


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
lЭтот механизм реализован с помощью виртуальных методов.
lВиртуальным называется метод, ссылка на который разрешается на этапе выполнения программы.
Виртуальные методы
lДля определения виртуального метода используется спецификатор virtual, например:
class A {
public:
virtual void metod1();
…
};
class B : public A{
public:
virtual void metod1();
…
};
Правила описания и использования виртуальных методов
lЕсли в базовом классе метод определен как виртуальный, метод, определенный в производном классе с тем же именем и набором параметров, автоматически становится виртуальным, а с отличающимся набором параметров — обычным.
class A {
public:
virtual void metod1();
…
};
class B : public A{
public:
void metod1(); // виртуальный метод
void metod1(int a); // обычный метод
…};
lВиртуальные методы наследуются, то есть переопределять их в производном классе требуется только при необходимости задать отличающиеся действия. Права доступа при переопределении изменить нельзя.
class A {
public:
virtual void metod1();
…
};
class B : public A{
public:
…
};
A *pointer = new B;
pointer->metod1(); // допустимая операция будет вызван
// метод класса A
lЕсли виртуальный метод переопределен в производном классе, объекты этого класса могут получить доступ к методу базового класса с помощью операции доступа к области видимости.
class A {
public:
virtual void metod1();
…
};
class B : public A{
public:
void metod1(){
…
A::metod1();
…
}
…
};
A *pointer = new B;
pointer->metod1();
lЕсли в базовом классе метод определен как виртуальный, метод, определенный в производном классе с тем же именем и набором параметров, автоматически становится виртуальным, а с отличающимся набором параметров — обычным.
lВиртуальные методы наследуются, то есть переопределять их в производном классе требуется только при необходимости задать отличающиеся действия. Права доступа при переопределении изменить нельзя.
lЕсли виртуальный метод переопределен в производном классе, объекты этого класса могут получить доступ к методу базового класса с помощью операции доступа к области видимости.
lВиртуальный метод не может объявляться с модификатором statiс.
Абстрактные классы и чисто виртуальные методы
lПри описании класса можно описать виртуальный метод у которого нет реализации в данном классе. Для этого используется специальный синтаксис.
class A {
public:
virtual void metod1() = 0;
…
};
lТакой метод называется чисто виртуальным.
lКласс, содержащий хотя бы один чисто виртуальный метод, называется абстрактным.
lАбстрактные классы предназначены для представления общих понятий, которые предполагается конкретизировать в производных классах.
lАбстрактный класс может использоваться только в качестве базового для других классов — объекты абстрактного класса создавать нельзя, поскольку прямой или косвенный вызов чисто виртуального метода приводит к ошибке при выполнении.
Правила использования абстрактных классов
lАбстрактный класс нельзя использовать при явном приведении типов, для описания типа параметра и типа возвращаемого функцией значения;
lдопускается объявлять указатели и ссылки на абстрактный класс, если при инициализации не требуется создавать временный объект;
lесли класс, производный от абстрактного, не определяет все чисто виртуальные функции, он также является абстрактным.
lМожно создать функцию, параметром которой является указатель на абстрактный класс. На место этого параметра при выполнении программы может передаваться указатель на объект любого производного класса.
Пример использования абстрактных классов
class Figure {
public:
virtual void draw() = 0;
…
};
class Triangle : public Figure{
public:
virtual void draw();
…
};
class Square : public Figure{
public:
virtual void draw();
…
};
Figure *mas[2];
mas[0] = new Triangle();
mas[1] = new Square();
for(int i=0;i<2;i++)
mas[i]->draw();
Множественное наследование
lМножественное наследование означает, что класс имеет несколько базовых классов.
lМножественное наследование применяется для того, чтобы обеспечить производный класс свойствами двух или более базовых.
lЧаще всего один из этих классов является основным, а другие обеспечивают некоторые дополнительные свойства, поэтому они называются классами подмешивания.
Иерархия классов при множественном наследовании

Синтаксис множественного наследования
class имя:
[private|protected|public] базовый_класс1,
[private|protected|public] базовый_класс2,
…
{
тело класса
};
Пример множественного наследования
class clX {
public:
clX();
int ValueX;
…
};
class clY {
public:
clY();
bool ValueY;
…
};
class clZ: public clX,
public clY{
public:
clZ();
double ValueZ;
…
};
…
clZ *z = new clZ;
z->ValueX = 10;
z->ValueY = true;
z->ValueZ = 5.7;
…
delete z;
Проблемы множественного наследования
lЕсли в базовых классах есть одноименные элементы, при этом может произойти конфликт идентификаторов.
lЕсли у базовых классов есть общий предок, это приведет к тому, что производный от этих базовых класс унаследует два экземпляра полей предка, что чаще всего является нежелательным (ромбовидное наследование).
Пример устранения конфликта идентификаторов
class clX {
public:
clX();
int ValueQ;
…
};
class clY {
public:
clY();
int ValueQ;
…
};
class clZ: public clX,
public clY{
public:
clZ();
…
};
…
clZ *z = new clZ;
z->clX::ValueQ = 10;
z->clY::ValueQ = 20;
…
delete z;
Конфликт двойного наследования общего предка
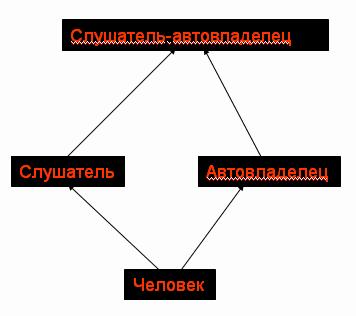
Устранение конфликта двойного наследования предка
class man {
public:
man();
char *fio;
…
};
class Listener:
virtual public man {
public:
Listener();
int group;
…
};
class AutoOwner:
virtual public man{
public:
AutoOwner();
char GosN[9];
…
};
class AutoListener:
public Listener,
public AutoOwner
{
public:
AutoListener();
char propuskN[10];
…
};
Шаблоны классов
lШаблоны классов предназначаются для отделения алгоритмов от конкретных типов данных и позволяют создавать параметризованные классы.
lПараметризованный класс создает семейство родственных классов, которые можно применять к любому типу данных, передаваемому в качестве параметра.
lНаиболее широкое применение шаблоны находят при создании контейнерных классов.
lКонтейнерным называется класс, который предназначен для хранения каким-либо образом организованных данных и работы с ними.
lПреимущество использования шаблонов состоит в том, что как только алгоритм работы с данными определен и отлажен, он может применяться к любым типам данных без переписывания кода.
Односвязный линейный список
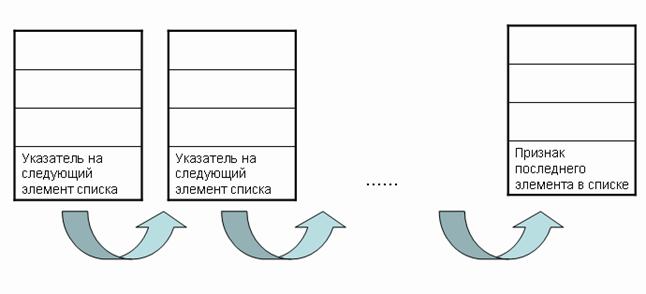
Класс для контейнера «стек целых чисел»
class Stack{
private:
struct DataElement{
int Value;
struct DataElement *next;
};
DataElement *first;
public:
Stack(){ first = NULL;}
~Stack(){ while(first!= NULL) Pop();}
void Push(int value){
DataElement *d = new DataElement();
d->Value = value;
d->next = first;
first = d;
}
int Pop(){
if(first == NULL) return 0;
DataElement *d = first;
first = first->next;
int tmp = d->value;
delete d;
return tmp;
}
};
Использование контейнера «стек целых чисел»
…
Stack *st = new Stack();
st-> Push(10);
st-> Push(15);
st-> Push(20);
int tmp = st->Pop();
tmp = st->Pop();
…
delete st;
Синтаксис определения шаблона класса
template <описание_параметров_шаблона> определение_класса;
lПараметры шаблона перечисляются через запятую.
lВ качестве параметров могут использоваться типы, шаблоны и переменные.
lТипы могут быть как стандартными, так и определенными пользователем.
lДля их описания используется ключевое слово class.
lВнутри шаблона параметр типа может применяться в любом месте, где допустимо использовать спецификацию типа.
Шаблон для контейнера «Стек»
template<class T> class Stack{
private:
struct DataElement{
T Value;
struct DataElement *next;
};
DataElement *first;
public:
Stack(){ first = NULL;}
~Stack(){ while(first!= NULL) Pop();}
void Push(T value){
DataElement *d = new DataElement();
d->Value = value;
d->next = first;
first = d;
}
T Pop(){
if(first == NULL) return 0;
DataElement *d = first;
first = first->next;
T tmp = d->value;
delete d;
return tmp;
}
};
Использование шаблона «стек»
Stack<int> *st = new Stack();
st-> Push(10);
st-> Push(15);
int tmp = st->Pop();
tmp = st->Pop ();
…
delete st;
…
Stack<double> *st = new Stack();
st-> Push(10.6);
st-> Push(15.7);
double tmp = st->Pop ();
tmp = st->Pop ();
…
delete st;
…
Stack<Listener *> *st = new Stack();
st-> Push(new Listener());
st-> Push(new Listener());
Listener *tmp = st->Pop ();
tmp = st->op ();
…
delete st;
Описание методов вне шаблона
template <описание_параметров_шаблона>
возвр_тип имя_класса <параметры_шаблона>:: имя_функции (список_параметров функции)
Например:
template <class T>
T Stack<T>::Pop()
{
…
}
Макрообработка
Основные понятия
•Макрообработка - это обработка самой программы до ее выполнения.
•Макрообработка используется в основном для разработки проблемно-ориентированных языков, повышения удобочитаемости программ и их компоновки с целью выполнения в различных режимах (тестирующем, отладочном, рабочем).
•Макропроцессор – часть транслятора или отдельная программа, производящая макрообработку.
•На входе совокупность синтаксических конструкций языка программирования и макросредств, на выходе – программа, готовая к трансляции.
•Лексема - минимальная единица текста, которую обрабатывает макропроцессор.
•Лексемами являются последовательности букв и цифр, не разделенных специальными знаками, и сами специальные знаки (скобки, знаки операций и т. д.).
•Макропроцессор считывает лексему из входного текста а на выход помещает соответствующую ей последовательность лексем.
•Если производится не тривиальная замена одной лексемы на другую, то то введенная лексема (или последовательность лексем) называется макрокомандой или макросом.
•Макроопределения – средства описания макросов.
•Макровызовы – средства для выполнения макросов.
•Макросредства включают в себя макроопределения, макровызовы, предопределенные макросы, средства для вычислений в процессе макрообработки.
Классификация макропроцессоров
•По области применения – специализированные и общего назначения.
–Специализированные макропроцессоры, имея возможность использовать знания о синтаксисе языка программирования, могут предоставить более удобный и широкий набор средств.
–Макропроцессоры общего назначения имеет смысл применять в многоязыковых программных системах, когда важны единообразие используемых средств и легкость обучения.
•По степени близости макросредств к языкам программирования – языкоподобные и независимые.
–Языкоподобные макропроцессоры хороши тем, что знание исходного языка программирования помогает в изучении макросредств.
–Однако похожий синтаксис имеет и недостатки: в тексте программы трудно отличить макросредства от обычных операторов; одинаковое написание может привести к неправильному пониманию семантики макросредств.
•По фазе трансляции, на которой производится макрообработка – текстовые, синтаксические и вычислительные.
–Текстовые – обработка исходного текста программы до трансляции
–Синтаксические – обработка исходного текста на этапе синтаксического анализа
–Вычислительные – обработка исходного текста на этапе генерации кода, используются главным образом для вставки в генерируемый код последовательностей команд, для выполнения не обеспечиваемых языком действий.
Текстовые макропроцессоры
•Текстовые макропроцессоры используются в основном для сокращения записи программы, частичного изменения синтаксиса и для изменения текста программы в зависимости от значений параметров.
Виды макроопределений
•Подстановка нескольких лексем вместо одной.
macro L is
PL
end macro;
•
•Параметрическая подстановка
macro L(PlfP2, . . . ,Pn) is
PL
end macro;
•Определение значения лексемы (macroeval)
macroeval L is
Е
end macroeval;
•Условный макрооператор (macroif)
macroif В macrothen
PL1
macroelse
PL2
end macroif;
•Макрооператор цикла (macrowhile).
macrowhile В macrodo
PL
end macrodo;
Дополнительные средства
•Ввод текста из дополнительных источников
•Промежуточное хранение отдельных частей текста
•Выдача диагностических сообщений о ходе макрообработки
•Управление печатью листинга программы
Недостатки текстовых макропроцессоров
•Листинг программ, получаемый транслятором, отличается от исходной программы, что может привести к путанице результатов.
•Могут возникнуть трудности с обнаружением ошибок, возникающих вследствие неправильного определения макросов.
–В тех случаях, когда неправильно описан макрос или в макровызове употреблены неправильные параметры, средства диагностики транслятора неизбежно будут ссылаться на генерируемый текст, и может оказаться затруднительным соотнести эти диагностические сообщения с ошибочным макросом, который является причиной их появления.
•Невозможно проверить законность аргументов макровызовов.
– Например, может быть оговорено, что аргумент должен быть целой константой, однако чрезвычайно трудно проконтролировать соблюдение этого требования во время макрообработки, так как все аргументы трактуются как последовательности лексем.
Синтаксические макропроцессоры
• Синтаксические макропроцессоры (объединены в одном процессе макрообработка и синтаксический анализ) дают возможность программисту определять новые синтаксические конструкции через более простые синтаксические структуры базового языка программирования.
Преимущества синтаксических макропроцессоров
•Нет промежуточной генерации текста поэтому меньше возможности для путаницы.
•Можно задавать синтаксическую структуру макровызовов и синтаксические классы параметров; следовательно, на этапе синтаксического анализа можно обнаружить неправильные макровызовы и даже выявить некоторые семантические ошибки.
Пример макроса для синтаксического макропроцессора
macro while <логическое выражение> do
<последовательностъ операторов> end do;
is
метка: if %1 then %2
goto метка;
end if;
end macro;
Макрообработка в С++
•Исторически сложилось, что макропроцессор в С++ называется «препроцессором».
•По классификации препроцессор относится к специализированным, независимым, текстовым макропроцессорам
•Инструкции препроцессора называются директивами.
•Директивы должны начинаться с символа #, перед которым в строке могут находиться только пробельные символы.
Директива #include
•Директива #include <имя_файла> вставляет содержимое указанного файла в ту точку исходного файла, где она записана.
•Включаемый файл также может содержать директивы #include.
•Поиск файла, если не указан полный путь, ведется в стандартных каталогах включаемых файлов. Вместо угловых скобок могут использоваться кавычки (" ") — в этом случае поиск файла ведется в каталоге, содержащем исходный файл, а затем уже в стандартных каталогах.
•Директива #include является простейшим средством обеспечения согласованности объявлений в различных файлах, она включает в них информацию об интерфейсе из заголовочных файлов.
Директива #define
•Директива #def ine определяет подстановку в тексте программы. Она используется для определения:
–символических констант:
#define имя текст_подстановки
–макросов, которые выглядят как функции, но реализуются подстановкой их
текста в текст программы:
#define имя(параметры) текст_подстановки
–символов, управляющих условной компиляцией. Они используются вместе с директивами #i fdef и #i fndef. Формат: #define имя : Примеры:
#define VERSION 1
#define VASIA "Василий Иванович"
#define MAX(x. y) ((x)>(y)?(x):(y))
#define MUX
•Имена рекомендуется записывать прописными буквами, чтобы зрительно отличать их от имен переменных и функций.
•Параметры макроса используются при макроподстановке, например, если в тексте программы используется вызов макроса у = MAX(suml. sum2):, он будет заменен на
у = ((suml)>(sum2)?(suml):(sum2));
Директивы условной компиляции
•Директивы условной компиляции #if, #ifdef и #ifndef применяются для того, чтобы исключить компиляцию отдельных частей программы.
•Это бывает полезно при отладке или, например, при поддержке нескольких версий программы для различных платформ.
Формат директивы #if:
#if константное_выражение
…
[#elif константное_выражение
…]
[#elif константное_выражение
…]
[#else
…]
#endif
Пример условной компиляции
#if VERSION ==1
#define INCFILE "vers1.h"
#elif VERSION == 2
#define INCFILE "vers2.h"
/* и так далее */
#else
#define INCFILE "versN. h“
#endif
#include INCFILE
Директивы #ifdef и #ifndef
•Часто в программах используются директивы #ifdef и #ifndef, позволяющие управлять компиляцией в зависимости от того, определен ли с помощью директивы fdefine указанный в них символ (хотя бы как пустая строка, например, fdefine 32_BIT_SUPP0RT):
#ifdef символ
// Расположенный ниже код компилируется, если символ
// определен
#ifndef символ
// Расположенный ниже код компилируется, если символ не
// определен
•Действие этих директив распространяется до первого #elif, #else или #endif.
Директива #undef
•Директива #undef имя удаляет определение символа.
•Используется редко, например, для отключения какой-либо опции компилятора.
Предопределенные макросы
•В C++ определено несколько макросов, предназначенных в основном для того, чтобы выдавать информацию о версии программы или месте возникновения ошибки.
•cplusplus — определен, если программа компилируется как файл C++.
•DATE — содержит строку с текущей датой в формате месяц день год, например:
printf(" Дата компиляции - %s \n", DATE );
•FILE — содержит строку с полным именем текущего файла.
•LINE — текущая строка исходного текста.
•TIME — текущее время, например:
printf(" Ошибка в файле %$ \n Время компиляции: %s\n ",
FILE, TIME);
Параллельная обработка
Причины развития языковых средств параллельной обработки
lРешение ряда задач более естественно выражается как совокупность взаимодействующих, параллельно выполняющихся процессов, процессов.
lШирокое распространение получили мультипрограммные операционные системы и и мультипроцессорные вычислительные системы.
Процесс
lПроцесс – совокупность операторов, выполняемых последовательно.
lПараллельная обработка – одновременное выполнение нескольких взаимодействующих процессов.
Основные понятия
lСпособы взаимодействия процессов (не являются взаимоисключающими):
nСвязь процессов – обмен данными между процессами
nСинхронизация процессов – согласование выполнения процессов
Основные понятия
lВзаимное исключение – возможность монопольной обработки данных процессом.
lПередача сообщений – основной механизм связи и синхронизации процессов
Средства для реализации параллельной обработки
lСредства обеспечения работы процессов (описание, создание, завершение, обработка исключений)
lМеханизмы, реализующие взаимное исключения и синхронизацию для процессов с общей памятью
lМеханизмы передачи сообщений
Описание процесса
process PR(L) is
D
begin
S
end process;
Оператор вызова процесса
init PR1(A1),PR2(A2), …, PRN(An);
Оператор прекращения процесса
init PR(A)[идентификатор];
abort идентификатор;
Завершение процесса генерацией исключения
raise идентификатор’ FAILURE
Средства для реализации параллельной обработки
lСредства обеспечения работы процессов (описание, создание, завершение, обработка исключений)
lМеханизмы, реализующие взаимное исключения и синхронизацию для процессов с общей памятью
lМеханизмы передачи сообщений
Взаимное исключение
process ПОСТАВЩИК is
use
БУФЕР, ДАННЫЕ : type,
ЖДАТЬ : procedure,
ВЫРАБОТАТЬ :
procedure(out ДАННЫЕ);
use B: in out БУФЕР;
X: ДАННЫЕ;
begin
do
ВЫРАБОТАТЬ(X);
while ПОЛОН(B) do
ЖДАТЬ();
end do;
ЗАНЕСТИ(B, X);
end do;
end process;
process ПОТРЕБИТЕЛЬ is
use
БУФЕР, ДАННЫЕ : type,
ЖДАТЬ : procedure,
ПОТРЕБИТЬ :
procedure(in ДАННЫЕ);
use B: in БУФЕР;
X: ДАННЫЕ;
begin
do
while ПУСТ(B) do
ЖДАТЬ();
end do;
ВЫБРАТЬ(B,X);
ПОТРЕБИТЬ(X);
end do;
end process;
Реализация буфера
subtype ИНДЕКС is integer range 0..n-1;
subtype КОЛИЧЕСТВО is integer range 0..n;
type БУФЕР is record
buffer: array(ИНДЕКС) of ДАННЫЕ;
first : ИНДЕКС; // индекс элемента массива с готовыми данными
count : КОЛИЧЕСТВО; // количество элементов в массиве
Функции ПОЛОН(B) и ПУСТ(B) возвращают результаты сравнения
B.count == n и B.count == 0 соответственно
Функция ЗАНЕСТИ :
B.buffer((B.first + B.count) % n ) := X;
B.count := B.count +1;
Функция ВЫБРАТЬ
X:= B. buffer(B. first);
B. first := (B. first + 1) % n;
B.count := B.count -1;
Возникновение ошибки
Поставщик
B. buffer((B. first + B. count) % n ) := X;
B. count := B. count +1;
Потребитель
X:= B. buffer(B. first);
B. first := (B. first + 1) % n;
B. count := B. count -1;
Вывод
lЧтобы исключить подобные ошибки, необходимо обеспечить такую синхронизацию процессов, при которой в каждый момент времени только один из нескольких процессов может использовать общий для всех ресурс, например общей области памяти.
lКритический интервал - фрагмент процесса, в котором есть обращение к общему ресурсу
Программное решение проблемы взаимного исключения
lНеобходимо предположение о неделимости операций доступа к памяти
Защита критических интервалов с помощью общей переменной
применим для защиты критических интервалов общую переменную door, которая может принимать два значения — open и close.
Значение close означает, что один из процессов вошел в критический интервал, значение open, что процесс может войти в критический интервал.
door: (open, сlose) := open;
— в начале критический интервал не занят
Защита критических интервалов с помощью общей переменной
процесс 1
do until(door=open);
door:=close; критический интервал 1
door:=open;
процесс 2
do until(door=open);
door:=close; критический интервал 2
door:=open;
Упорядочение критических интервалов
применим для защиты критических интервалов общую переменную переменная turn принимает значение 1, когда процесс 1 может войти в свой критический интервал, и значение 25 когда процесс 2 может войти в свой критический интервал.
turn: (1,2) := 1;
— вначале процесс 1 может войти в критический интервал, а процесс 2 не может
Упорядочение критических интервалов
процесс 1
do until(turn=1);
критический интервал 1
turn = 2;
процесс 2
do until(turn=2);
критический интервал 2
turn = 1;
Защита критических интервалов с помощью двух переменных
Пусть каждый процесс имеет свою переменную, которая может принимать значения inside и outside.
Значение inside означает, что процесс хочет войти или уже вошел в свой критический интервал, a outside, что процесс находится вне критического интервала.
Каждый процесс проверяет значение переменной другого процесса прежде, чем войти в свой критический интервал
statel, state2:(inside, outside):= outside;
— в начале процессы вне критических интервалов
Защита критических интервалов с помощью двух переменных
процесс 1
state1 := inside;
do until(state2=outside);
критический интервал 1
state1 := outside;
процесс 2
state2 := inside;
do until(state1=outside);
критический интервал 2
state2 := outside;
Защита критических интервалов с помощью двух переменных (доработанные процессы)
процесс 1
do
state1 := inside;
if state2 = inside then
state1 := outside;
end if;
do until
(state2=outside);
until(state1=inside);
критический интервал 1
state1 := outside;
процесс 2
do
state2 := inside;
if state1 = inside then
state2 := outside;
end if;
do until
(state1=outside);
until(state2=inside);
критический интервал 2
state2 := outside;
Защита критических интервалов (комбинированный метод)
Каждый процесс имеет связанную с ним переменную, которая индицирует желание процесса войти в критический интервал, и, если оба процесса хотят одновременно это сделать, для разрешения конфликта используется переменная, принимающая в качестве значения номер процесса, который имеет возможность войти в критический интервал.
statel, state2:(inside, outside):= outside;
turn: (1,2) := 1;
— в начале процессы вне критических интервалов, приоритет у первого процесса.
Защита критических интервалов (комбинированный метод)
процесс 1
state1 := inside;
if state2 = inside then
if turn = 2 then
state1 := outside;
do until(turn=1);
state1 := inside;
end if;
do until(state2=outside);
end if;
критический интервал 1
turn := 2;
state1 := outside;
процесс 2
state2 := inside;
if state1 = inside then
if turn = 1 then
state2 := outside;
do until(turn=2);
state2 := inside;
end if;
do until(state1=outside);
end if;
критический интервал 2
turn := 1;
state2 := outside;
Условия, которым должен удовлетворять любой метод, обеспечивающий взаимное исключение
lв любой момент времени не более одного процесса может находиться в своем критическом интервале;
lзадержка одного процесса вне его критического интервала не должна влиять на ход выполнения других процессов;
lне должно делаться никаких предположений об относительной скорости процессов;
lлюбой процесс, который готов войти в свой критический интервал, должен войти в него за конечное время
Двоичные семафоры
lДвоичный семафор – специальный тип данных.
lПеременные этого типа принимают значения 0 и 1, допустимы неделимые операции V и P.
lОперация Р
n - уменьшает значение семафора на 1, если оно отлично от 0;
nесли значение семафора равно 0, ждет, пока некоторый другой процесс не изменит значения семафора с помощью операции V, а затем уменьшает его
lОперация V – присваивает семафору значение 1.
mutex:semaphore := 1;
P(mutex);
критический интервал процесса N
V(mutex);
Двоичные семафоры
Достоинства
lМеханизм семафоров обеспечивает организацию любых схем взаимодействия процессов
lШироко используется в современных операционных системах
lВключен в ряд языков программирования
Двоичные семафоры
Недостатки
lРеализуют механизм низкого уровня
lБесконтрольное использование семафоров запутывает структуру управления параллельной программы
lПри программировании сложных взаимодействий велика вероятность возникновения ошибок, например:
nможно забыть выполнить операцию Р, в результате к общим ресурсам возможен доступ одновременно нескольких процессов
nможно забыть выполнить операцию V, что приведет к тупиковой ситуации
nв сложных программах можно забыть воспользоваться семафором
Двоичные семафоры
lНельзя запрограммировать альтернативное действие для случая, когда семафор окажется занятым
lНельзя ждать, пока один из нескольких семафоров окажется свободным
lЗа правильный доступ к общим ресурсам ответствен процесс, который осуществляет этот доступ. Это противоречит современной технологии программирования, — данные и все операции над ними должны объединяться в одну программную единицу
Простые критические интервалы
lКритический интервал – конструкция высокого уровня, используемая для реализации взаимного исключения
with R do
S
end do;
R – общая переменная;
S – последовательность операторов критического интервала.
Простые критические интервалы
lИспользование конструкции позволяет отказаться от явных действий с семафорами: открытие и закрытие их производится автоматически в соответствии с командами, сгенерированными транслятором.
lОтпадает необходимость в проверке правильности расстановки операций над семафорами.
lТранслятор может проверить, что общая переменная используется только внутри критических интервалов, так как мы явно указываем их в программе, следовательно, повышается надежность программ.
lОднако, все остальные недостатки семафоров присущи и простому критическому интервалу.
Мониторы

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
