Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Тема 6. Многомерные индексы.
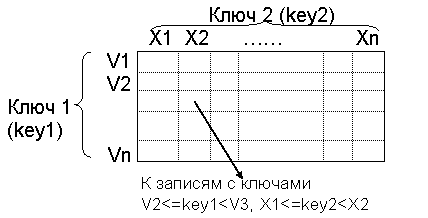
Проблема – как эффективно осуществлять поиск кортежей по двум и более условиям.
Пример. Ключ – комбинация полей F1 и F2. Пусть F1 – строка, F2 –число. Составной ключ индекса – конкатенация полей с использованием разделителя, например, ‘#’. Тогда, если F1=”abcd”, F2=23, то значение ключа индекса “abcd#23”.
Проблема 1. Сортировка в индексе по ключу – нет уверенности, что кортежи с одинаковыми значениями F1 или F2 будут находиться рядом.
Проблема 2. При использовании хэш – структур требуется знать полный ключ.
В обоих случаях нет возможности эффективного поиска по одному из ключевых атрибутов.
Решение – построение многомерных индексов.
Основные приложения – географические системы информации.
Типы запросов.
Запросы по одному из ключевых атрибутов. Запросы с диапазоном значений. Запросы на ближайшего соседа. Запросы типа «Где я нахожусь?».Как реализовать такие запросы на SQL?
1. Требуется найти ближайшего соседа точки (10,20) в двумерном пространстве. Точки представлены отношением:
Points (x, y).
SELECT * FROM Points p WHERE NOT EXIST
( SELECT * FROM Points q WHERE (q. x-10)*(q. x-10)+(q. y-20)*(q. y-20)<
(p. x-10)*(p. x-10)+(p. y-20)*(p. y-20) )
2. Выполнить запрос типа «Где я нахожусь?», если объекты хранения – прямоугольники.
Отношение – Rectangles(id, xl, yl, xr, yr).
Требуется найти прямоугольник(и), в котором(ых) находится точка (10,20).
SELECT id FROM Rectangles WHERE xl<=10 AND xr>=10 AND yl<=20 AND yr>=20
Использование обычных индексов.
1. Запросы с диапазоном значений.
Пусть есть два индекса типа В-дерева по каждому из атрибутов пространства x и y.
Пусть имеется набор 1 000 000 точек, распределенных случайным образом на множестве 0 £ x £ 1 000, 0 £ y £ 1 000. Пусть 100 точек помещается в 1 блок, 200 пар «ключ - указатель» помещаются в листовом блоке В-дерева.
В запросе указан диапазон: 450 < x £ 550, 450 < y £ 550.
Используя В-дерево по атрибуту x, получим около 100 000 точек по первому условию.
Используя В-дерево по атрибуту y, получим около 100 000 точек по второму условию.
Примерно 10 000 точек принадлежит пересечению этих множеств.
Заметим, что количество уровней В-дерева – 3. Допустим, что корень находится в оперативной памяти.
Количество операций ввода/ вывода = 2*501 (для чтения блоков индексов: 500 листовых узлов + 1 промежуточный узел) + 10 000 (блоков файла данных, если записи распределены случайным образом) = 11 002 оп. вв/выв.
Для хранения всего файла требуется 1 000 000 / 100 = 10 000 блоков.
Количество операций ввода/вывода при простом сканировании файла = 10 000 оп. вв/выв.
Таким образом, использование индекса не дает никаких преимуществ.
2. Запрос на ближайшего соседа.
Алгоритм – установка диапазона, выбор ближайшей точки внутри диапазона.
2 проблемы:
1. В диапазоне нет точек.
2. Ближайшая точка диапазона может оказаться не ближайшей точкой вообще.

В обоих случаях требуется расширять диапазон и производить все действия заново.
Виды многомерных индексов.
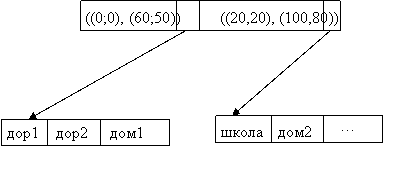
Сеточные файлы.Пространство точек (по двум атрибутам) разделяется сеткой. Сетка делит пространство на части, под каждую из которых выделяется сегмент хэш – структуры.
В данном примере будет 9 сегментов хэш – структуры.
Хранение кортежей организовано по схеме:

Если в блоке данных нет места, требуется добавить новую линию разбиения, увеличив хэш – структуру.
Проблема – быстрое увеличение количество сегментов хэш – структуры, причем многие сегменты могут указывать на пустые блоки данных.
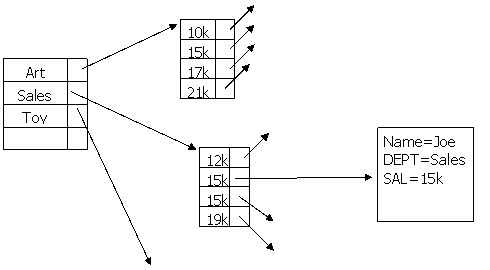
Хэш – разбиения.

Пример.
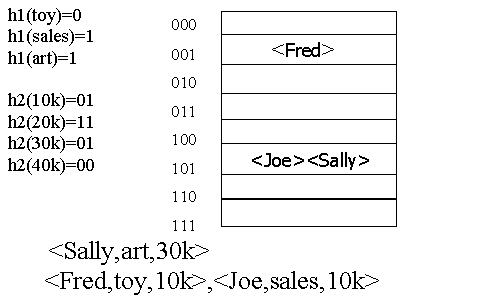

Индекс по первому атрибуту приводит к индексу по второму атрибуту, а уже тот приводит к файлу данных.

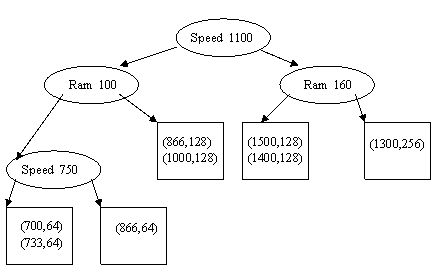
4. KD –дерево. – двоичное несбалансированное дерево, в котором внутренние узлы дерева соответствуют последовательно то одному, то другому атрибуту.

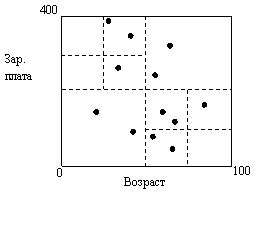
5. Квадратичные деревья.
Каждый внутренний узел соответствует «кубической» области. Если число точек в «кубе» меньше, чем помещается в блок, то этот «куб» трактуется как листовой блок. В противном случае «куб» делится на 4 равные части.

Дерево строится следующим образом:
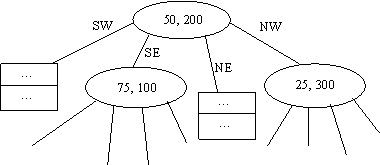

6. R-деревья – деревья регионов – наиболее часто используются в географических системах информации.
Во внутренних узлах некоторая прямоугольная область, которая может как содержать данные, так и не содержать их. Далее эти области можно разбивать. Листовые блоки хранят записи об объектах, находящихся в заданных регионах.