

Принципы построения и работы
микропроцессоров на микросхемах
ИСТОРИЯ СОЗДАНИЯ ПРОЦЕССОРА
Первый шаг
15 ноября 1971 г. можно считать началом новой эры в электронике. В этот день компания приступила к поставкам первого в мире микропроцессора Intel 4004 - именно такое обозначение получил первый прибор, послуживший отправной точкой абсолютно новому классу полупроводниковых устройств.
Создав новый рынок и захватив на нем господствующие высоты, Intel тем не менее стремилась расширить его границы, и за 25 лет процессоры проделали поистине гигантский путь.
Рассмотрим типы процессоров, которые применяются в данное время:
80286
Процессор i80286 был анонсирован 1 февраля 1982 г. Архитектура и характеристики чипа оказались весьма впечатляющими. Оставшись 16-разрядным прибором, по производительности новый ЦП в 3—6 раз превзошел своего предшественника (i8086) при тактовой частоте первой модификации 8 МГц. Благодаря использованию многовыводного корпуса разработчики смогли применить схему с раздельными шинами адресов и данных. 24 разряда адреса позволили обращаться к физической памяти объемом до 16 Мбайт — такую же емкость имели тогда и старшие модели большинства мэйнфреймов. Встроенная система управления памятью и средства ее защиты открывали широкие возможности использования МП в многозадачных средах. Кроме того, аппаратура i80286 обеспечивала работу с виртуальной памятью объемом до 1 Гбайт.
Новый ЦП имел два режима работы - реальный и защищенный. В первом случае он воспринимался как быстрый ЦП i8086 с несколько расширенной системой команд и прекрасно подходил тем потребителям, для которых, помимо скоростных характеристик, жизненно важным было сохранение существующего задела ПО. Работа в защищенном режиме позволяла использовать преимущества прибора в полном объеме, и прежде всего — большой объем основной памяти.
Первенец 32-разрядных систем
Первенец 32-разрядных систем i80386 был представлен 17 октября 1985 г. и имел все права на звание процессора для ЭВМ общего назначения. Использование КМОП-технологии с проектными нормами 1 мкм и двумя уровнями металлизации позволило разместить на кристалле 275 тыс. транзисторов и реализовать полностью 32-разрядную архитектуру ЦП. 32 разряда адреса обеспечили адресацию физической памяти объемом до 4 Гбайт и виртуальной памяти емкостью до 64 Тбайт. Помимо работы с виртуальной памятью допускались операции с памятью, имевшей страничную организацию. Предварительная выборка команд, буфер на 16 инструкций, конвейер команд и аппаратная реализация функций преобразования адреса значительно уменьшили среднее время выполнения команды. Благодаря этим архитектурным особенностям, процессор мог выполнять 3 - 4 млн. команд в секунду, что примерно в 6 - 8 раз превышало аналогичный показатель для МП i8086. Безусловно, новый прибор остался совместимым со своими предшественниками на уровне объектных кодов.
Особый интерес представляли три режима работы кристалла ( реальный, защищенный и режим виртуального МП i8086. В первом обеспечивалась совместимость на уровне объектных кодов с устройствами i8086 и i80286, работающими в реальном режиме. При этом архитектура i80386 была почти идентична архитектуре 86-го процессора, для программиста же он вообще представлялся как ЦП i8086, выполняющий соответствующие программы с большей скоростью и обладающий расширенной системой команд и регистрами. Благодаря этим качествам 32-разрядного продукта компания сохранила прежних клиентов, которые хотели модернизировать свои системы, не отказываясь от имевшегося задела в области программного обеспечения, и привлекла тех, кому изначально требовалась высокая скорость обработки информации.
Одно из основных ограничении реального режима было связано с предельным объемом адресуемой памяти, равным 1 Мбайт. От него свободен защищенный режим, позволяющий воспользоваться всеми преимуществами архитектуры нового ЦП. Размер адресного пространства в этом случае увеличивался до 4 Гбайт, а объем поддерживаемых программ до 64 Тбайт. Системы защищенного режима обладали более высоким быстродействием и возможностями организации истинной многозадачности.
Наконец, режим виртуального МП открывал возможность одновременного исполнения ОС и прикладных программ. написанных для МП i8086, i80286 и80386. Поскольку объем памяти, адресуемой 386-м процессором, не ограничен значением 1 Мбайт, он позволял формировать несколько виртуальных сред i8086.
10 апреля 1989 г. корпорация Intel объявила о начале выпуска 32 разрядного прибора второго поколения - i80486, ставшего после устройств i8080 и!8086 еще одним долгожителем.
Pentium
Стремительное усложнение программного обеспечения и постоянное расширение сферы применения компьютеров настоятельно требовали существенного роста вычислительной мощи центральных процессоров ПК. Ко всему прочему на пятки стали наступать и RISC-процессоры. Хотя в конце 80-х годов некоторые эксперты предсказывали близкий конец кристаллов СISC, корпорация Intel вполне справедливо посчитала, что до этого еще далеко и в микропроцессорах использованы не все возможности СISC-архитектуры. Кроме того, фирме вряд ли простили бы отказ от программной совместимости с предшествующими моделями - стоимость накопленного системного и прикладного ПО уже измерялась в миллиардах долларов.
Как это случалось не раз, проработки нового процессора начались, когда проект создания 486-го МП вступил в заключительную стадию. В основу продукта была положена суперскалярная архитектура (еще один атрибут из мира мэйнфреймов), которая и дала возможность получить пятикратное повышение производительности по сравнению с моделью 486DХ. Высокая скорость выполнения команд достигалась благодаря двум 5-ступенчатым конвейерам, позволявшим одновременно исполнять несколько инструкций. Для постоянной загрузки обоих конвейеров из кэш’а требуется широкая полоса пропускания. Совмещенный буфер команд и данных обеспечить ее не мог, и разработчики воспользовались решением из арсенала RISC-процессоров, оснастив Pentium раздельными буферами команд и данных. При этом обмен информацией с памятью через кэш данных осуществлялся совершенно независимо от процессорного ядра, а буфер инструкций был связан с ним через высокоскоростную 256-разрядную внутреннюю шину. Несмотря на то что новый кристалл был спроектирован как 32-разрядный, для связи с остальными компонентами системы использовалась внешняя 64-разрядная шина данных с максимальной пропускной способностью 528 Мбайт/с. Еще одной «изюминкой» архитектуры, позаимствованной у представителей универсальных ЭВМ стала схема предсказания переходов.
По скорости выполнения команд с плавающей точкой Pentium в пять - семь раз превзошел процессор 486DX2/50 и почти на порядок - микросхему 486DX/33.
Pentium Pro
27 марта 1995 г. Intel представила микропроцессор шестого поколения, получивший название Pentium Pro. Стремление выжать из CISC-архитектуры практически все, на что она способна, заставило разработчиков этого продукта пользоваться почти всеми техническими решениями, которые ранее применялись в супер ЭВМ и мэйнфреймах (благо, достигнутая степень интеграции это уже позволяла). Прежде всего речь идет об использовании механизма динамического разделения порядка выполнения команд нескольких многоступенчатых конвейеров вместо двух 5-ступенчатых конвейеров, характерных для Pentium. Новый ЦП имеет их три, в каждом из которых 14 ступеней. Подобный многофазный конвейер позволил обеспечить высокую тактовую частоту процессора (133 МГц в первой модели). Для осуществления постоянной загрузки конвейера необходимы высокоэффективный кэш команд и высококачественная схема предсказания переходов. Поэтому в отличие от своего предшественника, имевшего двухвходовой ассоциативный кэш инструкций, Pentium Pro обладает более эффективным четырехвходовым кэш’ем, а также схемой предсказания ветвлений на 512 входов. Кроме того, для повышения производительности была применена буферная память второго уровня емкостью 256 Кбайт, расположенная в отдельном чипе и смонтированная в том же корпусе, что и процессор. Кристалл кэш’а связан с процессором собственной синхронной 64-разрядной шиной, работающей на тактовой частоте процессора.
Технические характеристики нового ЦП обеспечили ему устойчивый сбыт в секторе высокопроизводительных серверов и рабочих станций, на долю которого приходится пока наибольший объем продаж кристалла. Что касается персональных компьютеров, то здесь распространение Pentium Pro пока сдерживается относительно высокой стоимостью и недостаточным объемом прикладного ПО, в полной мере использующего все преимущества процессора.
ПРИНЦИПЫ ПОСТРОЕНИЯ И РАБОТЫ МИКРОПРОЦЕССОРОВ НА МИКРОСХЕМАХ
Микропроцессор - это процессор, выполненный в виде большой интегральной схемы(БИС) и заключённый в герметический корпус. В основе любой ПЭВМ(персональной ЭВМ) лежит использование микропроцессоров. Микропроцессор является "мозгом" компьютера. Он
осуществляет выполнение программ, работающих на компьютере, и управляет работой остальных устройств компьютера. Основными характеристиками микропроцессора являются быстродействие и разрядность. Быстродействие - это число выполняемых операций в секунду. Разрядность характеризует объём информации, который микропроцессор обрабатывает за одну операцию: 8-разрядный процессор за одну операцию обрабатывает 8 бит информации, 32-разрядный - 32 бита. Скорость его работы во многом определяет быстродействие компьютера. В IBM PC используются микропроцессоры, разработанные фирмой Intel, или совместимые с ними процессоры других фирм.
Все персональные компьютеры и растущее число наиболее современного оборудования работают на специальной электронной схеме, названной микропроцессором. Часто его называют компьютер в чипе. Современный микропроцессор - это кусочек кремния, который был выращен в стерильных условиях по специальной технологии.
Полупроводники
Человек научился помещать примеси других атомов в кристаллическую решетку без разрушения этой сложной конструкции. Примеси позволили кремнию изменить свои свойства, касающиеся проводимости электрического тока. Эти свойства позволили отнести материал к новому классу – классу полупроводников. Этот термин отражает промежуточные свойства материала по способности проводить электрический ток: хуже, чем у проводников (медь), но лучше чем у изоляторов (синтетическое покрытие проводников).
Внесение примесей
Хотя эту неуловимую трансформацию материала логично описать в книге по производству металлов, эти средние свойства – проводить электрический ток – с самого начала их выявления обещали произвести революцию в электронике. В 1947 году ученые лаборатории Bell осторожно внесли примесь в кремниевый кристалл, разделив его кристаллическую решетку на три тонких слоя. Этот сэндвич позволил перемешать атомы различных материалов в кристаллической решетке.
Транзисторы
Таким образом, получился первый транзистор – крошечная пластина серебристого кремния, способная проводить электронный поток, причем входной поток, поступавший на один электрод, преобразовывался и имел уже другие значения на двух других электродах.
Транзисторы были прорывом в будущее. Они позволили отказаться от электронных вакуумных ламп.
Аналоговые и цифровые схемы
Электрические преобразования можно проводить двумя путями. Слабый сигнал может быть усилен в сигнал точно такой же формы, как оригинал, но с гораздо большими значениями. Этот процесс получения большего аналога малого сигнала получил название аналогового преобразования. А сам сигнал назван аналоговым. Такое преобразование можно использовать для усиления звука, когда мы получаем точно такой формы, но гораздо большего значения.
И, напротив, малый сигнал можно увеличить до большого и, наоборот, большой уменьшить до малого, игнорируя все промежуточные значения. В результате мы получим серию импульсов, которые могут быть использованы для кодировки значений каких-либо величин. Например, семью импульсами можно представить цифру семь. Точно так же можно закодировать любые цифры. Отсюда электронные устройства, использующие подобную технологию, названы цифровыми.
Цифровая логика
Само по себе включение одного выключателя другим может быть бесполезным, однако транзистор может быть включен комбинацией сигналов точно так же, как и одиночным импульсом. Действительно, транзисторная схема может быть разработана так, что она сформирует сигнал только после того, как получит два входных. Другая схема может то же самое только тогда, когда на ее входах нет ни одного входного сигнала, или когда присутствует хотя бы один. Такие схемы называются логическими вентилями. Они получили такое имя, потому что подобно обычным вентилям, могут пропускать, когда они открыты, либо не пропускать в закрытом состоянии, электрические сигналы. Эти функции позволяют реализовать принципы формальной логики.
Первые компьютеры были созданы по принципу логических вентилей, хотя они были разработаны не на транзисторах. И вакуумные лампы, и реле могут работать по тому же принципу логических вентилей. У транзисторов большое преимущество – они меньше и быстрее. Они так малы, что сотни тысяч могут разместиться на пластине кремния с ноготь человека.
Интегральные схемы
Микропроцессор представляет собой большую совокупность простых транзисторов, которая называется интегральной схемы или ИС, потому что они функционируют как много отдельных транзисторов и других устройств, интегрированных и реализованных на одной маленькой кремниевой пластине. Часто эту большую интегральную микросхему называют просто чипом.
Конструкция этих элементов выросла за пределы просто кристалла. Микропроцессор – это только одно устройство из большого числа интегральных схем, с помощью которых теперь реализуют огромное множество всевозможных приборов, начиная от аудио до часов. В микропроцессоре тысячи транзисторов соединены таким образом на кремниевой пластине, что одно и то же множество входных сигналов. Микропроцессоры отличаются от других интегральных схем, созданных на том же множестве транзисторов, тем, что преобразование сигнала происходит в соответствии с поступившем входным сигналом только внутри самой микросхемы.
Внутренности микропроцессора
Большинство микропроцессоров имеют специально встроенные области памяти, названные регистрами, в которых они осуществляют все свои манипуляции и расчеты. Например, для того, чтобы сложить два числа, первое помещается сначала в регистр, затем другое прибавляется и сумма остается внутри регистра.
Сигналы, путешествующие по микропроцессору, представляют сбой серию цифровых импульсов. Их перемещение происходит почти одновременно – параллельно по нескольким проводникам. Каждая серия таких импульсов представляет собой отдельную команду, реализующую определенную функцию микропроцессора. Каждая команда имеет для идентификации свое имя. Полный набор реализуемых функций и их имена называются множеством микрокоманд процессора.
Внутренняя структура кремния микропроцессора определяет, что он делает по каждому входному сигналу. В результате компьютерная программа для микропроцессора встраивается в его техническое обеспечение. Эта программа называется микрокодом для микропроцессора.
Соединение микропроцессоров
Помимо работы с внутренней памятью и манипуляций цифровыми битами микропроцессоры должны каким-то образом получать входную информацию и выдавать полученные результаты. Для реализации этой связи с внешним миром разработана микропроцессорная шина данных. Кроме того, микропроцессору необходимо каким-то образом определять, где хранятся данные во внешней памяти. Для этой цели придумана другая шина, названная адресной. Название говорит о том, что она используется для определения местонахождения необходимой информации.
Микропроцессоры отличаются по находящимся в их распоряжении ресурсами, что в свою очередь влияет на скорость их работы. Микропроцессоры могут отличаться не только числом регистров, но и размерами самих регистров. Регистры характеризуются числом битов, с которыми он может работать в единицу времени. Например, 16-битному необходим один или более регистров размерностью в 16-бит.
История развития микропроцессоров – это история увеличения размеров их регистров и ширины шины. С каждым новым поколением микропроцессоров увеличивался размер регистров и шире становилась адресная шина. В результате персональные компьютеры становились мощнее.
Четырехбитное мышление
Первый микропроцессор был изготовлен в 1971 году фирмой Intel Corporation. Это был четырехбитный микропроцессор 4004. Эти 4 бита позволяли кодировать все цифры и символы, что было достаточно для математических расчетов. Микропроцессор мог складывать, вычитать и умножать точно так же как это делают его старшие братья, хотя и не так быстро.
Теперь несколько слов о том, как был разработан 4004. Чип был разработан Тедом Хоффом из Intel Corporation. Первое упоминание о нем появилось в 1969 году в отчете по работам с несуществующей теперь японской компанией Busicom. Японцы заказали изготовить двенадцать типов микросхем для использования их в калькуляторах различных моделей. Малый объем каждой партии микросхем увеличивал стоимость их разработки. Однако Хоффу удалось создать такой чип, который мог использоваться во всех калькуляторах. Микросхема работала прекрасно и открыла век дешевых калькуляторов. Она явилась прекрасной базой для разработки программируемых устройств того времени.
Восьмибитные чипы
Солидные машины работают не только с цифрами, но так же и с текстами. Микропроцессор 4004 не обладал всеми этими способностями. Изготавливая микропроцессор для более широких целей, необходимо было увеличить размер его регистров. Это позволило бы ему понимать все буквы и цифры. Использование 6 бит позволяет различать все малые и большие буквы и цифры (можно закодировать 64 символа). Но при этом остается мало значений для кодировки знаков пунктуации и управляющих символов. В результате в 1972 году появился восьмибитный микропроцессор
Intel 8008. Размер его регистров соответствовал стандартной единице цифровой информации – байту.
Процессор 8008 являлся простым развитием 4004. Это был интересный и работоспособный микропроцессор. Его широко использовали при производстве персональных компьютеров.
Intel продолжал развеваться (как и вся отрасль). И в 1974 году был создан гораздо более интересный микропроцессор 8080. С самого начала разработки он закладывался как 8-битный чип. У него было более широкое множество микрокоманд (множество микрокоманд 8008 было расширено). Кроме того, это был первый микропроцессор, который мог делить числа.
Несколько инженеров фирмы имели идеи по усовершенствованию 8080. Они покинули Intel, чтобы реализовать их. Ими была организована Zilog Corporation, которая подарила миру микропроцессор Z80. В действительности Z80 являлся дальнейшей разработкой микропроцессора 8080. Было просто увеличено число его команд, что позволило создать и использовать на персональных компьютерах стандартные операционные системы.
Разработанная Digital Research операционная система, представляющая собой специальную программу, связывающую микропроцессор и остальные устройства технического обеспечения (например, оперативная память), была названа Control Program for Microcomputers (CP/M). Ее прародителями являлись операционные системы больших ЭВМ, но и размеры ее были гораздо скромнее, что давало возможность работать на микропроцессоре. Далекая от совершенства, она работала довольно надежно, что позволило ей стать своего рода стандартной для профессиональных пользователей малых компьютеров. Она помогла программистам, работавшим ранее на больших ЭВМ, адаптироваться к персональным компьютерам. Хотя СР/М предназначалась для 8080, Z80 раскрывал большие возможности для системных работ.
Тем временем Intel продолжал работы над 8-битным 8008. был разработан микропроцессор 8085, который работал от 5В и требовал меньше вспомогательных микросхем. Новшества разработки включали вектор прерываний и серию портов ввода-вывода. Теперь малые компьютеры стали непобедимыми!
ОСНОВНОЙ АЛГОРИТМ
РАБОТЫ ПРОЦЕССОРА.
Микропроцессор - это процессор, выполненный в виде большой интегральной схемы(БИС) и заключённый в герметический корпус. В основе любой ПЭВМ(персональной ЭВМ) лежит использование микропроцессоров. Микропроцессор является "мозгом" компьютера. Он осуществляет выполнение программ, работающих на компьютере, и управляет работой остальных устройств компьютера.
Основными характеристиками микропроцессора являются быстродействие и разрядность. Быстродействие - это число выполняемых операций в секунду. Разрядность характеризует объём информации, который микропроцессор обрабатывает за одну операцию: 8-разрядный процессор за одну операцию обрабатывает 8 бит информации, 32-разрядный - 32 бита. Скорость его работы во многом определяет быстродействие компьютера. В IBM PC используются микропроцессоры, разработанные фирмой Intel, или
совместимые с ними процессоры других фирм.
СТРУКТУРА МИКРОПРОЦЕССОРА.
¦ Микропроцессор ¦
+T+
¦ ¦ ¦
------+ ----+-- +----
¦ А Л У ¦ ¦ У У ¦ ¦ РЕГИСТРЫ ¦
L------ L------- L-----
А Л У - арифметическо-логическое устройство. Оно обеспечивает выполнение основных операций по обработке информации.
Любую задачу компьютер разбивает на отдельные логические операции, производимые над двоичными числами, причем в одну секунду осуществляются сотни тысяч или миллионы таких операций. Сложение, вычитание, умножение и деление - элементарные операции, выполняемые А Л У ЭВМ. Полный набор таких операций называют системой команд, а схемы их реализации составляют основу А Л У. Помимо арифметического устройства АЛУ включает и логическое устройство, предназначенное для операций, при осуществлении которых отсутствует перенос из разряда в разряд. Иногда эти операции называют логическое И и логическое ИЛИ. Все операции в АЛУ производятся в регистрах - специально отведенных ячейках АЛУ. Время выполнения простейших операций определяется минимальным временем сложенния двух операндов, находящихся в регистрах. В случае, если одно или оба слагаемых находятся не в регистра, а в запоминающем устройстве (ЗУ), учитывается также время пересылки слагаемых в регистры и время записи полученной суммы в ЗУ. В большинстве современных микропроцессоров это время составляет от нескольких сотен наносекунд до нескольких микросекунд.
У У - устройство управления, управляет процессом обработки и обеспечивает связь с внешними устройствами. РЕГИСТРЫ - внутренние носители информации микропроцессора. Это внутренняя память процессора. Регистров - три. Один хранит
команды или инструкции, два других - данные. В соответствии с командами процессор может производить сложение, вычитание или сопоставление содержимого регистров данных.
Основной микропроцессор определяет быстродействие компьютера. Исходный вариант компьютера IBM PC и модель IBM PC XT используют микропроцессор Intel-8088. Модель IBM PC AT использует более мощный микропроцессор Intel-80286 и ее
производительность приблизительно в 5-6 раз больше, чем у IBM PC XT. Модели серии PC/2 используют более мощный микропроцессор Intel-80386. Их производительность приблизительно в 3-4 раза больше, чем у IBM PC AT, однако это увеличение производительности существенно, в основном, для решения задач, требующих большого об'ема вычислений.
Характеристики микропроцессоров. Микропроцессоры отличаются друг от друга двумя характеристиками: типом(моделью) и тактовой частотой. Наиболее распространены модели Intel-8088, 80286, 80386SX, 80386(DX), 80486(SX, SX2, DX, DX2, DX4 и т. д.) и Pentium, они приведены в порядке возрастания производительности и цены. Одинаковые модели микропроцессоров могут иметь разную тактовую частоту - чем
выше тактовая частота, тем выше производительность и цена микропроцессора.
Тактовая частота указывает, сколько элементарных операций(тактов) микропроцессор выполняет в одну секунду. Тактовая частота измеряется в мегагерцах(МГц). Следует
заметить, что разные модели микропроцессоров выполняют одни и те же операции (например, сложение или умножение) за разное число тактов. Чем выше модель микропроцессора, тем меньше тактов требуется для выполнения одних и тех же операций. Поэтому микропроцессор Intel-80386 работает в два раза быстрее Intel-80286 с такой же частотой.
Сопроцессоры. Микропроцессоры 8088, 80286, 80386 сконструированы так, что они позволяют использовать арифметические сопроцессоры 8087, 80287, 80387 фирмы
"Intel"-соответственно.
Специализация сопроцессоров состоит в быстрой обработке чисел с плавающей запятой. Они могут выполнять как обычные операции сложения, вычетания, умножения и деления, так и более сложные операции, такие как вычисление тригонометрических
функций
Конструктивно заложенные в микропроцессор сигналы, позволяют передавать работу сопроцессору и затем получать результаты обработки. Чтобы использовать арифметический сопроцессор, находящийся в составе компьютера, необходимы
программы, которые могут выдавать специальные коды, необходимые для запуска сопроцессора.
ОСНОВНОЙ АЛГОРИТМ РАБОТЫ ПРОЦЕССОРА.
Процессор начинает работу после того, как программа записана в память ЭВМ, а в Счетчик Команд записан адрес первой команды программы. Работу процессора можно описать следующим циклом:
¦ чтение команды из памяти по адресу, записанному в СК
¦ увеличение СК на длину прочитанной команды
¦ выполнение прочитанной команды
Обратите внимание, что после чтения очередной команды процессор увеличивает СК на длину команды. Поэтому при следующем выполнении тела цикла процессор прочтет и выполнит следующую команду программы, потом еще одну и т. д. Цикл закончится, когда встретится и будет выполнена специальная команда "стоп". В итоге ЭВМ автоматически, без участия человека, команда за командой выполнит всю команду целиком.
Автоматизм работы процессора, возможность выполнения длинных последовательностей команд без участия человека – одна из основных отличительных осбенностей ЭВМ как универсальной машины обработки информации.
ПРИНЦИП ПРОГРАММНОГО
УПРАВЛЕНИЯ.
Память машины можно представлять себе как длинную страницу, состоящую из отдельных строк. Каждая такая строка называется ячейкой памяти., и в свою очередь, разделяется на разряды. Содержимым любого разряда может быть либо 0, либо 1.
Значит, в любую ячейку памяти записывается некоторый набор нулей и единиц - машинное слово. Все ячейки памяти занумерованы. Номер ячейки называют её адресом.
Наличие у каждой ячейки адреса позволяет отличать ячейки друг от друга, обращаться к любой ячейке, чтобы записать в неё новую информацию или извлечь ту информацию, которая в ней хранится.
Все ЭВМ работают в принципе одинаково. Когда бы вы ни заглянули в память ЭВМ, в её ячейках хранятся наборы нулей и единиц. ЭВМ выполняет без участия человека не только одну команду, но и длинную последовательность команд (программу). В этом и состоит один из основных принципов работы ЭВМ – принцип программного управления.
Каждая команда кодируется некоторой последовательностью из нулей и единиц и помещается, как и число, в одной ячейке оперативной памяти. Команда состоит из двух частей : кодовой и адресной. Кодовая часть команды указывает, какое действие должно быть выполнено, а адресная определяет расположение в памяти компьютера исходных данных и результата.
Общий вид команды машины может быть таким: К А1 А2 А3 , где К - код действия, а А1,А2,А3 - адреса ячеек памяти (на каждый адрес отводится по три разряда). Для выполнения команд служит специальное арифметико-логическое устройство.(АЛУ). Оно состоит из двух особых ячеек - счётчика команд и регистра команд, а также сумматора. При выполнении ЭВМ программы в счётчик команд последовательно заносятся номера ячеек, где содержатся исполняемые команды, сами команды помещаются в регистр команд,
а в сумматоре происходят арифметические действия. Сумматор также имеет свою ячейку - для промежуточных результатов вычислений. Отметим, что команды современных ЭВМ могут занимать несколько ячеек памяти.
Сравнение архитектуры POWER с другими RISC архитектурами.
Архитектура POWER
1. Эволюция архитектуры POWER в направлении архитектуры PowerPC
2. PowerPC 601
3. Процессор PowerPC 603
Описание архитектуры и принципов работы микропроцессоров семейства PowerPC
1. Общие сведения
2. Архитектура и работа процессора.
2.1 Поток команд.
2.2 Очередь команд и устройство распределения.
2.3 Устройство обработки переходов.
2.4 Устройство завершения команд.
2.5 Устройства выполнения.
2.5.1 Устройства выполнения целочисленных команд (IU).
2.5.2 Устройство выполнения команд с плавающей точкой (FPU)
2.5.3 Устройство загрузки/записи (LSU).
2.5.4 Устройство системных регистров (SRU).
2.6 Устройство управления памятью (MMU)
2.7 Встроенные кэши команд и данных.
3. Системный интерфейс. Схема выводов процессора.
3.1 Шины адреса и данных функционируют раздельно. Используются два вида доступов к памяти и
пересылки данных.
3.2 Группы выводов процессора 750.
4. Регистры и программная модель PowerPC.
4.1 Регистры PowerPC.
4.2 Система команд PowerPC.
Архитектура POWER
Архитектура POWER во многих отношениях представляет собой традиционную RISC-архитектуру. Она придерживается наиболее важных отличительных особенностей RISC: фиксированной длины команд, архитектуры регистр-регистр, простых способов адресации, простых (не требующих интерпретации) команд, большого регистрового файла и трехоперандного (неразрушительного) формата команд. Однако архитектура POWER имеет также несколько дополнительных свойств, которые отличают ее от других RISC-архитектур.
Во-первых, набор команд был основан на идее суперскалярной обработки. В базовой архитектуре команды распределяются по трем независимым исполнительным устройствам: устройству переходов, устройству с фиксированной точкой и устройству с плавающей точкой. Команды могут направляться в каждое из этих устройств одновременно, где они могут выполняться одновременно и заканчиваться не в порядке поступления. Для увеличения уровня параллелизма, который может быть достигнут на практике, архитектура набора команд определяет для каждого из устройств независимый набор регистров. Это минимизирует связи и синхронизацию, требуемые между устройствами, позволяя тем самым исполнительным устройствам настраиваться на динамическую смесь команд. Любая связь по данным, требующаяся между устройствами, должна анализироваться компилятором, который может ее эффективно спланировать. Следует отметить, что это только концептуальная модель. Любой конкретный процессор с архитектурой POWER может рассматривать любое из концептуальных устройств как множество исполнительных устройств для поддержки дополнительного параллелизма команд. Но существование модели приводит к согласованной разработке набора команд, который естественно поддерживает степень параллелизма по крайней мере равную трем.
Во-вторых, архитектура POWER расширена несколькими "смешанными" командами для сокращения времен выполнения. Возможно единственным недостатком технологии RISC по сравнению с CISC, является то, что иногда она использует большее количество команд для выполнения одного и того же задания. Было обнаружено, что во многих случаях увеличения размера кода можно избежать путем небольшого расширения набора команд, которое вовсе не означает возврат к сложным командам, подобным командам CISC. Например, значительная часть увеличения программного кода была обнаружена в кодах пролога и эпилога, связанных с сохранением и восстановлением регистров во время вызова процедуры. Чтобы устранить этот фактор IBM ввела команды "групповой загрузки и записи", которые обеспечивают пересылку нескольких регистров в/из памяти с помощью единственной команды. Соглашения о связях, используемые компиляторами POWER, рассматривают задачи планирования, разделяемые библиотеки и динамическое связывание как простой, единый механизм. Это было сделано с помощью косвенной адресации посредством таблицы содержания (TOC - Table Of Contents), которая модифицируется во время загрузки. Команды групповой загрузки и записи были важным элементом этих соглашений о связях.
Другим примером смешанных команд является возможность модификации базового регистра вновь вычисленным эффективным адресом при выполнении операций загрузки или записи (аналог автоинкрементной адресации). Эти команды устраняют необходимость выполнения дополнительных команд сложения, которые в противном случае потребовались бы для инкрементирования индекса при обращениях к массивам. Хотя это смешанная операция, она не мешает работе традиционного RISC-конвейера, поскольку модифицированный адрес уже вычислен и порт записи регистрового файла во время ожидания операции с памятью свободен.
Архитектура POWER обеспечивает также несколько других способов сокращения времени выполнения команд такие как: обширный набор команд для манипуляции битовыми полями, смешанные команды умножения-сложения с плавающей точкой, установку регистра условий в качестве побочного эффекта нормального выполнения команды и команды загрузки и записи строк (которые работают с произвольно выровненными строками байтов).
Третьим фактором, который отличает архитектуру POWER от многих других RISC-архитектур, является отсутствие механизма "задержанных переходов". Обычно этот механизм обеспечивает выполнение команды, следующей за командой условного перехода, перед выполнением самого перехода. Этот механизм эффективно работал в ранних RISC-машинах для заполнения "пузыря", появляющегося при оценке условий для выбора направления перехода и выборки нового потока команд. Однако в более продвинутых, суперскалярных машинах, этот механизм может оказаться неэффективным, поскольку один такт задержки команды перехода может привести к появлению нескольких "пузырей", которые не могут быть покрыты с помощью одного архитектурного слота задержки. Почти все такие машины, чтобы устранить влияние этих "пузырей", вынуждены вводить дополнительное оборудование (например, кэш-память адресов переходов). В таких машинах механизм задержанных переходов становится не только мало эффективным, но и привносит значительную сложность в логику обработки последовательности команд. Вместо этого архитектура переходов POWER была организована для поддержки методики "предварительного просмотра условных переходов" (branch-lockahead) и методики "свертывания переходов" (branch-folding).
Методика реализации условных переходов, используемая в архитектуре POWER, является четвертым уникальным свойством по сравнению с другими RISC-процессорами. Архитектура POWER определяет расширенные свойства регистра условий. Проблема архитектур с традиционным регистром условий заключается в том, что установка битов условий как побочного эффекта выполнения команды, ставит серьезные ограничения на возможность компилятора изменить порядок следования команд. Кроме того, регистр условий представляет собой единственный архитектурный ресурс, создающий серьезное узкое горло в машине, которая параллельно выполняет несколько команд или выполняет команды не в порядке их появления в программе. Некоторые RISC-архитектуры обходят эту проблему путем полного исключения из своего состава регистра условий и требуют установки кода условий с помощью команд сравнения в универсальный регистр, либо путем включения операции сравнения в саму команду перехода. Последний подход потенциально перегружает конвейер команд при выполнении перехода. Поэтому архитектура POWER вместо того, чтобы исправлять проблемы, связанные с традиционным подходом к регистру условий, предлагает: a) наличие специального бита в коде операции каждой команды, что делает модификацию регистра условий дополнительной возможностью, и тем самым восстанавливает способность компилятора реорганизовать код, и b) несколько (восемь) регистров условий для того, чтобы обойти проблему единственного ресурса и обеспечить большее число имен регистра условий так, что компилятор может разместить и распределить ресурсы регистра условий, как он это делает для универсальных регистров.
Другой причиной выбора модели расширенного регистра условий является то, что она согласуется с организацией машины в виде независимых исполнительных устройств. Концептуально регистр условий является локальным по отношению к устройству переходов. Следовательно, для оценки направления выполнения условного перехода не обязательно обращаться к универсальному регистровому файлу (который является локальным для устройства с фиксированной точкой). Для той степени, с которой компилятор может заранее спланировать модификацию кода условия (и/или загрузить заранее регистры адреса перехода), аппаратура может заранее просмотреть и свернуть условные переходы, выделяя их из потока команд. Это позволяет освободить в конвейере временной слот (такт) выдачи команды, обычно занятый командой перехода, и дает возможность диспетчеру команд создавать непрерывный линейный поток команд для вычислительных исполнительных устройств.
Первая реализация архитектуры POWER появилась на рынке в 1990 году. С тех пор компания IBM представила на рынок еще две версии процессоров POWER2 и POWER2+, обеспечивающих поддержку кэш-памяти второго уровня и имеющих расширенный набор команд.
По данным IBM процессор POWER требует менее одного такта для выполнении одной команды по сравнению с примерно 1.25 такта у процессора Motorola 68040, 1.45 такта у процессора SPARC, 1.8 такта у Intel i486DX и 1.8 такта Hewlett-Packard PA-RISC. Тактовая частота архитектурного ряда в зависимости от модели меняется от 25 МГц до 62 МГц.
Процессоры POWER работают на частоте 33, 41.6, 45, 50 и 62.5 МГЦ. Архитектура POWER включает раздельную кэш-память команд и данных (за исключением рабочих станций и серверов рабочих групп начального уровня, которые имеют однокристальную реализацию процессора POWER и общую кэш-память команд и данных), 64- или 128-битовую шину памяти и 52-битовый виртуальный адрес. Она также имеет интегрированный процессор плавающей точки и таким образом хорошо подходит для приложений с интенсивными вычислениями, типичными для технической среды, хотя текущая стратегия RS/6000 нацелена как на коммерческие, так и на технические приложения. RS/6000 показывает хорошую производительность на плавающей точке: 134.6 SPECp92 для POWERstation/Powerserver 580. Это меньше, чем уровень моделей Hewlett-Packard 9000 Series 800 G/H/I-50, которые достигают уровня 150 SPECfp92.
Для реализации быстрой обработки ввода/вывода в архитектуре POWER используется шина Micro Channel, имеющая пропускную способность 40 или 80 Мбайт/сек. Шина Micro Channel включает 64-битовую шину данных и обеспечивает поддержку работы нескольких главных адаптеров шины. Такая поддержка позволяет сетевым контроллерам, видеоадаптерам и другим интеллектуальным устройствам передавать информацию по шине независимо от основного процессора, что снижает нагрузку на процессор и соответственно увеличивает системную производительность.
Многокристальный набор POWER2 состоит из восьми полузаказных микросхем (устройств):
l Блок кэш-памяти команд (ICUКбайт, имеет два порта с 128-битовыми шинами;
l Блок устройств целочисленной арифметики (FXU) - содержит два целочисленных конвейера и два блока регистров общего назначения (побитовых регистра). Выполняет все целочисленные и логические операции, а также все операции обращения к памяти;
l Блок устройств плавающей точки (FPU) - содержит два конвейера для выполнения операций с плавающей точкой двойной точности, а такжебитовых регистра плавающей точки;
l Четыре блока кэш-памяти данных - максимальный объем кэш-памяти первого уровня составляет 256 Кбайт. Каждый блок имеет два порта. Устройство реализует также ряд функций обнаружения и коррекции ошибок при взаимодействии с системой памяти;
l Блок управления памятью (MMU).
Набор кристаллов POWER2 содержит порядка 23 миллионов транзисторов на площади 1217 квадратных мм и изготовлен по технологии КМОП с проектными нормами 0.45 микрон. Рассеиваемая мощность на частоте 66.5 МГц составляет 65 Вт.
Производительность процессора POWER2 по сравнению с POWER значительно повышена: при тактовой частоте 71.5 МГц она достигает 131 SPECint92 и 274 SPECfp92.
1. Эволюция архитектуры POWER в направлении архитектуры PowerPC
Компания IBM распространяет влияние архитектуры POWER в направлении малых систем с помощью платформы PowerPC. Архитектура POWER в этой форме может обеспечивать уровень производительности и масштабируемость, превышающие возможности современных персональных компьютеров. PowerPC базируется на платформе RS/6000 в дешевой конфигурации. В архитектурном плане основные отличия этих двух разработок заключаются лишь в том, что системы PowerPC используют однокристальную реализацию архитектуры POWER, изготавливаемую компанией Motorola, в то время как большинство систем RS/6000 используют многокристальную реализацию. Имеется несколько вариаций процессора PowerPC, обеспечивающих потребности портативных изделий и настольных рабочих станций, но это не исключает возможность применения этих процессоров в больших системах. Первым на рынке был объявлен процессор 601, предназначенный для использования в настольных рабочих станциях компаний IBM и Apple. За ним последовали кристаллы 603 для портативных и настольных систем начального уровня и 604 для высокопроизводительных настольных систем. Наконец, процессор 620 разработан специально для серверных конфигураций и ожидается, что со своей 64-битовой организацией он обеспечит исключительно высокий уровень производительности.
При разработке архитектуры PowerPC для удовлетворения потребностей трех различных компаний (Apple, IBM и Motorola) при сохранении совместимости с RS/6000, в архитектуре POWER было сделано несколько изменений в следующих направлениях:
l упрощение архитектуры с целью ее приспособления ее для реализации дешевых однокристальных процессоров;
l устранение команд, которые могут стать препятствием повышения тактовой частоты;
l устранение архитектурных препятствий суперскалярной обработке и внеочередному выполнению команд;
l добавление свойств, необходимых для поддержки симметричной многопроцессорной обработки;
l добавление новых свойств, считающихся необходимыми для будущих прикладных программ;
l ясное определение линии раздела между "архитектурой" и "реализацией";
l обеспечение длительного времени жизни архитектуры путем ее расширения до 64-битовой.
Архитектура PowerPC поддерживает ту же самую базовую модель программирования и назначение кодов операций команд, что и архитектура POWER. В тех местах, где были сделаны изменения, которые могли потенциально препятствовать процессорам PowerPC выполнять существующие двоичные коды RS/6000, были расставлены "ловушки", обеспечивающие прерывание и эмуляцию с помощью программного обеспечения. Такие изменения вводились, естественно, только в тех случаях, если соответствующая возможность либо использовалась не очень часто в кодах прикладных программ, либо была изолирована в библиотечных программах, которые можно просто заменить.
2. PowerPC 601
Первый микропроцессор PowerPC, PowerPC 601, в настоящее время выпускается как компанией IBM, так и компанией Motorola. Он представляет собой процессор среднего класса и предназначен для использования в настольных вычислительных системах малой и средней стоимости. Он был разработан в качестве переходной модели от архитектуры POWER к архитектуре PowerPC и реализует возможности обеих архитектур. При этом двоичные коды RS/6000 выполняются на нем без изменений, что дало дополнительное время разработчикам компиляторов для освоения архитектуры PowerPC, а также разработчикам прикладных систем, которые должны перекомпилировать свои программы, чтобы полностью использовать возможности архитектуры PowerPC.
Процессор 601 базировался на однокристальном процессоре IBM, который был разработан к моменту создания альянса трех ведущих фирм. Но по сравнению со своим предшественником, PowerPC 601 претерпел серьезные изменения в сторону повышения производительности и снижения стоимости. Например, в его состав было включено более сложное устройство переходов, расширенные возможностями мультипроцессорной работы, включая интерфейс шины высокопроизводительного процессора 88110 компании Motorola. В Power 601 реализована суперскалярная обработка, позволяющая выдавать на выполнение в каждом такте 3 команды, возможно не в порядке их расположения в программном коде.
3. Процессор PowerPC 603
PowerPC 603 является первым микропроцессором в семействе PowerPC, который полностью поддерживает архитектуру PowerPC (рисунок 5.20). Он включает пять функциональных устройств: устройство переходов, целочисленное устройство, устройство плавающей точки, устройство загрузки/записи и устройство системных регистров, а также две, расположенных на кристалле кэш-памяти для команд и данных, емкостью по 8 Кбайт. Поскольку PowerPC 603 - суперскалярный микропроцессор, он может выдавать в эти исполнительные устройства и завершать выполнение до трех команд в каждом такте. Для увеличения производительности PowerPC 603 допускает внеочередное выполнение команд. Кроме того он обеспечивает программируемые режимы снижения потребляемой мощности, которые дают разработчикам систем гибкость реализации различных технологий управления питанием.
При обработке в процессоре команды распределяются по пяти исполнительным устройствам в заданном программой порядке. Если отсутствуют зависимости по операндам, выполнение происходит немедленно. Целочисленное устройство выполняет большинство команд за один такт. Устройство плавающей точки имеет конвейерную организацию и выполняет операции с плавающей точкой как с одинарной, так и с двойной точностью. Команды условных переходов обрабатывается в устройстве переходов. Если условия перехода доступны, то решение о направлении перехода принимается немедленно, в противном случае выполнение последующих команд продолжается по предположению (спекулятивно). Команды, модифицирующие состояние регистров управления процессором, выполняются устройством системных регистров. Наконец, пересылки данных между кэш-памятью данных, с одной стороны, и регистрами общего назначения и регистрами плавающей точки, с другой стороны, обрабатываются устройством загрузки/записи.
В случае промаха при обращении к кэш-памяти, обращение к основной памяти осуществляется с помощью 64-битовой высокопроизводительной шины, подобной шине микропроцессора MC88110. Для максимизации пропускной способности и, как следствие, увеличения общей производительности кэш-память взаимодействует с основной памятью главным образом посредством групповых операций, которые позволяют заполнить строку кэш-памяти за одну транзакцию.
Описание архитектуры и принципов работы микропроцессоров семейства PowerPC
1. Общие сведения
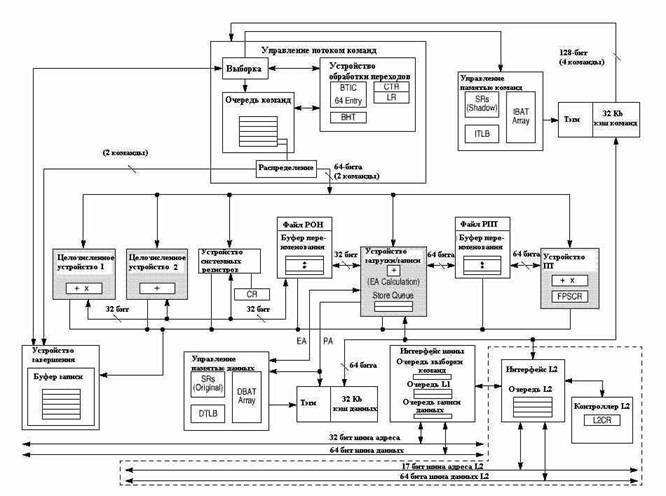
Семейство RISC-процессоров PowerPC в настоящее время состоит из следующих моделей: EC603e, 603e, 604e, 740, 750 (производятся фирмами Motorola и IBM).
В данной работе архитектура и работа микропроцессоров PowerPC рассматривается на базе процессора PowerPC 750. Полную документация по архитектуре и программированию всех процессоров доступна на сайтах Motorola и IBM.
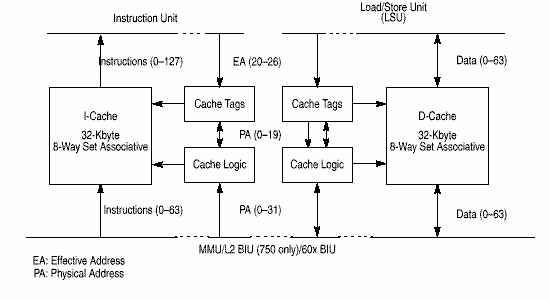
750 реализует 32-разрядную архитектуру PowerPC, которая предоставляет 32-разрядную адресацию, обработку целочисленных данных (8, 16, 32 разряда), данных с плавающей точкой (32 и 64 разряда).
Процессор 750 состоит из следующих устройств выполнения :
· Устройство с плавающей точкой (FPU)
· Устройство обработки переходов (BPU)
· Устройство системных регистров (SRU)
· Устройство загрузки/записи (LSU)
· Два целочисленных устройства (IUs): IU1 - выполняет все команды IU2 - выполняет все команды, кроме умножения и деления
750 является суперскалярным процессором: возможна выборка четырех команд из кэша и выполнение шести команд за один такт. Большинство целочисленных команд выполняется за один такт. Выполнение команд с плавающей точкой разбиваются на три ступени. Одна команда с ПТ занимает одну ступень, таким образом одновременно FPU может выполнять три команды с плавающей точкой (32-разрядные операнды). Сложение 64-разрядных операндов выполняется за три такта, умножение и умножение-сложение за четыре.
750 имеет независимый встроенный восьмиканальный, 32 Кб, физически адресуемый кэш команд и данных, а также независимые устройства управления памятью команд и данных (memory management unit, MMU). Каждое MMU имеет ассоциативный буфер TLB (DTLB и ITLB) для сохранения адресов недавно использованных страниц. Архитектурой PowerPC также определяется наличие таблиц трансляции адресов блоков памяти (block address translation array, IBAT и DBAT), Подробнее работа памяти описана в соответствующем разделе.
Кэш L2 реализован в виде встроенных памяти тэгов и внешней памяти SRAM. Доступ к внешней SRAM происходит через порт кэша L2, который поддерживает один банк памяти до 1 Мб SRAM.
750 имеет 32-разрядную адресную шину и 64-разрядную шину данных. Внешние устройства получают системные ресурсы через устройство внешнего центрального арбитра. В 750 используется MEI (modified/exclusive/invalid) протокол для синхронизации кэша и памяти и предотвращения ошибок при обращении к кэшу.
2. Архитектура и работа процессора.
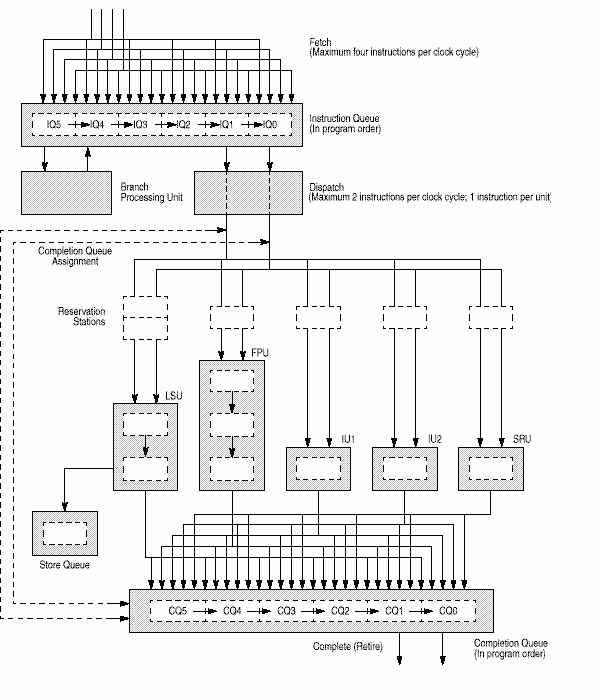
2.1 Поток команд.
Как видно из рисунка, устройство управления потоком команд состоит из устройства последовательной выборки (fetcher), очереди из шести команд (instruction queue, IQ), устройства распределения команд и устройства обработки переходов (BPU).
Оно определяет адрес следующей команды для выборки по информации из устройства выборки и BPU.
Команда загружается из кэша команд в очередь команд. BPU извлекает команды перехода из последовательного загрузчика. Команды перехода, которые не могут быть обработаны немедленно, предсказываются с помощью специальных алгоритмов динамического или статического (определен архитектурой) предсказания переходов.
Команды перехода, не влияющие на LR или CTR (регистры, содержащие адреса переходов), удаляются из потока команд.
Команды из предсказанной ветви не завершаются, пока переход не обработан наверняка, сохраняя программную модель последовательного выполнения. Если переход был неправильным, устройство выполнения уничтожает все предсказанные пути команд и выбирает команды из правильной ветви.
2.2 Очередь команд и устройство распределения.
Очередь команд (IQ) содержит шесть команд и может быть загружена четырьмя командами за такт. Устройство выборки пытается загрузить команды на все свободные места в очереди. Все команды распределяются к соответствующим устройствам выполнения (IU1, IU2, FPU, LSU, SRU) из двух верхних позиций в очереди с максимальной скоростью две за такт. Устройство распределения проверяет зависимости регистров источника и приемника, определяет свободна ли место в очереди завершения команд, и распределяет последовательные команды по назначению.
2.3 Устройство обработки переходов.
BPU получает команды перехода из устройства выборки и делает упреждающий поиск условных ветвей для их раннего предсказания, достигая попадания в большинстве случаев.
Команды безусловного перехода или с известным условием могут быть предсказаны сразу. Для переходов с неопределенными условиями используется динамическое или статическое предсказание. Команды из предсказанной ветви выполняются, но не завершаются и не записывают результаты до подтверждения корректности перехода.
Динамическое предсказание использует таблицу истории переходов (BHT) из 512 записей, кэш который содержит по 2 бита, определяющие 4 уровня вероятности перехода. Когда динамическое предсказание запрещено переход выбирается исходя из бита в коде команды для предсказания условных переходов.
Когда переход сделан ( или предсказан), команды из остальных ветвей удаляются и загружаются команды из нужной ветви. BTIC - кэш на 64 элемента, содержащий команды из последних переходов. Когда команды находятся в BTIC, они считываются на следующем такте, иначе через один такт.
BPU содержит сумматор для вычисления адресов переходов и использует три регистра - регистр связи (LR), регистр-счетчик (CTR) и CR. BPU вычисляет точку возврата из процедуры и сохраняет результат в LR определенных команд перехода. Также в регистрах LR и CTR содержат адреса для некоторых команд обработки переходов. Из-за использования специальных регистров обработка команд переходов независима от выполнения целочисленных команд и команд с ПТ.
2.4 Устройство завершения команд.
В точке распределения команд, порядок выполнения команд поддерживается назначение команде места в очереди завершения на 6 мест. Устройство завершения отслеживает команды от распределения через устройства выполнения и возвращает результаты в порядке выполнения команд в программе из 2 нижних мест в очереди выполнения.
Команда не может быть отправлена на выполнение, если нет места в очереди завершения. Команды перехода, не модифицирующие CTR и LR удаляются из потока команд и не занимают места в очереди завершения. Команды, модифицирующие CTR и LR занимают место в очереди, но не посылаются на выполнение.
Завершение команды состоит в записи результатов в регистры (GPR, FPR, LR и CTR).
Завершенные команды удаляются из очереди завершения.
2.5 Устройства выполнения.
2.5.1 Устройства выполнения целочисленных команд (IU).
Каждое IU состоит из трех однотактовых подустройств - быстрый сумматор/компаратор, обработки логических операций и выполнения сдвигов и циклических сдвигов. Только одно подустройство может выполнять команду в каждый момент времени.
2.5.2 Устройство выполнения команд с плавающей точкой (FPU)
FPU выполняет операции одинарной точности (32 разряда) за один проход, состоящий из трех тактов. Операнды берутся из регистров FPR или буфера переименования FPR. Результаты записываются в буфер переименования регистров и доступны для последующих команд. Команды поступают в FPU в порядке распределения устройством управления командами.
FPU содержит массив для умножения-сложения одинарной точности и контрольный регистр (FPSCR). Массив умножения-сложения позволяет 750 эффективно выполнять команды умножения и умножения-сложения. FPU является конвейерным, так что за один такт выдается одна обработанная команда. Для поддержки команд с ПТ предоставляютсяразрядных регистра. Остановки, вызванные конфликтами при записи в FPR минимизируются 6 регистрами переименования с ПТ. 750 записывает содержимое регистров переименования при выходе команды из устройства завершения.
750 поддерживает все форматы с ПТ стандарта IEEE 754 (нормализованные, ненормализованные, NaN, ноль, бесконечность).
2.5.3 Устройство загрузки/записи (LSU).
LSU выполняет все команды загрузки и сохранения и предоставляет интерфейс пересылки данных между GPR, FPR, и подсистем кэш/память.
Команды загрузки и записи выполняются в порядке программы; однако некоторые обращения в память могут происходить вне очереди команд. Команды синхронизации могут быть использованы для изменения порядка команд. Максимум одна операция загрузки из кэша вне очереди может быть выполнена за такт, с двухтактовой задержкой загрузки из кэша. Данные из кэша хранятся в регистрах переименования до их записи в GPR или FPR. Сохранение не может выполняться вне очереди и операции сохранения находятся в очереди сохранения до разрешения на запись. 750 выполняет команды сохранения максимум одну за такт с общей трехтактовой задержкой записи в кэш.
2.5.4 Устройство системных регистров (SRU).
SRU выполняет различные команды системного уровня, такие как логические операции с регистром условия и команды работы с регистрами специального назначения. Команды, выполняемые SRU, сохраняются в нем и обрабатываются после выполнения всех предыдущих команд.
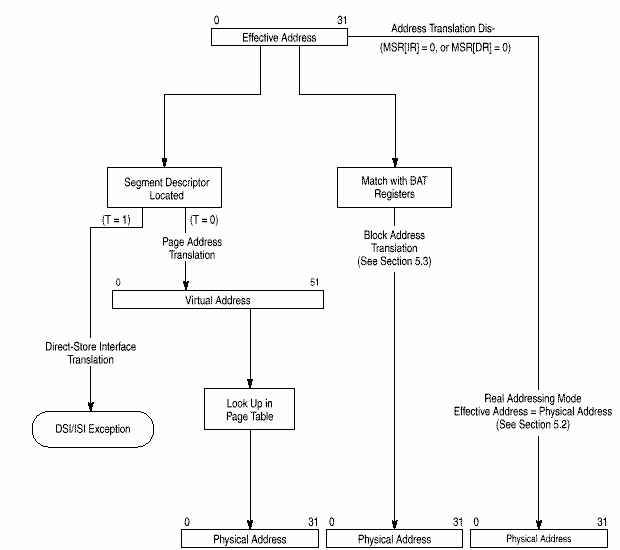
2.6 Устройство управления памятью (MMU).
MMU поддерживает до 4 Петабайт (252) виртуальной памяти и до 4 Гигабайт (232) физической памяти для команд и данных со страницами по 4 Кб и сегментами по 256 Мб. MMU контролирует привилегии доступа, разбивая память на блоки и страницы. Вообще, механизм преобразования адресов состоит в преобразовании эффективного адреса в промежуточный виртуальный исходя из сегментной информации и затем в физический по таблицам страниц. Дескрипторы сегментов, используемые для генерации промежуточного внутреннего адреса, хранятся как встроенные 32-разрядные сегментные регистры.
В 750 реализовано 2 буфера TLB, так что доступ к TLB для команд и данных может производится независимо.
Механизм преобразования адресов блоков (block address translation, BAT) - программно-контролируемый массив доступных преобразований адресов блоков. Механизм BAT управляет преобразованием блоков до 256 Мб из 32-разрядного эффективного адресного пространства в физическое. Используются для преобразования адресов, не часто меняющих свое отображение. Элементами массива BAT являются пары BAT-регистров, доступных в режиме супервизора. В 750 есть отдельные механизмы BAT для команд и данных (4 IBAT и 4 DBAT).
LSU и устройство управления потоком команд вычисляют эффективные адреса данных и команд. MMU преобразует эффективные адреса в физические для доступа к памяти.
750 поддерживает следующие режимы преобразования адресов:
· Реальный (real addressing) - физический адрес совпадает с эффективным.
· Страничный (page address translation) - преобразует адреса страниц (4 Кб)
· Блочный (block address translation) - преобразует базовые адреса блоков (от 128 Кб до 256 Мб)
Если работает преобразование адресов, MMU преобразует старшие биты эффективного адреса в физический. Если адрес найден в массиве BAT, то физический адрес выдается сразу, иначе 32-битный эффективный адрес расширяется в 52-битный виртуальный замещением 24 старших битов на сегментный регистр, адресуемый 4 старшими битами ЕА. 52-разрядные виртуальные адреса разделены на 4 Кб страницы, отображаемые в физические.
Младшие биты адреса одинаковы и используются для вычисления индекса в массиве тэгов кэша. После преобразования адресов MMU посылает физический адрес в кэш и данные считываются. Если кэш не используется или данных в нем нет, то не преобразованные младшие биты соединяются с преобразованными старшими в 32-разрядный физический адрес, который используется для доступа к внешней памяти.
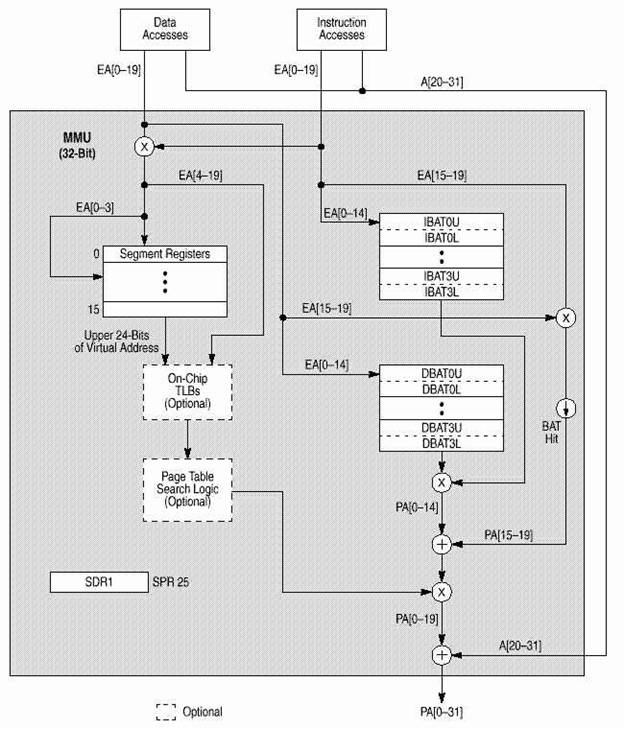
TLB используется для сохранения последних преобразований адресов при обращении к памяти. При каждом обращении, преобразование эффективного адреса по страницам или блокам производится одновременно. Если преобразование найдено и в TLB и в BAT, используется преобразование адреса блока в BAT. Обычно преобразование адреса находится в TLB и физический адрес доступен для считывания из кэша сразу. Иначе адрес ищется в таблице страниц следуя модели, определенной архитектурой PowerPC.
TLB команд и данных преобразует адрес одновременно с доступом к внутреннему кэшу, исключая затраты времени в случае попадания в TLB.
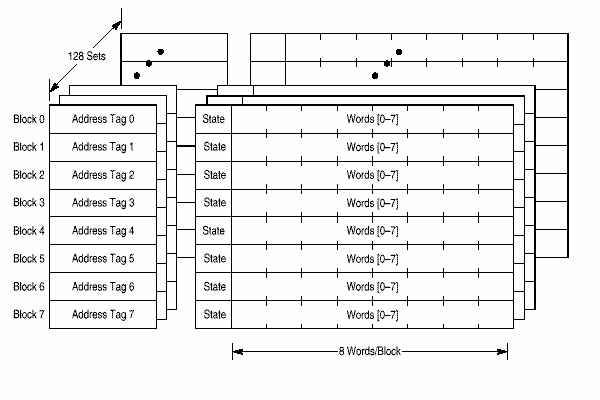
В 750 реализованы отдельные 32 Кб кэши для команд и данных (Гарвардская архитектура). Оба кэша восьмиканальные частично ассоциативные. По архитектуре PowerPC кэши адресуются физически, реальный адрес хранится в директории кэша. Оба кэша организованы в блоки по 32 байта. Блок кэша - блок памяти, для которого описано состояние когерентности. Для каждого банка данных кэша используется алгоритм PLRU (pseudo least-recently-used) замены данных (алгоритм изложен в документации). Когерентность данных глобальной памяти и данных в кэше производится по протоколу MEI процедурой слежения (snooping) по шине когерентности. Состояния когерентности для кэша данных: Modified (Exclusive) (M), Exclusive (Unmodified) (E), Invalid (I). Для кэша команд: Invalid (INV), Valid (VAL). Каждый кэш можно сделать недействительным (invalidate) установкой соответствующих битов в специальных регистрах (HID0).
При непопадании в кэш, блоки заполняются за 4 прохода по 64 бита. Двойные слова одновременно записываются в кэш и в запрашивающее устройство, минимизируя задержки.
Оба кэша тесно связаны с устройством шины интерфейса (bus interface unit, BUI). BUI получает запросы от кэшей и выполняет эти операции в соответствии с протоколом 60х. BUI предоставляет очереди адресов, логику приоритетов и логику контроля шины.
Кэш данных предоставляет буферы для сохранения и загрузки операций шины. Все данные из соответствующих адресных очередей помещены в кэш данных. В кэше данных также производится сохранение тэгов, требуемых для когерентности с памятью и замещение блоков кэша функциями PLRU.
Кэш данных организован в 128 банков по 8 блоков. Каждый блок содержит 32 байта, 2 бита состояния и адресный тэг. Каждый блок кэша содержит 8 последовательных слов из памяти которые загружаются с границы в 8 слов (т. е. биты ЕА[27-31] равны 0): таким образом блок кэша никогда не пересекает границу страницы. Не выровненные обращения через границу страницы могут повлечь уменьшение производительности. Во время загрузки данных кэш не блокируется для внешних доступов до полной загрузки.
В течение такта кэш данных предоставляет для считывания в LSU двойное слово. Как и кэш команд, кэш данных может быть сделан недействительным (invalidated) весь или поблочно. Данные кэша делаются недоступными и недействительными сбросом HID0[DCE] и установкой HID0[DCFI], кэш данных может быть заблокирован установкой HID0[DLOCK]. Тэги кэша имеют один порт, поэтому одновременная загрузка/сохранение и обращения для когерентности кэша вызывают конфликт, при этом LSU внутренне блокируется на один такт для записи блока данных в 8 слов в буфер обратной записи.
Кэш команд также состоит из 128 банков по 8 блоков. Каждый блок состоит из 32 байтов, 1 бита состояния и адресного тэга. За один цикл кэш команд предоставляет до 4 команд в очередь команд. В кэше команд поддерживаются только состояния верно/неверно (valid/invalid) для данных. Кэш команд не отслеживается, поэтому если изменяется память, данные которой содержатся в кэше, программа должна сообщать об этом устройству выборки команд. Кэш команд может быть сделан недействительным весь или поблочно. Доступ к кэшу запрещается и кэш делается недействительным сбросом HID0[ICE] и установкой HID0[ICFI], кэш блокируется установкой HID0[ILOCK].
В 750 реализован также кэш команд переходов (branch target instruction cache, BTIC). В BTIC хранятся встретившиеся в программе команды переходов/циклов. Если команда находится в BTIC она поступает в очередь команд на такт быстрее, чем из кэша команд.
3. Системный интерфейс. Схема выводов процессора.
3.1 Шины адреса и данных функционируют раздельно. Используются два вида доступов к памяти и пересылки данных:
· Однотактовая (single-beat) пересылка - пересылка 8, 16, 24, 32 или 64 битов за такт шины. Используется при некэшируемых доступах в память.
· Четырехтактовая пакетная (four-beat burst) пересылка данных - используется для чтения блоков кэша. Так как кэши первого уровня с обратной записью, то пакетные доступы к памяти используются наиболее часто.
Доступ к системной шине дается через механизм внутреннего арбитража.
Обычно доступы к памяти слабо упорядочены - последовательности команд загрузки/записи не обязательно выполнять в порядке их следования - то есть можно максимизировать эффективность использования шины без потери когерентности. 750 позволяет выполнять операции загрузки/записи не в порядке расположения в очереди команд (если нет зависимостей между ними и нет случаев некэшируемых доступов).
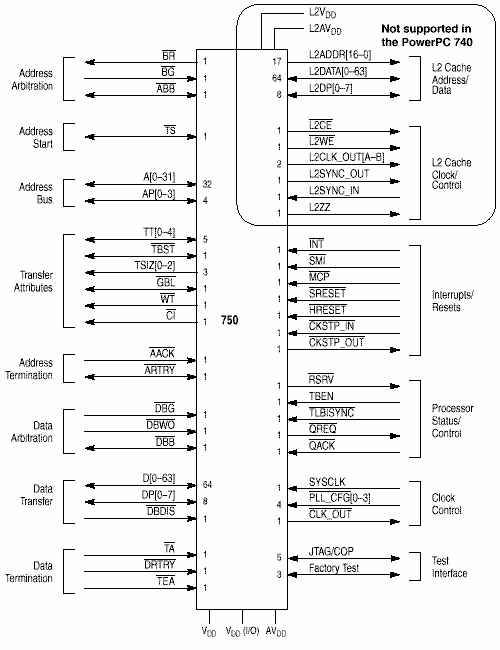
3.2 Процессор 750 имеют следующие группы выводов:
· Арбитраж шины адресов
1. BR (Bus Request) Output - запрос операций на шине адреса
2. BG (Bus Grant) Input - разрешение операций на шине адреса
3. ABB (Address Bus Busy) Output - указывает, что 750 является мастером шины. Input - указывает на занятость шины.
· Старт передачи адреса - показывает, что мастер шины (bus master) начал транзакцию на шине адреса.
1. TS (Transfer Start) Output - указывает, что 750 начал транзакцию и шина адреса и атрибуты верны. Input - другой мастер шины начал транзакцию и шина адреса и ат-рибуты доступны для слежения.
· Передачи адреса - включает в себя шину адреса и сигналы четности адреса для про-верки.
1. A[0-31] (Address Bus) Output - физический адрес данных для пересылки. Input - фи-зический адрес для операции слежения (snooping) .
2. AP[0-3] (Address Bus Parity) Output - четность для каждых 4 байт адреса. Input - чет-ность для каждых 4 байт адреса для операции слежения.
· Атрибуты пересылки - показывают размер пересылки, является ли пакетной, прямой записью или бескэшевой.
1. TT[0-4] (Transfer Type) Output - текущий тип пересылки
2. TSIZ[0-2] (Transfer Size) Output - размер текущей пересылки данных.
3. TBST (Transfer Burst) Output - указывает на текущую пакетную пересылку.
4. CI (Cache Inhibit) Output - указывает, что однотактовые пересылки не кэшируются.
5. WT (Write Through) Output - указывает, что однотактовая транзакция записывается write-through. Сигнал чтении показывает выборку команды или загрузку данных.
6. GBL (Global) Output - указывает, что транзакция глобальная. Input - указывает, что транзакция должна быть отслежена.
· Завершения передачи адреса - подтверждают конец адресной фазы транзакции.
1. AACK (Address Acknowledge) Input - указывает на завершение адресной фазы тран-закции.
2. ARTRY (Address Retry) Output - указывает, что 750 обнаружил условия при которых фаза передачи адреса должна быть повторена.
· Арбитраж шины данных.
1. DBG (Data Bus Grant) Input - доступ к операциям на шине данных
2. DBWO (Data Bus Write Only) Input - указывает на возможность записи по внеоче-редному адресу, даже если адрес чтения стоит перед адресом записи.
3. DBB (Data Bus Busy) Output - указывает, что 750 является мастером шины. Input - другое устройство мастер шины.
· Пересылка данных - содержит сигналы шины данных и четности.
1. DH[0-31], DL[0-31] (Data Bus) - шина данных раздела на две половины - верхняя шина (DH) и нижнюю шину (DL). Output - состояние данных при записи. Input - данные при чтении.
2. DP[0-7] (Data Bus Parity) Output - четность для каждых 8 бит при транзакции запи-си/чтения.
3. DBDIS (Data Bus Disable) - указывает, что 750 должен освободить шину данных и четности в течение текущего цикла.
· Завершения пересылки данных - сигналы завершения требуются после каждого цикла пересылки данных. В одноцикловых (single-beat) транзакциях сигналы завершения указывают на окончания владения шиной, при пакетных доступах сигналы завершения поступают после каждого цикла и отдельно сигнал окончания владения шиной.
1. TA (Transfer Acknowledge) - указывает на удачное завершение цикла пересылки данных.
2. DRTRY (Data Retry) - указывает на недействительность данных предыдущей пере-сылки
3. TEA (Transfer Error Acknowledge) - ошибка на шине.
· Адрес/данные кэша Lимеет отдельные шины адреса и данных для доступа к кэшу L2.
· Тактовые/контрольные сигналы кэша L2.
· Сигналы прерываний/сброса - сигналы внешних прерываний, ошибочных остановок, программных и аппаратных сбросов.
1. INT (Interruptвызывает прерывание если MSR[EE] установлен, иначе преры-вание игнорируется.
2. SMI (System Management Interrupt) - прерывание системного управления, если
MSR [EE] установлен.
3. MCP (Machine Check Interrupt)
4. CKSTP_IN (Checkstop Interruptдолжен прервать операцию и сбросить все выходы 5. CKSTP_OUT - указывает на наступление условия остановки.
6. HRESET (Hard Reset) - полное аппаратное прерывание.
7. SRESET (Soft Reset) - начинает процесс исключительной ситуации сброса.
· Статус процессора и контроль - устанавливают бит когерентности станций резерва-ции, временную базу и другие функции.
· Контроля тактовой частоты.
· Тестовый интерфейс.
4. Регистры и программная модель PowerPC.
Архитектура PowerPC включает в себя следующие уровни:
· Уровень команд пользователя (user instruction set architecture, UISA) - определяет базовые пользовательские команды, регистры, типы данных, модели память и про-граммирования для однопроцессорной среды.
· Архитектура виртуальной среды (virtual environment architecture, VEA) - определяет модель памяти для мультипроцессорной среды, команды контроля кэша и другие па-раметры виртуальной среды.
· Архитектура операционной среды (OEA) - определяет модель управления памя-тью, регистры супервизора, требования синхронизации и модель исключений.

4.1 Регистры PowerPC.
Регистры определены на всех трех уровнях архитектуры PowerPC. Архитектура PowerPC определяет операции регистр-регистр для всех команд обработки. Источником данных является встроенные регистры или непосредственные операнды. Трехрегистровый формат команд позволяет отличать регистр результата от 2 регистров-источников, по-зволяя использовать их в других командах. Данные пересылаются между памятью и ре-гистрами только специальными командами загрузки/сохранения.
Регистры процессора 750 показаны на рисунке.
· Регистры пользовательского уровня (UISA) - доступны из всех программ с уровнями привилегий пользователя или супервизора.
Регистры общего назначения (GPR). 32 регистра GPR (GPR0-GPR31) используются как источники или приемники для целочисленных команд и предоставляют данные для формирования адреса.
Регистры с ПТ (FPR). 32 регистра FPR (FPR0-FPR31) используются как источники или приемники данных в командах с ПТ. Все регистры FPR поддерживают формат ПТ с двойной точностью.
Регистр условия (CR). 32-битный регистр, состоит из восьми 4-битных полей, CR0-CR7, отражает результаты определенных арифметических операций и обес-печивают механизм тестирования и переходов.
Регистр контроля и статуса операций с ПТ (FPSCR). FPSCR содержит тип резуль-тата операции с ПТ, все сигнальные биты исключительных ситуаций с ПТ, биты общих исключений, биты разрешения исключений и биты контроля для совмес-тимости со стандартом IEEE 754.
Остальные регистры уровня пользователя являются регистрами специального назна-чения (SPR). В PowerPC используется специальный механизм для явного доступа к SPR (команды mtspr и mfspr).
Регистр целочисленных исключений (XER). XER показывает переполнение или перенос для целочисленных операций.
Регистр связи (LR) LR предоставляет адрес перехода для команды Branch condition to link register (bclr) и может быть использован для хранения логического адреса команды следующей за переходом и связи команд, обычно для связи с про-цедурами.
Регистр-счетчик (CTR). Содержит счетчик цикла, который может уменьшатся на 1 при выполнении определенных команд перехода.
· Регистры пользовательского уровня (VEA) — PowerPC VEA определяет механизм базы времени (time base facility, TB), который состоит из двух 32-битных регистров - time base upper (TBU) и time base lower (TBL). Изменяются командами супервизора и доступны для чтения на пользовательском уровне.
· Регистры уровня супервизора (OEA) — OEA определяет регистры, используемые операционной системой для управления памятью, конфигурированием, обработкой исключений и других функций. Определены следующие 32-разрядные регистры:
Регистры конфигурации
-Регистр состояния машины (MSR). MSR определяет режимы работы
процессора.
Изменяется командами Move to machine state register (mtmsr), System Call (sc) и
Return from Exception (rfi).
- Регистр модели процессора (PVR). Регистр только для чтения, идентифицирует
модель и уровень архитектуры PowerPC процессора (0х0008 для 750).
Регистры управления памятью
- Регистры преобразования адресов блоков (BAT). PowerPC OEA включает в се -
бя массив регистров для преобразований адресов блоков, которые могут зада -
вать 4 блока для команд и 4 блока для данных. Регистры BAT реализованы по -
парно - 4 пары BAT команд (IBAT0U-IBAT3U и IBAT0L-IBAT3L) и 4 пары BAT
данных (DBAT0U-DBAT3U и DBAT0L-DBAT3L). Из-за раздельной загрузки
старших и нижних слов BAT, программа должна проверять преобразование
BAT во время загрузки регистров.
- Сегментный регистр (SR). Определеныбитных сегментных регистра
(SR0-SR15). Поля сегментных регистров интерпретируется по разному в
зависимости от значения бита 0. В 750 реализованы отдельные MMU для ко -
манд и данных. Регистры SR относятся к MMU данных. Для MMU команд
используются SR в других, так называемых «теневых» сегментных регистрах.
Регистры обработки исключений
-Регистр адреса данных (DAR). После ошибки преобразования адреса DAR
содержит эффективный адрес, сгенерированный ошибочной командой.
- SPRG0-SPRG3. Используются операционной системой.
- DSISR. Определяет причину ошибки преобразования адреса.
- Регистр сохранения/восстановления статуса машины 0 (SRR0). Содержит адрес
команды выполняющейся после обработки исключения.
- Регистр сохранения/восстановления статуса машины 1 (SRR1). Сохраняет статус
машины при исключении и восстанавливает после обработки исключения.
Разные регистры.
- База времени (TB). TB является 64-битной структурой для поддержки времени и
таймера.
-Регистр декремента (DEC). 32-битный счетчик с декрементом,
предоставляющий механизм вызова исключительной ситуации декремента после
программной задержки.
Остальные регистры уровня супервизора являются регистрами специального назначения, специфическими для процессора 750. С их назначением можно ознакомится в соответст-вующей документации.
4.2 Система команд PowerPC.
Все команды имеют длину 32 бита. Форматы всех команд можно найти в документации В основном команды имеют следующие поля:
0-5 биты - код команды
6-10 биты - rD(destination) / rS(source) / crfD(результат в поле регистра CR или FPSCR) / crbD(результат как бит регистра CR или FPSCR)
11-15 биты - rA(регистр источник или приемник) / crbA(бит регистра CR как источник) / crfS(поле регистра CR или FPSCR как источник)
16-20 биты - rB(регистр как источник) / crbB(бит регистра CR как источник)
16-31 биты - SIMM(операнд со знаком) / UIMM (операнд без знака)
Целочисленные команды оперируют с операндами размером в слово (16 бит). Команды с ПТ оперируют с операндами одинарной или двойной точности. По архитектуре PowerPC ко-манды имеют длину 4 байта. Пересылка между памятью и регистрами общего назначения производится байтами, полусловами и словами. Пересылка между памятью и регистрами с ПТ производится словами и двойными словами.
Арифметические и логические команды не читают и не изменяют память. Содержимое па-мяти должно быть загружено в регистр и затем использовано в вычислениях. Загрузку и за-пись выполняют специальные команды.
Программы обращаются к памяти используя 32-битный эффективный (логический) адрес, вычисляемый процессором при обращении к памяти, выполнении перехода или выборке команды. Если при вычислении эффективный адрес превышает максимальный, адрес опе-ранда рассматривается как расположенный циклически через нулевой эффективный адрес.
Байты в памяти нумеруются последовательно, начиная с 0 и каждый номер является адресом байта. Адресом операнда в памяти является адрес его первого байта.
Для команд перехода как эффективный адрес используется непосредственный операнд или косвенно содержимое регистра связи или счетчика.
Целочисленные команды
· Арифметические.
· Сравнения. Выполняют сравнение rA с операндом UIMM, SIMM или регистром rB. Ре-зультат помещается в поле регистра CR, по умолчанию в CR0.
· Логические. Выполняют побитовые логические операции.
· Сдвига и циклического сдвига.
Команды обработки чисел с ПТ.
· Арифметические. При этом операнды с одинарной точностью преобразовываются в опе-ранды с двойной точностью.
· Сложения с суммированием.
· Округления и преобразования 64-битных чисел с ПТ двойной точности в 32-битные оди-нарной точности.
· Сравнения. Сравнение содержимого двух регистров FPR.
· Команды работы с регистром FPSCR.
· Копирования. Выполняют копирование данных из одного регистра FPR в другой.
Команды сохранения/загрузки.
Доступы к памяти в PowerPC делятся на выровненные и невыровненные. Адрес операнда считается не выровненным, если он не кратен его длине. Например, операнд длиной 12 байт выровнен по слову если его адрес кратен 4. Некоторые команды требуют выравнивания опе-рандов в памяти. Вообще, наилучшая производительность достигается, когда операнды в памяти выровнены.
· Целочисленной загрузки/сохранения. Сохранение/загрузка регистра rS/rD как байта, по-луслова, слова или двойного слова по эффективному адресу.
· Целочисленной загрузки/сохранения с реверсом байтов
· Множественной целочисленной загрузки/сохранения. Используются для пересылки блоков данных в и из регистров общего назначения, данные могут быть выровнены (множественная загрузка) или нет (загрузка строк, выполняется гораздо дольше).
· Загрузки/сохранения чисел с ПТ. Эффективный адрес генерируется используя косвенно регистр с индексной константой. Прямое сохранение в память не поддерживается. При загрузке числа одинарной точности преобразуются к двойной при загрузке в регистры FPR. При сохранении наоборот.
· Синхронизации памяти
Команды перехода и контроля потока команд
Некоторые команды перехода выполняются условно исходя из значения битов регистра CR. Если ни одна выполняемая в данный момент команда не влияет на CR, то переход решается немедленно.
· Относительный переход
· Условный переход на относительный адрес
· Переход по абсолютному адресу
· Условный переход на абсолютный адрес
· Переход по регистру связи
· Переход по регистру-счетчику
Другие команды
· Команды системных вызовов
· Команды контроля процессора. Чтение и запись CR, MSR и SPR.
· Команды синхронизации завершения операций с памятью с асинхронными событиями.
· Команды контроля памяти. Управления кэшем (пользователь и супервизор), управления сегментными регистрами (супервизор) и TLB (супервизор)
