

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Адресация в Интернете
В Интернете существует единая система адресации, основанная на использовании IP-адреса.
Каждый компьютер, подключенный к Интернету, имеет свой уникальный 32-битный (в двоичной системе) IP-адрес.
По формуле (2.1) легко подсчитать, что общее количество различных IP-адресов составляет более 4 миллиардов:
N = 232 = 4
Таблица 4.1. IP-адресация в сетях различных классов |
|

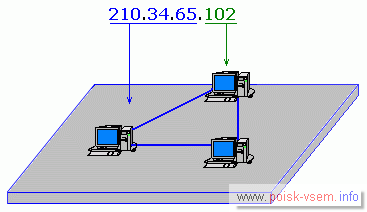
В сетях класса А (для глобальных сетей огромного масштаба) крайнее левое число определяет адрес сети, а остальные числа – адрес узла.
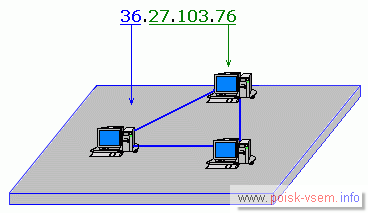
В сетях класса В (как правило, для крупных организаций) левые два числа определяют адрес сети, а правые два – адрес узла.
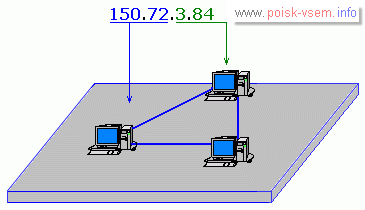
В сетях класса С (для небольших организаций) левые три числа определяют адрес сети, а крайнее правое – адрес узла.
Про IP-адресацию можно еще долго рассказывать и объяснять. Но я этого делать не буду, потому как это тема отдельной книги. А еще потому, что цифровой код IP-адреса сложно воспринимать и, тем более, запоминать (человеку)!
Доменное имя
Доменное имя – это IP-адрес, представленный символьными последовательностями, которые разделены точками. Понятное человеку доменное имя в символьной форме преобразуется в понятный компьютеру цифровой IP-адрес.
Такое преобразование осуществляет специальная служба Сети - Служба доменных имен DNS (Domain Name Service - система доменных имен).
При символьной, в отличие от IP-адресации, уровни иерархии (они называются доменами) в доменном имени расположены в обратном порядке
Домен первого уровня позволяет классифицировать сайты по двум признакам:
по географическому или по тематическому
URL-адреса
Каждый инфрмационный ресурс в Интернет имеет свой уникальный адрес.
Этот адрес называется URL (Uniform Resource Locator) - универсальный адрес ресурса.
URL-адрес имеет следующий вид:
Протокол://адрес сервера/путь/имя файла
Протокол. Определяет метод доступа к данным. Отделяется от остальной части адреса двоеточием и двумя наклонными чертами (://).
http ://– сокращение от Hyper Text Transfer Protocol (протокол пересылки гипертекста).
Но Интернет богат не только сайтами. Здесь также сосредоточены огромные хранилища файлов, которые находятся на FTP-серверах.
Адрес FTP-сервера часто (но не всегда!) начинается с ftp:// это протокол перемещения файлов
Адрес сервера. Это доменное имя компьютера, на котором размещены данные.
Путь к файлу. Последовательно указанные каталоги и подкаталоги, которые разделяются наклонной чертой (/). В последнем из них содержится нужный файл.
Имя файла. Имя искомого файла. Имеет имя и расширение, разделенные точкой. http://super. /images/auto/super/l165.gif
Задачи для тренировки
1.
Доступ к файлу hello. jpg, находящемуся на сервере home. info,
осуществляется по протоколу ftp. Фрагменты адреса файла закодированы
буквами от А до Ж. Запишите последовательность этих букв, кодирующую
адрес указанного файла в сети Интернет.
А) info
Б) ://
В) home.
Г) /
Д) hello
Е) ftp
Ж) .jpg
2.
A | .net |
Б | ftp |
В | :// |
Г | http |
Д | / |
Е | .org |
Ж | txt |
Доступ к файлу , находящемуся на сервере txt. org, осуществляется по протоколу http. В таблице фрагменты адреса файла закодированы буквами от А до Ж. Запишите последовательность этих букв, кодирующую адрес указанного файла в сети Интернет.
ПОИСК информации в интернет
Существует два больших класса поисковых систем:
каталоги (Directory - Dir)
и
поисковые машины (Search Engine - SE).
Поисковые машины также называют указателями, или индексами.
Применяется еще также термин поисковик.
Под поисковиком может подразумеваться как каталог, так и указатель, но чаще – указатель.
Поисковик и поисковая система – слова-синонимы
Классификация каталогов по степени их специализации / универсальности
- Специализированные каталоги
- Универсальные каталоги
Специализированные каталоги.
Специализированные каталоги содержат только ссылки на сайты по какой-то одной определенной теме.
Но тут у Вас наверное может возникнуть вопрос: "А в чем же тогда отличие между подборкой ссылок на определенную тему и специализированным каталогом.
Как вам сказать…
Пользователь просто сам почувствует, что перед ним.
В подборке ссылок количество сайтов (вернее, ссылок) - меньше. Они или не разнесены по подкатегориям, или это разделение не значительное. И т. п.
В специализированном каталоге – все наоборот. Да и вообще, в нем чувствуется, так сказать, солидность.
Хотя, конечно, автор специализированной подборки ссылок может называть ее специализированным каталогом. :)
Но пользователю-то в конечном итоге – какая разница как будет называться такой сайт?
Ведь главное, чтобы он на нем нашел то, что ему нужно!
Пример специализированного каталога:
Каталог медицинских ресурсов Русского медицинского сервера www. dir.

Универсальные каталоги.
В универсальных каталогах ссылки сгруппированы по различным темам.
Каждая рубрика такого каталога ветвится на более мелкие подрубрики.
А те, в свою очередь могут разделяться тоже на подподрубрики, и т. д.
Примеры универсальных каталогов:
Каталог от поисковой системы Яндекс: www. yaca. *****
Каталог от поисковой системы Апорт: www. *****
Самостоятельный каталог www. list. *****
1-й способ поиска по каталогу:
постепенно продвигаться по разделам и подразделам каталога, от более общих, к более конкретным.
2-й способ поиска по каталогу:
пользоваться поисковой машиной, встроенной в каталог, и предназначенной для поиска по нему (если таковая имеется, конечно же).
Популярные каталоги от крупнейших поисковых систем:
От Yandex – www. yaca. *****
От Aport – www. *****
От Google – www. *****/dirhp? hl=ru
Популярные российские каталоги:
***** – www. *****
***** - www. *****
***** – *****/rus/index. html
***** – www. *****
Принцип работы поисковой машины
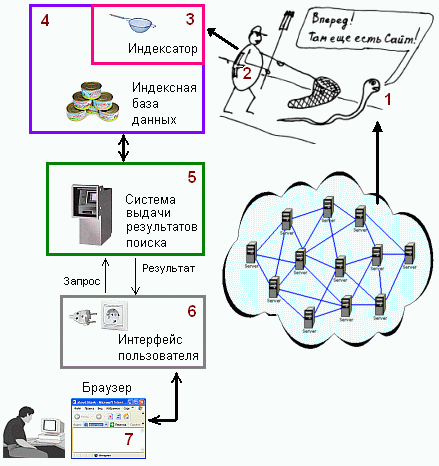
Назначение элементов поисковой машины.
1) Червяк (Crawler) – программа.
Лазает по Интернету, куда глаза глядят.
(Или куда направляют его разработчики поисковой системы, так как бывают и сфокусированные поисковые машины, ориентированные на сайты определенной направленности).
Задача Червяка – поиск на вэб-страницах всех ссылок на другие вэб-страницы.
На тех, других вэб-страницах – ссылок на новые другие вэб-страницы.
И так далее…
Что Червяк с этими ссылками делает? Отдает их на съедение пауку!
2) Паук (Spider) – программа.
Паук загружает (в смысле копирует) по ссылкам, переданным ему червяком, вэб-страницы в саму поисковую машину.
Работает как обычный браузер, но ни на какой монитор никакого изображения не выводит, а загружает только HTML-код вэб-страниц.
Этот код он передает индексатору.
* Поскольку червяк и паук работают вместе, то часто эти две программы называют HTTP-робот или поисковый робот.
(Поисковый робот = Червяк + Паук).
3) Индексатор (Indexer) – программа.
Анализирует и помечает себе:
- адрес страницы;
- название страницы;
- верхнюю часть страницы (ее фрагмент);
- слова из текста;
- какие слова содержатся в заголовке вэб-страницы;
- какие – в ссылках;
- какие – просто в тексте документа;
- какие слова выделены курсивом;
- какие жирным шрифтом;
- написано ли слово прописными или строчными буквами;
- в каком месте документа (в начале, в середине, в конце) это слово встречается;
- как часто оно вообще встречается;
- и т. д. и т. п.
Загрузка из сети данных и их предварительный анализ индексатором называемся индексацией.
Если сайт был загружен и проанализирован поисковой машиной, значит, про такой сайт говорят, что он проиндексирован.
Индексация может производиться на разную глубину.
То есть может быть проиндексировано только начало веб-документа, или вообще, только его заголовок.
Всю информацию, полученную в результате анализа страницы (о содержимом документа, о самом документе), индексатор сохраняет в специальном формате и помещает в базу данных.
4) База данных (Database) – служит для хранения информации, полученной в результате анализа (индексации) страницы.
Но в базе данных еще сохраняются и сами документы (вэб-страницы) в таком первоначальном виде, который они имели на момент индексации.
Тогда позже, при поиске, пользователь сможет просмотреть ту страницу из базы данных поисковой машины.
Для этого ему нужно будет выбрать на странице результатов поиска пункт, типа "Эта страница, сохраненная в КЭШе". Или подобное название, - у разных поисковых систем этот пункт по-разному может называться. Но у многих может и отсутствовать.
Для чего нужно это пользователю?
Если, например, он не хочет переходить на ныне существующую страницу, а хочет посмотреть, какой она была на момент индексации.
Ведь за время, прошедшее с момента индексации и до момента поиска, страница могла измениться!
Или, если на момент поиска этой страницы уже не существует!
Да, да, сайты могут исчезать.
По разным причинам…
Тогда единственное, чем остается довольствоваться ищущему – это страница, сохраненная в базе данных.
То есть, получается, что в базе данных хранятся все известные поисковику вэб-страницы и информация, полученная в результате анализа этих страниц.
Поэтому база данных хранится на носителях с очень огромным объемом памяти.
И для ее поддержания и обработки требуется много разных ресурсов.
Часто базу данных еще "с легкой руки" называют индексом.
Например, можно услышать или прочитать примерно следующее: "Индекс (читай – "база данных") такого-то поисковика насчитывает столько-то миллионов вэб-страниц".
В таких случаях, скорее всего, имеют в виду, что "столько-то миллионов вэб-страниц" поисковик, а точнее, его индексатор, проанализировал и сохранил в своей базе данных.
5) Система принятия запросов и выдачи результатов поиска (Search Engine Results Engine).
Как раз с ней и работает пользователь.
Он вводит запросы.
А система решает, – какие именно результаты выдавать пользователю в соответствии с его запросами.
6) Интерфейс пользователя (User interface).
Сначала давайте выясним, что вообще означает понятие "интерфейс".
Вообще, этому слову посвящено много разных определений. Я же скажу буквально в двух словах.
Интерфейс – это способ взаимодействия.
Или, способ соединения, если хотите.
Интерфейсами Вы пользуетесь каждый день, по нескольку раз!
Подключаете бытовой прибор к электросети: интерфейс = вилка + розетка.
Работаете на ПК: интерфейс = клавиатура (мышка), для ввода данных в ПК + монитор, для вывода данных из ПК.
И т. д. и т. п.
Таким образом, Интерфейс пользователя (User interface) = правила для написания запросов + способ представления результатов поиска.
7) Браузер (Browser) – его Вы уже знаете. Это программа, предназначенная для отображения веб-страниц (и, естественно, результатов поиска в том числе) на мониторе пользователя.
Итак, мы рассмотрели принцип работы поисковой машины
Где поисковик ищет для Вас информацию.
Хочу еще раз обратить Ваше внимание на то, что поисковик по Вашему запросу не кидается с головой в Итернет для поиска нужной Вам информации.
Нет, он ищет по своей, предварительно созданной базе данных.
Благодаря этому обработка запроса происходит намного(!) быстрее, чем если бы он рыскал в поисках по всей Сети.
Но вместе с тем, область поиска ИПС получается ограниченной объемом базы данных.
Поиск должен производиться по определенному алгоритму.
Да, действительно, она решает:
1) Включать или не включать в результаты поиска тот или иной документ.
Если какой-то документ не содержит ни одного из введенных ключевых слов (например, если эти слова достаточно редкие), то, понятно, он вообще не будет указан в результатах поиска.
Но!!!
Так работают поисковые машины, которые используют матричную модель поиска.
Те же ИПС, которые пользуются пространственно-векторной моделью, могут в результатах поиска выдать даже такой документ (или документы), в которых не содержится некоторых или даже всех ключевых слов, введенных в запросе!
Однако, несмотря на это, такой документ будет соответствовать запросу, т. е. будет релевантным!
Если Вы хотите подробнее узнать об описанных выше моделях поиска, то введите их названия в качестве запроса к ИПС.
Еще введите запрос "законы Зипфа".
Основываясь на законах Зипфа сейчас работает большинство поисковых систем!
2) На каком месте в списке результатов поиска поставить найденный документ.
В большинстве случаев введенные в поле запроса слова содержатся не только в одном документе, а в нескольких, а то и вообще, в огромном количестве документов.
Если, например, это очень распространенные, часто употребляемые слова.
В таком случае, выходит, что поисковая система должна в результатах поиска показать все документы с такими словами. Вот некоторые элементы алгоритмов поиска, которыми в той или иной степени руководстуется большинство поисковых систем:
- Присутствует ли ключевое слово в имени домена или в url-адресе страницы?
Если да, то вес страницы увеличивается.
- Присутствует ли ключевое слово в заголовке документа (между тегами <title и /title>)?
Если да, то вес увеличивается.
- Встречается ли ключевое слово в названиях разделов, подразделов документа?
Если да, то вес увеличивается.
- Встречается ли ключевое слово в тексте документа выделенным жирным, курсивом или как-то по-другому?
Если да, то вес увеличивается.
- Часто ли ключевое слово встречается в тексте веб-документа?
Чем чаще, тем вес выше.
Но до определенного предела!
Если ключевое слово будет встречаться в документе чаще среднестатистических показателей (по некоторым данным, если занимает более 5%-7% от всего объема текста), то это будет расцениваться или как спам, или как специальная попытка разработчика страницы увеличить вес страницы.
И тогда поисковик не будет увеличивать вес страницы, а то и понизит его!
- Расположены ли слова в веб-документе в том же порядке, как и в запросе?
Если да, то вес увеличивается.
- Ключевые слова расположены в документе в одном предложении, подряд, между ними небольшое расстояние (немного других, не ключевых слов между ними)?
Если да, то вес увеличивается.
- Встречается ли ключевое слово в тексте ссылки, расположенной на данной странице?
Если да, то вес увеличивается.
- Существуют ли другие страницы (на этом же сайте, или на других), с которых ссылки ведут на рассматриваемый документ?
Если да, то вес этого документа увеличивается.
Причем, чем с большего количества страниц будет ссылок на этот документ, тем большим будет его вес.
Но тогда можно ведь наделать кучу страниц и сайтов со ссылками на нужный документ, чтобы увеличить его вес?!
Такой номер вряд ли обведет поисковые системы вокруг пальца.
Потому что поисковая система анализирует еще и то, насколько популярна (авторитетна) та страница, с которой ведет ссылка на рассматриваемый документ.
Как?
А "смотрит" много ли ссылок ведет на сайт, на котором есть ссылка на рассматриваемый документ.
В общем, все, как и в жизни – популярным является то, что люди (а в Интернете – сайты) советуют друг другу.
И уж на этот критерий (ссылки на свою вэб-страницу с других сайтов) разработчик не в силах повлиять как-то искусственно.
Ведь чтобы на твой ресурс ссылались другие, нужно, чтобы он действительно, по настоящему был популярен!
Кто захочет давать ссылку на своем сайте на чей-то плохой сайт?!
Ну, разве что за деньги…
Но ведь все равно, рано или поздно авторитет такого продажного сайта начнет падать – люди не любят, когда их обманывают, советуют им плохое.
- Совпадают ли слова, введенные в поле запроса, с:
- ключевыми словами (keywords), указанными на странице ее разработчиком;
- со словами, указанными разработчиком, в описании (description) стр
Но среди всех тех документов, несомненно, существуют такие, которые в большей степени (лучшие), и которые в меньшей степени (худшие) соответствуют тому, что именно хотел найти пользователь.
И если лучший документ окажется в конце списка результатов поиска, то это, по сути, равнозначно тому, что этот лучший документ вообще не был найден.
Потому что поисковик в результатах поиска может выдать ссылки на сотни и тысячи, на десятки и сотни тысяч, на миллионы документов, в которых содержатся слова из запроса.
Какому пользователю хватит терпения (а то и всей жизни!), чтобы их хотя бы просмотреть?
Я не говорю уже о том, чтобы переходить по ссылкам на все те документы!
Поэтому поисковая система старается сортировать документы, содержащие ключевые слова, так, чтобы лучшие из них попали наверх списка результатов поиска, а худшие – в конец.
Чем лучше – тем выше, чем хуже – тем ниже.
Тогда пользователь сразу же увидит только лучшие документы.
