
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Специальные типы задач в ППО gLite.
I. Язык описания задания в Grid - JDL
Для того, чтобы запустить задание в Grid, используя gLite, необходимо создать файл, содержащий описание этого задания. Для этого используется язык, который называется JDL (Job Description Language)[1]. JDL атрибуты определяют действия, которые должны быть выполнены WMS (Workload management System)[2] для планирования и запуска задания или заданий сложного запроса. Некоторые атрибуты JDL являются обязательными, и если пользователь не определит их, то WMS не сможет выполнить запрос. Для некоторых других атрибутов система может найти значение по умолчанию, если это необходимо для обработки запроса.
JDL позволяет описание следующих типов запросов (запросов, которые поддерживает WMS):
- Job простая задача
- DAG набор зависимых задач
- Collection набор независимых задач
Тип запроса определяется в JDL атрибутом Type:
Type=”Job/DAG/Collection”;
По умолчанию значением атрибута Type является Job. Для запроса типа Job можно определить тип задачи с помощью атрибута JobType. В настоящее время WMS поддерживает следующие типы задач (это неприменимо к запросам DAG и Collection):
- Normal обычная задача
- Interactive интерактивная задача
- MPICH параллельное приложение, использующее протокол распараллеливания процессов MPI
- Parametric
- Checkpointable
- Partitionable
I. Простое задание
Ниже представлено JDL-описание простейшего задания:
#
Type=”job”; # Тип запроса - задание (по умолчанию)
JobType=”normal”; # Тип задачи - обычный (по умолчанию)
|
![]() Executable = "/bin/echo";
Executable = "/bin/echo";
# Программа будет запускаться с одним аргументом "Hello World"
Arguments = "Hello World";
|
# соответственно
![]() StdOutput = "stdout. log";
StdOutput = "stdout. log";
StdError = "stderr. log";
|
![]() OutputSandbox = {"stdout. log", "stderr. log"};
OutputSandbox = {"stdout. log", "stderr. log"};
Задание в Grid запускается с использованием команды gLite
glite-wms-job-submit <имя JDL файла>
В случае успешного выполнения команда возвращает идентификатор задания ID:
================ glite-wms-job-submit Success ======================
The job has been successfully submitted to the WMProxy
Your job identifier is:
https://tigerman. cnaf. infn. it:9000/stshjZvp-yPdn7jGVX64Ag
Этот ID в дальнейшем может быть использован в следующих командах управления заданием gLite:
- glite-wms-job-status <ID> : Получить статус задания:
*****
BOOKKEEPING INFORMATION:
Status info for the Job : https://tigerman. cnaf. infn. it:9000/NEs1GSI8uYDE33SaobBIyA
Current Status: Ready
Status Reason: unavailable
Destination: lxde01.pd. infn. it:2119/blah-lsf-grid03
Submitted: Mon Jul 11 19:48:38 2006 CEST
- glite-wms-job-output <ID> : Передать выходные файлы задания
- glite-wms-job-cancel <ID> : Прекратить выполнение задания
II. DAG - Direct Acyclic Graph.
DAG представляет собой набор задач (нодов), в котором вход, выход или выполнение одних задач может зависеть от других. DAG может быть представлен графом, где нодами являются задачи, а ребра определяют зависимости:
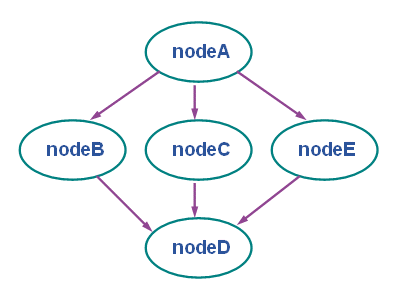
Рис.1 Direct Acyclic Graph
Зависимости не могут быть циклическими (Acyclic Graph). DAG в целом (как и его ноды) получает уникальный ID, который может использоваться в командах управления заданием. Ниже приведен пример JDL файла для DAG, изображенного на рис.1:
[
Type=”DAG”;
VirtualOrganization=”Atlas”;
InputSandBox={
"/home/data/data1.txt",
"/home/data/data2.txt"
};
nodes=[
nodeA = [
Description=[
Executable = “prg1”;
InputSandbox={"root. InputSandbox[0],"/home/data/data2.txt"};
OutputSanbox = “outd1.txt”;
];
];
nodeB = [
Description=[
Executable = “prg2”;
InputSandbox="/home/data/data3.txt";
OutputSanbox = “outd2.txt”;
];
];
nodeC = [
Description=[
Executable = “prg3”;
OutputSanbox = “outd3.txt”;
];
];
nodeD = [
file=”nodeD. jdl”;
];
nodeE = [
file=”nodeE. jdl”;
];
dependencies={
{ nodeA, nodeB }, { nodeA, nodeC }, { nodeA, nodeC },
{ {nodeB, nodeC, nodeD}, nodeE}
};
];
]
Структура JDL описания DAG состоит из ряда вложенных секций в следующей иерархии:
- Корневая (root) секция, которая содержит полное описание с некоторыми атрибутами, связанными с DAG в целом, т. к. они наследуются всеми нодами DAG.
- Дочерняя секция Nodes, содержащая JDL описание всех нодов и на том же уровне атрибут Dependencies, определяющий зависимости между всеми нодами DAG.
- Набор секций внутри секции Nodes, каждая из которых соответствует конкретному ноду и содержит его полное описание
Описание конкретного нода может быть определено либо с использованием атрибута Description, либо в отдельном файле, адрес которого определяется через атрибут File.
Все ноды, которые не содержат InputSandbox атрибут в своем описании, наследуют его значение от корневого InputSandbox атрибута DAG.
Ноды, представляющие задачи без входных данных, должны содержать в своем описании пустой InputSandbox:
InputSandbox = {};
В описании нода допускается делать ссылки на корневые атрибуты DAG или атрибуты другого нода.
InputSandbox={"root. InputSandbox[0],"/home/data/data2.txt"};
JDL описание DAG не может содержать OutputSandbox атрибута в корневой секции, а только в JDL описании нодов. OutputSandbox DAGа в целом рассматривается как сумма всех output sandboxes нодов.
Когда glite-wms-job-output команда выдается для DAG ID, она запрашивает выходные файлы всех нодов, но сохраняет их в разных поддиректориях, соответствующих разным нодам. Это позволяет избежать перезаписи файлов с одинаковыми именами, которые относятся к разным нодам. Имена поддиректорий соответствуют именам нодов.
III. Запрос типа Collection
Collection - это набор независимых задач, который пользователь может запустить и мониторировать одним запросом. По сути это DAG без зависимостей нодов, но синтаксис JDL описания немного отличается от описания DAG. Как и для DAG, после запуска задания как все ноды Collection получают уникальные jobID, так и задание вцелом связывается с jobID, который может использоваться в командах управления задачами.
Ниже приведен пример JDL описания запроса типа Collection:
[
type = "collection";
InputSandbox = {"date. sh"};
RetryCount = 0;
nodes = {
[
file ="jobs/job1.jdl" ;
],
[
NodeName = “job2”;
Executable = "/bin/sh";
Arguments = "date. sh";
Stdoutput = "date. out";
StdError = "date. err";
OutputSandbox ={"date. out", "date. err"};
],
[
file ="jobs/job3.jdl" ;
]
};
]
Следует отметить, что набор независимых задач может быть запущен в gLite с использованием нового параметра –collection в команде glite-wms-job-submit:
glite-wms-job-submit –collection <dirpath> …….
Эта опция позволяет определить путь до директории, которая содержит
JDL файлы независимых задач, составляющих требуемую коллекцию.
Команда glite-wms-job-submit сама создаст соответствующий JDL с типом
Type=collection и запустит задание в gLite.
IV. Интерактивные задачи.
Интерактивная задача определяется установкой атрибута JobType в Interactive.
JobType = “Interactive”;
Когда выдается запрос на запуск интерактивной задачи, команда glite-wms-job-submit запускает в фоновом режиме специальный процесс (Grid console shadow) который будет слушать порт, на который будут направляться стандартные потоки из запущенной задачи. Кроме того, команда glite-wms-job-submit открывает новое графическое окно, куда будет перенаправляться вывод из задачи (рис.2).
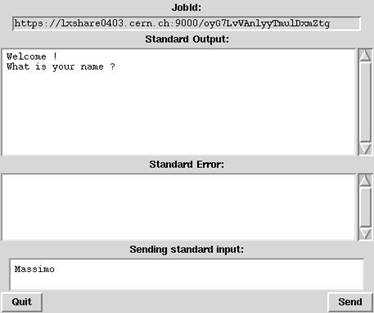
Ниже представлен пример JDL-файла, содержащего описание простого интерактивного задания:
[
JobType = "Interactive";
Executable = "interactive. sh";
InputSandbox = {"interactive. sh"};
]
Следует отметить, что здесь не требуется атрибут OutputSandbox, т. к. вывод из задачи будет перенаправляться в графическое окно.
Запускаемая задача, определенная атрибутом Executable, является скриптом bash, текст которого представлен ниже:
#!/bin/sh
echo "Welcome!"
echo - n "Please tell me your name: "
read name
echo "That is all, $name."
echo "Bye bye."
exit 0
V. Параметрическое задание.
Параметрическое задание – это задание, имеющее один или более параметрических атрибутов в JDL. Параметрические атрибуты изменяют свои значения в соответствии с другим атрибутом (Parameters), который также определяется в JDL-описании задания. Запуск параметрического задания приводит к запуску набора задач, имеющих одинаковые описания кроме значений параметрических атрибутов, т. е. для каждого значения параметра создается отдельная задача. Параметрическое задание, а также все созданные задачи, получают уникальные ID. Это позволяет мониторировать и управлять как каждой задачей по отдельности, так и всем заданием в целом. Ниже приведено JDL описание параметрического задания:
[
JobType = "Parametric";
Executable = "/bin/sh";
Arguments = "md5.sh input_PARAM_.txt";
InputSandbox = {"md5.sh", "input_PARAM_.txt"};
StdOutput = "out_PARAM_.txt";
StdError = "err_PARAM_.txt";
Parameters = 10;
ParameterStart = 1;
ParameterStep = 4;
OutputSandbox ={"out_PARAM_.txt","err_PARAM_.txt"};
]
После запуска такого задания будет сформирован DAG с N задачами, где
N = (Parameters – ParameterStart)/ParameterStep = 3
JDL описание сгенерированных задач будет следующее:
[
JobType = "Normal";
Executable = "/bin/sh";
Arguments = "md5.sh input1.txt";
InputSandbox = {"md5.sh", "input1.txt"};
StdOutput = "out1.txt";
StdError = "err1.txt";
OutputSandbox ={"out1.txt","err1.txt"};
]
[
JobType = "Normal";
Executable = "/bin/sh";
Arguments = "md5.sh input2.txt";
InputSandbox = {"md5.sh", "input2.txt"};
StdOutput = "out2.txt";
StdError = "err2.txt";
OutputSandbox ={"out2.txt","err2.txt"};
]
[
JobType = "Normal";
Executable = "/bin/sh";
Arguments = "md5.sh input3.txt";
InputSandbox = {"md5.sh", "input3.txt"};
StdOutput = "out3.txt";
StdError = "err3.txt";
OutputSandbox ={"out3.txt","err31.txt"};
]
Назначенное значение параметра экспортируется задаче через переменную окружения ParameterValue. Кроме того, каждой задаче присваивается имя “node_P”,где Р есть значение параметра для данного экземпляра задачи. Это имя задачи можно увидеть при использовании команды glite-wms-job-status, которая выдана для всего параметрического задания. В приведенном примере атрибут Parameters определяет совместно с атрибутами ParameterStart и ParameterStep диапазон параметризации (по умолчанию ParameterStart=0 и ParameterStep=1).
Как альтернатива, атрибут Parameters может специфицировать список значений, которые будут использоваться при назначении значений параметрическим атрибутам. Например:
Parameters = {alpha, beta, gamma};
В этом случае атрибуты ParameterStart и ParameterStep не используются.
VI. MPI задачи.
Message Passing Interface (MPI) приложения выполняются параллельно на нескольких процессорах. С точки зрения пользователя задача, которая должна выполняться как MPI, специфицируется установкой JDL атрибута JobType в MPICH. Когда этот атрибут включается, то должен также быть определен атрибут NodeNumber, который определяет требуемое число CPU. Пользовательский интерфейс (UI) автоматически будет требовать, чтобы MPICH окружение было установлено на CЕ и число CPU на этих СЕ было не меньше требуемого. Это достигается добавлением в JDL описание задачи выражения типа следующего:
(other. GlueCEInfoTotalCPUs >= <NodeNumber> ) &&
Member("MPICH",other. GlueHostApplicationSoftwareRunTimeEnvironment)
Программа, которая специфицирована в JDL как Executable, не должна быть MPI приложением напрямую. Это должен быть скрипт, который запускает MPI программу через mpirun3. Это позволит пользователю выполнить в скрипте некоторые предварительные шаги. Эти шаги обычно включают компиляцию MPI программы, т. к. результирующий двоичный код может быть различный, в зависимости от MPI версии и конфигурации. Следует также отметить, что некоторые MPI приложения требуют разделяемой файловой системы (shared filesystem) среди используемых CPU. Для того, чтобы определить наличие разделяемой файловой системы, можно использовать переменную окружения VO <name of VO> SW DIR, которая либо содержит путь до разделяемой директории, либо “.”, если разделяемая файловая система отсутствует.
Ниже представлен полный пример MPI задания.
Простейшая MPI задача может быть следующая (MPItest. c):
#include "mpi. h"
#include <stdio. h>
int main(int argc, char *argv[])
{
int numprocs; /* Number of processors */
int procnum; /* Processor number */
/* Initialize MPI */
MPI_Init(&argc, &argv);
/* Find this processor number */
MPI_Comm_rank(MPI_COMM_WORLD, &procnum);
/* Find the number of processors */
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
printf ("Hello world! from processor %d out of %d\n", procnum, numprocs);
/* Shut down MPI */
MPI_Finalize();
return 0;
}
JDL описание:
JobType = "MPICH";
NodeNumber = 10;
Executable = "MPItest. sh";
Arguments = "MPItest";
StdOutput = "test. out";
StdError = "test. err";
InputSandbox = {"MPItest. sh","MPItest. c"};
OutputSandbox = {"test. err","test. out","mpiexec. out"};
Запускаемый скрипт:
#!/bin/sh - x
# Binary to execute
EXE=$1
echo "*******"
echo "Running on: $HOSTNAME"
echo "As: " ‘whoami‘
echo "*******"
echo "Compiling binary: $EXE"
echo mpicc - o ${EXE} ${EXE}.c
mpicc - o ${EXE} ${EXE}.c
if [ "x$PBS_NODEFILE" != "x" ] ; then
echo "PBS Nodefile: $PBS_NODEFILE"
HOST_NODEFILE=$PBS_NODEFILE
fi
if [ "x$LSB_HOSTS" != "x" ] ; then
echo "LSF Hosts: $LSB_HOSTS"
HOST_NODEFILE=‘pwd‘/lsf_nodefile.$$
for host in ${LSB_HOSTS}
do
echo $host >> ${HOST_NODEFILE}
done
fi
if [ "x$HOST_NODEFILE" = "x" ]; then
echo "No hosts file defined. Exiting..."
exit
fi
echo "*******"
CPU_NEEDED=‘cat $HOST_NODEFILE | wc - l‘
echo "Node count: $CPU_NEEDED"
echo "Nodes in $HOST_NODEFILE: "
cat $HOST_NODEFILE
echo "*******"
CPU_NEEDED=‘cat $HOST_NODEFILE | wc - l‘
echo "Checking ssh for each node:"
NODES=‘cat $HOST_NODEFILE‘
for host in ${NODES}
do
echo "Checking $host..."
ssh $host hostname
done
echo "*******"
echo "Executing $EXE with mpirun"
chmod 755 $EXE
mpirun - np $CPU_NEEDED - machinefile $HOST_NODEFILE ‘pwd‘/$EXE
Этот скрипт сначала компилирует MPI приложение, а затем создается список хостов, на которых будет выполнятся эта задача. В переменной CPU NEEDED сохраняется число имеющихся нодов. Затем скрипт проверяет, что ssh работает на всех нодах. Затем вызывается mpirun с параметрами –np и –machinefile.
