

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
УДК 681.3.06:519.95
ВЫБОР ОПТИМАЛЬНЫХ УЗЛОВ СГЛАЖИВАНИЯ
ЛИНЕЙНЫМИ СПЛАЙНАМИ
В работе предлагается простой алгоритм (типа Беллмана) выбора узлов склейки линейного сплайна, предназначенного для дальнейшей аппроксимации, сглаживания, выбора типа функциональной зависимости. Приведены примеры.
типизация, аппроксимация, линейные сплайны, сглаживание
Задача типизации данных есть задача (в лучшем случае) определения вида функциональной зависимости экспериментальных данных или (в худшем случае) некоторых характеристик этой зависимости, как то: наличие экстремумов, участ-
ков монотонности, периодичности и т. д. (см., напр. [1]).
В общем случае задачу можно сформулировать следующим образом. Пусть X, Y – линейные метрические пространства. Пусть также D ⊂ X×Y – некоторое конечное множество, представляющее собой набор экспериментальных данных, = conv(D) – его выпуклая оболочка. Выберем некоторый класс функций ℱ= {f: X → Y}, определенных на R ⊃¯X={x∈X: (x, y)∈} (проекция на Х), с графиком G = {(x,y): x∈ : y = f(x)}. Пусть для подмножеств U, V⊂Y корректно определено расстояние ρ(U, V). Тогда величина E (D) =ρ(¯Y ,f(¯X)) оценивает сте-пень близости графика G и экспериментальных данных D. В таком случае задачу типизации можно определить как поиск такой ∈ℱ, для которой достигается значение E (D)= E (D). Обычно расстояние ρ индуцируется введенными на X, Y нормами, а в качестве класса ℱ выбирают некоторое параметризованное семейство функций, задача тогда сводится к удовлетворительному (относительно выбранной метрики) подбору параметров. Если в результате такого подбора удается получить E (D)=0, то интерполирует D, в противном случае получим
аппроксимацию или сглаживание данных.
Решение задачи в такой общей постановке не представляется возможным, за исключением некоторых частных случаев, сводящихся, в основном, к X, Y = ℝ и выбору в качестве ℱ класса, содержащего элементарные алгебраические и (или) трансцендентные функции (полиномы, стандартные гармонические функции, функции математической физики). Нередко выбирается одна функция с харак-терными свойствами, а параметром соответствующего семейства является сдвиж-ка аргументов. Даже в этой, сравнительно простой, ситуации можно получить
достаточно богатый для решения подобных задач класса ℱ (см., напр., [2, 3]).
Обычно экспериментальные данные содержат случайный компонент (погрешности), при котором интерполяция, особенно при требованиях гладкости заданного порядка, теряет смысл. В этом случае задача типизации преследует фильтрацию и выявление скрытых закономерностей. Здесь следует выбирать компромисс между функциональным богатством класса ℱ и алгоритмической сложностью его использования. В различных практических приложениях этот компромисс нередко решается в пользу выбора сплайнов, в основном полиномиальных, степени не выше 3 – 5-й [4, 5].
Полиномиальные сплайны можно однозначно определить положением уз-лов склейки многочленов и значениями производных заданного порядка на фик-сированном множестве, обычно жестко связанном с множеством узлов. Выбор значений производных полиномиальных сплайнов (при фиксированном множе-стве узлов) – это (в обычной постановке) легко решаемая линейная задача, тогда как выбор узлов – нелинейная, связанная с серьезными алгоритмическими труд-ностями. В данной работе предлагается алгоритм оптимального выбора узлов линейных сплайнов, склеенных из отрезков прямых. Это не является серьезным ограничением по следующим причинам. Во-первых, метод разумно применять в случае данных, содержащих случайную компоненту (помеху), прошедших пред-варительную обработку (сглаживание, фильтрацию), и в этом случае точный вид функциональной зависимости не играет принципиальной роли. Во-вторых, ре-зультат легко аппроксимируется гладкой функцией [6], пригодной для дальней-шего анализа. В-третьих, для "аккуратных" данных алгоритм позволяет выделить характерные участки функциональной зависимости (например, положение точек
экстремумов).
Рассмотрим сначала случай известной действительной функции действи-тельного переменного f: [a, b] → ℝ и пусть ρ(f, φ, a, b) – выбранная интегральная
метрика, например, ρ(f, φ, a, b) = . Выберем m точек a = t0< t1<
… < tm< tm+1= b, на каждом отрезке [tj, tj+1] определим φ(t) отрезками прямых φ(t)=f(tj) + и подчиним выбор {tj} требованию ∑mk=0 ρ(f,φ,tk,tk+1)→ min. Структура задачи позволяет воспользоваться принципом оптимальности Беллмана [7], который приводит к рекуррентному процессу
Rm(y) = ρ(f, φ, y, b),
Ri(y) = {Ri+1(z) + ρ(f,φ,y, z)}, i=m-1,…,0. (1)
Дальнейшее упрощение задачи можно получить по пути дискретизации. В этом случае следует построить алгоритм, подобный алгоритмам Беллмана и Дейкстры [8] поиска кратчайшего пути на ориентированном графе. Пусть n > m – число точек определенной на [a, b] произвольной сетки a = x0< x1<…< xn= b. Возьмем в качестве функции φ отрезок прямой, проходящей через соседние узлы
сетки данных. Введем стандартную в l2 меру, полагая
ui, j = ρ(f, φ, xi, xj) = ∑ j-1k=i+1, (2)
и будем выбирать оптимальные узлы {ti}⊂{xj}nj=0 среди узлов фиксированной сет-
ки. Равенства (1) в этом случае примут вид
Rm, j = uj, n, j = 1,…, n-1,
Ri, k = {Ri+1,j + uk, j}, k = 0,…, n+i-m-1. (3)
Теперь алгоритм становится совсем прозрачным и может быть записан в виде:
1) для j = 1,…, n-1 вычисляются значения Rm,j = uj,n и полагается Am,j = n;
2) двигаясь "с хвоста", для i = m-1, …, 0, k = 0,…, n+i-m-1 находим значения Ri,k из уравнения (3) перебором соответствующих значений j из указанного промежутка и запоминаем номер индекса ν = j*, на котором достигается минимум, полагая Ai,k = ν;
3) выбранные номера узлов восстанавливаются из матрицы А, полагая для j = 0, …, m+1 s0 = 0, s1 = A0,1, sj = A ( j > 1), tj = x.
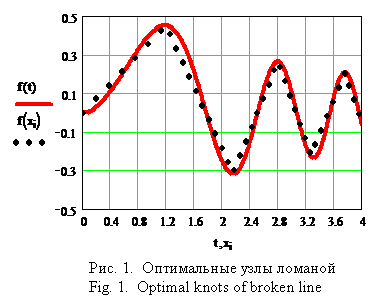
Пример 1. Рассмотрим функцию f(t) = на [0, 4], где она имеет пять локальных экстремумов. Разобьем отрезок на n = 50 равных частей с шагом h = 0.08, полагая xi = ih, yi = f(xi), i = 0,…, n. Выбрав m = 5 узлов ломаной (по числу экстремумов), получим t = (1.2, 2.16, 2.8, 3.28, 3.76) – точки локальных экстремумов суть 1.174, 2.154, 2.794, 3.311, 3.756 (см. рис. 1).
Если взять сетку, сгущенную в окрестности подозрительных точек, напри-мер, х = (0, 0.4, 0.8, 1, 1.15, 1.17, 1.175, 1.18, 1.22, 1.25, 1.8, 2, 2.15, 2.155, 2.16, 2.2, 2.3, 2.5, 2.77, 2.79, 2.81, 2.82, 3, 3.25, 3.3, 3.31, 3.32, 3.45, 3.7, 3.75, 3.76, 3.8, 4)Т, то в результате получим точки t = (1.18, 2.155, 2.81, 3.31, 3.76).
 |
Полезно отметить, что в качестве φ в приведенном алгоритме можно взять любую подходящую функцию. Ее достаточно определить на отрезке [0, 1] и мас-штабировать по необходимости (функция должна воспроизводить константу). Ес-ли в данном примере выбрать φ(t) = (((2t – 5)t +2)t + 2)t2, обладающую свойства-ми: φ(0) = φ′(0) = φ′(1) = 0, φ(1) = 1, φ(1- t) = 1 – φ(t) (сдвижки этой функции, как несложно убедиться, константу восстанавливают), то в качестве меры уклонения
можно взять (ср. с (2))
ui, j = ρ(f, φ, xi, xj) = ∑ j-1k=i+1. (4)
В результате получим тот же набор точек. Положив xi = ti, i = 1,…, 5, x0 = 0, x6 = 4, wi = f(xi), ∀i, r (x,w,t) = , получим гладкое восполнение дискретной информации (рис. 2).
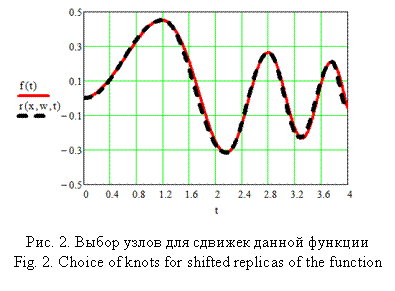
Очевидно, ситуация не изменится, если исследуемая функциональная зави-симость изначально задана своими значениями на конечной сетке. Это удобно при планировании эксперимента и практических исследованиях: процесс анализа можно проводить в несколько этапов, на каждом добавляя необходимую инфор-
мацию в окрестности характерных точек.
При наличии большого искажения данных случайными помехами разумно провести предварительное сглаживание (доступные пакеты имеют много инструментов для достижения этой цели, см., например, Matlab, MathCad, Maple,
Statistica и др.).
Пример 2. Рассмотрим временной ряд yi, i = 0,…, 255, определяемый стан-дартным гауссовым шумом c математическим ожиданием M(y) = 0, дисперсией σ2(y) = 1 (реализованный в пакете MathCad функцией qnorm(rnd(1),0,1)), сглажен-ный с помощью встроенной функции ksmooth с шириной окна равной 20 (массив ysmo). Построим линейный сплайн с пятью (m = 5, массив у1) узлами. Гладкая аппроксимация (функция z(t)) построена с помощью техники, изложенной в [6].
Результат представлен на рис. 3.
Таким образом, пример 1 демонстрирует выявление характерных элементов функциональной зависимости с использованием линейных сплайнов либо копий некоторой фиксированной функции, пример 2 показывает возможность выявле-ния типа функциональной зависимости, скрытой случайными помехами.
Небольшое замечание по поводу выбора количества характерных узлов: в основном, он диктуется свойствами исследуемого процесса, предполага-емыми a-priori. В ходе исследования это количество несложно менять в силу простоты и легкой реализуемости приведенного алгоритма. Если же поведение исследуемой зависимости неизвестно, особенно в присутствии случайных помех, полезно рассматривать оценку дисперсии отклонения этой зависимости от выб-ранного шаблона как функцию количества выбранных узлов и минимизировать ее до разумного предела – при большом числе узлов эту оценку можно сделать как угодно малой, но тогда полностью пропадет практический смысл такой типизации.
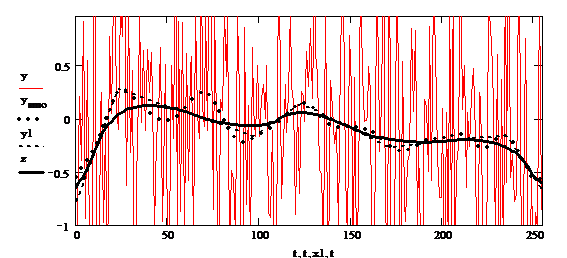
Рис. 3. Типизация в присутствии гауссова шума
Fig. 3. Typization through a Gaussian noise
СПИСОК ИСПОЛЬЗОВАННЫХ ЛИТЕРАТУРНЫХ ИСТОЧНИКОВ
1. Алексеев, кусочными функциями и задача типизации / // Кибернетика АНУССР. – 1968. - №15. - С. 49-53.
2. Kramer H. K. Decomposition of a function into a weighted sum of shifted replicas of another function. /H. K.Kramer, R. N. Lane // Journal of Mathematical Analysis and Applications − 1974. − v.46. − N 3. − p. 395-608.
3. Rong Quing Jia. Linear independence of translates of a box spline /Jia Quing Rong // Journal of Approximatin Theory − 1984 − v.40. − N 2. − p. 158-160.
4. Бор, К. де. Практическое руководство по сплайнам / К. де Бор. – М.: Радио и связь, 1985. – 303 c.
5. Половко, А. Интерполяция. Методы и компьютерные технологии их реализации /А. Половко. – С. Пб.: БХВ-Петербург, 2006. – 320 c.
6. Пахнутов, пакетом ломаных / // Известия КГТУ. – 2007. - №12. – С. 190–199.
7. Арис, А. Дискретное динамическое программирование / А. Арис. – М.: МИР, 1969. – 171 с.
8. Новиков, математика для программистов /. – СПб.: Питер, 2002. – 304 с.
OPTIMAL CHOICE OF KNOTS FOR SMOOTHING
BY LINEAR SPLINES
I. A. Pakhnoutov
In the paper author offers a simple Bellman-type algorithm of choice linear spline knots to approximate, smooth or define a sort of functionality in further data processing. Examples presented.
typization, approximation, linear splines, smoothing
