

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
![]() На правах рукописи
На правах рукописи
_________________
ХА ТИ ЧУНГ
РАЗРАБОТКА И ИССЛЕДОВАНИЕ МЕТОДОВ ПОСТРОЕНИЯ АТРИБУТНОГО ТЕМАТИЧЕСКОГО КЛАССИФИКАТОРА ДОКУМЕНТОВ
Специальность: 05.13.17 — Теоретические основы информатики.
АВТОРЕФЕРАТ
диссертации на соискание учёной степени
кандидата технических наук
Таганрог – 2009
Работа выполнена в Технологическом институте Южного федерального университета в г. Таганроге.
НАУЧНЫЙ РУКОВОДИТЕЛЬ:
доктор технических наук, профессор
ОФИЦИАЛЬНЫЕ ОППОНЕНТЫ:
доктор технических наук, профессор,
;
кандидат технических наук,
.
ВЕДУЩАЯ ОРГАНИЗАЦИЯ:
им. » г. Таганрог.
Защита диссертации состоится « 26 » июня 2009 г. в 14-20 на заседании диссертационного совета (Д 212.208.21) при Южном федеральном университете по адресу: 347928 г. Таганрог, пер. Некрасовский, 44, ауд. Д-406.
С диссертацией можно ознакомиться в Зональной научной библиотеке ЮФУ по адресу: г. Ростов-на-Дону, ул. Пушкинская, 148.
Автореферат разослан «___» мая 2009г.
 Ученый секретарь
Ученый секретарь
диссертационного совета Д 212.208.21,
доктор технических наук, профессор
ОБЩАЯ ХАРАКТЕРИСТИКА РАБОТЫ
Актуальность темы. В настоящее время объем электронных изданий и документов в интернет, локальных сетях, электронных библиотеках, электронных каталогах и др. по некоторым оценкам удваивается каждый год. Однако ограниченные возможности инструментариев поиска и классифицирования информации существенно затрудняют пользователю доступ к релевантной его запросам информации. Проблема разработки эффективных подходов тематической классификации документов стала сегодня объектом серьезных исследований. Для решения этой проблемы были разработаны и предложены ряд подходов, связанных с выделением и извлечением информационных объектов, определением их статистических, лингвистических и семантических характеристик, построением семантико-тематической структуры документов и тематик, тематической фильтрацией и пр. Этой проблеме также посвящен ряд международных научных конференций и семинаров.
Как показывает анализ подходов в области классификации документов, каждый из них обладает определенными достоинствами и недостатками, а также областью эффективного использования. Однако, ни в одном из этих методов для повышения эффективности классификации не используется явное выделение функциональных областей в документах. В то же время, использование разнородной информации из данных областей может существенно улучшить результаты классификации документов. Поэтому, несмотря на то, что существует много работ по тематической классификации, на сегодня в общем виде данная проблема до сих пор еще не решена. Таким образом, разработка методов и систем автоматической тематической классификации документов остается одной из актуальных проблем в области информатики и имеет как теоретическую, так и практическую значимость.
Настоящее диссертационное исследование выполнено в рамках данной проблематики и направлено на разработку и исследование моделей и методов атрибутной тематической классификации документов.
Объект исследований. Методы построения атрибутного тематического классификатора документов.
Цели и задачи работы. Разработка и исследование методов построения атрибутного тематического классификатора документов.
Для достижения поставленной цели исследования были решены следующие основные задачи:
1. Построение и исследование моделей атрибутного описания документов и тематик, отличающихся от известных моделей тем, что традиционная совокупность классификационных признаков дополнена атрибутными функциональными характеристиками.
2. Разработка способов построения классифицирующей функции на основе частичных функций близости атрибутных множеств документов и тематик.
3. Разработка методов построения обучающих выборок, методов обучения и настройки атрибутного классификатора для тематической классификации документов.
4. Построение программной модели для экспериментального исследования атрибутного классификатора и апробации теоретических выводов результатов.
5. Проведение экспериментального моделирования и исследования разработанного атрибутного классификатора.
Методы исследования. Для решения выше перечисленных задач использованы методы математического и комбинаторного анализов, методы нечеткой логики, методы оптимизации, методы статистического анализа, методы лингвистического анализа, технология программирования.
Научная новизна работы. Состоит в следующем:
1. Разработана модифицированная модель описания документа, которая отличаются от известных моделей тем, что наряду с описанием основного текста содержит ряд дополнительных атрибутов, таких как описания названия, авторов, аннотации, глоссарии и пр., а также таких атрибутов, как УДК, ISBN и пр., которые соответствуют данному типу документов.
2. Разработана модифицированная модель описания тематики, атрибутивно согласованная с предложенной моделью описания документа, что позволяет устанавливать между документами и тематиками степень близости по однотипным атрибутам описаний.
3. Разработана классифицирующая функция на основе частичных функций близости по типу “текст”↔“текст”, “текст”↔“экспертное знание”, “экспертное знание”↔“экспертное знание”, “описательные атрибуты”↔“описательные атрибуты”, которая в отличие от известных позволяет учитывать информацию из дополнительных атрибутов документов и тематик.
4. Сформулированы в виде лемм требования к структуре правильно построенной обучающей выборки, правила и процедура обучения классификатора путем настройки коэффициентов доверия и порогов классифицирующей функции в виде решения оптимизационной задачи и разработаны методики коррекции обучающей выборки, что позволяет организовать обучение и настройку разработанного атрибутного классификатора.
5. Предложено представлять классифицирующую функцию в виде лингвистической переменной, а построенные правила нечеткого логического вывода использовать для классификации, что позволяет существенно упростить переобучение атрибутного классификатора путем коррекции нечетких переменных и/или правил логического вывода.
Основные положения, выносимые на защиту. На защиту выносятся следующие научные положения и результаты, полученные в диссертационном исследовании:
1. Атрибутные модели описания документа и тематики.
2. Классифицирующая функция на основе частичных функций близости по типу “текст”↔“текст”, “текст”↔“экспертное знание”, “экспертное знание”↔“экспертное знание” и “описательные атрибуты”↔“описательные атрибуты”.
3. Методы построения правильной обучающей выборки, правила и процедура обучения классификатора путем настройки коэффициентов доверия и порогов классифицирующей функции в виде решения оптимизационной задачи, методика коррекции обучающей выборки на основе решения оптимизационной задачи.
4. Представление классифицирующей функции в виде лингвистической переменной и системы правил нечеткого логического вывода.
Теоретическая и практическая значимость результатов исследования.
1. Разработанная модифицированная модель описания документа позволяет наряду с характеристиками основного текста включить в описание документа информацию из дополнительных функциональных областей (атрибутов) таких, как названия, авторы, аннотация, глоссарий, УДК, ISBN и пр., которые соответствуют данному типу документов.
2. Разработанная модифицированная модель описания тематики атрибутивно согласована с предложенной моделью описания документа и позволяет устанавливать между документами и тематиками степень близости по однотипным атрибутам описаний.
3. Разработанная классифицирующая функция на основе частичных функций близости по типу “текст”↔“текст”, “текст”↔“экспертное знание”, “экспертное знание”↔“экспертное знание”, “описательные атрибуты”↔“описательные атрибуты” позволяет интегрально учитывать информацию из дополнительных атрибутов документов и тематик.
4. Сформулированные в виде лемм требования к структуре правильно построенной обучающей выборки, правила и процедура обучения классификатора путем настройки коэффициентов доверия и порогов классифицирующей функции в виде решения оптимизационной задачи, а также разработанные методики коррекции обучающей выборки позволяют организовать обучение и настройку разработанного атрибутного классификатора.
5. Разработанное представление классифицирующей функции в виде лингвистической переменной и построенные правила нечеткого логического вывода позволяют существенно упростить переобучение атрибутного классификатора путем коррекции нечетких переменных и/или правил логического вывода.
Разработанные методы, способы и алгоритмы дополняют существующие теоретические разработки в данной области и подтверждают их теоретическую значимость, а их практическая значимость подтверждается результатами экспериментального моделирования и возможностью их применения в системах информационного поиска документов, электронных библиотеках и библиотеках различных учреждений.
Достоверность результатов. Вытекает из их математического обоснования, корректного использования методов математического и комбинаторного анализов, нечеткой логики, оптимизации, статистического и лингвистического анализов, технологии программирования, а также подтверждается результатами проведенных модельных экспериментов.
Использование результатов работы. Результаты диссертационного исследования используются в ряде работ, выполненных в международной лаборатории ELDIC, и в учебном процессе, что подтверждается актами о внедрении результатов исследования в рамках работ по госбюджетной НИР № 000 “Исследование и разработка гибридных логико-математических и нечетко-лингвистических моделей задач искусственного интеллекта, информационного поиска и распознавания образов” и учебном процессе по дисциплине “Организация электронных архивов данных” магистерской программы “Интеллектуальные системы” по направлению 230100 “Информатика и вычислительная техника” факультета автоматики и вычислительной техники Таганрогского технологического института Южного федерального университета.
Апробация результатов работы. Основные результаты работы неоднократно докладывались и обсуждались на конференциях и семинарах различного уровня, в том числе:
- VIII Всероссийской научной конференции студентов и аспирантов "Техническая кибернетика, радиоэлектроника и системы управления (КРЭС'06)" (Таганрог, ТРТУ, 2006г);
- Всероссийской научной школе-семинаре молодых ученых, аспирантов и студентов "Интеллектуализация информационного поиска, скантехнологии и электронные библиотеки" (Таганрог, ТТИ ЮФУ, 2007г);
- Всероссийской научной школе-семинаре молодых ученых, аспирантов и студентов "Интеллектуализация информационного поиска, скантехнологии и электронные библиотеки" (Таганрог, ТТИ ЮФУ, 2008г);
- VI Всероссийской научной конференции молодых ученых, аспирантов и студентов "Информационные технологии, системы анализ и управление" (Таганрог, ТТИ ЮФУ, 04-05 декабря 2008г).
Публикации. По материалам диссертации автором опубликовано 7 печатных работ, в том числе одна статья в издании из списка, рекомендованного ВАК, в которых отражены основные результаты диссертационного исследования.
Структура и объем работы. Диссертация состоит из введения, четырех глав, заключения и приложений. Текст изложен на 136 страницах, содержит 24 рисунков, 13 таблицы, список литературы из 75 наименований.
КРАТКОЕ СОДЕРЖАНИЕ РАБОТЫ.
Во введении показана и обоснована актуальность темы диссертационного исследования, показана существующая степень разработки проблемы, сформулированы цель и задачи исследования, сформулированы положения и результаты, выносимые на защиту, определены научная новизна и практическая значимость результатов исследования, приведены данные об апробации и использовании научных результатов, о публикациях и структуре диссертационной работы.
В первой главе определены основные понятия и терминология, используемая в диссертационном исследовании, проведен анализ существующих подходов в области классификации, таких как вероятностный, векторный, и комбинированный. Рассмотрены и проанализированы такие методы тематической классификации как статистические Байесовские, k-ближайших соседей, центроидные, нейронные сети, логические, гибридные и пр., а также проанализированы используемые в них математические модели описания документов, тематик, классифицирующих функций. В результате этого анализа определено место атрибутной классификации среди этих методов и отобран математический инструментарий для целей диссертационного исследования.
Во второй главе разрабатываются модели описания документов и тематик, которые учитывают не только основное текстовое содержания документа, но и ряд его дополнительных атрибутов, характерных для данного рода документов.
Документ представляется в виде основного текста, составляющего его семантическую сущность, а также некоторой дополнительной информации, которая определяет стандартизированный формат, способ составления и оформления документов данного вида. Например, книга кроме основного текста содержит название, описание авторов, оглавление, аннотацию, список литературы и пр., а также такие атрибуты как ISBN, УДК и пр. Также свои форматы имеют научные статьи, научно-технические отчеты и т. п. Учитывая все это, модель описания документа представляется в виде: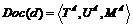 , где
, где ![]() ,
, ![]() и
и ![]() - атрибутные множества. Здесь множество
- атрибутные множества. Здесь множество ![]() создается на основе термов тела документа (
создается на основе термов тела документа (![]() - терм,
- терм, ![]() - встречаемость терма,
- встречаемость терма, ![]() - важность терма). Множество
- важность терма). Множество ![]() представляет термы
представляет термы ![]() из дополнительных областей и их важность
из дополнительных областей и их важность 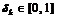 для данного документа. Множество
для данного документа. Множество ![]() представляет индивидуализированные атрибуты, где
представляет индивидуализированные атрибуты, где ![]() - тип,
- тип, ![]() - значение ,
- значение , ![]() - важность соответственно.
- важность соответственно.
Описание тематики 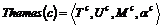 атрибутивно согласовано с описаниями документов, формируется на основе обучающей выборки (ОВ) и экспертного знания. Множество
атрибутивно согласовано с описаниями документов, формируется на основе обучающей выборки (ОВ) и экспертного знания. Множество ![]() формируется классификатором из термов
формируется классификатором из термов ![]() текстов документов вместе с характеристиками встречаемости
текстов документов вместе с характеристиками встречаемости ![]() и
и 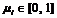 - степени важности
- степени важности ![]() для тематики. Множество
для тематики. Множество ![]() формируется классификатором и уточняется экспертами. Здесь
формируется классификатором и уточняется экспертами. Здесь ![]() - характеристические термы тематики,
- характеристические термы тематики, ![]() - важность терма
- важность терма ![]() в тематике
в тематике ![]() . Множество
. Множество ![]() представляет характерные описательные атрибуты тематики, аналогичные документам.
представляет характерные описательные атрибуты тематики, аналогичные документам. ![]() - пороговое значение атрибутной классифицирующей функции (АКФ). Если значение АКФ больше
- пороговое значение атрибутной классифицирующей функции (АКФ). Если значение АКФ больше ![]() , то документ относится к тематике
, то документ относится к тематике ![]() , в противном случае - нет.
, в противном случае - нет.
Процедура формирования описания тематики имеет следующий вид:
1. Эксперты формируют наименование тематики;
2. Эксперты формируют часть элементов множества ![]() .
.
3. Эксперты формируют часть ![]() ;
;
4. Эксперты формируют ОВ;
5. Классификатор по ОВ строит множества ![]() и доопределяет множество
и доопределяет множество ![]() ;
;
6. В процессе настройки и обучения классификатор определяет ![]() для АКФ.
для АКФ.
В третьей главе разработаны модели атрибутной классифицирующей функции, проведен их анализ, а также сконструированы алгоритмы настройки и обучения атрибутного классификатора.
Построение АКФ связано с определением для каждой пары ![]() функции вида
функции вида ![]() , где
, где ![]() - частичная функция близости (ЧФБ) документа тематике. Здесь
- частичная функция близости (ЧФБ) документа тематике. Здесь 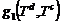 имеет тип “текст”↔“текст”;
имеет тип “текст”↔“текст”; ![]() - “текст”↔“экспертное знание”;
- “текст”↔“экспертное знание”; 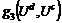 - “экспертное знание”↔“экспертное знание”;
- “экспертное знание”↔“экспертное знание”; ![]() - “описательные атрибуты”↔“описательные атрибуты”. Таким образом, АКФ учитывает все атрибутные множества документов и тематик.
- “описательные атрибуты”↔“описательные атрибуты”. Таким образом, АКФ учитывает все атрибутные множества документов и тематик.
Конструкцию ![]() АКФ определим в виде линейной суммы частичных функций близости и учтем роли каждой из них коэффициентами доверия
АКФ определим в виде линейной суммы частичных функций близости и учтем роли каждой из них коэффициентами доверия ![]() ,
,![]() ,
,![]() ,
,![]() . Тогда данное представление АКФ
. Тогда данное представление АКФ ![]() имеет вид:
имеет вид:
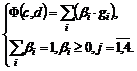 (1)
(1)
Значение правильно настроенной АКФ имеет максимум только на соответствующей документу тематике, при этом значение АКФ должно превысить порог ![]() .
.
Определение 1. Классификатор, для которого установлены пороги ![]() , назовем базовым классификатором (БК).
, назовем базовым классификатором (БК).
Лемма 1. Для правильно построенного классификатора, если для документа ![]() и тематики
и тематики ![]() существует классифицирующая функция вида
существует классифицирующая функция вида ![]() , то всегда для данного документа любая другая классифицирующая функция
, то всегда для данного документа любая другая классифицирующая функция ![]() для всех
для всех ![]() .
.
Доказательство данной леммы вытекает из определения базового классификатора.
Лемма 2. В правильно построенной обучающей выборке ![]() для каждого документа
для каждого документа ![]() всегда существует одна и только одна классифицирующая функция вида
всегда существует одна и только одна классифицирующая функция вида 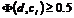 .
.
Доказательство данной леммы базируется на определении ОВ.
Данные леммы положены в основу процедуры построения обучающей выборки ![]() . Так, если лемма 1 не выполняется, то в ОВ некоторые документы относятся классификатором более чем к одной тематике. В этом случае необходимо уточнить описания документов и соответствующих тематик. Если не выполняется лемма 2, то ОВ содержит документы, термы которых не учтены в описаниях тематик. Коррекция: термы из документов либо учесть в описаниях тематик, либо документы удалить из ОВ.
. Так, если лемма 1 не выполняется, то в ОВ некоторые документы относятся классификатором более чем к одной тематике. В этом случае необходимо уточнить описания документов и соответствующих тематик. Если не выполняется лемма 2, то ОВ содержит документы, термы которых не учтены в описаниях тематик. Коррекция: термы из документов либо учесть в описаниях тематик, либо документы удалить из ОВ.
Пусть для документа ![]() и тематики
и тематики ![]() построены описания по рассмотренным атрибутным моделям. Тогда ЧФБ
построены описания по рассмотренным атрибутным моделям. Тогда ЧФБ ![]() представим в виде:
представим в виде:
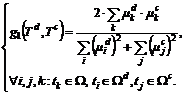 (2)
(2)
Здесь числитель представляет сумму произведений важностей общих для документа и тематики термов (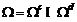 ), а знаменатель - сумму квадратов важностей всех термов (
), а знаменатель - сумму квадратов важностей всех термов (![]() и
и ![]() ) атрибутных множеств
) атрибутных множеств ![]() и
и ![]() соответственно.
соответственно.
По аналогии сформируем ЧБФ ![]() ,
, ![]() ,
, ![]() :
:
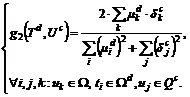 (3)
(3)
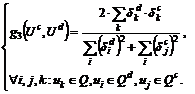 (4)
(4)
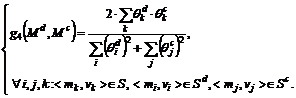 (5)
(5)
В диссертации показывается, что значения ЧБФ ![]() ,
,![]() ,
,![]() ,
,![]() нормализованы на интервале
нормализованы на интервале ![]() .
.
Для формирования описаний документов, используя алгоритмы извлечения термов, определяются множества 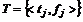 ,
, ![]() и
и 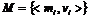 . Далее для каждого терма определяется его важность. Так, для множества
. Далее для каждого терма определяется его важность. Так, для множества ![]() важность представляется в виде:
важность представляется в виде:
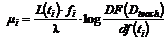 (6)
(6)
и учитывает количество слов ![]() в терме, среднюю длину
в терме, среднюю длину ![]() термов по данному документу, определяемую формулой
термов по данному документу, определяемую формулой 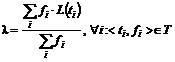 . Здесь
. Здесь 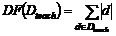 - количество документов обучающей выборки с учетом размера текста документов,
- количество документов обучающей выборки с учетом размера текста документов, ![]() - размер текста документа в числе термов,
- размер текста документа в числе термов, ![]() - количество термов в обучающих документах, в тексте которых встречается терм
- количество термов в обучающих документах, в тексте которых встречается терм ![]() .
.
Если использовать однословные термы и не учитывать размера текста документа в числе термов, то важность терма для документа приводится к известному в тематической классификации выражению ![]() .
.
В дальнейшем важность термов всегда будем нормализовать по типу ![]() , где
, где ![]() . Сокращение размерности множества
. Сокращение размерности множества ![]() осуществляется за счет удаления не характерных для данного документа слов и словосочетаний (стоп-термов, термов общего назначения и т. д.).
осуществляется за счет удаления не характерных для данного документа слов и словосочетаний (стоп-термов, термов общего назначения и т. д.).
Важность термов атрибутного множества ![]() определим через настраиваемый параметр
определим через настраиваемый параметр ![]() , который соответствует средней важности термов множества
, который соответствует средней важности термов множества ![]() . Пусть вначале
. Пусть вначале ![]() , где
, где 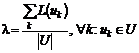 - средняя длина термов множества U, а
- средняя длина термов множества U, а ![]() - число слов в терме
- число слов в терме ![]() . Если терм
. Если терм ![]() встречается в
встречается в ![]() (
(![]() ), то повысить его важность
), то повысить его важность ![]() и удалить кортеж
и удалить кортеж ![]() из множества
из множества ![]() , в противном случае, снизить его важность
, в противном случае, снизить его важность 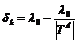 . После вычисления важностей всех термов множества U необходимо провести их нормализацию по типу
. После вычисления важностей всех термов множества U необходимо провести их нормализацию по типу 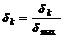 , где
, где ![]() максимальное значение из всех
максимальное значение из всех ![]() (
(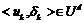 ).
).
При сравнении термов использован знак ![]() (
(![]() ), что означает идентичность термов
), что означает идентичность термов ![]() и
и ![]() . Понятие идентичности может быть расширено до термов-синонимов. В этом случае алгоритм также сохраняет работоспособность, однако необходимо включить в базу данных классификатора тематические словари и тезаурусы синонимов.
. Понятие идентичности может быть расширено до термов-синонимов. В этом случае алгоритм также сохраняет работоспособность, однако необходимо включить в базу данных классификатора тематические словари и тезаурусы синонимов.
Определение важности описательных атрибутов множества ![]() документа выполняется экспертами и служит для более тонкой настройки классификатора.
документа выполняется экспертами и служит для более тонкой настройки классификатора.
Формирование атрибутных множеств тематик классификатора выполняется по обучающей выборке и экспертной информации в соответствии с моделью описания тематики. Для этого вначале необходимо распределить документы по тематикам и построить ОВ вида 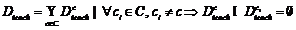 , где
, где ![]() - множество всех тематик. Далее задать экспертным путем степени близости документов тематикам
- множество всех тематик. Далее задать экспертным путем степени близости документов тематикам 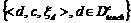 . Из практики желательно выполнение условие
. Из практики желательно выполнение условие ![]() .
.
Алгоритм подготовки атрибутных множеств термов ![]() ,
, ![]() и
и 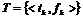 для тематики имеет вид:
для тематики имеет вид:
1. Для каждого обучающего документа ![]() определить множества
определить множества ![]() ,
, ![]() ,
, 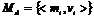 , Данные процедуры выполняются по аналогии формирования описания документа.
, Данные процедуры выполняются по аналогии формирования описания документа.
2. Для обучающей выборки тематики ![]() сформировать множество
сформировать множество ![]() по следующей формуле
по следующей формуле ![]() .
.
3. Для обучающей выборки тематики ![]() сформировать множество
сформировать множество ![]() по следующей формуле
по следующей формуле ![]() .
.
4. Предъявить экспертам для коррекции и пополнения множества ![]() и
и ![]() .
.
5. Сформировать объединенное множество ![]() , взяв для каждой пары
, взяв для каждой пары ![]() из всех множеств
из всех множеств ![]() , для которых
, для которых ![]() , а параметр
, а параметр ![]() в паре определить по формуле
в паре определить по формуле 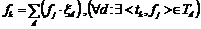 . Здесь под знаком суммы представлено произведение встречаемости терма
. Здесь под знаком суммы представлено произведение встречаемости терма ![]() в документе
в документе 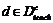 и важности
и важности ![]() документа
документа ![]() для тематики
для тематики ![]() .
.
Определение важности термов для атрибутного множества ![]() выполняется по аналогии с документами. Определение важности термов для множества
выполняется по аналогии с документами. Определение важности термов для множества ![]() не должно зависеть от частоты их встречаемости в тексте документов ОВ. Если важность не задана явно экспертами, то она определяется следующим образом.
не должно зависеть от частоты их встречаемости в тексте документов ОВ. Если важность не задана явно экспертами, то она определяется следующим образом.
Пусть 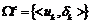 - множество термов, заданных экспертами, с их важностям. Если
- множество термов, заданных экспертами, с их важностям. Если ![]() , то
, то ![]() определяется как
определяется как ![]() . Если
. Если ![]() , то
, то 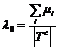 определяет среднюю важность термов множества
определяет среднюю важность термов множества ![]() .
.
Пусть в начале 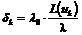 , где
, где 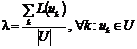 средняя длина термов множества U. Если терм
средняя длина термов множества U. Если терм ![]() встречается в
встречается в ![]() , то повысить его важность по формуле и удалить кортеж из , иначе снизить его важность по формуле . После того как важности всех термов множества U определены, необходимо провести нормализацию по типу , где - максимальное значение из всех
, то повысить его важность по формуле и удалить кортеж из , иначе снизить его важность по формуле . После того как важности всех термов множества U определены, необходимо провести нормализацию по типу , где - максимальное значение из всех ![]() (
(![]() ).
).
Определение важности описательных атрибутов множества ![]() выполняется только экспертным путем.
выполняется только экспертным путем.
После определения всех атрибутных множеств документов ОВ и тематик, выполняется настройка АКФ с целью максимизации порога ![]() путем подбора коэффициентов доверия
путем подбора коэффициентов доверия 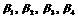 . Сформулированные правила регулирования коэффициентов доверия имеют следующий вид:
. Сформулированные правила регулирования коэффициентов доверия имеют следующий вид:
Правило 1. Если близость типа “экспертное знание”↔“экспертное знание” “высокая”, то повысить коэффициент доверия ![]() к ЧФБ
к ЧФБ ![]() и снизить коэффициенты доверия
и снизить коэффициенты доверия ![]() к ЧФБ
к ЧФБ ![]() и
и ![]() .
.
Правило 2. Если близость типа “экспертное знание”↔“экспертное знание” “средняя”, а близость типа “текст”↔“текст” “высокая”, то повысить коэффициенты доверия ![]() к ЧФБ по типу близости “текст”↔“текст” и “текст”↔“экспертное знание”.
к ЧФБ по типу близости “текст”↔“текст” и “текст”↔“экспертное знание”.
Правило 3. Если близость типа “экспертное знание”↔“экспертное знание” меньше “средняя”, то повысить коэффициент доверия ![]() к ЧФБ
к ЧФБ ![]() и
и ![]() .
.
Правило 4. Если близости типов “текст”↔“текст” и “текст”↔“экспертное знание” “низкая”, то увеличить коэффициенты доверия ![]() к ЧФБ
к ЧФБ ![]() .
.
Правило 5. При высоком значении близости типа “текст”↔“текст” увеличить коэффициент доверия ![]() к ЧФБ
к ЧФБ ![]() .
.
Пусть 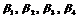 прямо пропорционально зависят от ЧФБ, тогда
прямо пропорционально зависят от ЧФБ, тогда ![]() , а АКФ имеет вид
, а АКФ имеет вид 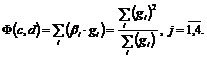 Из анализа следует, что значение АКФ сдвигается в ту сторону, где одна из ЧФБ принимает значение большее, чем другие ЧФБ. Цель – максимизация АКФ, т. е.
Из анализа следует, что значение АКФ сдвигается в ту сторону, где одна из ЧФБ принимает значение большее, чем другие ЧФБ. Цель – максимизация АКФ, т. е. ![]() .
.
Достижение данной цели сформулируем в виде оптимизационной задачи. Для этого вычислим значения всех ЧФБ документов ОВ и сформируем линейную систему уравнений, представленную ниже в векторной форме:
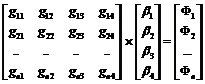 . (7)
. (7)
Наложим на (7) в соответствии с леммой 1 ограничения вида:
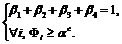 (8)
(8)
После введения ![]() дополнительных переменных
дополнительных переменных ![]() и
и ![]() получим следующие соотношения:
получим следующие соотношения:
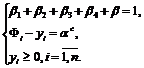
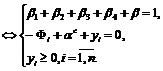 (9)
(9)
Решение (9) является правильным только тогда, когда введенная переменная ![]() . Приведем (9) к следующему виду:
. Приведем (9) к следующему виду:
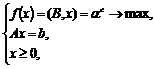 (10)
(10)
где ![]() ,
, ![]() и
и ![]() - матрица размерности
- матрица размерности ![]() , элементы которой представляют коэффициенты из равенств (9), а
, элементы которой представляют коэффициенты из равенств (9), а ![]() представляет вектор столбцов левой части всех равенств системы (9). Виды матриц
представляет вектор столбцов левой части всех равенств системы (9). Виды матриц ![]() и
и ![]() представлены ниже.
представлены ниже.
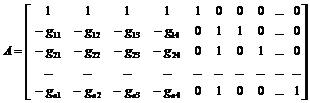 ,
, ![]() .
.
Из анализа матриц ![]() и
и ![]() видно, что оптимизационная задача (10) является разрешимой, поскольку имеет
видно, что оптимизационная задача (10) является разрешимой, поскольку имеет ![]() линейно независимых столбцов. Для нее всегда найдется допустимое решение
линейно независимых столбцов. Для нее всегда найдется допустимое решение 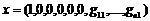 , т. е.
, т. е. ![]() ,
, ![]() ,
,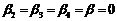 . Также можно доказать, что
. Также можно доказать, что ![]() , поскольку
, поскольку ![]() . Поставленная оптимизационная задача (10) является одним из видов задач линейного программирования и представлена в канонической форме. Ее можно решать, например, с помощью симплекс-метода.
. Поставленная оптимизационная задача (10) является одним из видов задач линейного программирования и представлена в канонической форме. Ее можно решать, например, с помощью симплекс-метода.
При анализе результатов решения оптимизационной задачи возможны следующие случаи:
Случай 1 (![]() ). Нарушение требования леммы 1. Провести коррекцию обучающей выборки.
). Нарушение требования леммы 1. Провести коррекцию обучающей выборки.
Случай 2. Нарушение доверие к ЧФБ вследствие не выполнения правил регулирования коэффициентов доверия. Провести коррекцию обучающей выборки.
Теперь рассмотрим представление АКФ в виде лингвистической переменной. Для этого зададим для каждой из ЧФБ лингвистические значения вида: {“высокая”, “средняя”, “низкая”, “близка к нулю”}. Очевидно, каждое из этих лингвистических значений можно рассматривать как нечеткую переменную и представлять одним из следующих способов: ступенчатым, трапециевидным, треугольным, гауссовым и т. п.
Исходя из этого, сформируем АКФ в виде лингвистической переменной <LV, T, U>, где LV=“принадлежность” - имя лингвистической переменной; T(LV)={“принадлежит”, “вероятно принадлежит”, “вероятно не принадлежит”, “не принадлежит”} – множество лингвистических значений; U=[0,1] – область определения LV.
Зададим правила нечеткого вывода в виде:
![]() : если принимает значение
: если принимает значение ![]() , -
, - ![]() , -
, - ![]() и -
и - ![]() , то LV принимает значение
, то LV принимает значение ![]() .
.
Здесь ![]() {“высокая”, “средняя”, “низкая”, “близка к нулю”} и
{“высокая”, “средняя”, “низкая”, “близка к нулю”} и ![]() {“принадлежит”, “вероятно принадлежит”, “вероятно не принадлежит”, “не принадлежит”}.
{“принадлежит”, “вероятно принадлежит”, “вероятно не принадлежит”, “не принадлежит”}.
Обозначим лингвистические значения “высокая”, “средняя”, “низкая” и “близка к нулю” через 1, 2, 3 и 4 соответственно, тогда нечеткую систему вывода атрибутного классификатора можно задать таблицей вида:
|
|
|
| LV |
1 | 1 | 1 | - | принадлежит |
2 | 1 | принадлежит | ||
- | вероятно принадлежит | |||
3 | 1 | вероятно принадлежит | ||
- | вероятно не принадлежит | |||
4 | 1 | вероятно не принадлежит | ||
- | вероятно не принадлежит | |||
2 | 1 | - | принадлежит | |
2 | 1 | принадлежит | ||
- | вероятно принадлежит | |||
4 | вероятно не принадлежит | |||
3 | 1 | принадлежит | ||
2, 3 | вероятно принадлежит | |||
4 | вероятно не принадлежит | |||
4 | 1, 2 | вероятно принадлежит | ||
3, 4 | вероятно не принадлежит | |||
3 | 1 | 1, 2 | принадлежит | |
- | вероятно принадлежит | |||
2 | 1 | принадлежит | ||
- | вероятно принадлежит | |||
3 | 1 | вероятно принадлежит | ||
- | вероятно не принадлежит | |||
4 | - | не принадлежит | ||
4 | 1 | 1, 2 | вероятно принадлежит | |
- | вероятно не принадлежит | |||
2 | 1, 2 | вероятно принадлежит | ||
- | вероятно не принадлежит | |||
3-4 | - | не принадлежит |
В четвертой главе обсуждаются вопросы экспериментального моделирования атрибутной классификации, приводится структура программной модели (ПМ) и результаты анализа проведенных на ней экспериментов.
ПМ включает базу данных, хранилище документов, хранилище текстов, подсистему распознавания и преобразования документов. В ней организуется пакетный режим конвертирования документов в текстовые форматы, выделение термов, определение дополнительной информации о документах. Взаимодействие ПМ с пользователями осуществляется через специальный интерфейс. Сама ПМ реализована в виде библиотеки на языке C# в платформе.NET.
Каждый документ, введенный в ПМ, сохраняется в хранилище документов, распознается и после этого в документе определяются функциональные области, термы и их встречаемость. Далее информация о документе сохраняется в базе данных. После моделирования близости документа тематикам принимается решение о классификации документа.
Для проведения экспериментов были составлены 14 тематик, обучающая и тестовая выборки, включающие научные статьи, книги и др. документы, представляющие область информатики. Суммарный объем выборок составил около 2000 документов, занимающих 20Gb памяти.
Эксперимент 1. Настройка классификатора - определение порогов классификации для тематик. В первичной ОВ всем тематикам приписано по 11 обучающих документов. При прогоне классификатора по ОВ для 8 из 14 тематик пороговое значение АКФ оказалось меньше 0.5. Поэтому проведена коррекция ОВ путем добавления в 5 из 14 тематик по 3 документа. Кроме того, в описания всех тематик добавлены термы из предметных указателей и глоссариев книг. После коррекции результаты классификации стали удовлетворительными. Результат настройки классификатора показан ниже на рисунке 1.
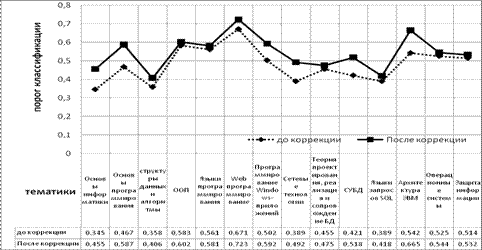
Рисунок 1. Настройка порогов классификации.
Здесь пунктирной линией обозначены пороги классификации тематик до коррекции, а сплошной линией – после коррекции.
Эксперимент 2. Оценка полноты и точности классификации по тестовой выборке.
Пусть 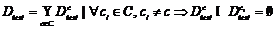 - тестовая выборка, а
- тестовая выборка, а ![]() - экспертные оценки близостей
- экспертные оценки близостей ![]() документов тематикам,
документов тематикам, ![]() - множество документов из ТВ, соответствующих тематике с по мнению экспертов,
- множество документов из ТВ, соответствующих тематике с по мнению экспертов, ![]() - множество документов, отнесенных в тематику с классификатором и
- множество документов, отнесенных в тематику с классификатором и 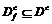 - множество документов, правильно отнесенных к тематике с. Пусть
- множество документов, правильно отнесенных к тематике с. Пусть ![]() - объем документа
- объем документа ![]() в числе термов. С учетом выше изложенного характеристики качества классификации сформируем следующим образом:
в числе термов. С учетом выше изложенного характеристики качества классификации сформируем следующим образом:
a) полнота для одной тематики 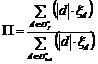 ;
;
b) полнота для классификатора 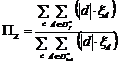 ;
;
c) точность для одной тематики 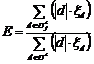 ;
;
d) точность работы классификатора 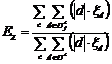 .
.
Определение качества классифицирования проводилось отдельно для однословных и многословных термов. Многословные термы состояли от 1 до 3 слов. Результат классификации на тестовой выборке, составленной из 187 книг, представлен на рисунке 2.
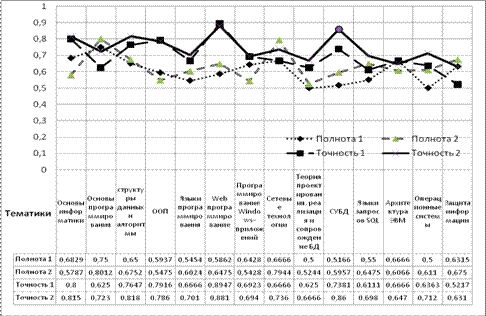
Рисунок 2. Оценка качества атрибутной классификации.
Среднее значение полноты классификации в случае использования однословных термов (полнота 1) составил 61%, в случае использования многословных термов (полнота%. Среднее значение точности классификации при использовании однословных термов (точность 1) составило 64%, в случае многословных термов (точность%. Таким образом, точность классификации на прямую связана с возможностями выделения термов лингвистическим обеспечением классификатора.
В заключении приводятся основные научные результаты, полученные в диссертационной работе, и формулируются выводы.
1. Проведено исследование существующего состояния теоретических и практических исследований в области классификации, которое показало, что при анализе документов не в полной мере интегрально учитываются атрибутные составляющие документов для построения классифицирующей функции. Сделан вывод о том, что учет информации из атрибутных характеристик документов мог бы существенно повысить точность классифицировании в условиях неполной информации по основному содержанию документов.
2. Для цели диссертационного исследования сформулированы основные терминологические понятия из области классификации, дана их содержательная и математическая интерпретация, выбран основной математический инструментарий, который учитывает модели представления документов и методы их анализа.
3. Предложена модифицированная модель описания документа, которая наряду с описанием основного текста содержит ряд дополнительных атрибутов, таких как описания названия, авторов, аннотации, глоссариев и пр., а также таких атрибутов как УДК, ISBN и пр., которые соответствуют данному типу документов.
4. Предложена модифицированная модель описания тематики, атрибутивно согласованная с предложенной моделью описания документа, что позволяет устанавливать между ними степени близости по однотипным атрибутам описаний.
5. Разработана конструкция классифицирующей функции ![]() , аргументами которой являются частичные функции близости
, аргументами которой являются частичные функции близости ![]() ,
,![]() ,
,![]() ,
,![]() . Предложено функцию
. Предложено функцию ![]() представлять в виде линейной комбинации частичных функций близости, нормализованной на интервале [0,1]. Каждая такая функция отражает частичную близость документа тематике на основе типов: “текст”↔“текст”, “текст”↔“экспертное знание”, “экспертное знание”↔“экспертное знание” и дополнительных атрибутов множеств описания. Введено понятие базового классификатора, обладающего минимальной точностью, а также сформулированы требования в виде лемм к структуре правильно построенной обучающей выборки.
представлять в виде линейной комбинации частичных функций близости, нормализованной на интервале [0,1]. Каждая такая функция отражает частичную близость документа тематике на основе типов: “текст”↔“текст”, “текст”↔“экспертное знание”, “экспертное знание”↔“экспертное знание” и дополнительных атрибутов множеств описания. Введено понятие базового классификатора, обладающего минимальной точностью, а также сформулированы требования в виде лемм к структуре правильно построенной обучающей выборки.
6. Сконструирована обобщенная функция важности термов и предложено формировать атрибутные множества на основе разработанного в диссертации алгоритма извлечения термов.
7. Сформулированы правила и построена процедура обучения классификатора путем настройки коэффициентов доверия и порогов классифицирующей функции. Настройка коэффициентов доверия и порогов классифицирующей функции сформулирована в виде оптимизационной задачи.
8. На основе решения данной оптимизационной задачи разработана методика коррекции обучающей выборки.
9. Предложено представление классифицирующей функции в виде лингвистической переменной и построены правила нечеткого логического вывода, позволяющие существенно упростить переобучение классификатора путем коррекции нечетких переменных и/или правил логического вывода.
10. Разработана программная модель для моделирования разработанного атрибутного классификатора и на ней поставлены ряд экспериментов. Результаты экспериментов подтвердили полученные в диссертации теоретические выводы.
ПУБЛИКАЦИИ ПО ТЕМЕ РАБОТЫ
1. Ха алгоритма сбора и классификации документов в поисковой машине на основе нечеткой логики // Сборник трудов VIII Всероссийской научной конференции студентов и аспирантов "Техническая кибернетика, радиоэлектроника и системы управления (КРЭС'06)" - Таганрог: Изд-во ТРТУ, 2006г. - с. 253-254.
2. Ха системы обработки текстовой информации на основе алгебраических методов с учетом семантических характеристик текста. // Сборник трудов Всероссийской научной школы - семинара молодых ученых, аспирантов и студентов "Интеллектуализация информационного поиска, скантехнологии и электронные библиотеки". - Таганрог: Изд-во ТТИ ЮФУ, 2007г. - с. 61-65.
3. Ха особенностей вьетнамского языка в системе русско-вьетнамского (вьетнамско-русского) машинного перевода. // Известия ЮФУ. Технические науки. Тематический выпуск «Интеллектуальные САПР».- Таганрог: Изд-во ТТИ ЮФУ. № 2 (7–с. 206-210.
4. Ха автоматизированной модели каталогизации документов в информационной образовательной системе. // Сборник трудов V Всероссийской конференции студентов, аспирантов и молодых ученых “Технология Microsoft в теории и практике программирования”. –Таганрог: Изд-во ТТИ ЮФУ, 2008г. - с. 122-125.
5. Ха Т. Ч., , Создание текстовой выборки на основе электронного архива данных лаборатории ELDIC для исследования задач автоматической обработки текстов на естественном языке. // Сборник трудов всероссийской научной школы-семинара молодых ученых, аспирантов и студентов: "Интеллектуализация информационного поиска, скантехнологии и электронные библиотеки". –Таганрог: Изд-во ТТИ ЮФУ, 2008г. –с. 82-86.
6. Ха моделей представления документов и классификатора на основе нечеткой логики. // Известия ЮФУ. Технические науки. Тематический выпуск “Интеллектуальный САПР”.–Таганрог: Изд-во ТТИ ЮФУ, 2008. –№9(86). –с.139-144.
7. Ха Т. Ч. О проблеме извлечение термов из текста в задаче автоматизированной классификации документов. // Сборник трудов VI Всероссийской научной конференции молодых ученых, аспирантов и студентов “Информационные технологии, системный анализ и управление”. Таганрог: Изд-во ТТИ ЮФУ, 2008г. ‑с. 30-33.
![]() В работе [5], написанной в соавторстве, программная модель интегрирования с известными решениями для распознавания текстов является личным вкладом автора.
В работе [5], написанной в соавторстве, программная модель интегрирования с известными решениями для распознавания текстов является личным вкладом автора.
Технологический институт Южного федерального университета в г. Таганроге
г. Таганрог, пер. Некрасовский 44.
