
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
1. Введение……………………………………………………………………………………………3
2. SMP и Hyper-Threading……………………………………………………………………………4
3. Hyper-Threading: совместимость………………………………………………………………….6
4. Hyper-Threading: зачем она нужна………………………………………………………………..7
5. Заключение………………………………………………………………………………………...10
6. Список использованных источников информации……………………………………………..12
Обзор технологии Hyper-Threading от Intel. Сравнение производительности. Задачи поставленные перед технологией. Каков прирост производительности за счёт использования технологии. Совместимость с ОС.
1. Введение
Разработка этой технологии корпорация Intel начала около… 10 лет назад! В 1993 году инженеры Intel заметили, что ресурсы процессоров при выполнении каких-либо задач используются не полностью. После проведения ряда исследований в этой области, Глен Хинтон, сотрудник корпорации Intel, предложил идею создания новой технологии, которая бы более интенсивно задействовала процессор. Технология получила название Hyper-Threading. В 1996 г. Инженеры Intel приступили к введению этой технологии в новую разработку - ядро, которое имело рабочее название Willamette. Впервые Hyper-Threading в физической реализации увидела свет в 1999 г., этим же годом датируются и первые тестирования процессоров с этой технологией.
Хотя первоначально она создавалась под кодовым именем "технология Джексона" (Jackson Technology) как возможный, вероятный вариант, Intel официально анонсировала свою технологию на форуме IDF прошлой осенью. Кодовое имя Jackson было заменено более подходящим Hyper-Threading. Итак, для того чтобы разобраться, как работает новая технология, нам нужны кое-какие первоначальные знания. А именно, нам нужно знать, что такое поток, как выполняются эти потоки. Почему работает приложение? Как процессор узнает, какие операции и над какими данными он должен совершать? Вся эта информация содержится в откомпилированном коде выполняемого приложения. И как только приложение получает от пользователя какую-либо команду, какие-либо данные, – процессору сразу же отправляются потоки, в результате чего он и выполняет то, что должен выполнить в ответ на запрос пользователя. С точки зрения процессора, поток – это набор инструкций, которые необходимо выполнить. Когда в вас попадает снаряд в Quake III Arena, или когда вы открываете документ Microsoft Word, процессору посылается определенный набор инструкций, которые он должен выполнить.
Процессор точно знает, где брать эти инструкции. Для этой цели предназначен редко упоминаемый регистр, называемый счетчиком команд (Program Counter, PC). Этот регистр указывает на место в памяти, где хранится следующая для выполнения команда. Когда поток отправляется на процессор, адрес памяти потока загружается в этот счетчик команд, чтобы процессор знал, с какого именно места нужно начать выполнение. После каждой инструкции значение этого регистра увеличивается. Весь этот процесс выполняется до завершения потока. По окончании выполнения потока, в счетчик команд заносится адрес следующей инструкции, которую нужно выполнить. Потоки могут прерывать друг друга, при этом процессор запоминает значение счетчика команд в стеке и загружает в счетчик новое значение. Но ограничение в этом процессе все равно существует – в каждую единицу времени можно выполнять лишь один поток. Существует общеизвестный способ решения данной проблемы. Заключается он в использовании двух процессоров – если один процессор в каждый момент времени может выполнять один поток, то два процессора за ту же единицу времени могут выполнять уже два потока. Отметим, что этот способ не идеален. При нем возникает множество других проблем. С некоторыми, вы уже, вероятно, знакомы. Во-первых, несколько процессоров всегда дороже, чем один. Во-вторых, управлять двумя процессорами тоже не так-то просто. Кроме того, не стоит забывать о разделении ресурсов между процессорами. Например, до появления чипсета AMD 760MP, все x86 платформы с поддержкой многопроцессорности разделяли всю пропускную способность системной шины между всеми имеющимися процессорами. Но основной недостаток в другом – для такой работы и приложения, и сама операционная система должны поддерживать многопроцессорность. Способность распределить выполнение нескольких потоков по ресурсам компьютера часто называют многопоточностью. При этом и операционная система должна поддерживать многопоточность. Приложения также должны поддерживать многопоточность, чтобы максимально эффективно использовать ресурсы компьютера. Не забывайте об этом, когда мы будем рассматривать ещё один подход решения проблемы многопоточности, новую технологию Hyper-Threading от Intel.
![]() Казалось бы не так уж и давно вышел Pentium 4 2,8 ГГц, но компания Intel видимо настолько горда способностью своего нового процессорного ядра к постоянному “разгону”, что не дает нам покоя анонсами все новых и новых процессоров. Однако сегодняшний процессор отличается от предыдущей топовой модели не только на 200 с небольшим мегагерц — то, о чем давно мечтали многие пользователи, наконец-то свершилось: технология эмуляции двух процессоров на одном процессорном ядре, ранее бывшая достоянием лишь сверхдорогих Xeon.
Казалось бы не так уж и давно вышел Pentium 4 2,8 ГГц, но компания Intel видимо настолько горда способностью своего нового процессорного ядра к постоянному “разгону”, что не дает нам покоя анонсами все новых и новых процессоров. Однако сегодняшний процессор отличается от предыдущей топовой модели не только на 200 с небольшим мегагерц — то, о чем давно мечтали многие пользователи, наконец-то свершилось: технология эмуляции двух процессоров на одном процессорном ядре, ранее бывшая достоянием лишь сверхдорогих Xeon.
Все последующие модели Pentium 4, начиная с рассматриваемого, будут обладать поддержкой технологии Hyper-Threading. Однако кто-то может вполне резонно поинтересоваться: «А зачем мне двухпроцессорная машина дома? И действительно — зачем? Именно это я и постарался объяснить ниже. Итак: Hyper-Threading — что это такое и зачем он может быть нужен в обычных персональных компьютерах?
Как работает классическая SMP(Symmetric Multi-Processor) - система с точки зрения обычной логики? Не так уж велико количество пользователей, хорошо себе представляющих как работает SMP-система, и в каких случаях от использования двух процессоров вместо одного можно ожидать реального увеличения быстродействия, а в каких — нет.
Итак, представим, что у нас есть, к примеру, два процессора вместо одного. Что это дает?
В общем-то ничего. Потому что в дополнение к этому нужна еще и операционная система, умеющая задействовать эти два процессора. Эта система должна быть по определению многозадачной (иначе никакого смысла в наличии двух CPU просто быть не может), но кроме этого, ее ядро должно уметь распараллеливать вычисления на несколько CPU. Классическим примером многозадачной ОС, которая этого делать не умеет, являются все ОС от Microsoft, называемые обычно для краткости “Windows 9x” — 95, 95OSR2, 98, 98SE, Me. Они просто-напросто не могут определить наличие более чем одного процессора в системе.
Поддержкой SMP обладают ОС этого же производителя, построенные на ядре NT: Windows NT 4, Windows 2000, Windows XP. Также этой поддержкой обладают все ОС, основанные на идеологии Unix — всевозможные Free - Net - BSD, коммерческие Unix (такие как Solaris, HP-UX, AIX), и многочисленные разновидности Linux.
Если же два процессора все же определились системой, то дальнейший механизм их задействования в общем довольно прост. Если в данный момент времени исполняется одно приложение — то все ресурсы одного процессора будут отданы ему, второй же будет просто простаивать. Если приложений стало два — второе будет отдано на исполнение второму CPU, так что по идее скорость выполнения первого не должна уменьшиться. Однако на самом деле все сложнее.
Исполняемое пользовательское приложение может быть запущено всего одно, но количество процессов (т. е. фрагментов машинного кода, предназначенных для выполнения некой задачи) в многозадачной ОС всегда намного больше. Поэтому на самом деле второй CPU способен немного “помочь” даже одиночной задаче, взяв на себя обслуживание процессов, порожденных операционной системой.
Кроме того, даже одно приложение может порождать потоки (threads), которые при наличии нескольких CPU могут исполняться на них по отдельности. Так, например, поступают почти все программы рендеринга — они специально писались с учетом возможности работы на многопроцессорных системах. Поэтому в случае использования потоков выигрыш от SMP иногда довольно весом даже в “однозадачной” ситуации.
По сути, поток отличается от процесса только двумя вещами — он во-первых никогда не порождается пользователем (процесс может запустить как система, так и человек, в последнем случае процесс = приложение; появление потока инициируется исключительно запущенным процессом), и во-вторых — поток выгружается вместе с родительским процессом независимо от своего желания.
Также не стоит забывать, что в классической SMP-системе оба процессора работают каждый со своим кэшем и набором регистров, но память у них общая. Поэтому если две задачи одновременно работают с ОЗУ, мешать они друг другу будут все равно, даже если CPU у каждой свой. Фактически — это тоже многопроцессорность, только виртуальная. Ибо процессор Pentium 4 на самом деле один. А процессоров ОС видит — два.
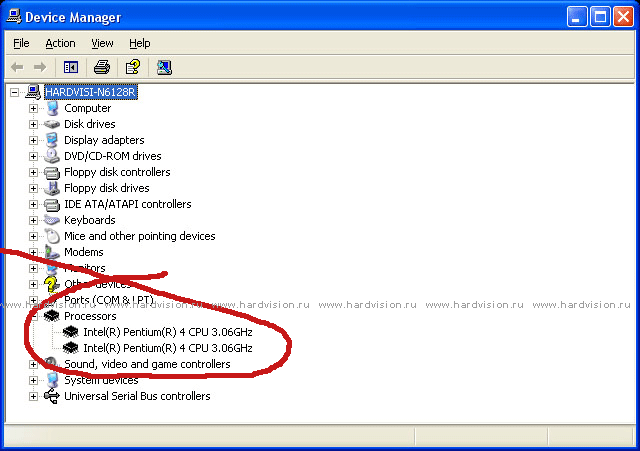
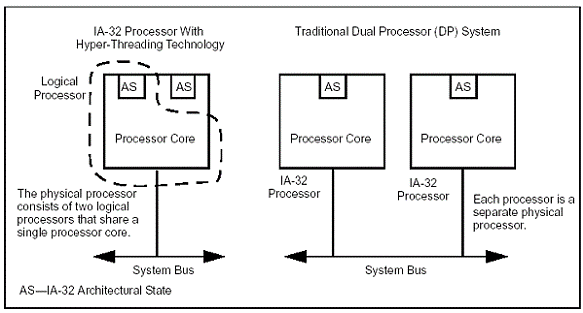
Классическому “одноядерному” процессору добавили еще один блок AS — IA-32 Architectural State. Architectural State содержит состояние регистров (общего назначения, управляющих, APIC, служебных). Фактически, AS#1 плюс единственное физическое ядро (блоки предсказания ветвлений, ALU, FPU, SIMD-блоки и пр.) представляет из себя один логический процессор (LP1), а AS#2 плюс все то же физическое ядро — второй логический процессор (LP2). У каждого LP есть свой собственный контроллер прерываний (APIC — Advanced Programmable Interrupt Controller) и набор регистров. Для корректного использования регистров двумя LP существует специальная таблица — RAT (Register Alias Table), согласно данным в которой можно установить соответствие между регистрами общего назначения физического CPU. RAT у каждого LP своя. В результате получается схема, при которой на одном и том же ядре могут свободно выполняться два независимых фрагмента кода т. е. де-факто — многопроцессорную систему!
3. Hyper-Threading: совместимость
Кроме того, возвращаясь к вещам практическим и приземленным, хотелось бы затронуть еще один немаловажный аспект: не все ОС, даже поддерживающие многопроцессорность, могут работать с таким CPU как с двумя. Связано это с таким “тонким” моментом, как изначальное определение количества процессоров при инициализации операционной системы. Intel прямо заявляет, что ОС без поддержки ACPI второй логический процессор увидеть не смогут. Кроме того, BIOS системной платы также должен уметь определять наличие процессора с поддержкой Hyper-Threading. Фактически, применительно, к примеру, к Windows, это означает, что оказывается неприемлемой не только линейка Windows 9x, но и Windows NT — последняя ввиду отсутствия поддержки ACPI не сможет работать с одним новым Pentium 4 как с двумя.
Несмотря на заблокированную возможность работы с двумя физическими процессорами, с двумя логическими, получаемыми с помощью Hyper-Threading, сможет работать Windows XP Home Edition.
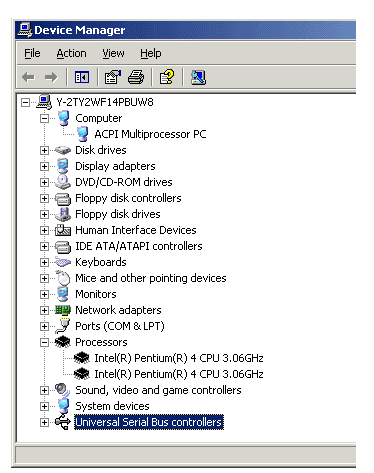 А Windows XP Professional, кстати, несмотря на ограничение количества физических процессоров до двух, при двух установленных CPU с поддержкой Hyper-Threading честно “видит” четыре.
А Windows XP Professional, кстати, несмотря на ограничение количества физических процессоров до двух, при двух установленных CPU с поддержкой Hyper-Threading честно “видит” четыре.
К сожалению новые CPU с частотой более 3 ГГц могут потребовать замены системной платы.
Даже при номинальном сохранении все того же процессорного разъема Socket 478 Intel не удалось оставить в неприкосновенности потребляемую мощность и тепловыделение новых процессоров. Увеличение потребления по току связано не только с ростом частоты, но и с тем, что из-за ожидаемого использования “виртуальной многопроцессорности” нагрузка на ядро в среднем вырастет, следовательно, возрастет и средняя потребляемая мощность. “Старые” системные платы в некоторых случаях могут быть совместимы с новыми CPU — но только если делались “с запасом”. Грубо говоря, те производители, которые делали свои платы в соответствии с рекомендациями самой Intel относительно потребляемой Pentium 4 мощности, оказались в проигрыше по отношению к тем, кто немного перестраховался. Но и это еще не все. Кроме ОС, BIOS и электроники платы, с технологией Hyper-Threading должен быть совместим еще и чипсет. Поэтому счастливыми обладателями двух процессоров по цене одного смогут стать только те, чья системная плата основана на одном из новых чипсетов с поддержкой 533 МГц FSB: i850E, i845E, i845PE/GE.
4. Hyper-Threading: зачем она нужна
Компания Intel, если внимательно посмотреть, никогда не отличалась абсолютным совершенством своих продуктов, более того — вариации на те же темы от других производителей подчас получались гораздо более интересными и концептуально стройными. Однако, как оказалось, абсолютно все делать совершенным и не нужно — главное чтобы чип олицетворял собой какую-то идею, и идея эта приходилась очень вовремя и к месту. И еще — чтобы ее просто не было у других.
Так было с Pentium, когда Intel противопоставила весьма производительному в целочисленных операциях AMD Am5x86 мощный FPU. Так было с Pentium II, который получил широкую шину и быстрый кэш второго уровня, благодаря чему за ним так и не смогли угнаться все процессоры Socket 7. Так было и с Pentium 4, который противопоставил всем остальным наличие поддержки SSE2 и быстрый рост частоты — и тоже де-факто выиграл. Сейчас Intel предлагает Hyper-Threading.
Я думаю, что стоит задуматься — почему производитель, известный грамотностью своих инженеров (ни слова про маркетологов) и громадными суммами, которые он тратит на исследования, предлагает эту технологию.
Объявить Hyper-Threading “очередной маркетинговой штучкой”, конечно, проще простого. Однако не стоит забывать, что это технология, она требует исследований, денег на разработку, времени, сил. Не проще ли было нанять за меньшую сумму еще одну сотню PR-менеджеров или сделать еще десяток красивых рекламных роликов? Видимо, не проще. А значит, “что-то в этом есть”. Следует попытаться понять даже не то, что получилось в результате, а то, чем руководствовались разработчики IAG (Intel Architecture Group), когда принимали решение — разрабатывать “эту интересную мысль” дальше, или отложить на потом.
Как ни странно, для того чтобы понять как функционирует Hyper-Threading, вполне достаточно понимать как работает любая многозадачная операционная система. И действительно — ведь исполняет же каким-то образом один процессор сразу десятки задач? Этот “секрет” всем уже давно известен — на самом деле, конечно одновременно все равно выполняется только одна (на однопроцессорной системе) задача, просто переключение между кусками кода разных задач выполняется настолько быстро, что создается иллюзия одновременной работы большого количества приложений.
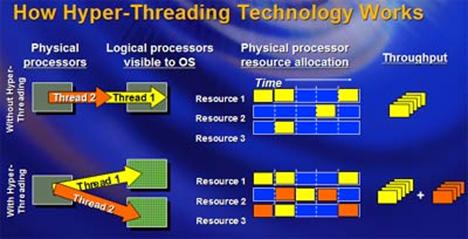
По сути, Hyper-Threading предлагает то же самое, но реализована аппаратно, внутри самого CPU. Есть некоторое количество различных исполняющих блоков (ALU, MMU, FPU, SIMD), и есть два “одновременно” исполняемых фрагмента кода. Специальный блок отслеживает, какие команды из каждого фрагмента необходимо выполнить в данный момент, после чего проверяет, загружены ли работой все исполняющие блоки процессора. Если один из них простаивает, и именно он может исполнить эту команду — ему она и передается. Естественно, существует и механизм принудительного посыла команды на выполнение — в противном случае один процесс мог бы захватить весь процессор (все исполняющие блоки) и исполнение второго участка кода (исполняемого на втором “виртуальном CPU”) было бы прервано. Данный механизм (пока) не является интеллектуальным т. е. не способен оперировать различными приоритетами, а просто чередует команды из двух разных цепочек в порядке живой очереди. Если, конечно, не возникает ситуации, когда команды одной цепочки по исполняющим блокам нигде не конкурируют с командами другой. В этом случае получается действительно на 100% параллельное исполнение двух фрагментов кода.
Самое очевидное следствие применения технологии Hyper-Threading — повышение коэффициента полезного действия процессора. Действительно — если одна из программ использует в основном целочисленную арифметику, а вторая — выполняет вычисления с плавающей точкой, то во время исполнения первой FPU просто ничего не делает, а во время исполнения второй — наоборот, ничего не делает ALU. Казалось бы, на этом можно закончить.
Однако это идеальный (с точки зрения применения Hyper-Threading) вариант. Следует рассмотреть и другой: обе программы задействуют одни и те же блоки процессора. Понятно, что ускорить выполнение в данном случае довольно сложно — ибо физическое количество исполняющих блоков от “виртуализации” не изменилось. А вот не замедлится ли оно?
В случае с процессором без Hyper-Threading имеется просто “честное” поочередное выполнение двух программ на одном ядре с арбитром в виде операционной системы, и общее время их работы определяется:
временем выполнения кода программы №1
временем выполнения кода программы №2
временными издержками на переключение между фрагментами кода программ №1 и №2
В случае с Hyper-Threading схема становится немного другой:
время выполнения программы №1 на процессоре №1 (виртуальном)
время выполнения программы №2 на процессоре №2 (виртуальном)
время на переключение одного физического ядра (как набора требуемых обеим программам исполняющих блоков) между двумя эмулируемыми “виртуальными CPU”
Остается признать, что и тут Intel поступает вполне логично: конкурируют между собой по быстродействию только пункты за номером три, и если в первом случае действие выполняется программно-аппаратно (ОС управляет переключением между потоками, задействуя для этого функции процессора), то во втором случае имеется полностью аппаратное решение — процессор все делает сам. Теоретически, аппаратное решение всегда оказывается быстрее программного.
Также одним из серьезнейших неприятных моментов является то, что Pentium 4 приходится иметь дело с классическим x86-кодом, в котором активно используется прямое адресование ячеек и даже целых массивов, находящихся за пределами процессора — в ОЗУ. Да и вообще большинство обрабатываемых данных чаще всего находится там. Поэтому делить между собой виртуальные CPU будут не только регистры, но и общую для обоих процессорную шину, минуя которую данные в CPU попасть просто не могут.
Однако тут есть один тонкий момент: на сегодняшний день “честные” двухпроцессорные системы на Pentium III и Xeon находятся в точно такой же ситуации! Потому что шина AGTL+, доставшаяся в наследство всем сегодняшним процессорам Intel от знаменитого Pentium Pro (в дальнейшем ее лишь подвергали модификациям, но идеологию практически не трогали) — всего одна, сколько бы CPU ни было установлено в системе.
Отойти от этой схемы на x86 попробовала только AMD со своим Athlon MP — у AMD 760MP/760MPX от каждого процессора к северному мосту чипсета идет отдельная шина. Впрочем, даже в таком варианте проблема отодвигается не очень далеко — так как шина памяти точно одна — причем вот в этом случае уже везде.
Но и даже из этого в общем-то не очень приятного момента Hyper-Threading может помочь извлечь какую-то пользу. Дело в том, что по идее должен будет наблюдаться существенный прирост производительности не только в случае с несколькими задачами, использующими разные функциональные блоки процессора, но и в том случае, если задачи по-разному работают с данными, находящимися в ОЗУ. Если одно приложение что-то усиленно считает “внутри себя”, другое же — постоянно подкачивает данные из ОЗУ, то общее время выполнения их в случае использования Hyper-Threading по идее должно уменьшиться даже если они используют одинаковые блоки исполнения инструкций — хотя бы потому, что команды на чтение данных из памяти смогут обрабатываться в то время, пока наше первое приложение будет что-то считать.
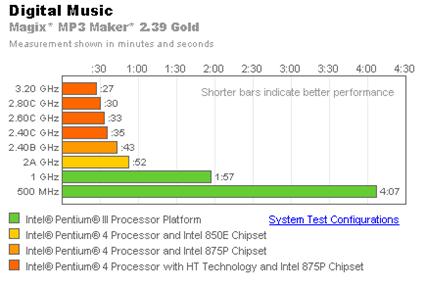
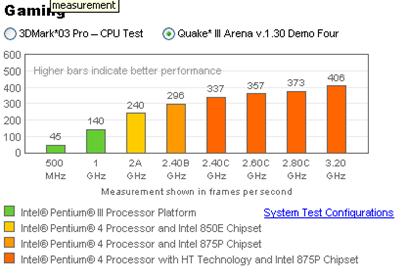
Максимум эффективности от Hyper-Threading.
Вы думаете, Intel разработала Hyper-Threading только лишь для своей линейки серверных процессоров? Конечно же, нет. Если бы это было так, они бы не стали впустую тратить место на кристалле других своих процессоров. По сути, архитектура NetBurst, использующаяся в Pentium 4 и Xeon, как нельзя лучше подходит для ядра с поддержкой одновременной многопоточности. Давайте ещё раз представим себе процессор. На этот раз в нем будет ещё одно исполнительное устройство – второе целочисленное устройство. С использованием второго целочисленного устройства, единственный конфликт случился только на последней операции. Наш теоретический процессор в чем-то похож на Pentium 4. В нем имеется целых три целочисленных устройства (два ALU и одно медленное целочисленное устройство для циклических сдвигов). А что ещё более важно, оба целочисленных устройства Pentium 4 способны работать с двойной скоростью – выполнять по две микрооперации за такт. А это, в свою очередь, означает, что любое из этих двух целочисленных устройств Pentium 4/Xeon могло выполнить те две операции сложения из разных потоков за один такт.
Но это не решает нашей проблемы. Было бы мало смысла просто добавлять в процессор дополнительные исполнительные устройства с целью увеличения производительности от использования Hyper-Threading. С точки зрения занимаемого на кремнии пространства это было бы крайне дорого. Вместо этого, Intel предложила разработчикам оптимизировать программы под Hyper-Threading.
Используя инструкцию HALT, можно приостановить работу одного из логических процессоров, и тем самым увеличить производительность приложений, которые не выигрывают от Hyper-Threading. Итак, приложение не станет работать медленнее, вместо этого один из логических процессоров будет остановлен, и система будет работать на одном логическом процессоре – производительность будет такой же, что и на однопроцессорных компьютерах. Затем, когда приложение сочтет, что от Hyper-Threading оно выиграет в производительности, второй логический процессор просто возобновит свою работу.
Проблемы с Hyper-Threading в Windows XP SP1
"Компьюлента" уже сообщала о проблемах с производительностью, возникающих на компьютерах на базе процессоров Intel с технологией Hyper-Threading после установки первого сервис-пака для ОС Windows XP. Однако компания Microsoft сообщила о обнаружении еще одной проблемы аналогичного свойства. Она связана с возникновении сбоев в модуле Ky. sys и проявляется вследствие некорректной обработки пакетов запроса ввода-вывода (IRP). Возникающая при этом утечка ресурсов и приводит к сбоям. В Microsoft создали заплатку, исправляющую данный недостаток, однако устанавливать ее рекомендуется лишь в крайних случаях. Большинству пользователей лучше дождаться нового сервис-пака.
5. Заключение
В очередной раз, к радости всего прогрессивного человечества, Intel выпустила новый Pentium 4, производительность которого еще выше чем у предыдущего Pentium 4, и дело тут не только в лишних двухстах мегагерцах, а и в новой технологии под названием – Hyper-Threading
Технология Hyper-Threading с теоретической точки зрения выглядит весьма неплохо и соответствует реалиям сегодняшнего дня. Уже довольно редко можно застать пользователя с одним сиротливо открытым окном на экране — всем хочется одновременно и музыку слушать, и по Internet бродить, и диски с любимыми MP3 записывать, а может даже, и поиграть на этом фоне в какую-нибудь компьютерную игру. Есть только два способа повышать производительность — повышать частоту, и повышать производительность за такт. И, если вся архитектура Pentium4 рассчитана на первый путь, то Hyper Threading — как раз второй. Уже с этой точки зрения ее можно только приветствовать. Так же Hyper Threading несет несколько интересных следствий, как-то: изменение парадигмы программирования, привнесение многопроцессорности в массы, увеличение производительности процессоров. Однако, на этом пути есть несколько "больших кочек", на которых важно не "застрять": отсутствие нормальной поддержки со стороны операционных систем и, самое главное, необходимость перекомпиляции (а в некоторых случаях и смены алгоритма) приложений, чтобы они в полной мере смогли воспользоваться преимуществами Hyper Threading. К тому же, наличие Hyper Threading сделало бы возможной действительно параллельную работу операционной системы и приложений — а не "кусками" по очереди, как сейчас. Конечно, при условии, что хватит свободных исполнительных устройств.
Hyper-Threading позволяет увеличить коэффициент полезного действия процессора в определенных ситуациях. В частности — в ситуациях, когда одновременно исполняются разнородные по характеру приложения. Это конечно плюс, но он не является всеобъемлющим и глобальным. Потому что эффект от Hyper-Threading наблюдается исключительно в некоторых случаях. Понятно, что появление CPU, способного в два раза быстрее делать все то, что делалось ранее — это громадный прорыв. Однако Intel не стал инициировать начало новой эпохи перемен, просто добавив своему процессору возможность кое-что делать быстрее.
Однако Hyper-Threading нельзя назвать “бумажной” технологией, так как при определенных комбинациях она дает вполне ощутимый эффект. Даже намного больший эффект, чем иногда наблюдается при сравнении, к примеру, двух платформ с одним процессором на разных чипсетах. Хотя эффект этот наблюдается не всегда, и существенно зависит от стиля работы пользователя с компьютером. Причем именно здесь проявляется то что: Hyper-Threading — это не SMP. “Классический SMP-стиль”, где пользователь рассчитывает на реакцию столь же классической “честной” многопроцессорной системы, здесь не даст желаемого результата.
“Стиль Hyper-Threading” — это сочетание процессов “развлекательных” или “служебных” с процессами “рабочими”. Пользователь не получит существенного ускорения от CPU с поддержкой этой технологии в большинстве классических многопроцессорных задач, или если по привычке будет запускать только одно приложение в один момент времени. Но он скорее всего получит уменьшение времени исполнения многих фоновых задач, исполняемых в качестве “довеска” к обычной работе. Фактически, Intel просто еще раз напомнила всем нам, что операционные системы, в которых мы работаем — многозадачные. И предложила способ ускорения — но не столько одного какого-то процесса самого по себе, сколько комплекса выполняемых одновременно приложений. Это интересный и достаточно востребованный подход.
Хотя мы все были крайне обрадованы, когда до нас дошли слухи об использовании Hyper-Threading в ядрах всех современных Pentium 4/Xeon, все же это не будет бесплатной производительностью на все случаи жизни. Причины ясны, и технологии предстоит преодолеть ещё многое, прежде чем мы увидим Hyper-Threading, работающую на всех платформах, включая домашние компьютеры. А при поддержке разработчиков, технология определенно может оказаться хорошим союзником Pentium 4, Xeon, и процессорам будущего поколения от Intel.
При существующих ограничениях и при имеющейся технологии упаковки, Hyper-Threading кажется более разумным выбором для потребительского рынка, чем, например, подход AMD в SledgeHammer – в этих процессорах используется целых два ядра. И до тех пор, пока не станут совершенными технологии упаковки, такие как Bumpless Build-Up Layer, стоимость разработки многоядерных процессоров может оказаться слишком высокой.
Интересно заметить, насколько разными стали AMD и Intel за последние несколько лет. Ведь когда-то AMD практически копировала процессоры Intel. Теперь же компании выработали принципиально иные подходы к будущим процессорам для серверов и рабочих станций. AMD на самом деле проделала очень длинный путь. И если в процессорах Sledge Hammer действительно будут использоваться два ядра, то по производительности такое решение будет эффективнее, чем Hyper-Threading. Ведь в этом случае кроме удвоения количества всех исполнительных устройств снимаются проблемы, которые мы описали выше.
Hyper-Threading ещё некоторое время не появится на рынке обычных ПК, но при хорошей поддержке разработчиков, она может стать очередной технологией, которая опустится с серверного уровня до простых компьютеров.
Список использованных источников информации.
http://www. *****/?dir=cpu&doc=intel_p4_northwood_306_ht http://*****/reviews/mainsystem/hyper-treading/ http://www. /ru/ http://www. alexey-das. *****/hard/cpu/ht/ht. htm