
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Лекция № 11
Метод вставок.
При использовании этого метода сортировки упорядоченная последовательность создается на свободном участке памяти. Под сортировку выделяется объем памяти, равный длине отсортированного массива записей.
Элементы исходной последовательности обозначим Ai, а элементы упорядоченной последовательности - Bj. Первый элемент A1 исходной последовательности A занимает первую позицию в свободном участке памяти, т. е. становится первым элементом B1 последовательности B. Элемент A2 сравнивается с B2. Если в результате сравнения оказалось, что A2 < B1, то элемент B1 передвигается на одну позицию, а элемент A2 занимает его прежнее место. Теперь в свободном участке памяти размещены два элемента B1 и B2, образующих последовательность, упорядоченную по возрастанию значений ключа.
В течение каждого i-го прохода процесса сортировки элемент Ai сравнивается поочередно со всеми элементами последовательности B начиная с B1. При обнаружении Bj, большего Ai, элементы Bj, Bj+1, Bj+2, . . . , Bi-1, передвигаются на одну позицию, освобождая место для элемента Ai, который занимает j-ю позицию.
A | 10 | 4 | 11 | 9 | 7 | 2 | |
B | Проход 1 Проход 2 Проход 3 Проход 4 Проход 5 Проход 6 | 10 4 4 4 4 2 | 10 10 9 7 4 | 11 10 9 7 | 11 10 9 | 11 10 | 11 |
рис. Пример сортировки методом вставок.
Последовательность из N элементов будет отсортирована за N проходов. Максимальное число сравнений равно сумме членов арифметической прогрессии 1+2+3+...+(N-1) и определяется формулой.
Cmax = ![]() (N-i)=0,5N(N-1)
(N-i)=0,5N(N-1)
Если исходная последовательность имеет обратную упорядоченность, то для сортировки потребуется минимальное число сравнений Cmin =N-1.
Среднее число сравнений пропорционально 0,25 N2.
Линейное число перестановок равно нулю, и будет это в том случае, когда исходная последовательность уже упорядочена. Максимальное число перестановок Cmax потребуется для сортировки исходной последовательности, имеющей обратную упорядоченность. Среднее число перестановок пропорционально 0,25 N2.
Метод подсчета.
Упорядоченная последовательность B создается в свободной области памяти в результате сортировки исходной последовательности А. Метод основан на том, что (к+1)-й элемент упорядоченной последовательности превышает ровно к элементов и, следовательно занимает (к+1)-ю позицию. В процессе сортировки на каждом i-м проходе i-й элемент исходной последовательности попарно сравнивается со всеми остальными элементами. Если в результате сравнения установлено, что Ai > Aj, то значение числа к увеличивается на единицу. По окончании прохода значение к оказывается равным числу элементов, меньших чем Ai.
Номер позиции i-го элемента в последовательности B равен к+1.
i | 1 | 2 | 3 | 4 | 5 | 6 |
A (i) | 10 | 4 | 11 | 9 | 7 | 2 |
N прохода | 1 | 2 | 3 | 4 | 5 | 6 |
k | 4 | 1 | 5 | 3 | 2 | 0 |
B (k+1) | 2 | 4 | 7 | 9 | 10 | 11 |
рис. Пример сортировки методом подсчета.
В результате первого прохода устанавливается, что первый элемент исходной последовательности А(1)=10 оказался больше четырех элементов и для него устанавливается к=4. Этот элемент займет пятую позицию в упорядоченной последовательности В. Аналогично определяются позиции всех остальных элементов последовательности.
Для сортировки последовательности из N элементов требуется N проходов, на каждом проходе выполняется N сравнений. Число проходов и сравнений не зависит от степени упорядоченности исходной последовательности. Поэтому для данного метода максимальное, минимальное и среднее число сравнений равно N2.
Рассмотренный алгоритм сортировки методом подсчета можно использовать лишь в тех случаях, когда в исходной последовательности отсутствуют одинаковые элементы, иными словами, когда в упорядоченном массиве нет записей с одинаковыми значениями ключей. Для сортировки массивов, имеющих записи с одинаковыми значениями ключей алгоритм нужно модифицировать.
Метод Шелла.
Шеллом в 1959г., минимален по памяти и обеспечивает высокую скорость сортировки. Метод использует сравнения и перестановки элементов, как и метод вставок, однако в сравнении участвуют не соседние элементы, а отстоящие друг от друга на определенном расстоянии. При необходимости перестановки элементы перемещаются скачком на это же расстояние, а не на одну позицию, как в методе вставок.
Для проведения сортировки последовательность из N элементов делится на N/2 групп или на (N-1)/2, если N нечетно. Каждая группа содержит по два элемента. Если число элементов нечетно, то одна часть будет содержать три элемента. Элементы, принадлежащие одной группе, состоят из N/2 позиций. Это расстояние называется шагом.
i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
A (i) | 3 | 11 | 6 | 4 | 9 | 5 | 7 | 8 | 10 | 2 | 1 |
Проход 1 | 1 | 7 | 6 | 4 | 2 | 3 | 11 | 8 | 10 | 9 | 5 |
Проход 2 | 1 | 3 | 2 | 4 | 5 | 7 | 6 | 8 | 10 | 9 | 11 |
Проход 3 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
рис. Пример сортировки методом Шелла.
Одиннадцать элементов исходной последовательности A разделены на 5 групп с шагом, равным пяти. Элементы, принадлежащие одной группе, объединены скобками.
В течение первого прохода осуществляется упорядочивание элементов каждой группы методом вставок. В результате первого прохода изменяется порядок следования элементов первой группы. Элемент 1 займет первую позицию, элементы 3 и5 передвинутся вправо и займут соответственно шестую и одиннадцатую позицию. Поменяются местами также элементы второй группы (11 и 7) и элементы пятой группы (9 и 2).
Для осуществления каждого следующего прохода Шелл предложил устанавливать шаг, равный половине предыдущего шага (у дробных чисел берется целая часть). Тогда для этого примера шаг между элементами группы на втором проходе равен двум. В течение второго прохода упорядочиваются две группы элементов: первая группа, состоящая из элементов 1, 6, 2, 11, 10, 5 и вторая группа, состоящая из элементов 7, 4, 3, 8, 9. В результате второго прохода элементы этих групп окажутся упорядоченными по возрастанию их значений.
Для третьего прохода устанавливается шаг, равный 1, и упорядочивается единственная группа. В результате попарных сравнений и обменов исходная последовательность оказывается полностью упорядоченной после третьего прохода.
Для сортировки последовательности из N элементов требуется около log2N проходов.
Число сравнений, необходимое для сортировки методом Шелла, существенно зависит от шага. Самим Шеллом предложена последовательность N/2, N/4, N/8 и т. д..
Приближенную оценку числа сравнений производят по формуле N log2N.
Методы сортировки, использующие древовидное представление данных.
Массив записи может быть отсортирован с помощью бинарного дерева. Процесс сортировки состоит из фазы построения дерева и фазы его обхода.
Сформируем двоичное дерево из последовательных записей, имеющих следующее значение ключа: 3, 11, 6, 4, 9, 5, 7, 8, 10, 2, 1. Затем предпримем смешанный обход полученного дерева. В этом случае читается сначала левое поддерево, затем сам узел, а затем его правое поддерево. В результате чтения содержимого узлов дерева в процессе такого обхода получена такая последовательность признаков: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11. Эта последовательность отсортирована по возрастанию значений ключевого признака.
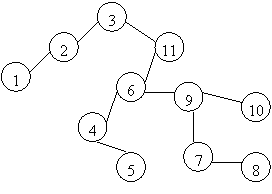 | |
| |
Рис. Построение дерева сортировки.
Число сравнений, необходимое для сортировки, равно числу операций сравнения, выполняемых в процессе построения дерева. Число сравнений зависит от расстановки данных перед сортировкой. Число сравнений тем меньше, чем ближе дерево сортировки к сбалансированному, т. е. чем меньше его объем. Минимум числа сравнений достигается в сбалансированном дереве и оценивается формулой N log2N, где N- число сортируемых записей. Сортировка на двоичном сбалансированном дереве требует наименьшего числа сравнений среди всех ранее рассмотренных методов сортировки.
Число сравнений окажется максимальным, если надо отсортировать уже упорядоченную последовательность. Число сравнений в этом случае оценивается формулой 0,5(N2-N), т. е. пропорционально 0,5N2.
Таблица. Число сравнений, выполняемых при построении дерева.
Ключ | Число сравнений | Сравниваемые элементы |
3 11 6 4 9 5 7 8 10 2 1 | 0 1 2 3 3 4 4 5 4 1 2 | - 3 3, 11 3, 11, 6 3, 11, 6 3, 11, 6, 4 3, 11, 6, 9 3, 11, 6, 9, 7 3, 11, 6, 9 3 3, 2 |
Суммарное число сравнений -29.
Сортировка по дереву используется в тех случаях, когда требуется быстрая сортировка при минимальном объеме памяти.
Внешняя сортировка.
Когда объем сортируемых данных велик и превышает свободный объем ОП, то для сортировки используется ВЗУ. Обычно применяют МЛ, как наиболее дешевые и емкие ВЗУ.
Наиболее общей формой внешней сортировки с применением МЛ является сбалансированное n-ленточное слияние. Для n-ленточного слияния требуется 2n МЛ и 2n лентопротяжных устройств.
Исходная последовательность, размещенная на одной МЛ, разносится на n МЛ следующим образом. Первая запись — на первую МЛ., вторая — на вторую, n-я запись на n-ю МЛ. В дальнейшем (n+1)-я запись снова записывается на первую МЛ, (n+2)-я на вторую и т. д. до тех пор, пока вся исходная последовательность не будет распределена на n МЛ.
Сбалансированное n-ленточное слияние осуществляется в два этапа. На первом этапе из записей, хранящихся на каждой МЛ формируются упорядоченные цепочки длиной L. Т. к. все цепочки имеют одинаковую длину, слияние называется сбалансированным. Упорядочение цепочек происходит в ОП и длина каждой цепочки L определяется исходя из выделенного для сортировки объема ОП. Упорядоченные цепочки размещаются на n свободных МЛ. Затем эти ленты перематываются к началу и выполняется второй этап внешней сортировки-слияния.
Он осуществляется в несколько циклов. После каждого цикла слияния длина упорядоченных цепочек увеличивается в n раз. В результате слияния формируется единая упорядоченная последовательность записей. В литературе n-ленточное слияние называется также n-путевым слиянием.
| ||||||||||
| ||||||||||
|
|
| ||||||||
| ||||||||||
| ||||||||||
| ||||||||||
МЛ3 МЛ1 МЛ2 МЛ3 МЛ4 МЛ1 МЛ2 МЛ3 МЛ4 МЛ1
рис. Пример сбалансированного 2-ленточного слияния.
Предположим, что в свободной области ОП могут разместиться лишь две записи. Тогда в результате первого этапа сортировки будут сформированы цепочки, каждая из которых содержит по две записи, упорядоченные по возрастанию значений ключа. Эти цепочки разместятся на МЛ3 и МЛ4, а МЛ1 и МЛ2 оказываются свободными и могут вновь использоваться для записи на них данных.
Начинается этап слияния. В первом цикле слияния попарно сравниваются и упорядочиваются элементы первых цепочек с МЛ3 и МЛ4, затем элементы вторых цепочек с МЛ3 и МЛ4 и т. д.. Вновь сформированные упорядоченные цепочки длиной 2L размещаются на МЛ1 и МЛ2.
Во втором цикле сравниваются и упорядочиваются элементы первых цепочек с МЛ1 и МЛ2, затем элементы вторых цепочек с МЛ1 и МЛ2. Вновь сформированные упорядоченные цепочки длиной 4L размещаются на МЛ3 и МЛ4. И, наконец, в результате сравнений и упорядочения цепочек с МЛ3 и МЛ4 формируется единая упорядоченная цепочка записей, размещенная на МЛ1. Все сравнения осуществляются в ОП. Перед выполнением каждого цикла МЛ перематывается к началу.
Таблица. Последовательность сравнения ключей записей при слиянии.
1-й цикл | 2-й цикл | 3-й цикл | |||
I | II | I | II | I | II |
1,3 5,3 5,6 2,8 7,8 4,9 10,9 10,12 13,14 15,14 15,16 | 1 3 5 6 2 7 8 11 4 9 10 12 13 14 15 16 | 1,2 3,2 3,7 5,7 6,7 4,13 9,13 10,13 12,13 | 1 2 3 5 6 7 8 11 4 9 10 12 13 14 15 16 | 1,4 2,4 3,4 5,4 5,9 6,9 7,9 8,9 11,9 11,10 11,12 | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
I - элементы сравниваемых цепочек; II - элементы формируемой цепочки. Если при сравнении одна из цепочек оказывается исчерпанной, то все оставшиеся элементы другой цепочки дописываются в конец вновь формируемой цепочки.
Факторы, учитываемые при выборе метода сортировки.
Размер сортируемого массива. При этом выясняется, нужна ли внешняя сортировка, нужно ли использовать методы, использующие минимальное количество памяти. Т. е. надо произвести оценку количества записей в массиве.
Длина ключа. Длина и место расположения ключа в пределах записи определяют время, необходимое для выполнения операции сравнения.
Вид ключей. Время сравнения зависит от внутреннего представления данных и от доступности команд сравнения для различных типов данных.
Исходное распределение данных. Выявление закономерности в исходном распределении записей позволит выбрать метод сортировки, обеспечивающий минимальное число сравнений при данном конкретном порядке распределения ключей в исходной последовательности.
Возможность дублирования ключей. Иногда необходимо распознавание повторяющихся ключей. Тогда алгоритм сортировки должен предусматривать проверку на равенство. Когда повторения распознавать не надо, важно предотвратить обмены при равенствах.
Длина записей. Длина записей совместно с их количеством позволяет оценить необходимый для сортировки объем ОП.
Основные принципы информационного поиска.
Основное значение информационного поиска — решение вопроса о соответствии данных, содержащихся в записи, установленному критерию выдачи.
Существуют следующие виды информационного поиска.
Поиск по совпадению. Аргумент поиска содержит наименования одного или нескольких признаков (имена полей записи) и их значения. Критерием выдачи является прямое совпадение.Поиск по интервалу. Аргумент поиска содержит имена одного или нескольких признаков и пределы изменения значений этих признаков. Критерием выдачи является принадлежность данному интервалу.
Поиск по выражению. Аргумент поиска представляет собой арифметическое или теоретико-множественное выражение или формулу булевой алгебры. Операндами являются имена признаков. Критерии выдачи называются логическими критериями.
Логика поиска задает словесное, содержательное описание задачи поиска; определяет вид аргумента поиска; устанавливает критерии, с помощью которых оценивается соответствие найденной информации запросу. Логика поиска определяет оценки эффективности поиска - полноту и точность.
Стратегия поиска — это реализация логики поиска в условиях конкретной системы и конкретной ЭВМ. При разработке стратегии поиска оценивается характер хранимой информации, объем информационных массивов и тип ЗУ; выбирается метод поиска данных в памяти ЭВМ; определяются алгоритмы поиска с учетом формы запросов и ответов, учитывается тип структур, используемых для организации данных.
Методы доступа к информации.
Под методом доступа понимается совокупность технических и программных средств, обеспечивающих возможность хранения и выборки данных, расположенных на физических устройствах ЭВМ.
Последовательный доступ или метод последовательного перебора.
Самый универсальный, наиболее простой и самый длительный метод поиска. Реализует доступ к данным базы путем последовательного просмотра записей. Можно использовать при любом способе организации информационного массива, для любых структур данных, при любой форме аргумента поиска. В процессе поиска осуществляется последовательное обращение к каждой записи массива и при этом определяется, удовлетворяет ли данная запись критерию выдачи.
Последовательный поиск в массиве из N записей требует в среднем (N+1)/2 сравнений (единица в числителе появляется при нечетном N).
Ускоренные методы поиска.
Существенное ускорение процесса поиска возможно в упорядоченных последовательных информационных массивах. К ускоренным методам поиска относятся двоичный и блочный поиски.
