer, а для остальных простейших типов можно либо создать отдельный буфер этого типа, либо получить такой буфер из байтового буфера посредством метода с префиксом as. Таким образом, буфер с примитивными данными нельзя преобразовать к байтовому буферу. Впрочем, вы можете помещать примитивы в байтовый буфер и извлекать их оттуда с помощью представлений, это не такое уж строгое ограничение.
Подробно о буфере
Буфер (Buffer) состоит из данных и четырех индексов, используемых для доступа к данным и эффективного манипулирования ими. К этим индексам относятся метка (mark), позиция (position), предельное значение (limit) и вместимость (capacity). Есть методы, предназначенные для установки и сброса значений этих индексов, также можно узнать их значение (табл. 16.7).

Методы, вставляющие данные в буфер и считывающие их оттуда, обновляют эти индексы в соответствии с внесенными изменениями. Следующий пример использует очень простой алгоритм (перестановка смежных символов) для смешивания и восстановления символов в буфере CharBuffer:
//: io/UsingBuffers. java
import java. nio.*;
import static net. mindview. util. Print.*;
public class UsingBuffers {
private static void symmetricScramble(CharBuffer buffer){
while(buffer. hasRemaining()) {
buffer. mark();
char c1 = buffer. get();
char c2 = buffer. get();
buffer. reset();
buffer. put(c2).put(c1);
}
}
public static void main(String[] args) {
char[] data = "UsingBuffers".toCharArray();
ByteBuffer bb = ByteBuffer. allocate(data. length * 2);
CharBuffer cb = bb. asCharBuffer();
cb. put(data);
print(cb. rewind());
symmetricScramble(cb);
print(cb. rewind());
symmetricScramble(cb);
print(cb. rewind());
}
}
Хотя получить буфер CharBuffer можно и напрямую, вызвав для символьного массива метод wrap(), здесь сначала выделяется служащий основой байтовый буфер ByteBuffer, а символьный буфер CharBuffer создается как представление байтового. Это подчеркивает, что в конечном счете все манипуляции производятся с байтовым буфером, поскольку именно он взаимодействует с каналом.
Отображаемые в память файлы
Механизм отображения файлов в память позволяет создавать и изменять файлы, размер которых слишком велик для прямого размещения в памяти. В таком случае вы считаете, что файл целиком находится в памяти, и работаете с ним как с очень большим массивом. Такой подход значительно упрощает код изменения файла. Небольшой пример:
//: io/LargeMappedFiles. java
// Создание очень большого файла, отображаемого в память.
// {RunByHand}
import java.nio.*;
import java.nio.channels.*;
import java. io.*;
import static net. mindview. util. Print.*;
public class LargeMappedFiles {
static int length = 0x8FFFFFF; // 128 MB
public static void main(String[] args) throws Exception {
MappedByteBuffer out =
new RandomAccessFile("test. dat", "rw").getChannel()
.map(FileChannel. MapMode. READ_WRITE, 0, length);
for(int i = 0; i < length; i++)
out. put((byte)'x');
print("Finished writing");
for(int i = length/2; i < length/2 + 6; i++)
printnb((char)out. get(i));
}
}
Чтобы одновременно выполнять чтение и запись, мы начинаем с создания объекта RandomAccessFile, получаем для этого файла канал, а затем вызываем метод mар(), чтобы получить буфер MappedByteBuffer, который представляет собой разновидность буфера прямого доступа. Заметьте, что необходимо указать начальную точку и длину участка, который будет проецироваться, то есть у вас есть возможность отображать маленькие участки больших файлов. Класс MappedByteBuffer унаследован от буфера ByteBuffer, поэтому он содержит все методы последнего. Здесь представлены только простейшие вызовы методов put() и get(), но вы также можете использовать такие возможности, как метод asCharBuffer() и т. п. Программа напрямую создает файл размером 128 Мбайт; скорее всего, это превышает ограничения вашей операционной системы на размер блока данных, находящегося в памяти. Однако создается впечатление, что весь файл доступен сразу, поскольку только часть его подгружается в память, в то время как остальные части выгружены. Таким образом можно работать с очень большими (размером до 2 Гбайт) файлами. Заметьте, что для достижения максимальной производительности используются низкоуровневые механизмы отображения файлов используемой операционной системы.
Производительность
Хотя быстродействие «старого» ввода/вывода было улучшено за счет переписывания его с учетом новых библиотек nio, техника отображения файлов качественно эффективнее. Следующая программа выполняет простое сравнение производительности:
//: io/MappedIO. java
import java. nio.*;
import java. nio. channels.*;
import java. io.*;
public class MappedIO {
private static int numOfInts = 4000000;
private static int numOfUbuffInts = 200000;
private abstract static class Tester {
private String name;
public Tester(String name) { this. name = name; }
public void runTest() {
System. out. print(name + ": ");
try {
long start = System. nanoTime();
test();
double duration = System. nanoTime() - start;
System. out. format("%.2f\n", duration/1.0e9);
} catch(IOException e) {
throw new RuntimeException(e);
}
}
public abstract void test() throws IOException;
}
private static Tester[] tests = {
new Tester("Stream Write") {
public void test() throws IOException {
DataOutputStream dos = new DataOutputStream(
new BufferedOutputStream(
new FileOutputStream(new File("temp. tmp"))));
for(int i = 0; i < numOfInts; i++)
dos. writeInt(i);
dos. close();
}
},
new Tester("Mapped Write") {
public void test() throws IOException {
FileChannel fc =
new RandomAccessFile("temp. tmp", "rw")
.getChannel();
IntBuffer ib = fc. map(
FileChannel. MapMode. READ_WRITE, 0, fc. size())
.asIntBuffer();
for(int i = 0; i < numOfInts; i++)
ib. put(i);
fc. close();
}
},
new Tester("Stream Read") {
public void test() throws IOException {
DataInputStream dis = new DataInputStream(
new BufferedInputStream(
new FileInputStream("temp. tmp")));
for(int i = 0; i < numOfInts; i++)
dis. readInt();
dis. close();
}
},
new Tester("Mapped Read") {
public void test() throws IOException {
FileChannel fc = new FileInputStream(
new File("temp. tmp")).getChannel();
IntBuffer ib = fc. map(
FileChannel. MapMode. READ_ONLY, 0, fc. size())
.asIntBuffer();
while(ib. hasRemaining())
ib. get();
fc. close();
}
},
new Tester("Stream Read/Write") {
public void test() throws IOException {
RandomAccessFile raf = new RandomAccessFile(
new File("temp. tmp"), "rw");
raf. writeInt(1);
for(int i = 0; i < numOfUbuffInts; i++) {
raf. seek(raf. length() - 4);
raf. writeInt(raf. readInt());
}
raf. close();
}
},
new Tester("Mapped Read/Write") {
public void test() throws IOException {
FileChannel fc = new RandomAccessFile(
new File("temp. tmp"), "rw").getChannel();
IntBuffer ib = fc. map(
FileChannel. MapMode. READ_WRITE, 0, fc. size())
.asIntBuffer();
ib. put(0);
for(int i = 1; i < numOfUbuffInts; i++)
ib. put(ib. get(i - 1));
fc. close();
}
}
};
public static void main(String[] args) {
for(Tester test : tests)
*****nTest();
}
}
runTest() — не что иное как метод шаблона, предоставляющий тестовую инфраструктуру для различных реализаций метода test(), определенного в безымянных внутренних подклассах. Каждый из этих подклассов выполняет свой вид теста, таким образом, методы test() также являются прототипами для выполнения различных действий, связанных с вводом/выводом. Хотя кажется, что для отображаемой записи следует использовать поток FileOutputStream, на самом деле любые операции отображаемого вывода должны проходить через класс RandomAccessFile так же, как выполняется чтение/запись в рассмотренном примере. В методах test() также учитывается инициализация различных объектов для работы с вводом/выводом, и, несмотря на то что настройка отображаемых файлов может быть затратной, общее преимущество по сравнению с потоковым вводом/выводом все равно получается весьма значительным.
Блокировка файлов
Блокировка файлов позволяет синхронизировать доступ к файлу как к совместно используемому ресурсу. Впрочем, потоки, претендующие на один и тот же файл, могут принадлежать различным виртуальным машинам JVM, или один поток может быть Java-потоком, а другой представлять собой обычный поток операционной системы. Блокированные файлы видны другим процессам операционной системы, поскольку механизм блокировки Java напрямую связан со средствами операционной системы. Вот простой пример блокировки файла:
//: io/FileLocking. java
import java. nio. channels.*;
import java. util. concurrent.*;
import java. io.*;
public class FileLocking {
public static void main(String[] args) throws Exception {
FileOutputStream fos= new FileOutputStream("file. txt");
FileLock fl = fos. getChannel().tryLock();
if(fl!= null) {
System. out. println("Locked File");
TimeUnit. MILLISECONDS. sleep(100);
fl. release();
System. out. println("Released Lock");
}
fos. close();
}
}
Блокировать файл целиком позволяет объект FileLock, который можно получить, вызывая метод tryLock() или lock() класса FileChannel. Сетевые каналы SocketChannel, DatagramChannel и ServerSocketChannel не нуждаются в блокировании, так как они доступны только в пределах одного процесса. Метод tryLock() не приостанавливает программу. Он пытается овладеть объектом блокировки, но если ему это не удается (если другой процесс уже владеет этим объектом или файл не является разделяемым), то он просто возвращает управление. Метод lock() ждет до тех пор, пока не удастся получить объект блокировки, или поток, в котором этот метод был вызван, не будет прерван, или же пока не будет закрыт канал, для которого был вызван метод lock(). Блокировка снимается методом FileChannel. release().
Также можно заблокировать часть файла вызовом
tryLock(long position, long size, boolean shared)
или
lock (long position, long size, boolean shared)
Блокируется участок файла размером size от позиции position. Третий аргумент указывает, будет ли блокировка совместной. Методы без аргументов приспосабливаются к изменению размеров файла, в то время как методы для блокировки участков не адаптируются к новому размеру файла. Если блокировка была наложена на область от позиции position до position + size, а затем файл увеличился и стал больше размера position + size, то часть файла за пределами position + size не блокируется. Методы без аргументов блокируют файл целиком, даже если он растет. Поддержка блокировок с эксклюзивным или разделяемым доступом должна быть встроена в операционную систему. Если операционная система не поддерживает разделяемые блокировки и был сделан запрос на получение такой блокировки, используется эксклюзивный доступ. Тип блокировки (разделяемая или эксклюзивная) можно узнать при помощи метода FileLock. isShared().
Блокирование части отображаемого файла
Как уже было упомянуто, отображение файлов обычно используется для файлов очень больших размеров. Иногда при работе с таким большим файлом требуется заблокировать некоторые его части, в то время как доступные части будут изменяться другими процессами. В частности, такой подход характерен для баз данных, чтобы несколько пользователей могли работать с базой одновременно. В следующем примере каждый их двух потоков блокирует свою собственную часть файла:
//: io/LockingMappedFiles. java
// Блокирование части отображаемого файла.
// {RunByHand}
import java.nio.*;
import java.nio.channels.*;
import java. io.*;
public class LockingMappedFiles {
static final int LENGTH = 0x8FFFFFF; // 128 MB
static FileChannel fc;
public static void main(String[] args) throws Exception {
fc =
new RandomAccessFile("test. dat", "rw").getChannel();
MappedByteBuffer out =
fc. map(FileChannel. MapMode. READ_WRITE, 0, LENGTH);
for(int i = 0; i < LENGTH; i++)
out. put((byte)'x');
new LockAndModify(out, 0, 0 + LENGTH/3);
new LockAndModify(out, LENGTH/2, LENGTH/2 + LENGTH/4);
}
private static class LockAndModify extends Thread {
private ByteBuffer buff;
private int start, end;
LockAndModify(ByteBuffer mbb, int start, int end) {
this. start = start;
this. end = end;
mbb. limit(end);
mbb. position(start);
buff = mbb. slice();
start();
}
public void run() {
try {
// Exclusive lock with no overlap:
// Монопольная блокировка без перекрытия:
FileLock fl = fc. lock(start, end, false);
System. out. println("Locked: "+ start +" to "+ end);
// Perform modification:
// Модификация:
while(buff. position() < buff. limit() - 1)
buff. put((byte)(buff. get() + 1));
fl. release();
System. out. println("Released: "+start+" to "+ end);
} catch(IOException e) {
throw new RuntimeException(e);
}
}
}
}
Класс потока LockAndModify устанавливает область буфера и получает его для модификации методом slice(). В методе run() для файлового канала устанавливается блокировка (вы не вправе запросить блокировку для буфера, это позволено только для канала). Вызов lock() напоминает механизм синхронизации доступа потоков к объектам, у вас появляется некая «критическая секция» с монопольным доступом к данной части файла. Блокировки автоматически снимаются при завершении работы JVM, закрытии канала, для которого они были получены, но можно также явно вызвать метод release() объекта FileLock, что здесь и показано.
