

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Министерство образования и науки Российской Федерации
НОВОСИБИРСКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
доказательство
правильности
программ
Часть 2
Дополнительные приемы
НОВОСИБИРСК
2005
УДК
Рецензенты: , канд. техн. наук, доц. каф. ПМт;
, канд. техн. наук, ст. преп. каф. АВТ
Работа подготовлена на кафедре автоматики для студентов III-IV курса АВТФ (специальности 2204)
дневной и заочной форм обучения
Доказательство правильности программ: Дополнительные приемы: Конспект лекций. – Новосибирск, Изд-во НГТУ, 2005. – 36 с.
В работе изложены дополнительные приемы доказательства правильности блок-схем и программ для ЭВМ. Основные принципы доказательства правильности были рассмотрены в первой части конспекта лекций, выпущенной в издательстве НГТУ в 2004 г. Во второй части рассматриваются различные виды математической индукции, в том числе структурная индукция, положенная в основу приемов доказательства правильности рекурсивных программ, а также аксиоматический подход к доказательству правильности программ и формализация доказательства с помощью индуктивных утверждений. Данный подход дает программисту некоторое систематическое средство для проверки его программ за столом, а также способствует более глубокому пониманию важнейших понятий программирования. Предлагаемые принципы доказательства иллюстрируются многочисленными примерами.
Пособие будет полезно и для студентов других специальностей, изучающих программирование и интересующихся вопросами доказательства правильности программ.
© Новосибирский государственный
технический университет, 2005
Глава 1. РАЗЛИЧНЫЕ ВЕРСИИ МАТЕМАТИЧЕСКОЙ ИНДУКЦИИ
Математическая индукция представляет собой некоторый общий способ доказательства в математике. Обычно математическую индукцию вводят как метод доказательства утверждений о положительных числах. Чаще всего на практике используется принцип простой индукции, суть которого заключается в следующем:
Пусть S(n) — некоторое высказывание о целом числе n и требуется доказать, что S(n) справедливо для всех положительных чисел n.
Согласно простой математической индукции, для этого необходимо
1) доказать, что справедливо высказывание S(1);
2) доказать, что если для любого положительного числа n справедливо высказывание S(n), то справедливо и высказывание S(n +1).
Из приведенных выше двух утверждений вытекает, что S(n) справедливо для всех положительных чисел. Этот факт интуитивно очевиден, хотя при аксиоматической трактовке целых чисел сам принцип в такой формулировке следует рассматривать как аксиому. Из первого положения индукции следует, что справедливо S(1), а из второго – что справедливо S(2), если справедливо S(1). Но S(1) справедливо, следовательно, должно быть справедливо и S(2). Из второго положения индукции вытекает также, что справедливо S(3), если справедливо S(2). Таким образом, поскольку мы знаем, что S(2) справедливо, то, следовательно, справедливо S(3) и т. д. Отсюда интуитивно видно, что эти два положения вместе доказывают справедливость S(1), S(2), S(3), ..., S(n)....
Именно принцип простой математической индукции, а также принцип модифицированной простой индукции, подробно рассмотренные в предыдущем учебном пособии, используются для доказательства правильности программ. В данном пособии сформулированы и проиллюстрированы на примерах более строгая версия математической индукции, обобщение этого метода на случай любых вполне упорядоченных множеств, а не только положительных чисел, а также структурная индукция, используемая для доказательства правильности рекурсивных функций.
1.1. Строгая математическая индукции
При доказательствах некоторых высказываний о целых числах иногда требуется более строгая версия принципа индукции.
Принцип строгой индукции
Пусть S(n) – некоторое высказывание о целом числе n и требуется доказать, что S(n) справедливо для всех положительных n. Для этого необходимо:
1) доказать, что справедливо S(1);
2) доказать, что если справедливы S(1), S(2), S(3), ..., S(n) для всех положительных n, то справедливо и S(n + 1).
Отметим, что эта версия индукции почти идентична простой индукции, за одним исключением: при доказательстве второго положения в качестве гипотезы предполагается не просто справедливость высказывания S(n), а справедливость высказываний S(1), S(2), S(3), ..., S(n). Исходя из этой более строгой гипотезы, необходимо, как и выше, доказать справедливость S(n + 1).
Интуитивно ясно, что эти два положения подразумевают справедливость S(n) для любого положительного числа n. Из первого положения известно, что S(1) справедливо, а из второго следует, что если справедливо S(1), то справедливо и S(2). Так как S(1) действительно справедливо, следовательно, то же можно сказать и о S(2). Затем, так как и S(1), и S(2) справедливы, из второго положения следует справедливость S(3). Из справедливости высказываний S(1), S(2), S(3) и второго утверждения вытекает справедливость высказывания S(4) и т. д.
Рассмотрим несколько примеров, в которых полезно использовать принцип строгой индукции.
Пример 1.1. Простым числом называется положительное число, делящееся без остатка только на 1 и на само себя. Мы хотим доказать, что каждое положительное число n можно представить в виде произведения одного и более простых чисел. Докажем это с помощью строгой индукции по n:
1) если n = 1, то это число является простым, и, следовательно, его можно представить как «произведение» одного простого числа;
2) предположим, что каждое из чисел 1, 2, ..., n может быть записано в виде произведения простых чисел. Необходимо показать, что число n + 1 также можно представить в виде произведения простых чисел. Если n + 1 является простым числом, то очевидно, что его можно записать в виде произведения одного простого числа на 1. Если n + 1 – не простое число, тогда существует некоторое положительное число a, такое, что 1 < a < n + 1, и оно делит n + 1 без остатка.
Другими словами, 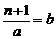 , или n + 1 = a×b.
, или n + 1 = a×b.
Каждое из чисел a и b меньше n. Следовательно, по гипотезе индукции и a, и b можно представить в виде произведения простых чисел. Отсюда очевидно, что и n + 1 можно записать как произведение этих же простых чисел, так как n + 1 = a×b.
Следует отметить, что в этом примере, по существу, требуется строгая индукция. О числах a и b известно лишь только то, что они меньше n. Поэтому, для того чтобы использовать индукцию, необходимо знать, что каждое из положительных чисел 1, 2, ... , n может быть представлено в виде произведения простых чисел. Одного предположения о том, что n можно записать в виде произведения простых чисел, оказывается недостаточно.
Пример 1.2. Рассмотрим последовательность чисел, называемых числами Фибоначчи. В нее входят f0 = 0, f1 = 1, f2 = 1, f3 = 2, f4 = 3, f5 = 5, f6 = 8, ... , где (n + 1)-е число Фибоначчи определяется как fn + 1= fn + fn – 1 (для n ³ 1). Пусть = (1 +![]() )/2 и требуется доказать, что fn £ an – 1 для любого неотрицательного числа a. Для доказательства используем метод строгой индукции по n. Так как доказывается высказывание о неотрицательных числах, а принцип индукции сформулирован для положительных, используем очевидную модификацию метода:
)/2 и требуется доказать, что fn £ an – 1 для любого неотрицательного числа a. Для доказательства используем метод строгой индукции по n. Так как доказывается высказывание о неотрицательных числах, а принцип индукции сформулирован для положительных, используем очевидную модификацию метода:
1. Для n = 0 необходимо показать, что f0 £ a0 – 1 . Это справедливо, так как f0 = 0 ![]() = a–1. Необходимо рассмотреть особый случай, когда n = 1. Здесь мы имеем f1 = 1 £ 1=a0 = a1–1.
= a–1. Необходимо рассмотреть особый случай, когда n = 1. Здесь мы имеем f1 = 1 £ 1=a0 = a1–1.
2. Предположим, что fm £ am – 1 справедливо для всех неотрицательных целых чисел m = 0, 1, 2, ... , n. Нужно показать, что fn+1 £ a(n + 1) – 1 также справедливо. По гипотезе индукции fn £ an – 1 и fn–1 £ a(n – 1) – 1. Поэтому
fn + 1 = fn + fn – 1 £an – 1 + an – 2 = an – 2 × (a+1).
Обратите внимание, что
a2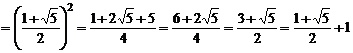 = a + 1.
= a + 1.
Фактически мы так и выбирали a, чтобы выполнялось условие a + 1 = a2. Поэтому мы получаем
fn + 1 = fn + fn – 1 £ an – 2 × (a+1) = an – 2 × a2 = an = a(n + 1) – 1 .
что и требовалось доказать.
Отметим, что необходимо было знать, что и fn, и fn–1 удовлетворяют гипотезе индукции. Только в этом случае доказательство возможно. Одного только знания о справедливости высказывания для fn недостаточно. Таким образом, строгая индукция нам необходима по существу. Отметим также, что в данном частном случае нам потребовалось доказывать, что f0 £ a0 и f1 £ a1; мы не можем записать f1 как f0 + f–1 , так как f–1 не существует.
В качестве упражнения по данной теме попробуйте изменить приведенный в данном разделе принцип индукции для доказательства справедливости высказывания S(n) для целых чисел n, удовлетворяющих условию n ³ n0, а не только для любых положительных целых чисел.
1.2. Обобщенная индукция
Метод математической индукции можно обобщить и применять не только для доказательства высказываний о множестве положительных целых чисел, но и о более общих множествах некоторых объектов. Для этого сначала дадим определение, связанное с обобщением структуры целых чисел.
Определение. Говорят, что бинарное отношение < вполне упорядочивает множество X, или множество вполне упорядочено, если отношение < обладает следующими свойствами:
1) если x, y, z принадлежат X, а х < у и у < z, то х < z;
2) для х и у из X справедлива одна и только одна из трех возможностей: либо х < у, либо у < х, либо х = у;
3) если А – любое непустое подмножество X, то в А существует некоторый элемент х, такой, что х £ у для любого у, принадлежащего А.. Другими словами, любое непустое подмножество X содержит «наименьший элемент».
Отметим, что это определение касается обобщения структуры положительных (неотрицательных) целых чисел. Множество положительных целых чисел вполне упорядочено относительно обычного отношения <.
Пример 1.3. Множество всех целых не вполне упорядочено с помощью обычного отношения <. Такое множество обладает свойствами 1 и 2, но не обладает свойством 3. Множество всех отрицательных целых есть непустое подмножество множества целых, но не содержит наименьшего элемента.
Пример 1.4. Множество неотрицательных действительных чисел не является вполне упорядоченным с помощью обычного отношения <. Как и в предыдущем примере, для него выполняются свойства 1 и 2, но не выполняется свойство 3. Например, множество всех действительных чисел больше единицы, (такое множество можно обозначить следующим-образом: {х : х есть действительное и х > 1}) не содержит наименьшего элемента. Действительно, единица меньше любого элемента множества, но она множеству не принадлежит.
Пример 1.5. Множество всех упорядоченных пар неотрицательных целых чисел вполне упорядочено с помощью отношения лексикографического порядка <. Это отношение можно определить так: отношение (n1, n2) < (n3, n4) справедливо, если и только если (n1 < n3) или (n1 = n3 и n1 < n4). В качестве упражнения покажите, что такое отношение обеспечивает нужную упорядоченность.
Теперь сформулируем принцип обобщенной индукции для доказательства высказываний относительно любых вполне упорядоченных множеств.
Принцип обобщенной индукции
Пусть X – вполне упорядоченное относительно < множество, а S(х) – некоторое высказывание, касающееся элемента х из X. Если требуется доказать справедливость S(х) для всех х, принадлежащих X, то необходимо:
1) доказать, что справедливо S(х0), где х0 – наименьший элемент в X;
2) доказать для всех х в X, удовлетворяющих условию х0 < х, что если справедливо S (у) для всех у < х, то справедливо и S(х).
Отметим, что если X – множество положительных целых чисел, а отношение < имеет обычный смысл, то принцип обобщенной индукции идентичен принципу строгой индукции (разд. 1.1).
Чтобы убедиться в действенности принципа обобщенной индукции как метода доказательства, предположим, что S(х) – некоторое высказывание, для которого уже доказаны оба положения. Мы хотим сделать вывод о том, что S(х) справедливо для любых х в X. Предположим, что это не так. Пусть множество А = {х: х принадлежит X и S(х) ложно}. Если S(х) не справедливо для всех х в X, то А – непустое подмножество X. Так как X вполне упорядочено, то известно, что А содержит наименьший элемент а0. По определению это наименьший элемент X, для которого S(х) не справедливо, Таким образом, S(у) справедливо для всех у (если они есть), удовлетворяющих условию у < а0. Если а0 – наименьший элемент в X, то S(а0) справедливо, что следует из первого положения. В противном случае из справедливости S(у) для всех у < а0 и второго положения вытекает, что S(а0) справедливо. Но это противоречит предположению, что а0 принадлежит А и S(а0) ложно. Единственный способ устранить это противоречие – считать А пустым множеством, т. е. в X нет элементов, для которых высказывание S(х) ложно.
Пример 1.6. Рассмотрим последовательность чисел, определенную следующим образом: S0, 0 = 0, а для любой другой пары неотрицательных чисел m, n
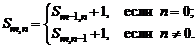
Например, первые элементы этой последовательности:
S0, 0 = 0, S1, 0 = S0, 0 + 1 = 0 + 1 = 1,
S0, 1 = S0, 0 + 1 = 1, S1, 1 = S1, 0 + 1 = 1 + 1 = 2,
S2, 0 = S1, 0 + 1 = 2, S2, 1 = S2, 0 + 1 = 3, ... .
Нужно доказать, что Sm, n = m + n для любых неотрицательных целых m, n. Используем принцип обобщенной индукции на множестве X упорядоченных пар неотрицательных целых чисел. Множество упорядочено на основе лексикографического порядка, описанного в примере 3. Чтобы доказать справедливость Sm, n = m + n для любых < m, n > в X, необходимо:
1) доказать, что Sm, n = m + n справедливо, если < m, n > – наименьший элемент в X. Но так как наименьший элемент – пара < 0, 0 >, то нужно показать, что S0, 0 = 0 + 0 = 0. Это очевидно по определению S0, 0;
2) доказать, что если Sm’, n’ = m’ + n’ справедливо для любых пар < m’, n’ > < < m, n >, то справедливо и Sm, n = m + n для любых < 0, 0 > < < m, n > в X. Предположим, что формула Sm’, n’ = m’ + n’ верна для < m’, n’ > < < m, n >. Это гипотеза индукции. Нужно показать, что Sm, n = m + n. Существует две возможности: либо
n = 0, либо n ¹ 0. Если n = 0, то по определению Sm, n = Sm–1, n + 1. Однако < m–1, n > < < m, n >, и, следовательно, по нашей гипотезе Sm–1, n = (m – 1) + n. Поэтому Sm, n = Sm–1, n+ 1 = = (m – 1 + n) + 1 =
= m + n. Если n ¹ 0, то Sm, n = Sm, n–1 + 1 по определению. Но
< m, n–1 > < < m, n > и по гипотезе Sm, n–1 = m + (n – 1). Следовательно, в этом случае Sm, n = Sm, n–1 + 1 = (m + n – 1) + 1 = m + n, что и требовалось доказать.
Глава 2. ФОРМАЛИЗАЦИЯ ДОКАЗАТЕЛЬСТВА правильности С ПОМОЩЬЮ ИДУКТИВНЫХ УТВЕРЖДЕНИЙ
В первой части конспекта лекций мы сформулировали и показали на примерах, как используется метод индуктивных утверждений. И формулировки индуктивных утверждений, и процесс доказательства проводились довольно неформальным образом. Если использовать какую-либо формальную нотацию для записи индуктивных утверждений и соответствующую дедуктивную систему для проведения доказательств, то можно формализовать весь этот процесс. В данной главе мы обсудим некоторые аспекты такой формализации. Если мы надеемся, что в конце концов придем к тому, что при поддержке некоторой «механической» системы будем либо выполнять доказательство, либо его проверять, то некоторого типа формализация нам необходима. Студенты, которых интересует вопрос формализации, могут обратиться к литературе [3, 4, 5]. Наиболее изученной формальной нотацией для формулирования и проведения математического доказательства является исчисление предикатов. Мы полагаем, что студент знаком с такого рода нотацией, либо предлагаем ему воспользоваться книгами по математической логике [7, 8] и самостоятельно ознакомиться с данными вопросами.
Напомним, что метод индуктивных утверждений состоит в следующем [1]. Для доказательства частичной правильности некоторой блок-схемы относительно утверждений А и С мы связываем утверждение А с начальной точкой блок-схемы, а утверждение С – с конечной. Кроме этого, необходимо выделить и связать с блок-схемой некоторые другие утверждения (описывающие отношения между значениями переменных, справедливые в момент попадания в соответствующую точку программы). Нужно, в частности, связать по крайней мере с одной из точек в замкнутом пути (цикле) одно такое утверждение. Затем необходимо для каждого пути в блок-схеме, ведущего из точки i с утверждением Аi в точку j с утверждение Аj при условии, что на пути из i в j нет промежуточных точек с утверждениями, доказать, что если мы находимся в точке i и справедливо утверждение Аi а затем переходим по нашему пути в точку j, то при попадании в эту точку будет справедливо утверждение Аj. Для формализации такого доказательства необходимо:
1) использовать некоторую формальную нотацию для записи утверждений;
2) формализовать то, что необходимо доказывать для каждого пути в блок-схеме;
3) использовать для выполнения доказательства некоторую формальную систему вывода (дедуктивную систему).
Развитие формальных методов вывода для выполнения доказательств не входит в круг вопросов, рассматриваемых в данном учебном пособии. Заинтересованный студент может познакомиться с этими вопросами в любом хорошем учебнике логики и учебном пособии [3]. Мы рассмотрим лишь вопросы, относящиеся к п. 1 и 2. Для цели, указанной в п. 1, можно использовать нотацию исчисления предикатов (или другую формальную нотацию). С ее помощью можно формулировать нужные утверждения. Исчисление предикатов не совсем подходит для формулирования индуктивных утверждений. Многие из них трудно (если вообще возможно) выразить с помощью этой нотации. Поиски наиболее подходящей формальной системы для записи индуктивных утверждений и проведения доказательств являются предметом современных исследований. Тем не менее здесь для выражения утверждений будет использоваться исчисление предикатов. Что касается п. 3, то надо дать некоторый систематический метод формирования для каждого из путей блок-схемы подлежащего доказательству формализованного высказывания. Множество всех таких высказываний, которые нужно доказывать для определения частичной правильности программы, иногда называют множеством условий верификации (verification conditions) для этой программы.
Для систематического формирования условий верификации некоторой блок-схемы поступим следующим образом. Рассмотрим по порядку все пути в блок-схеме. Предположим, что речь идет о пути из точки i в точку j. Утверждение, относящееся к точке i, обозначим через Аi (Х, Y, ...), где X, Y, ... – переменные, входящие в это утверждение. Аналогично обозначим и утверждение для точки j: Аj (Х, Y, ...). По пути из точки i в точку j значения переменных могут измениться (например, оператором присваивания). Для переменной V через epath (V) (изменение переменной вдоль пути) будем обозначать выражение, определяющее значение переменной V в точке j «в терминах» значений переменных в точке i и значений, присваиваемых переменным по мере прохождения пути. Если, например, на пути из i в j выполняется лишь пересылка X Y + 1, то epath (Х) = Y + 1, а epath (Y) = Y. Если на этом пути было три оператора присваивания Х X + 1,
Y Y + Y и X Х + Y – 2, то epath (Х) = (Х + 1) + (Y + Y) – 2 =
= X + 2•Y – 1 и epath (Y) = Y + Y = 2•Y. Однако на пути из точки i в точку j может встретиться несколько точек, где выполняются проверки. Будем обозначать такие проверки через tk (Х, Y, ...), где k – указывает точку, к которой относится проверка, а X, Y, ... – переменные, от которых она зависит. Предположим, что tk (Х, Y, ...), ..., t1 (Х, Y, ...) – полный набор всех проверок, встречающихся в различных точках на пути из точки i в точку j. Для каждой из этих проверок (tm (Х, Y, ...)) сформулируем высказывание![]() :
:
![]() ,
,
если путь из i в j проходит по ветви, отмеченной T (истина), и
![]() ,
,
если путь из i в j проходит по ветви, отмеченной буквой F (ложь). Через path’ обозначается часть пути из i в j от точки i до точки m. Теперь образуем полное высказывание ![]() . Запишем формализованное условие верификации для пути из точки i в точку j:
. Запишем формализованное условие верификации для пути из точки i в точку j:
[Аi (Х, Y, ...) L С path] ® Аj [e path (Х), e path (Y), ...).
Если на пути не встречаются проверки, то С path высказывание не включается.
Пример 2.1. Рассмотрим блок-схему (рис. 2.1), с которой мы уже имели дело в примере 2.3 в первой части учебного пособия [2]. Для записи утверждений, относящихся к разным точкам блок-схемы, использована нотация исчисления предикатов.
Сформируем множество условий верификации.
1. Путь из точки 1 в точку 2 назовем р1. Для этого пути имеем ер1 (J1) = J1, ер1 (J2) = J2, ер1 (IQ) = 0, ер1 (IR) = J1. Так как по пути проверки не выполняется, то можно написать следующее условие верификации для этого пути:
(0 £ J1 L 1 £ J2) ® [ер1 (J1) = ер1 (IQ) · ер1 (J2) + ер1 (IR) L 0 £ ер1 (IR)],
( 0 £ J1 L 1 £ J2 ) ® ( J1 = IQ · J2 + J1 L 0 £ J1).
2. Путь из точки 2 через точки 3, 4 в точку 2 обозначим через р2. Для этого пути имеем ер2 (J1) = J1, ер2 (J2) = J2, ер2 (IQ) = IQ + 1, ер2 (IR) = IR – J2.
На пути есть только одна проверка IR < J2. Ту часть пути р2, которая ведет от точки 2 до этой проверки, обозначим через р2'. Так как путь р2 после проверки проходит по ветви, отмеченной F, то
![]() .
.
Поскольку проверка только одна, получаем
Сp2 º Ø tp2.
Отсюда условие верификации для этого пути имеет вид
( J1 = IQ · J2 + IR L 0 £ IR L J2 £ IR ) ®
® [ер2 (J1) = ер2 (IQ) · ер2 (J2) + ер2 (IR) L 0 £ ер2 (IR)],
или после преобразования
(J1 = IQ · J2 + IR L 0 £ IR L J2 £ IR) ®
® [J1 = (IQ + 1) · J2 + (IR – J2) L 0 < IR – J2].
Рис. 2.1 |

3. Путь из точки 2 через 5 в точку 6 обозначим через рЗ. Для этого пути имеем ер3 (J1) = J1, ер3 (J2) = J2, ер3 (IQ) = IQ, ер3 (IR) = IR. На пути встречается лишь одна проверка IR < J2.
Часть пути от точки 2 до этой проверки обозначим через р3'. Как и выше, имеем ер3' (IR) = IR и ер3' (J2) = J2. Так как после проверки путь проходит по ветви, обозначенной Т (истина), то
![]() .
.
Следовательно, условие верификации для всего пути имеет вид
(J1 = IQ·J2+IR L 0£IR L IR<J2) ® (J1 = IQ·J2+IR L 0<IR L IR<J2).
Для того, чтобы закончить формализованную версию доказательства правильности данной блок-схемы методом индуктивных утверждений, остается лишь доказать справедливость каждого из этих трех верификационных условий с помощью некоторой системы вывода (дедукции). Мы не будем тратить время и обсуждать такую формальную систему. Если студент знаком с исчислением предикатов, то он может представить себе, насколько просто проводится доказательство этих условий с использованием только основных аксиом целой арифметики.
Глава 3. АКСИОМАТИЧЕСКИЙ ПОДХОД
К ДОКАЗАТЕЛЬСТВУ ЧАСТИЧНОЙ ПРАВИЛЬНОСТИ
Доказательство правильности для программ, написанных на языках программирования, в первой части учебного пособия мы проводили так же, как и для блок-схем. Другими словами, мы сопоставляли с некоторыми ключевыми точками в программе индуктивные утверждения. В частности, с каждым из замкнутых путей (циклов) должно быть сопоставлено по крайней мере одно такое утверждение. Затем мы показывали, что при попадании в процессе вычислений в ту или иную точку оказывалось справедливым соответствующее утверждение. Такое доказательство частичной правильности можно провести и в другой форме. Можно показать, что доказательство основывается на некоторых аксиомах или правилах верификации. В этом разделе рассмотрены правила верификации и показана их эквивалентность методу индуктивных утверждений. Мы не приводим полного множества правил верификации для какого-нибудь языка, а лишь на двух примерах поясним основную идею. Для записи правил верификации используем следующую нотацию: {А1} Р {А2}, где А1 и А2 – утверждения (индуктивные), а Р – фрагмент программы из одного или нескольких операторов. Такая запись означает, что если непосредственно перед выполнением Р справедливо А1 то после выполнения Р (если оно закончится) будет справедливо А2. Теперь перейдем к примерам правил верификации.
Пример 3.1. Представим себе, что в используемом нами языке есть оператор вида IF С ТНЕN S1 ЕLSЕ S2 и мы хотим доказать (как часть некоторого доказательства правильности), что {А1} IF С ТНЕN S1 ЕLSЕ S2 {А2}. Другими словами, нужно доказать, что если непосредственно перед выполнением этого оператора было справедливо А1 а затем закончилось выполнение оператора, то непосредственно после этого будет справедлива А2. Мы предполагаем, что оператор имеет смысл, традиционный для языков программирования, т. е. он эквивалентен приведенному на рис. 3.1 фрагменту блок-схемы. Аксиома, или правило верификации, которое можно использовать для доказательства приведенного утверждения, гласит:
Рис. 3.1. |
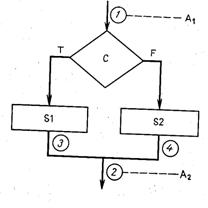
Если можно доказать, что
1) {А1 L С} S1{А2}
и
2) {А1 L Ø С} S2{А2},
то отсюда можно заключить, что
3) {А1} IF С ТНЕN S1 ЕLSЕ S2 {А2}.
Эквивалентность этой аксиомы методу индуктивных утверждений в форме, приведенной в первой части пособия, довольно очевидна. Действительно, доказывая правильность фрагмента программы, мы должны удостовериться в следующем:
1'. Если мы попали в точку 1 и справедливо утверждение А1 а затем проходим от точки 1 через точку 3 до точки 2, то А2 справедливо. Но для этого же пути известно, что до выполнения 51 справедливы и утверждение А1 и условие С, и мы стремимся показать, что если попадем в точку 2 (т. е. если выполнение S1 закончится), то А2 будет справедливо.
2'. Если мы попадем в точку 1 и справедливо утверждение А1 а затем проходим от точки 1 через точку 4 до точки 2, то А2 справедливо. Но для этого пути известно, что до выполнения S2 справедливо А1 и ложно условие С (т. е. Ø С справедливо). Мы стремимся показать, что если попадем в точку 2 (т. е. при условии окончания S2), то будет справедливо А2.
Таким образом, положения 1' и 2', которые нужно доказывать в методе индуктивных утверждений, фактически идентичны двум предусловиям 1 и 2, которые нужно доказывать, если мы хотим использовать соответствующее правило верификации.
Рис. 3.2 |
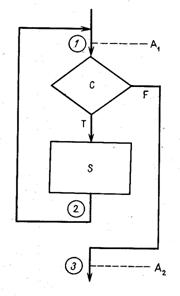
Пример 3.2. Предположим, что мы используем язык, в котором есть оператор вида
DO WHILE (C)
S
END;
Смысл этого оператора полностью характеризуется приведенным на рис. 3.2 фрагментом блок-схемы. Если нужно доказать {А1} Р {А2} где Р – такой же цикл, как DО WHILE, то можно воспользоваться следующей аксиомой или правилом верификации: Если можно доказать, что
1) {А1 L С} S{А1}
и
2) из {А1 L Ø С} следует А2,
то отсюда можно заключить, что
3) {А1} P {А2}.
Эквивалентность этой аксиомы методу индуктивных утверждений очевидна, так как при доказательстве частичной правильности нашего фрагмента блок-схемы мы должны удостовериться, что:
1'. Если мы попали в точку 1 и справедливо утверждение А1 а затем проходим из точки 1 через точку 2 в точку 7, то снова справедливо утверждение А1. Но для этого пути нам известно, что до выполнения S справедливы и утверждение А1 и условие С. Мы стремимся показать, что если мы вновь попадем в точку 1 (т. е. выполнение S закончится), то А1 будет справедливым.
2.' Если мы попадем в точку 1 и справедливо условие А1, а затем проходим из точки 1 в точку 3, то А2 будет справедливо. Но для этого пути справедливо А1 и ложно условие С (т. е. Ø С справедливо). Мы стремимся показать, что из А1 и Ø С следует А2.
Следовательно, оба положения 1' и 2', которые нужно доказывать в методе индуктивных утверждений, фактически идентичны двум предусловиям 1 и 2, которые мы должны доказывать, если хотим использовать правило верификации.
Приведенное правило верификации иногда записывают в менее общей форме:
Если можно доказать, что
1) {А1 L С} S{А1},
то отсюда можно заключить, что
2) из {А1} P {А1 L Ø С}, где Р – цикл вида DO WHILE.
Студент может легко убедиться в справедливости такого варианта правила, а кроме того, и в том, что он, как и первый вариант, используется лишь для доказательства частичной правильности. Оба варианта не гарантируют, что Р когда-нибудь закончится.
Пример 3.3. Рассмотрим пример доказательства частичной правильности с помощью правил верификации. Для этого нам потребуется еще одно дополнительное правило. Предположим, что Р1, Р2 – два фрагмента программы и необходимо доказать некоторый факт, касающийся фрагмента, состоящего из Р1, за которым непосредственно следует Р2. В этом случае может оказаться полезным следующее правило верификации:
Если можно доказать, что
1) {А1} Р1 {А2}
и
2) {А2} Р2 {А3} ,
то отсюда можно заключить, что
3) {А1} Р1; Р2 {А3} .
В доказательстве мы будем использовать следующую запись:
{А1}
Р
{А2}.
Это то же самое, что и запись { А1}Р {А2}.
Докажем с помощью правил верификации частичную правильность программы на ПЛ/1, соответствующей блок-схеме, для которой мы уже доказали частичную правильность в примере 2.3 в первой части учебного пособия [2]. Студент может сравнить эти два доказательства и убедиться в их идентичности. Фрагмент программы имеет вид
/* {0 £ J1 L 1 £ J2} */
IQ=0;
IR=J1;
/* {J1= IQ ·J2 + IR L 0 £ IR} */
DО WHILE (IR ³ J1);
IQ = IQ + 1;
IR = IR – J2;
END ;
/* {J1= IQ ·J2 + IR L 0 £ IR < J2} */
Мы хотим доказать, что {0 £ J1 L 1£ J2} P {J1= IQ·J2 + IR L 0 £ IR < J2}, где Р – приведенный выше фрагмент программы. Для этого нам нужно доказать:
1. {0 £ J1 L 1 £ J2} º {А1}
IQ=0;
IR=J1;
{J1= IQ ·J2 + IR L 0 £ IR} º {А2}
Это очевидно, так как после выполнения двух операторов из этого фрагмента программы мы будем иметь IQ=0 и IR=J1, а поэтому справедливо J1= 0·J2 + J1 = J1. Кроме того, так как перед выполнением этих действий справедливо 0 £ J1 и значение J1 при этом не изменяется, то после их выполнения будет справедливо
0 £ J1 = IR.
2. {J1= IQ ·J2 + IR L 0 £ IR} º {А2}
DО WHILE (IR ³ J1);
IQ = IQ + 1;
IR = IR – J2;
END ;
{J1= IQ ·J2 + IR L 0 £ IR < J2} º {А3}
Для доказательства этого положения воспользуемся правилом верификации, приведенным в примере 3.2. Из правила следует, что мы сможем сделать требуемое заключение, если докажем:
а) {А2 L IR ³ J2}
IQ = IQ + 1
IR = IR – J2
{А2}
Пусть переменные перед выполнением этого фрагмента программы имели значения J1n, J2n, IQn и IRn. Таким образом, J1n=IQn·J2n + IRn и 0 £ IRn L IRn ³ J2n. После выполнения программы переменные примут следующие значения: J1n+1= J1n, J2n+1= J2n, IQn+1= IQn + 1, IRn+1= IRn – J2n,. Нужно показать, что J1n+1=
= IQn+1·J2n+1 + IRn+1 и 0 £ IRn+1. Это легко сделать, подставив в наше высказывание J1n+1, J2n+1, IQn+1 и IRn+1. После подстановки получим
J1n= (IQn + 1)·J2n + (IRn – J2n) = IQn·J2n + J2n + IRn – J2n =
= IQn·J2n + IRn и 0 £ IRn – J2n или J2n £ IRn.
Оба утверждения по нашему предположению должны быть справедливы.
б) Из А2 и Ø(IR ³ J1) следует А3, т. е. из J1= IQ ·J2 + IR L 0 £ IR и Ø(IR ³ J1) следует из J1= IQ ·J2 + IR L 0 £ IR < J1. Это очевидно, так как из J1= IQ ·J2 + IR следует J1= IQ ·J2 + IR, а из 0 £ IR и Ø(IR ³ J1) следует 0 £ IR < J1.
Таким образом, мы доказали:
1) {А1}
IQ = IQ + 1
IR = IR – J2
{А2}
2) {А2}
DО WHILE (IR ³ J1);
IQ = IQ + 1;
IR = IR – J2;
END;
{А3}
и, следовательно, по правилу верификации можно заключить, что требуемое утверждение справедливо:
3) {А1} º {0 £ J1 L 1 £ J2}
IQ = IQ + 1
IR = IR – J2
DО WHILE (IR ³ J1);
IQ = IQ + 1;
IR = IR – J2;
END;
{А3}º { J1= IQ ·J2 + IR L 0 £ IR < J1}
рис. 3.3 |
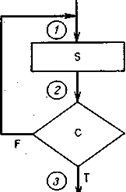
Студент может легко убедиться, что доказательство с помощью правил верификации фактически идентично доказательству, которое можно было бы провести методом индуктивных утверждений.
В качестве упражнения представьте, что в используемом языке программирования есть оператор вида REPEAT S UNTIL С. Этот оператор имеет традиционный для языков программирования смысл: он эквивалентен приведенной на рис. 3.3 блок-схеме. Сформулируйте правило верификации для доказательства справедливости
{А1} REPEAT S UNTIL С{А2}.
Глава 4. ДОКАЗАТЕЛЬСТВО ПРАВИЛЬНОСТИ
РЕКУРСИВНЫХ ПРОГРАММ
Во многих языках программирования разрешается писать рекурсивные программы, т. е. программы, в которых при вычислениях допускается обращение (рекурсивное) к самой себе аналогично тому, как обычная, нерекурсивная программа обращается к некоторой подпрограмме. Рекурсивные программы особенно удобны в тех случаях, когда речь идет о данных, структура которых определяется рекурсивно (например, списки или деревья). В языке Лисп, созданном специально для «нечисленных» вычислений на основе списков, понятие рекурсии является фундаментальным. В этой главе описаны методы, которые полезны при доказательстве правильности рекурсивных программ. Основной метод в таких доказательствах называется методом структурной индукции. Доказательство методом структурной индукции представляет собой доказательство с помощью математической индукции, но индукция осуществляется по структуре данных, с которыми работает программа.
Если студент незнаком с понятием рекурсии, он все равно сможет понимать излагаемый здесь материал. Мы не будем пользоваться каким-нибудь стандартным рекурсивным языком программирования, например Алголом или Лиспом, а «изобретем» упрощенный язык, которого нам будет достаточно, чтобы проиллюстрировать понятие рекурсии. В разд. 4.1 введен такой язык, в разд. 4.2 описан метод структурной индукции, а примеры рассмотрены в разд. 4.3. В разд. 4.4 показано, что метод структурной индукции может оказаться полезным и в тех случаях, когда речь идет о нерекурсивных программах. В частности, показано, что метод структурной индукции иногда легче использовать для доказательства правильности, чем метод индуктивных утверждении, если, например, речь идет о нерекурсивных программах, выполняющих рекурсивные по существу процессы, такие, как просмотр деревьев.
4.1. Упрощенный язык программирования
для иллюстрации понятия рекурсии
Упрощенный язык программирования нужен нам, чтобы ознакомить студентов с понятием рекурсии. Если студент знаком с рекурсией в каком-либо из существующих языков программирования, ему будет очень просто сопоставить наш упрощенный язык с соответствующими возможностями в этих реальных языках. Однако, если вы даже и незнакомы с понятием рекурсии из существующих языков, это не помешает вам понять содержание данного раздела.
Программа в нашем упрощенном языке программирования состоит из определения функции, заданного в виде
F(Х1, ... , ХN) º IF проверка 1 THEN выражение 1
ELSE IF проверка 2 THEN выражение 2
.
:
ELSE IF проверка m THEN выражение m
ELSE OTHERWISE выражение m + 1
Такая программа вычисляет значение F(Х1,... , ХN). Сначала выполняется проверка 1. Если проверка 1 дает ответ «истина», то значение функции есть значение выражения 1. Если проверка 1 дает ответ «ложь», то выполняется проверка 2. Если эта проверка дает ответ «истина», то значение функции есть значение выражения 2. Процесс идет таким образом до тех пор, пока не будет обнаружена первая из проверок (i-я), дающая значение «истина». Значение функции в этом случае есть значение выражения i. Если ни одна из проверок не окажется положительной, то значение функции есть значение выражения m + 1. Рекурсия вводится в этот язык программирования следующим образом: функция F, определяемая в нашей программе, может входить как часть в любое из выражений или проверок в программе. Такое появление F называется рекурсивным обращением к этой функции. Для каждой такой рекурсивной программы нужно еще указать, для каких значений аргументов X1, ... , ХN применима программа, т. е. нужно задать область определения функции. Выполнение программы заключается в применении ее к некоторым конкретным данным из ее области определения.
Пример 4.1. Рассмотрим рекурсивную программу, определенную для любого положительного целого числа X:
F(Х) º IF Х = 1 THEN 1
ELSE OTHERWISE X•F(Х–1)
Чтобы понять, как работает такая программа, выполним ее для некоторого конкретного значения аргумента X. Например,
F(4) = 4 • F(3) [Так как условие 4 = 1 ложно, то F(4)=4•F(3).
Теперь нужно вычислить F(3), т. е. рекурсивно
обратиться к F.]
= 4 • 3 • F(2) [Т. к. при вычислении F(3) условие 3=1 ложно,
то F(3) = 3•F(2).]
= 4 • 3 • 2 • F(1) [Так как условие 2 = 1 ложно, то F(2) = 2•F(1).]
= 4 • 3 • 2 • 1 [Так как условие 1 = 1 истинно, то F(1) = 1.]
= 24 = 4 !
В разд. 4.2 мы докажем, что F(Х) = Х! для любого положительного целого числа X.
Пример 4.2. Рассмотрим следующую рекурсивную функцию (функцию Аккермана), применимую для любой пары неотрицательных целых чисел X1, Х2:
А(Х1, Х2) º IF X1 = 0 THEN Х2 + 1
ELSE IF Х2=0 THEN А(Х1–1, 1)
ELSE OTHERWISE А(Х1–1, А(Х1, Х2–1))
Проследим, как выполняется такая программа для некоторой пары X1 и Х2. Например,
А(1, 2) = А(0, А(1, 1)) [Так как условия X1 = 0 и Х2 = 0
ложны, необходимо вычислять А(1, 1) –
рекурсивное обращение.]
= А(0, А(0, А(1, 0))) [Так как условия X1 = 0 и Х2 = 0 ложны,
нужно вычислять А(1, 0).]
= А(0, А(0, А(0, 1))) [Так как условие X1 = 0 ложно,
а Х2 = 0 истинно.]
= А(0, А(0, 2)) [Так как X1 = 0 истинно,
следовательно, А(0, 1) = 1 + 1 = 2.]
= А(0, 3) [Так как X1 =0 истинно, следовательно,
А(0, 2) = 2 + 1 = 3.]
= 4 [Так как X1 = 0 истинно, следовательно,
А(0, 3) = 3 + 1=4.]
Из этого примера следует, что при выполнении вычислений для рекурсивной программы мы можем сталкиваться с неоднозначностями, которые требуют уточнений. Например, в приведенных вычислениях при обращении А(0, А(1, 1)) мы предполагаем, что А(1, 1) должно быть вычислено прежде, чем мы продолжим вычисления, относящиеся к внешнему обращению к А. Если отдать предпочтение вычислениям, связанным с внешним обращением, то вычисления должны были бы идти в следующем порядке:
А(1, 2) = А(0, А(1, 1)) = А(1, 1) + 1 = А(0, А(1, 0)) + 1 =
= (А(1, 0) + 1) + 1 = (А(0, 1) + 1) + 1 = (2 + 1) + 1=4.
Значение А(1, 2) остается тем же, хотя последовательность вычислений отлична от предыдущей. Можно доказать, что если к одним и тем же аргументам некоторой рекурсивной функции применять две различные последовательности ее вычисления, то результат будет одним и тем же при условии конечности этих последовательностей. Однако вполне возможно, что одна последовательность не будет заканчиваться, хотя другая последовательность закончится. Рассмотрим следующий пример.
Пример 4.3. Возьмем рекурсивную программу, применимую к любой паре неотрицательных целых X1, Х2:
F(Х1, Х2) º IF X1 =0 ТНЕN 0
ELSE OTHERWISE F(0, F(Х1, Х2))
Проследим за вычислением F(1, 1), используя два различных правила вычислений. По первому правилу мы будем стараться сначала заканчивать вычисления, относящиеся к внешнему обращению. По второму правилу мы будем отдавать предпочтение самому внутреннему обращению:
1) F(1, 1) = F(0, F(1, 1)) [Так как условие X1 = 0 ложно.]
= 0 [Так как условие X1 = 0 истинно
для внешнего обращения к F.]
2) F(1, 1) = F(0, F(1, 1)) [Так как условие X1 = 0 ложно.]
= F(0, F(0, F(1, 1))) [Так как условие X1 = 0 для
внутреннего обращения ложно.]
= F(0, F(0, F(0, F(1, 1)))) =
= F(0, F(0, F(0, F(0, F(1,1))))) и т. д.
Таким образом, в первом случае последовательность вычислений F(1, 1) конечна и F(1, 1) = 0. Во втором случае вычисления не заканчиваются и, следовательно, значение F(1, 1) не определено. Однако отметим, что если для каких-либо аргументов в обоих случаях вычисления заканчиваются, то результат будет одним и тем же. Например, F(0, М) = 0 независимо от применяемых правил вычислений.
Итак, чтобы сделать наш язык программирования точным, нам нужно задать правила вычислений для программ, определяющие последовательность вычислений. В данной главе мы будем считать, что правило вычислений отдает предпочтение самому левому и самому внутреннему обращению. Другими словами, в любой из моментов вычислений первым начинает вычисляться левое и внутреннее обращение (для простоты далее везде будем опускать слово «самое») к функции F, все аргументы которой уже не содержат F. Это правило – не обязательно наилучшее, иногда оно может приводить к неоканчивающейся последовательности вычислений, хотя другое правило дало бы конечную последовательность (пример 4.3). Однако во многих существующих языках программирования используется правило вычислений, подобное описанному выше. Кроме того, как мы уже отмечали, если, следуя этому правилу, вычисления заканчиваются, то результат будет тем же, что и при других правилах, приводящих к окончанию. Большинство рассматриваемых нами программ заканчивается при любых значениях аргументов независимо от того, какие правила вычислений мы используем, а следовательно, и результат в любых случаях будет одинаковым. Однако для определенности все же будем считать, что предпочтение отдается левому внутреннему обращению.
Многие из приводимых в этой главе примеров относятся к работе со списками. В таких программах мы используем некоторое подобие «лисповской» нотации. По этой нотации список – набор объектов, отделенных друг от друга пробелами и заключенных в квадратные скобки [ ]. Объектами, входящими в такие списки, являются атомы или другие списки. Атом – строка буквенно-цифровых символов, не содержащая пробелов. Мы будем считать, что атомы должны начинаться с одной из букв А, В, С, D или F, а переменные – с букв, отличных от этих букв. Такой прием позволяет нам при написании программ различать переменные и атомы и обходиться без более общей функции Quote, используемой в Лиспе. Например, [А В С] – список из трех элементов, каждый из которых есть атом; [А [В А [С]] В С] – список, в котором (на верхнем уровне) четыре элемента. Второй элемент – сам список [В А [С]]. Третий элемент этого списка – опять список [С]. Для пустого списка, т. е. списка, не содержащего ни одного элемента, мы выделяем специальное имя NIL. Кроме того, мы будем использовать следующие проверки и функции:
1. Проверка = может применяться как к спискам, так и к числам. Например, проверка [А В] = [А В] истинна, а проверки [А В] = [В А], [А В] = [А [В]], В = А, А = NIL ложны.
2. Проверка АТОМ (X) применима к любым объектам, будь то атомы или списки. АТОМ (X) дает значение TRUE (истина), если X – атом или пустой список. Если X – непустой список, то
АТОМ (X) дает значение FALSE (ложь).
3. Функция CAR (L) применима к любому непустому списку. В качестве результата выступает первый (на верхнем уровне) элемент этого списка. Примеры:
CAR ( [А В С] ) дает А.
CAR ( [[А В] С] ) дает [А В].
CAR (NIL) не определено.
CAR (А) не определено.
4. Функцию CDR(L) можно применять к любому непустому списку. Результатом является список, полученный из L путем отбрасывания первого его элемента (на верхнем уровне). Примеры:
CDR ( [А В С] ) дает [В С].
CDR ( [[А В] С] ) дает [С].
CDR ( [В] ) дает NIL (или [ ] ).
CDR (NIL) не определено.
CDR (А) не определено.
5. Функцию CONS(Х, L) можно применять к любому списку L и любому X, будь то атом или список. В результате получается новый список: первый его элемент есть X, а потом идут элементе списка L. Примеры:
CONS ( А, [В С] ) дает [А В С].
CONS ( [А В], [В [С]] ) дает [[А В] В [С]].
CONS (А, NIL) дает [А].
CONS (А, В) не определено.
В некоторых из наших примеров мы будем использовать и специальные атомы ТRUЕ и FALSE.
Пример 4.4. Как пример использования новой нотации приведем рекурсивную программу, определяющую, является ли X элементом списка L (на верхнем уровне):
МЕМВЕR (Х, L) º IF L = NIL ТНЕN FALSE
ЕLSЕ IF Х = САR (L) ТНЕN TRUE
ЕLSЕ ОТНЕRWISЕ МЕМВЕR (X, CDR (L))
Проследим, как идет процесс вычислений по такой программе для фактических аргументов С и [А В С D]:
МЕМВЕR (С, [А В С D] ) = МЕМВЕR (С, [В С D] )
= МЕМВЕR (С, [С В] )
= TRUЕ
Теперь проследим, как проходит вычисление при фактических аргументах С и [А В [С D]]:
МЕМВЕR (С, [А В [С D]]) = МЕМВЕR (С, [В [С D]] )
= МЕМВЕR (С, [[С В]] )
= МЕМВЕR (С, NIL)
= FALSE
Пример 4.5. Напишем рекурсивную программу, добавляющую список L1 к списку L2, другими словами, в этом списке, состоящем из двух, элементы первого стоят перед элементами второго:
APPEND (L1, L2) º IF L1 = NIL ТНЕN L2
ЕLSЕ OTHERWISE CONS (CAR (L1),
АРРЕND (CDR(L1), L2))
Проследим, как идет процесс вычислений при нескольких различных парах аргументов:
АРРЕND ([А В], [С D]) =
= CONS (САR ([А В]), АРРЕND (CDR ([А В]), [С D])))
= СОNS (А, АРРЕND ([В], [С D] ))
= СОNS (А, СОNS (CAR ([В]), АРРЕND (CDR([В]), [С D])))
= CONS (А, СОNS (В, АРРЕND (NIL, [С D] )))
= СОNS (А, СОNS (В, [С, D]))
= СОNS (А, [В С D])
= [А В С D]
АРРЕND ([[А]], [В С] ) = СОNS ([А], АРРЕND (NIL, [В С])
= СОNS ([А], [В С])
= [[А] В С]
АРРЕND([А В], NIL) = СОNS (А, АРРЕND ([В], NIL))
= СОNS (А, СОNS (В, АРРЕND (NIL, NIL)))
= СОNS (А, СОNS ( [В] )
= СОNS (А, [В] )
= [А В]
В качестве упражнения проследите, как проходит процесс вычисления функции Аккермана (программа приведена в примере 4.2) при следующих аргументах а) А(1,1); б) А(2,1).
4.2. Структурная индукция
Рекурсивные программы обычно строятся по следующей схеме: сначала в них явно определяется способ вычисления результата для наипростейших значений аргументов рекурсивной функции, затем способ вычисления результата для аргументов более сложного вида, причем используется сведение к вычислениям с данными более простого вида (с аргументами рекурсивного обращения к той же функции). Таким образом, вполне естественно попытаться доказать правильность таких программ следующим образом:
1) доказать, что программа работает правильно для простейших данных (аргументов функции);
2) доказать, что программа работает правильно для более сложных данных (аргументов функции) в предположении, что она работает правильно для более простых данных (аргументов функции).
Такой способ доказательства правильности для рекурсивных функций естествен, поскольку он следует основной схеме вычислений в рекурсивных программах. Студенты уже, конечно, обратили внимание на то, что этапы 1 и 2 фактически являются этапами доказательства с помощью индукции, но индукция осуществляется «по структуре» данных, которые обрабатывает программа. В частности, если можно сопоставить интуитивное понятие более простых данных (допустимых аргументов функции) и более сложных с отношением во вполне упорядоченном множестве значений данных (допустимых аргументов функции), то этапы 1 и 2 будут аналогичны этапам доказательства правильности работы программы для всех допустимых аргументов с помощью метода обобщенной индукции. Предложенный выше способ доказательства правильности назовем доказательством с помощью структурной индукции. Проиллюстрируем этот метод на нескольких очень простых рекурсивных программах.
Пример 4.6. Докажем правильность следующей программы (разд. 4.1, пример 4.1):
F(Х) º IF X = 1 ТНЕN 1
ЕLSЕ ОТНЕRWISЕ X•F(Х – 1)
Предполагается, что эта функция вычисляет факториал от аргумента. Нужно доказать, что F(М) = 1 • 2 • 3 • ... • N = N! для любого положительного числа N. При доказательстве с помощью структурной индукции используем простую индукцию по положительным целым числам:
1) докажем, что F(1)= 1!. Действительно, F(1)= 1=1!;
2) докажем (для любого положительного числа N), что если
F(М) = 1 • 2 • ... • N = N!, то F(N + 1) = 1 • 2 • ... • N • (N + 1) = (N + 1)!. Следовательно, мы предполагаем, что N – положительное число, а F(N) = N! – гипотеза индукции. Так как N положительное число, то проверка N + 1 = 1 дает отрицательный ответ, и, прослеживая далее последовательность вычислений, получаем
F(N + 1) = (N + 1) • F((N + 1) – 1) = (N + 1) • F(N) =
= (N +1) • (N!) = (N +1) • (1 • 2 • ... • N) = 1 • 2 • ... • N • (N +1) = (N +1)!
(По гипотезе
индукции)
что и требовалось доказать, т. е. F(N) = N! для любого положительного числа N.
Пример 4.7. Докажем правильность следующей программы (разд. 4.1, примера 4.4):
МЕМВЕR (Х, L) º IF L = NIL THEN FALSЕ
ЕLSЕ IF Х = CAR(L) ТНЕN TRUE
ЕLSЕ ОТНЕRWISЕ МЕМВЕR (X, CDR(L))
Эта программа применима для любого элемента X и любого списка L. Предполагается, что она дает значение ТRUЕ, если X входит в качестве элемента верхнего уровня в список L; в противном же случае она дает значение FALSЕ:
МЕМВЕR (Х, L¢) = TRUE, если X элемент списка L¢
= FALSЕ в других случаях.
Для доказательства правильности работы этой программы используем структурную индукцию. Анализ программы показывает, что при рекурсивном обращении к МЕМВЕR из третьей строки программы только второй аргумент обращения выглядит проще, чем ранее. Таким образом, естественно вести индукцию только по второму аргументу функции. При рекурсивном обращении к МЕМВЕR ее второй аргумент CDR (L) представляет собой список, который содержит на один элемент (на верхнем уровне) меньше, чем список L. Следовательно, в структурной индукции можно использовать простую индукцию по числу элементов в списке L. Так как это число всегда неотрицательно, то доказательство основывается на простой индукции по неотрицательным целым числам. Итак, нужно:
1) доказать, что для любого списка, содержащего нуль элементов, МЕМВЕR работает правильно. Поскольку список, имеющий нуль элементов, это просто пустой список NIL, то очевидно, что МЕМВЕR (Х, NIL) = FALSЕ, так как X не есть элемент списка NIL;
2) доказать (для любого целого числа N), что если программа МЕМВЕR правильно работает для всех списков L¢, содержащих N элементов (на верхнем уровне), то она будет правильно работать и для всех списков L, содержащих на верхнем уровне (N + 1) элементов. Поэтому предположим, что МЕМВЕR правильно работает для списков L¢ длиной N, т. е.
МЕМВЕR (Х, L¢) = TRUE если X есть элемент из L¢,
= FALSЕ в других случаях.
Это гипотеза индукции. Предположим, что L есть список, содержащий (N + 1) элементов. Поскольку (N + 1) ³ 1, то L ¹ NIL. Прослеживая выполнение функции, видим, что
МЕМВЕR (Х, L) = TRUE если X = CAR (L),
= МЕМВЕR (Х, CDR (L)) в других случаях.
Если X = CAR(L) (а мы знаем, что CAR(L) определено, так как L¹NIL), то X – элемент списка L, и, следовательно, значение TRUЕ есть именно то значение, которое требуется. Если Х ¹ CAR (L), то X будет элементом списка L, если и только если X будет элементом CDR (L). (Функция CDR (L) определена, так как L ¹ NIL.) Однако CDR (L) представляет собой список из N элементов, и по гипотезе индукции следует, что МЕМВЕR (Х, СDR (L)) будет правильно вычислять значение TRUE или FALSЕ в зависимости от того, является ли X элементом CDR (L) или нет. Таким образом, если Х ¹ CDR (L), то МЕМВЕR (Х, L) = МЕМВЕR (Х, CDR (L)), а последняя функция вычисляет значение либо TRUЕ, либо FALSЕ в зависимости от того, будет ли X элементом CDR (L), а следовательно, элементом списка L или нет, что и требовалось доказать.
Пример 4.8. Докажем правильность следующей рекурсивной программы (разд. 4.1, пример 4.5):
АРРЕND (L1, L2) º IF L1 = NIL ТНЕN L2
ЕLSЕ ОТНЕRWISE СONS (CAR (L1),
АРРЕND (CDR (L1, L2))
Предполагается, что программа применима к любым двум спискам L1 и L2 и в качестве результата дает список, состоящий из элементов списка L1, за которым следуют элементы списка L2. Анализ программы показывает, что при рекурсивном обращении к АРРЕND только первый из ее двух аргументов выглядит проще, чем ранее. Таким образом, при доказательстве методом структурной индукции используем простую индукцию по длине (числу элементов) списка L1. Для этого необходимо:
1. Доказать правильность работы АРРЕND для любого списка L1 длиной 0. Список длиной нуль – пустой список NIL. Утверждение АРРЕND (NIL, L2) = L2 правильно, так как это список, составленный из элементов списка L1 (а он пустой), за которыми следуют элементы списка L2.
2. Доказать для любых неотрицательных целых чисел N, что если АРРЕND правильно работает для любых списков L1¢ длиной N, то АРРЕND будет правильно работать и для всех списков L1 длиной (N + 1). Предположим, что АРРЕND для всех списков L1¢ длиной N работает правильно, т. е. АРРЕND (L1¢, L2) есть список, составленный из элементов L1¢, за которыми следуют элементы списка L2. (Это гипотеза индукции.) Предположим, что длина списка L1 равна (N + 1). Так как (N +1) ³ 1, то L1 ¹ NIL. Прослеживая вычисление функции, мы видим, что
АРРЕND(L1, L2) = CONS (CAR (L1), АРРЕND (CDR (L1), L2))
(Известно, что CAR (L1 и CDR (L1) определены, ибо L1 ¹ NIL.) Однако CDR (L1) – список длиной N, и из гипотезы индукции следует, что АРРЕND (CDR (L1), L2) есть список, состоящий из элементов CDR (L1) и элементов списка L2. Таким образом, список АРРЕND (CDR (L1), L2) содержит все элементы списка L1, кроме первого, за которыми идут все элементы списка L2. Кроме того, так как СОNS (CAR (L1), АРРЕND (CDR (L1), L2)) образует список, у которого первый элемент CAR (L1), а затем следуют элементы списка АРРЕND (CDR (L1), L2), то очевидно, что этот список состоит из всех элементов списка L1 (включая и первый элемент CAR (L1)) и всех элементов списка L2. Следовательно, в этом случае функция АРРЕND работает правильно, что и требовалось доказать.
Замечание
В начале раздела мы уже говорили о том, что если можно было бы сопоставить наше интуитивное представление о простоте данных (допустимых аргументов функции) с некоторым вполне упорядочивающим отношением < на множестве значений данных, то доказательство правильности для рекурсивных программ можно было бы проверить методом обобщенной индукции по этим данным. Отметим, что в примере 4.6 мы проводили доказательство именно этим методом, поскольку данными этой функции были целые числа, а обычное отношение < вполне упорядочивает соответствующие значения. В примерах же 4.7 и 4.8 такого отношения <, определенного на множестве значений данных для наших программ (это были списки), уже не было. Вместо него мы использовали тот факт, что вполне упорядоченным было множество некоторых свойств значений данных, а именно длины. Длина любого списка – неотрицательное целое число, а обычное отношение < вполне упорядочивает множество неотрицательных целых чисел. Если мы хотим определить отношение < не на множестве некоторого из свойств данных, а на самих данных (в нашем случае списках), то это можно сделать следующим образом: будем говорить, что L1 < L2, если и только если длина L1< длины L2. К несчастью, для вполне упорядочивающего порядка этого недостаточно, так как отношение < определяет лишь частичный, а не общий порядок. Например, при L1 = [А В С] и L2 = [D Е F] мы не можем сказать, что L1 < L2, или L2 < L1, или L1 = L2. Другими словами, существуют данные (списки одинакового размера), не сравнимые между собой, и, следовательно, порядок, заданный отношением <, не является общим. Таким образом, наше множество не будет вполне упорядоченным; иногда такие множества называют обоснованно упорядоченными (well-founded). Оказывается, что существования обоснованного порядка (который более общий, чем вполне упорядочивающий) достаточно для проведения доказательства по индукции. Таким образом, в примерах 4.7 и 4.8 доказательство можно было бы проводить с помощью обобщенной индукции по данным, упорядоченным на основе обоснованного порядка. Обоснованный порядок < можно было бы и превратить во вполне упорядочивающий, если списки равной длины считать не несравнимыми, а равными; но это уже несколько неуклюжий прием. Далее мы будем продолжать проводить индукцию на множестве некоторых свойств данных (таких, как длина) и не беспокоиться по поводу формального определения типа существующего порядка.
В качестве упражнений решите следующие задачи:
а) рассмотрите следующую рекурсивную программу, применимую для любого положительного целого числа N:
F(N) º IF N = 1 ТНЕN 1
ЕLSЕ ОТНЕRWISЕ F(N – 1) + N,
и докажите, что F(N) = (N • (N + 1) )/2 при любом положительном целом N;
б) рассмотрите рекурсивную программу, применимую для любых неотрицательных целых чисел N:
F(N) = IF N = 0 ТНЕN 1
ЕLSЕ ОТНЕRWISЕ 2 • F(N – 1),
выведите формулу для вычисляемой функции F(N) и докажите ее правильность.
4.3. Структурная индукция для нерекурсивных программ
В первой части учебного пособия для доказательства правильности нерекурсивных (итеративных) программ был введен метод индуктивных утверждений. Однако если нерекурсивная программа фактически выполняет рекурсивный процесс, то при доказательстве ее правильности иногда легче использовать метод структурной индукции, а не метод индуктивных утверждений. В этом разделе мы рассмотрим пример, иллюстрирующий подобный случай.
Пример 4.9. Мы хотим доказать, что если выполнять программу, блок-схема которой приведена на рис. 4.1, с TREE, представляющим собой указатель на корневую вершину некоторого двоичного дерева (TREE = L, если дерево пустое), то в конце концов выполнение ее закончится, причем будут просмотрены в некотором порядке все вершины этого дерева. (Для ознакомления с используемой в блок-схеме нотацией и алгоритмами просмотра двоичных деревьев см. стр. 394-398 в книге Д Кнута «Искусство программирования для ЭВМ», том 1, изд-во «Мир», 1976.) Просмотр идет следующим образом: для каждой вершины дерева просматриваются одним и тем же способом все вершины левого поддерева, выходящего из данного, затем сама исходная вершина, а затем в том же порядке все вершины правого поддерева. Наша программа фактически реализует некоторый рекурсивный процесс, и ее можно было бы легко написать в «рекурсивной форме». В нашей же нерекурсивной версии алгоритм основан на использовании явного стека. Мы могли бы доказать, что программа правильна, и методом индуктивных утверждений (студенты могут проделать это самостоятельно в качестве упражнения), однако рекурсивность самого процесса приводит к предположению, что это доказательство удобнее провести с помощью структурной индукции. Сначала докажем, что справедливо утверждение, связанное в блок-схеме с точкой 2. При доказательстве используется структурна, индукция по размеру (числу вершин) дерева, на которое указывает Р. Для этого необходимо:
1. Доказать, что если размер дерева, на которое указывает Р, равен нулю, то утверждение справедливо. Но если размер дерева, задаваемого Р, равен нулю, то наше утверждение тривиально, ибо мы попадаем в точку 2 с пустым деревом, которое можно считать уже просмотренным в соответствующем порядке (ведь просматривать нечего), причем Р = L, а SТАСK остался без изменений.
2. Доказать (для всех n > 0), что если наше утверждение верно для всех деревьев размером меньше n (гипотеза индукции), то оно также справедливо и для дерева размером n. Предположим, что мы находимся в точке 2 и Р = Р0 = L, затем переходим из точки 2 через точки 3, 4 вновь в точку 2.
рис. 4.1 |
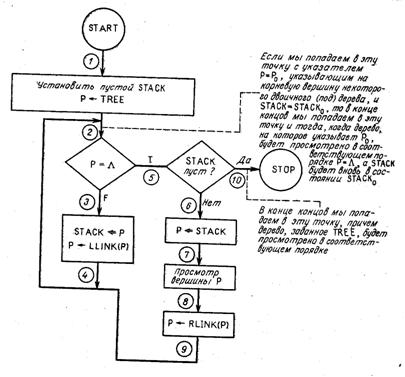
При возвращении в точку 2 Р указывает на левое поддерево первоначального дерева, на которое указывало Р (т. е. Р = LLINK(Р0)), а SТАСК в состоянии 5ТАСК0,Р0 (т. е. значение Р0 уже помещено в вершину стека). Так как размер дерева, на которое теперь указывает Р, меньше n, то мы знаем (по гипотезе индукции), что если мы когда-нибудь вернемся в точку 2, то это левое поддерево уже будет просмотрено в соответствующем порядке и, кроме того, Р = L, а SТАСК опять будет в состоянии SТАСК0,Р0. Так как Р = L, пройдем по пути из точки 2 через точки 6, 7, 8 вновь в точку 2. Вернувшись в точку 2, будем иметь Р = PLINK(Р0), а SТАСК – в состоянии SТАСК0. Исходная вершина будет уже просмотрена. Таким образом, уже будут просмотрены в соответствующем порядке вершины левого поддерева и корень (исходная вершина) дерева. Указатель Р теперь будет «смотреть» на правое поддерево; оно меньше дерева, на которое указывал Р0. Опять можно использовать гипотезу индукции и сделать заключение, что, если в конце концов мы вернемся в эту точку, дерево, на которое указывает Р, будет просмотрено (это правое поддерево исходного дерева), Р = L и SТАСК будет в состоянии SТАСК0. В этот момент оказывается, что мы просмотрели левое поддерево, корневую вершину и правое поддерево. Но из этого следует, что мы в соответствующем порядке просмотрели все исходное дерево. Причем Р = L, а SТАСК – в состоянии SТАСК0, что и требовалось доказать.
Изложенное доказательство легко приводит нас и к доказательству правильности, так как при первом попадании в точку 2 (из точки 1) Р = ТRЕЕ, а SТАСК пуст. Только что доказанное утверждение, связанное с точкой 2, гласит, что при попадании в точку 2 поддерево, на которое указывал Р, будет уже надлежащим образом просмотрено и SТАСК будет в исходном состоянии (пуст), а Р = L. В этот момент, так как Р = L, мы попадем в точку 5, так как SТАСК пуст, далее – в точку 10; это и показывает справедливость утверждения о правильности, связанного с точкой 10.
В общем случае, интересно сравнить для нерекурсивных (итеративных) программ доказательство методом индуктивных утверждений с доказательством методом структурной индукции. Доказательства методом индуктивных утверждений фактически являются доказательством с помощью индукции по числу попаданий (в цикле) в некоторую точку программы. Доказательства с помощью структурной индукции также являются доказательствами по индукции, но индукция проводится по структуре данных, с которыми работает программа. Безусловно, именно структура данных определяет, сколько раз мы попадем в различные точки программы, и поэтому оба метода имеют очень много общего. Причем оказывается, что если программа по природе рекурсивна, то структуру данных очень просто использовать для выяснения процесса выполнения программы, и поэтому доказательство обычно легче проводить с помощью структурной индукции, а не индуктивных утверждений. Основная трудность в любом из методов – выбор правильных утверждений, которые связываются с точками в циклах программы, причем для разных методов эти утверждения различаются лишь в одном: индуктивные утверждения не должны содержать какой-либо информации об окончании работы, а утверждения для структурной индукции должны содержать информацию как о частичной правильности, так и об окончании.
Глава 5. СОВРЕМЕННЫЕ ИССЛЕДОВАНИЯ, СВЯЗАННЫЕ С ДОКАЗАТЕЛЬСТВОМ ПРАВИЛЬНОСТИ ПРОГРАММ
В настоящее время в области доказательства правильности программ проводятся интенсивные исследования. Для простоты обсуждения выделим среди этих исследований три основных направления:
1. Методы доказательства (частичной) правильности или конечности.
2. Проблемы разработок программ и создания языков программирования.
3. Механизация процесса доказательства правильности.
Эти направления перекрываются, и мы их рассматриваем не для того, чтобы уточнить области исследований, а просто как некоторое средство организации обсуждения. Само обсуждение будет очень кратким: мы попытаемся лишь выявить характер исследований в данном направлении и отметить некоторых из специалистов, которые работают в этих направлениях. Более подробно студенты могут ознакомления с тем или иным направлением исследований, работая самостоятельно.
5.1. Методы доказательства
В наших учебных пособиях (и в курсе теории вычислительных процессов) мы сконцентрировали внимание на двух основных методах: методе индуктивных утверждений и структурной индукции. Метод индуктивных утверждений впервые был предложен Флойдом и Науром. Барстелл в 1969 г. предложил метод структурной индукции. В главе 2 очень кратко рассмотрены понятия, относящиеся к правилам верификации и аксиомам для доказательства частичной правильности. Этот метод, впервые предложил Хоар.
Существуют и другие методы доказательства правильности программ. Различные методы доказательства полной правильности итеративных программ приводятся в работах Базу, Бурсталла, Дейкстры, Манны и др. В работе Бурсталла рассмотрен алгебраический подход к доказательству правильности. В работах Бурсталла и Вегбрейта обсуждаются методы доказательства правильности программ, использующих сложные структуры или модифицирующие структуру данных. В работах Манны показано, как можно использовать метод индуктивных утверждений для доказательства правильности недетерминированных программ. В работах Ашкрофта, Келлера, Липтона рассматриваются методы доказательства правильности параллельных программ.
Такой метод доказательства, как метод индуктивных утверждений, где речь идет лишь о доказательстве частичной правильности, требует отдельного доказательства конечности итеративных программ. Флойд и Манна использовали вполне упорядоченные (или частично упорядоченные) множества для доказательства конечности. В работе Манны проведено сравнение различных методов доказательства конечности. В работе Сайтеса описаны методы доказательства «чистого» окончания программ.
Для доказательства правильности рекурсивных программ было предложено много индуктивных методов. В работах Маккарти, Морриса и Парка предлагаются индуктивные методы, в которых индукция ведется по уровню рекурсии. Эти методы отличаются от доказательства методом структурной индукции, описанного в нашей книге, где индукция ведется по структуре данных, с которыми работает программа. В работе Манны, Леса и Виллемина проведено сравнение многих из предложенных индуктивных методов доказательства правильности рекурсивных программ.
В работе Манны «Математическая теория вычислений» дается некоторый формальный подход ко многим известным методам доказательства правильности программ. Рассмотрены методы доказательства правильности и конечности для итеративных и рекурсивных программ.
5.2. Конструирование программ и языков
Желание создавать программы, для которых было бы легко удостовериться в их правильности, привлекло внимание к проблеме конструирования программ и разработки языков программирования. Работа «Конструктивный подход к проблеме правильности программ» была одной из первых работ, относящихся к проблемам конструирования программ и доказательству их правильности. Другая его работа «Программирование без Goto» также была одной из первых, где вопросы разработки языка связывались с проблемами правильности (речь шла об исключении операторов перехода). Эти же проблемы обсуждались и в других его работах.
Большинство последних работ, где проблемы построения программ связываются с проблемами их правильности, посвящены структурному программированию. Основное внимание в них уделяется таким методам создания программ, которые позволяли бы программисту следить (неформально убеждаться) за правильностью программы на всех этапах процесса программирования. Этой теме посвящены работы Дейкстры и Хоара «структурное программирование», а также работа Макхована и Келли «Стратегии структурного программирования «сверху вниз» и «снизу вверх». Вирт в книге «Системное программирование: введение» написал введение в программирование, где он так же рассматривает структурное программирование и проблемы доказательства правильности. В работе Хоара «Доказательство правильности структурированных программ» приводится детальное доказательство правильности для одной структурированной программы. Миллс («Новые пути компьютерного программирования» и «Как написать правильную программу и доказать это») и Бакер («Структурное программирование в создании программного обеспечения») рекомендуют использовать структурное программирование при создании программного обеспечения. Проблемы структурного программирования и использования оператора перехода рассматриваются и в работе Кнута «Структурное программирование с оператором go to».
После знаменитого письма Дейкстры об операторе перехода (GO ТО) появились работы, где прослеживается влияние проблемы доказательства правильности на разработку языка программирования. Среди языков, в которых проявилось влияние вопросов доказательства правильности, следует отметить такие языки, как Паскаль, А1рharh, Сlu, Nucleus. В работе Хоара «Процедуры и параметры: аксиоматический подход» обсуждаются возможные ограничения на процедуры и параметры, которые могли бы облегчить доказательство правильности. Морисс «Верификационно-ориентированные языки программирования» рассматривает язык, ориентированный на верификацию. Кларк в своей работе обсуждает конструкции языка программирования, для которых невозможно получить хорошую систему аксиом, подобную введенной Хоаром. Он показывает, что в языке могут присутствовать некоторые такие общие свойства, при которых будет невозможно построить логичную и полную систему аксиом, как это было сделано Хоаром. Кларк предлагает такие свойства либо как-то видоизменить, либо вообще исключить из языка для облегчения доказательства правильности.
Книга Дейкстры «Дисциплина программирования» посвящена методам доказательства правильности и конструированию программ и языков. В ней вводится новый формализм для проведения доказательства правильности и новый минимальный язык, на котором написаны все примеры программ в книге. Этот язык специально создавался для того, чтобы ограничить программирование очень простыми, но «мощными» конструкциями, приспособленными в то же время и для методов верификации, использованных в работе. Основное содержание книги – программы, для которых автор очень подробно разбирает вопросы их создания и доказательства правильности.
5.3. Механизация процесса доказательства правильности
Целью многих исследований в области доказательства правильности программ является формализация и в конце концов механизация таких доказательств. Если можно будет создать работающую систему механической верификации, то это сыграет важную роль в вычислительной технике. Хотя неформальное доказательство правильности, подобное тому, о котором шла речь в наших учебных пособиях, и является полезным, но ведь здесь возможны и ошибки. Хорошо было бы иметь некоторую механическую систему верификации, которая либо помогала проводить доказательство правильности в интерактивном режиме, либо работала как непогрешимый контролер для доказательств. На каком из этих направлений будет достигнут успех – пока неясно. Однако сейчас уже предпринимаются первые попытки построить такие системы.
Если мы хотим использовать механическую систему верификации при проведении доказательства правильности, то нужно каким-то образом формализовать и индуктивные утверждения, и сами доказательства. Чаще всего для формализации используется исчисление предикатов первого порядка, хотя такой способ не всегда пригоден для выражения некоторых утверждений и для доказательств. В работах Бурсталла и Манны есть примеры формализованных доказательств правильности на основе нотации исчисления предикатов первого порядка. В работе Лискова и Зиллеса «Программирование с абстрактными типами данных» исследуются различные методы спецификации, которые можно было бы использовать для формальной записи индуктивных утверждений.
Большинство уже построенных систем механической верификации основывается на методе индуктивных утверждений. Такие системы в качестве входных данных рассматривают исходную программу, которую нужно верифицировать, и вместе с ней сформулированные программистом индуктивные утверждения. Основываясь на «заложенных в ней знаниях» синтаксиса и семантики языка программирования, система прослеживает все пути, по которым может идти выполнение программы, и формирует множество условий верификации, которые должны обеспечить верификацию всей программы. В главе 2 мы уже показали, как можно формировать такие формализованные условия верификации: для этого используются программы алгебраических и логических упрощений и «доказыватель» (программа) теорем исчисления предикатов первого порядка. Из-за того что программа, доказывающая механически теоремы, скорее всего будет при некоторых доказательствах обнаруживать ошибки, системы обычно делаются интерактивными и позволяют пользователю вмешиваться в те части доказательств, где обнаруживаются неточности. Системы механической верификации такого типа описываются в работах Гуда, Кинга, Судзуки и др. Системы механической верификации обсуждаются также в работах Куппера, Лондона, Игараши, Левитта, Вандингера.
Боуер и Мур описывают систему механической верификации для доказательства теорем о программах на Лиспе. Эта система существенно отличается от названных выше систем. Так как она предназначена для доказательства теорем о рекурсивных по определению программах, то в качестве основного метода в ней используется не метод индуктивных утверждений, а метод структурной индукции.
Во всех системах механической верификации, использующих метод индуктивных утверждений, требуется, чтобы индуктивные утверждения задавал пользователь. Было бы очень удобно, если бы система могла сама «задавать» (создавать) некоторые или даже все индуктивные утверждения. В работах Каплейна, Грефа и Вандингера, Германна и Вебгрейта, Манны описываются некоторые эвристические методы, цель которых – механическое формирование индуктивных утверждений. Хотя ни один их этих методов не пригоден для любых программ, но некоторые комбинации таких методов могли бы быть полезными при формировании многих из индуктивных утверждений.
Некоторые идеи и методы систем механической верификации используются в более ограниченных системах, которые создаются для того, чтобы помочь программисту систематически тестировать и отлаживать свою программу. Реализации таких систем описываются в работах Кинга («Корректное доказательство правильности программ», «Подход к программному тестированию»), Элсписа Левитта и Валдингера («Интерактивная система для верификации компьютерных программ».
Литература
1. Доказательство правильности программ. – М.: Мир, 1982.
2. Веретельникова правильности программ: Метод индуктивных утверждений. Конспект лекций. – Новосибирск, Изд-во НГТУ, 2004.
3. Информатика. Теория и практика структурного программирования: Методическая разработка. – Новосибирск, изд-во НГТУ, 1999.
4. Теория и практика структурного программирования. /Пер. с англ., М.: Мир, 1982.
5. Хопкрофт Дж., Нильман Дж. Введение в теорию автоматов, языков и вычислений, 2-е изд. – М.: Изд. дом «Вильямс», 2002.
6. Метод индуктивных утверждений для доказательства правильности программ: Учебное пособие. – Новосибирск, 2002. – В электронном виде.
7. Математическая логика. – М.: Мир, 1973.
8. Язык логики. – М.: Наука, 1969.
ОГЛАВЛЕНИЕ
Глава 1. РАЗЛИЧНЫЕ ВЕРСИИ МАТЕМАТИЧЕСКОЙ ИНДУКЦИИ 3
1.1. Строгая математическая индукции 4
Принцип строгой индукции 4
1.2. Обобщенная индукция 6
Принцип обобщенной индукции 8
Глава 2. ФОРМАЛИЗАЦИЯ ДОКАЗАТЕЛЬСТВА правильности
С ПОМОЩЬЮ ИДУКТИВНЫХ УТВЕРЖДЕНИЙ 9
Глава 3. АКСИОМАТИЧЕСКИЙ ПОДХОД К ДОКАЗАТЕЛЬСТВУ ЧАСТИЧНОЙ ПРАВИЛЬНОСТИ 14
Глава 4. ДОКАЗАТЕЛЬСТВО ПРАВИЛЬНОСТИ РЕКУРСИВНЫХ ПРОГРАММ 21
4.1. Упрощенный язык программирования для иллюстрации
понятия рекурсии 21
4.2. Структурная индукция 28
4.3. Структурная индукция для нерекурсивных программ 34
Глава 5. СОВРЕМЕННЫЕ ИССЛЕДОВАНИЯ, СВЯЗАННЫЕ
С ДОКАЗАТЕЛЬСТВОМ ПРАВИЛЬНОСТИ ПРОГРАММ 37
5.1. Методы доказательства 38
5.2. Конструирование программ и языков 39
5.3. Механизация процесса доказательства правильности 40
Литература 42
