
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Сортировка с помощью дерева (пирамидальная сортировка).
Этот метод возник при попытке улучшить сортировку выбором, эффективность которой – О(n2).
Напомню, сортировка выбором основана на выборе наименьшего ключа среди n элементов, затем среди n-1 элементов и т. д. Поиск наименьшего ключа соответственно требует n-1, n-2, n-3 и т. д. сравнений.
Можно ускорить сортировку, уменьшив количество сравнений при поиске наименьшего элемента, если в результате каждого прохода получать больше информации, чем просто позицию минимального элемента.
Например, можно сравнить попарно соседние элементы и определить в каждой паре меньший элемент. Для этого потребуется n/2 сравнений. Затем сравнить попарно меньшие элементы и определить меньшие из меньших (требуется n/4 сравнений). Наконец получится одна пара меньших из меньших и определяется наименьший элемент.
Изобразим этот процесс графически:
![]()
![]() 06
06
12 ![]()
![]()
![]()
![]() 06
06
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() 44
44
4406 67
Хотя в сумме получилось n-1 сравнений, но зато определен минимальный элемент и получено дерево выбора, хранящее информацию о наименьших элементах в подгруппах из двух, четырех и т. д. элементах.
Как использовать это дерево для выбора следующего наименьшего элемента?
Для этого убираем из дерева выбора наименьший элемент (выбор) и заменяем его в дереве на «дыру» (или ключ ![]() ). Для этого мы спускаемся по дереву по пути, указанному значением наименьшего ключа и заменяем его «дырой».
). Для этого мы спускаемся по дереву по пути, указанному значением наименьшего ключа и заменяем его «дырой».
![]()
![]()
![]()
12 ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() 44
44![]()
4406 67
При возврате корректируем промежуточные узлы дерева, замененные «дырами», выбираем вновь в парах наименьшие значения (снизу вверх).
![]()
![]() 12
12
12 ![]()
![]()
![]()
![]() 18
18
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() 44
44
4467
В корне дерева вновь оказался элемент с наименьшим ключом. Вновь удаляем его из дерева и т. д.
Повторив n таких шагов, дерево становится пустым (то есть состоит из «дыр») и процесс сортировки закончен.
Поскольку операция спуска по дереву при исключении элемента на каждом шаге пропорциональна log2n, то сортировка займет время nlog2n, то есть это лучше, чем О(n2) для элементарной сортировки выбором.
Но мы видим, что задача сортировки стала сложнее. Она требует хранение дополнительной информации (2n-1) о структуре дерева, сам алгоритм усложнился и выигрыш кажется сомнительным. Желательно избавиться от «дыр» в дереве, которые приводят к ненужным сравнениям при удалении элементов. Кроме того, хотелось бы вернуться к сортировке без использования дополнительной памяти.
То есть нужно найти такой способ организации дерева, чтобы не использовать дополнительной памяти и в нем не было бы «дыр».
Автор Дж. Уильямс предложил организацию дерева в виде пирамиды, и сортировка соответственно называется пирамидальной сортировкой.
Пирамида определяется как последовательность ключей 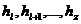 такая, что
такая, что ![]()
![]() и
и  для i=l, …, z/2, где
для i=l, …, z/2, где ![]() - левый сын,
- левый сын, ![]() - правый сын узла
- правый сын узла ![]() .
.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Часто пирамиду называют частично упорядоченным деревом, поскольку здесь не обязательно соблюдение требования ![]() . Такую последовательность (дерево) можно разместить в массиве. Корень дерева занимает первую позицию, то есть имеет индекс 1, сыновья корня – позиции 2, 3. В свою очередь сыновья сыновей занимают позиции 4 и 5 и 6 и 7 соответственно и т. д. Попробуем использовать вместо дерева выбора такую пирамиду. Например, пирамида является деревом выбора.
. Такую последовательность (дерево) можно разместить в массиве. Корень дерева занимает первую позицию, то есть имеет индекс 1, сыновья корня – позиции 2, 3. В свою очередь сыновья сыновей занимают позиции 4 и 5 и 6 и 7 соответственно и т. д. Попробуем использовать вместо дерева выбора такую пирамиду. Например, пирамида является деревом выбора.
![]()
![]() 06
06
![]()
![]()
![]()
![]() 42 12
42 12
55
Как построить пирамиду на базе сортируемого массива?
Во-первых, надо рассматривать алгоритм построения и расширения пирамиды. Пусть дана исходная пирамида из семи элементов, которую мы хотим расширить, добавив элемент ![]() =44.
=44.
![]()
![]()
![]()
![]()
![]()
![]()
![]() 42 06
42 06
55
Добавляем этот элемент в корень будущей пирамиды (в массиве - слева). Далее этот элемент просеивается по пути, на котором находятся меньшие по сравнению с ним элементы. Просеивание идет до тех пор, пока элемент не займет правильное место. Встречающиеся на пути меньшие элементы соответственно поднимаются вверх. При этом в корень попадает минимальный элемент.
![]()
![]() 44
44
![]()
![]()
![]()
![]() 42 06
42 06
55
При просеивании соблюдается правило: если промежуточный узел имеет сыновей, ключи которых меньше, то следующим выбирается сын с наименьшим значением, то есть при просеивании 44 мы выберем узлы 6 и 12
![]()
![]() 06
06
![]()
![]()
![]()
![]() 42 12
42 12
55
Как в сортируемом массиве выстроить пирамиду?
44|
![]()
Вторую половину массива можно считать нижним уровнем пирамиды. Здесь элементы взаимно не упорядочены. Будем постепенно добавлять к пирамиде слева элементы, и просеивать их.
44|
![]()
44 55 |67
![]()
44 |12 67
![]()
0644 67
![]()
![]() 06 1
06 1
42 ![]()
![]()
![]()
![]() 2 12 3
2 12 3
![]() 5 7
5 7
67 8
Теперь надо удалить элемент из пирамиды таким образом, чтобы на ее вершине вновь оказался минимальный элемент. Это можно сделать, взяв самый последний элемент в пирамиде и поставив его в вершину. Последующее просеивание поставит в вершину новый минимальный элемент.
![]()
![]() 12
12
![]()
![]()
![]()
![]() 42 18
42 18
55
И т. д. пока пирамида не опустеет.
Рассмотрим алгоритм в пирамиде. Входом является массив и индексы, задающие границы строящейся в массиве пирамиды.
Shift (A, l, R)
1 i![]() l
l
2 j![]() 2i
2i
3 x![]() A[i]
A[i]
4 if j<R & A[j+1]<A[j]
5 then j![]() j+1
j+1
6 while j![]() R & A[j]<x
R & A[j]<x
7 do A[i] ![]() A[j]
A[j]
8 i![]() j
j
9 j![]() 2i
2i
10 if j<R & A[j+1]<A[j]
11 then j![]() j+1
j+1
12 A[i] ![]() x
x
Вопрос: куда девать извлекаемые из пирамиды элементы? Их можно помещать на место последних элементов, которые переносятся в вершину пирамиды во время сортировки.
Итак, имеем исходную пирамиду:
0644 67
Удаляем элемент из вершины (06) и затем помещаем в вершину последний элемент (67). Значение 06 помещаем на место 67. При этом правая граница пирамиды смещается влево на одну позицию.
![]()
![]()
![]()
![]() 6744 | 06
6744 | 06
1244 06
![]()
![]() 44| 12 06
44| 12 06
 |
1812 06
![]()
![]()
![]()
![]() 67|
67|
4212 06
94|
4412 | 06
![]()
![]() 6712 | 06
6712 | 06
 |
5512 | 06
94 67 |06
6712 | 06
Heap_Sort (A)
1 ![]() Формирование пирамиды
Формирование пирамиды
2 L=![]()
3 R![]() length[A]
length[A]
4 while L>1
5 do L![]() L-1
L-1
6 Shift (A, L, R)
7 ![]() Сортировка
Сортировка
8 while R>1
9 do x![]() A[1]
A[1]
10 A[1] ![]() A[R]
A[R]
11 A[R] ![]() x
x
12 R![]() R-1
R-1
13 Shift (A, L, R)
Оценка эффективности:
Пирамидальная сортировка неэффективна для небольших n, но очень эффективна при больших n и становится сравнима с сортировкой Шелла. Даже в самом плохом случае сортировка имеет эффективность О(nlogn). Неясно, какой случай плохой. Сортировка очень любит последовательности, в которых элементы более менее отсортированы в обратном порядке.
