
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Критерий применяется в случаях, когда выборки анализируются на предмет наличия в их элементах некоторого признака. Обозначим через 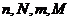 количество элементов, обладающих этим признаком, и общее количество элементов в каждой из сравниваемых выборок.
количество элементов, обладающих этим признаком, и общее количество элементов в каждой из сравниваемых выборок.
1. Вычисляется коэффициент Фишера по формуле
 .
.
2. Если ![]() , делается вывод, что выборки различны с доверительной вероятностью 0,95.
, делается вывод, что выборки различны с доверительной вероятностью 0,95.
9 Проверка нормальности закона распределения случайной величины
Для проверки того, что по данным конкретной выборки СВ распределена по нормальному закону, следует убедиться, что высказывание «Исходная выборка и «эталонная» выборка с таким же количеством элементов, для которой СВ распределена строго по нормальному закону, НЕ ЯВЛЯЮТСЯ различными» справедливо с требуемой доверительной вероятностью ![]() . В этом случае вероятность справедливости противоположного высказывания «Исходная выборка и «эталонная» выборка, ЯВЛЯЮТСЯ различными» должна быть равна
. В этом случае вероятность справедливости противоположного высказывания «Исходная выборка и «эталонная» выборка, ЯВЛЯЮТСЯ различными» должна быть равна ![]() . Если это второе, противоположное, высказывание неверно, то верно исходное. Для проверки верности второго высказывания используют критерий «хи-квадрат».
. Если это второе, противоположное, высказывание неверно, то верно исходное. Для проверки верности второго высказывания используют критерий «хи-квадрат».
1. Выбирают количество диапазонов ![]() , на которые разбивают область изменения значений СВ из исходной выборки, но так, чтобы в каждый диапазон попадало не менее 5 значений СВ. Обозначим точки разбиения через
, на которые разбивают область изменения значений СВ из исходной выборки, но так, чтобы в каждый диапазон попадало не менее 5 значений СВ. Обозначим точки разбиения через ![]() .
.
2. Рассчитывают количество ![]() объектов исходной выборки, для которых значения СВ попадают в промежуток
объектов исходной выборки, для которых значения СВ попадают в промежуток 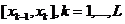 . Если значение СВ оказывается в точности на границе двух промежутков, к соответствующим переменным
. Если значение СВ оказывается в точности на границе двух промежутков, к соответствующим переменным ![]() добавляется по ½.
добавляется по ½.
3. Рассчитывают количество ![]() объектов «эталонной» выборки, для которых значения СВ попадают в промежуток
объектов «эталонной» выборки, для которых значения СВ попадают в промежуток
![]() .
.
4. В этой формуле ![]() - соответственно общее количество объектов, математическое ожидание и среднее квадратичное отклонение исходной выборки, а также функция Лапласа.
- соответственно общее количество объектов, математическое ожидание и среднее квадратичное отклонение исходной выборки, а также функция Лапласа.
5. Проверяется различие исходной и эталонной выборок по критерию «хи-квадрат» с доверительной вероятностью ![]() . Если оказывается, что выборки НЕ ЯВЛЯЮТСЯ РАЗЛИЧНЫМИ с этой доверительной вероятностью, это означает, что верно первое из высказываний, приведенных в начале настоящего раздела, т. е. СВ, отвечающая исходной выборке, с доверительной вероятностью
. Если оказывается, что выборки НЕ ЯВЛЯЮТСЯ РАЗЛИЧНЫМИ с этой доверительной вероятностью, это означает, что верно первое из высказываний, приведенных в начале настоящего раздела, т. е. СВ, отвечающая исходной выборке, с доверительной вероятностью ![]() распределена по нормальному закону.
распределена по нормальному закону.
10 Выявление грубых ошибок
1. Задаются доверительной вероятностью ![]() и по рисунку 1 для
и по рисунку 1 для ![]() определяют значение
определяют значение ![]() .
.
2. Для выборки рассчитываются математическое ожидание ![]() и среднее квадратичное отклонение
и среднее квадратичное отклонение ![]() .
.
3. Все значения СВ, меньшие ![]() и большие
и большие ![]() считаются грубыми ошибками и отбрасываются.
считаются грубыми ошибками и отбрасываются.
4. Математическое ожидание и среднее квадратичное отклонение рассчитываются заново.
11 Анализ степени взаимовлияния двух случайных величин
Взаимовлияние измеряется с помощью коэффициента корреляции Пирсона ![]()
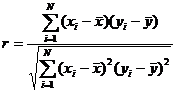 ,
,
где ![]() - значения переменных величин
- значения переменных величин ![]() и
и ![]() для объекта выборки с номером
для объекта выборки с номером ![]() ;
;
![]() - соответствующие математические ожидания.
- соответствующие математические ожидания.
Коэффициент Пирсона ![]() может принимать значения из интервала [-1; +1]. Значение r = 0 означает отсутствие линейной связи между переменными (но не исключает статистической связи нелинейной). Положительные значения коэффициента свидетельствуют о прямой линейной связи; чем ближе его значение к +1, тем сильнее связь. Отрицательные значения коэффициента свидетельствуют об обратной линейной связи; чем ближе его значение к -1, тем сильнее обратная связь. Значения r = ±1 означают наличие полной линейной связи, прямой или обратной. В случае полной связи все точки с координатами
может принимать значения из интервала [-1; +1]. Значение r = 0 означает отсутствие линейной связи между переменными (но не исключает статистической связи нелинейной). Положительные значения коэффициента свидетельствуют о прямой линейной связи; чем ближе его значение к +1, тем сильнее связь. Отрицательные значения коэффициента свидетельствуют об обратной линейной связи; чем ближе его значение к -1, тем сильнее обратная связь. Значения r = ±1 означают наличие полной линейной связи, прямой или обратной. В случае полной связи все точки с координатами ![]() лежат на прямой
лежат на прямой 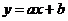 .
.
Коэффициент детерминации ![]() показывает, на какую долю изменение зависимой переменной объясняется изменением влияющей на нее переменной.
показывает, на какую долю изменение зависимой переменной объясняется изменением влияющей на нее переменной.
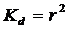
Таким образом, если коэффициент корреляции ![]() = 0,5, то
= 0,5, то ![]() = 0,25, т. е. различия в значениях зависимой переменной на 25% объясняются различиями в значениях независимой переменной (и на 75% - факторами, не учтенными в уравнении регрессии).
= 0,25, т. е. различия в значениях зависимой переменной на 25% объясняются различиями в значениях независимой переменной (и на 75% - факторами, не учтенными в уравнении регрессии).
12 Простая регрессия
В простой линейной регрессии предполагается, что зависимая переменная ![]() является линейной функцией
является линейной функцией ![]() от независимой переменной
от независимой переменной![]() . Требуется найти значения параметров
. Требуется найти значения параметров ![]() и
и ![]() , при которых прямая
, при которых прямая ![]() будет наилучшим образом описывать (аппроксимировать) значения переменных
будет наилучшим образом описывать (аппроксимировать) значения переменных 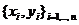 . Можно использовать нелинейную, например полиномиальную, регрессию, в которой предполагается, что зависимая переменная является нелинейной функцией заданной структуры с неопределенными коэффициентами (например, полиномом некоторой степени от независимой переменной). Например, полиномом второй степени будет зависимость вида
. Можно использовать нелинейную, например полиномиальную, регрессию, в которой предполагается, что зависимая переменная является нелинейной функцией заданной структуры с неопределенными коэффициентами (например, полиномом некоторой степени от независимой переменной). Например, полиномом второй степени будет зависимость вида 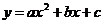 и задачей регрессии будет нахождение коэффициентов
и задачей регрессии будет нахождение коэффициентов ![]() .
.
Критериями качества аппроксимации могут быть
· минимум максимальной ошибки (абсолютной или относительной),
· минимум средней ошибки (абсолютной или относительной),
· минимум среднеквадратичной ошибки (абсолютной или относительной).
Оптимизация по критерию минимума максимальной ошибки.
Для линейной регрессии для каждого номера ![]() ошибка от представления значения
ошибка от представления значения ![]() аппроксимирующей его функцией равна
аппроксимирующей его функцией равна ![]() . Обозначим максимальную из абсолютных величин этих ошибок через
. Обозначим максимальную из абсолютных величин этих ошибок через ![]() . Тогда
. Тогда
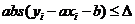 ,
,
или, что то же самое
![]() . (1)
. (1)
Условие (1) задает систему неравенств, которым должны удовлетворять неопределенные переменные ![]() . Они должны быть выбраны так, чтобы, при выполнении условий (1) переменная
. Они должны быть выбраны так, чтобы, при выполнении условий (1) переменная ![]() принимала минимально возможное значение:
принимала минимально возможное значение:
![]() . (2)
. (2)
Такая задача является математической задачей оптимизации и решается в Excell с помощью надстройки «Поиск решения». Заметим, что она является задачей т. н. линейного программирования, что облегчает решение.
Для линейной регрессии для каждого номера ![]() относительная ошибка имеет вид
относительная ошибка имеет вид ![]() , соответственно, неравенства (1) переходят в
, соответственно, неравенства (1) переходят в
![]() , (3)
, (3)
где через ![]() обозначена максимальная из относительных ошибок. Построение регрессии сводится к отысканию таких значений переменных
обозначена максимальная из относительных ошибок. Построение регрессии сводится к отысканию таких значений переменных ![]() , при которых условия (3) выполняются с наименьшим возможным значением
, при которых условия (3) выполняются с наименьшим возможным значением ![]() :
:
![]() (4)
(4)
Оптимизация по критерию минимума средней ошибки.
В этом случае вместо максимальной ошибки ![]() или
или ![]() для каждого номера
для каждого номера ![]() вводится в рассмотрение его ошибка
вводится в рассмотрение его ошибка ![]() или
или ![]() и соотношения (1), (3) заменяются на (1а) и (2а) соответственно:
и соотношения (1), (3) заменяются на (1а) и (2а) соответственно:
![]() , (1а)
, (1а)
![]() . (3а)
. (3а)
С помощью надстройки «Поиск решения» отыскиваются такие значения переменных ![]() или
или ![]() соответственно, которые, удовлетворяя (1а) или (3а) обеспечивают минимальное значение критериев (2а) или (4а):
соответственно, которые, удовлетворяя (1а) или (3а) обеспечивают минимальное значение критериев (2а) или (4а):
![]() , (2а)
, (2а)
![]() . (4а)
. (4а)
Эти задачи также являются задачами линейного программирования.
Оптимизация по критерию минимума среднеквадратичной ошибки.
В случае абсолютной ошибки среднее квадратичное отклонение ![]() рассчитанных значений зависимой переменной от заданных равно
рассчитанных значений зависимой переменной от заданных равно
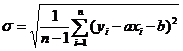 .
.
Минимизируя его, из условия равенства нулю частных производных по ![]() и
и ![]() получены формулы для коэффициентов линейной регрессии:
получены формулы для коэффициентов линейной регрессии:
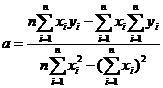 ,
,
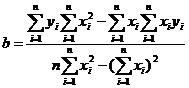 .
.
В случае относительной ошибки среднее квадратичное отклонение ![]() рассчитанных значений зависимой переменной от заданных равно
рассчитанных значений зависимой переменной от заданных равно
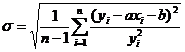 .
.
Аналогично предыдущему, из условия равенства нулю частных производных
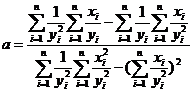
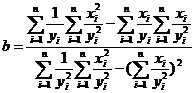
13 Множественная регрессия
Множественная регрессия – это аппроксимация зависимости СВ от нескольких независимых переменных величин. Исходными данными является набор векторов ![]() , которые сопоставляют значениям
, которые сопоставляют значениям ![]() независимых переменных
независимых переменных ![]() значение зависимой переменной
значение зависимой переменной ![]() для каждого из
для каждого из ![]() элементов выборки. Уравнение регрессии имеет вид
элементов выборки. Уравнение регрессии имеет вид
![]() ,
,
а ее построение сводится к определению таких значений коэффициентов 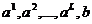 , при которых достигается минимум одного из критериев, указанных в п.13.
, при которых достигается минимум одного из критериев, указанных в п.13.
Приведем соответствующие оптимизационные математические модели.
Оптимизация по критерию минимума максимальной ошибки.
При оптимизации по абсолютной величине ошибки
![]() .
.
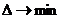 .
.
При оптимизации по относительной величине ошибки
![]() ,
,
![]()
Оптимизация по критерию минимума средней ошибки.
При оптимизации по абсолютной величине ошибки
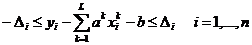 ,
,
![]()
При оптимизации по относительной величине ошибки
![]() .
.
![]() .
.
Эти задачи также являются задачами линейного программирования и решаются с помощью надстройки «Поиск решения» Excell.
Оптимизация по критерию минимума среднеквадратичной ошибки.
В случае оптимизации по абсолютной или относительной ошибке среднее квадратичное отклонение ![]() рассчитанных значений зависимой переменной от заданных равно соответственно
рассчитанных значений зависимой переменной от заданных равно соответственно
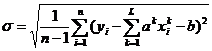 ,
,
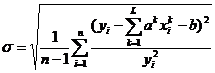 .
.
Определение значений коэффициентов целесообразно вести непосредственной оптимизацией в Excell соответственно функций
![]() ,
,
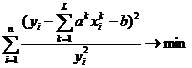 .
.
Заметим, что это задачи нелинейной оптимизации, которые решаются с помощью надстройки «Поиск решения» Excell, но более сложны для решения.
14 Выделение наиболее значимых независимых переменных и их комплексов
Для того, чтобы определить, какая из независимых переменных или их группа наиболее существенно влияет на зависимую переменную при построении множественной регрессии, нужно в модели, описанные в п.13, внести следующее дополнение. Добавим к числу оптимизируемых коэффициентов двоичные неопределенные переменные ![]() , которые могут принимать значения 0 или 1, и в число ограничений на допустимые значения всех оптимизируемых коэффициентов включим следующие:
, которые могут принимать значения 0 или 1, и в число ограничений на допустимые значения всех оптимизируемых коэффициентов включим следующие:
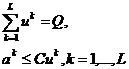 , (5)
, (5)
где ![]() - количество независимых переменных, которые мы желаем учитывать при построении регрессии, а
- количество независимых переменных, которые мы желаем учитывать при построении регрессии, а ![]() «очень большое» число, которое заведомо превосходит возможные значения неопределенных коэффициентов в уравнении регрессии.
«очень большое» число, которое заведомо превосходит возможные значения неопределенных коэффициентов в уравнении регрессии.
Дополненная таким образом оптимизационная задача решается с помощью надстройки «Поиск решения» Excell. Напомним, что при этом нужно не забыть объявить переменные ![]() как «двоичные». Тогда при
как «двоичные». Тогда при ![]() оптимальное решение будет включать лишь одну, наиболее значимую независимую переменную, при
оптимальное решение будет включать лишь одну, наиболее значимую независимую переменную, при ![]() - лишь две и т. д. Сопоставляя полученное при этом значение критерия с его значением при учете всех независимых переменных, можно увидеть, насколько учет лишь нескольких из них ухудшает результат.
- лишь две и т. д. Сопоставляя полученное при этом значение критерия с его значением при учете всех независимых переменных, можно увидеть, насколько учет лишь нескольких из них ухудшает результат.
15 Кластеризация множества объектов
Кластеризация – это разбиение множества объектов, между которыми установлено отношение близости (расстояние), на группы наиболее близких между собой объектов. В каждой группе выделяется объект – центр кластера. Максимальное из расстояний от объектов, входящих в кластер, до его центра называется радиусом кластера. Максимальный радиус всех кластеров, на которые разбито множество объектов, называется радиусом кластеризации этого множества.
Оптимальной называется кластеризация, которая при заданном радиусе кластеризации множества разбивает его на минимальное число кластеров. Оптимальную кластеризацию можно осуществить, используя надстройку «Поиск решения» Excell на основе следующей математической модели целочисленного линейного программирования.
Пусть ![]()
![]() - количество объектов множества,
- количество объектов множества,
![]() - номера объектов,
- номера объектов, ![]() ,
,
![]() - мера близости (расстояние) между объектами с номерами
- мера близости (расстояние) между объектами с номерами ![]() ,
,
![]() - радиус кластеризации множества.
- радиус кластеризации множества.
Рассчитывается признак ![]() возможности включения объекта с номером
возможности включения объекта с номером  в кластер, центром которого является объект с номером
в кластер, центром которого является объект с номером ![]()
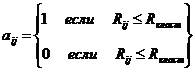 .
.
Вводятся неопределенные двоичные переменные 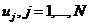 - признаки того, является ли объект с номером
- признаки того, является ли объект с номером ![]() центром кластера. Тогда условия
центром кластера. Тогда условия
![]()
гарантируют, что каждый объект будет включен хотя бы в один кластер с радиусом ![]() . При выполнении этих условий оптимальные значения переменных
. При выполнении этих условий оптимальные значения переменных ![]() определяются из требования минимума общего числа кластеров:
определяются из требования минимума общего числа кластеров:
![]() .
.
Иногда бывает, что небольшое число объектов слишком отличается от остальных объектов множества, что заставляет неоправданно увеличивать радиус кластеризации, с тем, чтобы «охватить» их наряду с прочими объектами. Можно расширить предыдущую модель, дав исследователю возможность оптимально исключать из кластеризации некоторое число заранее неизвестно каких объектов с тем, чтобы сделать кластеризацию остальных объектов более компактной.
Для этого вводятся дополнительные двоичные переменные ![]() - признаки того, что
- признаки того, что ![]() -й объект исключается из кластеризации (в этом случае
-й объект исключается из кластеризации (в этом случае ![]() ). Пусть
). Пусть ![]() - количество объектов, которое может быть исключено из кластеризации. Тогда оптимизационная модель имеет вид
- количество объектов, которое может быть исключено из кластеризации. Тогда оптимизационная модель имеет вид
![]() ,
,
![]() ,
,
 .
.
Литература
1. , Новочадов методы в медико-биологическом эксперименте. Волгоград: Изд-во ВолГМУ, 2005. – 84 с. Электронный ресурс http://window. *****/window/library? p_rid=47751
2. Учебное пособие по теории вероятностей. Электронный ресурс http://vm. *****/online-tv/index. html
3.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
