


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Рис.4. Диаграмма работы ДО SJF.
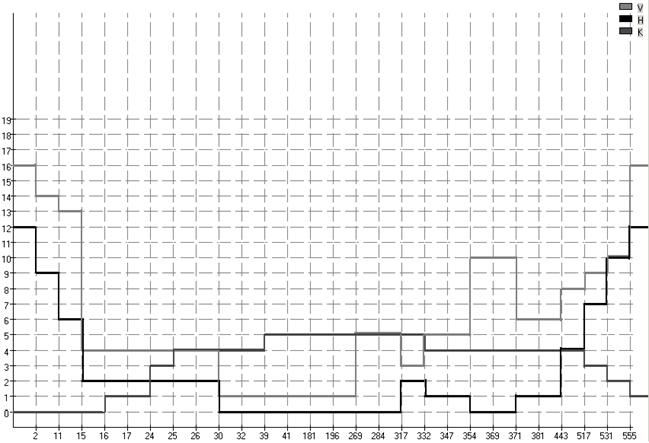
Рис.5. Диаграмма использования ресурсов при ДО SJF
Таблица 5. Сводная таблица результатов по ДО SJF
Задание | tп | tв | tн | tз | Wi |
0 | 2 | 2 | 16 | 181 | 3.272727 |
1 | 11 | 11 | 25 | 269 | 3.984615 |
2 | 15 | 15 | 24 | 317 | 4.328571 |
3 | 15 | 15 | 24 | 354 | 4.250000 |
4 | 17 | 182 | 196 | 371 | 6.454545 |
5 | 26 | 333 | 347 | 517 | 7.569231 |
6 | 30 | 30 | 39 | 332 | 4.328571 |
7 | 30 | 372 | 381 | 555 | 6.575000 |
8 | 32 | 270 | 284 | 443 | 7.490909 |
9 | 41 | 355 | 369 | 531 | 7.553846 |
Вывод по ДО SJF:
Максимальный коэффициент мультипрограммирования равен 5.
Средневзвешенное время обращения Wср= 5.58
1.6 Сравнительный анализ двух диаграмм.
Максимальный коэффициент мультипрограммирования у обоих алгоритмов — 5. Дисциплина обслуживания SJF обладает меньшим значением средневзвешенного времени обращения (5.58) по сравнению с FIFO (5.687). следовательно для такой последовательности заданий выгоднее немного более выгодной использовать ДО SJF. Однако различия в работе дисциплин для этой последовательности задач незначительные и наблюдаются лишь с момента времени t=269. При использовании обеих ДО общее время работы одинаковое и равно 555.Таким образом, рекомендуемым алгоритмом является SJF, вследствие меньшего значения средневзвешенного времени обращения.
Раздел 2
2.1 Задание.
Разработать структуру функционирования диспетчера работ в вычислительной системе, заданной в разделе 1, на интервале Т1, который соответствует максимальному коэффициенту мультипрограммирования. Квант времени, выделяемый каждой работе, выбирается исходя из конкретной ситуации: число работ, параллельно занимающих процессор; интервал Т1; дисциплины обслуживания.
Диспетчер использует метод разделения времени в сочетании с приоритетами.
2.2 Исходные данные.
Вариант выбирается согласно порядковому номеру в журнале.
Соответственно варианту выбираются дисциплины обслуживания, то есть:
· бесприоритетная: LIFO - линейная дисциплина обслуживания стека - Last In First Out;
· приоритетная: адаптивное обслуживание
В качестве набора задач был взят поток задач, сформированный в части 1 данной работы. Квант диспетчера = 5, квант выполнения работы =10.
2.3 Диспетчеризация задач для бесприоритетной ДО LIFO.
Общий принцип функционирования бесприоритетных ДО таков: дисциплина обслуживания выбирает заявки из очереди без учета их важности, по принципу последовательности их поступления.
В данном случае используется ДO LIFO (LAST INPUT – FIRST OUTPUT), т. е последним пришел – первым обслужился. На этом принципе и основывается построение оптимизированной таблицы задач в данном случае. Так как у системы нет информации о приоритетах, то tобсл. почти постоянно.
Программно это реализуется следующим образом: просматривается очередь задач, ожидающих выполнение на процессоре и выбирается последний поступивший.
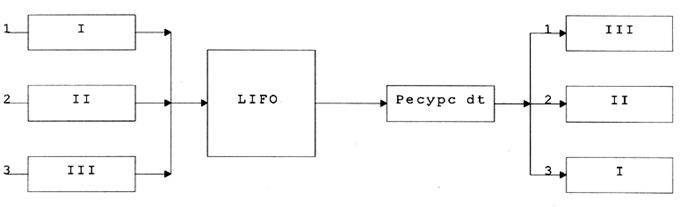
Рис. 6. Схема алгоритма - LIFO
Описание схемы:
На входе 3 задания (I, II, III) в порядке поступления (1, 2, 3). В соответствии с ДО LIFO формируется оптимизированная таблица задач. Задаче выделяется процессорное время. Выходная цепочка задачи построена в соответствии с ДО.Количество заданий может быть любым - от 2-х и более.
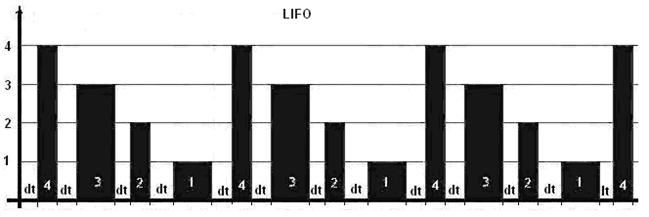
Рис. 7. Диаграмма LIFO
Алгоритм работы диспетчера по дисциплине LIFO:
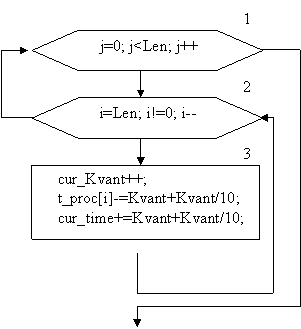 |
Рис. 8 Блок-схема LIFO
2.4 Диспетчер задач для приоритетной ДО – адаптивное обслуживание
В этом случае решения об абсолютном или относительном приоритетах принимаются в зависимости от обстановки. Для решения этого вопроса взвешивается - "что стоит" прерывание.
Пусть Сi - "стоимость" ожидания заявки для i-ой работы (т. е. высокоприоритетная), Сj - "стоимость" ожидания заявки для j-ой работы (низкоприоритетной), т. е. j>i (отсчет от меньшего к большему).
Тj - время обслуживания j-ой заявки;
Тi - время обслуживания i-ой заявки, тогда, если ТiСj < ТjСi, то i-ая работа (заявка) не прерывается.
Если будет прервана, то будет "стоить" ТjСi, если не будет прервана, то будет "стоить" ТiСj.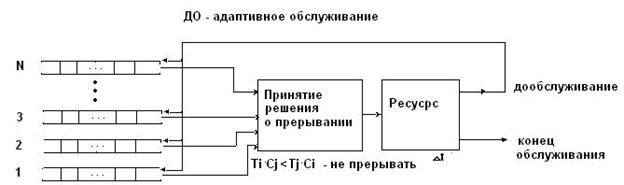
Рис. 9. Схема алгоритма - адаптивное обслуживание
Таблица 6. Принцип работы ДО – адаптивное обслуживание
Номер задачи | Время поступления,
| Трудо емкость tCPU | приоритет | C | ||||
0 | 2 | 40 | 5 | 6 | Ti*Cj | знак | Tj*Ci | коммент |
1 | 11 | 50 | 4 | 7 | 40*7 | < | 50*6 | 0-ю не прерываем |
2 | 15 | 60 | 2 | 9 | 50*9 | > | 60*7 | 2 прерывает 1-ю |
3 | 15 | 70 | 3 | 8 | 50*8 | < | 70*7 | 1-ю не прерываем |
4 | 17 | 40 | 1 | 10 | 70*10 | > | 40*8 | 4-я прерывает 3-ю |
5 | 26 | 50 | 10 | 1 | 70*1 | < | 50*8 | 3-ю не прерываем |
6 | 30 | 60 | 8 | 3 | 50*3 | > | 60*1 | 6-я прерывает 5-ю |
7 | 30 | 70 | 9 | 2 | 50*2 | > | 70*1 | 7-я прерывает 5-ю |
8 | 32 | 40 | 6 | 5 | 50*5 | > | 40*1 | 8-я прерывает 5-ю |
9 | 41 | 50 | 7 | 4 | 50*4 | > | 50*1 | 9-я прерывает 5-ю |
Трассировку ДО выполним вручную.
Выберем квант диспетчера = 1, квант выполнения работы =5
Таблица 7. Журнал событий ДО адаптивного обслуживания
Время | События |
0 | Заданий нет. Простой системы. |
2 | Поступило задание 0: начинается ввод задания. Процессор простаивает |
11 | Поступило задание 1: начинается ввод задания. Процессор простаивает. |
15 | Поступило задание 2: начинается ввод задания. Поступило задание 3: начинается ввод задания. Процессор простаивает. |
16 | Завершён ввод задания 0. Задания на процессоре: 0 . |
17 | Поступило задание 4: нехватка ресурсов - задание помещено в очередь. Задания на процессоре: 0 |
24 | Завершён ввод задания 2. Завершён ввод задания 3. Задания на процессоре: |
25 | Завершён ввод задания 1. Задания на процессоре: |
26 | Поступило задание 5: нехватка ресурсов - задание помещено в очередь. Задания на процессоре: |
30 | Поступило задание 6: начинается ввод задания. Поступило задание 7: нехватка ресурсов - задание помещено в очередь. Задания на процессоре: |
32 | Поступило задание 8: нехватка ресурсов - задание помещено в очередь. Задания на процессоре: |
39 | Завершён ввод задания 6. Задания на процессоре: |
41 | Поступило задание 9: нехватка ресурсов - задание помещено в очередь. Задания на процессоре: |
181 | Завершено задание 0 и его ресурсы освобождены. Из очереди выбирается задание 4: начинается ввод задания. Задания на процессоре: |
196 | Завершён ввод задания 4. Задания на процессоре: |
269 | Завершено задание 1 и его ресурсы освобождены. Из очереди выбирается задание 8: начинается ввод задания. Задания на процессоре: |
284 | Завершён ввод задания 8. Задания на процессоре: |
317 | Завершено задание 2 и его ресурсы освобождены. Задания на процессоре: |
332 | Завершено задание 6 и его ресурсы освобождены. Из очереди выбирается задание 5: начинается ввод задания. Задания на процессоре: |
347 | Завершён ввод задания 5. Задания на процессоре: |
354 | Завершено задание 3 и его ресурсы освобождены. Из очереди выбирается задание 9: начинается ввод задания. Задания на процессоре: |
369 | Завершён ввод задания 9. Задания на процессоре: |
371 | Завершено задание 4 и его ресурсы освобождены. Из очереди выбирается задание 7: начинается ввод задания. Задания на процессоре: |
381 | Завершён ввод задания 7. Задания на процессоре: |
443 | Завершено задание 8 и его ресурсы освобождены. Задания на процессоре: |
517 | Завершено задание 5 и его ресурсы освобождены. Задания на процессоре: |
531 | Завершено задание 9 и его ресурсы освобождены. Задания на процессоре: 7 9 . |
555 | Завершено задание 7 и его ресурсы освобождены. Задания на процессоре: 7 . |
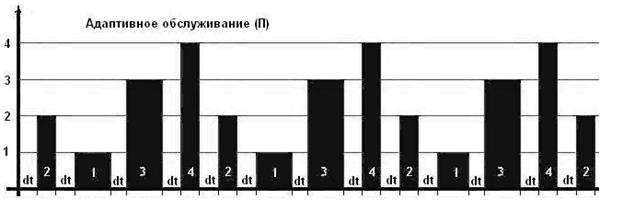
Рис. 10. Диаграмма адаптивного обслуживания
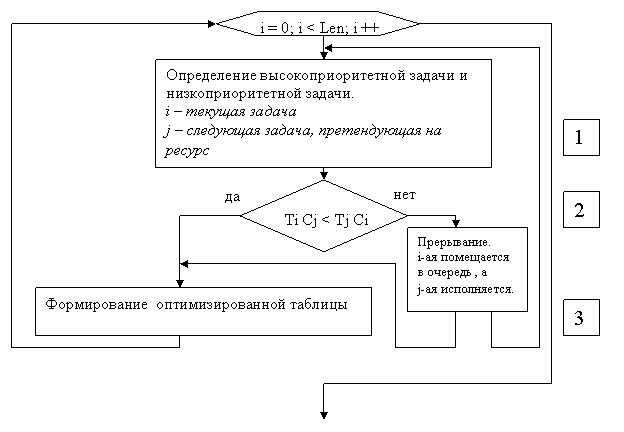

Рис. 11 Блок-схема диспетчера задач (ДО – адаптивное обслуживание).
Описание схемы:
1) Определение высокоприоритетной задачи и
низкоприоритетной задачи.
2) Принятие решения – прерывать или нет.
3)Формирование оптимизированной таблицы. И, в случае прерывания, помещение i-ой задачи в очередь.
2.5 Программная реализация диспетчера с ДО FIFO.
#include <iostream>
using namespace std;
struct task
{
int v;
int h;
int cpu;
int t_post;
int t_real;
int finish;
};
void main()
{
task a[11];
a[1].v=2;
a[1].h=3;
a[1].cpu=40;
a[1].t_post=2;
a[2].v=1;
a[2].h=3;
a[2].cpu=50;
a[2].t_post=11;
a[3].v=3;
a[3].h=2;
a[3].cpu=60;
a[3].t_post=15;
a[4].v=6;
a[4].h=2;
a[4].cpu=70;
a[4].t_post=15;
a[5]=a[1];
a[5].t_post=17;
a[6]=a[2];
a[6].t_post=26;
a[7]=a[3];
a[7].t_post=30;
a[8]=a[4];
a[8].t_post=30;
a[9]=a[1];
a[9].t_post=32;
a[10]=a[2];
a[10].t_post=41;
int ZAG[11]={0}; // загружаются
for(int l=1; l<11; l++)
{
a[l].t_real=0;
a[l].finish=0;
ZAG[l]=-1;
}
int OC[11]={0}; // очередь работ
int o=0; // указатель на первый свободный
int PROC[11]={0}; // список работ на проце
int p=0;
int z=0;
int time=0; // реал тайм
int kv_d=5; // квант диспетчеру
int kv_r=10; // квант работе
int V=16;
int H=12;
int start=0;
int i;
int j;
int pointer=0;
int kit=0;
while(kit<58) // работать пока в очереди есть что нить
{
cout<<"\n----new"<<kit<<endl;
cout<<"\ntime="<<time<<endl;
cout<<"Kolichestvo resursov\n";
cout<<"V= "<<V<<"\tH= "<<H<<endl;
cout<<"Ochered rabot na processore\n";
for(i=0; i<11; i++)
cout<<PROC[i]<<" ";
cout<<endl;
cout<<"Vremya v techenii kotorogo rabota obrabativalas"<<endl;
for(i=1; i<11; i++)
cout<<a[i].t_real<<" ";
cout<<endl;
for(j=0; j<p; j++) // просмотреть очередь проца
{
//if(start==1)
//{ j=p-1;
//cout<<"\n\np="<<p<<endl;
//cout<<"j="<<j<<endl;
if(a[PROC[j]].t_real>=a[PROC[j]].cpu && a[PROC[j]].finish!=1)
{
H+=a[PROC[j]].h;
V+=a[PROC[j]].v;
a[PROC[j]].finish=1;
cout<<"\n!!!zavershilas rabota "<<PROC[j]<<endl<<endl;
a[PROC[j]].t_real=-666;
if(j+1!=p)
{
for(int k=j; k<p; k++)
PROC[k]=PROC[k+1];
PROC[p]=0;
p--;
}
else
{
PROC[p-1]=0;
p--;
}
}
}
for(i=10; i>0; i--) // просмотреть каждую работу.
{
if(time>=a[i].t_post && a[i].finish!=1 && ZAG[i]==-1) //???????????
{
if(a[i].h<=H && a[i].v<=V)
{
H=H-a[i].h;
V=V-a[i].v;
ZAG[i]=time;
cout<<"\n!!!Postupila na zagruzku rabota "<<i<<endl<<endl;
}
}
}
//проверка очереди загрузки. нужно ли перенести в очередь на выполнение.
for(i=1; i<11; i++)
{
if(ZAG[i]>0)
{
if(time-ZAG[i]>=a[i].h*5)
{
start=1;
ZAG[i]=-666;
PROC[p]=i;
cout<<"\n\n!!Zagruzka raboti "<<i<<"zavershena"<<endl;
p++;
}
}
}
time+=kv_d;
if(start!=0)
{
pointer=p-1;
a[PROC[pointer]].t_real+=kv_r;
time+=kv_r;
if(PROC[pointer]==0) pointer=0;
}
kit++;
}
}
2.6 Листинг работы программы диспетчера с ДО FIFO.
----new0
time=0
Kolichestvo resursov
V= 16 H= 12
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
0 0
----new1
time=5
Kolichestvo resursov
V= 16 H= 12
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
0 0
!!!Postupila na zagruzku rabota 1
----new2
time=10
Kolichestvo resursov
V= 14 H= 9
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
0 0
----new3
time=15
Kolichestvo resursov
V= 14 H= 9
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
0 0
!!!Postupila na zagruzku rabota 4
!!!Postupila na zagruzku rabota 3
!!!Postupila na zagruzku rabota 2
----new4
time=20
Kolichestvo resursov
V= 4 H= 2
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
0 0
----new5
time=35
Kolichestvo resursov
V= 4 H= 2
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
10 0
!!!Postupila na zagruzku rabota 7
----new6
time=50
Kolichestvo resursov
V= 1 H= 0
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
20 0
----new7
time=65
Kolichestvo resursov
V= 1 H= 0
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
2 0 0
----new8
time=80
Kolichestvo resursov
V= 1 H= 0
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
20 0 0
----new9
time=95
Kolichestvo resursov
V= 1 H= 0
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
200 0 0
----new10
time=110
Kolichestvo resursov
V= 1 H= 0
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
20 0 0 0
----new11
time=125
Kolichestvo resursov
V= 1 H= 0
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
30 0 0 0
----new12
time=140
Kolichestvo resursov
V= 1 H= 0
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
30 0 0 0
----new13
time=155
Kolichestvo resursov
V= 1 H= 0
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
30 0 0 0
----new14
time=170
Kolichestvo resursov
V= 1 H= 0
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
30 0 0 0
----new15
time=185
Kolichestvo resursov
V= 1 H= 0
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
30 0 0 0
----new16
time=200
Kolichestvo resursov
V= 1 H= 0
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
40 0 0 0
!!!zavershilas rabota 1
После определенного количества итераций получим:
----new54
time=770
Kolichestvo resursov
V= 8 H= 7
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
-66 -
----new55
time=785
Kolichestvo resursov
V= 8 H= 7
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
-66 -
----new56
time=800
Kolichestvo resursov
V= 8 H= 7
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
-66 -
----new57
time=815
Kolichestvo resursov
V= 8 H= 7
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
-66 -
!!!zavershilas rabota 5
----new58
time=830
Kolichestvo resursov
V= 10 H= 10
Ochered rabot na processore
0 0 0
Vremya v techenii kotorogo rabota obrabativalas
-66 - -
!!!zavershilas rabota 8
2.7 Программная реализация диспетчера с ДО «адаптивное обслуживание
#include <iostream>
using namespace std;
struct task
{
int v;
int h;
int cpu;
int t_post;
int t_real;
int finish;
int c;
};
void main()
{
task a[11];
a[1].v=2;
a[1].h=3;
a[1].cpu=40;
a[1].t_post=2;
a[1].c = 6;
a[2].v=1;
a[2].h=3;
a[2].cpu=50;
a[2].t_post=11;
a[2].c = 7;
a[3].v=3;
a[3].h=2;
a[3].cpu=60;
a[3].t_post=15;
a[3].c = 9;
a[4].v=6;
a[4].h=2;
a[4].cpu=70;
a[4].t_post=15;
a[4].c = 8;
a[5]=a[1];
a[5].t_post=17;
a[5].c = 10;
a[6]=a[2];
a[6].t_post=26;
a[6].c = 1;
a[7]=a[3];
a[7].t_post=30;
a[7].c = 3;
a[8]=a[4];
a[8].t_post=30;
a[8].c = 2;
a[9]=a[1];
a[9].t_post=32;
a[9].c = 5;
a[10]=a[2];
a[10].t_post=41;
a[10].c = 4;
int ZAG[11]={0}; // загружаются
for(int l=1; l<11; l++)
{
a[l].t_real=0;
a[l].finish=0;
ZAG[l]=-1;
}
int OC[11]={0}; // очередь работ
int o=0; // указатель на первый свободный
int PROC[11]={0}; // список работ на проце
int p=0;
int z=0;
int time=0; // реал тайм
int kv_d=5; // квант диспетчеру
int kv_r=10; // квант работе
int V=16;
int H=12;
int start=0;
int i;
int j;
int pointer=0;
int kit=0;
while(kit<59) // работать пока в очереди есть что нить
{
cout<<"\n----new"<<kit<<endl;
cout<<"\ntime="<<time<<endl;
cout<<"Kolichestvo resursov\n";
cout<<"V= "<<V<<"\tH= "<<H<<endl;
cout<<"Ochered rabot na processore\n";
for(i=0; i<11; i++)
cout<<PROC[i]<<" ";
cout<<endl;
cout<<"Vremya v techenii kotorogo rabota obrabativalas"<<endl;
for(i=1; i<11; i++)
cout<<a[i].t_real<<" ";
cout<<endl;
for(j=0; j<p; j++) // просмотреть очередь проца
{
if(a[PROC[j]].t_real>=a[PROC[j]].cpu && a[PROC[j]].finish!=1)
{
H+=a[PROC[j]].h;
V+=a[PROC[j]].v;
a[PROC[j]].finish=1;
cout<<"\n!!!zavershilas rabota "<<PROC[j]<<endl<<endl;
a[PROC[j]].t_real=-666;
if(j+1!=p)
{
for(int k=j; k<p; k++)
PROC[k]=PROC[k+1];
PROC[p]=0;
p--;
}
else
{
PROC[p]=0;
p--;
}
}
}
for(j = 1; j< 11; i=j, j++) // просмотреть каждую работу.
{
if(time>=a[j].t_post && a[j].finish!=1 && ZAG[j]==-1)
{
if (j > 1)
{
if (a[i].t_post * a[j].c > a[j].t_post * a[i].c)
{
ZAG[i] = -1; //прерываем i-ю задачу
H = H+a[i].h;
V = V+a[i].v;
cout<<"\n!!!Rabota "<<i<<" prervana rabotoj " << j << endl<<endl;
}
}
if(a[j].h<=H && a[j].v<=V)
{
H=H-a[j].h;
V=V-a[j].v;
ZAG[j]=a[j].h*5; // запомнить
cout<<"\n!!!Postupila na zagruzku rabota "<<j<<endl<<endl;
}
}
}
//проверка очереди загрузки. нужно ли перенести в очередь на выполнение.
for(i=1; i<11; i++)
{
if(ZAG[i]==0)
{
ZAG[i]=-5;
start=1;
PROC[p]=i;
p++;
}
if(ZAG[i]>0)
{
ZAG[i]-=kv_d;
}
}
time+=kv_d;
if(start!=0)
{
a[PROC[pointer]].t_real+=kv_r;
time+=kv_r;
pointer++;
if(PROC[pointer]==0) pointer=0;
}
kit++;
}
}
Заключение
В ходе выполнения работы знания, полученные за период обучения курсу «Операционные системы» были закреплены.
В ходе выполнения Раздела 1 было выяснено, что алгоритм SJF для данного конкретного потока задач, заданного вариантом, показал себя лучше, чем алгоритм FIFO для выборки задач из очереди ожидающих ресурсы.
В ходе выполнения Раздела 2 были изучены два диспетчера c ДО: LIFO (бесприоритетная ДО) и адаптивное обслуживание, и запрограммирован диспетчер с ДО LIFO. Программа тестировались на потоке задач, сформированном в разделе 1. Общее время выполнения потока задач равно 830.
Список литературы
1) , – Системное программное обеспечение: учебник. – 2001. – 1 часть.
2) . Операционные системы как системы управления вычислительными ресурсами: Учеб. пособие. – Новосибирск: Изд-во НГТУ, 2001. – 63 с.
3) Современные операционные системы. 2-е изд. – СПб.: Питер,2007. – 1038 с.
4) http://www. *****/educat/systemat/gutorov/index. asp

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
