


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Название Аналитический обзор
название Аналитический обзор...
1. Обзор методов и средств организации и управления качеством туннелируемых виртуальных сетей в образовательной индустрии.
1.1 Виртуальные туннелируемые библиотеки в едином образовательном пространстве высшей школы (индустрии образования) – единая инф. среда, единое инф. пространство, фамилии Медведева и Путина, Тихонова, Иванников… Портальное строительство Тихонова… Период расцвета внутри вузов, в частности – мирэа (ссылка на доклад Сигова). Виртуализация сетей с целью персонализации информационного обслуживание с исп. мультиагентности и мультимедиа.
1.2. Анализ контента. способ рамещения и отыскания – в образовании. требования к сетям: доступно массово недорого, пжц, липаев, сертификация, качество (Мордвинов НИИ ВО).
1.3. Какие есть виртуальные сети, прогноз на завтра. какие задачи надо решать.
1.4. Обзор и выбор методов. Материалы проведенного в 1.1-1.4 обзора выполнены –география, глубина (…Таким образом по результатам аналитического обзора формулируются цели и задачи исследования)
постановка задач исследования
2. Разработка метода моделирования туннелируемых виртуальных сетей
2.1. Разработка обобщенной модели на основе ограничения числа туннелей
2.2. Частная интерпретация модели туннелируемой виртуальной сети с учетом ограничения числа туннелей
2.3. Видоизменение модели в условиях комплексирования потоков в туннеле
3. Управление трафиком в виртуальной сети на основе изучения взаимного искажения данных
3.1 Разработка метрик для оценки уровня взаимного искажения данных
3.2 Уточняющие коэффициенты модели на основе представления метрик
3.3 Линеаризация целевой функции управления трафиком в условиях динамической маршрутизации
3.4 Алгоритмизация решения целевой функции управления трафиком
4. Менеджмент и практическая реализация массового мультисервисного мультиагентного обслуживания пользователей в индустрии образования
4.1 Апробация, экспериментальные замеры и внедрение в систему высшей школы методов и средств моделирования туннелируемых виртуальных сетей
4.2 Менеджмент моделирования, проектирования и сопровождения виртуальных библиотек на основе виртуализации сетей в системе непрерывного образования ВШ РФ (на примере практики МИРЭА)
4.3. Руководящие технические материалы …
1. актуализация задач
разнообразие изъянов — пересечение — реберные точки
глубина, география — в каждом параграфе
обзор — дотошный: диссертации (докт, канд), статьи, монографии, ртм, стандарты, отчеты...
методы, средства регулирование
оценка маршрутизаторами искажения
обзор энтропийного регулирования
обзор приемов алгоритмизации
2. как решать вопросы?
3 мат описания на выходе в одном общем методе -
признаки, свойства, функции, состояния
1. моделирование передачи потоковых данных в многопоточном однотуннельном режиме — показать, что не решена — выбор метода (обзор методов)
«исследователи занимались не достаточно, наиболее близкой можно считать, а в настоящей диссертации найдено целесообразным идти по... что является целесообразным потому что...»
2. метрики: есть аналоги для других задач [], приминительно к решаемой можно основываться на...
единый метод
3. корреляционная энтропия (семантико-энтропийное регулирование) — корреляционный анализ в энтропийной форме
4. алгоритмизация
1. Виртуальные сети
Интернет является сетью виртуальных сетей. Современные сети Интернет объединяют в единое целое многие десятки (а может быть уже и сотни) тысяч локальных сетей по всему миру, построенных на базе самых разных физических и логических протоколов (ethernet, Token Ring, ISDN, X.25, Frame Relay, Arcnet и т. д.). Эти сети объединяются друг с другом с помощью последовательных каналов (протоколы SLIP, PPP), сетей типа FDDI (часто используется и в локальных сетях), ATM, SDH(Sonet) и многих других. В самих сетях используются протоколы TCP/IP (Интернет), IPX/SPX (Novell), Appletalk, Decnet, Netbios и бесконечное множество других, признанных международными, являющихся фирменными и т. д. Картина будет неполной, если не отметить многообразие сетевых программных продуктов. На следующем уровне представлены разнообразные внутренние (RIP, IGRP, OSPF) и внешние (BGP и т. д.) протоколы маршрутизации и маршрутной политики, конфигурация сети и задание огромного числа параметров, проблемы диагностики и сетевой безопасности. Немалую трудность может вызвать и выбор прикладных программных средств (Netscape, MS Internet Explorer и пр.). В последнее время сети внедряются в управление (CAN), сферу развлечений, торговлю, происходит соединение сетей Интернет и кабельного телевидения.
Каждая из сетей, составляющих Интернет, может быть реализована на разных принципах, это может быть Ethernet (наиболее популярное оборудование), Token Ring (вторая по популярности сеть), ISDN, X.25, FDDI или Arcnet. Все внешние связи локальной сети осуществляются через порты-маршрутизаторы (R). Если в локальной сети использованы сети с разными протоколами на физическом уровне, они объединяются через специальные шлюзы (например, Ethernet-Fast Ethernet, Ethernet-Arcnet, Ethernet-FDDI и т. д.). Выбор топологии связей определяется многими факторами, не последнюю роль играет надежность. Использование современных динамических внешних протоколов маршрутизации, например BGP-4, позволяет автоматически переключаться на один из альтернативных маршрутов, если основной внешний канал отказал.
Широкому распространению Интернет способствует возможность интегрировать самые разные сети, при построении которых использованы разные аппаратные и программные принципы. Достигается это за счет того, что для подключения к Интернет не требуется какого-либо специального оборудования (маршрутизаторы не в счет, ведь это ЭВМ, где программа маршрутизации реализована аппаратно). Некоторые протоколы из набора TCP/IP (ARP, SNMP) стали универсальными и используются в сетях, построенных по совершенно иным принципам.
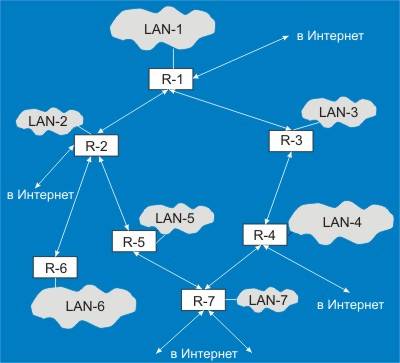
Рис. 1. Схема построения сети Интернет
Широкое внедрение ИНТРАНЕТ, где группы разбросанных по сети пользователей локальных сетей объединяются друг с другом с помощью виртуальных каналов VLAN (Virtual Local Area Network; http:///nsc/200374.html), потребовало разработки новых протоколов. Архитектура VLAN позволяет эффективно разделять трафик, лучше использовать полосу канала, гарантировать успешную совместную работу сетевого оборудования различных производителей и обеспечить высокую степень безопасности. При этом пакеты следуют между портами в пределах локальной сети. В последнее время для задач построения VLAN разработан стандартный протокол IEEE 802ий сетевой уровень). Этот протокол предполагает, что пакеты VLAN имеют свои идентификаторы, которые и используются для их переключения. Протокол может поддерживать работу 500 пользователей и более. Полное название стандарта - IEEE 802.10 Interoperable LAN/MAN Security (MAN - Metropolitan Area Network - региональная или муниципальная сеть). Стандарт принят в конце 1992 года. Количество VLAN в пределах одной сети практически не ограничено. Протокол позволяет шифровать часть заголовка и информационное поле пакетов.
Стандарт ieee 802.10 определяет один протокольный блок данных (PDU), который носит название SDE (Secure Data Exchange) PDU. Заголовок пакета ieee 802.10 имеет внутреннюю и внешнюю секции и показан на рис. 2.
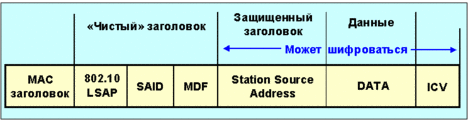
Рис. 2. Формат пакета IEEE 802.10
Поле чистый заголовок включает в себя три субполя. MDF (Management Defined Field) является опционным и содержит информацию о способе обработки PDU. Четырехбайтовое субполе said (Security Association Identifier) - идентификатор сетевого объекта (VLAN ID). Субполе 802.10 LSAP (Link Service Access Point) представляет собой код, указывающий принадлежность пакета к протоколу vlan. Предусматривается режим, когда используется только этот заголовок.
Защищенный заголовок копирует себе адрес отправителя из mac-заголовка (MAC - Media Access Control), что повышает надежность.
Поле ICV (Integrity Check Value) - служит для защиты пакета от несанкционированной модификации. Для управления VLAN используется защищенная управляющая база данных SMIB(security management information base).
Наличие VLAN ID (said) в пакете выделяет его из общего потока и переправляет на опорную магистраль, через которую и осуществляется доставка конечному адресату. Размер поля data определяется физической сетевой средой. Благодаря наличию mac-заголовка VLAN-пакеты обрабатываются как обычные сетевые кадры. По этой причине VLAN может работать в сетях TCP/IP (Appletalk или Decnet менее удобны). В среде типа Netbios работа практически невозможна. Сети ATM прозрачны для VLAN. Протокол VLAN поддерживается корпорацией cisco, 3com и др. Хотя VLAN ориентирован на локальные сети, он может работать и в WAN, но заметно менее эффективно.
Созданная для целей безопасности эта техника оказалась полезной для структуризации локальных сетей, приводящей к улучшению их рабочих характеристик. В настоящее время доступны переключатели, маршрутизаторы и даже концентраторы, поддерживающие виртуальные сети.
Виртуальные сети просто необходимы, когда локальная сеть в пределах одного здания совместно используется несколькими фирмами, а несанкционированный доступ к информации желательно ограничить.
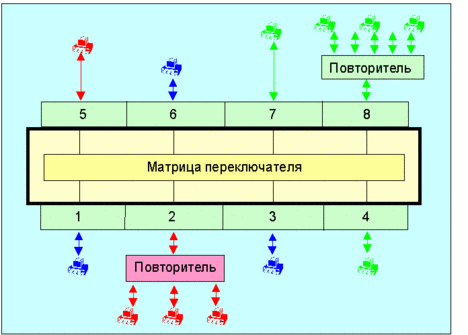
Рис. 3. Схема переключателя (или концентратора) с поддержкой VLAN.
Для формирования VLAN необходимо устройство, где возможно осуществлять управление тем, какие порты могут соединяться. Например, пусть запрограммирована возможность пересылки пакетов между портами 1, 3 и 6, 2 и 5, а также между портами 4, 7 и 8. Тогда пакет из порта 1 никогда не попадет в порт 2, а из порта 8 в порт 6 и т. д. Таким образом, переключатель как бы разделяется на три независимых переключателя, принадлежащих различным виртуальным сетям. Управление матрицей переключения возможно через подключаемый из вне терминал или удаленным образом с использованием протокола SNMP. Если система переключателей, концентраторов (и возможно маршрутизаторов) запрограммирована корректно, возникнет три независимые виртуальные сети.
Данная технология может быть реализована не только в рамках локальной сети. Возможно выделение виртуальной сети в масштабах Интернет. В сущности, идея создания корпоративных сетей в Интернет (ИНТРАНЕТ) является обобщением идей виртуальных сетей на региональные сети.
2. Маршрутизация в VLAN
Период экстенсивного развития сети Интернет завершился несколько лет тому назад даже в РФ. Сейчас многие сервис-провайдеры пытаются привлечь клиентов дополнительными информационными услугами: IP-телефония, интерактивные игры, доступ к разнообразным базам данных и депозитариям, электронным магазинам, видеоконференциям, видеотелефонии, различным разновидностям цифрового телевидения и т. д. Клиенты же ищут не просто любого доступа в Интернет, а интересуются полосой пропускания, безопасностью, стабильностью связи. Именно с этим сопряжен бум разработок основополагающих документов (RFC) в последние 5 лет. По этой причине многие компании, в первую очередь производящие сетевое оборудование, уделяют повышенное внимание средствам управления трафиком (ТЕ) и QoS.
Около 10 лет назад началась разработка первого протокола RSVP (RFC-2205). В нем осуществляется резервирование полосы пропускания (интегральный сервис) вдоль виртуального пути. Запрос резервирования посылает получатель трафика, а исполнителями запроса являются маршрутизаторы, обслуживающие виртуальный путь этого трафика.
Современные задачи требуют более тонкой настройки качества обслуживания (QoS). Важными параметрами, характеризующими QoS, являются: задержка доставки (RTT), дисперсия времени доставки пакета, вероятность его потери, например, из-за переполнения буферов в транзитных сетевых устройствах. Все эти характеристики зависят от организации очередей в сетевых устройствах. С точки же зрения пользователя важно получить гарантию того, что все характеристики QoS окажутся в пределах допусков непосредственно на его рабочем месте. Машина же пользователя чаще всего подключена к переключателю уровня L2, который может не поддерживать ни один из протоколов, гарантирующих QoS.
Если рассмотреть ситуацию на канальном уровне (L2), здесь имеется сильная зависимость от физического уровня (L1). В сетях с маркерным доступом (Token Ring или FDDI, см. book. *****) существуют механизмы управления приоритетом и способы контроля доступа, гарантирующие определенное значение задержек сетевого отклика. В сетях ISDN и в особенности в ATM предусмотрен целый арсенал средств управления, работающих на фазе установления виртуального канала (процедура SETUP). Для Ethernet до последнего времени ситуация была много хуже. Здесь только некоторые переключатели поддерживают VLAN. Технология виртуальных сетей L2 позволяет сформировать в локальной сети соединение точка-точка. В таком соединении можно гарантировать пропускную способность на уровне 10/100Мбит/c. К сожалению VLAN L2 создаются и модифицируются, как правило администратором, но можно эту проблему перепоручить сценарию, например, на PERL, работающему с демоном SNMP сетевого прибора. В такой сети можно также гарантировать низкий уровень разброса времени реакции сети. Если сформировать VLAN с числом узлов (N) больше двух, можно гарантировать полосу лишь не ниже (10/100)/N. Для произвольной сети Ethernet никаких гарантий на уровне L2 предоставить нельзя. Здесь можно рассчитывать только на вышележащие уровни (IP/TCP/UDP).
Принципы организации приоритетного трафика на уровне L2 рассмотрены в стандарте 802.1р. Стандарт 802.1р является частью стандарта 802.1D (мостовые соединения). В протоколе 802.1Q определена 4-байта метки (рис.4). Поле EtherType=TPID (Tagged Protocol Identifier) содержит код 0x8100. Это поле соотвествует полю тип протокола стандартного поля кадра Ethernet и указывает на необходимость обработки кадра согласно требованиям IEEE 802.1Q (grouper. ieee. org/groups/802/1/pages/802.1v. html).
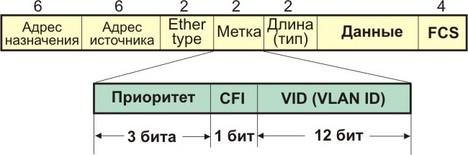
Рис. 4. Формат меток VLAN на уровне L2 (стандарт 802.1р).
Поле приоритета пользователя - 3 бита, 1-битовое поле CFI (Canonical Format Identifier) и 12-битовое поле VID (идентификатор виртуальной сети) называются TCI (Tagged Control Information). 3-битовое поле IP-приоритета размещается здесь без проблем. После введения метки в кадр нужно пересчитать контрольную сумму FCS. Канальный уровень в этом случае должен поддерживать множественные очереди. Добавление метки может привести к превышению предельно допустимой длины кадра (1518 байт). В этой связи IEEE разрабатывает спецификацию 802.3ас, где максимальная длина кадра равна 1522 октета. Группа IETF, разрабатывающая систему обеспечения требуемого уровня услуг на специфических нижних уровнях ISSLL (Integrated Services over Specific Lower Layers), предлагает способы отображения запросов протокола резервирования уровня L3 (RSVP) на 802.1р с помощью системы управления полосой пропускания субсети SBM (Subnet Bandwidth Manager). Протокол SBM предполагает, что одна из станций в субсети выполняет функцию DSBM (Designated SBM), и осуществляет управление доступом для всех запросов на резервирование ресурсов, посылаемых DSBM-клиентами. При работе протокола SBM используются мультикатсинг-адреса 224.0.0.17 (все станции прослушивают этот адрес), а DSBM-кандидаты прослушивают - 224.0.0.16. Данная технология может использоваться, например, в IP-телефонии (TDMoIP - Time Division Multiplexing over IP)). В этом случае UDP-порт порт получателя = 2142.
Топология связей в локальной сети на уровне L3 определяется протоколами маршрутизации (статическими или динамическими - RIP, OSPF, IGRP). В последнее время поставщики сетевого оборудования стали предлагать устройства уровня L2, способные осуществлять отбор пакетов на уровне L3 и даже L4 (TCP/UDP). В принципе ничто не мешает создать сетевые переключатели уровня L2, способные гарантировать пропускную способность, минимизировать вероятность потери пакета и т. д.
Любые способы управления трафиком на уровне L3 для сетей, работающих в рамках стека протоколов TCP/IP, в настоящее время базируются на возможностях этих транспортных протоколов (IP, UDP, TCP).
Протокол предусматривает задание значение ToS, определяемое соответствующим полем заголовка. Одно-октетное поле тип сервиса (TOS - Type Of характеризует то, как должна обрабатываться дейтограмма.
Субполе приоритет предоставляет возможность присвоить код приоритета каждой дейтограмме. Значения приоритетов приведены в таблице (в настоящее время это поле не используется).
0 Обычный уровень
1 Приоритетный
2 Немедленный
3 Срочный
4 Экстренный
5 CEITIC/ECP
6 Межсетевое управление
7 Сетевое управление
В новейших разработках (RFC-2474, Definition of the Differentiated Services Field (DS Field) in the IPv4 and IPv6 Headers) поле TOS заменено на поле DSCP (Differentiated Services Code Point), где младшие 6 бит выделены для кода DS (Differentiated Services), а старшие два бита пока не определены и их следует обнулять.
До середины 90-х годов поле TOS в большинстве реализаций игнорировалось. Но после начала разработок средств обеспечения качества обслуживания (QoS) внимание к этому возрасло. Появилось предложение замены поля TOS на поле DSCP (Differenciated Services Code Point), которое также имеет 8 бит (см. RFC-2474). См. рис. 5. Биты CU пока не определены.
Протокол TCP имеет в заголовке 6-битовое поле флаги (значения представлены в таблице 1). Значения битов флаги предоставляет дополнительные возможности управления.
Таблица 1. Значения бит поля флаги
Обозначение битов (слева на право) поля флаги | Значение бита, если он равен 1 |
URG | Флаг важной информации, поле Указатель важной информации имеет смысл, если URG=1. |
ACK | Номер октета, который должен был прийти следующим, правилен. |
PSH | Этот сегмент требует выполнения операции push. Получатель должен передать эти данные прикладной программе как можно быстрее. |
RST | Прерывание связи. |
SYN | Флаг для синхронизации номеров сегментов, используется при установлении связи. |
FIN | Отправитель закончил посылку байтов. |
Указанные выше поля заголовков представляют собой основу существующих методов управления трафиком. Конечно, можно использовать и поля данных, но для этого нужно, чтобы это стало международным стандартом.
Существенную проблему составляет необходимость идентифицировать пакеты, принадлежащие определенному процессу. Эта задача легко решается только в рамках протокола IPv6. Там в заголовке предусмотрено поле метка потока. Некоторые возможности предоставляет также протокол MPLS.
3. Управление трафиком (Traffic engeniering)
Управление трафиком (TE) связано с оптимизацией рабочих характеристик сетей. Вообще, ТЕ включает в себя технологию и научные принципы измерения, моделирования, описание, управление трафиком Интернет и приложение таких знаний и техники для получения определенных рабочих характеристик.
Главной целью управления трафиком в Интернет является достижение эффективной и надежной работы сети. Управление трафиком стало непременной функцией многих автономных систем, из-за высокой стоимости услуг Интернет.
3.1. Объективные характеристики управления трафиком
Ключевые характеристики, сопряженные с управлением трафиком, могут относиться к следующим категориям:
1. ориентированные на трафик или
2. ориентированные на ресурсы.
Задачи, ориентированные на управление трафиком, включают в себя аспекты улучшения QoS информационных потоков. В модели “оптимальных усилий” для Интернет-сервиса ключевая задача управления трафиком включает в себя: минимизацию потерь пакетов и задержек, оптимизацию пропускной способности и согласование наилучшего уровня услуг. В данной модели минимизация вероятности потери пакетов является наиболее важным аспектом. Статистически заданные характеристики трафика (такие как разброс времени доставки пакетов, вероятность потери и максимальное время доставки) становятся важными в грядущих дифференцированных услугах Интернет. Одним из подходов решения таких проблем является оптимизация использования всех имеющихся ресурсов сети. В частности, желательно гарантировать, чтобы субнаборы сетевых ресурсов не были перегружены, в то время как аналогичные ресурсы на альтернативных маршрутах недогружены. Полоса пропускания является критическим ресурсом современных сетей. Следовательно, центральной функцией управления трафиком является эффективное управление пропускной способностью.
Минимизация перегрузок является первичной задачей. Здесь речь идет не о кратковременных перегрузках, а о долгосрочных, влияющих на поведение сети в целом. Перегрузка обычно проявляется двояко:
1. Когда сетевых ресурсов недостаточно или они не соответствуют существующей загрузке.
2. Когда потоки трафика неэффективно распределены по имеющимся ресурсам.
Первый тип проблем перегрузки может быть решен путем:
(1) расширения ресурса, или
(2) применением классических средств управления перегрузкой, или
(3) сочетанием этих подходов. Классическое управление перегрузкой пытается регулировать уровень потребности, снижая его до имеющегося в распоряжении уровня ресурсов. Классическое управление перегрузкой включает в себя: ограничение потока, управление шириной окна для потока, управление очередями в маршрутизаторе, диспетчеризацию и т. д.
Второй тип проблем перегрузки, связанный с неэффективным размещением ресурсов, может быть решен посредством управления трафиком.
Вообще, перегрузка, связанная с неэффективным размещением ресурсов, может быть уменьшена с помощью политики балансировки нагрузки в различных фрагментах сети. Задачей таких стратегий является минимизация максимальной перегрузки или напротив минимизация максимума использования ресурса. Когда перегрузка минимизирована путем оптимального размещения ресурсов, потери пакетов и задержка доставки падают, а совокупная пропускная способность возрастает. Таким образом, восприятие конечным пользователем качества сетевого обслуживания становится лучше.
Понятно, что балансировка определяет политику оптимизации рабочих характеристик сети. Не смотря ни на что, возможности, предоставляемые управлением трафиком, должны быть достаточно гибкими, чтобы сетевые администраторы могли реализовать другие политики, которые принимают во внимание господствующую структуру цен или даже модель получения доходов.
3.2. Управление трафиком и ресурсами
Оптимизация рабочих характеристик сетей является фундаментальной проблемой управления. В модели процесса управления трафиком, инженер трафика, или подходящая система автоматизации, действует как контроллер в системе с адаптивной обратной связью. Эта система включает набор взаимосвязанных сетевых элементов, систему мониторирования состояния сети, и набор средств управления конфигурацией. Инженер трафика формулирует политику управления, отслеживает состояние сети посредством системы мониторинга, характеристики трафика, и предпринимает управляющие действия, чтобы перевести сеть в требуемое состояние, в соответствии с политикой управления. Это может быть осуществлено с помощью действий, предпринимаемых как отклик на текущее состояние сети, или превентивно, используя прогнозирование состояния и тенденции и предпринимая действия, предотвращающие нежелательные будущие состояния.
В идеале управляющие действия должны включать:
1. Модификацию параметров управления трафиком,
2. Модификацию параметров, связанных с маршрутизацией,
3. Модификацию атрибутов и констант, связанных с ресурсами.
Уровень человеческого вмешательства в процесс управления трафиком, когда это возможно, должен быть минимизирован. Это может быть реализовано путем автоматизации операций, описанных выше. Операции эти могут быть распределенными и масштабируемыми.
В настоящее время используется несколько методов управления трафиком:
1. Динамическая маршрутизация (RIP, OSPF, IGRP, BGP) и т. д.). Здесь нет средства резервирования полосы, но имеется механизм изменения маршрута при изменении значений метрики или из-за выхода из строя узла или обрыва канала. Некоторые из таких протоколов (OSPF, IGRP) могут строить отдельные таблицы маршрутизации для каждого уровня TOS/QOS [1], но метрики для каждого уровня задаются сетевым администратором. Здесь имеется возможность запараллеливания потоков с целью увеличения пропускной способности. Эти протоколы работают только в пределах одной автономной системы (AS). Протокол же BGP, используемый для прокладки путей между автономными системами не способен как-либо учитывать уровень TOS/QOS (использует алгоритм вектора расстояния, что связано с трудностью согласования значений метрик состояния канала администраторами разных AS). Новая версия многопротокольного расширения MP-BGP специально создана для совместной работы с MPLS при формировании виртуальных сетей, но и он безразличен к TOS/QOS.
2. Формирование виртуальных сетей на уровнях L2 и L3. Протоколы VLAN обеспечивают повышенный уровень безопасности, но не способны резервировать полосу. К этому типу относится и протокол MPLS.
3. Резервирование полосы в имеющемся виртуальном канале (протокол RSVP). RSVP может работать с протоколами IPv4 и IPv6. Протокол достаточно сложен для параметризации, по этой причине для решения этой задачи был разработан протокол COPS, который существенно облегчает параметризацию. Функция COPS сходна с задачей языка RPSL для маршрутизации.
4. Автоматическое резервирование полосы при формировании виртуального канала процедурой SETUP в сетях ATM, ISDN, DQDB, Frame Relay и т. д. Управления очередями осуществляется аппаратно, но базовые параметры могут задаваться программно. Программы управления трафиком MPLS позволяют расширить возможности L2 сетей ATM и Frame Relay.
5. Использование приоритетов в рамках протокола IPv6. Возможность присвоения потокам меток облегчает, например, разделение аудио - и видеоданных.
6. Управление перегрузкой (окно перегрузки в TCP, ICMP(4) для UDP-потоков (ICMP L2 и т. д.).
3.3. Мультипротокольная коммутация меток (протокол MPLS)
Основы протокола MPLS описаны в официальных документах RFC. Существуют публикации и на русском языке. Имеются три монографии, посвященных рассматриваемой проблематике.
Протокол MPLS хорошо приспособлен для формирования виртуальных сетей (VPN) повышенного быстродействия (метки коммутируются быстрее, чем маршрутизируются пакеты). Принципиальной основой MPLS являются IP-туннели. Для его работы нужна поддержка протокола маршрутизации MP-BGP. Протокол MPLS может работать практически для любого маршрутизируемого транспортного протокола (не только IP). После того как сеть сконфигурирована (для этого используются специальные, поставляемые производителем скрипты), сеть существует, даже если в данный момент через нее не осуществляется ни одна сессия. При появлении пакета в виртуальной сети ему присваивается метка, которая не позволяет ему покинуть пределы данной виртуальной сети. Никаких других ограничений протокол MPLS не накладывает. Протокол MPLS предоставляет возможность обеспечения значения QoS, гарантирующего более высокую безопасность. Не следует переоценивать уровня безопасности, гарантируемого MPLS, атаки типа “человек посередине” могут быть достаточно разрушительны. При этом для одного и того же набора узлов можно сформировать несколько разных виртуальных сетей (используя разные метки), например, для разных видов QoS. Но можно использовать возможности АТМ (процедура setup), если именно этот протокол применен в опорной сети (возможные перегрузки коммутаторов не в счет).
Для обеспечения структурирования потоков в пакете создается стек меток, каждая из которых имеет свою зону действия. Формат стека меток представлен на рис. 5 (смотри RFC-3032). В норме стек меток размещается между заголовками сетевого и канального уровней (соответственно L2 и L3). Каждая запись в стеке занимает 4 октета.
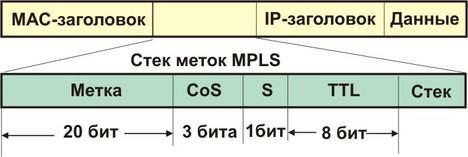
Рис. 5. Формат стека меток
![]()
Рис. 5а. Размещение меток в стеке
Место заголовка МАС может занимать заголовок РРР. В случае работы с сетями АТМ метка может занимать поля VPI и VCI. Смотри рис 6. Глубина стека в данном случае не может превышать 1.

Рис. 6. Формат меток в ячейках АТМ
На рисунке полю QoS соответствует субполю приоритет поля ToS. Поле CoS имеет три бита, что достаточно для поля приоритета IP-заголовка. 6-битовое поле кода дифференцированной услуги DSCP сюда записать нельзя. Можно попробовать разместить этот код в поле самой метки. S - флаг-указатель дна стека меток; TTL - время жизни пакета MPLS.
Существующие версии программного обеспечения Cisco IOS (например, Cisco IOS Release 12.0) содержат набор средств управления трафиком. В частности, имеется возможность формировать статические маршруты и управлять динамическими маршрутами путем манипулирования значениями метрики. Иногда этого вполне достаточно, но в большинстве случаев провайдер нуждается в более эффективных средствах.
Межрегиональные каналы являются одной из основных расходных статей провайдеров. Управление трафиком позволяет IP-провайдеру предложить оптимальный уровень услуг своим клиентам с точки зрения полосы и задержки. Одновременно эта технология снижает издержки обслуживания сети.
MPLS представляет собой интеграцию технологий уровней L2 и L3. Управление трафиком в MPLS реализуется путем предоставления традиционных средств уровня L2 уровню L3. Таким образом, можно предложить в односвязной сети то, что достижимо только путем наложения уровня L3 на уровень L2.
Управление коммутацией по меткам основывается на базе данных LIB (Label Information Base). Пограничный маршрутизатор MPLS LER (Label Edge Router) удаляет метки из пакетов, когда пакет покидает облако MPLS, у вводит их во входящие пакеты. Схема работы с помеченными и обычными IP-пакетами показана на рис. 7.
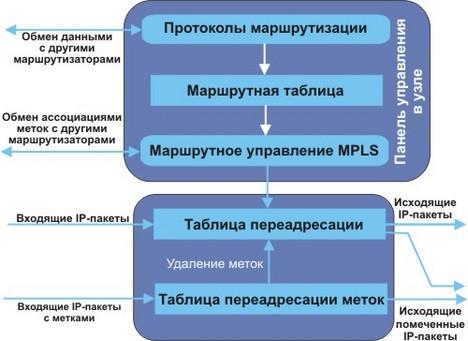
Рис. 7. Обработка помеченных и обычных IP-пакетов
Управление трафиком MPLS автоматически устанавливает и поддерживает туннель через опорную сеть, используя возможности RSVP. Путь, используемый данным туннелем в любой момент времени определяется на основе ресурсных требований и сетевых возможностей, таких как полоса пропускания. В самом ближайшем будущем MPLS сможет решать проблему обеспечения требуемого уровня QoS и самостоятельно.
Информация об имеющихся ресурсах доводится до сведения заинтересованных субъектов с помощью протокола IPG (Interior Protocol Gateway), алгоритм которого базируется на состоянии канала.
Путь туннеля вычисляется, основываясь на сформулированных требованиях и имеющихся ресурсах (constraint-based routing). IGP автоматически маршрутизирует трафик через эти туннели. Обычно, пакет, проходящий через опорную сеть MPLS движется по одному туннелю от его входной точки к выходной.
Управление трафиком MPLS основано на следующих механизмах IOS:
- Туннелях LSP (Label-switched path), которые формируются посредством RSVP, c расширениями системы управления трафиком. Туннели LSP представляют собой туннельные двунаправленные интерфейсы IOS c известным местом назначения. Протоколах маршрутизации IGP, базирующиеся на состоянии канала (такие как IS-IS) с расширениями для глобальной рассылки ресурсной информации, и расширениях для автоматической маршрутизации трафика по LSP туннелям. Модуле вычисления пути MPLS, который определяет пути для LSP туннелей. Модуле управления трафиком MPLS, который обеспечивает доступ к и запись ресурсной информации, подлежащей рассылке. Переадресации согласно меткам, которая предоставляет маршрутизаторам возможности, сходные с уровнем L2, перенаправлять трафик через большое число узлов согласно алгоритму маршрутизации отправителя.
Одним из подходов управления опорной сетью является определение сети туннелей между всеми участниками обменов. Протокол IGP, работающий в начале туннеля, определяет то, какой трафик должен проходить через любой оконечный узел. Модули вычисление пути и управления MPLS определяют маршрут LSP туннеля. Для каждого туннеля подсчитывается число пропущенных пакетов и байт.
Иногда, поток настолько велик, что его нельзя пропустить через один канал (туннель). В этом случае может быть создано несколько туннелей между отправителем и получателем.
Для реализации MPLS управления трафиком сеть должна поддерживать следующие возможности Cisco IOS:
- Мультипротокольную переадресацию пакетов с использованием меток (MPLS) IP-переадресацию CEF (Cisco Express Forwarding) Протокол маршрутизации IS-IS (Intermediate System-to-Intermediate System; см. RFC-1142, -1195, -2763, -2966 и -2973)
Дополнительные данные о MPLS и управлении трафиком можно найти в документации Cisco (поддерживается в реализациях 7620, 7640, 7200, 7500 и 12000):
- Cisco IOS Release 12.0 Switching Services Configuration Guide, глава "Tag Switching" Cisco IOS Release 12.0 Switching Services Command Reference, глава "Tag Switching Commands". Cisco IOS Release 11.3 Switching Services Command Reference, Часть 1, глава "Configuring RSVP" Cisco IOS Release 11.3 Network Protocols Command Reference, Часть 1, глава "RSVP Commands". Cisco IOS Release 12.0 Switching Services Configuration Guide, глава "Tag Switching". Cisco IOS Release 12.0 Switching Services Command Reference, глава "Tag Switching Commands".
Протоколы состояния канала типа IS-IS для вычисления кратчайшего пути для всех узлов сети используют алгоритм Дикстры SPF. Маршрутные таблицы получаются на основе дерева кратчайших путей. Эти таблицы содержат упорядоченный набор адресов места назначения и информацию о ближайших соседей. Если маршрутизатор осуществляет прокладку путей на основе алгоритма шаг-за-шагом, первым шагом является физический интерфейс, соединенный с маршрутизатором.
Новые алгоритмы управления трафиком вычисляют пути до одного или более узлов в сети. Эти маршруты рассматриваются как логические интерфейсы исходного маршрутизатора. В данном контексте эти маршруты представляют собой LSP и рассматриваются как TE-туннели.
Эти TE-туннели являются реальными маршрутами, контролируемыми маршрутизаторами, которые размещены в начале этих туннелей. В отсутствии ошибок TE-туннели гарантируют отсутствие петель, но маршрутизаторы должны согласовать использование TE-туннелей. Иначе могут стать возможными зацикливания двух или более таких туннелей. Вероятность возникновения такой ситуации незначительна, так как трасса туннеля определяется отправителем.
Управление трафиком MPLS:
- Исключается необходимость ручной конфигурации сетевых устройств, чтобы задать определенные маршруты. Вместо этого, можно положиться на возможности управления трафиком, предоставляемые MPLS. Производится оценка полосы канала и значения трафика при прокладке маршрута через опорную сеть. Имеет механизмы динамической адаптации, которые позволяют сделать опорную сеть устойчивой к отказам даже в условиях, когда несколько путей были рассчитаны в режиме off-line. В случае отказа узлов производится коррекция топологии опорной сети.
3.4. Протокол резервирования ресурсов RSVP
Если сетевые условия позволяют, то, используя протокол RSVP (где QoS задается в спецификации потока (flowspec) - практически на сегодня это единственное реализуемое решение), можно попытаться зарезервировать для заданной виртуальной сети определенное значение полосы пропускания. Следует иметь в виду, что протокол RSVP приспособлен в основном для резервирования определенного значения полосы пропускания, а не произвольного QoS (спецификации QoS см. в RFC-2210, 2211 и 2212) для существующего виртуального соединения. Если виртуальное соединение разорвано, следом ликвидируются и все резервирования. Следует, разумеется, иметь в виду, что RSVP может работать как c TCP - так и c UDP-сессиями поверх IPv4 и IPv6. Сессия резервирования инициируется получателем данных. Резервирование может осуществляться как для уникаст, так и мультикаст-потоков. Протокол RSVP (L. Zhang, R. Braden, Ed., S. Berson, S. Herzog, S. Jamin «Resource ReSerVation Protocol», RFC-2205; смотри также RFC, -2490, , -2872, -2961, -2996, -3097, -3175, -3181, ) определяет режим резервирования (способ объединения нескольких заявок для одного и того же интерфейса: WF, FF, SE), формирования резервирования и его поддержания в условиях отсутствия поддержки данного протокола в одном или нескольких узлах виртуального пути, пересылки QoS-запросов другим маршрутизаторам и т. д., но решения принимаются маршрутизатором локально без знания условий в остальной части пути. По этой причине здесь не может идти речь о минимизации задержки, обеспечении надежности или безопасности, хотя в перспективе это может стать возможным.
Следует учитывать, что инициатором резервирования в RSVP всегда является клиент (именно он посылает первичные запросы). По этой причине могут возникнуть проблемы при попытке централизованного управления QoS посредством RSVP.
RSVP не имеет механизмов управления очередями в конкретных интерфейсах, а механизм резервирования полосы пропускания для одного из направлений обмена является зоной ответственности изготовителя маршрутизатора и не публикуется. Кроме того, при скоростях несколько сот Мбит/с часто обработка процедур буферизации перепоручается аппаратным средствам (например, в случае компании CISCO).
· RSVP выполняет резервирование для уникастных и мультикастных приложений, динамически адаптируясь к изменениям членства в группе вдоль маршрута.
· RSVP является симплексным протоколом, т. е., он выполняет резервирование для однонаправленного потока данных.
· RSVP ориентирован на получателя, т. е., получатель данных инициирует и поддерживает резервирование ресурсов для потока.
· RSVP поддерживает динамическое членство в группе и автоматически адаптируется к изменениям маршрутов.
· RSVP не является маршрутным протоколом, но зависит от существующих и будущих маршрутных протоколов.
· RSVP транспортирует и поддерживает параметры управления трафиком и политикой, которые остаются непрозрачными для RSVP.
· RSVP обеспечивает несколько моделей резервирования или стилей, для того чтобы удовлетворить требованиям различных приложений.
· RSVP обеспечивает прозрачность операций для маршрутизаторов, которые его не поддерживают.
· RSVP может работать с IPv4 и IPv6.
Подобно приложениям маршрутизации и протоколам управления, программы RSVP исполняется в фоновом режиме.
Спецификация flowspec в запросе резервирования включает в себя значение класса услуг и два набора параметров:
1. "Rspec", который определяет желательное значение QoS, и
2. "Tspec", который описывает информационный поток.
Форматы и содержимое Tspecs и Rspecs определяются общими моделями обслуживания [RFC 2210] и обычно недоступны для RSVP. Конкретный формат спецификации фильтра зависит от того, используется IPv4 или IPv6. Например, спецификация фильтра может использоваться для выделения некоторых составных частей информационного потока, осуществляя отбор с учетом полей пакетов прикладного уровня. В интересах упрощения в описываемом стандарте RSVP спецификация фильтра имеет довольно ограниченную форму: IP-адрес отправителя и, опционно, номер порта SrcPort (UDP/TCP).
Так как номера портов UDP/TCP используются для классификации пакетов, каждый маршрутизатор должен уметь анализировать эти поля. Это вызывает потенциально три проблемы.
1. Необходимо избегать IP-фрагментации потока данных, для которого желательно резервирование ресурсов. Документ [RFC 2210] специфицирует процедуру вычисления минимального MTU для приложений, использующих средства RSVP.
2. IPv6 вводит переменное число Internet заголовков переменной длины перед транспортным заголовком, увеличивая трудность и стоимость классификации пакетов. Эффективная классификация информационных пакетов IPv6 может быть достигнута путем использования поля метки потока заголовка IPv6.
3. IP-уровень безопасности как для IPv4, так и IPv6 может шифровать весь транспортный заголовок, скрывая номера портов промежуточных маршрутизаторов.
Сообщения RSVP, несущие запросы резервирования, исходят со стороны получателя и направляются отправителю информации.
Процесс RSVP проходит стадии проверки допуска и политики. Если какой-либо тест не прошел, резервирование отвергается и посылается сообщение об ошибке. Если все тесты прошли успешно, узел устанавливает классификатор пакетов, для того чтобы отбирать пакеты, указанные в спецификации фильтра. Далее устанавливается контакт с соответствующим канальным уровнем для получения желательного QoS, заданного в flowspec. Для простой выделенной линии, желаемый QoS будет получен с помощью диспетчера пакетов в драйвере канального уровня. Если технология канального уровня поддерживает свои средства управления QoS, тогда RSVP должен согласовать с канальным уровнем получение требуемого QoS.
Когда получатель данных отправляет запрос резервирования, он может запросить также присылку сообщения, подтверждающего резервирование. Процесс резервирования распространяется от получателей к отправителям, от узла к узлу. В каждом узле требования резервирования объединяются и сопоставляются с имеющимися возможностями. Это продолжается до тех пор, пока запрос не достигнет отправителя или пока не возникнет конфликт перегрузки. В результате получатель данных, направивший запрос резервирования, получит сообщение об успехе или ошибке.
Базовая модель резервирования RSVP является однопроходной: получатель посылает запрос резервирования вдоль мультикастинг-дерева отправителю данных и каждый узел по пути воспринимает или отвергает этот запрос. RSVP поддерживает улучшенную версию однопроходного варианта алгоритма, известного под названием OPWA (One Pass With Advertising) [OPWA95]. С помощью OPWA управляющие пакеты RSVP, посланные вдоль маршрута для сбора данных, которые могут быть использованы для предсказания значения QoS маршрута в целом. Результаты доставляются протоколом RSVP в ЭВМ получателя. Эти данные могут позднее служить для динамической адаптации соответствующих запросов резервирования.
Запрос резервирования включает в себя набор опций, которые в совокупности называются стилем. Одна опция резервирования определяет способ резервирования различными отправителями в пределах одной сессии.
Другая опция резервирования контролирует выбор отправителей. В одних случаях каждому отправителю ставится в соответствие определенная спецификация фильтра, в других - таких спецификаций не требуется вовсе. В настоящее время определены следующие стили:
· Стиль WF (Wildcard-Filter)
Стиль WF использует опции: "разделенного" резервирования и произвольного выбора отправителя ("wildcard"). Таким образом, резервация со стилем WF создает резервирование, которое делится между потоками всех отправителей. Это резервирование может рассматриваться как общая «труба", чей размер равен наибольшему из ресурсных запросов от получателей, и не зависит от числа отправителей. Стиль резервирования WF передается в направлении отправителей и автоматически распространяется на новых отправителей при их появлении.
· Стиль FF (Fixed-Filter)
Стиль FF использует опции: "четкое" (distinct) резервирование и "явный" (explicit) выбор отправителя. Таким образом, простой запрос со стилем FF создает точно заданное резервирование для информационных пакетов от определенного отправителя, без совместного использования ресурса с другими отправителями в пределах одной и той же сессии.
· Стиль SE (Shared Explicit)
Стиль SE использует опции: "разделенное" (shared) резервирование и "явный" explicit) выбор отправителя. Таким образом, стиль резервирования SE формирует одно резервирование, которое совместно используется несколькими отправителями. В отличие от стиля WF, SE позволяет получателю непосредственно специфицировать набор отправителей.
Для облегчения работы с RSVP разработан протокол COPS (Common Open Policy Service; RFC-2748, The COPS Protocol, D. Durham, Ed. Смотри также RFC-2749, -2940 и -3084).
Протокол COPS предназначен для обмена информации о политике между серверами политики (Policy Decision Point или PDP и их клиентами (Policy Enforcement Points или PEP). Примером клиента политики является RSVP-маршрутизатор, который должен реализовывать управление доступом, базирующееся на определенной политике. Предполагается, что существует, по крайней мере, один сервер, определяющий политику в каждом из доменов. Базовая модель взаимодействия между сервером политики и клиентом совместима с документом по управлению доступом.
В конфигурационном сценарии PEP выполнит запрос PDP для определенного интерфейса, модуля, или функциональности, которые могут быть специфицированы в информационном объекте именованного клиента. PDP пошлет потенциально несколько решений, содержащих именованные блоки конфигурационных данных PEP. Предполагается, что PEP инсталлирует и использует конфигурацию локально. Конкретная именованная конфигурация может быть актуализована путем отправки дополнительных сообщений-решений для данной конфигурации. Когда PDP более не хочет, чтобы PEP использовал часть конфигурационной информации, он пошлет сообщение-решение, специфицирующее именованную конфигурацию и объект флагов решения (decision flags) с командой удаления конфигурации. PEP должен удалить соответствующую конфигурацию и послать сообщение-отчет PDP, об этом удалении.
При работе с АТМ ситуация ненамного лучше, программное обеспечение АТМ-коммутаторов также обычно не доступно. Но имеется возможность работы RSVP поверх АТМ.
При наличии механизмов реализации других типов QoS (см., например, RFC-2430 и Rosen, Rekhter, Tappan, Farinacci, Fedorkow, Li, and Conta, "MPLS Label Stack Encoding", где предлагается ввести дополнительные биты в заголовок). В рамках одной автономной системы (AS), где используется внутренний протокол маршрутизации OSPF, можно обеспечить требуемый уровень QoS, но это будет делаться вручную, во всяком случае, на уровне задания значений метрики. Теоретически можно это сделать и автоматически, например, в случае применения версии протокола IGRP (внутренний протокол компании CISCO), поддерживающего автоматическую оценку значений метрики. К сожалению, компания CISCO отошла от первоначального плана и значения метрики там задается в настоящее время также администратором.
Реализация управления QoS предполагает организацию эффективной системы мониторинга базовых параметров, характеризующих требуемый уровень QoS. Для этого требуется контролировать уровень информационных потоков во всех фрагментах VPN, постоянно измерять значение RTT и его дисперсии, контролировать уровень вероятности потери пакетов во всех фрагментах виртуального пути. Желательно также отслеживать корреляции перечисленных параметров и локального значения загрузки. Схема мониторинга и управления QoS показана на рис. 8.
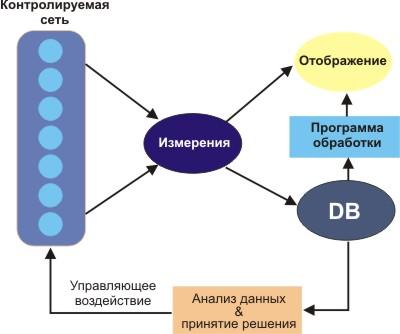
Рис. 8.
Управляющее воздействие может осуществляться с помощью скриптов или с привлечением механизмов политик. В любом случае нужно позаботиться об исключении влияния случайных флуктуаций результатов измерений.
3.5. Выводы
1. Для сетей TCP/IP основным инструментом управления QoS пока является протокол RSVP (это касается и MPLS).
2. Протокол MPLS является удобным средством формирования корпоративных сетей (VPN), которые позволяют поднять их безопасность.
3. Для обеспечения работы MPLS необходима поддержка протоколов IS-IS и MP-BGP всеми маршрутизаторами VPN.
4. Протокол MPLS предоставляет гибкие средства мониторинга трафика в пределах VPN.
5. Технология управления трафиком ТЕ предполагает совмещение возможностей протоколов уровней L2 и L3.
6. Протокольных средств управления очередями в Ethernet или в TCP/IP не существует. Такие средства имеются в ATM-коммутаторах, ограниченные возможности имеются в некоторых маршрутизаторах CISCO и в коммутаторах L2 (например, выбор между режимами store-and-forward и cutthrough и т. д.). В любом случае такие режимы конфигурируются администратором индивидуально для каждого сетевого устройства. Разумеется, что-то можно сделать с помощью протокола SNMP дистанционно.
7. Переход на IPv6 существенно расширяет возможности управления трафиком за счет использования меток потоков (пока не ясно насколько эта возможность поддерживается программно). Данное свойство особенно важно для передачи мультимедийных данных, например, программ цифрового телевидения. Последнее предполагает значительное расширение интегральной полосы каналов опорной сети (хотя бы до 155Мбит/c).
8. Все выше сказанное отражает ситуацию сегодняшнего дня, когда не стандартизовано дополнительных средств управления трафиком и QoS.
4. Сетевое моделирование
Ни один проект крупной сети со сложной топологией в настоящее время не обходится без исчерпывающего моделирования будущей сети. Программы, выполняющие эту задачу, достаточно сложны и дороги. Целью моделирования является определение оптимальной топологии, адекватный выбор сетевого оборудования, определение рабочих характеристик сети и возможных этапов будущего развития. Ведь сеть, слишком точно оптимизированная для решений задач текущего момента, может потребовать серьезных переделок в будущем. На модели можно опробовать влияние всплесков широковещательных запросов или реализовать режим коллапса (для Ethernet), что вряд ли кто-то может себе позволить в работающей сети. В процессе моделирования выясняются следующие параметры:
· Предельные пропускные способности различных фрагментов сети и зависимости потерь пакетов от загрузки отдельных станций и внешних каналов.
· Время отклика основных серверов в самых разных режимах, в том числе таких, которые в реальной сети крайне нежелательны.
· Влияние установки новых серверов на перераспределение информационных потоков (Proxy, Firewall и т. д.).
· Решение оптимизации топологии при возникновении узких мест в сети (размещение серверов, DNS, внешних шлюзов, организация опорных каналов и пр.).
· Выбор того или иного типа сетевого оборудования (например, 10BaseTX или 100BaseFX) или режима его работы (например, cut-through, store-and-forward для мостов и переключателей и т. д.).
· Выбор внутреннего протокола маршрутизации и его параметров (например, метрики).
· Определение предельно допустимого числа пользователей того или иного сервера.
· Оценка необходимой полосы пропускания внешнего канала для обеспечения требуемого уровня QOS.
· Оценка влияния мультимедийного трафика на работу локальной сети, например, при подготовке видеоконференций.
Перечисленные задачи предъявляют различные требования к программам. В одних случаях достаточно провести моделирование на физическом (MAC) уровне, в других нужен уже уровень транспортных протоколов (например, UDP и TCP), а для наиболее сложных задач нужно воспроизвести поведение прикладных программ. Все это должно учитываться при выборе или разработке моделирующей программы. Ведь нужно учесть, что ваша машина должна в той или иной мере воспроизвести действия всех машин в моделируемой сети. Таким образом, машина эта должна быть достаточно быстродействующей и, несмотря на это, моделирование одной секунды работы сети может занять при определенных условиях не один час.
Результаты моделирования должны иметь точность 10-20%, так как этого достаточно для большинства целей и не требует слишком много машинного времени. Следует иметь в виду, что для моделирования поведение реальной сети, надо знать все ее рабочие параметры: длины кабеля от концентратора до конкретной ЭВМ, задержки используемых кабелей, задержки концентраторов (этот параметр часто отсутствует в документации и его придется брать из документации на сетевой протокол, например из IEEE 802.3). Параметры могут быть определены и прямым измерением. Чем точнее вы воспроизводите поведение сети, тем больше машинного времени это потребует. Кроме того, вам предстоит сделать некоторые предположения относительно распределения загрузки для конкретных ЭВМ и других сетевых элементов, задержек в переключателях, мостах, времени обработки запросов в серверах. Здесь нужно учитывать и характер решаемых на ЭВМ задач. www/ftp-сервер или обычная персональная рабочая станция создают различные сетевые трафики. Определенное влияние на результат могут оказывать и используемые ОС. В случае моделирования реальной сети можно произвести соответствующие измерения, что иногда тоже не слишком просто. Учитывая сложность моделирования на одной ординарной ЭВМ, следует ограничиваться моделированием не более чем одной минуты для каждого из наборов параметров (этого времени достаточно для копирования практически любого файла через локальную сеть). Исключение может составлять моделирование внешнего трафика, но в этом случае весь локальный трафик должен рассматриваться как фоновый.
4.1. Аналитическое моделирование
Определение характеристик сети до того, как она будет введена в эксплуатацию, имеет первостепенное значение. Это позволяет отрегулировать характеристики локальной сети на стадии проектирования. Решение этой проблемы возможно путем аналитического или статистического моделирования.
Аналитическая модель сети представляет собой совокупность математических соотношений, связывающих между собой входные и выходные характеристики сети. При выводе таких соотношений приходится пренебрегать какими-то малосущественными деталями или обстоятельствами.
Телекоммуникационная сеть при некотором упрощении может быть представлена в виде совокупности процессоров (узлов), соединенных каналами связи. Сообщение, пришедшее в узел, ждет некоторое время до того, как оно будет обработано. При этом может образоваться очередь таких сообщений, ожидающих обработки. Время передачи или полное время задержки сообщения d равно:
D = Tp + S + W,
где Tp, S и W, соответственно, время распространения, время обслуживания и время ожидания. Одной из задач аналитического моделирование является определение среднего значения D. При больших загрузках основной вклад дает ожидание обслуживания W. Для описания очередей в дальнейшем будет использована нотация Д. Дж. Кенделла: A/B/C/K/m/z,
где А - процесс прибытия: В - процесс обслуживания; С - число серверов (узлов); К - максимальный размер очереди (по умолчанию - ![]() ); m - число клиентов (по умолчанию -
); m - число клиентов (по умолчанию - ![]() ); z - схема работы буфера (по умолчанию FIFO). Буквы А и В представляют процессы прихода и обслуживания и обычно заменяются следующими буквами, характеризующими закон, соответствующий распределения событий.
); z - схема работы буфера (по умолчанию FIFO). Буквы А и В представляют процессы прихода и обслуживания и обычно заменяются следующими буквами, характеризующими закон, соответствующий распределения событий.
D - постоянная вероятность;
M - марковское экспоненциальное распределение;
G - обобщенный закон распределения;
Ek - распределение Эрланга порядка k;
Hk - гиперэкспоненциальное распределение порядка k;
Наиболее распространенными схемами работы буферов являются FIFO (First-In-First-Out), LIFO (Last-In-First-Out) и FIRO (First-In-Random-Out). Например, запись M/M/2 означает очередь, для которой времена прихода и обслуживания имеют экспоненциальное распределение, имеется два сервера, длина очереди и число клиентов могут быть сколь угодно большими, а буфер работает по схеме FIFO. Среднее значение длины очереди Q при заданной средней входной частоте сообщений l и среднем времени ожидания W определяется на основе теоремы Литла (1961):
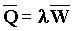
Для варианта очереди M/G/1 входной процесс характеризуется распределением Пуассона со скоростью поступления сообщений l. Вероятность поступления k сообщений на вход за время t равно:
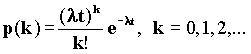
Пусть N - число клиентов в системе, Q - число клиентов в очереди и пусть вероятность того, что входящий клиент обнаружит j других клиентов, равна:
Пj = P[n=j], j=0,1,2,… 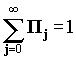 ; П0 = 1- r; r = lt;
; П0 = 1- r; r = lt;
Тогда среднее время ожидания w:
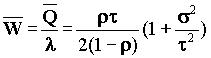 (формула Поллажека-Хинчина)
(формула Поллажека-Хинчина)
s - среднеквадратичное отклонение для распределения времени обслуживания.
Для варианта очереди M/G/1 H(t) = P[x£ t] = 1 - e-mt (H - функция распределения времени обслуживания). Откуда следует s2 = t2.
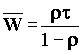
Для варианта очереди m/d/1 время обслуживания постоянно, а среднее время ожидания составляет:
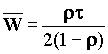
Аналитическая модель для сетей Ethernet (CSMA-CD) разработана Лэмом (S. S.Lam: “A Carrier Sense Multiple Access Protocol for Local Networks,” Computer Networks, vol. 4, n. 1, pp. 21-32, January 1980). Здесь предполагается, что сеть состоит из бесконечного числа станций, соединенных каналами с доменным доступом. То есть станция может начать передачу только в начале какого-то временного домена. Распределение сообщений подчиняется закону Пуассона с постоянной скоростью следования l. Среднее значение времени ожидания для таких сетей составляет:
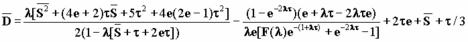
где е - основание натурального логарифма, t - задержка распространения сигнала в сети. ![]() , соответственно первый и второй моменты распределения передачи или обслуживания сообщения. f(l) преобразование Лапласа для распределения времени передачи сообщения. Следовательно
, соответственно первый и второй моменты распределения передачи или обслуживания сообщения. f(l) преобразование Лапласа для распределения времени передачи сообщения. Следовательно
 , а для сообщений постоянной длины f(l)=e-r
, а для сообщений постоянной длины f(l)=e-r 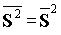 , где
, где ![]() . Для экспоненциального распределения длин сообщений:
. Для экспоненциального распределения длин сообщений:
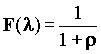 ,
, ![]() .
.
Рассмотрим вариант сети Ethernet на основе концентратора-переключателя с числом каналов N. При этом будет предполагаться, что сообщения на входе всех узлов имеют пуассоновское распределение со средней интенсивностью li, распределение сообщений по длине произвольно. Сообщения отправляются в том же порядке, в котором они прибыли. Трафик в сети предполагается симметричным. Очередь имеет модель M/G/1. Среднее время ожидания в этом случае равно:
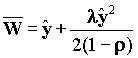 ,
,
где 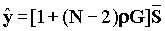 ,
,
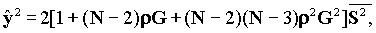
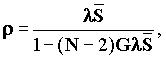
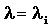 , а G=1/(N-1) равно вероятности того, что сообщение отправителя i направлено получателю j. Требование стабильности r£ 1 требует, чтобы
, а G=1/(N-1) равно вероятности того, что сообщение отправителя i направлено получателю j. Требование стабильности r£ 1 требует, чтобы 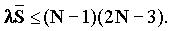 Для больших n это приводит к
Для больших n это приводит к 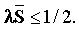 .
.
Среднее время распространения сообщения в сети равно ![]() , где t равно rtt.
, где t равно rtt.
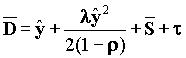
4.2. Симуляционное моделирование
Симуляционное (статистическое) моделирование служит для анализа системы с целью выявления критических элементов сети. Этот тип моделирование используется также для предсказания будущих характеристик системы. Такое моделирование может осуществляться с использованием специализированных языков симулирования и требует априорного знания относительно статистических свойств системы в целом и составляющих ее элементов. Процесс моделирования включат в себя формирование модели, отладку моделирующей программы и проверку корректности выбранной модели. Последний этап обычно включает в себя сравнение расчетных результатов с экспериментальными данными, полученными для реальной сети.
При статистическом моделировании необходимо задать ряд временных характеристик, например:
Системное время | Интервал от момента генерации сообщения до получения его адресатом, включая ожидание в очереди |
Время ожидания | Промежуток от приема сообщения сетевым интерфейсом до обработки его процессором |
Время распространения | Задержка передачи сообщения от одного сетевого интерфейса до другого |
Время передачи | Задержка пересылки сообщения от одного процессора до другого |
Полный список таких временных характеристик включает в себя значительно больше величин.
В процессе моделирования рассчитываются следующие параметры:
Статистика очередей |
Средняя длина очереди |
Пиковая длина очереди |
Среднеквадратичное отклонение длины очереди от среднего значения |
Статистика времени ожидания |
Среднее время ожидания |
Максимальное время ожидания |
Среднеквадратичное отклонение времени ожидания |
Статистика системного времени |
Среднее системное время |
Максимальное системное время |
Среднеквадратичное отклонение системного времени |
Полное число сообщений в статистике системного времени |
Пиковое значение числа системных сообщений |
Среднеквадратичное отклонение числа системных сообщений |
Статистика потерь сообщений |
Полное число потерянных сообщений |
Частота потери сообщений |
Доля потерь из-за переполнения очереди |
Доля потерь из-за таймаутов |
Возможны разные подходы к моделированию. Классический подход заключается в воспроизведении событий в сети как можно точнее и поэтапное моделирование последствий этих событий. В реальной жизни события могут происходить одновременно в различных точках сети. По этой причине для моделирования идеально подошел бы многопроцессорный компьютер, где можно воспроизводить любое число процессов одновременно. В любом случае необходимо выбрать некоторый постоянный временной интервал и считать, что события произошли одновременно, если расстояние между ними меньше этого интервала. Для сетей типа ethernet таким временным интервалом может быть бит-тайм (для 10-мегагбитного ethernet это 100нс). Понятно, что это уже отступление от реальности (ведь задержки в сетевом кабеле не кратны этому времени), но не слишком значительное. Надо сказать, что такого рода предположений при моделировании приходится делать много. По этой причине крайне важно сравнивать результаты моделирования с данными, полученными для реальной сети. Если отличия лежат в пределах 10-20%, можно считать, что сделанные предположения не увели программу слишком далеко от жизни и ею можно пользоваться для расчетов. Рассмотренный выше подход пригоден для моделирования сетевого коллапса, так как скорость расчетов здесь зависит от числа узлов и почти не зависит от сетевой загрузки.
Другим подходом может стать метод, где для каждого логического сегмента (зоны столкновений) сначала моделируется очередь событий. При этом в каждой рабочей станции моделируется последовательность пакетов, ожидающих отправки. Эта очередь может время от времени модифицироваться, например, при получении ЭВМ пакета извне и необходимости послать на него отклик. После того как такая очередь для каждого сетевого объекта (сюда помимо ЭВМ входят мосты, переключатели и маршрутизаторы) построена, запускается программа отправки пакетов. При этом выбирается самый первый по времени пакет (ожидающий дольше других) и проверяются для него условия начала передачи (отсутствие несущей на входе сетевого интерфейса в данный момент и в течение 9,6 мксек до рассматриваемого момента - 96 тайм-битов). Если условия отправки выполнены, он “посылается” в сеть. Вычисляются моменты достижения им всех узлов данного логического сегмента, проверяются условия его столкновения с другими пакетами. Следует заметить, в этом подходе снимаются ограничения “дискретности” временной шкалы, использованной в предыдущем “классическом” подходе. Этот подход позволяет заметно ускорить расчеты при большом числе узлов, но малой загрузке сети. Проблемы реализации данной концепции моделирования связаны с обслуживанием довольно сложного списка, описывающего очередь пакетов, ожидающих отправки. В структуру этого списка включается и описание ситуации в сети на данный временной период. Дополнительные трудности сопряжены с поведением мостов, переключателей и маршрутизаторов, так как они могут вставлять в очередь дополнительные элементы, требующие немедленного обслуживания. Аналогичные вставки в очередь будут вызывать полученные станцией пакеты ICMP или TCP, требующие откликов. Причем такое вставление в очередь асинхронно по отношению к процедуре “отправки” пакетов. Очередь для всей локальной сети может быть единой, тогда пакеты разных логических сегментов должны быть помечены определенными флагами. При переходе из сегмента в сегмент флаг будет меняться. Возможно и построение независимых очередей для каждого из логических сетевых сегментов.
Целью моделирования является определение зависимости пропускной способности сети и вероятности потери пакета от загрузки, числа узлов в сети, длины пакета и размера области столкновений.
Исходные данные о структуре и параметрах сети берутся из базы данных. Ряд параметров сети задаются конфигурационным файлом (профайлом). Сюда могут записываться емкость буфера интерфейса и драйвера, время задержки обработки запроса (хотя в общем случае эта величина может также иметь распределение) и т. д.. К таким параметрам относятся также: MTU, MSS, TTL, window, некоторые значения таймаутов и т. д.
Сеть разбивается на логические сегменты (зоны столкновений), в каждой из которых работает независимая синхронизация процессов (хотя эти процессы и влияют друг на друга через мосты, переключатели и маршрутизаторы).
Полное моделирование сети с учетом рабочих приложений предполагает использование следующих распределений:
· Распределение по проценту времени использования каждого из узлов для того или иного вида приложений.
· Распределение узлов сети по их активности.
· Распределение по используемым протоколам
· Распределение по длинам пакетов.
Последние два пункта существенным образом коррелированы с первым, так как используемые протоколы зависят от приложения, а активность узла может определяться, например длиной пересылаемого файла. По этой причине при полномасштабном моделировании сначала определяется, что собирается делать рабочая станция или сервер, (с учетом распределения по приложениям определяется характер задачи: FTP, MS explorer и т. д.). После этого разыгрываются параметры задания (длина файла, удаленность объекта и пр.), а уже на основе этого формируется фрагмент очереди пакетов.
Задача первого этапа: проверка пропускной способности при вариации загрузки и длин пакетов, подсчет числа столкновений, проверка влияния размера буфера сетевого интерфейса на пропускную способность (влияние размера буфера переключателей по пути до адресата).
Исходные данные для первого этапа:
· частота посылки пакетов для каждого из узлов (в начале равная для всех) [d - интервал между пакетами]
· длина пакета, посылаемого каждым узлом, (в начале равна для всех: минимальная [512 бит] и максимальная [12000 бит])
· временное распределение моментов посылки пакетов (в начале равномерное)
Структура описания каждого из узлов включает в себя (формируется с учетом будущего расширения):
· Номер узла (идентификатор)
· Код типа узла (байт: рабочая станция, мост, переключатель, маршрутизатор, повторитель)
· mac-адрес (для повторителя =0)
· ip-адрес (для повторителя, обычного MAC-моста и переключателя =0)
· Байт статуса (узел ведет передачу; до узла дошел чужой пакет,….)
- d (среднее расстояние между концом предыдущего и началом очередного пакета в бит-тактах)
· Дисперсия ширины пакетов
· Дисперсия значения d (зазор между последовательными пакетами).
· Код используемого протокола (IPv4 или IPv6; TCP, UDP, ICMP и т. д.).
· Полная длина сообщения в байтах
· Время обработки пакета (задержка посылки отклика в бит-тактах)
· Длина очередного пакета
· Байт типа адресации (unicast, broadcast, multicast)
· Ширина окна (число отправляемых пакетов без подтверждения)
· Объем входного буфера (число пакетов; может измеряться и в байтах, но тогда нужны специальные указатели)
· Объем выходного буфера (число пакетов)
· Байт режима работы (для мостов и переключателей: cut-through; store-and-forward и т. д.; для рабочей станции определяется типом используемого протокола и фазой его реализации)
Формат описания топологии сети (список)
Элемент списка:
· Идентификатор узла (номер)
· Код типа узла
· Список узлов соседей (номер_соседа:задержка_до_него)
Процесс посылки пакета включает в себя (в соответствии с требованиями документа IEEE 802.3):
1. Проверку возможности начала (отсутствует чужая активность, ipg=9,6 мксек)
2. Последовательную передачу битов (каждый бит-такт)
3. Контроль состояния столкновений (на протяжении времени, соответствующего диаметру столкновений сегмента сети)
4. Обработка случаев столкновения (посылка jam)
5. При столкновении вычисление номера бит-такта попытки возобновления передачи
Попытка начала передачи предполагает проверку:
1. Осуществлялась ли передача на предыдущем бит-такте?
2. Контроль числа свободных от передачи бит-тактов (<96 ?)
Процесс приема предполагает:
1. Контроль окончания приема (бит-такт без данных в канале). Окончание приема может означать переход в режим анализа полученных данных.
2. Контроль наличия столкновения
3. Необходимо предусмотреть возможность (в некоторых режимах) контроля адресов (mac и ip) и содержимого пакета и т. д. (включая изменение режима работы узла, например, переход от чтения к передаче). Данный пункт абсолютно необходим для мостов и переключателей.
Центральный менеджер осуществляет:
1. Регистрацию начала передачи любым из узлов (номер узла и номер бит-такта)
2. Расчет положения начала пакета к началу очередного бит-такта для всех возможных путей распространения.
3. Запись в байты статуса узлов
Вариант 1 (равномерное распределение по времени)
Для каждого узла устанавливается определенная средняя частота посылки пакетов. Время посылки предполагается случайным. Средняя частота может быть задана равной для всех узлов. Так как минимальный размер пакета равен 64 байт (51.2 мксек=512 бит-тактов), максимальная частота посылки пакетов составляет ~19.5 кГц.
Минимальный средний период посылки пакетов определяется в бит-тактах и должен быть больше 512 бит-тактов. Понятно, что пока узел осуществляет передачу, он не может пытаться передать новый пакет (многозадачные, многопользовательские системы с несколькими сетевыми интерфейсами пока рассматривать не будем). По этой причине частота посылки пакетов однозначно определяется паузой между концом предыдущего пакета и началом нового (d). Среднее значение периода посылки пакетов равно Тпакета+96(бит-тактов)+d (значение d величина статистическая). Для каждого узла задается значение d (сначала равное для всех узлов). Если предположить равномерное распределение вероятности (передача пакета может начаться в любой бит-такт с равной вероятностью).
При определении того, пытаться ли начинать передачу в данный бит-такт будет проверка условия:
rndm<1/d (выполнение условия предполагает попытку начала передачи).
Если вероятность прихода n пакетов на время t распределена по закону Пуассона:
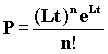 , где L - средняя частота следования событий, то реальное время между событиями t может быть определено как t = - T ln(R). R - случайное число 0£ R £ 1, а T = 1/L.
, где L - средняя частота следования событий, то реальное время между событиями t может быть определено как t = - T ln(R). R - случайное число 0£ R £ 1, а T = 1/L.
Результатами моделирования могут являться (фиксируются отдельно для каждого набора входных параметров):
1. | Вероятность потери пакета для логического сегмента и каждой из рабочих станций. |
2. | Пропускная способность серверов для каждого из логических сегментов (путь сервер -> логический сегмент) |
3. | Вероятность столкновения для каждого логического сегмента и каждой рабочей станции. |
4. | Распределение потоков по логическим сегментам (и рабочим станциям) независимо для каждого направления (вход и выход). |
5. | Распределение потоков для всех входов/выходов переключателей мостов и маршрутизаторов. |
6. | Доля вспомогательного трафика (ICMP, SNMP, отклики TCP, широковещательные запросы и т. д.) по отношению к информационному потоку для различных узлов сети (серверов, маршрутизаторов) |
7. | Уровень широковещательного трафика для каждого из логических сегментов |
5. Заключение
Были рассмотрены основополагающие принципы построения виртуальных сетей и управления трафиком, передаваемым внутри них. Из приведенного обзора становится видно, что искажение сигнала при совместном использовании физических каналов, вызванное передачей разных потоков данных в рамках существующих протоколов и стандартов, не учитывается, хотя, несомненно, ведет за собой снижение пропускной способности канала, что является одной из ключевых характеристик любых сетей. Более того, даже на предпроектном этапе – этапе сетевого моделирования невозможно выявить подобные «узкие места» в сети и, тем более, заложить возможность управления трафиком при масштабировании сети и создании новых пересекающихся виртуальных сетей.
Таким образом, видится уместным, с учетом множества прикладных проблем, связанных со стандартизированием средств и служб QoS, как показал обзор, фактически единственной технологии позволяющей решать задачи управления трафиком в виртуальных сетях, что решать проблему искажения сигнала стоит на предпроектном этапе.
