
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
В данном конкретном коде суммируются символы ai+ai+2=bj (нумерацию ведем отдельно по информационным и проверочным символам). Затем каждый полученный проверочный символ вставляется в общую последовательность после информационного символа ai+6, т. е. на расстоянии ℓ≥h=4 от последнего информационного символа, входящего в данную сумму. В итоге каждый информационный символ влияет на значение двух проверочных символов. Процесс кодирования продолжается непрерывно до тех пор, пока не будет закодирована вся последовательность поступающих символов.
Декодирование при приеме сводится к следующему.
Из принимаемой последовательности выделяется последовательность проверочных символов.
Из принятых информационных символов формируется последовательность проверочных символов аналогично тому, как это делалось на входе канала связи при кодировании.
Сформированная на месте приема последовательность проверочных символов суммируется по модулю 2 с принятой последовательностью проверочных символов. Полученная сумма используется в качестве синдрома ошибок.
Если данная сумма (синдром) состоит из одних нулей, это значит, что в полученной последовательности информационных символов ошибок нет, и она передается потребителю информации.
Если синдром получается не нулевым, специальная схема по синдрому формирует вектор ошибки, который затем суммируется по модулю 2 с принятой последовательностью информационных символов, и тем самым исправляется ошибка (или ошибки). Исправленная последовательность передается получателю информации.
На рис. 3.2 показаны синдрома одно-, двух-, трех - и четырехкратных ошибок. Среди них нет повторяющихся. Это означает, что такие ошибки могут опознаваться однозначно, а следовательно, и декодироваться. Легко убедиться, что синдрома кратных ошибок являются суммой синдромов соответствующих однократных.
Если последующая пачка ошибок начинается раньше, чем через 3h+1 после окончания предыдущей пачки, однозначность определения ошибки нарушается. Этот факт иллюстрируется показанными на рис. 2 синдромами №12 и 13, соответствующими ошибкам как в символах a3b3, так и в символах a1 и b7.
Выполнив аналогичные построения синдромов ошибок, можно убедиться, что в случае интервала между пачками 3h+1 однозначное определение ошибочных разрядов возможно, т. е. декодирование не приводит к неверным исправлениям.
Литература:
[1] стр. 256-260. [2] стр. 290-292.
Задание для самостоятельной работы:
В процессе изучения изложенного материала необходимо научиться самостоятельно формировать синдромы различных ошибок (по кратности и расположению), векторы ошибок и определять номера разрядов, ошибки в которых исправляют полученные векторы ошибок. Правильность полученных результатов можно проверить по примерам, показанным на рис. 3.2.
Рассмотрим один из возможных вариантов формирования вектора ошибок. Для наглядности разряды будем нумеровать в соответствии
с рис. 3.2.
Если произошло искажение одного информационного символа, то синдром будет содержать две единицы (см. векторы №1-3 на рис. 3.2). Вектор одиночной ошибки в информационном разряде можно сформировать так: задержать синдром на два такта и подать задержанный и незадержанный синдромы на логическую схему И(&) с двумя входами:
……
И(&) …
……
На выходе схемы И получаем последовательность, имеющую одну единицу. Эту последовательность и можно использовать в качестве вектора ошибки.
Если искажены два соседних информационных символа (например, а1, и а2, синдром ошибки будет содержать четыре единицы (см. синдром №14). При этом на выходе схемы И формируется последовательность с двумя единицами подряд, которую также можно использовать в качестве вектора ошибок.
Формирование вектора ошибок несколько усложняется, если кроме информационных искажаются рядом стоящие проверочные символы. Рассмотрим для наглядности следующий пример. Пусть искажены четыре символа подряд: a1b1a2b2. В этом случае в синдроме, кроме четырех единиц соответствующих ошибкам в информационных разрядах, перед ними будут еще две единицы за счет ошибок в проверочных разрядах b1 и b2, т. е. синдром ошибок будет выглядеть так: …… (см. синдром №10 на рис. 3.2). Если формировать в этом случае вектор ошибок по приведенной методике, получим следующий результат:
…
И(&) …
…
Сформированную последовательность нельзя использовать в качестве вектора указанных ошибок, так как она содержит не только две единицы, соответствующие ошибкам в информационных разрядах, но и еще две лишних единицы. Поэтому в общем случае алгоритм формирования вектора ошибок несколько усложняется:
1) инвертируется синдром, полученный в результате обработки принятой последовательности,
2) на один вход логической схемы И с тремя входами подается проинвертированный синдром, на остальные два входа – неинвертированные синдромы, задержанные по сравнению с инвертированным на 2 и 4 такта.
На выходе схемы М получаем требующийся вектор ошибок:
…
И(&) …
…
…
3) просуммировав полученный вектор с задержанной на соответствующее количество тактов последовательностью информационных символов, получим исправленную последовательность:
… | а-5 | а-4 | а-3 | а-2 | а-1 | а1 | а2 | а3 | а4 | ||
Å | … | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | … |
… | а-5 | а-4 | а-3 | а-2 | а-1 |
|
| а3 | а4 | … |
Здесь ![]() и
и ![]() - символы, противоположные соответственно символам а1 и а2.
- символы, противоположные соответственно символам а1 и а2.
3.3.10. Несистематические сверточные коды
Развитие теории сверточных кодов заметно отличалось от развития теории блочных кодов. При построении хороших классов блочных кодов и разработке алгоритмов декодирования весьма существенным оказывается использование алгебраических методов. В случае сверточных кодов это не так. Многие хорошие сверточные коды были найдены просмотром (с помощью ЭВМ) большого числа кодов и последующим выбором кодов с хорошими свойствами. Методов декодирования сверточных кодов, аналогичных алгебраическим методам исправления кратных ошибок, применяемым в блочных кодах, не существует.
В общем случае кодер несистематического сверточного кода представляет собой регистр сдвига с g ячейками и сумматорами, в которых символы входящей последовательности суммируются по модулю 2. За время, в течение которого на вход кодера подается m символов, на выходе образуется n символов. Отношение m/n называется скоростью кода. Величина ![]() называется кодовым ограничением и определяет количество выходных символов, формирующихся с участием одного и того же входного символа. Кодовое ограничение играет примерно ту же роль, что длина кодовой комбинации в блочных кодах.
называется кодовым ограничением и определяет количество выходных символов, формирующихся с участием одного и того же входного символа. Кодовое ограничение играет примерно ту же роль, что длина кодовой комбинации в блочных кодах.
Рассмотрим кратко сверточные коды со скоростью 1/2.
Один из возможных вариантов кодера при g=2 изображен на рис. 3.3.
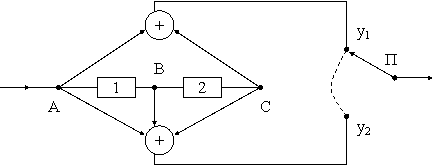 |
Рис. 3.3
В течение каждого такта на вход (в точку А) подается один символ кодируемой последовательности, а на выход поступают два символа у1 и у2, снимаемые с помощью переключателя П:
у1=аАÅаС; у2=аАÅаВÅаС.
Например, при подаче на вход последовательности 1000000... на выходе будет формироваться последовательность ... Легко убедиться, что в общем случае выходная последовательность является суммой по модулю 2 последовательностей, соответствующих каждой единице кодируемой последовательности.
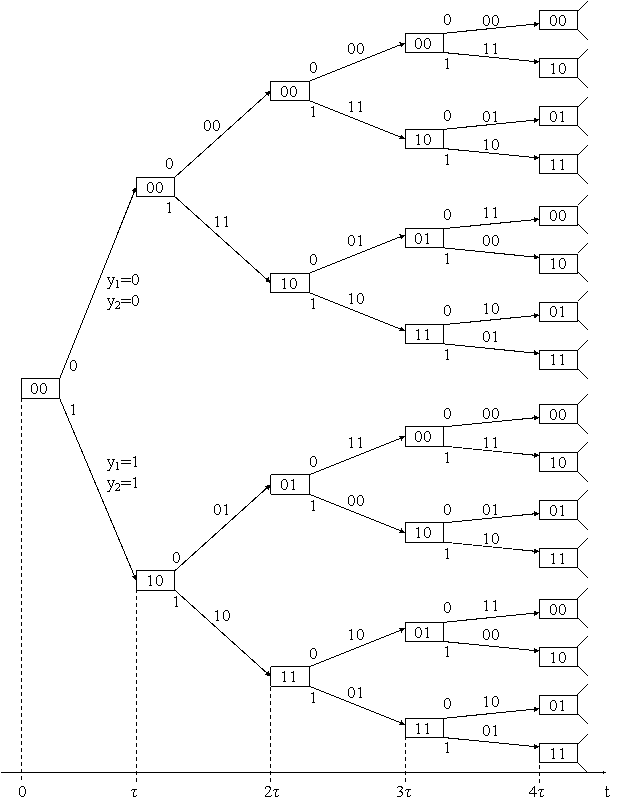 Связь между входными и выходными последовательностями удобно представить в виде кодового дерева, изображенного на рис. 3.4.
Связь между входными и выходными последовательностями удобно представить в виде кодового дерева, изображенного на рис. 3.4.
Рис. 3.4
В настоящее время известно несколько методов декодирования сверточных несистематических кодов: порогового, многопорогового, последовательного и по максимуму правдоподобия (алгоритм Витерби). Алгоритм Витерби обеспечивает большие достоверности и быстродействие, чем все существующие алгоритмы для каналов со средним и высоким уровнями шумов и в настоящее время признан одним из существующих принципов построения декодеров. Поэтому в данном курсе при изучении сверточных несистематических кодов достаточно ознакомиться с алгоритмом декодирования Витерби.
Для понимания принципа построения декодера, реализующего алгоритм Витерби, построим диаграмму состояний выходов кодера в зависимости от значений входных сигналов. Диаграмма показана на
рис. 3.4 и представляет собой дерево сверточного кода. В диаграмме использованы следующие обозначения. В прямоугольниках проставлены значения сигналов, имеющих место в точках В и С кодера (см. рис. 3.3) в течение каждого такта длительностью τ; знаки 0 и 1 у каждой стрелки на каждом ребре - символы кодируемой последовательности на входе кодера; у1 и у2 - символы на выходах кодера в течение соответствующего такта, т. е. формируемой кодовой последовательности.
Формирование кодовой последовательности, т. е. процесс кодирования, можно проследить, двигаясь по соответствующим ребрам кодового дерева (рис. 3.4). Например, при подаче на вход последовательности 111111... необходимо двигаться по нижним ветвям дерева. В результате формируется выходная последовательность ...
Из структуры дерева видно, что, начиная с 4-го такта, в ветвях появляется периодичность: верхнее ребро идентично 5-му, 2-е - 6-му и т. д. В 5-м такте таких идентичных ребер уже по четыре, в 6-м - по восемь и т. д. Это означает, что при сохранении всех свойств дерева его можно преобразовать в решетку, показанную на рис. 3.5. Этой решеткой и воспользуемся для пояснения алгоритма декодирования Витерби.
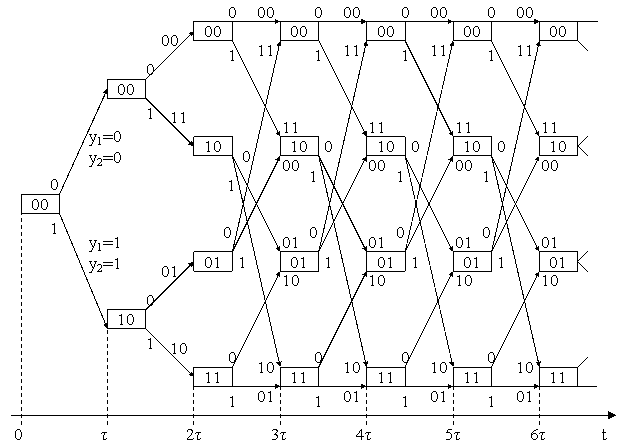
Рис. 3.5
Ошибки в данном случае исправляются по принципу наименьшего расстояния Хэмминга, т. е. наименьшего числа несовпадений в сравниваемых последовательностях. Для наглядности рассмотрим конкретный призер. Пусть переданная последовательность имеет вид ..., а принята последовательность ... В соответствии с рис. 5 при поступлении на вход кодера символа 1 на его выходе появится последовательность 11, а при подаче на вход 0 - последовательность 00. Принята же последовательность 01, следовательно, имеет место ошибка. Используем для исправления ошибки кодовую решетку (рис. 3.5). Будем называть весом W этапа декодирования количество единиц, получаемое при суммировании по модулю 2 принятой двухразрядной двоичной последовательности и двоичной последовательности, указываемой каждым ребром решетки для данного этапа.
В нашем случае для первого этапа
00 11
Å 01 Å 01
01, т. е. вес W11 = 1, 10, т. е. вес W12 = 1
На втором этапе происходит 4 сравнения:
00
Å 00 Å 11 Å 10 Å 01
00
W21 = 0 W22 = 2 W23 = 1 W24 = 1
Суммарный вес каждого двухэтапного пути
WΣ1=W11+W21=1; WΣ2=W11+W22=3; WΣ3=W12+W23=2; WΣ4=W12+W24=2.
Далее на каждом этапе, начиная с 3-го, из двух ребер, идущих к одному узлу, необходимо отбрасывать ребро, соответствующее пути с большим суммарным весом. В конечном итоге на каком-то этапе будут отброшены все пути, кроме одного. Тогда принимается решение о приеме последовательности, соответствующей этому пути. Например, при декодировании принятой комбинации ... после 12-го этапа декодирования оставшиеся нотброшенными пути имеют вид, показанный на рис. 3.6.
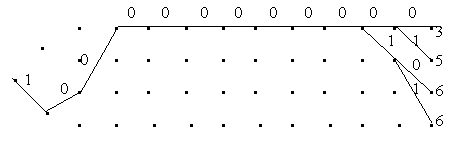 |
Рис. 3.6
Здесь числами указаны веса соответствующих вариантов.
Из рисунка видно, что на первых девяти этапах декодирования все пути слились в один, т. е. декодируемые символы определены однозначно и записываются так: ...
Глубина декодирования, т. е. количество этапов, после которого остается только один путь, не может быть определена заранее: это случайная величина, зависящая от числа разрядов, в которых произошла ошибка. Поэтому при практической реализации декодера устанавливается фиксированная глубина декодирования. Так, в примере, показанном на рис. 6, при необходимости принимать решение после 13 этапов в качестве правильной была бы выбрана верхняя ветвь, соответствующая минимальному суммарному весу WΣ=3, т. е. декодированная последовательность выглядела бы так: ...
Рассмотренный конкретный вид кода исправляет одиночные в двойные ошибки при декодировании с учетом не менее 12 символов, т. е. при вынесении решения не раньше, чем через 12 этапов.
Задание для самостоятельной работы:
После изучения теории несистематических сверточных кодов необходимо научиться кодировать и декодировать кодовые последовательности кодом Финка-Хагельбергера, используя кодовую решетку (см. рис. 3.5).
В достаточном объеме теория сверточных кодов изложена в [3, 4].
3.3.11. Эффективность корректирующих кодов
Эффективность корректирующих кодов оценивается различными способами. В качестве критерия эффективности часто используют обеспечиваемую кодом достоверность передачи информации при фиксированной скорости передачи информации, средней мощности сигнала, неизменных свойствах помехи. В этом случае сравниваются вероятности ошибок при работе корректирующим и безызбыточным кодами при одинаковых мощностях сигналов, продолжительностях передачи и статистических свойствах помехи.
Например, в бинарном канале с амплитудной манипуляцией при помехе в виде белого шума в случае, когда отношение сигнал/помеха
![]()
(ЕС - энергия элементарного сигнала, N0 - плотность энергетического спектра белого шума, беэызбыточный блочный код с n=5 дает при оптимальном приеме, ту же вероятность ошибок Рош=0,20, что и циклический код 15,5, а при отношении С/П<1 применение корректирующего кода ухудшает помехоустойчивость передачи информации. Это объясняется тем, что переход на корректирующий код требует при неизменной общей длительности передачи информации уменьшения длительности элементарного сигнала, что уменьшает отношение сигнал/помеха 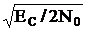 , а то приводит при малых значениях С/П к резкому возрастанию вероятности ошибочного приема каждого элементарного сигнала, а следовательно, и к возрастанию вероятности кратных ошибок, не исправляемых корректирующим кодом.
, а то приводит при малых значениях С/П к резкому возрастанию вероятности ошибочного приема каждого элементарного сигнала, а следовательно, и к возрастанию вероятности кратных ошибок, не исправляемых корректирующим кодом.
3.3.12. Арифметические коды
Среди цифровой информации большое место занимает числовая. Результаты измерений физических величин, большая часть экономической и документальной информации представляется в числовой форме. В некоторых случаях для обнаружения и исправления ошибок при передаче и обработке числовой информации могут быть применены общие метода теории кодирования. Однако более эффективным оказывается использование специальных методов кодирования числовой информации. Так, для контроля работа различных устройств ЭВМ и в первую очередь правильности выполнения арифметических операций в процессорах, в особенности процессов суммирования, применяются специальные арифметические коды.
Рассмотрим арифметические АN-коды. АN-коды пригодны для обнаружения и исправления ошибок при суммировании и записи чисел в случае, если речь идет о конечном множестве целых чисел. Для возможности обнаруживать ошибки нужно, чтобы при проведении операций не все числа были разрешенными. Тогда появление неразрешенного числа и будет признаком наличия ошибки.
Ограничимся рассмотрением случая, когда числа записываются в бинарной форме, что чаще всего бывает в ЭВМ. Если при операциях использовать числа не в естественном виде, а предварительно умноженные на некоторое число А, называемое генератором, причем в качестве генератора взять простое число (делящееся на единицу и на самое себя), в результате суммирования, вычитания или умножения получится число, делящееся на А без остатка. Если же по каким-либо причинам в одном из разрядов числа произойдет ошибка (вместо нуля будет записана единица или наоборот), то такое число не будет делиться на А без остатка. Следовательно, наличие остатка при делении числа на А может быть признаком ошибки в записи числа. Более того, при соблюдении определенных условий ошибки в разных разрядах будут приводить к остаткам разной величины. Тогда по значению остатка можно будет судить однозначно о номере разряда, в котором произошла ошибка, а следовательно, исправлять ее.
Приведем простейшие примеры, по которым можно проследить методику построения AN-кодов.
Пример. Примем значение генератора А=19. Определим значения остатков при наличии одиночной ошибки в разных разрядах. Ошибка в одном и том же разряде в виде перехода 1 в 0 (1→0) и 0 в 1 (0→1) приводят к разным значениям остатков, поэтому учтем оба варианта. Результаты расчетов запишем в таком виде:
номер разряда | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | |
0→1 | 17 | 18 | 9 | 14 | 7 | 13 | 16 | 8 | 4 | 2 | 1 | ü ý остатки þ |
1→0 | 2 | 1 | 10 | 5 | 12 | 6 | 3 | 11 | 15 | 17 | 18 |
Полученные результаты позволяют сделать следующие выводы. Вели исследуемое число AN имеет количество разрядов не более девяти, то такой код может обнаруживать и исправлять все одиночные ошибки, так как при ошибках в пределах этих разрядов значения остатков не повторяются.
Начиная с 10-го разряда значения остатков повторяются (например, ошибка вида 0→1 в 10-м разряде дает такой же остаток, как и 1→0 в 1-м разряде).
Анализируя приведенные данные, нетрудно убедиться, что кратные ошибки могут и не быть обнаруженными рассматриваемым кодом. Например, ошибки вида 0→1 в 11-м и 2-м разрядах дадут сумму остатков, равную 19, т. е. А; следовательно, число с ошибками в указанных разрядах делится на А без остатка. Если же исследуемое число имеет количество разрядов не более девяти, то данный код обнаруживает все одиночные и двойные ошибки, поскольку в пределах этих разрядов никакие два остатка не дают сумму, равную А=19.
Таким образом, АN-код с A=19 может применяться для исправления одиночных или для обнаружения двойных ошибок, если проверяемое число АN имеет не более девяти двойных разрядов, а также для обнаружения одиночных ошибок, если число разрядов больше девяти.
Наибольшее число из множества, в котором при А=19 исправляются все одиночные ошибки, равно , т. е. 511. Следовательно. наибольшее число из множества чисел, подлежащего кодированию
Nmax = ANmax : A = 511 : 19 = 26 (целая часть частного).
Для увеличения множества чисел, при котором код выполняет свои функции, необходимо соответственно увеличивать значение генератора А. Можно показать, что применение в качестве генератора не простого числа приводит к резкому уменьшению разнообразия значений остатков, т. е. к уменьшению разрядности чисел, которые можно закодировать таким кодом при сохранении корректирующих свойств последнего.
Как уже указывалось, кодирование при использовании AN-кода сводится к умножению исходного числа N на заранее выбранное значение генератора А.
В простейшем случае ошибки исправляются следующим образом. Предварительно в память декодера заносятся все значения остатков, играющих роль синдромов ошибок. Декодируемое число делится на значение генератора А, и остаток сравнивается со значениями, заложенными в память. По определенному таким образом значению разряда, в котором обнаружена ошибка, формируется вектор ошибки, который затем суммируется по модулю 2 с декодируемым числом. Если в конечном итоге число необходимо представить в исходном виде, полученное после исправления число АN делится на А.
При работе с многоразрядными числами приведенный метод декодирования становится технически сложным, так как требуется большой объем памяти для запоминания синдромов и усложняется схема сравнения полученного остатка с таблицей остатков. В настоящее время в этом случав используются более сложные варианты АN-кодов (например, циклические), в которых процедура декодирования и исправления ошибок более проста.
Существуют варианты АN-кодов, исправляющих не только одиночные, но и кратные ошибки.
Литература:
[1] стр. 256-260. [2] стр. 297-306. [3] стр. 152-154.
Контрольные вопросы:
1. Чем определяется количество (массив) чисел, к которым применим конкретный вариант AN-кода, исправляющего одиночные ошибки?
2. Почему в качестве порождающего числа в AN-кодах применяются только просто числа?
3. Может ли AN-код использоваться для проверки правильности деления чисел или записи чисел после деления?
Задачи:
1. Построить таблицу остатков AN-кода по заданному значению порождающего числа А.
2. Задано кодируемое число N и порождающее число А. Необходимо закодировать число N данным кодом AN.
3. Задано значение порождающего числа А. Произвести декодирование числа и записать получившееся число в десятичной форме (N10).
Пример: А=19, AN=1100111. Произвести декодирование.
Ответ: AN=1 N10=95.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
