
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Перемещаемые разделы
Одним из методов борьбы с фрагментацией является перемещение всех занятых участков в сторону старших либо в сторону младших адресов, так, чтобы вся свободная память образовывала единую свободную область (рисунок 2.11). В дополнение к функциям, которые выполняет ОС при распределении памяти переменными разделами, в данном случае она должна еще время от времени копировать содержимое разделов из одного места памяти в другое, корректируя таблицы свободных и занятых областей. Эта процедура называется "сжатием". Сжатие может выполняться либо при каждом завершении задачи, либо только тогда, когда для вновь поступившей задачи нет свободного раздела достаточного размера. В первом случае требуется меньше вычислительной работы при корректировке таблиц, а во втором - реже выполняется процедура сжатия. Так как программы перемещаются по оперативной памяти в ходе своего выполнения, то преобразование адресов из виртуальной формы в физическую должно выполняться динамическим способом.
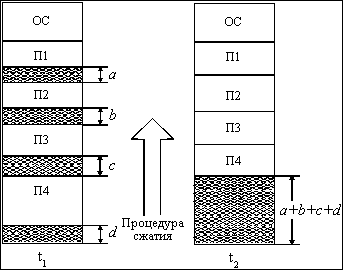
Рис. 2.11. Распределение памяти перемещаемыми разделами
Хотя процедура сжатия и приводит к более эффективному использованию памяти, она может потребовать значительного времени, что часто перевешивает преимущества данного метода.
Вопросы 19, 20, 21.
Понятие виртуальной памяти
Уже достаточно давно пользователи столкнулись с проблемой размещения в памяти программ, размер которых превышал имеющуюся в наличии свободную память. Решением было разбиение программы на части, называемые оверлеями. 0-ой оверлей начинал выполняться первым. Когда он заканчивал свое выполнение, он вызывал другой оверлей. Все оверлеи хранились на диске и перемещались между памятью и диском средствами операционной системы. Однако разбиение программы на части и планирование их загрузки в оперативную память должен был осуществлять программист.
Развитие методов организации вычислительного процесса в этом направлении привело к появлению метода, известного под названием виртуальная память. Виртуальным называется ресурс, который пользователю или пользовательской программе представляется обладающим свойствами, которыми он в действительности не обладает. Так, например, пользователю может быть предоставлена виртуальная оперативная память, размер которой превосходит всю имеющуюся в системе реальную оперативную память. Пользователь пишет программы так, как будто в его распоряжении имеется однородная оперативная память большого объема, но в действительности все данные, используемые программой, хранятся на одном или нескольких разнородных запоминающих устройствах, обычно на дисках, и при необходимости частями отображаются в реальную память.
Таким образом, виртуальная память - это совокупность программно-аппаратных средств, позволяющих пользователям писать программы, размер которых превосходит имеющуюся оперативную память; для этого виртуальная память решает следующие задачи:
l размещает данные в запоминающих устройствах разного типа, например, часть программы в оперативной памяти, а часть на диске;
l перемещает по мере необходимости данные между запоминающими устройствами разного типа, например, подгружает нужную часть программы с диска в оперативную память;
l преобразует виртуальные адреса в физические.
Все эти действия выполняются автоматически, без участия программиста, то есть механизм виртуальной памяти является прозрачным по отношению к пользователю.
Наиболее распространенными реализациями виртуальной памяти является страничное, сегментное и странично-сегментное распределение памяти, а также свопинг.
Страничное распределение
На рисунке 2.12 показана схема страничного распределения памяти. Виртуальное адресное пространство каждого процесса делится на части одинакового, фиксированного для данной системы размера, называемые виртуальными страницами. В общем случае размер виртуального адресного пространства не является кратным размеру страницы, поэтому последняя страница каждого процесса дополняется фиктивной областью.
Вся оперативная память машины также делится на части такого же размера, называемые физическими страницами (или блоками).
Размер страницы обычно выбирается равным степени двойки: 512, 1024 и т. д., это позволяет упростить механизм преобразования адресов.
При загрузке процесса часть его виртуальных страниц помещается в оперативную память, а остальные - на диск. Смежные виртуальные страницы не обязательно располагаются в смежных физических страницах. При загрузке операционная система создает для каждого процесса информационную структуру - таблицу страниц, в которой устанавливается соответствие между номерами виртуальных и физических страниц для страниц, загруженных в оперативную память, или делается отметка о том, что виртуальная страница выгружена на диск. Кроме того, в таблице страниц содержится управляющая информация, такая как признак модификации страницы, признак невыгружаемости (выгрузка некоторых страниц может быть запрещена), признак обращения к странице (используется для подсчета числа обращений за определенный период времени) и другие данные, формируемые и используемые механизмом виртуальной памяти.
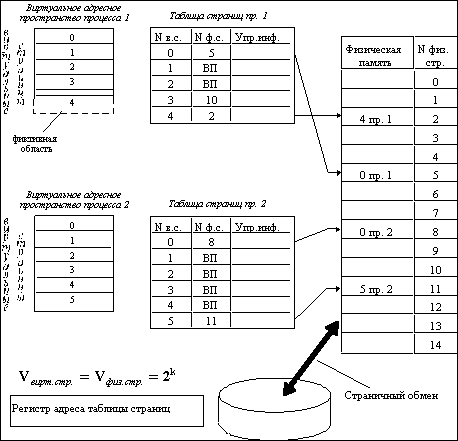
Рис. 2.12. Страничное распределение памяти
При активизации очередного процесса в специальный регистр процессора загружается адрес таблицы страниц данного процесса.
При каждом обращении к памяти происходит чтение из таблицы страниц информации о виртуальной странице, к которой произошло обращение. Если данная виртуальная страница находится в оперативной памяти, то выполняется преобразование виртуального адреса в физический. Если же нужная виртуальная страница в данный момент выгружена на диск, то происходит так называемое страничное прерывание. Выполняющийся процесс переводится в состояние ожидания, и активизируется другой процесс из очереди готовых. Параллельно программа обработки страничного прерывания находит на диске требуемую виртуальную страницу и пытается загрузить ее в оперативную память. Если в памяти имеется свободная физическая страница, то загрузка выполняется немедленно, если же свободных страниц нет, то решается вопрос, какую страницу следует выгрузить из оперативной памяти.
В данной ситуации может быть использовано много разных критериев выбора, наиболее популярные из них следующие:
l дольше всего не использовавшаяся страница,
l первая попавшаяся страница,
l страница, к которой в последнее время было меньше всего обращений.
В некоторых системах используется понятие рабочего множества страниц. Рабочее множество определяется для каждого процесса и представляет собой перечень наиболее часто используемых страниц, которые должны постоянно находиться в оперативной памяти и поэтому не подлежат выгрузке.
После того, как выбрана страница, которая должна покинуть оперативную память, анализируется ее признак модификации (из таблицы страниц). Если выталкиваемая страница с момента загрузки была модифицирована, то ее новая версия должна быть переписана на диск. Если нет, то она может быть просто уничтожена, то есть соответствующая физическая страница объявляется свободной.
Рассмотрим механизм преобразования виртуального адреса в физический при страничной организации памяти (рисунок 2.13).
Виртуальный адрес при страничном распределении может быть представлен в виде пары (p, s), где p - номер виртуальной страницы процесса (нумерация страниц начинается с 0), а s - смещение в пределах виртуальной страницы. Учитывая, что размер страницы равен 2 в степени к, смещение s может быть получено простым отделением k младших разрядов в двоичной записи виртуального адреса. Оставшиеся старшие разряды представляют собой двоичную запись номера страницы p.
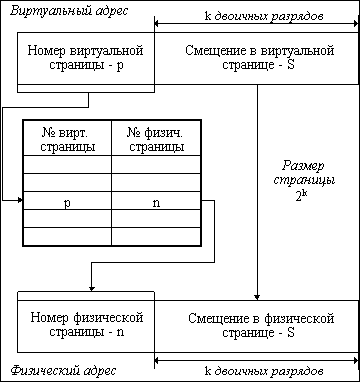
Рис. 2.13. Механизм преобразования виртуального адреса в физический
при страничной организации памяти
При каждом обращении к оперативной памяти аппаратными средствами выполняются следующие действия:
1. на основании начального адреса таблицы страниц (содержимое регистра адреса таблицы страниц), номера виртуальной страницы (старшие разряды виртуального адреса) и длины записи в таблице страниц (системная константа) определяется адрес нужной записи в таблице,
2. из этой записи извлекается номер физической страницы,
3. к номеру физической страницы присоединяется смещение (младшие разряды виртуального адреса).
Использование в пункте (3) того факта, что размер страницы равен степени 2, позволяет применить операцию конкатенации (присоединения) вместо более длительной операции сложения, что уменьшает время получения физического адреса, а значит повышает производительность компьютера.
На производительность системы со страничной организацией памяти влияют временные затраты, связанные с обработкой страничных прерываний и преобразованием виртуального адреса в физический. При часто возникающих страничных прерываниях система может тратить большую часть времени впустую, на свопинг страниц. Чтобы уменьшить частоту страничных прерываний, следовало бы увеличивать размер страницы. Кроме того, увеличение размера страницы уменьшает размер таблицы страниц, а значит уменьшает затраты памяти. С другой стороны, если страница велика, значит велика и фиктивная область в последней виртуальной странице каждой программы. В среднем на каждой программе теряется половина объема страницы, что в сумме при большой странице может составить существенную величину. Время преобразования виртуального адреса в физический в значительной степени определяется временем доступа к таблице страниц. В связи с этим таблицу страниц стремятся размещать в "быстрых" запоминающих устройствах.
Сегментное распределение
При страничной организации виртуальное адресное пространство процесса делится механически на равные части. Это не позволяет дифференцировать способы доступа к разным частям программы (сегментам), а это свойство часто бывает очень полезным. Например, можно запретить обращаться с операциями записи и чтения в кодовый сегмент программы, а для сегмента данных разрешить только чтение. Кроме того, разбиение программы на "осмысленные" части делает принципиально возможным разделение одного сегмента несколькими процессами. Например, если два процесса используют одну и ту же математическую подпрограмму, то в оперативную память может быть загружена только одна копия этой подпрограммы.
Рассмотрим, каким образом сегментное распределение памяти реализует эти возможности (рисунок 2.14). Виртуальное адресное пространство процесса делится на сегменты, размер которых определяется программистом с учетом смыслового значения содержащейся в них информации. Отдельный сегмент может представлять собой подпрограмму, массив данных и т. п. Иногда сегментация программы выполняется по умолчанию компилятором.
При загрузке процесса часть сегментов помещается в оперативную память (при этом для каждого из этих сегментов операционная система подыскивает подходящий участок свободной памяти), а часть сегментов размещается в дисковой памяти. Сегменты одной программы могут занимать в оперативной памяти несмежные участки. Во время загрузки система создает таблицу сегментов процесса (аналогичную таблице страниц), в которой для каждого сегмента указывается начальный физический адрес сегмента в оперативной памяти, размер сегмента, правила доступа, признак модификации, признак обращения к данному сегменту за последний интервал времени и некоторая другая информация. Если виртуальные адресные пространства нескольких процессов включают один и тот же сегмент, то в таблицах сегментов этих процессов делаются ссылки на один и тот же участок оперативной памяти, в который данный сегмент загружается в единственном экземпляре.
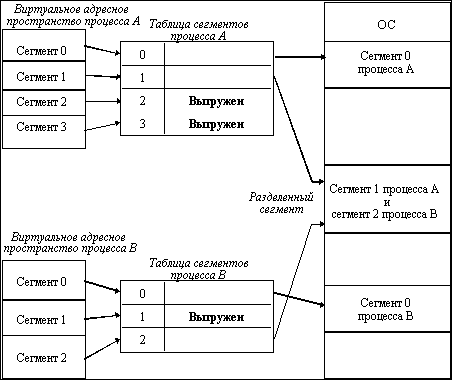
Рис. 2.14. Распределение памяти сегментами
Система с сегментной организацией функционирует аналогично системе со страничной организацией: время от времени происходят прерывания, связанные с отсутствием нужных сегментов в памяти, при необходимости освобождения памяти некоторые сегменты выгружаются, при каждом обращении к оперативной памяти выполняется преобразование виртуального адреса в физический. Кроме того, при обращении к памяти проверяется, разрешен ли доступ требуемого типа к данному сегменту.
Виртуальный адрес при сегментной организации памяти может быть представлен парой (g, s), где g - номер сегмента, а s - смещение в сегменте. Физический адрес получается путем сложения начального физического адреса сегмента, найденного в таблице сегментов по номеру g, и смещения s.
Недостатком данного метода распределения памяти является фрагментация на уровне сегментов и более медленное по сравнению со страничной организацией преобразование адреса.
Странично-сегментное распределение
Как видно из названия, данный метод представляет собой комбинацию страничного и сегментного распределения памяти и, вследствие этого, сочетает в себе достоинства обоих подходов. Виртуальное пространство процесса делится на сегменты, а каждый сегмент в свою очередь делится на виртуальные страницы, которые нумеруются в пределах сегмента. Оперативная память делится на физические страницы. Загрузка процесса выполняется операционной системой постранично, при этом часть страниц размещается в оперативной памяти, а часть на диске. Для каждого сегмента создается своя таблица страниц, структура которой полностью совпадает со структурой таблицы страниц, используемой при страничном распределении. Для каждого процесса создается таблица сегментов, в которой указываются адреса таблиц страниц для всех сегментов данного процесса. Адрес таблицы сегментов загружается в специальный регистр процессора, когда активизируется соответствующий процесс. На рисунке 2.15 показана схема преобразования виртуального адреса в физический для данного метода.
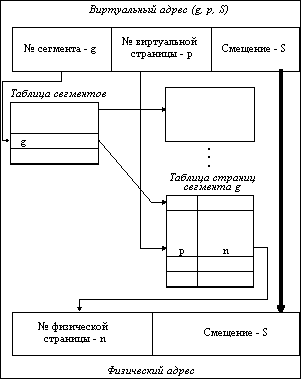
Рис. 2.15. Схема преобразования виртуального адреса в физический для
сегментно-страничной организации памяти
Алгоритмы замещения страниц????????????????????
Оптимальный алгоритм
Наилучший алгоритм замещения страниц легко описать. Когда действует прерывание, в памяти находится некоторый набор страниц. К одной из этих страниц будет обращаться следующая команда процессора. На другие страницы, возможно, не будет ссылок в течение 10, 100, а может и 1000 инструкций. Каждая страница может быть помечена количеством команд, которые будут выполняться перед первым обращением к этой странице.
Оптимальный алгоритм сообщает, что должна быть выгружена таблица с наибольшей меткой. Этот алгоритм не выполним.
NRU (Not Recently Used) — Не использовавшаяcя в последнее время страница
С каждой страницей связаны два бита — R (Referenced — обращения), устанавливается всякий раз при обращении и бит M (Modified — изменение), устанавливается, когда страница изменяется. Эти биты могут использоваться для реализации простого алгоритма. Когда процесс запускается, оба страничных бита для всех его страниц установлены в 0.
Когда происходит страничное прерывание, ОС проверяет все страницы и делит их на четыре класса:
ñ Класс 0: не было обращений и изменений.
ñ Класс 1: не было обращений, страница изменена.
ñ Класс 2: было обращение, страница изменена.
ñ Класс 3: было обращение и изменение.
Алгоритм NRU удаляет случайную страницу из непустой группы с наименьшим номером.
FIFO
ОС поддерживает список всех страниц, в котором первая страница является старейшей, а страницы в хвосте списка попали в него совсем недавно. Когда происходит страничное прерывание, выгружается страница из головы списка, а новая страница добавляется в конец.
Недостаток алгоритма заключается в том, что наиболее часто запрашиваемая страница может быть выгружена.
Вторая попытка
Алгоритм, призванный решить проблемы алгоритма FIFO. Для того, чтобы избежать проблемы вытеснения из памяти используемых страниц, у самой старейшей страницы изучается бит R. Если R=1, то страница переводится в конец очереди, если R=0, то страница выгружается.
Часы
В начальный момент «Стрелка» указывает на старейшую страницу. Когда происходит прерывание, проверяется страница, на которую указывает стрелка. Если ее бит R = 0, страница выгружается, на ее место встает новая страница, стрелка сдвигается на одну позицию. Если бит R = 1, он устанавливается в 0 и стрелка меняет свою позицию. Это повторяется до тех пор, пока не будет найдена страница с R = 0.
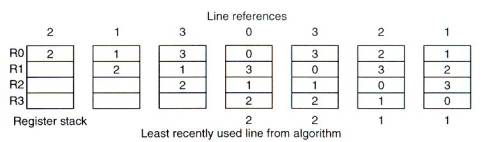
LRU (Least Recently Used) — Наиболее давно использовавшаяся страница
В основе этого алгоритма лежит наблюдение, что страницы, к которым происходило многократное обращение в нескольких последних командах, вероятно также будут часто использоваться в следующих инструкциях. Аналогично наоборот, если к странице в последнее время обращений не было, то не будет их и в ближайшем будущем. Эта идея привела к следующему алгоритму: во время прерывания выгружается из памяти страница, которая не использовалась дольше всего.
Для реализации этого алгоритма необходимо хранить в памяти связный список всех находящихся в памяти страниц. Сложность в том, что список должен обновляться при каждом обращении к памяти.
Рабочий набор
Рабочий набор – множество страниц, которое процесс использует в данный момент. Рабочий набор разработан для того, чтобы значительно снизить процент страничных прерываний. Суть алгоритма заключается в том, чтобы определить рабочий набор, найти и выгрузить страницу, которая не входит в рабочий набор. Этот алгоритм можно реализовать, записывая, при каждом обращении к памяти, номер страницы в специальный сдвигающийся регистр, затем удалялись бы дублирующие страницы.
Чтобы не происходило частых прерываний, нужно чтобы часто запрашиваемые страницы загружались заранее, а остальные подгружались по необходимости. В многозадачных системах процессы часто перемещаются на диск (то есть все их страницы удаляются из памяти), чтобы позволить другим процессам получить доступ к центральному процессору. Возникает вопрос, что делать, когда процесс снова загружается в память? С формальной точки зрения делать ничего не нужно. Процесс будет вызывать одно за другим страничные прерывания до тех пор, пока не загрузится в память весь его рабочий набор. Проблема в том, что наличие 20, 100 или даже 1000 страничных прерываний при каждой загрузке процесса сильно замедляет работу системы и, кроме того, тратит впустую значительное количество времени работы центрального процессора, так как обработка страничного прерывания ОС требует нескольких миллисекунд работы процессора.
Поэтому многие системы со страничной организацией пытаются отслеживать рабочий набор каждого процесса и обеспечивают его нахождение в памяти до запуска процесса
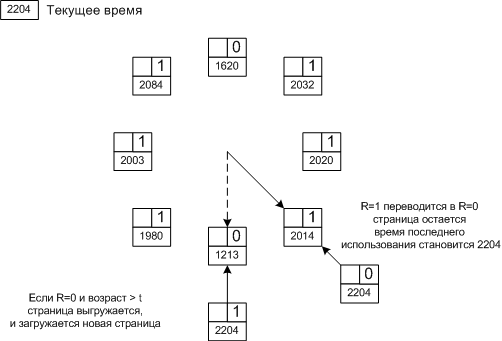
WSClock
Алгоритм основан на алгоритме "часы", но использует рабочий набор.
Используются битов R и M, а также время последнего использования.
Вопросы 22, 23, 24. Организация ввода/вывода
Функционирование любой вычислительной системы обычно сводится к выполнению двух видов работы: обработке информации и операций по осуществлению ее ввода-вывода.
Содержание понятий "обработка информации" и "операции ввода-вывода" зависит от того, с какой точки зрения мы смотрим на них. С точки зрения программиста, под "обработкой информации" понимается выполнение команд процессора над данными, лежащими в памяти независимо от уровня иерархии – в регистрах, кэше, оперативной или вторичной памяти. Под "операциями ввода-вывода" программист понимает обмен данными между памятью и устройствами, внешними по отношению к памяти и процессору, такими как магнитные ленты, диски, монитор, клавиатура, таймер. С точки зрения операционной системы "обработкой информации" являются только операции, совершаемые процессором над данными, находящимися в памяти на уровне иерархии не ниже, чем оперативная память. Все остальное относится к "операциям ввода-вывода". Чтобы выполнять операции над данными, временно расположенными во вторичной памяти, операционная система, сначала производит их подкачку в оперативную память, и лишь затем процессор совершает необходимые действия.
Контроллеры устройств
Устройства ввода/вывода, как правило, состоят из механической части и электронной части. В большинстве случаев эти части можно особо выделить для придания модели более модульного и общего характера. Электронный компонент называется контроллером устройства.
Плата контроллера обычно снабжается разъемом, к которому может быть подключен кабель, ведущий к самому устройству. Многие контроллеры способны управлять двумя, четырьмя или даже восемью идентичными устройствами. Обычно интерфейс между контроллером и устройством является стандартным, то есть официальным стандартом ANSI, IEEE или ISO, либо фактическим стандартом. Так, многие компании производят жесткие диски, соответствующие интерфейсу IDE или SCSI. Мы упоминаем о различии между контроллером и устройством потому, что операционная система практически всегда имеет дело с контроллером, а не с самим устройством. У большинства небольших компьютеров взаимодействие с устройствами организуется по модели единой шины.
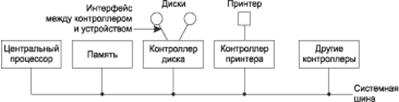
Интерфейс между устройством и контроллером часто является интерфейсом очень низкого уровня.
Контроллер монитора (видеоконтроллер) считывает из памяти байты, содержащие символы, которые следует отобразить, и формирует сигналы, используемые для модуляции луча электронной трубки, заставляющие ее выводить изображение на экран. Видеоконтроллер также формирует сигналы, управляющие горизонтальным и вертикальным перемещениями электронного луча. Если бы не контроллер, программисту пришлось бы делать это самому. В действительности же операционная система всего-навсего инициализирует контроллер, задавая небольшое число параметров, таких как количество символов или пикселов в строке и число строк на экране, а тяжелую работу по управлению разверткой берет на себя контроллер.
Ввод-вывод с отображением на память (методы)
У каждого контроллера сть несколько регистров, с помощью которых с ним может общаться центральный процессор. Записывая в эти регистры определенные значения, операционная система посылает устройству команды приема и передачи данных, включения, выключения и пр. Также некоторые регистры служат для отображения текущего состояния, готовности и др.
В дополнение к регистрам управления, многие устройства имеют буфер данных, доступный для чтения и записи со стороны ОС, пример — видеопамять.
Как процессор взаимодействует с регистрами управления и буферами данных устройств? Существует две альтернативы. Первая предполагает назначение каждому регистру номера порта ввода-вывода. Процессор может считать регистр с номером PORT и сохранить результат в своем регистре REG, используя специальную команду ввода-вывода, например in REG, PORT, аналогично — OUT PORT, REG.
В этом случае память и область ввода-вывода имеют разные адресные пространства.
Существуют другие методы ввода-вывода, при которых регистры ввода-вывода являются частью обычного адресного пространства. Такая организация называется вводом-выводом с отображением на память. Она была впервые применена на мини-компьютере PDP-11. Каждому регистру управления назначается уникальный адрес памяти, с которым обычная память не связана. В современных компьютерах применяется смешанная организация, при которой буферы данных устройств отображаются в адресное пространство, а отдельные регистры доступны с помощью механизма портов.

Прямой доступ к памяти (DMA)
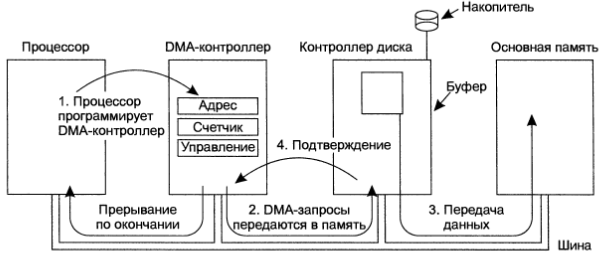
Процессор может запрашивать данные у контроллера побайтно, но если требуется получать от устройства большие блоки, значительная часть времени будет потрачена впустую. По этой причине для взаимодействия с памятью применяют другой метод, называемый прямым доступом к памяти (Direct Memory Access, DMA).
DMA-контроллер имеет независимый от процессора доступ к системной шине. DMA контроллер имеет несколько регистров, доступных процессору для чтения и записи: регистр адреса, счетчик байтов и ряд регистров управления.
Прежде чем разбираться с принципами работы DMA, следует разобраться как осуществляется чтение с диска без прямого доступа к памяти. Сначала контроллер считавает блок данных с носителя во внутренний буфер, подсчитывает контрольные суммы и т. п. Затем генерируется прерывание. Обработчик в ОС считывает данные из буфера контроллера и помещает их в основную память. Адрес памяти инкрементируется, счетчик оставшихся байтов декрементируется. Счетчик прекращается, когда значение счетчика становится равным нулю.
Прямой доступ к памяти изменяет эту процедуру. Сначала процессор программирует DMA-контроллер, записывая в его регистры значения, указывающие контроллеру, что и куда передавать. Затем DMA-контроллер передает команду контроллеру диска считать блок данных. После появления в буфере контроллера корректных данных, DMA-контроллер начинает перенос данных из диска в память. Эта процедура происходит в цикле, пока счетчик данных не обнулится. По завершении этой процедуре, инициируется прерывание и ОС оповещается о том, что данные уже лежат в ОП.
Прерывания
Как правило, регистры контроллеров содержат один или нескольуо битов состояния. Их можно проверить и определить, не завершена ли операция вывода и имеются-ли новые данные в устройстве ввода. Цикл, исполняемый процессором и проверяющий бит состояния до готовности устройства принять или передать данные, называется опросом, или активным ожиданием. Поскольку такое ожидание может оказаться очень долгим, активное ожидание допустимо лишь в небольших однозадачных системах.
В дополнение к битам состояния, многие контроллеры часто используют прерывания, которые позволяют сообщить процессору, что регистры готовы для записи или чтения. В результате завершение операции, вызывающей прерывание, останавливает процессор и запускает процедуру обработки прерывания. Процедура обработки прерывания информирует ОС о том, что ввод-вывод завершен. После этого у ОС появляется возможность обработать полученные данные.
Обработка прерываний в защищенном режиме работы процессора
Как и в случае с сегментами памяти, информация о обработчиках прерываний располагается в структуре данных, которая находится в ОП. Эта структура называется IDT (Interrupt Description Table). Каждый элемент этой структуры выглядит следующим образом:
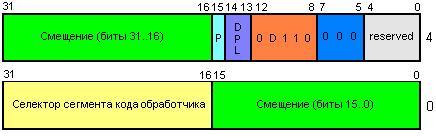
Информация о расположении IDT находитсяв регистре IDTR, который имеет структуру, аналогичную GDTR:
32-битный линейный базовый адрес | 16-битный лимит таблицы } 48 бит
Загружается регистр командой LIDT.
Во время прерывания в стек помещаются служебные регистры в следующем порядке: EFLAGS, CS, EIP. По окончании обработки прерывания ОС выполняет команду iretd, которая выгружает значения из стека.
Классификация прерываний
Механизм обработки прерываний, по которому процессор прекращает выполнение команд в обычном режиме и, частично сохранив свое состояние, ответвляется на выполнение других действий, оказался настолько удобен, что зачастую разработчики процессоров используют их и для других целей. Хотя эти случаи и не относятся к операциям ввода-вывода, мы вынуждены упомянуть их здесь, для того, чтобы их не путали с прерываниями. Похожим образом процессор обрабатывает исключительные ситуации и программные прерывания.
Для внешних прерываний характерны следующие особенности:
ñ Внешнее прерывание обнаруживается процессором между выполнением команд (или между итерациями в случае выполнения цепочечных команд).
ñ Процессор при переходе на обработку прерывания сохраняет часть своего состояния перед выполнением следующей команды.
ñ Прерывания происходят асинхронно с работой процессора и непредсказуемо, программист ни коим образом не может предугадать, в каком именно месте работы программы произойдет прерывание.
Исключительные ситуации возникают во время выполнения процессором команды. К их числу относятся ситуации переполнения, деления на ноль, обращения к отсутствующей странице памяти (см. часть III) и т. д. Для исключительных ситуаций характерно следующее:
ñ Исключительные ситуации обнаруживаются процессором во время выполнения команд.
ñ Процессор при переходе на выполнение исключительной ситуации сохраняет часть своего состояния перед выполнением текущей команды.
ñ Исключительные ситуации возникают синхронно с работой процессора, но непредсказуемо для программиста, если только тот специально не заставил процессор делить некоторое число на ноль.
Программные прерывания возникают после выполнения специальных команд, как правило, для выполнения привилегированных действий внутри системных вызовов. Программные прерывания имеют следующие свойства:
ñ Программное прерывание происходит в результате выполнения специальной команды.
ñ Процессор при выполнении программного прерывания сохраняет свое состояние перед выполнением следующей команды.
ñ Программные прерывания, естественно, возникают синхронно с работой процессора и абсолютно предсказуемы программистом.
Надо честно сказать, что похожие механизмы обработки внешних прерываний, исключительных ситуаций и программных прерываний лежат целиком на совести разработчиков процессоров. Существуют вычислительные системы, где все эти три ситуации обрабатываются по-разному.
Вопросы 25, 26, 27, 28
Файловая система
Файловая система— порядок, определяющий способ организации, хранения и именования данных на носителях информации в компьютерах, а также в другом электронном оборудовании: цифровых фотоаппаратах, мобильных телефонах и т. п. Файловая система определяет формат содержимого и физического хранения информации, которую принято группировать в виде файлов. Конкретная файловая система определяет размер имени файла (папки), максимальный возможный размер файла и раздела, набор атрибутов файла. Некоторые файловые системы предоставляют сервисные возможности, например, разграничение доступа или шифрование файлов.
Файловая система связывает носитель информации с одной стороны и API для доступа к файлам — с другой. Когда прикладная программа обращается к файлу, она не имеет никакого представления о том, каким образом расположена информация в конкретном файле, так же, как и на каком физическом типе носителя (CD, жёстком диске, магнитной ленте, блоке флеш-памяти или другом) он записан. Всё, что знает программа — это имя файла, его размер и атрибуты. Эти данные она получает от драйвера файловой системы. Именно файловая система устанавливает, где и как будет записан файл на физическом носителе (например, жёстком диске).
С точки зрения операционной системы , весь диск представляет собой набор кластеров (как правило, размером 512 байт и больше)[1]. Драйверы файловой системы организуют кластеры в файлы и каталоги (реально являющиеся файлами, содержащими список файлов в этом каталоге). Эти же драйверы отслеживают, какие из кластеров в настоящее время используются, какие свободны, какие помечены как неисправные.
Однако файловая система не обязательно напрямую связана с физическим носителем информации. Существуют виртуальные файловые системы, а также сетевые файловые системы, которые являются лишь способом доступа к файлам, находящимся на удалённом компьютере.
Основные функции любой файловой системы нацелены на решение следующих задач:
ñ именование файлов;
ñ программный интерфейс работы с файлами для приложений;
ñ отображения логической модели файловой системы на физическую организацию хранилища данных;
ñ организация устойчивости файловой системы к сбоям питания, ошибкам аппаратных и программных средств;
ñ содержание параметров файла, необходимых для правильного его взаимодействия с другими объектами системы (ядро, приложения и пр.).
В многопользовательских системах появляется ещё одна задача: защита файлов одного пользователя от несанкционированного доступа другого пользователя, а также обеспечение совместной работы с файлами, к примеру, при открытии файла одним из пользователей, для других этот же файл временно будет доступен в режиме «только чтение».
Иерархия файловых систем
<<<http://ru. wikipedia. org/wiki/FHS // http://*****/operating_systems/articles/fhs. shtml >>>
В корневой файловой системе должна находиться информация для загрузчика и основные файлы, необходимые в процессе старта системы (например, ядро). Здесь же должны размещаться файлы конфигурации и все, что необходимо для монтирования других файловых систем, включая такие утилиты, как mount. Чтобы обеспечить возможность восстановления системы после сбоев, в корневой файловой системе должны присутствовать все утилиты, необходимые администратору для диагностирования проблем и реконструкции системы после любой аварийной ситуации. Здесь же должны быть расположены и те утилиты, которые необходимы для восстановления данных с резервных копий.
По ряду причин размер корневой файловой системы желательно сделать достаточно малым.
ñ Иногда приходится монтировать корневую файловую систему с носителя малого объема.
ñ Корневая файловая система обычно содержит неразделяемые файлы, специфичные для конкретной системы. Разделяемые файлы можно разместить на сетевых дисках. Это позволяет использовать в качестве рабочих станций в сети компьютеры с маленькими по объему локальными жесткими дисками.
ñ Маленькая корневая файловая система менее подвержена разрушению в случае сбоев.
ñ Из стандарта можно сделать вывод о том, что в корневой файловой системе обязательно должны целиком располагаться каталоги /bin, /dev, /etc, /lib, /sbin и, возможно, /root.
ñ Каталог /boot в силу аппаратных ограничений может оказаться необходимым разместить на отдельном разделе диска, расположенном целиком в пределах первых 1024 цилиндров загрузочного диска.
ñ Остальные подкаталоги корневого каталога (home, mnt, opt, tmp, usr, var) могут размещаться в других файловых системах (на других разделах или дисках). Более того, в стандарте явно постулируется, что в каталогах /usr, /opt и /var размещаются такие файлы, которые могут располагаться в других разделах диска или в других файловых системах. Разработчики стандарта советуют в том случае, когда /var не может быть размещен в отдельном разделе диска, переместить каталог /var из корневого раздела в раздел с каталогом /usr. Однако /var нельзя делать ссылкой на /usr потому что это затрудняет разделение /usr и /var и может привести к конфликту имен, лучше уж сделать /var ссылкой на /usr/var.
Отметим, что в статье речь идет только о требованиях и рекомендациях стандарта FHS, разработанного с ориентацией на операционные системы Linux и BSD. Даже конкретные дистрибутивы Linux не во всем следуют этому стандарту. Так, в Red Hat Linux версий 7.3 и 8.0 каталог /etc/opt хотя и создан, но пуст, а конфигурационные каталоги пакетов размещаются непосредственно в /etc. Можно указать и другие отклонения от стандарта. Но все же в основном структура каталогов выдерживается в соответствии с FHS, так что знакомство с этим стандартом, безусловно, полезно всем пользователям Linux, а тем более разработчикам.
FHS — сокращение от Filesystem Hierarchy Standard, что в переводе c английского означает «Стандарт иерархии файловой системы». Этот стандарт принят дляунификации местонахождения файлов и директорий с общим назначением в файловой системе ОС UNIX. На данный момент большинство UNIX-подобных систем в той или иной степени следует этим правилам.
Директория | Описание |
/ | Корневая директория, содержащая всю файловую иерархию. |
/bin/ | Основные утилиты, необходимые как в однопользовательском режиме, так и при обычной работе всем пользователям (например: cat, ls, cp). |
/boot/ | Загрузочные файлы (в том числе файлы загрузчика, ядро, initrd, System. map). Часто выносится на отдельный раздел. |
/dev/ | Основные файлы устройств (например, /dev/null, /dev/zero). |
/etc/ | Общесистемные конфигурационные файлы (имя происходит от et cetera). |
/etc/opt/ | Файлы конфигурации для /opt/. |
/etc/X11/ | Файлы конфигурации X Window System версии 11. |
/etc/sgml/ | Конфигурационные файлы SGML. |
/etc/xml/ | Конфигурационные файлы XML. |
/home/ | Содержит домашние директории пользователей, которые в свою очередь содержат персональные настройки и данные пользователя. Часто размещается на отдельном разделе. |
/lib/ | Основные библиотеки, необходимые для работы программ из /bin/ и /sbin/. |
/media/ | Точки монтирования для сменных носителей, таких как CD-ROM, DVD-ROM (впервые описано в FHS-2.3). |
/mnt/ | Содержит временно монтируемые файловые системы. |
/opt/ | Дополнительное программное обеспечение. |
/proc/ | Виртуальная файловая система, представляющая состояние ядра операционной системы и запущенных процессов в виде файлов. |
/root/ | Домашняя директория пользователя root. |
/sbin/ | Основные системные программы для администрирования и настройки системы, например, init, iptables, ifconfig. |
/srv/ | Данные, специфичные для окружения системы. |
/tmp/ | Временные файлы (см. также /var/tmp). |
/usr/ | Вторичная иерархия для данных пользователя; содержит большинство пользовательских приложений и утилит, используемых в многопользовательском режиме. Может быть смонтирована по сети только для чтения и быть общей для нескольких машин.[1] |
/usr/bin/ | Дополнительные программы для всех пользователей, не являющиеся необходимыми в однопользовательском режиме. |
/usr/include/ | Стандартные заголовочные файлы. |
/usr/lib/ | Библиотеки для программ, находящихся в /usr/bin/ и /usr/sbin/. |
/usr/sbin/ | Дополнительные системные программы (такие как демоны различных сетевых сервисов). |
/usr/share/ | Архитектурно-независимые общие данные. |
/usr/src/ | Исходные коды (например, здесь располагаются исходные коды ядра). |
/usr/X11R6/ | X Window System, версии 11, релиз 6. |
/usr/local/ | Третичная иерархия для данных, специфичных для данного хоста. Обычно содержит такие поддиректории, как bin/, lib/, share/.[2] |
/var/ | Изменяемые файлы, такие как файлы регистрации (log-файлы), временные почтовые файлы, файлы спулеров. |
/var/lib/ | Информация о состоянии. Постоянные данные, изменяемые программами в процессе работы (например, базы данных, метаданные пакетного менеджера и др.). |
/var/lock/ | Лок-файлы, указывающие на занятость некоторого ресурса. |
/var/log/ | Различные файлы регистрации (log-файлы). |
/var/mail/ | Почтовые ящики пользователей. |
/var/run/ | Информация о запущенных программах (в основном, о демонах). |
/var/spool/ | Задачи, ожидающие обработки (например, очереди печати, непрочитанные или неотправленные письма). |
/var/spool/mail/ | Местоположение пользовательских почтовых ящиков (устаревшее). |
/var/www/ | Файлы веб-сайтов (например, иерархия файлов виртуальных хостов). |
/var/tmp/ | Временные файлы, которые должны быть сохранены между перезагрузками. |

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
