
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Московский государственный институт электроники и математики
(Технический Университет)
Управление распределенными ресурсами ОС.
Выполнили:
Группа: С-85
Проверил : д. т.н. профессор
Москва 2008
Аннотация:
Создание единой технологической системы хранения, поиска и обработки информации на основе распределенных информационно-вычислительных ресурсов является одной из важнейших задач интеграции научных исследований, проводимых различными коллективами. В рамках этой задачи помимо проблем модификации первичных информационно-вычислительных ресурсов организаций в направлении их интеграции в единое информационно-вычислительное пространство, стоит проблема разработки основных принципов организации таких ресурсов с целью их эффективного использования. Соответствующая распределенная система организации данных и ресурсов требует создания служб, обеспечивающих публикацию ресурсов, поддержку их качества и аутентичности; поиск информации и доступ к метаданным; единый доступ к разнородным информационным и вычислительным ресурсам; контроль аутентификации и разграничение доступа; мониторинг ресурсов, анализ их загруженности и эффективности использования; распределенное выполнение запросов и анализ распределенных данных.
Эти механизмы должны составлять основу системы усвоения данных – превращения информации в систему электронных библиотек данных, метаданных, алгоритмов и программ, вычислительных ресурсов. Создаваемые технологии должны предоставлять возможности для точного и адекватного удовлетворения потребностей пользователей, формально обращающихся к одному и тому же ресурсу. Комбинация возможности доступа к данным через базу метаданных, службы каталогов и зарегистрированный набор
Оглавление
Аннотация: 2
Распределенные информационно-вычислительные ресурсы.. 4
Операционные системы для вычислительных комплексов. 4
Распределенные файловые системы.. 5
Примеры распределенных файловых систем.. 5
Проблемы администрации распределенных файловых систем. 7
Поддержка автономной работы с распределенными данными. 8
Расширение файловых систем с помощью Web. 9
Управление распределенными ресурсами в ОС UNIX. 10
Взаимодействие между процессами в UNIX. 10
Разделяемая память. 12
Семафоры.. 13
Очереди сообщений. 15
Программные каналы.. 18
Программные гнезда (sockets). 19
Вызов удаленных процедур. 23
Принципы организации многопользовательского режима. 31
Понятие нити (threads). 34
Подходы к организации нитей и управлению ими в разных вариантах ОС UNIX. 35
Вывод. 38
Литература. 39
Распределенные информационно-вычислительные ресурсы
Интеграция информационных и вычислительных ресурсов в единую среду и организация доступа к ним является одним из важнейших направлений развития современных информационных технологий. Стремительное развитие глобальных информационных и вычислительных сетей ведет к изменению фундаментальных парадигм обработки данных вследствие необходимости поддержки и развития распределенных информационно-вычислительных ресурсов. Технологии их использования получают все больший приоритет в современном информационном обществе. При этом наблюдаются тенденции к исключительно распределенной схеме создания, поддержания и хранения ресурсов, так как эффективная эксплуатация информационных ресурсов возможна только при постоянной поддержке со стороны их авторов и создателей. В то же время существует стремление к виртуальному объединению информационных и вычислительных ресурсов на уровне предоставления доступа к ним. Таким образом, можно постулировать принцип формирования на базе ресурсов сети единого поля компьютерной информации и ресурсов, способного стать универсальным и машинонезависимым носителем данных и средством их обработки.
Для организации единой среды информационных и вычислительных ресурсов были разработаны специальные операционные системы: сетевые и распределенные операционные системы.
Операционные системы для вычислительных комплексов
Существует два основных подхода к организации операционных систем для вычислительных комплексов, связанных в сеть, – это сетевые и распределенные операционные системы. Необходимо отметить, что терминология в этой области еще не устоялась. В одних работах все операционные системы, обеспечивающие функционирование компьютеров в сети, называются распределенными, а в других, наоборот, сетевыми. Мы придерживаемся той точки зрения, что сетевые и распределенные системы являются принципиально различными.
В сетевых операционных системах для того, чтобы задействовать ресурсы другого сетевого компьютера, пользователи должны знать о его наличии и уметь это сделать. Каждая машина в сети работает под управлением своей локальной операционной системы, отличающейся от операционной системы автономного компьютера наличием дополнительных сетевых средств (программной поддержкой для сетевых интерфейсных устройств и доступа к удаленным ресурсам), но эти дополнения существенно не меняют структуру операционной системы.
Распределенная система, напротив, внешне выглядит как обычная автономная система. Пользователь не знает и не должен знать, где его файлы хранятся, на локальной или удаленной машине, и где его программы выполняются. Он может вообще не знать, подключен ли его компьютер к сети. Внутреннее строение распределенной операционной системы имеет существенные отличия от автономных систем.
Распределенные файловые системы
Ключевым компонентом любой распределенной системы является файловая система. Как и в централизованных системах, в распределенной системе функцией файловой системы является хранение программ и данных и предоставление доступа к ним по мере необходимости. Файловая система поддерживается одной или более машинами, называемыми файл-серверами. Файл-серверы перехватывают запросы на чтение или запись файлов, поступающие от других машин (не серверов). Эти другие машины называются клиентами. Каждый посланный запрос проверяется и выполняется, а ответ отсылается обратно. Файл-серверы обычно содержат иерархические файловые системы, каждая из которых имеет корневой каталог и каталоги более низких уровней. Рабочая станция может подсоединять и монтировать эти файловые системы к своим локальным файловым системам. При этом монтируемые файловые системы остаются на серверах.
Важно понимать различие между файловым сервисом и файловым сервером. Файловый сервис - это описание функций, которые файловая система предлагает своим пользователям. Это описание включает имеющиеся примитивы, их параметры и функции, которые они выполняют. С точки зрения пользователей файловый сервис определяет то, с чем пользователи могут работать, но ничего не говорит о том, как все это реализовано. В сущности, файловый сервис определяет интерфейс файловой системы с клиентами.
Файловый сервер - это процесс, который выполняется на отдельной машине и помогает реализовывать файловый сервис. В системе может быть один файловый сервер или несколько, но в хорошо организованной распределенной системе пользователи не знают, как реализована файловая система. В частности, они не знают количество файловых серверов, их месторасположение и функции. Они только знают, что если процедура определена в файловом сервисе, то требуемая работа каким-то образом выполняется, и им возвращаются требуемые результаты. Более того, пользователи даже не должны знать, что файловый сервис является распределенным. В идеале он должен выглядеть также, как и в централизованной файловой системе.
Так как обычно файловый сервер - это просто пользовательский процесс (или иногда процесс ядра), выполняющийся на некоторой машине, в системе может быть несколько файловых серверов, каждый из которых предлагает различный файловый сервис. Например, в распределенной системе может быть два сервера, которые обеспечивают файловые сервисы систем UNIX и MS-DOS соответственно, и любой пользовательский процесс пользуется подходящим сервисом.
Файловый сервис в распределенных файловых системах (впрочем, как и в централизованных) имеет две функционально различные части: собственно файловый сервис и сервис каталогов. Первый имеет дело с операциями над отдельными файлами, такими, как чтение, запись или добавление, а второй - с созданием каталогов и управлением ими, добавлением и удалением файлов из каталогов и т. п.
Примеры распределенных файловых систем
Распределенные файловые системы OpenAFS и Coda имеют собственные механизмы управления разделами, которые упрощают возможности хранения общедоступной информации. Они так же поддерживают дублирование способность делать копии разделов и сохранять их на других файловых серверах. Если один файловый сервер становится недоступным, то все равно к данным, хранящимся на его разделах, можно получить доступ с помощью имеющихся резервных копий этих разделов.
Самое главное различие между подходом Windows MacOS (совместное использование каталогов и дисков) и подходом Linux, MacOS X и других Unix-подобных многопользовательских операционных систем в том, как эти операционные системы используют и организовывают разделы. Windows MacOS экспортируют разделы как отдельные каталоги или диски, и удаленные системы, которые хотят обратиться к общедоступным устройствам, должны обязательно подключить их к себе.
Когда самый высокий уровень организации в файловой системе это раздел диска (например, как в файловых системах Windows), рабочие станции клиентов для получения доступа к этим данным должны обязательно подключиться к разделу и назначить ему отдельную букву в своей локальной раскладке (например, диск E, F, G, и т. д). Буквы могут быть назначены сетевым разделам в пользовательских и групповых профилях Windows (для стандартизации). Но, к сожалению, не на всех компьютерах расположение букв может быть одинаковым. Например, на компьютере с большим количеством жестких дисков и разделов нужные буквы могут быть заняты, и поэтому придется давать сетевым разделам другие обозначения.
Напротив, файловая система Unix это иерархическая файловая система, к которой дополнительные разделы добавляются с помощью монтирования их к существующей директории. Это позволяет эффективно добавить любой источник данных в любую существующую файловую систему.
После выполнения этой процедуры файлы, хранимые в удаленной файловой системе, доступны процессам локального компьютера точно таким же образом, как если бы они хранились на локальном дисковом устройстве.
На рисунке 2.5 приведен пример, в котором два подкаталога удаленной файловой системы-сервера (share и X11) монтируются к двум (пустым) каталогам файловой системы-клиента.
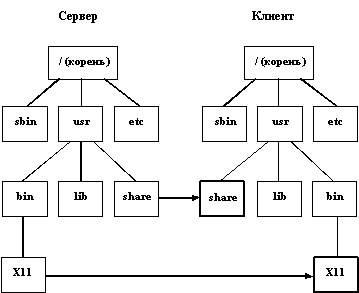
Рис. 1. Схема монтирования удаленной файловой системы
В принципе, такая схема обладает и достоинствами, и недостатками. К достоинствам, конечно, относится то, что при работе в сети можно экономить дисковое пространство, поддерживая совместно используемые информационные ресурсы только в одном экземпляре. Но, с другой стороны, пользователи удаленной файловой системы неизбежно будут работать с удаленными файлами существенно более медленно, чем с локальными. Кроме того, реальная возможность доступа к удаленному файлу критически зависит от работоспособности сервера и сети. Заметим, что распространенные в мире UNIX сетевые файловые системы NFS (Network File System - сетевая файловая система) и RFS (Remote File Sharing - совместное использование удаленных файлов) являются достаточно тщательно спроектированными и разработанными продуктами, во многом сглаживающими отмеченные недостатки.
Современные распределенные файловые системы типа OpenAFS или Coda включают в себя специальные сервисы для управления разделами. Это позволяет вам смонтировать разделы различных файловых серверов в центральную иерархию директорий, поддерживаемую файловыми системами. OpenAFS использует центральный каталог, называемый «/afs», а Coda использует «/coda». Эти иерархии директорий доступны всем клиентам распределенной файловой системы, и выглядят одинаково на любой из клиентских рабочих станций. Это дает возможность пользователям работать со своими файлами одинаково на любом компьютере. Если ваш настольный компьютер не работает, вы совершенно спокойно можете использовать любой другой все ваши файлы находятся в безопасности на сервере.
Распределенные файловые системы, предоставляющие одни и те же данные многим различным компьютерным системам, дают пользователям возможность использовать любую операционную систему, лучше всего подходящую для их задач. Пользователи Macintosh могут пользоваться всеми преимуществами графических инструментальных средств, доступных в Mac OS, и одновременно хранить свои данные на централизованных файловых серверах. Пользователи Windows так же могут иметь доступ к устойчивой глобальной файловой системе. Распределенные файловые системы особенно привлекательны при попытке координации работы между группами, расположенными в различных городах, государствах, или даже в разных странах. Преимущество общие данные всегда доступны по сети, независимо от вашего местонахождения.
Проблемы администрации распределенных файловых систем.
Использование распределенных файловых систем дает системным администраторам не только новые возможности, но и новые проблемы. Но распределенные системы способны упростить многие из стандартных административных задач. В сетевой среде пользователи должны иметь возможность зайти в сеть под своим именем с любого компьютера. Это значит, что механизм входа в сеть (или аутентификации) тоже должен быть сетевым. Поэтому в среде распределенной файловой системы файлы групп и паролей, расположенные на индивидуальных компьютерах, вторичны по отношению к сетевым механизмам аутентификации (таким, как Kerberos или NIS, которые предоставляют пользователям возможность работать на любом компьютере). Но стандартные локальные механизмы проверки пароля все же должны существовать, чтобы администраторы могли выполнять на локальных компьютерах необходимые задачи.
Сохранение общих данных на централизованных файловых серверах (а не на индивидуальных компьютерах) упрощает такие административные задачи, как резервирование и восстановление файлов и каталогов. Это так же централизует такие стандартные административные задачи, как контроль за использованием файловой системы, и представляет новые возможности управления хранением данных например, балансирование загрузки.
Распределенные файловые системы типа OpenAFS и Coda обеспечивают встроенные логические системы управления разделами, которые дают администраторам возможность переместить интенсивно используемые данные на более мощные или менее используемые компьютеры. Если распределенная файловая система поддерживает дублирование, копии интенсивно используемых данных могут распределяться между многими файловыми серверами. Это может уменьшить нагрузку на сеть, и облегчить работу серверов. Распределенные файловые системы используют логические разделы вместо физических дисковых разделов, и это позволяет легко добавить в сеть новую свободную память прямо во время работы. (Для добавления нового диска в локальный компьютер пришлось бы потратить некоторое время).
Использование распределенных файловых систем так же облегчает возможность совместного доступа к программному и аппаратному обеспечению. Но перед этим нужно удостовериться, что лицензии к используемым программам разрешают установку программного обеспечения в распределенной файловой системе. Сервера печати одна из первоначальных причин появления среды «клиент-сервер». Распределенные файловые системы так же упрощают совместный доступ к специализированным аппаратным средствам, соединяясь по сети с компьютером, на котором установлены нужные аппаратные средства, и при этом все еще имея доступ к вашим данным.
Использование централизованной распределенной файловой системы может обеспечивать существенные преимущества в стоимости и быстродействии выполнения работы для клиентских систем. Распределенные файловые системы существенно уменьшают аппаратные затраты, минимизируя количество памяти на любом десктопе или ноутбуке. Использование распределенной файловой системы в качестве архива для пользовательских данных обычно означает более быструю загрузку клиентских машин, потому что большое количество данных больше не хранится локально и поэтому не нуждается в проверке после перезапуска клиента. Комбинация распределенной файловой системы и использования журналируемых файловых систем на клиентских компьютерах может дать значительное увеличение скорости запуска системы.
Поддержка автономной работы с распределенными данными.
Использование распределенной файловой системы увеличивает зависимость компьютерных систем от сети. Эта зависимость от данных, к которым люди могут обращаться только по сети, вызывает некоторые интересные проблемы для пользователей лаптопов/мобильных компьютеров, которые нуждаются в доступе к своим данным даже тогда, когда доступ к сети невозможен. Это называется «автономная работа» система должна функционировать, если ресурсы, которые обычно присутствуют в сети (например, пользовательские данные), по каким-то причинам не доступны. Даже Windows обеспечивает графический интерфейс для возможности маркировки файлов, с которыми вы хотите работать, когда вы отключены от сети, и для синхронизации этих файлов, когда вы соединяетесь повторно.
Распределенные файловые системы Coda и InterMezzo, которые являются в настоящее время доступными для Linux, тоже обеспечивают интегрированную поддержку для автономной работы. Так же сейчас ведется работа над обеспечением этой возможности для файловых систем NFS. Coda и InterMezzo уже поддерживаются ядром Linux.
Coda - распределенная файловая система с происхождением из OpenAFS, которая разрабатывается в университете Carnegie Mellon с 1987 года. InterMezzo относительно новая распределенная файловая система, упор в разработке которой сделан на высокой доступности, гибком дублировании каталогов, поддержке автономных операций, и постоянном кэшировании.
Расширение файловых систем с помощью Web.
До создания распределенных файловых систем совместное использование файлов через сеть ограничивалось простыми передачами файлов с помощью использования протокола передачи файлов FTP (File Transfer). Появление Всемирной паутины в значительной степени упростила процесс работы с FTP теперь не нужно знать команды, потому что протокол FTP интегрирован в большинство браузеров. Способность легко передавать файлы через Web также вела к расширению Паутины и существенному улучшению основного протокола передачи гипертекста HTTP (HyperText Transfer Protocol), который сейчас является основанием для многих систем распределенного использования файлов.
Самая известная из них это WebDAV, которая расшифровывается как «Web-система распределенной авторизации и контроля версий» (Web-enabled Distributed Authoring and Versioning). WebDAV это набор расширений к протоколу HTTP, обеспечивающий совместную среду для пользователей, которая позволяет им скачивать, упорядочивать и редактировать файлы, хранящиеся на Web-серверах.
Поддержка WebDAV встроена во многие популярные Web-серверы, например Apache, где это основывается на опознавательных механизмах сервера. (От простых файлов. htaccess до интегрированных NIS, LDAP, или даже механизма аутентификации Windows). Использование WebDAV для доступа и модификации файлов через Web встроено в операционные системы Mac OS X, в новые версии Microsoft Internet Explorer, а так же доступно и в Linux при использовании таких приложений, как менеджер файлов Nautilus. Хотя это и не файловая система в традиционном смысле, но вы можете даже смонтировать WebDAV в Линуксе, используя загружаемый модуль ядра под названием davfs.
WebDAV обеспечивает такие стандартные для распределенных систем возможности, как блокировка файлов, создание, переименование, копирование, удаление файлов, а так же поддерживает такие продвинутые возможности, как метаданные файла (более подробная информация о файле заголовок, тема, создатель, и т. д). В ближайшем будущем WebDAV будет включать интегрированную поддержку управления версиями, которая упростит работу многих пользователей над общими файлами, отслеживая изменения, авторов этих изменений, и другие аспекты общего использования документа. Эти возможности контроля над версиями обеспечиваются в соответствии с протоколом DeltaV, который активно разрабатывается Рабочей группой DeltaV подразделением Проектировочной группы Интернета (IETF Internet Engineering Task Force). Некоторые проекты, например, Subversion (WebDAV и DeltaV-основанная замена стандарту CVS), уже доступны в альфа-версии. Subversion обеспечивает систему контроля над версиями и сохранение архива файла на основе базы данных, имеющей API языка C, и моделирует версионную файловую систему, легкодоступную через Web.
Управление распределенными ресурсами в ОС UNIX
UNIX является примером исключительно удачной реализации простой мультипрограммной и многопользовательской операционной системы. В свое время она проектировалась как инструментальная система для разработки программного обеспечения. UNIX, прежде всего, обладает простым, но очень мощным командным языком и независимой от устройств файловой системой. Поскольку при создании этой ОС использовался язык высокого уровня, на котором пишутся не только системные, но и прикладные программы (речь идет о языке С), то система и приложения, выполняющиеся в ней, получились легко переносимыми (мобильными). Компилятор с языка С для всех оттранслированных программ дает реентерабельный и разделяемый код, что позволяет эффективно использовать имеющиеся в системе ресурсы. ОС UNIX в своей основе наиболее полно отвечает требованиям технологии «клиент-сервер». Единственным по-настоящему важным отличием распределенных систем от централизованных является способ взаимодействия между процессами.
Взаимодействие между процессами в UNIX
Каждый процесс в ОС UNIX выполняется в собственной виртуальной памяти, т. е. если не предпринимать дополнительных усилий, то даже процессы-близнецы, образованные в результате выполнения системного вызова fork(), на самом деле полностью изолированы один от другого (если не считать того, что процесс-потомок наследует от процесса-предка все открытые файлы). Тем самым, в ранних вариантах ОС UNIX поддерживались весьма слабые возможности взаимодействия процессов, даже входящих в общую иерархию порождения (т. е. имеющих общего предка).
Очень слабые средства поддерживались и для взаимной синхронизации процессов. Практически, все ограничивалось возможностью реакции на сигналы, и наиболее распространенным видом синхронизации являлась реакция процесса-предка на сигнал о завершении процесса-потомка.
По-видимому, применение такого подхода являлось реакцией на чрезмерно сложные механизмы взаимодействия и синхронизации параллельных процессов, существовавшие в исторически предшествующей UNIX ОС Multics. В ОС Multics поддерживалась сегментно-страничная организация виртуальной памяти, и в общей виртуальной памяти могло выполняться несколько параллельных процессов, которые, естественно, могли взаимодействовать через общую память. За счет возможности включения одного и того же сегмента в разную виртуальную память аналогичная возможность взаимодействий существовала и для процессов, выполняемых не в общей виртуальной памяти.
Для синхронизации таких взаимодействий процессов поддерживался общий механизм семафоров, позволяющий, в частности, организовывать взаимное исключение процессов в критических участках их выполнения (например, при взаимно-исключающем доступе к разделяемой памяти). Этот стиль параллельного программирования в принципе обеспечивает большую гибкость и эффективность, но является очень трудным для использования. Часто в программах появляются трудно обнаруживаемые и редко воспроизводимые синхронизационные ошибки; использование явной синхронизации, не связанной неразрывно с теми объектами, доступ к которым синхронизуется, делает логику программ трудно постижимой, а текст программ - трудно читаемым.
Понятно, что стиль ранних вариантов ОС UNIX стимулировал существенно более простое программирование. В наиболее простых случаях процесс-потомок образовывался только для того, чтобы асинхронно с основным процессом выполнить какое-либо простое действие (например, запись в файл). В более сложных случаях процессы, связанные иерархией родства, создавали обрабатывающие "конвейеры" с использованием техники программных каналов (pipes). Эта техника особенно часто применяется при программировании на командных языках.
Долгое время отцы-основатели ОС UNIX считали, что в той области, для которой предназначался UNIX (разработка программного обеспечения, подготовка и сопровождение технической документации и т. д.) этих возможностей вполне достаточно. Однако, постепенное распространение системы в других областях и сравнительная простота наращивания ее возможностей привели к тому, что со временем в разных вариантах ОС UNIX в совокупности появился явно избыточный набор системных средств, предназначенных для обеспечения возможности взаимодействия и синхронизации процессов, которые не обязательно связаны отношением родства (в мире ОС UNIX эти средства обычно называют IPC от Inter-Process Communication Facilities). С появлением UNIX System V Release 4.0 (и более старшей версии 4.2) все эти средства были узаконены и вошли в фактический стандарт ОС UNIX современного образца.
Нельзя сказать, что средства IPC ОС UNIX идеальны хотя бы в каком-нибудь отношении. При разработке сложных асинхронных программных комплексов (например, систем реального времени) больше всего неудобств причиняет избыточность средств IPC. Всегда возможны несколько вариантов реализации, и очень часто невозможно найти критерии выбора. Дополнительную проблему создает тот факт, что в разных вариантах системы средства IPC реализуются по-разному, зачастую одни средства реализованы на основе использования других средств. Поэтому эффективность реализации различается, из-за чего усложняется разработка мобильных асинхронных программных комплексов.
Тем не менее, знать возможности IPC, безусловно, нужно, если относиться к ОС UNIX как к серьезной производственной операционной системе. В этом разделе мы рассмотрим основные стандартизованные возможности в основном на идейном уровне, не вдаваясь в технические детали.
Порядок рассмотрения не отражает какую-либо особую степень важности или предпочтительности конкретного средства. Мы начинаем с пакета средств IPC, которые появились в UNIX System V Release 3.0. Этот пакет включает:
· средства, обеспечивающие возможность наличия общей для процессов памяти (сегменты разделяемой памяти - shared memory segments);
· средства, обеспечивающие возможность синхронизации процессов при доступе к совместно используемым ресурсам, например, к разделяемой памяти (семафоры - semaphores);
· средства, обеспечивающие возможность посылки процессом сообщений другому произвольному процессу (очереди сообщений - message queues).
Эти механизмы объединяются в единый пакет, потому что соответствующие системные вызовы обладают близкими интерфейсами, а в их реализации используются многие общие подпрограммы. Вот основные общие свойства всех трех механизмов:
· Для каждого механизма поддерживается общесистемная таблица, элементы которой описывают всех существующих в данный момент представителей механизма (конкретные сегменты, семафоры или очереди сообщений).
· Элемент таблицы содержит некоторый числовой ключ, который является выбранным пользователем именем представителя соответствующего механизма. Другими словами, чтобы два или более процесса могли использовать некоторый механизм, они должны заранее договориться об именовании используемого представителя этого механизма и добиться того, чтобы тот же представитель не использовался другими процессами.
· Процесс, желающий начать пользоваться одним из механизмов, обращается к системе с системным вызовом из семейства "get", прямыми параметрами которого является ключ объекта и дополнительные флаги, а ответным параметром является числовой дескриптор, используемый в дальнейших системных вызовах подобно тому, как используется дескриптор файла при работе с файловой системой. Допускается использование специального значения ключа с символическим именем IPC_PRIVATE, обязывающего систему выделить новый элемент в таблице соответствующего механизма независимо от наличия или отсутствия в ней элемента, содержащего то же значение ключа. При указании других значений ключа задание флага IPC_CREAT приводит к образованию нового элемента таблицы, если в таблице отсутствует элемент с указанным значением ключа, или нахождению элемента с этим значением ключа. Комбинация флагов IPC_CREAT и IPC_EXCL приводит к выдаче диагностики об ошибочной ситуации, если в таблице уже содержится элемент с указанным значением ключа.
· Защита доступа к ранее созданным элементам таблицы каждого механизма основывается на тех же принципах, что и защита доступа к файлам.
Перейдем к более детальному изучению конкретных механизмов этого семейства.
Разделяемая память
Для работы с разделяемой памятью используются четыре системных вызова:
· shmget создает новый сегмент разделяемой памяти или находит существующий сегмент с тем же ключом;
· shmat подключает сегмент с указанным дескриптором к виртуальной памяти обращающегося процесса;
· shmdt отключает от виртуальной памяти ранее подключенный к ней сегмент с указанным виртуальным адресом начала;
· наконец, системный вызов shmctl служит для управления разнообразными параметрами, связанными с существующим сегментом.
После того, как сегмент разделяемой памяти подключен к виртуальной памяти процесса, этот процесс может обращаться к соответствующим элементам памяти с использованием обычных машинных команд чтения и записи, не прибегая к использованию дополнительных системных вызовов.
Синтаксис системного вызова shmget выглядит следующим образом:
shmid = shmget(key, size, flag);
Параметр size определяет желаемый размер сегмента в байтах. Далее работа происходит по общим правилам. Если в таблице разделяемой памяти находится элемент, содержащий заданный ключ, и права доступа не противоречат текущим характеристикам обращающегося процесса, то значением системного вызова является дескриптор существующего сегмента (и обратившийся процесс так и не узнает реального размера сегмента, хотя впоследствии его все-таки можно узнать с помощью системного вызова shmctl). В противном случае создается новый сегмент с размером не меньше установленного в системе минимального размера сегмента разделяемой памяти и не больше установленного максимального размера. Создание сегмента не означает немедленного выделения под него основной памяти. Это действие откладывается до выполнения первого системного вызова подключения сегмента к виртуальной памяти некоторого процесса. Аналогично, при выполнении последнего системного вызова отключения сегмента от виртуальной памяти соответствующая основная память освобождается.
Подключение сегмента к виртуальной памяти выполняется путем обращения к системному вызову shmat:
virtaddr = shmat(id, addr, flags);
Здесь id - это ранее полученный дескриптор сегмента, а addr - желаемый процессом виртуальный адрес, который должен соответствовать началу сегмента в виртуальной памяти. Значением системного вызова является реальный виртуальный адрес начала сегмента (его значение не обязательно совпадает со значением прямого параметра addr). Если значением addr является нуль, ядро выбирает наиболее удобный виртуальный адрес начала сегмента. Кроме того, ядро старается обеспечить (но не гарантирует) выбор такого стартового виртуального адреса сегмента, который обеспечивал бы отсутствие перекрывающихся виртуальных адресов данного разделяемого сегмента, сегмента данных и сегмента стека процесса (два последних сегмента могут расширяться).
Для отключения сегмента от виртуальной памяти используется системный вызов shmdt:
shmdt(addr);
где addr - это виртуальный адрес начала сегмента в виртуальной памяти, ранее полученный от системного вызова shmat. Естественно, система гарантирует (на основе использования таблицы сегментов процесса), что указанный виртуальный адрес действительно является адресом начала (разделяемого) сегмента в виртуальной памяти данного процесса.
Системный вызов shmctl:
shmctl(id, cmd, shsstatbuf);
содержит прямой параметр cmd, идентифицирующий требуемое конкретное действие, и предназначен для выполнения различных функций. Видимо, наиболее важной является функция уничтожения сегмента разделяемой памяти. Уничтожение сегмента производится следующим образом. Если к моменту выполнения системного вызова ни один процесс не подключил сегмент к своей виртуальной памяти, то основная память, занимаемая сегментом, освобождается, а соответствующий элемент таблицы разделяемых сегментов объявляется свободным. В противном случае в элементе таблицы сегментов выставляется флаг, запрещающий выполнение системного вызова shmget по отношению к этому сегменту, но процессам, успевшим получить дескриптор сегмента, по-прежнему разрешается подключать сегмент к своей виртуальной памяти. При выполнении последнего системного вызова отключения сегмента от виртуальной памяти операция уничтожения сегмента завершается.
Семафоры
Для синхронизации процессов, а точнее, для синхронизации доступа нескольких процессов к разделяемым ресурсам, используются семафоры. Семафоры не предназначены для обмена большими объемами данных. Вместо этого, они выполняют функцию, полностью соответствующую своему названию – разрешать или запрещать процессу использование того или иного разделяемого ресурса.
Семафор в ОС UNIX состоит из следующих элементов:
· значение семафора;
· идентификатор процесса, который хронологически последним работал с семафором;
· число процессов, ожидающих увеличения значения семафора;
· число процессов, ожидающих нулевого значения семафора.
Для работы с семафорами поддерживаются три системных вызова:
· semget для создания и получения доступа к набору семафоров;
· semop для манипулирования значениями семафоров (это именно тот системный вызов, который позволяет процессам синхронизоваться на основе использования семафоров);
· semctl для выполнения разнообразных управляющих операций над набором семафоров.
Системный вызов semget имеет следующий синтаксис:
id = semget(key, count, flag);
где прямые параметры key и flag и возвращаемое значение системного вызова имеют тот же смысл, что для других системных вызовов семейства «get», а параметр count задает число семафоров в наборе семафоров, обладающих одним и тем же ключом. После этого индивидуальный семафор идентифицируется дескриптором набора семафоров и номером семафора в этом наборе. Если к моменту выполнения системного вызова semget набор семафоров с указанным ключом уже существует, то обращающийся процесс получит соответствующий дескриптор, но так и не узнает о реальном числе семафоров в группе (хотя позже это все-таки можно узнать с помощью системного вызова semctl).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
