


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Категориальный анализ в задачах
принятия управленческих решений
1, 1, 1, 2
1Поволжский государственный университет телекоммуникаций и информатики
Самара, , Россия
*****@***ru
тел: +7 (8, факс: +7 (8
2Институт проблем управления сложными системами РАН
Самара, ул. Садовая, 61, Россия
*****@***ru
тел: +7 (8, факс: +7 (8
Ключевые слова: категориальный анализ, свойства и категории качества объектов, идентификация объектов, сегментирование, байесовская вероятность
Abstract
The questions of the object’s identification of “hidden essence” in the problems of management decision making are considered. A category analysis over of object’s properties on the basis of Bayesian approach is produced. The algorithm for identifying objects is presented.
Введение
Существует класс трудно формализуемых задач, связанных с идентификацией скрытой сущности объекта. Под термином «скрытая сущность» подразумеваются особые черты объекта (например, личностные свойства индивида, его склонности к определенным поступкам, его соответствие сложившейся ситуации и т. п.). Эти и аналогичные им стороны объекта, как правило, не лежат на поверхности и в то же время они в определенных ситуациях весьма важны для принятия управленческих решений, связанных с этим объектом.
Задачи идентификации скрытой сущности многочисленны и могут принадлежать разным предметным областям, например:
· выдача кредитов клиенту банка (идентификация порядочности клиента);
· оценка лояльности и оттока клиентов телекоммуникационной компании;
· соответствие должности, занимаемой объектом (идентификация соответствия);
· достоверная оценка качества продукции;
· выявление авторства неизвестного текста;
· идентификация спама;
· определение диагноза болезни по набору признаков (симптомов) и др.
Порядочность, лояльность, достоверность, соответствие, адекватность, − все это виды скрытой сущности, которая должна быть оценена не только качественно, но и количественно. Формирование такой оценки обычно связывают с вероятностной мерой, что определяет наличие реальных рисков ошибочной идентификации объекта. Насколько конкретный объект соответствует его имиджу, реальный ли это имидж или мнимый − ответ на эти вопросы имеет важное, а иногда решающее значение.
В качестве объекта может выступать фирма (предприятие), клиент, техническая система и т. п. Не умаляя общности можно утверждать, что особое значение методы идентификации скрытой сущности приобретают для задач, в которых объектом исследования является человек как представитель определенного социума (клиент компании, сотрудник предприятия), как носитель болезни, обладатель определенных знаний и т. п.
Скрытую сущность объекта трудно оценить, - традиционные математические модели идентификации в этих задачах редко оказываются полезными, здесь чаще используются такие методы как поиск прецедентов, формирование «кредитных историй», выявление достоверных фактов, сравнение с аналогами и т. п. Использование этих и им подобных методов в совокупности приводит к формированию общего многогранного имиджа объекта, собранного из разнородных сведений, данных, косвенных признаков и неочевидных связей.
История этого направления восходит к концепциям экспертных систем [1], дискриминантного анализа и проверки гипотез, методам Data Mining [2] и т. п.
В отличие от этих традиционных направлений мы рассматриваем категориальный анализ как средство получения результатов путем «слепого» поиска на множестве свойств объекта прямых и косвенных признаков, присущих объекту, и анализа стереотипов.
Концептуальная основа категориального анализа строится на постулате, что набор таких свойств и признаков неявно связан с идентифицируемой сущностью объекта, причем, чем более представительным является этот набор, тем сильнее такая связь.
1 Свойства и категории качества объектов
В основу категориального анализа ложится состояние объекта, характеризуемое перечнем (обычно статическим) всех свойств данного объекта и текущими (обычно динамическими) значениями каждого из этих свойств, которые могут быть как присущи объекту, так и приобретены с течением времени. Именно эти свойства делают объект индивидуальным, особенно если в качестве объекта рассматривается клиент. Позиционирование такого объекта и составляет задачу идентификации скрытой сущности.
Любой объект характеризуется свойствами и категориями качества. Свойства характеризуют общие черты объекта, например, «запах», «цвет», «возраст» и т. п. Категории определяют значения качества свойств (например, «резкий» запах, «красный» цвет, «пожилой» возраст). Чем больше свойств и категорий качества участвуют в описании объекта, тем конкретнее описан объект, тем он определеннее, тем полнее его описание. Свойства и категории качества объектов рассматриваются как основные черты, характеризующие его с разных точек зрения. Например, свойство «отцовства» − объект (отец) имеет детей (является отцом). При этом качество «отцовства» характеризуется количеством детей. Такого рода качество имеет несколько категорий: многодетный отец, малодетный отец, бездетный отец и т. п.
Любое свойство несет в себе определенную информативность, если, например, рассматривается возможность использования конкретного индивида в качестве водителя автобуса, то свойства «Пол» (иметь пол) и «Возраст» имеют интуитивно бóльшую информативность, чем свойство образованности («Образование»).
Свойства объекта могут быть тесно связаны с интересами компании (например, материальное состояние клиента или количество иждивенцев). Свойство обладания материальными ценностями является очень важным для, например, выдачи кредита, в то же время свойство образованности клиента для этой ситуации может играть второстепенную роль. Все резко меняется, если кредит выдается в виде гранта для продолжения научной работы.
Главное и второстепенное в категориальном анализе подвержено резким изменениям, в некоторых случаях фактор изменчивости понятий может полностью изменить оценку сущности, в этом состоит особая важность изучения свойств, когда второстепенные на первый взгляд свойства в определенных ситуациях могут стать важнее тех, которые считаются основными.
Кроме того свойства и категории можно разделить на очевидные и неочевидные. Очевидные характеризуются тем, что объекту можно поставить в соответствие значение категории качества. Например, мы знаем, что возраст объекта имеет значение «пожилой». Неочевидные свойства таковы, что мы не можем уверенно поставить в соответствие объекту значение категории качества, но субъективно мы можем оценить такое значение, используя субъективные вероятности, характеризующие отношения между категориями в свойстве.
Совокупность свойств и категорий качества, используемых в задачах категориального анализа, в общем случае целесообразно представить в виде таблицы с буквенно-индексными обозначениями категорий (таблица 1), где каждое свойство объекта определено совокупностью категорий качества (в каждой строке число категорий больше единицы).
Таблица 1 – Свойства и категории качеств
Свойства | Категории качества | |||||
1 | 2 | … | m | … | M | |
1 |
|
| … |
| … |
|
2 |
|
| … |
| … |
|
… | … | … | … | … | … | … |
N |
|
| … |
| … |
|
Верхний индекс в записи ![]() идентифицирует свойство, нижний – категорию качества, присущую объекту, подчеркивание определяет выбранную категорию соответствующего свойства. Выбор категории качества интерпретируется как категориальное событие – конкретный факт индивидуальной характеристики объекта (ИХО).
идентифицирует свойство, нижний – категорию качества, присущую объекту, подчеркивание определяет выбранную категорию соответствующего свойства. Выбор категории качества интерпретируется как категориальное событие – конкретный факт индивидуальной характеристики объекта (ИХО).
Категории в любой строке таблицы альтернативны, т. е. они образуют полную группу несовместных категориальных событий. Любая строка таблицы свойств и качеств может быть расширена путем введения более «тонких» категорий или сокращена введением более «грубых».
Для каждого свойства должна быть выбрана только одна категория качества. Формируемый при этом набор категорий интерпретируется как совокупность фактов, определяющих ИХО. Для таблицы 1 такой набор может быть представлен следующим образом:
(1) ![]() .
.
Категории качества в этом наборе конъюнктивны (совместные категориальные события).
Набор категорий качества должен характеризовать объект с разных точек зрения, чем богаче и разностороннее этот набор, тем выше достоверность оценки скрытой сущности объекта.
ИХО представляет собой не только характеристику одного отдельно взятого объекта, - в общем случае эта аббревиатура представляет собой стереотип, который рассматривается как множество объектов с одинаковыми ИХО.
Особое значение в этих рассуждениях отводится понятию «скрытая сущность» и её категории качества. Например, сущностное свойство клиента банка - «Претендовать на получение кредитов». В этой ситуации важно знать сущность клиента, – к какой категории его отнести: либо его следует охарактеризовать как исправного плательщика, аккуратно оплачивающего долг, либо оценивать его как ненадежного плательщика. В этом примере имеем две категории сущности:
1) «неплательщик» или
2) «надежный плательщик».
Отметим, что эти категории альтернативны, т. е. с позиций теории вероятностей они образуют полную группу несовместных событий. Множество объектов – заемщиков, попадающих в соответствующую категорию сущности (1 или 2), будем называть сегментом. В общем случае сегмент Sg – это совокупность объектов, принадлежащих одной из категорий сущности. В этом примере имеем две категории сущности и соответственно два сегмента, в общем случае количество сегментов может быть и другим, бóльшим 2-х, но поскольку сущностные категории всегда альтернативны, любой объект может попасть только в один из рассматриваемых сегментов.
2 Посегментная статистика свойств и категорий
Посегментная статистика свойств и категорий качеств существенно расширяет структуру таблицы 1 в двух направлениях (таблица 2):
1) путем введения «карманов» ![]() для статистических данных по каждой категории качества
для статистических данных по каждой категории качества ![]() .
.
2) путем формирования статистики свойств и категорий для каждого сегмента ![]() .
.
Таблица 2 - Посегментная статистика свойств и категорий качеств для сегмента ![]()
Свойства | Категории качества | Объем выборки | ||||
1 | 2 | … | m | M | ||
1 |
|
| … |
|
| ─ |
|
| … |
|
|
| |
2 |
|
| … |
|
| ─ |
|
| … |
|
|
| |
… | … | … | … | … | … | … |
… | … | … | … | … | … | |
N |
|
| … |
|
| ─ |
|
| … |
|
|
|
В каждом из выше упомянутых карманов содержится сумма объектов ![]() , попавших в статистику соответствующих категорий. Поскольку для каждого i-ого свойства статистика формируется на одном и том же множестве объектов, очевидно условие:
, попавших в статистику соответствующих категорий. Поскольку для каждого i-ого свойства статистика формируется на одном и том же множестве объектов, очевидно условие:
(2) ![]() .
.
Таблица 2 представляет сегмент ![]() , для других сегментов используются аналогичные по форме таблицы, но статистика, собираемая в них, для различных сегментов отличается.
, для других сегментов используются аналогичные по форме таблицы, но статистика, собираемая в них, для различных сегментов отличается.
Отношение
(3) ![]()
интерпретируется как наполняемость соответствующей категории (соответствующего «кармана»). В то же время эти отношения определяют эмпирические вероятности (частости) категориальных событий.
Интуитивно ясно, что чем больше статистика одного сегмента (например «Надежный плательщик») отличается от статистики другого («Неплательщик»), тем с большей вероятностью можно идентифицировать скрытую сущность объекта. Худший случай, когда статистика сегментов не имеет существенных различий. Для того чтобы провести надежную идентификацию, необходимо априори сформулировать наиболее информативные свойства, несвязанные друг с другом, кроме того, их число должно быть достаточно велико.
Формирование посегментной статистики может проводиться с использованием обучающей выборки объектов, заранее классифицированных с высокой степенью достоверности. Отсутствие такой выборки в отдельных случаях можно заменить введением дополнительных свойств и категорий качества.
Таблица 2 может иметь и иную структуру, например, в «карманах» могут размещаться непосредственно отношения типа (3) или субъективные вероятности [3], - смысловое содержание таблицы при этом остается прежним.
При использовании отношений (3) для любого i-го свойства в соответствии с альтернативностью категорий и отношением (2) выполняется условие нормировки:
![]() .
.
Вероятности ![]() следует рассматриваться как условные, то есть относящиеся к категориальным событиям в конкретном сегменте
следует рассматриваться как условные, то есть относящиеся к категориальным событиям в конкретном сегменте ![]() :
: ![]() , причём для всех
, причём для всех ![]() и для любого i
и для любого i 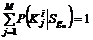 .
.
3 Алгоритм идентификации объекта
Система сегментов ![]() (n = 1,2,…,L) может быть представлена условными эмпирическими вероятностями
(n = 1,2,…,L) может быть представлена условными эмпирическими вероятностями 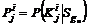 ,
, ![]() ;
; ![]() , которые в совокупности образуют многомерный информационный образ сегмента. Каждый сегмент имеет собственный образ, отличающийся от остальных.
, которые в совокупности образуют многомерный информационный образ сегмента. Каждый сегмент имеет собственный образ, отличающийся от остальных.
Посегментная статистика свойств и категорий, которую образуют эти образы, рассматривается как статистическая база данных.
Кроме статистики свойств и категорий в каждом из сегментов, имеется набор априорных вероятностей по сегментам. Эти две компоненты являются основой для выявления скрытой сущности объекта.
В качестве меры «тяготения» объекта к соответствующему сегменту предлагается использовать байесовскую вероятность [4], которая интерпретируется как оценка влияния свойств и категорий объекта (фактов ИХО) на апостериорную вероятность. Таким образом, ИХО рассматривается как основной компонент, влияющий на «превращение» априорной вероятности тяготения в апостериорную.
Несмотря на множество различных технологий по выявлению скрытой сущности объекта (и в первую очередь Data Mining), полагаемся на широко известное мнение, что, «несмотря на простоту байесовских процедур, результаты их работы могут превзойти результаты работы более сложных алгоритмов классификации».
Собственно пересчёт априорных вероятностей в апостериорные на основе фактов, входящих в ИХО, реализуется хорошо известной формулой Байеса [5], которая при введенных выше обозначениях выглядит следующим образом:
(4) 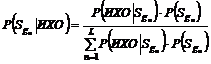 .
.
В формуле (4) ![]() – априорные вероятности попадания клиента в сегмент
– априорные вероятности попадания клиента в сегмент ![]() ,
, ![]() – условные вероятности тяготения объекта к сегменту
– условные вероятности тяготения объекта к сегменту ![]() при условии, что ИХО является фактом,
при условии, что ИХО является фактом, ![]() – обратная вероятность (вероятность наличия фактов ИХО в сегменте
– обратная вероятность (вероятность наличия фактов ИХО в сегменте ![]() ).
).
Необходимо отметить, что формула (4) предполагает, что параметры в наборе ИХО независимы. Таким образом, предположение независимости свидетельств позволяет записать:
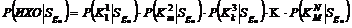
Отсюда (4) примет вид:
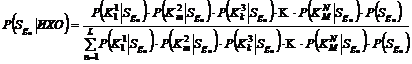 .
.
Одним из показателей адекватности выдвигаемых предположений в соответствии с представленной методологией категориального анализа может выступать траектория изменения априорной неопределённости, которая показывает зависимость апостериорной вероятности от последовательно представляемых условий (набора ИХО). Данная траектория показывает, как происходит изменение апостериорных вероятностей в соответствии с алгоритмом пересчёта и последовательном представлении условий при приближении к результату. Причём наиболее достоверный результат будет в том случае, когда траектория распределения апостериорных вероятностей в зависимости от факторов, влияющих на результат, будет наиболее «гладкой». Например, в результате пересчёта получили, что из 5-и предъявляемых ИХО вероятность принадлежности объекта к сегменту при 2-ом условии равна 0.1, а вероятности при предъявлении остальных ИХО изменяются в пределах от 0.4-0.6. Результат 2-го условия резко изменяет траекторию апостериорной вероятности, что сказывается на достоверности полученного результата. Анализ подобного рода траектории изменения априорной неопределенности позволит визуально охарактеризовать изменения априорной вероятности с учётом предъявляемых ИХО и сделать вывод о предъявляемом наборе условий и об адекватности полученных результатов пересчёта в целом.
Заключение
Таким образом, в развиваемом подходе основой категориального анализа является общая и посегментная статистика объектов, дифференцированная по секторам, свойствам и категориям. Наличие и представительность такой статистики определяет достоверность оценки скрытой сущности объекта на основе свойственных для него фактов и косвенных признаков как по отдельности, так и в совокупности.
Формула (4) предполагает независимость свойств, входящих в ИХО. Вместе с тем это предположение нередко выглядит весьма ограничительным. Например, зависимость свойства «Образование» от свойства «Возраст» (чем больше возраст, тем вероятнее наличие высшего образования). На основе предположения о независимости свойств строится так называемый наивный байесовский классификатор [6], который использует прямое произведение вероятностей категориальных событий. Такое предположение характеризуется линейной сложностью процедуры байесовской классификации, отсутствие независимости свойств придает этой процедуре экспоненциальную сложность.
Следует также отметить, что категориальный анализ, основанный на вероятностном подходе, позволяет не только количественно оценить принадлежность объекта к определённому сегменту, но и дополнить имеющуюся базу новыми апостериорными значениями по новым объектам. Кроме того, подобного рода анализ является универсальным, так как внесение каких-либо новых переменных не изменяет принцип анализа, а лишь усложняет определение условных вероятностей в связи с увеличением исследуемых факторов. Вместе с тем такой перерасчёт способен значительно увеличить информативность процесса получения новых знаний на основе основного свойства информации – её аддитивности.
Кроме того, при идентификации объекта важно оценить вклад каждого отдельного взятого свойства в изменение апостериорной вероятности принадлежности объекта сегменту. Такие вклады позволяют ранжировать влияние того или иного свойства на оценку скрытой сущности.
Список литературы
[1] Балтрашевич В. Э Реализация инструментальной экспертной системы. – СПб.: Политехника, 1997.
[2] Назначение систем Data Mining [Электронный ресурс]. – Режим доступа: http://www. *****/journal/articles/276.html, свободный. – Загл. с экрана.
[3] Бернштейн сочинений. Т.4. Теория вероятностей. Математическая статистика. – М.: Гостехимиздат, 1964.
[4] Байесовские процедуры классификации: Вводный обзор [Электронный ресурс]. – Режим доступа: http://www. *****/DMS/Machine%20Learning/MachineLearning/Overv iews/NaiveBayesClassifierIntroductoryOverview%20.htm, свободный. – Загл. с экрана.
[5] Кораблин М. А., Мелик-Шахназаров А. В., Салмин лояльности клиентов телекоммуникационной компании на основе байесовского подхода // Информационные технологии. 2006. №4. - С. 63–67.
[6] Hastie T., Tibshirani R., Friedman J. The Elements of Statistical Learning. — Springer, 2001.
