

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Лекция 9. Модели триггеров
Традиционно триггеры принято относить к вентильному уровню, на котором находятся и логические элементы (лекция 3). Поэтому триггеры называют элементами, хотя такое название и не очень корректно.
В действительности триггеры являются более сложными объектами, состоящими из нескольких (от двух до девяти) простых логических вентилей. Отсюда следует, что модели триггеров можно представить не только поведенческими, но и структурными моделями, оставаясь на одном и том же уровне иерархии, а именно, на уровне логического моделирования (рис.1).
 |
Рис. 1. Поведенческая и структурная модели стробируемого RS-триггера
Попытка создать структурную модель для логического элемента неизбежно приводит к понижению уровня на одну ступеньку иерархии, то есть к необходимости рассматривать такой элемент как систему, образованную структурными примитивами более низкого уровня (транзисторами, резисторами, конденсаторами и прочими компонентами). Следовательно, логическое моделирование приходится заменять схемотехническим (электронным), приобретая при этом все недостатки излишней детализации.
Рассмотрим основные особенности моделирования триггеров.
Прежде всего, триггеры – это элементы памяти. Сказанное означает, что новое состояние триггера может определяться не только набором входных сигналов, но и предшествующим (текущим, старым) его состоянием. Например, JK-триггер, работающий в режиме инверсии (J = K = 1), меняет своё состояние на противоположное. Если Вы не указали его текущее состояние, то моделирующей программе не удастся определить и новое.
То же самое можно сказать и о счётчике. Если его состояние неизвестно (равно значению шины X), то при добавлении в счётчик единицы (X := X+1), состояние его по-прежнему будет неизвестным и равным X.
Отсюда следует, что при моделировании цифровых схем с памятью могут возникнуть проблемы, если моделятору не удалось изначально инициализировать объект. Поэтому пользователю перед началом моделирования приходится искусственно задавать исходное состояние схемы, например, сбрасывая все триггеры в «0» или устанавливая их в «1». В некоторых системах моделирования предусмотрен режим начальной установки элементов памяти случайным образом.
Сказанное касается не только поведенческих, но и структурных моделей триггеров, когда они раскрыты до уровня вентилей. Объясняется это тем, что структурные схемы элементов с памятью содержат один или несколько контуров, то есть цепей с обратными связями.
Задавая начальное состояние триггера, Вы тем самым определяете значения сигналов на цепях обратной связи. В противном случае моделирующая программа не сможет определить выход элемента, на входах которого действует неизвестный сигнал обратной связи, и результаты моделирования будут не адекватны поведению реальной схемы.
Ещё большие трудности возникают при моделировании триггерных структур с несколькими контурами обратных связей (например, D-триггер типа 555TM2). Даже получив информацию о начальном состоянии такого триггера, моделятор не сможет выяснить значения сигналов на всех цепях обратной связи, и моделирование не даст ожидаемых результатов.
Единственный способ избежать названных проблем заключается в том, чтобы начинать моделирование с установочной комбинации входных сигналов.
Для структурных моделей триггеров – это, пожалуй, единственная особенность. Во всём остальном моделирование триггеров ничем не отличается от моделирования любых других цифровых комбинационных схем.
При рассмотрении поведенческих моделей триггеров дополнительно приходится учитывать ещё три особенности данного класса объектов:
§ наличие запрещённых наборов входных сигналов;
§ динамическое управление записью в некоторых структурах триггеров;
§ необходимость хранить в булевской модели триггера не только текущее, но и старое состояние триггера или (что, то же самое) его текущее и будущее состояния.
Рассмотрим названные особенности более подробно.
Известно, что асинхронная установка и сброс триггера имеют наиболее высокий и, что самое неприятное, равный между собой приоритет. Например, если на входы триггера одновременно приходят команды тактируемой записи «1» и асинхронного сброса, то триггер реагирует на более приоритетную из них и устанавливается в «0».
Но если одновременно подать равноприоритетные и противоречивые по действию команды асинхронной установки и сброса, то триггер окажется перед неразрешимой дилеммой, кого из двух «равновеликих начальников» предпочесть.
Такие комбинации входных сигналов называют запрещёнными, но не потому, что триггер «растерялся» и не знает, что делать. Любой реальный TTL-триггер отреагирует на подобные «издевательства» вполне определённым образом, установив на обоих выходах одинаковые значения Q = NQ = 1, которые экспериментатору предлагается интерпретировать как сигнал «бедствия».
Вы можете возразить, что ничего страшного в этом нет. Ведь такие состояния, правда, кратковременно возникают всегда, когда триггер меняет своё состояние на противоположное.
В действительности опасность заключается не в том, что триггер «сломался» и перестал выдавать парафазный сигнал, а в том, что при выходе из запрещённого режима в режим хранения он устанавливается в одно из двух возможных для него состояний случайным образом. Поэтому дальнейшее поведение моделируемой схемы становится не предсказуемым.
При разработке моделей триггеров следует решить для себя вопрос, насколько глубоко и точно надо отражать в модели описанные процессы. Надо ли моделировать случайное поведение объекта, обращаясь к датчикам псевдослучайных чисел или достаточно просто «отлавливать» запрещённые комбинации входных сигналов и сообщать пользователю, в какой момент времени и на каком триггере они обнаружены. Можно предусмотреть режим остановки моделятора при обнаружении такой ситуации.
Динамическое управление записью означает, что триггер открывается для приёма новой информации только на короткое время, когда формируется фронт или спад сигнала синхронизации.
В структурных моделях триггеров всё происходит само собой, естественным образом и никаких особых действий не требуется. Для поведенческих моделей триггеров надо контролировать значения сигналов синхронизации и фиксировать моменты их переключения.
Если в алфавите моделей цифровых сигналов имеются значения типа фронт (, /, R) или спад (¯, \, F), то никаких дополнительных проблем не возникает. В противном случае придётся завести для сигнала синхронизации не одну, а две переменных и сравнивать текущее и старое состояние этого сигнала, чтобы не пропустить момент его переключения.
Булевские модели триггеров, не учитывающие в явном виде временные задержки, могут преподнести ещё один неприятный сюрприз. Предположим, нам надо смоделировать работу трёхразрядного регистра сдвига вправо (рис.2).
Если для выходных сигналов Q1, Q2 и Q3 в моделях триггеров определено только по одному контейнеру, то его содержимое будет обновляться сразу же, как только моделятор вычислит текущее значение переменной.
Допустим, что регистр сброшен в «0» сигналом RESET, а затем пришла команда сдвига SHIFT (а точнее, её задний фронт). Результат моделирования должен получиться таким: Q1=1, Q2=0, Q3=0. Однако это произойдёт только в том случае, если моделятор будет вызывать модели триггеров в порядке справа налево, то есть сначала обработает триггер DD3, потом DD2, и, наконец, DD1. Если вызовы моделей будут происходить в обратном порядке, то результат окажется неверным: Q1=Q2=Q3=1. Это произошло потому, что, моделируя триггер DD2, программа использовала обновлённые значения на выходах триггера DD1 (Q1 = 1 и NQ1 = 0). То же самое происходит и с триггером DD3.
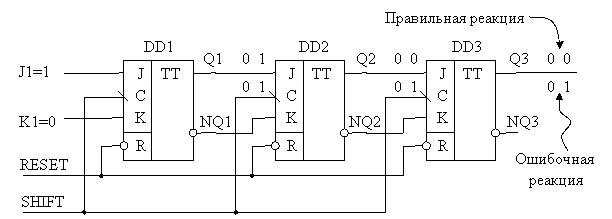 |
Рис. 2. Недостаточное видение проблем создания булевских моделей
триггеров может привести к серьёзным ошибкам моделирования
Понятно, что результат моделирования не должен зависеть от порядка обработки элементов схемы. Этого можно достичь, если для каждого выхода триггера зарезервировать не один, а два контейнера. Первый должен сохранять старое (текущее), а другой новое (только что вычисленное, будущее) значение триггера. При этом пока не будут обработаны все элементы схемы, моделятор должен использовать старые значения. Закончив очередной цикл работы, моделятор продвинет модельное время на один такт, и перепишет содержимое всех контейнеров. Будущие значения станут текущими, а контейнеры для будущих значений освободятся и их можно использовать для новых результатов.
Итак, модели триггеров строятся многими способами:
§ из отдельных вентилей в виде структурных моделей;
§ в форме характеристического уравнения (поведенческая аналитическая модель);
§ в виде блок-схемы алгоритма (поведенческая алгоритмическая модель).
Рассмотрим названные разновидности моделей на примере стробируемого RS-триггера, показанного на рис. 1.
Ранее (лекция 8) мы уже отмечали, что модель цифровой схемы можно представить системой булевских уравнений: для каждого логического элемента - своё уравнение. Порядок записи уравнений в системе может быть произвольным и это не должно влиять на результаты моделирования, хотя интуитивно понятно, что они должны следовать в порядке срабатывания реальных элементов в реальной схеме.
В таблице 1 показано, как может выглядеть булевская модель стробируемого RS-триггера, показанного на рис.1,б. Уравнения записаны в произвольном порядке в формате языка моделирования PML пакета PCAD.
В исходном состоянии (такт Т0) на входы триггера подан пассивный набор сигналов (S = C = R = 0). Триггер находится в режиме хранения, и для определённости примем, что в нём записана «1» . Если просчитать систему булевских уравнений для названных условий, то будет ещё раз подтверждён вектор 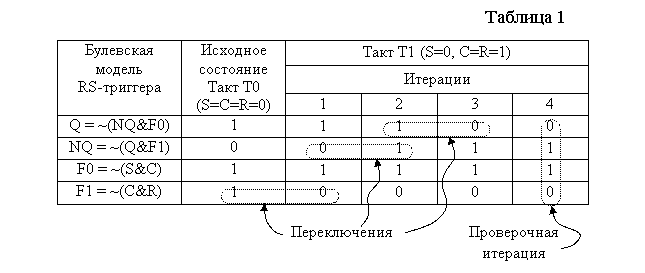
исходного состояния на всех четырёх выходах (Q=1, NQ=0, F0=1, F1=1).
В следующем цикле работы моделятора (такт Т1) на входы триггера подаётся набор входных сигналов (S=0, C=R=1), который должен сбросить его в состояние «0». Однако, выполнив первый прогон модели (третий столбец таблицы), мы обнаруживаем, что результаты моделирования не соответствуют действительности: на выходе по-прежнему Q = 1. Правильно переключился лишь выход F1.
Моделятор сравнивает полученный вектор результатов с предыдущим (в данном случае с вектором исходного состояния) и убеждается, что они не совпадают. Это означает, что итерационный процесс вычисления результата моделирования на текущем такте не закончен, и следует повторить прогон модели.
Заметим, что повторные прогоны модели осуществляются для одного и того же набора входных данных (в нашем примере – для такта Т1). Понятно, что и модельное время остаётся прежним.
Повторные прогоны модели на неизменном наборе входных данных называются итерациями. Они длятся до тех пор, пока не совпадут результаты двух соседних итераций, что свидетельствует об окончании переходных процессов в моделируемой схеме. В нашем примере – это третья и четвёртая итерации. Последняя итерация не даёт никаких новых результатов, но она нужна, чтобы убедиться в окончании вычислительного процесса на текущем такте. По этой причине её называют проверочной итерацией.
Итерационный характер получения результатов моделирования является серьёзным недостатком рассмотренного метода, так как в несколько раз увеличивает общее время модельного эксперимента. В дальнейшем мы узнаем, что ранжированием цифровых схем можно существенно уменьшить требуемое число итераций, а для комбинационных схем и вовсе избавиться от них.
Добавим, что в современных АСМ, использующих событийный метод моделирования и модели элементов, учитывающие временные задержки, об итерациях можно вспоминать лишь как о кошмарных пережитках недалёкого прошлого.
Подводя итог обсуждению структурных моделей триггеров, можно констатировать, что они имеют два серьёзных недостатка:
§ длительное время моделирования из-за низкоуровневого описания (на уровне логических вентилей);
§ наличие итераций, то есть многократных прогонов модели на неизменном наборе входных данных, что в конце концов приводит к тому же результату – дополнительным временным затратам на моделирование.
К достоинствам структурных моделей триггеров следует отнести их повышенную точность и универсальность. Они позволяют без всяких «наворотов» имитировать неисправности отдельных элементов структуры, наблюдать реакцию схемы на запрещённые наборы входных сигналов, не беспокоиться о том, имеет ли триггер динамическое управление и как его отобразить в модели.
Аналитическая модель триггера представляет собой его характеристическое уравнение. Для рассматриваемого в качестве примера стробируемого RS-триггера она выглядит следующим образом:
при выполнении условия S*R = 0:
QNEW = S*C + QOLD* ~(R*C),
NQNEW = ~QNEW.
Здесь:
QNEW – новое (будущее) состояние триггера;
QOLD – старое (текущее) состояние триггера;
S, C, R – значения входных сигналов для текущего момента модельного времени;
символы «*», «+» и «~» означают соответственно логические операции конъюнкции, дизъюнкции и отрицания.
Условие S*R = 0 весьма важно. Нарушение его означает, что триггер оказался в запрещённом режиме, где приведённые уравнения недействительны.
Убедимся, что расчёты по характеристическому уравнению дают правильные результаты.
В исходном состоянии (такт Т0) S = C = R = 0 и триггер хранит «1», то есть QOLD = 1, а NQOLD = 0. Условие S*R = 0 выполняется, значит, уравнения «работают». Подставляя названные значения в характеристическое уравнение триггера, подтверждаем его исходное состояние:
QNEW = S*C + QOLD* ~(R*C) = 0*0 + 1*~(0*0) = 1.
NQNEW = ~QNEW = 0.
В следующем такте Т1 S = 0, а C = R = 1, то есть триггер должен сброситься в «0». По-прежнему условие S*R = 0 выполняется, следовательно, уравнениями можно пользоваться:
QNEW = S*C + QOLD* ~(R*C) = 0*1 + 1*~(1*1) = 0.
NQNEW = ~QNEW = 1.
Как видим, модель даёт правильные результаты, причём за один просчёт уравнений и без всяких итераций. Это основное достоинство рассмотренного типа моделей триггеров – она работает быстро. Кроме того, привлекательной выглядит и простота модели.
Однако, недостатки этой модели, пожалуй, перевешивают все её достоинства. Во-первых, область её действия ограничена выполнением условия S*R =0, которое надо проверять всякий раз перед вызовом модели. Для триггеров с динамическим управлением приходится проверять выполнение ещё одного условия – появления фронта или спада на входе сигнала синхронизации.
Во-вторых, многие детали в поведении реального объекта такая модель просто игнорирует, а моделирование неисправностей и вообще исключается.
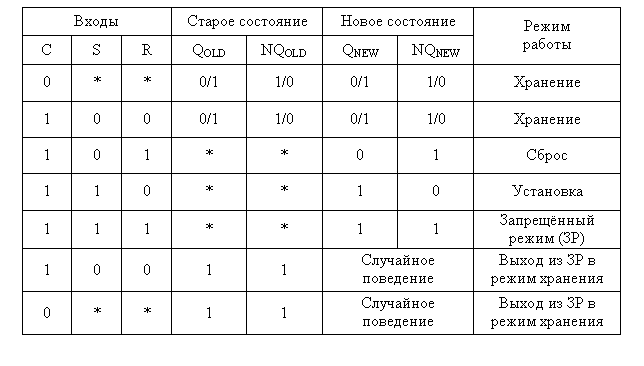
Алгоритмическая модель триггера строится по его логической таблицы, называемой также таблицей переходов. Она отражает поведение триггера на разных наборах входных сигналов, а построенная по ней модель фактически имитирует это поведение. По этой причине такую модель называют также имитационной.
Для рассматриваемого стробируемого RS-триггера названная таблица выглядит так, как показано на рис.3.
Символ звёздочка «*», поставленный в некоторых ячейках таблицы означает, что в данной позиции может стоять либо «0» либо «1» и от этого новое состояние триггера не зависит. Комбинация сигналов S = C = R = 1 переводит элемент в запрещённый режим.
Две нижние строки таблицы несут информацию о том, что триггер оказался в запрещённом режиме (QOLD = NQOLD = 1) и на текущем наборе входных сигналов переходит в режим хранения (C = 1, S = R = 0 или C = 0, S = * и R = *). В этом случае на выходах триггера возникают гонки, и он случайным образом принимает одно из двух возможных состояний. Чтобы отразить в модели случайное поведение, потребуется датчик псевдослучайных чисел (ДПСЧ).
Допустим, в нашем распоряжении имеется датчик, который генерирует числа в диапазоне 0…1 по равномерному закону распределения. Если считать, что установка и сброс триггера равновероятны, то можно принять такое решение: когда выданное датчиком случайное число j окажется меньше 0,5, будем сбрасывать триггер в «0», в противном случае – устанавливать его в «1».
Рис. 3. Полная таблица переходов стробируемого RS-триггера
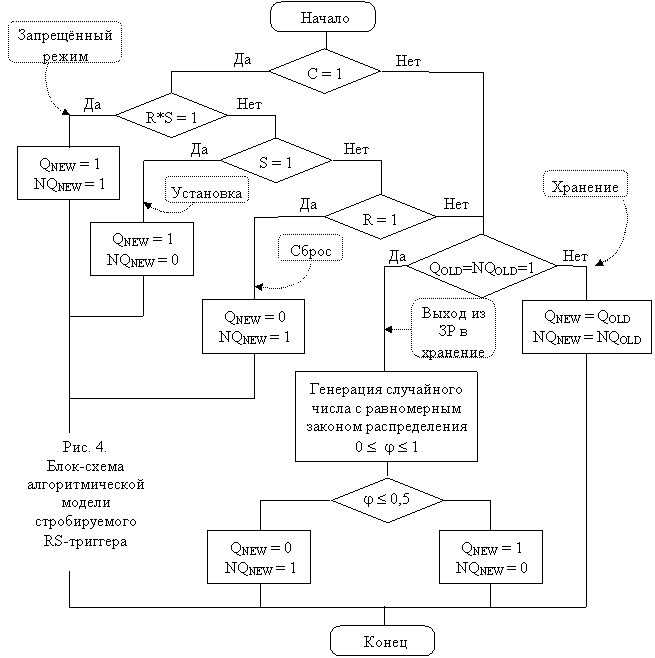
Блок-схема алгоритма, имитирующего поведение рассмотренного RS-триггера, показана на рис. 4.
ЛекцияТабличное представление цифровой схемы
Существуют три способа описания структуры моделируемого объекта:
§ графическое описание в форме принципиальной, функциональной или структурной схемы;
§ текстовое описание в виде списков элементов и цепей;
§ табличное описание, содержащее ту же самую информацию об элементах и цепях, но задаваемую в виде таблиц и ссылок.
Покажем на примере двухвходового цифрового мультиплексора различные способы представления моделируемого объекта (рис. 5). Заметим, что во всех случаях речь идёт о структурных моделях, в которых объект представляется в виде системы, состоящей из отдельных взаимосвязанных фрагментов, называемых структурными примитивами.
Разновидности описаний для поведенческих моделей нам уже известны – это булевские уравнения (аналитические модели) и алгоритмические описания в виде блок-, граф- или операторных схем (имитационные модели). Возможно также словесное или табличное описание поведения объекта, например - логические таблицы.
Графическое описание в данном примере представляет собой функциональную схему (рис.5,а), на которой в обязательном порядке должны быть проставлены уникальные имена элементов (DD1…DD4) и цепей (INP1, INP2, ADR, F1, F2, F3, OUT1).
 |
Текстовое описание (рис. 5,б) составлено по функциональной схеме в виде системы булевских уравнений (они записаны в формате языка VHDL). Обратите внимание, что в описании отсутствуют имена элементов DD1…DD4. Это означает, что структура объекта представлена списком цепей, а точнее сигналов, действующих на данных цепях. Тем не менее, неявно элементы присутствуют в описании, ведь именно они определяют функции not, and и or, выполняемые над сигналами.
Существует ещё один альтернативный способ описания структуры, которая задаётся списком элементов в явном виде, а цепи указываются неявно. И только по одинаковым именам сигналов можно понять, что они действуют на одной и той же цепи, то есть в действительности эти точки соединены электрическим проводником. В качестве примера такого описания назовём SPICE-описание структуры в САПР DesignLab 8 (разговор о нём ещё впереди).

Рис.5. Способы структурного описания цифрового мультиплексора
Для наглядности представим «список» элементов сначала в графической форме (рис.5,в), а затем преобразуем его в табличное описание (рис.5,г). Такое описание кажется менее наглядным, но оно легко транслируется во внутреннюю структуру данных (в связный список) и потому удобно для компьютерной обработки.
Показанная на рис.5,г таблица хороша только для визуального восприятия. При попытке программной реализации обнаруживаются все её недостатки и, прежде всего, неэффективное использование оперативной памяти «по максимуму» (ориентация на максимальное число элементов, максимальное число входов, максимальную длину имени).
Для создания гибких структур данных, то есть таких структур, размеры и организация которых динамически изменяются, очень удобно использовать указатели (ссылки). Характерным примером такой структуры являются уже упоминаемые нами вскользь связные списки.
На рис.6 показано использование указателей для связывания списков элементов и списков сигналов (соединений). В отличие от таблицы, показанной на рис.5,г, в двух правых столбцах указываются не имена сигналов, а только их адреса (номера строк) в таблице соединений.
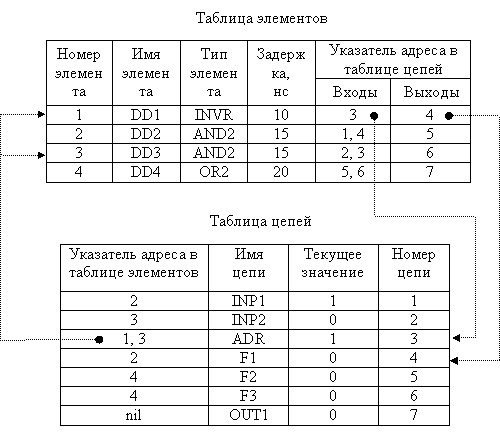 |
Рис.6. Табличное описание цифрового мультиплексора с использованием указателей
Например, для элемента DD1 по ссылке 3 легко найти имя сигнала ADR, действующего на его входе, а по ссылке 4 – имя выходной цепи F1, на которую работает данный элемент.
В таблице соединений задаётся полный список всех цепей, включая входы INP1, INP2, ADR, выход OUT1 и внутренние связи F1, F2, F3. Здесь же могут храниться и текущие значения сигналов для всех цепей (столбец 3).
В принципе приведённой информации вполне достаточно, чтобы промоделировать работу любой схемы. Простейшие способы моделирования (лекция 10) предлагают обрабатывать все элементы схемы в том порядке, как они записаны в таблице элементов.
Моделятор выбирает из таблицы первый элемент с именем DD1, находит имя сигнала ADR на его входе и его текущее значение ADR = 1. Затем он выясняет тип этого элемента и вызывает соответствующую подпрограмму INVR, передавая в неё входные данные. Отработав, подпрограмма возвращает моделятору вычисленное значение выходного сигнала, которое он присваивает выходной цепи F1.
Затем из таблицы считывается имя следующего элемента DD2, и повторяются те же самые действия, пока не будет исчерпан весь список. После этого модельное время продвигается на один шаг (такт) и моделятор выполняет следующий цикл, обрабатывая реакцию схемы на новый набор входных данных.
Для моделирования всех однотипных элементов используется одна и та же подпрограмма. В нашем примере модель AND2 для двухвходовой схемы 2И будет вызвана дважды, сначала для обработки элемента DD2, а затем - элемента DD3.
Метод обработки всех элементов схемы и в неизменном порядке нельзя назвать эффективным. Допустим, что в текущий момент времени переключается только вход INP1 мультиплексора (рис.5,а), а входы INP2 и ADR сохраняют свои старые значения. Это означает, что элементы DD1 и DD3 не изменят своих состояний. Спрашивается, зачем их моделировать, если в результате мы не получим ничего нового?
Отсюда следует вывод, что если находить и обрабатывать только те элементы, на входах которых обнаружены переключения (события), то можно существенно повысить эффективность моделирования. Тем более что таких элементов совсем не много (по различным оценкам менее 2…10% от общего объёма схемы).
Вот для этих целей и нужна левая часть таблицы цепей, а точнее её первый столбец. В нём задаются ссылки на таблицу элементов, по которым моделятор находит элементы-приёмники данного сигнала. Например, чтобы узнать, на какие элементы «работает» вход ADR, достаточно заглянуть в левый столбец и по ссылкам 1, 3 найти в таблице элементов имена приёмников DD1 и DD3.
Аналогичным образом для сигнала F2 по ссылке 4 находится его элемент-приёмник DD4. Но ведь сигнал F2 формируется выходом элемента DD2. Следовательно, указатель 4 описывает в действительности электрическое соединение между выходом DD2 и входом DD4.
Вернёмся к ранее рассмотренной ситуации, когда в текущем цикле работы моделятора переключается только сигнал INP1. В таблице цепей (столбец 1) сообщается, что этот сигнал воздействует только на один элемент.
Следовательно, моделятору надо найти и промоделировать один единственный элемент-приёмник (последователь) этого сигнала. По ссылке 2 в таблице элементов выясняется имя искомого элемента – DD2. А дальше всё происходит по уже известным нам правилам. Получив новое (будущее) значение выходного сигнала F2, моделятор сравнит его с текущим значением и выяснит, распространится ли переходной процесс на элемент DD4.
Выход элемента DD4 подключён к внешней цепи OUT1, то есть вообще не имеет последователей (значение указателя равно nil - никакой). Таким образом, переключения в схеме закончатся, как только будут достигнуты её внешние выходы. Более подробно рассмотренная технология моделирования обсуждается в лекции 11.
Мы рассмотрели один из простейших способов табличного описания моделируемой схемы. В действительности использование указателей гораздо шире, чем это показано на рис.6. Чтобы сделать работу со структурами данных более эффективной, в описание добавляют ещё две таблицы: таблицу входных и таблицу выходных соединений (рис.7). Для простых схем подобные нагромождения могут показаться «архитектурными излишествами», однако для сложных схем они вполне оправданы.
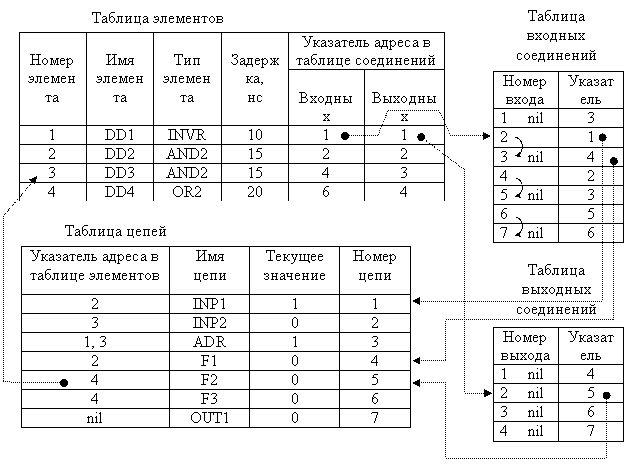 |
Рис.7. Улучшение структуры данных с помощью дополнительных
таблиц входных и выходных соединений
Иногда информация о самих элементах (выполняемая функция, задержки, имена контактов) представляется в виде отдельной таблицы, и на неё задаются соответствующие ссылки. Предлагаем Вам самостоятельно выполнить эту работу, несколько модифицировав описание, показанное на рис.7.
Понятно, что любой вид описания содержит фактически одну и ту же информацию о структуре объекта и может быть конвертирован из одной формы представления в другую без особых проблем. Например, по табличному описанию объекта Вы без труда сумеете восстановить его функциональную схему.
Заканчивая разговор о табличном представлении модели цифровой схемы, заметим, что такое описание имеет ещё одно достоинство – простоту внесения изменений в моделируемую схему. Изменяя ссылки, фактически отражающие пути прохождения сигналов, Вы без труда сможете отлаживать свою схему, пока она не заработает так, как Вам этого хочется.
