
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Объединение последовательностей объектов распознавания
,
Аннотация
В статье рассматриваются вопросы, возникающие в проблеме склеивания результатов распознавания частей страницы при вводе в компьютер с помощью ручного сканера. Приводятся специальные алгоритмы объединения текстовых объектов, позволяющие разрешать как специфические проблемы ручного сканирования, так и общие задачи слияния объектов различной природы.
1. Введение
При оптическом распознавании текста (OCR) в том случае, когда изображение вводится с помощью ручного сканера, возникает ряд проблем. Узость сканера не позволяет отсканировать страницу полностью. Поэтому приходится сканировать сначала верхнюю, а потом нижнюю половинку страницы с последующим их поворотом на 90o и соединением (см. рис. 1). При этом пересекающиеся части половинок, как правило, не совпадают. Например, некоторые строки могут отсутствовать в одной из них или могут быть по-разному распознаны в результате ошибок программы распознавания, искажений сканера или неаккуратного сканирования. Верхняя и нижняя половинки страницы часто сканируются с разной скоростью, рывками, с разным наклоном. Наконец, короткие строки на краях страницы могут быть захвачены сканером только на одной из половинок. В настоящей работе предлагается способ конкатенации частей страницы после их раздельного распознавания на основе методов объединения последовательностей текстовых объектов, то есть отождествлением строк верхней и нижней половинок страницы с учётом структуры текста и информации OCR.
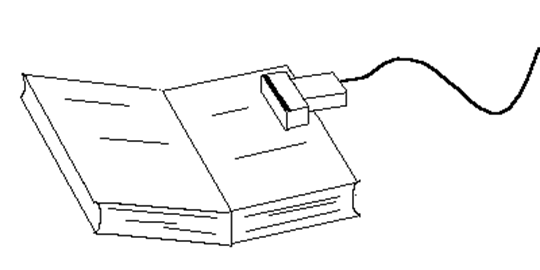
Рис.1 Сканирование книги ручным сканером
Рассматривается случай, когда объектами являются символы, строки символов или наборы строк (фрагменты), полученные при распознавании текста. OCR снабжает каждый символ оценкой Cr, означающей, насколько хорошо он был распознан. Оценка Cr определяется из результатов применения естественных (например, метод наложения) и экспертных (метод штрафов) методов [1]. Например, буква "И" на рис. 2 может распознаваться как И или сходный с ней символ Н, но система распознавания учитывает наклон черты у И и уменьшает Cr у Н. В этом примере Cr для И равно 200 из 254 (буква "И" не идеальна), а для Н - 80.
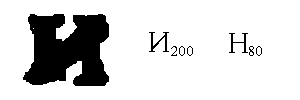
Рис. 2. Оценки распознавания
Распознанные строки символов разбиты на слова, что позволяет использовать алгоритмы сопоставления слов, повышать надежность отождествления длинных строк и снижать время работы этих алгоритмов.
После распознавания файл представляет собой набор фрагментов (рис. 3). В связи с тем, что в результате сканирования страница делится на две, некоторые фрагменты исходного текста также распадаются. Поэтому из верхней и нижней половинок нужно выбрать пары фрагментов для объединения, после чего производить сопоставление строк в пределах каждой пары фрагментов.
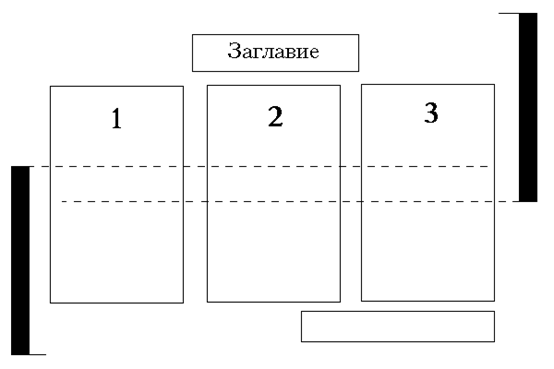
Рис. 3. Разбиение фрагментированной страницы на верхнюю и нижнюю части
Поставленные задачи отличаются от хорошо известной в литературе постановки "Approximate pattern matching". Описанные в литературе методы обычно применяются для отыскания подстроки символов в строке [2-4]. Хотя их можно применить и в двумерном случае, обычно специфично двумерные методы показывают лучшие результаты [5]. В нашем случае можно использовать геометрические привязки.
При постановке задачи "Approximate pattern mathing" мера отличия двух последовательностей символов - количество операций вставления, удаления и замены символа, необходимых для достижения точного совпадения. В методах, рассматриваемых в данной статье и учитывающих ошибки распознавания, при определении меры соответствия двух последовательностей используются дополнительные данные, такие, как оценки Cr. Это позволяет значительно повысить достоверность результатов [6].
2. Общее описание методов.
Для объединения последовательностей текстовых объектов необходимо знание функции сравнения CMP этих объектов. Функция сравнения характеризует, насколько сравниваемые объекты соответствуют друг другу. Для того, чтобы объединить две последовательности объектов, необходимо найти область пересечения последовательностей и сопоставить неидентичные области, то есть наложить искаженные при распознавании объекты с учётом возможности исчезновения объектов.
Описываемые методы делятся на 2 группы : IMAGE и ТЕКСТ.
IMAGE. Каждый объект может иметь свои координаты (координаты прямоугольника, который он занимает) в исходном изображении. Сравнение объектов производитcя с помощью их координат и текстового представления.
ТЕКСТ. Редуцированный вариант IMAGE. В этой группе методов игнорируются координаты объектов. Методы дает удовлетворительные результаты при сравнении строк символов и могут использоваться в отличие от группы IMAGE для сопоставления объектов, не обладающих геометрическими привязками. Являются менее трудоёмким, поэтому разумно применять методы группы ТЕКСТ на этапах предварительного принятия решения о сопоставлении объектов, однако после выработки гипотез могут потребоваться более точные методы IMAGE.
2.1. Сопоставление последовательностей
Сопоставление последовательностей осуществляется посредством наложения нескольких (в идеальном случае всех) объектов одной последовательности на объекты другой, для чего используется один из следующих методов из группы ТЕКСТ :
Метод простого сравнения - отыскивается первый попавшийся объект, соответствующий данному, согласно функции сравнения с некоторым наперед заданным порогом. Метод простого сравнения применяется при поиске пропавших строк.
Использование статистики - решение, совпадает ли отыскиваемый объект с одним из элементов последовательности, принимается по результам сравнения объекта со всеми элементами последовательности. Этот метод гораздо медленнее, чем метод простого сравнения, но его результаты более достоверны.
2.2. Поиск исчезнувших объектов
После нахождения пересечения при объединении последовательностей необходимо учитывать, что некоторые объекты могут содержаться в одной из последовательностей, но быть пропущены в другой, что объясняется в рамках рассматриваемой проблемы ошибками комбинаторных алгоритмов разрезания и склеивания (см. [1]). В случае незначительных искажений объектов (слов) пропуск букв обнаруживается анализом частей слова, а в более сложных ситуациях, когда слова различаются более чем на одну группу букв, требуется организация перебора методами динамического программирования. В рамках данной работы они не будут описаны из-за того обстоятельства, что современные системы оптического распознавания символов обеспечивают достаточное количество качественно распознанных слов для объединения половинок страницы, состоящих из наборов строк.
2.3. Объединение фрагментов текста
Половинки страницы, которые нужно объединить, могут представлять собой совокупности фрагментов. Описанными способами можно отыскать и объединить соответствующие фрагменты. В методах группы IMAGE можно сузить множество кандидатов на объединение, отбирая фрагменты по размерам и расположению относительно границ страницы.
3. Сопоставление без геометрических привязок
Будем считать, что функция сравнения символов CMP выдает 0, если символы не равны и минимальную из их оценок Cr, если равны. При рассмотрении последовательностей символов можно задать функцию сравнения последовательностей S1 и S2 как ![]() , где L - “длина пересечения” , равная наименьшей из длин S1 и S2, а через Sj[i] обозначен i-й объект последовательности. В этом случае для
, где L - “длина пересечения” , равная наименьшей из длин S1 и S2, а через Sj[i] обозначен i-й объект последовательности. В этом случае для ![]() мы получаем число от 0 (нет ни одной совпадающей пары символов) до L*Cr (последовательности совпадают и хорошо распознаны). Эта функция является базовой, из-за несовершенств распознавания она требует уточняющих эвристик, примером которых является штраф за различие длин последовательностей. С помощью определённой таким образом функции сравнения ниже будут построены алгоритмы объединения различных последовательностей, в том числе и для последовательностей с различной длиной.
мы получаем число от 0 (нет ни одной совпадающей пары символов) до L*Cr (последовательности совпадают и хорошо распознаны). Эта функция является базовой, из-за несовершенств распознавания она требует уточняющих эвристик, примером которых является штраф за различие длин последовательностей. С помощью определённой таким образом функции сравнения ниже будут построены алгоритмы объединения различных последовательностей, в том числе и для последовательностей с различной длиной.
3.1. Метод простого сравнения
Поиск идентичных последовательностей прекращается в том случае, когда функция сравнения выдает число, большее некоторой наперед заданной константы С. Она вычисляется из свойств функции сравнения следующим образом : пусть WL - наибольший результат, возвращаемый функцией сравнения объектов, которые на самом деле не равны, а WH - наименьший результат, возвращаемый функцией сравнения объектов, которые равны. Очевидно, что если WL больше WH, то лучше этот метод не использовать т. к. С должна лежать в диапазоне от WL до WH. Оценивание WH и WL следует из анализа вероятностей появления объектов на некотором представительном объёме распознанных объектов и функции их сравнения.
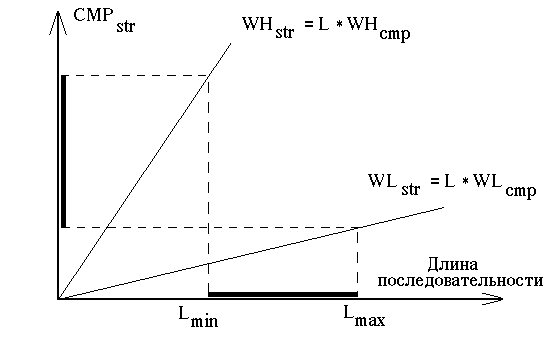
Рис. 4. Зависимости функций сравнения от длины последовательности
Если максимальная длина последовательности Lmax, минимальная длина последовательности Lmin, то для функции сравнения последовательностей WH=Lmin*WHcmp, WL=Lmax*WLcmp, где WHcmp, WLcmp - соответственно WH и WL для функции сравнения отдельных символов. Обозначим вероятность появления символа ch из алфавита A в тексте P(ch), а через Pr(ch) и Cr(ch) - вероятность правильного распознавания и среднюю оценку символа ch. Они определяются характером распознанного текста. Для функций сравнения мы получаем :
![]() (вероятность случайного совпадения);
(вероятность случайного совпадения);
![]() .
.
При вычислении WH считаем, что оба символа должны правильно распознаться.
В общем случае рассмотрим матрицу B, компоненты которой bi, j являются вероятностями перехода буквы i в j при распознавании. Тогда ![]() ,
, 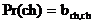 ,
, 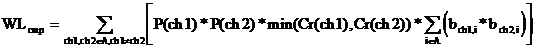 +
+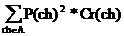 ,
,
![]() .
.
После нахождения WHcmp, WLcmp для определения диапазона возможных значений C, воспользуемся линейной зависимостью ![]() от длины строк L : WH = L * WHcmp, WL = L * WLcmp (см. рис. 4). Чтобы получить достоверные результаты при длине строк L, изменяющейся от Lmin до Lmax, C должна находиться в пределах от Lmax * WLcmp до Lmin * WHcmp.
от длины строк L : WH = L * WHcmp, WL = L * WLcmp (см. рис. 4). Чтобы получить достоверные результаты при длине строк L, изменяющейся от Lmin до Lmax, C должна находиться в пределах от Lmax * WLcmp до Lmin * WHcmp.
Для книжных страниц и деловых документов экспериментально получаем Lmin=5, Lmax=100, WH=150, WL=70, откуда C=700.
3.2. Метод использования статистики
При использовании этого метода вывод делается на основе результатов сравнения отыскиваемого объекта со всеми объектами последовательности на основе максимального max1 и второго по величине max2 значений, и использования порога доверия C. На рис. 5 показан пример возможного результата сравнения, i - номер объекта, с которым сравнивается отыскиваемый.
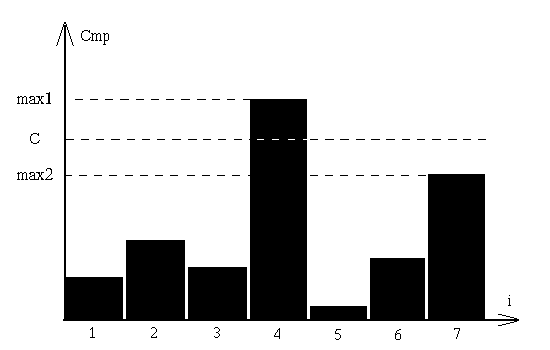
Рис. 5. Пример отыскания объекта по статистическим характеристикам
Решение принимается исходя из того, намного ли превышает максимальное значение второе по величине, то есть выполняется ли условие
![]()
Если оно не выполняется, то объект, соответствующий отыскиваемому, считается ненайденным.
Так как для получения достоверного результата должны выполняться условия ![]() то при выборе C должно выполняться
то при выборе C должно выполняться ![]() . Из вышеприведенных результатов
. Из вышеприведенных результатов ![]() .
.
Для расматриваемых классов текстов со значениями Lmin=5, Lmax=100, WH=150, WL=70 получаем значение C=2.
3.3. Поиск исчезнувших объектов
Предположим, что пересечение STR1 и STR2 было обнаружено, начиная с позиции I в STR1. Для отыскания исчезнувших объектов можно производить попарные сравнения STR1[ I + j] с STR2[j] для j от 0 до наименьшей из длин строк. Если найдется такое j, что STR1[ I + j ] и STR2[j] не равны, то нужно найти такое k > j : STR1[ I + j ] == STR2[k] или STR1[ I + k ] == STR2[j]. Если такое k найдено, то будем считать, что объекты STR2[j]... STR2[k] или STR1[I + j] ... STR1[I + k] исчезли соответственно из STR1 и STR2. Здесь равенство объектов может определяться методами простого сравнения (функция сравнения выдает число, большее наперед заданной константы) или использования статистики (при сравнении объекта S1 из STR1 с S2 из STR2 считаем их равными, если методом использования статистики поиск S2 в STR1 дает S1 и поиск S1 в STR2 - S2).
4. Сопоставление с использование координат объектов
4.1. Объединение последовательностей объектов
Представим пересечение последовательностей в виде групп объектов
GR[1,0] ... GR[1,N],
GR[2,0] ... GR[2,N]
(первый номер - номер последовательности), обладающих следующими свойствами:
1) ![]() (может быть пустым)
(может быть пустым) ![]() ,где k=1,2.
,где k=1,2.
2) Обозначим Interval(![]() ) =
) =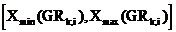 , где
, где 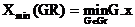 ,
, 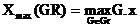 . Здесь G. x - абсцисса объекта G в последовательности.
. Здесь G. x - абсцисса объекта G в последовательности.
Interval(![]() ) пересекается с Interval(
) пересекается с Interval(![]() ) тогда и только тогда, когда i равняется j, l равняется k или одно из них пусто.
) тогда и только тогда, когда i равняется j, l равняется k или одно из них пусто.
Выбирая из каждой GR1,k GR2,k наилучший и объединяя их по всем k, получаем результирующую последовательность.
При распознавании строк текста возможны ситуации “слипания” и “разваливания” букв (когда две буквы распознаются как одна или буква распознается как две). Вследствие этого букве из одной строки может соответствовать две (или более) буквы из другой (см. рис. 6). Возможно также соответствие типа группа букв - группа букв. Этот метод может использоваться для объединения результатов распознавания строки текста двумя способами (двумя различными методами или даже двумя разными системами распознавания) за счёт выбора наиболее хорошо распознанных частей из каждой строки.
Gr1,0 Gr1,1
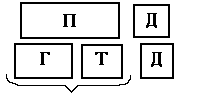
Gr2,0 Gr2,1
Рис. 6. Пример сопоставления строк
4.2. Отыскание пропавших строк текста
Имеется в виду поиск возможной пропажи при распознавании строки в одной из половинок отсканированного текста и его замена на строку-аналог из другой половины страницы.
Этот метод основан на том, что геометрическое расстояние между соседними строками текста на изображении примерно одинаково. Поэтому, вычислив расстояния между данными соседними строками и сравнив его со средним расстоянием, можно получить оценку, сколько строк могло исчезнуть между ними.
Далее эту оценку необходимо проверить методом ТЕКСТ на небольшом множестве строк - кандидатов.
4.3. Объединение фрагментов текста
Если известно расположение фрагментов в исходных изображениях, то можно по координатам выделить те пары, которые наиболее вероятно требуют объединения по близости расположения (см. рис. 7) :
|X1-X2| < dx и |width1-width2| < dx для объединения фрагментов по вертикали, где X1,X2, width1,width2 - абсциссы и ширины фрагментов,
или |Y1-Y2| < dy и |height1-height2| < dy - для объединения фрагментов по горизонтали, где Y1,Y2,height1,height2 - ординаты и высоты фрагментов, а dx и dy - допустимые отклонения координат и размеров.

Рис.7. Примеры взаиморасположения фрагментов
Перебираем все возможные или полученные алгоритмом 4.3. пары фрагментов, отыскиваем их пересечение методом ТЕКСТ и объединяем с использованием высоты и расстояния между строками.
5. Заключение
Все поставленные задачи (поиск пересечения строк и групп строк, поиск исчезнувших строк и символов, объединение фрагментов и групп фрагментов) имеют решения в одной из групп. При этом лучшие результаты получаются при использовании методов IMAGE. Возможно эти методы могут также найти применение при объединении изменений, вносимых в один и тот же файл программы разными людьми.
Правильность этих методов была проверена при многолетнем использовании основанной на них программы, находящейся в составе OCR Cuneiform [1].
Литература
1. , Славин распознавания и технологии ввода текстов в ЭВМ.
Информационные технологии и вычислительные системы 1996, No 1, стр. 48-53
2. R. Cole, R.Hariharan. Tighter Bounds on The Exact Complexity of String Matching. Proceedings
33rd Annual Symposium on Foundations of Computer Science (Cat. No 92/CH3188-0),
Pittsburgh, PA, USA, 24-27 Oct 1992 (Los Alamitos, CA, USA : IEEE Comput. Soc. Press
1992),p.600-609.
3. U. Manber, S.Wu. Approximate pattern te 1992, Vol.17,No 12,p 281-292.
4. L. Colussi. Correctness and Effieciency of Pattern Matching Algorithms. Information and
Computation, 95, 225-
5. Z. Galil, K. Park. Truely alphabet-independent two-dimensional pattern matching. Proceedings 33rd Annual Symposium on Foundations of Computer Science (Cat. No 92/CH3188-0), Pittsburgh, PA, USA, 24-27 Oct 1992 (Los Alamitos, CA, USA : IEEE Comput. Soc. Press 1992),p.247-56.
6. . Объединение строк, состоящих из текстовых объектов. // Семинар проекта
"Диалог". Тез. докл. - Казань, 1995 - стр.54-56
