
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Для визуализации ПО используются два различных формата: VRML и HTML. Первый формат (VRML-Virtual Reality Modelling Language) применяется при навигации по индексу оглавления и авторскому индексу. В данном случае понятия изображаются в виде трехмерных сфер, расположенных в заданном в соответствии с хранимой в БД информацией, иерархическом порядке. Связи между понятиями обозначаются в виде линий, соединяющих сферы. Гибкость и трехмерность данного представления, добавляют нам множество способов навигации. Также к каждому понятию, представляемому трехмерной сферой, возможно присоединение обработчика событий, реагирующего, например, на нажатие мыши. По щелчку на узле дерева вызывается страница заданная URL, находящимся в узле Anchor{}.
Второй формат – HTML (Hyper Next Marking Language) широко распространен. Для нашей системы он выбран, на основании богатых возможностей отображения структурированной текстовой информации.
Язык моделирования виртуальной реальности
VRML - язык моделирования виртуальной реальности. Это формат файлов для описания трехмерных объектов и миров для World Wide Web (подобно тому, как HTML используется для представления текста на WWW). Первая реализация VRML (1.0 спецификация) была создана компанией Silicon Graphics и представляла собой формат описания статических миров. Во второй реализации VRML (2.0 спецификация) добавились более сложные интерактивные возможности и анимация. Она была разработана компанией Silicon Graphics в сотрудничестве с компаниями Sony и Mitra. VRML технология имеет очень широкое применение (представление любой информации на web серверах в виде 3-х мерных, интерактивных виртуальных миров). Примерами могут служить интерактивные образовательные программы; виртуальные города, музеи, магазины и т. д.
VRML файлы можно создавать, используя любой текстовый редактор или множество появившихся в последнее время приложений для построения VRML миров. Файлы можно просматривать, используя либо отдельные VRML броузеры, либо VRML браузеры, встроенные в HTML браузеры. VRML файлы имеют следующую структуру:
o специальный комментарий в заголовке;
o комментарии, касающиеся текста программы;
o узлы - основные компоненты сцены;
o поля - атрибуты узлов (характеризуются значением, которое может изменяться);
o значения полей - атрибуты полей (характеризуются типом данных);
o именованные узлы - могут многократно использоваться в сцене.
VRML поддерживает стандартные типы данных. Все поля имеют определенный тип данных. В VRML строчные и прописные буквы различаются. Названия узлов начинаются с прописной буквы, затем следуют строчные. Названия полей состоят из прописных букв.
Пример простого VRML файла:
#VRML V2.0 utf8
# Цилиндр
Shape {
appearance Appearance {
material Material { }
}
geometry Cylinder{
height 2.0
radius 1.5
}
}
[ cylinder. wrl ]
Узлам можно давать имена, чтобы затем их многократно использовать.
Пример использования имен:
DEF MyCylinder Shape { . . . }
. . .
USE MyCylinder
. . .
USE MyCylinder
База данных
Начав с первой коммерческой реляционной СУБД, Oracle реализовал системы повышенной надежности, системы для поддержки хранилищ данных и аналитических систем, распределенных БД. Начав с чисто реляционной модели, Oracle последовательно реализовал хранение и обработку таких мультимедийных данных, как текст, изображение, видео, аудио, пространственная информация. Затем СУБД стала объектно-реляционной, т. е. стала поддерживать и объектную модель. Следующим шагом стало встраивание все в ту же СУБД средств поддержки многомерной модели (OLAP) и средств для Data Mining, средств поддержки специальных моделей, типичных для хранилищ данных. И, наконец, последним бурно развивающимся направлением стало встраивание в СУБД Oracle поддержки XML модели.
Поскольку направлений развития довольно много, перечислим наиболее интересные:
· встраивание в единую СУБД средств эффективного создания и поддержки работы очень большими (до 512 Pb) БД (VLDB), хранилищами данных, средств поддержки многомерных OLAP технологий и алгоритмов Data Mining (автоматическое исследование данных) с сохранением всех преимуществ коммерческой СУБД, средств проектирования и выполнения процедур извлечения, согласования, очистки, передачи и загрузки данных (ETL), средств персонализации;
· развитие в СУБД интернет технологий, таких как интернет файловая система (IFS), виртуальная Java машина (поддержка Java 1.3), работа с динамическими Web сервисами, средства проектирования и реализации порталов и портлетов
· реализация новых средств разделения информации между различными БД, серверами, приложениями (возможно от разных производителей). Начав с поддержки распределенных БД и репликации, Oracle реализовал поддержку систем работы с очередями сообщений, workflow, автоматическое поддержание логической и физической резервной БД, загрузку данных в хранилища и Data Store и, наконец, единую технологию, объединяющую все выше перечисленные – Oracle Stream;
· много изменений в последнее время было сделано в области совершенствования защиты данных. Наиболее интересными можно считать реализацию концепции приватной (персональной) БД (Private Database) на основе механизма Fine Grain доступа, коробочное решение по защите данных с использованием меток секретности строк данных (Label Security), новых средств кодирования данных в БД и при передаче;
· очень много усилий было в последние годы затрачено на превращение СУБД Oracle в непрерывно работающую и всегда доступную для приложений и пользователей платформу. Комплекс решений, таких как Real Application Cluster,
· логическая и физическая StandBy БД, выполнение администрирования БД без ее остановки и замедления работы с объектами БД позволяют реализовать на основе Oracle системы с временем простоя 5 – 15 минут в год. А новая возможность Flash Back позволяет пользователям легко путешествовать в прошлое и работать на эксплуатационной системе со своими вчерашними, позавчерашними и т д данными. Кроме того, подключение на лету все новых и новых узлов кластера позволяет плавно увеличивать мощность вычислительной системы;
· XML DB. Теперь наряду с обычными реляционными данными мы можем хранить в той же БД XML документы и быстро работать с ними. При этом документы хранятся в СУБД и используют все преимущества такого хранения. Специальные механизмы хранения, индексирования, построения XML View и т. д. позволяют не только эффективно хранить, но и запрашивать и изменять эти данные и их части. Причем традиционные SQL операции умеют работать как с реляционными данными, так и с XML файлами, и наоборот, с помощью XML операций можно работать с SQL данными. А кроме этого, XML DB позволяет разложить XML документы по иерархическим папкам, установить для них дополнительные средства контроля доступа (ACL), осуществить поиск нужных XML документов по контексту и т. д.;
· постоянно совершенствуются и упрощаются средства управления СУБД. Многие операции по администрированию БД, ранее требовавшие участия администратора БД, теперь выполняются автоматически. А графический инструмент администратора БД – Oracle Enterprise Manager позволяет, бросив быстрый взгляд на всю прикладную систему в целом, увидеть “узкие места” и далее помогает детализировать проблемы и подсказывает методы их устранения. Интеллектуальная экспертная система поможет настроить Вашу БД;
Если глобально посмотреть на направление всех основных изменений за последние годы, то их можно объединить в следующие группы:
- высокая доступность;
- масштабируемость и производительность;
- защита данных;
- развитие средств разработки;
- управляемость;
- работа с интернет контентом и мультимедиа;
- Business Intelligence;
- поддержка хостинга.
Разработка Web-приложений с помощью Oracle
PL/SQL (Procedural Language SQL - Процедурный язык SQL) - это дополнение языка SQL в версии Oracle9i. В PL/SQL язык SQL дополнен такими средствами обычных языков программирования, как обработка записей, управление ходом выполнения программы, средства выполнения манипуляций и вычислений с данными, а также обработки исключений.
Язык PL/SQL широко применяется для создания приложений Oracle9i. На этом языке, как и на языке Java, разрабатываются хранимые процедуры, хранимые функции и триггеры базы данных. Хранимые процедуры и функции представляют возможность повторно использовать код и выполнять обработку данных на сервере, возвращая пользователю или приложению готовый результат. Обратите внимания, что при использовании кода SQL приходится передавать в приложение каждую строку (например, как при использовании программ Oracle Forms или SQL*Plus), а при выполнении кода на сервере возвращается только готовый результат.
Хранимой процедурой называется программный модуль, выполняющий определенную обработку данных и возвращающий код, который позволяет определить, была ли процедура выполнена успешно. Например, хранимая процедура позволяет обработать группу строк с учетом заданного значения, а затем применить операторы DML к другой таблице в соответствии с результатом обработки этой группой строк.
Функция - это разновидность процедуры, которая отличается тем, что она возвращает в вызывающий оператор значение, например, результат вычисления. Процедуры и функции представляют собой превосходный способ выполнения сложных вычислений или обработки, которую было бы нелегко осуществить с применением только операторов SQL.
Пакеты - это программные конструкции, позволяющие объединять взаимосвязанные процедуры и функции, или процедуры и функции, которые часто применяются в приложениях определенного типа. При ссылке на любую процедуру или функцию пакета в память загружаются все процедуры и функции этого пакета.
Триггеры назначаются таблицам и предоставляют возможность применять дополнительные функциональные средства либо до, либо после выполнения оператора DML. Триггеры позволяют вести контрольные журналы для указанных таблиц, применять к другим таблицам дополнительные операторы DML на основе результатов выполненных операторов DML и т. д.
Код процедуры функций может находиться либо на клиентском компьютере, либо на сервере, но обычно целесообразнее выполнять большой объем обработки данных на сервере, поскольку это позволяет уменьшить сетевой трафик и повысить производительность приложений.
Межсетевой сервер приложений Oracle принимает от пользователей (из Web-браузеров) запросы и в ответ передает пользователям документы в коде HTML. Такие документы могут считываться с сервера или формироваться динамически с применением средств языка PL/SQL.
Запрос на формирование документа HTML представляет собой URL, содержащий в качестве виртуального адреса вызов пакета PL/SQL на WEB-сервере. Далее приведен код PL/SQL, предназначенный для формирования Web-страницы с сообщением «Hello World». Следует отметить, что применяемая для этого процедура PL/SQL создается обычным образом, с помощью оператора CREATE OR REPLACE. Для вывода кода на языке HTML применяются встроенные пакеты PL/SQL двух типов. Пакет htp содержит процедуры PL/SQL, предназначенные для вывода кода HTML, а htf содержит функции PL/SQL, которые возвращают код HTML в качестве результата. Префикс оператора htp. предоставляет интерпретатору PL/SQL информацию о том, что за ним следует оператор вывода кода HTML, который должен быть выведен в качестве результата. Например, оператор htp. htmlopen сообщает интерпретатору PL/SQL, что должна быть сформирована начальная часть документа HTML, а оператор htp. htmlclose сообщает о формировании окончательной части документа HTML. Аналогичную функцию выполняют операторы htp. bodyopen и htp. bodyclose, но они применяются для формирования начальной и конечной части страниц. С другой стороны, оператор htp. p используется для вывода элементов в документ HTML. В данном примере оператор htp. p применяется для вывода сообщения «Hello World».
Create or replace procedure helloworld
As
Begin
Htp. htmlopen;
Htp. bodyopen;
Htp. p(‘HelloWorld’);
Htp. bodyclose;
Htp. htmlclose;
End;
/
5 Предметная область - демонстрационный прототип
Межпредметные связи
Предметная область состоит из учебного курса метода ГРОМ, исполняющего роль концептуального каркаса для авторских курсов за счет существующих в нем межпредметных связей, самих авторских учебных курсов и интерфейс-индекса определяющего подчинение СЕТов авторских курсов главному индексу понятий учебного курса.


Такая структура предметной области является наиболее гибкой и наращиваемой за счет фактической независимости между учебным курсом и авторскими курсами – изменения в одном из курсов не влияет на другие. Изменению подвергается лишь интерфейс индекс. Добавление нового авторского курса приводит к добавлению новых связей в интерфейс-индексе, без изменения уже существующих, включая учебный курс. Изменения в учебном курсе метода ГРОМ также влияют только на интерфейс-индекс, не затрагивая содержание и структуру авторских курсов.
5.1.1 Авторский курс
В отсутствии учебного курса в классическом понимании для метода ГРОМ, обучение строится посредством совокупных авторских курсов. Авторские курсы представляются в системе специальным образом. Образ представления основывается на обобщении «разумного» вида курса для обучения. У «разумного» курса есть концептуальный каркас, который поддерживается индуктивными и обобщающими моделями. Ниже предлагается первое приближение по организации «разумного» курса на основании авторского.
Итак, авторский курс образует электронный учебник курса, обогащенный дополнительными структурными свойствами, связанными с необходимостью выявления в нем концептуальной сути (оглавления) на основе индуктивной базы понятий (индекс).
Документ = {Индекс, Оглавление}
Оглавление = {узел | узел Î Дерево}
узел = < i, значение i >
где i – единица оглавления (текст),
значение i = {СЕТ | единица текста каркаса, структурно организованная на основании гиперсвязей}.
Индекс = < j, локальное значение j, глобальное значение >
j – понятие (текст)
локальное значение j – определение понятия,
глобальное значение – {СЕТ (Док) | Док Î Документы FLINT},
СЕТ (Док) = {<СЕТ | i>}
где i фиксирует узел, которому принадлежит структурная единица текста СЕТ.
Документ должен позволить осуществлять в нем навигацию по концептуальной структуре (оглавлению) и по индуктивной структуре (индексу).
5.1.2 Интерфейс-индекс
Связь учебного курса метода ГРОМ с авторскими курсами осуществляется через глобальное значение понятия j. Кроме того, курс метода ГРОМ имеет связи с учебными курсами в рамках своей структурной организации.
Интерфейс-индекс реализует эти связь и соподчиняет авторские курсы нашему учебному курсу. Авторские курсы писались, зачастую, с иными целями, чем наш курс, но, в отличии от курса в методе ГРОМ, они несут не только логическую структуру, но и конкретное, тщательно проработанное содержание, изобилуют методическим материалом. Таким образом, интерфейс-индекс наполняет учебный курс материалом, позволяет легко добавлять новый материал либо удалять старый, менять структуру курса метода, ГРОМ не затрагивая содержание авторских курсов.
Например:
Обозначение фиксирует что определение понятия предназначено для маршрутизации вверх, т. к. является ограничением более общего экстенциального понятия.
Обозначение ¯ фиксирует что определение понятия предназначено для маршрутизации вниз, т. к. является расширением более частного интенсионального понятия.
Обозначение ¯ фиксирует смешанный характер определения.
УЯИП
= <ЯИП>; без <Квантора $>.
=¯ <алгебра логики>; с <предикатами>; и <квантором ">; от <предметных переменных>.
= <логика первого порядка>; без <Квантора $>.
=¯ <язык>; с <генерационной грамматикой>; с <перечислимым множеством>; слов но <неразрешимым>; с реальной проблемой <определимости> (<теорема Биркгофа>).
Рекурсивная последовательность
=¯ <рекурсия>; или <повторная>; или <каскадная>; но не <удаленная>.
5.1.3 Свойства предметной области
5.1.3.1 Иерархия
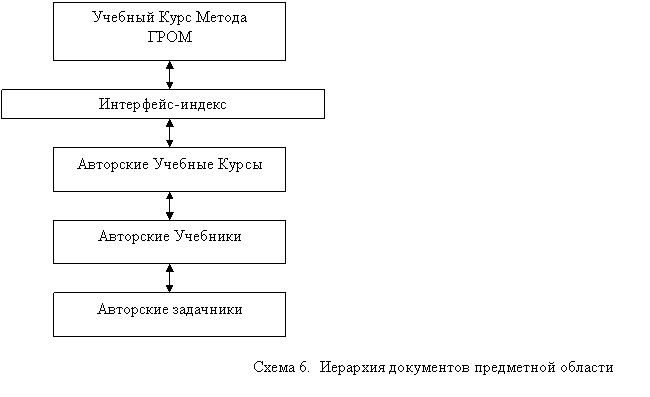 Предметная область имеет иерархическую структуру. На сх. 5 представлена иерархия документов в системе FLINT, для метода ГРОМ. Авторские курсы подчинены учебному курсу посредством интерфейс-индекса. Подчинение учебников и задачников определяется самим автором, при этом допустимо их отсутствие. При отсутствии подчиняющего авторского учебного курса, подчинение идет напрямую через интерфейс-индекс, либо задачники подчиняются чужому авторскому курсу.
Предметная область имеет иерархическую структуру. На сх. 5 представлена иерархия документов в системе FLINT, для метода ГРОМ. Авторские курсы подчинены учебному курсу посредством интерфейс-индекса. Подчинение учебников и задачников определяется самим автором, при этом допустимо их отсутствие. При отсутствии подчиняющего авторского учебного курса, подчинение идет напрямую через интерфейс-индекс, либо задачники подчиняются чужому авторскому курсу.
При движении сверху вниз, от учебного курса до задачи, снижается концептуальное видение предмета и возрастает конкретизация понятий. В этом плане учебные курсы сохраняют концептуальное видение той части предмета, которой они посвящены, но теряют его в рамках всей предметной области. Происходит потеря межпредметных связей, столь необходимых для вовлечения человека в концептуальный мир рациональной культуры.
На уровне документа (авторского курса, учебника или задачника) иерархия задается автором в соответствии с требованиями к структуре документа, направленными на придание ему свойств и методов для эффективной обработки. Иерархия задается посредством индекса документа и его оглавления, которое подчиняет под себя индекс. Документ имеет структуру, описанную в п. 4.1.1
СЕТы документа имеют менее очевидную иерархию, основанную, во-первых, на привязке СЕТов к индексу документа, и, во-вторых, по весам – спискам понятий входящим в СЕТ. Первое задет иерархию, второе - взаимосвязь СЕТов по непустому пересечению множеств понятий, входящих в СЕТ.
5.1.3.2 Однородность
Вопреки заложенной в предметную область иерархии, на каждом из уровней (документы, индексы, СЕТы) существует однородный материал.
В иерархии документов прописано лишь подчинение нижележащей группы выше лежащей. Так авторские курсы подчиняются нашему учебному курсу, но не подчиняются друг другу, являются взаимно независимыми и порождают однородность.
В случае индекса однородность порождается не проработанными в курсе понятиями, лежащими на самом нижнем уровне индекса. Таковыми являются: базовые понятия предмета, не несущие межпредметной нагрузки, но входящие во многие другие понятия; либо же понятия, встречающиеся только в задачах. Так как, если понятие не относится к курсу, но затрагивается задачей, то мы должны дать его определение, достаточное для понимания, и записать его в соответствующий индекс. При этом единственным связанным с этим понятием методическим материалом будет соответствующая задача.
5.1.3.3 Наследование
Наследование документов предметной области реализовано через соподчинение посредством интерфейс-индекса. Соподчинение документов предполагает фиксирование порядка подчинения двух документов. В головном документе представляется разрабатывающаяся цель обучения. Подчиненный документ, не разрабатывающийся специально для данной цели обучения, должен быть соподчинен цели головного документа. Соподчинение распространятся на совокупность документов. Фактически оно реализовано «прикреплением» СЕТов соподчиненного документа головному в соответствующее место оглавления или индекса. Очевидно, что при такой схеме реализуемо:
· соподчинение одного многим;
· соподчинение многих одному;
· частичная транзитивность – если С соподчинен В, а В соподчинен А, то С частично соподчинен А;
Полная транзитивность возникает когда все СЕТы В соподчинены А, и все СЕТы С соподчинены В.
Наследование реализованное через интерфейс-индекс не разрушает структуру документов, сохраняя их взаимную независимость
Учащийся - адаптивность ПО
Метод ГРОМ является развитием педагогического метода РО (развивающее обучение) по В. В. Давыдову. Его позиция: в предмете – нацеленность на теорию (мы ее разделяем); в учащемся – нацеленность на эфемерную творческую составляющую (мы ее уточняем). Главное, РО отказывается от профессионально-директивного обучения в пользу теоретического, которое влечет как повышенные требования к учащемуся, так ряд требований к материалу, основным из которых является адаптивность (персонификация).
Важным фактором при адаптации предметной области является интеллектуальное состояние учащегося. Понятия, которые по логике предмета или на взгляд автора курса являются равноценными, с точки зрения учащегося могут (и будут) отличаться по сложности восприятия, и наоборот. Частично на это влияет объективная сложность материала, частично – незнание понятий упоминаемых в материале. Таким образом, в системе выделяются два различных (ортогональных) метода оценки материала по отношению к учащимся. Это близость и сложность. Близость материала это количественная, и, соответственно, в достаточной степени объективная оценка материала, измеряемая процентом известных учащемуся понятий из числа встречающихся в материале. Сложность более субъективная оценка, в большей степени зависящая от мнения человека помещающего материал в систему. На использовании этих двух оценок, с возможностью их последующего уточнения, основывается адаптация предметной области в системе FLINT. Важным, для характеризации материала по близости и сложности, являются априорные классы учащихся.
5.1.4 Иерархия на однородности
Первое, что происходит при действиях учащегося в системе, это возникновение иерархии на однородном материале.
На уровне документов однородными считались слои авторских курсов, учебников и задачников. Но, с точки зрения учащегося, в одних документах знакомого материала (понятий) больше, в других меньше. В одних курсах изложение материала проще, а в других нет. Отсюда вытекает иерархия документов, причем, вначале идет «сортировка» по близости, а потом полученное – по сложности. Что на языке формул выражается как Сложность (Близость (Документы)).
В рамках одного документа главенствует близость, так менее знакомые понятия в индексе ставятся выше более знакомых учащемуся понятий. Незнакомое понятие объясняется через известный материал того же уровня, в рамках минимального покрывающего уровень поддерева индекса.
Структурные единицы текста могут сортироваться как по близости, так и по сложности излагаемого материала, в зависимости от решаемых задач и типа, к которому относится структурная единица текста.
5.1.5 Факторизация
В процессе обучения, интеллект учащегося прогрессирует, и ему становится безразлична иерархия на уже изученном материале. А зачастую, слишком глубокая иерархия может мешать учащемуся быстро «освежить» в памяти материал, изложенный в соответствующем месте предметной области. В таких случаях система производит факторизацию материала, отбрасывая ветви соответствующего поддерева индекса и оставляя лишь вершину. Это возможно, если потребовать, чтобы вышележащий в иерархии индекса (оглавления) СЕТ являлся обобщением нижележащего материала с обязательным требованием концептуальности изложения.
5.1.6 Маршрутизация
Метод ГРОМ, в первую очередь, ориентирован на учащегося, на оказание помощи в освоении материала и на максимальную адаптацию материала под текущее интеллектуальное состояние учащегося. При построении учебного процесса не от логики предмета, стоят две основные проблемы. Первая – выбор следующего понятия для изучения, которое не только будет потенциально понимаемо учащимся, но и будет продвигать его на предмете, обеспечивая интеллектуальное взросление. И вторая – «подтаскивать» учащемуся материал из уже изученного, который необходим ему для понимания изучаемого в данный момент. Предоставление соответствующего материала и называется маршрутизацией. Первый случай называется маршрутизацией вверх, так как если посмотреть на структуру учебного курса, то вверху будет понятие-цель, к которому необходимо продвигать учащегося. Второй случай – маршрутизация вниз.
5.1.6.1 Маршрутизация вниз
Наилучшим материалом для обеспечения понимания являются примеры и задачи. В методе ГРОМ особое место занимают пример-проблемы, это задачи, которые благодаря богатству межпредметных связей внутри себя, обеспечивают концептуальное видение учащимся предмета либо его части. Пример-проблемы распадаются на более частные задачи, которые и рассматриваются как искомый материал. В идеале, для каждого понятия, существенного в рамках курса, должна существовать пример-проблема. При этом задачи, связанные с ней, должны быть вынесены за приделы курса в авторские учебники и задачники. Таким образом, поиск примера к понятию происходит по следующему алгоритму, вначале, по понятию ищется связанная с ним пример-проблема, далее, по индексу примеров, выбираются все задачи связанные с этой пример-проблемой.
По задачи находим СЕТы авторского курса, с которыми она связана, далее по интерфейс-индексу выходим на СЕТы учебного курса. Последовательность - СЕТы учебного курса, СЕТы авторского курса, авторская задача - является маршрутом вниз. Из полученного множества маршрутов делается выборка по близости. Но за учащимся остается право выбора любого другого из найденных – мы не заставляем, мы только помогаем.
5.1.6.2 Маршрутизация вверх
В отличие от маршрутизации вниз, целью которой является пояснение материала, маршрутизация вверх занимается обучением, предоставляя не пример, а новое понятие. Маршрут вверх должен обеспечивать интеллектуальный рост и развитие учащегося, реализуемое не за счет усложнения материала из изученных областей, а за счет подбора нового материала максимального уровня сложности, который он сможет понять.
Как и в маршрутизации вниз, важнейшую роль играют примеры (задачи). Маршрут вверх начинается там, где закончился маршрут вниз, и возвращает учащегося наверх. Ситуация, когда маршрут увел учащегося в сторону от изучаемого материала на предметной области, является нормальной и не противоречащей логике системы и методу ГРОМ.
Итак, алгоритм построения маршрутов вверх следующий:
· маршруты вниз дали задачи;
· задачи дали набор понятий, либо в своей формулировке, либо в решении;
· по набору понятий берется обобщающая задача для полученных;
· в свою очередь, задачи верхнего уровня завязаны с искомыми новыми понятиями; новые понятия либо встречаются в задаче, либо являются началами маршрутов вниз, проходящих через эту задачу.
Из алгоритма следует необходимость введения дополнительного индекса задач, где вышележащие будут концептуальным обобщением ниже лежащих. Очевидно, что вверху нового индекса будут находиться пример-проблемы, а внизу лежать максимально частные (конкретные) задачи. Структура этого индекса представлена на сх.6 .
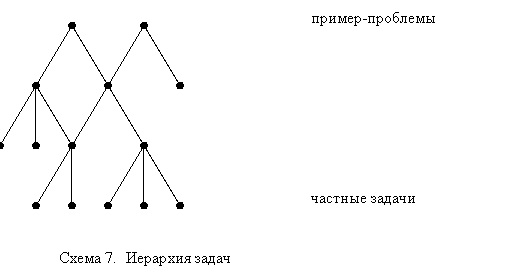
Фактически, маршрут вверх дает набор понятий для последующего изучения. Среди понятий, будут как понятия изучаемой области, так и далекие от неё. Учащемуся будут предоставляться все из найденных целей дальнейшего обучения, отсортированных по сложности материала. Слишком сложный или слишком легкий материал будет предлагаться позже. Маршрут, ведущей учащегося обратно к уже изученному материалу, будет отбрасываться как ошибочный.
Структура базы данных
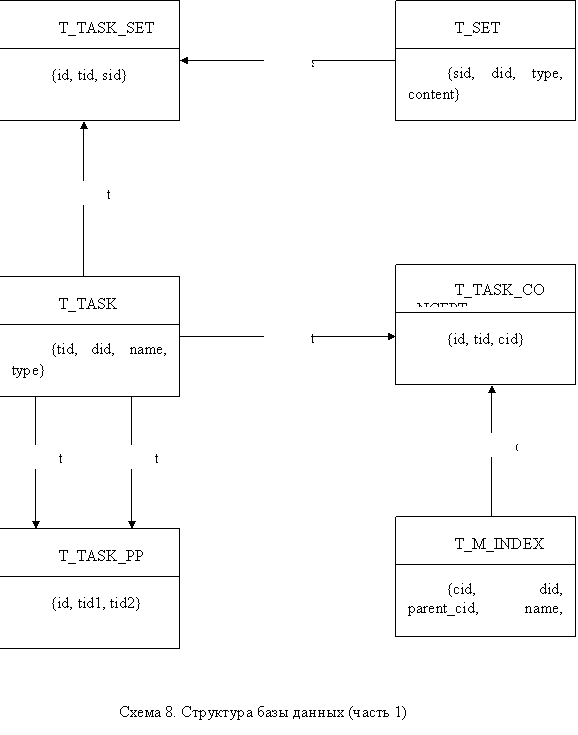
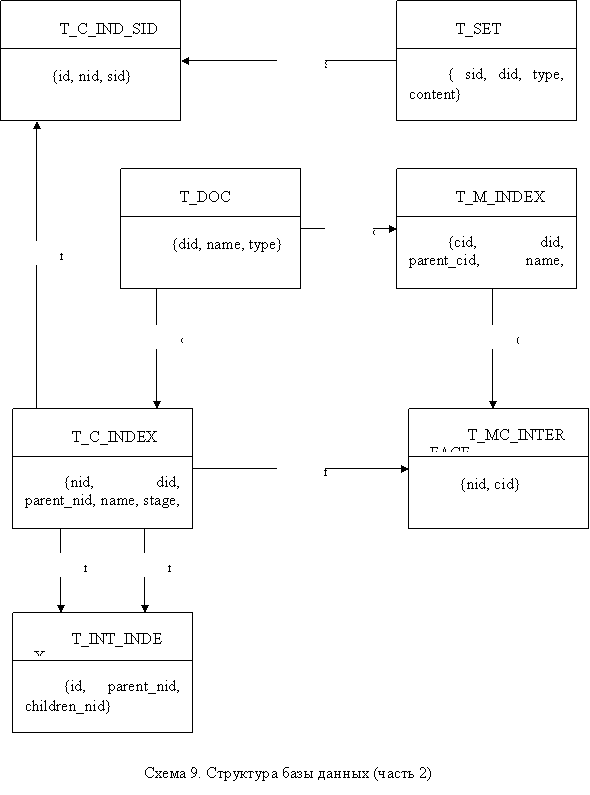
В основу демонстрационного прототипа положена БД Oracle. С ее помощью задаются все основные связи внутренних компонентов системы. Вот схематическое устройство взаимосвязи основных таблиц БД:

6 Визуализация - демонстрационный прототип
Адаптивность
Вход в систему традиционный - вводим имя пользователя и пароль. Авторизация происходит в соответствии с содержанием таблицы T_USER={usid, login, password, name, amu}, где usid - уникальный идентификатор пользователя, а login и password – его логин и пароль соответственно.

Рис. 1 Вход в систему
Окно системы разделено на 2 фрейма: левый HTML-фрейм содержит в себе главный индекс понятий, и ссылку «История», а правый VRML-фрейм изображает индекс-оглавление учебного курса. Содержание фрейма индекса-оглавления зависит от профиля пользователя. Адаптация осуществляется в соответствии с содержанием таблицы T_USER_VIEW={id, usid, nid, status}, usid - уникальный идентификатор пользователя, nid - идентификатор узла индекса-оглавления, status - его статус для данного пользователя (видимый или невидимый). Нажав кнопку «Pan» VRML-браузера (в данном случае мы используем Cortona VRML-browser), и, используя левую клавишу мыши, мы можем осуществлять навигацию по индексу-оглавлению.
При нажатии левой клавиши мыши на VRML-узле всплывает окно, позволяющее:
· скрыть для себя данный узел, а также все узлы поддерева, корнем, которого он является;
· развернуть данный узел, т. е сделать видимыми все узлы поддерева, корнем, которого он является;
· показать содержимое узла.
Рассмотрим поподробней третью возможность. Структура дерева индекса оглавления хранится в таблице T_C_INDEX={nid, did, parent_nid, name, stage, full_name}, где nid - идентификатор узла индекса-оглавления, did – идентификатор документа, parent_nid - идентификатор родительского узла индекса-оглавления (используется для построения дерева), name и full_name – имена узла (первое изображается рядом с узлом, второе всплывает, как подсказка при наведении мыши), stage – уровень узла. В таблице T_SET={sid, did, type, content} хранятся структурные единицы текста (сеты). sid здесь – уникальный идентификатор сета, did – идентификатор документа, type – тип сета (понятие, задача, пример-проблема), content – ссылка на html-файл, лежащий на сервере и содержащий данный сет. Взаимосвязь индекса-оглавления и сетов осуществляется посредством таблицы T_IND_SID={nid, sid}. Одному узлу может соответствовать несколько сетов, что и отражается в этой таблице.
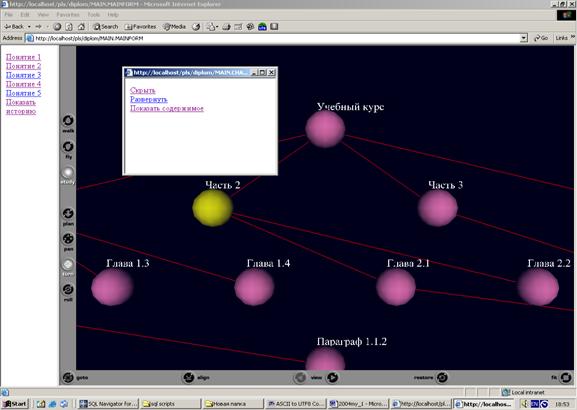
Рис. 2 Адаптивность
Итак, по нажатию ссылки «Показать содержимое», происходит выборка сетов данного узла из выше рассмотренных таблиц и отображение их в новых отдельных окнах. В этот момент, в таблицу T_HIST_NID={hid, usid, nid, hist_date} вносится строка, отражающая, что данный пользователь просмотрел данный узел в настоящее время. В дальнейшем, по нажатию ссылки «История», система подсвечивает голубым цветом все узлы, посещенные пользователем на всем протяжении его обучения.
Реализация маршрутизации вниз
Из левого фрейма щелчком по названию мы можем выбрать от 1 до 3 понятий, которые будут являться целью сеанса в обучающей системе. Далее появляется экран, в котором можно либо выбрать еще понятие, либо попросить выдать маршруты по уже выбранным. В случае выбора второго варианта, производится поиск узлов оглавления, в которых встречаются данные понятия. Соответствие устанавливается с помощью таблицы T_MC_INTERFACE={nid, cid}, где nid - уникальный идентификатор узла, cid - уникальный идентификатор понятия. Выбранные узлы помечаются синим цветом. Далее происходит выборка пример-проблем, соответствующих данным понятиям, при помощи таблицы T_TASK_CONCEPT={id, tid, cid}, где tid - уникальный идентификатор задачи, cid - уникальный идентификатор понятия. Открываются сеты выбранных пример – проблем. Выполняется это, на основании информации, содержащейся в таблице T_TASK_SET={id, tid, sid}, где tid - уникальный идентификатор задачи, sid - уникальный идентификатор сета. Между пример – проблемами и задачами авторского курса существует взаимосвязь, отраженная в индексе пример - проблем (таблица T_TASK_PP={id, tid1, tid2}. Задачи же эти, в свою очередь, связаны с главным индексом понятий авторского курса (также при помощи таблицы T_TASK_CONCEPT). И наконец, понятия встречаются в различных узлах оглавления. В результате мы получаем 2 множества узлов: узлы учебного курса и авторского курса, причем второе получено при помощи межпредметных связей. Хранятся они во временной таблице nids={id, nid, did}
Следующий этап – это генерация возможных маршрутов. PL/SQL-процедура Create_Routes по таблице nids формирует T_ROUTES, где заданы все возможные пути от узлов учебного курса до узлов авторского. Причем, связь между двумя курсами задается при помощи интерфейса индексов (таблица T_INT_INDEX={id, parent_nid, children_nid}). Также учитывается динамическая модель ПО конкретного учащегося и, если он скрыл некоторые узлы в системе, то маршруты, проходящие через них не отображаются. В левом HTML-фрейме появляются ссылки вида «Маршрут 1», «Маршрут 2» и т. д. При щелчке на любой из них, данный путь подсвечивается синим цветом, и при помощи стрелок внизу панели VRML-браузера мы можем перемещаться от узла.
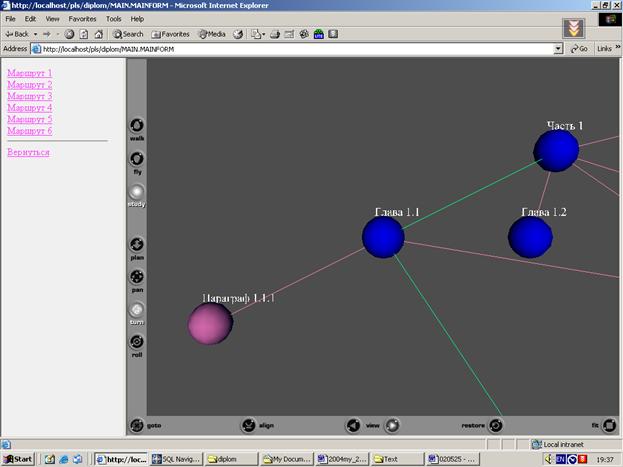
Рис. 3 Маршрутизация
7 Результаты и перспективы
Выбрана интегрированная среда разработки, обеспечивающая эффективное взаимодействие: реляционной базы данных Oracle, web-сервера Apache, графической визуализации формата VRML и гипертекстовой визуализации HTML.
В интегрированной среде реализован демонстрационный прототип визуализации учебного материала для метода обучения ГРОМ. Визуализация поддерживает учебную деятельность на межпредметных связях посредством:
· предъявления интегрированной картины состояния учащегося;
· предъявления маршрутов движения по учебному материалу на основе целей учащегося;
· предъявления операций по управлению учащимся учебным курсом (скрыть поддерево, поднять-опустить поддерево по структуре).
Перспектива работы состоит в проверке жизнеспособности демонстрационного прототипа на реальном учебном курсе. Для этого следует:
· обогатить реализованные операции в соответствии с методом ГРОМ;
· дополнительно реализовать необходимые операции, интегрирующие историю деятельности учащегося для улучшения адаптивности маршрутизации.
8 Благодарности
Автор глубоко признателен научному руководителю Громыко В. И., в непосредственном контакте с ним выполнена эта работа.
В дипломной работе использованы в качестве учебных материалов многие учебники [E]. Их авторам, – любезно позволившими ими воспользоваться, – M. Broy, B. Rumpe, , АА Никитину, , – наша (и научного руководителя) сердечная благодарность.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
