
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Словари (хэш-таблицы).
Часто бывают нужны динамические множества, поддерживающие только словарные операции. В множестве достаточно хранить “текущие” объекты
с периодической вставкой или удалением некоторых из них. Время от времени также возникает необходимость узнать, присутствует ли конкретный элемент в данном массиве. Для такого множества достаточно выполнения трех операций – вставки, удаления и поиска. Множество с таким набором операций называется словарем. Стоимость операций оценивается О(n) или О(h).
1. Для представления словарей можно использовать упорядоченные или неупорядоченные списки и деревья.
2. Если элементами множества являются целые числа 1,…,N или элементы множества можно сопоставить с таким множеством целых чисел, то словарь можно представить в виде двоичного дерева. Такое представление возможно, если множество не велико и стоимость операций – 0(1).
3. Третья возможность представления использует массив фиксированной длины – хэш-таблицу. Этот массив иногда называют таблицей расстановки. В худшем случае поиск в хэш-таблице может занимать столько же времени, сколько и в списке (0(n)), но на практике хеширование гораздо более эффективно и имеет стоимость 0(1).
Хэш-таблицу можно рассматривать как обобщение обычного массива. Если множество не велико, то для каждого возможного ключа можно отвести отдельную ячейку в массиве. В этом случае значение ключа отображается в соответствующий индекс массива и получает прямой доступ к элементу множества через этот индекс. Время доступа к любому элементу множества равно 0(1).
Таблица c прямой адресацией.
Такой вид хеширования применяется, когда количество возможных ключей невелико.
Пусть возможными ключами являются числа из множества U={1, 2, …, m}, где m – не очень велико. Предположим, что ключи всех элементов различны. Для хранения множества используется массив T[1..m], называемый таблицей с прямой адресацией. Каждая позиция или ячейка соответствует определенному ключу из множества U.
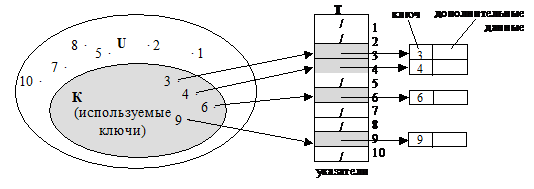 |
T[k] – место, предназначенное для записи указателя на элемент с ключом k. Если элемента с ключом k в таблице нет, то T[k]=NIL.
Реализация словарных операций тривиальна:
Direct_Address_Search (T, k)
1 return T[k]
Direct_Address_Insert (T, x)
1 T[Key[x]] ← x
Direct_Address_Delete (T, x)
1 T[Key[x]] ← NIL
Каждая из операций требует 0(1) времени.
Хеш-таблицы.
Прямая адресация обладает очевидным недостатком. Если множество U возможных ключей велико, то хранить в памяти массив Т размером │U│непрактично, а то и невозможно. Кроме того, если число реально присутствующих в таблице записей мало по сравнению с │U│, то много памяти тратится зря. Если количество записей в таблице существенно меньше, чем количество возможных ключей, то используется хеш-таблица. Хеш-таблица требует памяти О(│m│), где m – множество записей. Время поиска в хеш-таблице по-прежнему О(1).
В хеш-таблице элементу отводится номер h(k), где k – ключ элемента h(k) – хеш-функция. Число h(k) называют хеш-значением ключа k.
h: U→{1, 2, …m}.
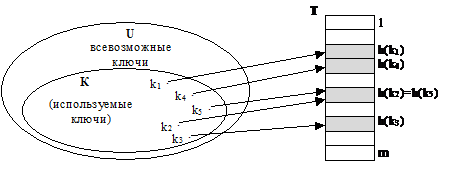 |
Для хеш-таблицы требуется массив длины m, а не │U│.
Проблема заключается в том, что хеш-значения двух разных ключей могут совпадать. Такой случай называется коллизией или столкновением. Эта ситуация неизбежна, поскольку │U│> m и неизбежна, потому что существуют разные ключи, имеющие одно и то же значение h(k). При выборе хеш-функции заранее неизвестно, какие именно ключи будут храниться в хеш-таблице. На всякий случай хеш-функцию разумно сделать “случайной” в некотором смысле, хорошо перемешивающей ключи по ячейкам массива (to hash - мелко порубить, помешивая). Но случайная функция должна быть детерминированной в том смысле, что при повторных вызовах с одним и тем же аргументом она должна возвращать одно и то же хеш-значение.
Разрешение коллизий с помощью цепочек.
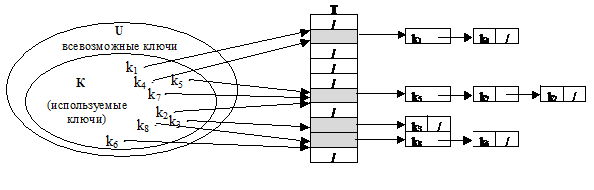 |
Технология сцепления элементов состоит в том, что элементы множества с одним и тем же хеш-значением связываются в цепочку-список. В позиции j хранится указатель на голову списка тех элементов, у которых хеш-значение ключа равно j. Если таких элементов в таблице нет, то позиция j содержит NIL. Такой способ разрешения коллизий позволяет хранить множества с потенциально бесконечным пространством ключей, снимая ограничения на размер множества. Поэтому этот способ организации хеш-таблицы называется открытым или внешним хешированием.
Каждый элемент хранит указатель на голову списка или NIL.
Основная идея при открытом хешировании заключается в том, что потенциальное множество разбивается на конечное число подмножеств. Для m подмножеств, пронумерованных от 0 до m-1 строится хеш-функция h такая, что для любого элемента из исходного множества h(k) принимает целочисленное значение на интервале [0…m]. Значение хеш-функции определяет индекс в массиве указателей Т.
Если подмножества примерно одинаковы, то в этом случае списки всех подмножеств должны быть наиболее короткими и средняя длина сегментов будет │U│/m = α.
Операции добавления, поиска и удаления реализуются легко :
Chained_Hash_Insert (T, x)
добавить x в голову списка T[h(Key[x])] (0(1))
Chained_Hash_Search (T, k)
найти элемент всписке T[h(k)] (0(α))
Chained_Hash_Delete (T, x)
Удалить х из списка T[h(Key[x])] (0(1)).
Операция добавления работает в худшем случае за время О(1). Максимальное время поиска пропорционально длине списка. Удаление элемента можно выполнить за О(1), при условии, что используются двусвязные списки.
При анализе хеширования с цепочками учитывается фактор заполнения таблицы Т. Коэффициентом заполнения таблицы называется число α = n/m, где n – число занесенных в таблицу элементов, m – число элементов массива Т. α может быть и меньше и больше единицы.
В худшем случае, когда хеш-значения всех ключей совпали, таблица сводится к одному списку длины n, и на поиск элемента будет тратиться время О(n), как в списке, плюс ещё время на вычисление хеш-функции.
Средняя стоимость поиска зависит от того, насколько равномерно хеш-функция распределяет хеш-значения ключей по позициям таблицы.
Если сделать предположение о равномерном хешировании, когда каждый элемент может попасть в любую позицию таблицы с равной вероятностью, то путем несложных доказательств можно сделать вывод, что время поиска элемента оценивается величиной 0(1+ α).
Если количество позиций в хеш-таблице m пропорционально числу n, т. е. n = 0(m), то α = n/m = 0(1) и 0(1+ α) = 0(1).
Поскольку стоимость добавления и удаления в хеш-таблицу также равно О(1), то при оптимистических предположениях о распределении вероятностей стоимость любой словарной операции равна 0(1).
Хеш-функции.
Итак, хорошая хеш-функция должна обеспечивать равномерное хеширование, т. е. для любого ключа все m хеш-значений должны быть равновероятны.
Пусть на множестве U зафиксировано распределение вероятностей Р. Предполагается, что ключи выбираются из U не зависимо друг от друга, и каждый ключ распределен в соответствии с Р.
Тогда равномерное хеширование означает, что ∑ P(k) = 1/m для j=0, 1, …, m-1.
k: h(k)=j
Как правило, распределение Р неизвестно, да и выбор ключей из U также редко некоррелирован. Если все таки Р известно, например ключи – случайные действительные числа, равномерно распределенные на промежутке [0…1], то можно использовать хеш-функцию h(k) = ëkmû, которая удовлетворяет условию равномерного хеширования.
На практике при выборе хеш-функций пользуются различными эвристиками, основанными на специфике задачи. Например, компилятор языка программирования хранит таблицу символов, в которой ключами являются идентификаторы программы. Часто в программе встречаются похожие идентификаторы (например, pt и pts). Хорошая хеш-функция будет стараться, чтобы хеш-значения у таких похожих идентификаторов были различны. Хеш-функцию стараются подобрать так, чтобы её поведение не коррелировало с различными закономерностями в хешируемых данных.
Представление ключей для хеширования.
Обычно предполагают, что область определения хеш-функции – множество целых неотрицательных чисел. Если по своей природе ключи не являются натуральными числами, то их можно преобразовать к такому виду. Например, последовательности символов можно интерпретировать как числа, записанные в системе счисления с подходящим основанием: pt – пара цифр 112, 116 в системе счисления с основанием 256, т. е. значение ключа равно 112*256+116=28788.
Далее будем считать, что ключи – натуральные числа.
Деление с остатком.
Построение хеш-функции методом деления с остатком состоит в том, что ключу k ставится в соответствие остаток от деления k на m, где m – число возможных хеш-значений.
h(k) = k mod m.
Например, если m=13, k=100, то h(k)=9.
При этом некоторых значений m стоить избегать. Например, если m=2P, то h(k) – просто р младших разрядов числа k. Если нет уверенности, что все комбинации р младших битов ключей равновероятны, то степень двойки в качестве m не выбирается.
Не рекомендуется также m=10P, если ключи – десятичные числа. Тогда уже часть младших цифр полностью определяет хеш-значение.
Если m=10P, то h(k) – младшие цифры числа. Плохо, если m – кратно 2, в этом случае h(k) четных k – четные, а нечетных k – нечетные. Плохо, если m кратно 3 для символьных и десятичных ключей, т. к. 10P/3 = 4P/3 =1, а 4P – основание символьных ключей.
Хорошие результаты получаются, если в качестве m выбирать простые числа, далеко отстоящие от степени двойки. Пусть, например, в хеш-таблицу нужно поместить примерно 2000 записей, причем перебор трех записей в цепочке при поиске допустимо. Тогда в качестве m можно взять, например 701. Число m простое и n/m=2000/701»3. Тогда хеш-функция h(k) = k mod 701.
Можно поэкспериментировать с реальными данными для исследования того, насколько равномерно будут распределены их хеш-значения.
Пример: плохого М и хорошего М:
М1=100 h1(k)=k mod 100
М2=101 h2(k)=k mod 101
K | 99 | 199 | 1099 | 4399 | 303 | 707 | 100 | 200 | |
h1 | 99 | 99 | 99 | 99 | 99 | 3 | 7 | 0 | 0 |
h2 | 99 | 98 | 89 | 56 | 8 | 0 | 0 | 100 | 99 |
Значения, дающие коллизии при любом М – числа, кратные М, М + 1, …, М + m-1.
Умножение.
Пусть количество хеш-значений равно m. Зафиксируем константу А на интервале 0<A<1 и положим
h(k) = ëm(k A mod1)û, где k A mod1 – дробная часть kA.
Достоинство метода умножения заключается в том, что качество хеш-функции мало зависит от выбора m. Обычно в качестве m – выбирают степень двойки, т. к. в большинстве компьютеров умножение на m реализуется как сдвиг слова. Пусть, например, длина слова в компьютере равна w битам и ключ k помещается в одно слово. Тогда, если m=2P, то вычисление хеш-функции можно провести так: умножим k на w - битовое целое число A*2w; получится 2w - битовое число. Пусть r0 – число, образованное младшими w битами, старшие p битов в r0 образуют хеш-значение.
 |
Метод умножения работает при любом выборе константы А, но некоторые значения А могут быть лучше других. Оптимальный выбор А зависит от того, какого рода данные хешируются.
Кнут после исследований заключает, что А » (√5 - 1)/2 = 0, является довольно удачным.
(√5 - 1)/2 = 0, – золотое сечение.
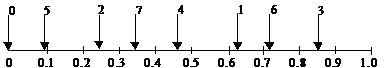 |
Если рассмотреть интервал [0…1], на котором лежат значения k A mod 1 (дробная часть k A), то можно заметить, как ведут себя последовательные значения k (+ 0)A mod 1, k (+ 1)A mod 1, k (+ 2)A mod 1 и т. д.
{0 A} = 0
{1 A} = 0.62
{2 A} = 0.24
{3 A} = 0.085
{4 A} = 0.47
{5 A} = 0.09
{6 A} = 0.71
{7 A} = 0.33
Каждая новая точка делит наибольший из интервалов золотым сечением (длина отрезка = сумме двух составляющих отрезков). Соответственно ведет себя и хеш-функция: h(k) = ëm(k A mod1)û на интервале ключей [0…m-1].
Проиллюстрируем метод на конкретном примере:
Пусть k = m = 10000 и A задается указанной формулой.
h(k) = ë10000 * (123456 * 0,61803…mod1)û =
= ë10000 * (76300,0041151…mod1)û =
= ë10000 * 0,0041151… û = ë41,151…û = 41.
Открытая адресация (закрытое хеширование).
При открытой адресации никаких списков нет, и все записи хранятся в самой хеш-таблице: каждая ячейка таблицы содержит либо элемент динамического множества, либо NIL. Поиск заключается в том, что определенным образом просматриваются элементы таблицы, пока не находится нужный элемент или не устанавливается факт, что элемента в таблице нет. При открытой адресации указатели не используются : последовательность просматриваемых ячеек вычисляется. За счет экономии памяти на указателях можно увеличить количество позиций в таблице, что уменьшает число коллизий и сокращает поиск. Чтобы добавить новый элемент, просматриваются ячейки 1…m таблицы, чтобы найти свободное место. Если просматривать все ячейки от 1 до m, то потребуется 0(n) времени. Но при открытой адресации порядок просмотра зависит от ключа. К хеш-функции добавляется второй аргумент - номер попытки (нумерация начинается с 0).
Хеш-функция имеет вид:
h: U * {0, 1, …, m-1}→{0, 1, …, m-1}.
Последовательность проб для данного ключа k имеет вид:
<h (k, 0), h (k, 1), …, h (k, m-1)>.
Функция h должна быть такой, чтобы каждое из чисел 0, …, m-1 встречалось ровно один раз.
Рассмотрим алгоритмы вставки и поиска в таблице с открытой адресацией. Предполагается для простоты, что запись не содержит дополнительной информации кроме ключа. Если ячейка пуста, то она содержит значение NIL, отличное от всех ключей.
Hash_Insert (T, k)
1. i← 0
2. repeat j← h(k, i) + 1
3. if T[j] = NIL
4. then T[j] ← k
5. return j
6. else i← i+1
7. until i = m
8. error “переполнение хеш-таблицы”
При поиске элемента с ключом k в таблице ячейки просматриваются в том же порядке, что и при вставке элемента с ключом k. Если встречается ячейка, в которой записан NIL, то это значит, что искомого элемента в таблице нет.
Внимание: предполагается, что элементы из таблицы не удаляются.
Hash_Search (T, k)
1. i← 0
2. repeat j← h(k, i) + 1
3. if T[j] = k
4. then return j
5. i← i + 1
6. until T[j] = NIL или i=m
7. return NIL
Удаление элемента из таблицы с открытой адресацией не так просто. Если записать на его место NIL, то в дальнейшем нельзя будет найти те элементы, в момент добавления которых это место вошло в число проб и было занято, и из-за этого была выбрана более удаленная позиция. Возможное решение – записывать на место удаленного элемента не NIL, а специальное значение DELETED (“удален”), и при добавлении рассматривать ячейку со значением DELETED, как свободную. При поиске эту ячейку нужно рассматривать, как занятую. Недостаток этого подхода в том, что время поиска может оказаться большим даже при низком коэффициенте заполнения.
Поэтому, если требуется удалять записи из хеш-таблицы, то предпочтение отдается хешированию с цепочками.
На практике используются обычно три способа вычисления последовательности проб: линейный, квадратичный и двойное хеширование. В каждом из этих способов последовательность < h (k, 0), h (k, 1), …, h (k, m-1) > будет перестановкой множества {0, 1, …, m-1} при любом значении ключа k. Ни один из этих способов не является равномерным по той причине, что они дают не более m2 перестановок из m! возможных. Больше всего перестановок получается при двойном хешировании.
Линейная последовательность проб.
Пусть h`: U→{0, 1,…, m-1} обычная хеш-функция. Функция, дающая линейную последовательность проб, задается формулой:
h (k, i) = (h`(k) + i) mod m.
При работе с ключом k первой выбирается ячейка T[h`(k)], а затем перебираются ячейки таблицы подряд: T[h`(k)+1], T[h`(k)+2], …. После T[m] следует ячейка T[1]. Поскольку последовательность проб полностью определяется первой ячейкой, реально используется всего m различных последовательностей.
У метода очевидный недостаток: он может привести к образованию кластеров – длинных последовательностей занятых ячеек, идущих подряд. Это удлиняет поиск. В самом деле, если в таблице из m ячеек все ячейки с четными номерами заняты, а ячейки с нечетными номерами – свободны, то среднее число проб при поиске элемента, отсутствующего в таблице есть 1.5. Если же m/2 занятых ячеек идут подряд, то среднее число проб равно m/8=n/4 (n – число занятых мест в таблице).
Квадратичная последовательность проб.
Хеш-функция, дающая квадратичную последовательность проб, задается формулой:
h (k, i) = (h` (k) + c1i + c2i2) mod m,
где h`(k) – обычная хеш-функция; c1 и c2 ≠ 0 – некоторые константы. Пробы начинаются с ячейки T[h`(k)], но дальше ячейки просматриваются не подряд: номер пробуемой ячейки квадратично зависит от номера попытки. Для того, чтобы использовались все ячейки таблицы, c1 и c2 выбираются не случайно.
Например, квадратичную последовательность проб дает следующий алгоритм:
Hash_Insert (T, k)
1. j← h`(k) + 1
2. i← 0
3. while i ≠ m
4. dv if T[j] = NIL
5. then T[j] = k
6. return j
7. j← (i + 1) mod m
8. j← (j + i) mod m
9. error “Переполнение хеш-функции”
Как и при линейном методе, вся последовательность проб определяется ключом, т. е. h`(k), поэтому получается m различных перестановок. Однако тенденция к образованию кластеров частично устраняется. Хотя и остается эффект кластеризации в более мягкой форме – образование вторичных кластеров.
Двойное хеширование.
Двойное хеширование – один из лучших методов открытой адресации. Перестановки индексов, возникающие при двойном хешировании, близки к равномерному хешированию.
При двойном хешировании функция h имеет вид:
h (k, i) = (h1(k) + i h2(k)) mod m, где
h1 и h1 – обычные хеш-функции. Т. е. последовательность проб при работе с ключом k является арифметической прогрессией (по модулю m) с первым членом h1(k) и шагом h2(k).
Пример:

m = 13
h1(k) = k mod 13
h2(k) = 1 + (k mod 11)
При k = 14 последовательность проб: 1 5 9
Чтобы последовательность пробных мест покрывала всю таблицу, значение h2(k) должно быть взаимно простым с m.
(Целые числа a и b взаимно просты, если HOD (a, b) = 1).
Если наибольший общий делитель h2(k) и m есть α, то арифметическая прогрессия по модулю m с шагом h2(k) займет долю 1/d в таблице.
1. Простой способ добиться этого условия – выбрать в качестве m степень двойки, а функцию h2 взять такую, чтобы она принимала только нечетные значения.
2. Другой вариант: m – простое число, значение h2 - целые положительные числа, меньшие m.
Например, для простого m можно положить:
h1(k) = k mod m
h2(k) = 1 + (k mod m`), где
m` чуть меньше, чем m. Например, m`= m-1 или m-2.
Если, например, m=701, m`= 700, k=123456 , то h1(k)=80 и h2(k)=257. Последовательность проб начнется с позиции 80 и далее идет с шагом 257, пока вся таблица не будет просмотрена.
В отличие от линейного и квадратичного методов при двойном хешировании можно получить при правильном выборе h1 и h2 не m, а 0(m2) различных перестановок, поскольку каждой паре (h1 и h2) соответствует своя последовательность проб. Благодаря этому производительность двойного хеширования близка к той, что получилась бы при равномерном хешировании.
Анализ хеширования с открытой адресацией.
Так же как при анализе хеширования с цепочками стоимость операций с открытой адресацией оценивается в терминах коэффициента заполнения α=n/m. Для открытой адресации α ≤ 1.
Если предположить идеальный случай, что хеширование равномерно, ключи выбираются случайным образом и все m! последовательностей проб равновероятны, то математическое ожидание проб при поиске в таблице с открытой адресацией отсутствующего элемента будет 1(1- α).
Если α отделен от 1, то поиск отсутствующего элемента будет занимать время О(1). Например, при α = 0.5, среднее число проб будет не больше 1/(= 2. Если α = 0.9, то среднее число проб не больше 1/(1 – 0.9) = 10.
Точно такую же оценку имеет и математическое ожидание стоимости операции добавления в таблицу. Математическое ожидание(МО) успешного поиска равно
1/α ln (1/1-α).
Если таблица заполнена наполовину (α=0.5), то среднее число проб для успешного поиска не превосходит 1.387, а если на 90% - то 2.559.
МО успешного поиска получается усреднением общего числа проб при добавлении каждого элемента. МО общего числа проб равно сумме МО для каждого шага. При добавлении (i+1)-го элемента α = i/m и МО i + 1 = 1/1- αi = 1/(1-i/m) = m/m-i.
Таким образом, общее МО = m/m + m/m-1 + …+ m/m-n+1 = m
= m(1/m + 1/m-1 +…+ 1/m-n+1 = m∫(1/t)dt = m ln(m/m-n)
m-n
Общее МО усредняем, т. е. делим на n:
m/n ln(m/m-n) = 1/α ln(1/1-α).
