

4. Графическая интерпретация эмпирических данных
Как правило, для графической интерпретации используют гистограмму. Гистограмма иллюстрирует плотность распределения тестовых баллов и позволяет показать соотношение размеров различных групп испытуемых, получивших низкие, средние и высокие баллы. При этом по оси абсцисс откладывается тестовый балл (или процент выполнения заданий теста при большом количестве заданий), высота столбцов соответствует частоте этого балла (или проценту испытуемых, имеющих результат в данном интервале, при большом количестве испытуемых).
На рис.1 приведена гистограмма, соответствующая матрице результатов тестирования, приведенной в табл.1.
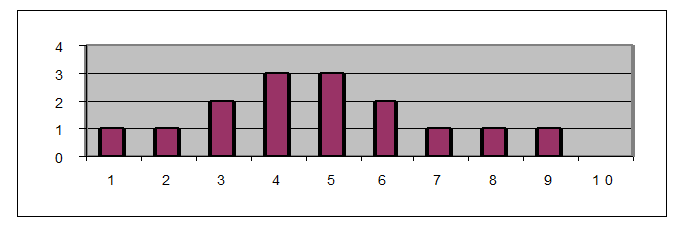
Рис. 1
5. Подсчет средних значений первичных баллов
Среднее значение индивидуальных баллов рассчитывается как среднее арифметическое всех баллов:
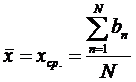 - среднее значение первичных баллов испытуемых,
- среднее значение первичных баллов испытуемых,
Аналогично,
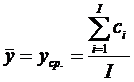 - среднее значение первичных баллов заданий.
- среднее значение первичных баллов заданий.
В рассматриваемом примере имеем:
![]() ;
;
![]() .
.
6. Расчет дисперсии тестовых баллов
Дисперсия (вариация) тестовых баллов характеризует меру рассеивания индивидуальных баллов испытуемых относительно среднего значения x :
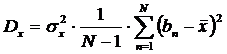
Как следует из формулы, дисперсия выражается в квадратных единицах. Чтобы этого избежать, в качестве меры рассеивания берут среднее квадратическое отклонение – квадратный корень из дисперсии:
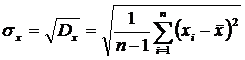
В нашем примере:
D =
Дисперсия играет важную роль в оценке качества теста при нормативно-ориентированной интерпретации. Слабая вариация результатов испытуемых говорит о низком качестве теста, т. к. указывает на низкую дифференциацию испытуемых по уровню подготовки. Излишне высокая дисперсия, характерная для случая, когда все испытуемые отличаются по числу выполненных заданий, также требует переработки теста. Превышение разумных пределов дисперсии приводит к искажению вида распределения, которое начинает существенно отличаться от планируемой теоретической нормальной кривой.
7. Проверка гипотезы о нормальности распределения тестовых баллов
Большинство методов, применяемых для получения характеристик тестовых заданий, относятся к группе параметрических методов математической статистики, для использования которых требуется нормальное распределение эмпирических данных. В хорошо сбалансированном по трудности тесте распределение индивидуальных баллов имеет вид нормальной кривой. Нормальное распределение характеризуется тем, что крайние значения признака в нем встречаются достаточно редко, а значения, близкие к средней величине - достаточно часто.
Наиболее удобна на практике нормированная нормальная кривая со средним значением 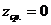 и стандартным отклонением
и стандартным отклонением ![]() . Такая кривая иногда называется единичной кривой (т. к. площадь под кривой равняется 1) (см. график на рис.2). Для совмещения любой нормальной кривой с единичной достаточно выполнить преобразование исходных баллов по формуле:
. Такая кривая иногда называется единичной кривой (т. к. площадь под кривой равняется 1) (см. график на рис.2). Для совмещения любой нормальной кривой с единичной достаточно выполнить преобразование исходных баллов по формуле:
Отметим некоторые свойства нормального распределения:
1) 68 % площади под кривой лежит в пределах одного стандартного отклонения, откладываемого влево и вправо от среднего значения (т. е. ![]() );
);
2) 95 % площади под кривой лежит в пределах двух стандартных отклонений, откладываемых влево и вправо от среднего значения (![]() );
);
3) 99,7 % площади под кривой лежит в пределах трех стандартных отклонений, откладываемых влево и вправо от среднего значения (![]() ).
).
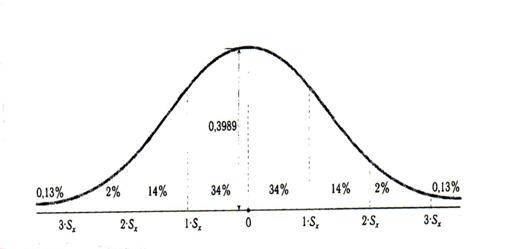
Рис.2
Нормальность распределения можно проверить путем расчета показателей асимметрии и эксцесса и сопоставления их с критическими значениями. Асимметрия оценивает степень отклонения распределения от симметричного распределения, характерного для нормальной кривой. Показатель асимметрии (А) вычисляется по формуле:
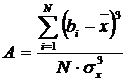 , (1)
, (1)
где все обозначения прежние.
Рассчитаем показатель асимметрии для теста, матрица ответов которого представлена в таблице 1. Имеем:
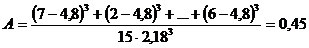 .
.
Для нормального распределения характерна нулевая асимметрия: А=0. Если А>0, то основная часть значений индивидуальных баллов больше среднего значения ![]() , что обычно характерно для излишне легких тестов. И наоборот, отрицательная асимметрия (А<0) встречается в излишне трудных тестах, не сбалансированных правильно по трудности при отборе заданий в тест. На рис.3 представлены кривые распределения с отрицательной, нулевой и положительной асимметрией (слева направо) соответственно.
, что обычно характерно для излишне легких тестов. И наоборот, отрицательная асимметрия (А<0) встречается в излишне трудных тестах, не сбалансированных правильно по трудности при отборе заданий в тест. На рис.3 представлены кривые распределения с отрицательной, нулевой и положительной асимметрией (слева направо) соответственно.
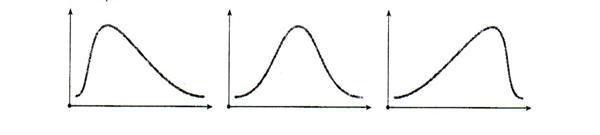
Рис.3
Эксцесс дает представление о том, является ли распределение островершинным или плоским. Показатель эксцесса (Е) вычисляется по формуле:
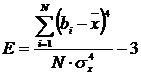 , (2)
, (2)
где все обозначения прежние. Для нормального распределения Е=0. Если кривая распределения – островершинная, то Е>0. Это бывает в тех случаях, когда какие-либо причины способствуют преимущественному появлению индивидуальных баллов, близких к среднему значению. Если же в распределении преобладают крайние значения, причем одновременно и более низкие, и более высокие, то кривая распределения будет плосковершинной и показатель эксцесса Е<0. На рис.4 изображены кривые с положительным, нулевым и отрицательным эксцессом (слева направо) соответственно.

Рис.4
В отдельных случаях при отрицательном эксцессе распределение индивидуальных баллов может быть двувершинным (бимодальным) (рис.5). Такое распределение указывает на то, что по результатам выполнения теста все испытуемые разделились на две группы: одна группа справилась с большинством легких заданий, а другая – с большинством трудных заданий теста. По всей вероятности, в тесте недостаточно представлены задания средней трудности. Необходимо провести коррекцию трудности заданий теста, добавив в него задания средней трудности, позволяющие выровнять распределение баллов.
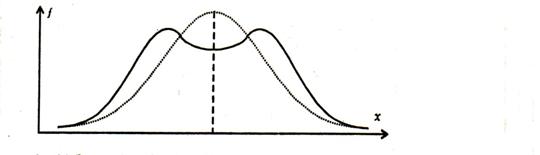
Рис.5
После вычисления значений асимметрии и эксцесса необходимо провести проверку значимости найденных значений с помощью какого-либо из известных критериев. Дело в том, что вычисленные значения асимметрии и эксцесса являются выборочными, т. к. основаны на результатах данной выборки испытуемых. Выборочные значения асимметрии и эксцесса, как правило, отличаются от 0. Требуется определить, значимы ли эти отличия или нет. Если отличия незначимы, то гипотеза о нормальном распределении генеральной совокупности принимается. В противном случае, если отличия значимы - отклоняется.
Существует простой способ оценить значимость отличий выборочных значений асимметрии и эксцесса от 0. Способ использует асимптотический подход, поэтому объем выборки N должен быть достаточно большим (N > 50). Известно, что выборочные значения aВ и eВ распределены асимптотически нормально с параметрами ![]() и
и ![]() соответственно. Для нормального генерального распределения a = 0 и e = 0. Средние квадратические отклонения могут быть приблизительно оценены следующим образом:
соответственно. Для нормального генерального распределения a = 0 и e = 0. Средние квадратические отклонения могут быть приблизительно оценены следующим образом:
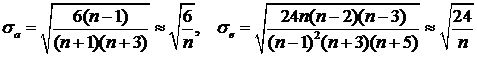 (3)
(3)
Следовательно, асимптотически А~![]() , Е~
, Е~![]() . Опуская выкладки, приведем простой алгоритм проверки гипотезы о нормальности генерального распределения с помощью выборочных асимметрии и эксцесса:
. Опуская выкладки, приведем простой алгоритм проверки гипотезы о нормальности генерального распределения с помощью выборочных асимметрии и эксцесса:
1) Выбираем уровень значимости ![]() . Обычно его выбирают равным 0,05.
. Обычно его выбирают равным 0,05.
2) Вычисляем значение ![]() по формуле
по формуле 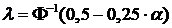 . При обычно выбираемом уровне значимости
. При обычно выбираемом уровне значимости ![]() = 0,05 параметр
= 0,05 параметр ![]() .
.
3) Вычисляем выборочные значения асимметрии А и эксцесса и Е (формулы (1) и (2)).
4) Вычисляем значения отклонений по формулам (3).
5) Если не выполняется хотя бы одно из неравенств
![]() , (4)
, (4)
то на уровне значимости ![]() гипотеза о нормальном распределении генеральной совокупности отклоняется. Если оба неравенства (4) выполняются, то нет оснований отвергать нулевую гипотезу.
гипотеза о нормальном распределении генеральной совокупности отклоняется. Если оба неравенства (4) выполняются, то нет оснований отвергать нулевую гипотезу.
Например, если объем выборки N=100, то 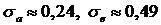 и неравенства (4) принимают вид:
и неравенства (4) принимают вид: ![]() .
.
8. Трудность задания (Коэффициент решаемости задания) – вычисляется по формуле:
k
Очевидно, при дихотомической оценке значение k соответствует доли испытуемых данной выборки, выполнивших задание правильно. Следовательно, ![]() . Чем больше k, тем легче данное задание, и, наоборот, чем меньше , тем оно труднее.
. Чем больше k, тем легче данное задание, и, наоборот, чем меньше , тем оно труднее.
Коэффициент решаемости 5-го задания в рассматриваемом примере равен:
Коэффициент решаемости задания ассоциируется с мерой его трудности. Оптимальное значение меры трудности для задания 0,5, но в тесте должны присутствовать и легкие задания (коэффициент решаемости ), и сложные (![]()
Если экспертным путем определялся уровень сложности заданий, то заданиям первого уровня сложности соответствуют значения трудности ![]() ; заданиям второго уровня сложности -
; заданиям второго уровня сложности -  и заданиям третьего уровня сложности -
и заданиям третьего уровня сложности - ![]() В случае несовпадения предполагаемого уровня сложности задания и полученного уровня его трудности необходим анализ причин несовпадения.
В случае несовпадения предполагаемого уровня сложности задания и полученного уровня его трудности необходим анализ причин несовпадения.
9. Дифференцирующая способность задания (дискриминативность)
Цель создания многих тестов состоит в обеспечении информации об индивидуальных различиях между испытуемыми. Поэтому задания теста должны обладать способностью различать испытуемых с различным уровнем подготовки. Если на какое-либо задание теста отвечают все испытуемые, независимо от уровня их подготовки, то такое задание не дифференцирует сильных студентов от слабых. Аналогичная ситуация с заданием, на которое нет ни одного правильного ответа. Еще хуже ситуация, когда сильные испытуемые не отвечают на задание правильно, а слабые – отвечают. В этом случае задание не только не дифференцирует испытуемых, но и вносит дезинформацию в их оценивание. Про такие задания говорят, что они имеют отрицательную дискриминативность.
В качестве показателя дискриминативности используют различные показатели, которые будут рассмотрены далее.
Показатель различительной способности задания (показатель дискриминативности)
Этот показатель очень прост в применении, поэтому довольно популярен. Пусть ![]()
![]() - коэффициент решаемости j-го задания лучшей половиной тестируемых,
- коэффициент решаемости j-го задания лучшей половиной тестируемых, ![]() - коэффициент решаемости j-го задания худшей половиной тестируемых. Тогда
- коэффициент решаемости j-го задания худшей половиной тестируемых. Тогда
![]() .
.
Чаще всех испытуемых делят не пополам, а отбирают 27 % испытуемых, имеющих высокие баллы и 27 % испытуемых, имеющих низкие баллы.
Очевидно, что -![]()
![]()
![]() . Если задание правильно выполняет больше лучших, чем худших тестируемых, то
. Если задание правильно выполняет больше лучших, чем худших тестируемых, то ![]() >0; в противном случае
>0; в противном случае ![]() <0. Если задание выполнит одинаковое количество лучших и худших, то
<0. Если задание выполнит одинаковое количество лучших и худших, то ![]() =0, задание не дифференцирует испытуемых. В литературе приводятся следующие принципы для интерпретации значений коэффициента
=0, задание не дифференцирует испытуемых. В литературе приводятся следующие принципы для интерпретации значений коэффициента ![]() :
:
1) Если ![]() ≥ 0,4, то задание функционирует удовлетворительно;
≥ 0,4, то задание функционирует удовлетворительно;
2) Если 0,30 ≤![]() ≤0,39, то требуется небольшая коррекция задания;
≤0,39, то требуется небольшая коррекция задания;
3) Если 0,20 ≤![]() ≤0,29, то задание нуждается в пересмотре;
≤0,29, то задание нуждается в пересмотре;
4) Если ![]() ≤0,19, то задание должно быть исключено из теста или полностью переделано.
≤0,19, то задание должно быть исключено из теста или полностью переделано.
Недостаток применения этого коэффициента состоит в том, что у него нет никакого известного выборочного распределения, поэтому невозможно определить, насколько значимо величина коэффициента больше 0, например. Однако он часто используется из-за своей простоты.
Остальные методы анализа дифференцирующей силы заданий являются различными видами коэффициентов корреляции.
Точечная бисериальная корреляция
Точечно-бисериальный коэффициент представляет собой упрощенную формулу Пирсона – коэффициента корреляции между результатами выполнения каждого задания и суммой баллов по всему тесту (при дихотомическом способе оценки):
![]() =
= ![]()
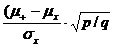 ,
,
где
![]() - средний балл испытуемых, выполнивших j-ое задание верно;
- средний балл испытуемых, выполнивших j-ое задание верно;
![]() - средний балл всей группы испытуемых;
- средний балл всей группы испытуемых;
![]() - среднее квадратическое отклонение результатов тестирования всех испытуемых;
- среднее квадратическое отклонение результатов тестирования всех испытуемых;
![]() - число испытуемых, выполнивших j-ое задание верно (трудность задания);
- число испытуемых, выполнивших j-ое задание верно (трудность задания);
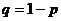 - число испытуемых, выполнивших j-ое задание неверно.
- число испытуемых, выполнивших j-ое задание неверно.
Полученный коэффициент корреляции иногда называют показателем валидности задания. Чем выше коэффициент корреляции, тем валиднее задание, тем выше его дифференцирующая способность. В целом, задание можно считать валидным, если значения (![]() )
)![]() >0,5.
>0,5.
Оценка валидности задания позволяет судить, насколько задание пригодно для работы в соответствии с общей целью создания теста. Если его цель – дифференциация испытуемых, то валидные задания должны четко отделять хорошо подготовленных от слабо подготовленных учеников тестируемой группы.
Бисериальный коэффициент корреляции
Это еще один коэффициент вычисления корреляции между результатами выполнения каждого задания и суммой баллов по всему тесту в предположении, что значения латентной переменной, лежащей в основе выполнения заданий, распределены нормально. Этот коэффициент и предыдущий связаны простым математическим соотношением. Следует отметить, что значение бисериальной корреляции для заданий средней трудности, по крайней мере, в полтора раза превышает значение точечной бисериальной корреляции для тех же самых переменных. Для заданий экстремальной трудности (очень легких и очень трудных) разница между бисериальной корреляцией и точечной бисериальной корреляцией резко возрастает.
Иногда используются и другие коэффициенты корреляции, например, коэффициент фи, тетрахорический коэффициент корреляции и др.
Могут быть предложены следующие рекомендации относительно выбора процедуры анализа дифференцирующей силы задания в случае их дихотомического оценивания.
1) Если задания имеют среднюю трудность, то выбор статистического критерия не играет особого значения. Поэтому можно использовать показатель дискриминативности, как самый легкий по вычислению.
2) Если стоит цель отобрать задания в экстремальном диапазоне трудности, то лучще применять бисериальный коэффициент корреляции.
Анализ заданий производится с учетом всей информации по нему, что, как правило, позволяет установить причины плохого функционирования задания. Для этого дополнительно используются данные по ответам испытуемых (в случае закрытых заданий данные по дистракторам). Все данные обычно сводят в таблицу.
Задание | Ответы к заданиям, % | Пропуски, % | Трудность задания р | Показатель дискрими- нативности | Точечная бисериальная корреляция | |||
1 | 2 | 3 | 4 | |||||
1 | 24 | 4 | 52 | 16+ | 4 | 0,16 | 0,00 | -0,06 |
2 | 4 | 28+ | 28 | 32 | 8 | 0,28 | -0,17 | -0,12 |
3 | 16 | 12 | 0 | 72+ | 0 | 0,72 | -0,17 | -0,29 |
Задание 1 имеет отрицательную точечную бисериальную корреляцию. Задание очень трудное – только 16% испытуемых выполнили его верно. При анализе распределения ответов видим, что 52% испытуемых выбрали вариант ответа 3 вместо помеченного, как правильный варианта 4. Возможная причина такой ситуации – отсутствие правильного ответа в задании.
Задание 2 также является отрицательно дифференцирующим. Оно тоже трудное. Ответы на него рспределены почти одинаково по трем из 4-х возможных позиций, включая правильный ответ. Возможная причина – испытуемые отвечали наугад. Дополнительно видим, что 8% испытуемых пропустили это задание, т. е., возможно, его не поняли. Возможно, задание было сформулировано неоднозначно, или для задания нет правильного ответа, или содержание задания неизвестно испытуемым.
Задание 3 имеет проблемы с содержанием и вариантами ответов. Оно легкое. Вариант ответа 3 никем не был выбран, т. е. это – неработающий дистрактор. Включение такого ответа увеличивает шансы на угадывание слабых испытуемых, поэтому задание получилось более легким. Необходимо переделать неработающий дистрактор.
10. Расчет корреляции между заданиями.
Для оценки связи между результатами выполнения двух заданий теста можно использовать коэффициент корреляции Пирсона. Результаты подсчета коэффициентов корреляции по всем заданиям сводят в таблицу – полную корреляционную матрицу.
Чем выше коэффициент корреляции между заданиями, тем сильнее они взаимосвязаны. Для тестов текущей успеваемости коэффициент корреляции между заданиями должен быть как можно ближе к 1. Если r<0, это означает, что сильные по другим заданиям студенты в этом задании терпят неудачу и наоборот. Как правило, это следствие некорректности задания. Задание, которое отрицательно коррелирует с несколькими заданиями, должно быть удалено из теста, что приведет к большей гомогенности (предметной чистоте) теста. Отрицательные значения корреляции указывают на отсутствие связи содержания этих заданий с содержанием других заданий.
В итоговом аттестационном тесте высокой корреляции между заданиями стараются избегать, т. к. вряд ли имеет смысл включать в тест несколько заданий, оценивающих одинаковые содержательные элементы. Поэтому в итоговом тесте обычно стремятся к невысокой положительной корреляции (рекомендуемое значение r для итогового теста: 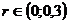 ). В этом случае каждое задание вносит свой специфический вклад в общее содержание теста, в противном случае задания подменяют друг друга.
). В этом случае каждое задание вносит свой специфический вклад в общее содержание теста, в противном случае задания подменяют друг друга.
11. Надежность теста.
Коэффициент надежности рассчитывается как коэффициент корреляции экспериментальных данных при обработке результатов выполнения двух половин одного и того же теста (метод расщепления), или одного и того же теста, но в разное время (ретестовый метод), или результатов тестирования параллельными вариантами. Рассмотрим различные методы вычисления надежности теста.
1). Ретестовый метод – основан на повторном применении одного и того же теста на одной и той же группе испытуемых (рекомендуется, не ранее, чем через 2 недели и не позже, чем через 3 недели). Коэффициент надежности в этом случае рассчитывается как коэффициент корреляции между оценками испытуемых по двум тестированиям.
Коэффициент надежности, вычисленный ретестовым методом, может дать завышенное значение, особенно если повторное тестирование проводится слишком близко по времени. Учащиеся могут запомнить ответы к некоторым заданиям, что негативно скажется при оценке надежности теста.
2). Метод параллельных форм.
Для исследования надежности теста этим методом используется корреляция между результатами выполнения одной группой испытуемых двух параллельных форм теста. На практике этот метод используется крайне редко ввиду невозможности разработки полностью параллельных вариантов. Однако, если проверена гипотеза о параллельности вариантов теста, этот метод можно применять.
Описанные два метода на практике используются редко, т. к. предполагают двукратное тестирование.
3). Метод расщепления – позволяет оценить надежность теста при одном предъявлении теста группе испытуемых. Результаты тестирования делятся на две группы, например, в одну группу берутся все нечетные задания, в другую – все четные задания. В качестве коэффициента надежности берется коэффициент корреляции между оценками испытуемых по двум группам заданий.
В результате расщепления длина теста уменьшается в два раза, поэтому значение коэффициента надежности теста будет заниженным. Для его коррекции используют формулу Спирмена-Брауна:
![]() ,
,
Если, например, 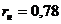 , то
, то 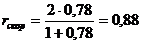 - скорректированное значение коэффициента надежности.
- скорректированное значение коэффициента надежности.
Метод расщепления основан на предположении о параллельности двух половин теста, что не всегда оказывается верным. Корреляция двух половин теста возрастает по мере роста гомогенности теста. В этой связи, коэффициент надежности, вычисленный таким способом, иногда называют коэффициентом внутренней согласованности теста.
Отметим, что итоговые тесты таким способом лучше не расщеплять, т. к. необходимо при расщеплении учитывать содержание теста.
4). Формула Кьюдера-Ричардсона (KR-20).
Представляет собой упрощенный вариант коэффициента Кронбаха альфа для случая дихотомических заданий. Формула Кьюдера-Ричардсона (KR-20) очень удобна:
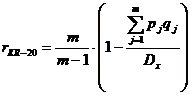
где m- число заданий в тесте;
![]() - трудность j-го задания теста;
- трудность j-го задания теста;
![]() ;
;
![]() - дисперсия баллов испытуемых по всему тесту.
- дисперсия баллов испытуемых по всему тесту.
Вычислим по этой формуле надежность теста, результаты выполнения которого приведены в таблице 1.
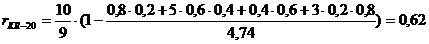
Такое низкое значение надежности может быть объяснено различными причинами (малая и нерепрезентативная выборка, малое количество заданий в тесте и т. д.), но недопустимо на практике.
Рекомендуется для большей точности для оценки коэффициента надежности использовать различные методы.
Коэффициент надежности ![]()
![]() . В качестве нижнего предела допустимых значений надежности обычно выбирают значение 0,7. При более низких значениях использование теста нецелесообразно ввиду большой погрешности измерения. К профессионально разработанным тестам предъявляются более жесткие требования: тесты с надежностью менее 0,8 считаются непригодными. Положение с выводами о качестве теста осложняется тем, что коэффициент надежности зависит от свойств выборки испытуемых, по результатам которых оценивается надежность теста. Поэтому при каждом использовании теста необходимо оценивать его надежность и только после этого говорить о достоверной интерпретации выполнения теста.
. В качестве нижнего предела допустимых значений надежности обычно выбирают значение 0,7. При более низких значениях использование теста нецелесообразно ввиду большой погрешности измерения. К профессионально разработанным тестам предъявляются более жесткие требования: тесты с надежностью менее 0,8 считаются непригодными. Положение с выводами о качестве теста осложняется тем, что коэффициент надежности зависит от свойств выборки испытуемых, по результатам которых оценивается надежность теста. Поэтому при каждом использовании теста необходимо оценивать его надежность и только после этого говорить о достоверной интерпретации выполнения теста.
К числу источников неудовлетворительной надежности теста можно отнести:
1) субъективизм при оценке результатов выполнения заданий теста
2) угадывание (как показывают исследования, угадывание существенно снижает надежность теста, особенно в тех случаях, когда слабые ученики прибегают к догадке при выполнении наиболее трудных заданий теста)
3) отсутствие логической корректности формулировок заданий (как правило, некорректные задания искажают истинную картину, что в целом негативно отражается на надежности теста)
4) неоправданный выбор весовых коэффициентов
5) длина теста
6) отсутствие стандартной инструкции к тесту
7) условия тестирования (шум, плохое освещение и т. д.)
8) плохое самочувствие испытуемого и пр.
Рассмотренные методы оценки коэффициента надежности неприменимы для критериально-ориентированных тестов, так как малая дисперсия в КРОТ приводит к завышенному значению коэффициента надежности. Для оценивания надежности в КРОТ используются другие методы.
12. Оценка ошибки измерения и построение доверительного интервала.
Зная надежность теста, можно оценить стандартную ошибку измерения ![]() :
:
![]() .
.![]()

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
