
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
XSI fx предназначен для базовой работы с растровой и векторной двухмерной графикой. [10]
2.2.5. Side Effects Houdini
Основным отличием Houdini от других редакторов трехмерной графики является полностью процедурнуя среда. Это означает, что представление трехмерного объекта формируется с помощью соединения последовательности операций. Такой подход имеет преимущество в том, что на создание достаточно сложной модели может уйти относительно немного времени, так как, например, возможно соединение нескольких операций в одну и организации «сетей операций». Подобная среда может напоминать визуальное программирование (в данном случае имеется в виду программирование сценариев в трехмерных редакторах, в Houdini также присутствуют и стандартные возможности расширения). Однако, стоит отметить, что такого рода продвинутый интерфейс может негативно влиять на скорость обучения пользованием этого продукта.
Данный пакет обладает достаточно богатыми возможностями, в том числе и связанными с визуализацией (встроенный визуализатор Mantra), однако исторически так сложилось, что его основной сильной стороной является продвинутая система анимации частиц, поэтому его применение часто связано с организацией эффектов, симулирующих различные физические явления. [11]
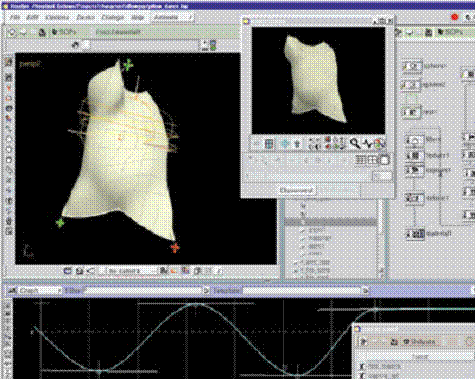
Рис. 5. Пользовательский интерфейс программы Houdini
2.2.6. Blender
Среди рассмотренных пакетов для работы с трехмерной графикой Blender является единственным полностью бесплатным продуктом с открытым кодом. Он распространяется по лицензии GNU General Public License, наиболее популярной среди открытых решений. В связи с этим, имеет неограниченные возможности расширения и, следовательно, стремительно развивается, догоняя по функциональности закрытые коммерческие проприетарные продукты. Также стоит упомянуть и компактный установочный дистрибутив в 8 мегабайт (после установки программа занимает 25 мегабайт), что часто от нескольких десятков до сотни раз меньше других программ. [12]
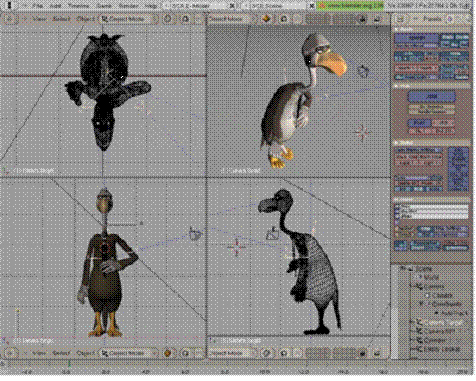
Рис. 6. Пользовательский интерфейс программы Blender
2.2.7. Выбор редактора
При анализе обзора трехмерных редакторов основным критерием была популярность программы, так как она определяет количество потенциальных пользователей. После анализа выбор был сужен до двух наиболее используемых продуктов: Autodesk 3ds max и Autodesk Maya [5, 6]. Они обладают схожим набором возможностей, однако проблема 3ds max заключается в непереносимости на все операционные системы, кроме семейства ОС Windows. Поэтому, итогом этого раздела стал выбор трехмерного пакета Autodesk Maya для выполнения практической части данной дипломной работы.
2.3. Обзор файловых форматов
2.3.1. Двоичные файловые форматы
Двоичный файл – это файл, который может содержать любые виды информации, которые можно закодировать двоичным кодом, например, в отличие от текстового файла. Обычно они содержат заголовки, которые являются блоками метаданных, описывающих определенную часть файла.
Для того, чтобы прочитать двоичный файл требуется алгоритм, который проходит по его содержимому и для которого он и предназначался. Можно попытаться разобрать содержимое в шестнадцатеричном редакторе, однако это будет подобно расшифровке секретных шифров. Отсюда вытекает и сложность модификации двоичных файлов.
[13]
2.3.2. Текстовые файловые форматы
Текстовой файл – последовательность определенных печатных символов, таких как буквы, цифры, знаков пунктуации, пробелов или контрольных символов. Символы в текстовом файле принадлежат определенной кодировке (например, ASCII, ANSI или Unicode) и при правильной ее настройке в текстовом редакторе (или просмотрщике) могут быть корректно отображены. В этом и заключается основное преимущество текстового представления – чтобы просмотреть такой файл достаточно программы-просмотрщика, которая входит в состав любой операционной системы.
Текстовые файлы используются в языках разметки, с помощью которых очень удобно упорядочивать данные. Наиболее универсальный и широко используемый язык разметки – XML (Extensible Markup Language). Он полностью стандартизован, поэтому нет проблем с кодировкой (стандартом является UTF-8, с помощью которой возможно кодирование символов алфавита любого языка). В большинстве современных программ конфигурационная информация сохраняется в XML, так как с помощью этого формата возможно организовывать удобную иерархическую структуру данных. В настоящее время заметны тенденции перехода на XML, например, компания Microsoft больше 15 лет использовала двоичный формат «DOC» для своего текстового процессора Word, перешла в 2007 году на текстовой формат Office Open XML.
[14]
2.3.3. Выбор формата
В истории трехмерных редакторов большое распространение получили именно двоичные файлы (например, форматы файлов программ 3ds max, Maya), в один файл можно было сохранить сразу всю информацию о сцене, например, кроме текстового описания координат примитивов включить непосредственно двухмерные изображения, представляющие текстуры. Однако, в новые и современные программы встраивают поддержку текстовых форматов. Для примера можно привести визуализаторы Kerkythea, Indigo, а также COLLADA – продвинутый открытый XML-подобный формат, целью которого является достижение взаимодействия различных трехмерных приложений.
Вследствие того, что визуализатор не обладает пока широкими возможностями, использовать уже существующую структуру формата (например COLLADA), имеющую ненужную избыточность не имеет смысла. Для некоторых этапов тестирования практической части данной работы (проверка результатов экспорта, изменение файла при необходимости) категорически не подходит двоичный формат. Основное достоинство двоичного формата – высокая скорость обработки. Однако, работу с текстовыми файлами можно организовать так, что замедление в скорости одного полного цикла обмена данными между трехмерным редактором и визуализатором, по сравнению с использованием двоичного формата, будет несущественным (см. главу 3.2.5). В свете всего написанного, был сделан вывод, что для практической части данной дипломной работы будет разработан собственный формат хранения трехмерной сцены на основе XML и согласованный с возможностями визуализатора.
3. Специальная часть
3.1. Схема взаимодействия визуализатора и трехмерного редактора
На схеме, изображенной на рисунке 7, показана организация взаимодействия визуализатора и трехмерного редактора, используя текстовые файлы. В программе Autodesk Maya присутствует API – программный интерфейс приложения, который используется как промежуточное звено между ядром Maya и пользовательской программой-модулем. Пользовательская программа-plugin генерирует на основе внутренних данных Maya текстовой XML-файл, экспортируя тем самым информацию о трехмерной сцене (архитектура Maya API и подробности реализации программы-модуля описаны в главе 3.5, формат XML-файла в главе 3.4). Далее текстовой файл считывается визуализатором с помощью класса XMLImport, который, взаимодействуя с библиотекой XML-парсера, передает данные о трехмерной сцене через интерфейс передачи информации ядру визуализации (особенности реализации этого процесса описаны в следующей главе). Программа-визуализатор, теперь имея все необходимые данные, сможет произвести визуализацию сцены.
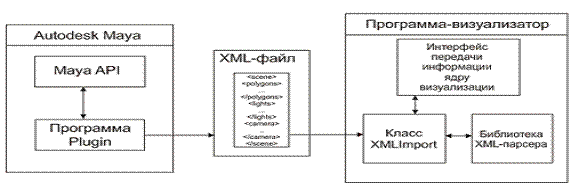
Рис. 7. Схема взаимодействия визуализатора и трехмерного редактора
3.2. Добавление возможности чтения файлов с описанием трехмерной сцены в программу-визуализатор
3.2.1. Компиляция программы-визуализатора
3.2.1.1. Средства разработки
Программа-визуализатор написана на языке С++. Операционная система, в которой будет компилироваться программа – Microsoft Windows XP SP2. Это связано с тем, что большинство художников/аниматоров, занимающихся трехмерной графикой используют именно ее. Средство разработки программного обеспечения – пакет Microsoft Visual Studio 2005 Service Pack 1, в состав которого входит компилятор MSVC 8.0. Также для компиляции визуализатора требуется установка инструментария для разработки приложений для графических процессоров – Nvidia CUDA 1.0 SDK, включающее в себя специальный компилятор. Тестовая компьютерная рабочая станция должна быть на основе материнской платы с поддержкой технологии PCI-Express с установленной видеокартой GeForce компании NVidia не ниже 8-ой серии.
Тестовая конфигурация, на которой исполнялась практическая часть данной дипломной работы и на которой гарантированно работают средства разработки и тестовые программы:
Материнская плата: ASUS A8N-SLI
Процессор: AMD Athlon X2 4600+
Оперативная память: Kingston 2GB DDR PC3200
Видеокарта: Albatron GeForce 8800GTX
3.2.1.2. Установка средств разработки
Установка средств разработки достаточно тривиальна для пользователя среднего уровня и очень подробно описана в документациях использованных программных продуктов (а также не представляет ценности для описания данной работы), поэтому здесь описана не будет. Следует лишь упомянуть, что инструментарий CUDA рекомендуется для удобства устанавливать в корень директории диска «C:\».
3.2.1.3. Настройка параметров переменных среды ОС
После установки инструментария CUDA, требуется настроить параметры переменных среды операционной системы, для удобства последующей настройки проекта среды разработки Visual Studio.
Данные параметры вызываются следующим образом:
Кнопка «Пуск» -> «Мой компьютер» -> (щелчок правой мышью) «Свойства» -> вкладка «Дополнительно» -> «Переменные среды».
Далее вносим значения системных переменных, в соответсвии с рисунком:
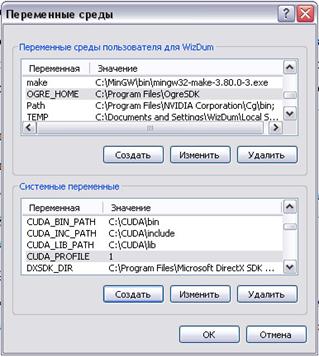
Рис. 8. Настройка параметров переменных среды ОС
3.2.1.4. Настройка проекта среды разработки
После запуска среды разработки Visual Studio, требуется создать новый проект: Visual C++ Win32 Console Application с установленным флагом «Empty Project».
В свойствах проекта нужно указать/прописать следующие значения:
1) Вкладка «C/C++» -> «General» -> «Additional include directories»:
«$(CUDA_INC_PATH);$(NVSDKCUDA_ROOT)/common/inc;
$(NVSDKCUDA_ROOT)/common/GLEW/include» (без кавычек)
Здесь мы указываем директории требующихся заголовочных файлов CUDA, а также файлов библиотеки OpenGL/GLUT и GLEW для обработки ввода/вывода.
2) Вкладка «C/C++» -> «General» -> «Debug»: Program Database (/Zi)
3) Вкладка «C/C++» -> «Optimization» -> «Optimization»:
Maximize Speed (/O2)
4) Вкладка «C/C++» -> «Preprocessor» -> « Preprocessor definitions»: WIN32;_CONSOLE
5) Вкладка «C/C++» -> «Code generation» ->
«Enable minimum rebuild»: No
«Basic runtime checks»: Default
«Runtime Library»: Multi-threaded (/MT)
6) Вкладка «Linker» -> «General» -> «Enable incremental linking»:
No (/INCREMENTAL:NO)
7) Вкладка «Linker» -> «General» -> «Additional library directories»:
«$(CUDA_LIB_PATH);
$(NVSDKCUDA_ROOT)/common/lib;$(NVSDKCUDA_ROOT)/common/GLEW/lib» (без кавычек)
8) Вкладка «Linker» -> «Input» -> «Additional Dependecies»:
«cudart. lib cutil32.lib glew32.lib» (без кавычек)
9) Вкладка «Linker» -> «Input» -> «Optimization» -> «References»:
Eliminate Unreferenced Data (/OPT:REF)
10) Вкладка «Linker» -> «Input» -> «Optimization» -> «Enable COMDAT Folding»:
Do Not Remove Redundant COMDATs (/OPT:NOICF)
3.2.1.5. Добавление файлов с исходным кодом
Теперь нужно добавить исходные файлы для компиляции:
1) Добавляем следующие файлы с исходным кодом:
а) Заголовочные файлы (*.h):
GraphicsGems.h, LinAl.h – вспомогательные операции линейной алгебры
render.h – объявление класса работы со сценой
scene.h – структуры, представляющие сцену
settings.h – различные настройки визуализации
б) Исходный код C++ (*.cpp):
main.cpp – главная исполняемая программа
render.cpp – реализация класса работы со сценой
в) Исходный код CUDA (*.cu):
rt.cu – функции загрузки сцены
rt_kernel.cu – ядро визуализации
GenerateRay.cu – функции, генерирующие лучи для трассировки
2) Создаем фильтр “RapidXML” для удобства и добавляем туда файлы, необходимые для работы библиотеки XML-парсера:
rapidxml. hpp, rapidxml_iterators. hpp, rapidxml_print. hpp, rapidxml_utils. hpp
3.2.1.6. Настройка компилятора CUDA
Для того, чтобы произвести сборку файлов «*.cu» нужно произвести следующие действия:
1) В свойствах файла «GenerateRay. cu» нужно указать:
«General» -> «Tool»: Custom Build Tool
2) В свойствах файла «rt. cu» нужно указать:
а) «General» -> «Tool»: Custom Build Tool
б) Передать параметры коммандной строке компилятору CUDA
«Custom Build Step» -> «General» -> «Command Line»:
«$(CUDA_BIN_PATH)\nvcc. exe - ccbin "$(VCInstallDir)bin" - c -DWIN32 - D_CONSOLE - D_MBCS - Xcompiler /EHsc,/W3,/nologo,/Wp64,/O2,/Zi,/MT - I"$(CUDA_INC_PATH)" -I./ - I "$(NVSDKCUDA_ROOT)/common/inc" - I "$(NVSDKCUDA_ROOT)/common/GLEW/include" -o $(ConfigurationName)\rt. obj rt. cu» (без кавычек)
С помощью этих команд будут получены объектные модули, которые затем будут собраны с другими объектными файлами в исполняемое приложение компоновщиком Visual Studio.
в) «Custom Build Step» -> «General» -> «Description»:
«Building with CUDA» (без кавычек)
Это сделано для удобства, чтобы видеть, когда работает компилятор CUDA в строке вывода отладки Output.
г) «Custom Build Step» -> «General» -> «Outputs»:
«$(ConfigurationName)\rt. obj» (без кавычек)
Здесь мы задаем имя файла объектного модуля.
д) «Custom Build Step» -> «General» -> «Additional Dependencies»:
«rt_kernel. cu» (без кавычек)
Так как файл «rt. cu» зависит от файла «rt_kernel. cu», нужно явно указать это.
3) Так как файл «rt_kernel. cu» собирается отдельно от среды разработки, нужно указать, что для него не требуется сборки:
«General» -> «Excluded From Build»: Yes
После всех проведенных операций можно скомпилировать и запустить программу, будет отрисована тестовая сцена, которая задана вручную. Сцена содержит в себе 7 треугольников (в данном визуализаторе треугольник является базовым примитивом). «Стены» и «пол» имеют нулевой коэффициент преломления и малый отражения – 0,01. Треугольник по центру – коэффициент преломления – 0,7, прозрачности – 1.0. Сцену освещают два точечных источника света.

Рис. 9. Результат работы визуализатора
3.2.2. Описание данных, передаваемых из трехмерного редактора
Информация, которую надо передать визуализатору – это данные о полигон, источниках света и о камере. Полигонов в случае используемого визуализатора является треугольник, который задается тремя точками (a, b, c), каждая из которых имеет по три координаты (x, y, z), принимающие вещественные значения. В данные о каждом треугольнике отчасти также включается параметры материала – цвет (модель RGB), коэффициенты отражения, преломления и прозрачности (все три коэффициента принимают значения от 0.0 до 1.0).
Источники света задаются местоположением (одна точка), значениями цвета и интенсивностью.
Камера задается одной точкой и тремя ортогональными нормализованными векторами – один указывает вверх, другой – вправо, а третий – указывает на точку, куда смотрит камера.
Исходя из сказанного был разработан формат файла, пример которого можно посмотреть в следующем подпункте.
3.2.3. Формат файла
Ниже приведен пример файла с описанием трехмерной сцены (три полигона, источник света, камера). Комментариями отделяются отдельные наборы сущностей, которые можно подвести под общий объект. Файл имеет кодировку UTF-8.
<scene>
<polygons>
<!-- пол -->
<polygon>
<color r="1.0" g="1.0" b="1.0" />
<a x="0" y="-30" z="-150" />
<b x="-150" y="-30" z="150" />
<c x="150" y="-30" z="150" />
<reflect value="0.01" />
<refract value="0" />
<alpha value="0" />
</polygon>
<!-- левая стена -->
<polygon>
<color r="1.0" g="0.2" b="0.2" />
<a x="-30" y="0" z="-150" />
<b x="-30" y="-150" z="150" />
<c x="-30" y="150" z="150" />
<reflect value="0.01" />
<refract value="0" />
<alpha value="0" />
</polygon>
<!-- правая стена -->
<polygon>
<color r="0.2" g="0.2" b="1.0" />
<a x="30" y="0" z="-150" />
<b x="30" y="-150" z="150" />
<c x="30" y="150" z="150" />
<reflect value="0.01" />
<refract value="0" />
<alpha value="0" />
</polygon>
</polygons>
<lights>
<light>
<position x="0" y="29" z="40" />
<properties r="1.0" g="1.0" b="1.0" intensity="250.0" />
</light>
</lights>
<camera>
<position x="0.0" y="0.0" z="0.0" />
<up x="0.0" y="1.0" z="0.0" />
<right x="1.0" y="0.0" z="0.0" />
<look x="0.0" y="0.0" z="1.0" />
</camera>
</scene>
Листинг 1. Пример XML-файла с описанием трехмерной сцены
3.2.4. Описание разработанного класса XMLImport
Класс «XMLImport» содержит конструктор, которому передается имя XML-файла с описанием трехмерной сцены – «filename». Public-функция Parse производит прохождение по всем узлам документа (который задается переменной «xmldoc», встроенного в RapidXml шаблонного типа «xml_document<>») и возвращает тип, в котором содержится информация о сцене в форме, необходимой визуализатору (TRender) . Private-функция «FileToString» обрабатывает переменную «fileString», являющейся указателем на строку и требующуюся для инициализации переменной «xmldoc».
class XMLImport
{
public:
XMLImport(const char* filename);
TRender Parse(TRender render);
private:
char* fileString;
void FileToString(const char* filename);
xml_document<> xmldoc;
};
Листинг 2. Объявление класса XMLImport
Главной частью класса является функция «Parse». В ней происходит разбор документа, который мы последовательно рассмотрим на примере прохождения по узлу полигонов в программе.
Для начала объявляем переменные указателя на шаблонный типа узла «xml_node» библиотеки RapidXml, представляющие узлы сцены и полигонов. Мы их сразу же инициализируем, обращаясь к методу «first_node» объекта документа «xmldoc», который находит корневой узел. Параметр строки в кавычках необязателен, однако очень удобен для обеспечения удобства чтения исходного текста программы. Указатель на переменную узла «params» используется для разбора параметров отдельного полигона. Так как значения параметров находятся не внутри узлов, а в их атрибутах, нам также потребуется указатель на шаблонный тип атрибутов. Тип «TPolygon» относится к интерфейсу визуализатора и является структурой, содержащей параметры полигона.
xml_node<> *scene = xmldoc. first_node("scene");
xml_node<> *polygons = scene->first_node("polygons");
xml_node<> *params;
xml_attribute<> *attrs;
TPolygon tpolygon;
Листинг 3. Объявление и инициализация переменных типа узла
Используя те же методы класса узла, а также метод «next_sibling» (следующий узел в данной части иерархии) мы последовательно проходим все узлы типа «полигон».
for(xml_node<> *polygon = polygons->first_node("polygon"); polygon; polygon = polygon->next_sibling("polygon"))
{ . . . }
Листинг 4. Условия цикла обхода узла полигонов
Внутри цикла мы получаем значения различных атрибутов (ниже в листинге расмотрены атрибута цвета – «r, g,b» узла «color») с помощью функции «value» и передаем их в поля структуры полигона. Функция «value» возвращает строку, поэтому требуется перевести ее в вещественное значение функцией «atof». В конце мы добавляем структуру полигона в объект типа «TRender».
params = polygon->first_node("color");
attrs = params->first_attribute("r");
tpolygon. Color. R = atof(attrs->value());
attrs = attrs->next_attribute("g");
tpolygon. Color. G = atof(attrs->value());
. . .
render. AddPolygonToScene(tpolygon);
Листинг 5. Операции, производимые внутри цикла
Ниже приведена блок-схема работы класса XMLImport. Полный листинг данного класа можно посмотреть в приложении 1 (пункт 7.1).
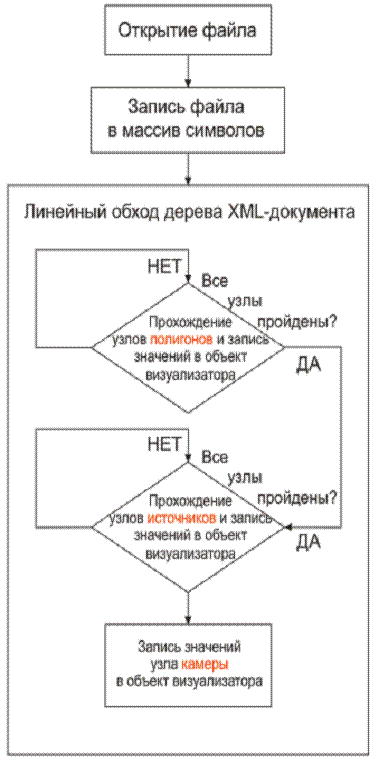
Рис. 11. Блок-схема алгоритма ввода информации в визуализатор
3.2.5. Описание библиотеки RapidXML
RapidXml – библиотека для парсинга XML-файлов, написанная человеком по имени Marcin Kalicinski и распространяемая бесплатно и свободно по одной из двух лицензий на выбор пользователя – «Boost Software License» (Version 1.0) или «The MIT License».
RapidXml – это попытка создать настолько быстрый XML-парсер, насколько возможно. При этом предоставляется удобство использования, соблюдается переносимость на различные платформы и минимально разумная совместимость со стандартом W3C.
RapidXml написан на С++, его скорость близка к скорости функции «strlen()» (оценка длины строки, см. рис. 10) при сравнении с использованием одних и тех же данных. Такая высокая скорость связана со следующими особенностями его архитектуры: во-первых, парсер не копирует строки, которые обрабатывает, а содержит указатели их местоположения в XML-документе. Во-вторых, RapidXml использует собственный объект для работы с памятью, так как использование операторов new/delete снизило бы скорость работы по сравнению с этой реализацией.
[15]
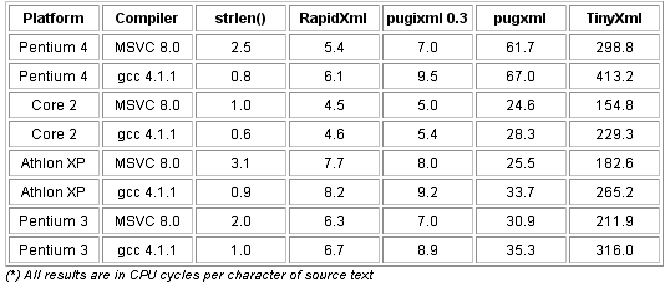 Рис. 10. Сравнение производительности RapidXml с другими парсерами
Рис. 10. Сравнение производительности RapidXml с другими парсерами
3.3. Написание программы-модуля для трехмерного редактора
3.3.1. Архитектура программы Autodesk Maya
3.3.1.1. Обзор
Целостное представление системы Maya и ее декомпозиция на основные
компоненты позволяют получить схему, показанную на следующем рисунке:

Рис. 11. Система Maya
Пользователь системы Maya взаимодействует с ее графическим пользо-вательским интерфейсом. Он выбирает пункты меню, изменяет параметры, анимирует и передвигает объекты и т. д. Во время его взаимодействия с интерфейсом пользователя Maya, на самом деле, инициируется команды языка сценариев MEL. Они посылаются командному ядру (Command Engine), где интерпретируются и выполняются.
Большинство команд MEL работают с графом зависимости Dependency Graph. Это происходит потому, что на интуитивном уровне Dependency Graph можно представить как полную трехмерную сцену. Граф зависимости не только описывает то, какие данные относятся к текущей сцене, но его структура и общая схема определяют способ обработки данных. Следующая глава описывает граф зависимости.
3.3.1.2. Структура приложения и Dependency Graph
Для описания структуры приложения Maya зададим вопрос: к чему же, в основе своей, действительно стремятся приложения трехмерной графики? На самом базовом уровне они лишь генерируют какие-то данные, которые затем обрабатываются при помощи серии операций. Конечным результатом этих шагов создания и обработки данных может, к примеру, стать итоговая полигональная сетка или ряд элементов изображения. Этапы преобразования фрагмента данных из начального состояния в окончательный результат можно легко определить как совокупность последовательных операций. Тогда результат одной операции подается на вход следующей и т. д. Каждая операция некоторым образом изменяет данные, а затем передает их следующей операции для дальнейшей обработки. Следовательно, процесс в целом можно представить себе так: данные приходят на один конец серии операторов и покидают другой конец в измененном виде. Подобное представление часто называют моделью потока данных.
Проанализировав тенденции ЗD-приложений, нетрудно обнаружить, что каждый отдельный модуль, на самом деле, можно разбить на более мелкие операции. Эти операции меньшего размера способны обрабатывать данные и передавать их следующим операциям. По сути, все функции, реализуемые обособленным модулем, можно инкапсулировать в серию взаимосвязанных операторов. Эти операторы принимают на вход одни данные и передают на выход другие. Будучи соединены последовательно, они образуют канал, или конвейер. Данные передаются первому оператору конвейера, а затем, после той или иной обработки, покидают последний оператор на другом конце. При правильном подборе операторов на одном конце конвейера можно поместить трехмерную модель, а на другом получить ряд элементов изображения. Продолжая обобщать этот подход, можно без труда прийти к тому, чтобы любые данные приходили на один конец конвейера и любые данные покидали другой конец. На самом деле, не обязательно требовать даже того, чтобы они относились к трехмерному пространству. Можно поместить на вход конвейера текстовый файл и получить на выходе отредактированную цепочку символов.
Ядро Maya, реализовано при использовании такой парадигмы потока данных. Названное ядро представлено графом зависимости - компонентом Dependency Graph. Ради простоты Dependency Graph будет обозначаться сокращенно, DG. Прежде чем двигаться дальше, должен отметить, что. с технической точки зрения, в основу DG положена двунаправленная модель, а не строгая модель потока данных.
DG предоставляет в ваше распоряжение только что упомянутые базовые строительные блоки. Он позволяет создавать произвольные данные, подаваемые на вход серии операций и служащие сырьем для получения обработанных данных на другом конце конвейера. Данные и операции над ними инкапсулируются в DG как узлы. Узлы заключают в себе любое количество ячеек памяти, которые содержат данные, используемые Maya. Кроме того, в состав узла входит оператор, способный обрабатывать данные узла и получать в результате нечто иное.
Распространенные задачи трехмерной графики могут быть решены путем соединения ряда узлов. Данные первого узла поступают на вход следующего, тот так или иначе их обрабатывает и выдает новые данные, затем поступающие на вход другого узла. Таким образом, данные проходят по сети узлов, начиная с самого первого узла и заканчивая последним. На этом пути узлы могут свободно обрабатывать и редактировать данные, как им будет угодно. Кроме того, они могут порождать новые данные, которые затем передаются в другие узлы. Каждый тип узлов предназначен для выполнения малого, ограниченного множества различных операций. Узел, управляющий ориентацией одного объекта, который должен указывать на другой, реализует лишь эту конкретную функцию. Он не может, к примеру, деформировать объект. Для решения именно этой задачи будет создан узел деформации. Проектируя узлы для решения конкретных единичных задач, можно сохранить их простоту и повысить управляемость.
Для выполнения какого-то сложного преобразования данных создается сеть подобных простых узлов. Количество и способ соединение узлов не ограничены, что дает возможность создавать сети произвольной сложности. Узлы Maya можно связывать и объединять в сложные потоки данных.
Свидетельством гибкости графа DG является тот факт, что при помощи узлов создаются и обрабатываются все данные (моделирование, динамика, анимация и т. д.) в среде Maya. Этот подход к построению сложных вещей из простых строительных блоков придает Maya реальную силу и гибкость. При таком универсальном подходе нетрудно заметить, что в систему Maya, не имеющую постоянного множества интерфейсов или понятия обособленных модулей, можно с легкостью встраивать новые возможности. [16]
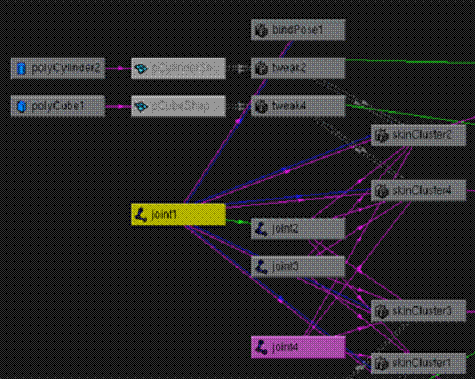
Рис. 12. Пример фрагмента DG
3.3.2. Программный интерфейс Maya API
3.3.2.1. Соглашение об именах
Имя каждого класса Maya начинается с заглавной буквы М, например MObject. Так как Maya не использует пространств имен C++, это помогает избегать любых конфликтов с прочими классами, описанными пользователем. Кроме того, Maya проводит разграничение между классами, помещая их в подклассы по признаку их функциональности. Хотя некоторые классы и не укладываются в типичную объектно-ориентированную иерархию «родитель – потомок», они действительно содержат общий набор функций и совместно пользуются общим префиксом. К примеру, вы обратите внимание на то, что многие классы имеют префикс МРх. От этого подкласса порождены все классы-заместители. Префиксы имен классов представлены в таблице:

Рис. 13. Таблица имен классов Maya API
3.3.2.2. Класс MObject
Класс MObject участвует в обращении к любым данным и потому служит для доступа ко всему спектру типов данных Maya. Может показаться, что он сам фактически содержит данные, которые вы используете. В действительности он представляет собой лишь описатель другого объекта, расположенного на уровне ядра, А поскольку это только описатель, его можно считать указателем на некий внутренний элемент данных, который входит в ядро, и лишь ядро может распоряжаться этим указателем. Помимо названного указателя, объект MObject как таковой не содержит никаких данных.
Реально объект MObject содержит «пустой» указатель (void *) на некие внутренние данные, подробные сведения о которых никогда не раскрываются, так что в своем коде вам не удастся преобразовать этот указатель в нечто значащее. Только ядро Maya точно знает о том, на что ссылается указатель. Класс MObject не содержит никаких данных, а напротив, включает в себя лишь ссылку, поэтому удаляя или создавая объект класса, вы просто удаляете и создаете описатель. На деле вы не уничтожаете и не порождаете никаких внутренних данных Maya.
3.3.2.3. Наборы функций MFn
Познакомившись с действующим в Maya механизмом представления собственных данных пакета, обратимся к вопросам их создания, редактирования и удаления. Прежде чем начать работу с данными, нужно получить их описатель. В качестве такого описателя Maya использует класс MObject. Когда адрес данных будет занесен в объект MObject, следующим шагом станет создание набора функций для дальнейшей обработки данных.
Наборы функций организованы в виде иерархии классов в соответствии с типом данных, который они обрабатывают. Все классы функциональных наборов основаны на MFnBase. Предки набора функций MFnTransform представлены рисунке ниже
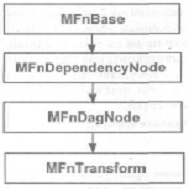
Рис. 14. Предки класса MFnTransform
Каждый очередной порожденный класс вносит свои новые функции, способные работать с более специализированными типами данных. Коль скоро MFnTransform порожден от MFnDagNode, он может оперировать всеми объектами, являющимися узлами DG. Аналогично, его предком является MFnDependencyNode, а значит, MFnTransform может обрабатывать любые узлы зависимости. Эта иерархия функциональности позволяет производным классам работать со всеми данными, которые умеют обрабатывать их предки.
Как Maya узнает о том, на какой тип данных ссылается объект MObject? Класс MObject содержит возвращающую тип объекта функцию-член apiTypef). Вызвав ее, каждый класс набора функций способен определить, совместим ли он с данным объектом. Кроме того, может использоваться еще одна аналогичная функция MObject с именем hasFn(). [17, 18, 19]
3.3.3. Настройка среды разработки
Для удобства настройки среды разработки стоит воспользоваться программой-мастером (wizard), которая автоматически создаст проект требуемого типа, добавит все зависимости и настройки. Ее заархивированный дистрибутив и инструкции по установке находится в папке «MayaInstFold\Maya2008\devkit\pluginwizard\» (MayaInstFold – путь куда была установлена Maya). После ее установки в Visual Studio появится новый тип проекта «MayaPluginWizard» с иконкой-логотипом Maya:

Рис. 15. Окно с проектами Visual Studio
3.3.4. Описание реализации программы-модуля
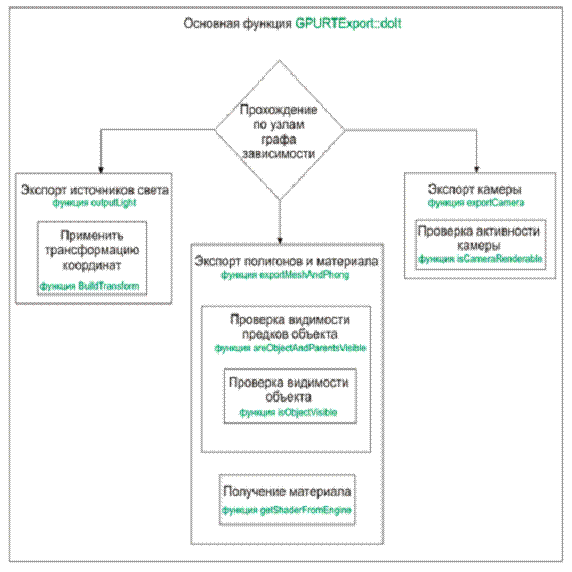
Работа программы-модуля, в основном, заключается в прохождении по узлам графа зависимости и поиске требуемых данных (см. рис. 17).
Сама программа состоит из девяти функций: одной основной, трех, отвечающих за экспорт требуемой информации и четырех вспомогательных.
Основная функция проходит по узлам графа зависимости и когда находит узел сетки полигонов, источника света или камеры, передает управление соответствующей функции экспорта. Вспомогательные функции требуются для определения видимости объектов, проверки камеры, является ли она активной и построения трансформаций координат (для перевода их из локальной системы координат в глобальную).
Важно заметить, что система координат Maya отличается от той, которая присутствует в визуализаторе. В Maya она – правосторонняя, а в визуализаторе – левосторонняя. Поэтому, для преобразования из одной системы в другую, потребовалось умножить на «-1» все значения координат оси «z» (рис. 16).
Полный листинг программы-модуля можно посмотреть в приложении 2 (пункт 7.2).
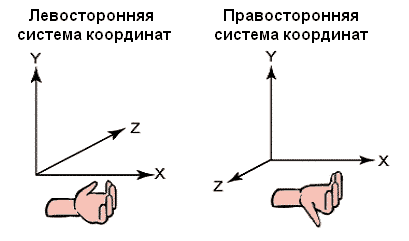
Рис. 16. Лево - и правосторонняя системы координат

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
