
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Оглавление
1. Классификация параллельных КС по структурно-функциональным признакам. 2
2. Классификация параллельных КС по функциональным возможностям КС с точки зрения пользователя. 5
3. Проведите сравнительный анализ классификаций компьютерных систем. 5
4. Мультикомпьютеры, кластеры и симметричные мультипроцессоры - общая характеристика, схемы построения, особенности каждой из систем, области применения. 5
5. Системы с распределенной и разделяемой памятью, массово-параллельные системы - общая характеристика, схема построения, особенности каждой из систем, области применения. 7
6. Структура, достоинства и недостатки UMA-, NUMA - и ccNUMA-систем.. 8
Масштабируемая архитектура. Что понимается под словами «масштабируемость кластера»? 10
Архитектуры S2MP и NUMA-flex как развитие архитектуры ccNUMA.. 11
7. Основные понятия теории моделирования параллельных КС. Методы моделирования параллельных КС. 11
8. Задачи моделирования параллельных КС. 12
9. Приведите основные принципы моделирования. 12
10. Моделирование параллельных процессов. Применение аппарата сетей Петри. Подклассы и расширение сетей Петри. 13
Применение сетей Петри для синтеза дискретных управляющих устройств. 14
12. Оценочные или Е-сети как расширение сетей Петри. 16
Моделирование конвейерной обработки информации. 17
13. Задачи сохранения и активности сети Петри. 19
Моделирование сетями Петри вычислительных процессов в КС, использующих кратные функциональные блоки. 21
14. Задачи достижимости и покрываемости сети Петри. 24
15. Задача безопасности и ограниченности сети Петри. 24
Моделирование сетями Петри задач синхронизации при взаимодействии процессов в КС.. 25
18. Анализ сетей Петри матричным методом.. 27
19. Матричный метод анализа сетей Петри достоинства и недостатки метода. 28
20. Подклассы сетей Петри. 28
21. Маркированные графы – подкласс сетей Петри. 28
22. P - и V- операции над семафорами, моделирование P/ V - систем сетью Петри. 29
Границы возможности моделирования с помощью сетей Петри. 29
23. Сети Петри и их особенности. 31
24. Покажите, используя матричный метод анализа сетей Петри, что маркировка (0, 7, 0, 1) недостижима из маркировки (1, 0, 1, 0) для сети Петри, изображенной на рисунке. 31
25. Дана последовательность запусков переходов s = t3 t2 t3 t2 t1 сети Петри, изображенной на рисунке. Определите вектор запуска и маркировку m’ сети Петри. 32
26. Определите является ли маркировка (1, 8, 0, 1) достижимой из маркировки (1, 0, 1, 0) для сети Петри, изображенной на рисунке. Найдите последовательность запусков переходов s. 32
Понятия множества и мультимножества и операции со множествами и мультимножествами. 32
27. Понятие о монотонной структуре. 33
28. Понятие о топологическом анализе структур КС. 34
29. Разбиения чисел. Основные понятия и определения. Принцип Дирихле. 35
30. Вложимость разбиений. 36
31. Ранговое условие вложимости; пример использования. 36
32. Принцип полного размещения; пример использования. 37
33. Вложимость с ограничениями; пример использования. 37
35. Особенностью распределения памяти в КС с сегментной организацией программ и данных (модель 2). Приведите пример. 39
36. Комбинаторная модель для оценки необходимого размера памяти КС (модель 4). Приведите пример. 40
37. Комбинаторная модель, позволяющая произвести расчет оценки сверху необходимого размера оперативной памяти КС. 40
Совместное исследование параллельных КС и алгоритмов. 40
38.Влияние топологии на технические характеристики сетей. 41
39. Классы характеристик КС. 42
Абсолютно однородная сеть (определение, примеры). 42
40. Проблемы адаптации структуры КС к алгоритмам решаемых задач в терминах теории графов. 43
Определите ![]() в узле КС и в КС (структура КС условно изображена на рис). 43
в узле КС и в КС (структура КС условно изображена на рис). 43
40. Проблемы адаптации структуры КС к алгоритмам решаемых задач в терминах теории графов. (Адаптация КС к алгоритму ← так в лекциях называется). 43
41. Надежность сети КС. 44
42.Отказоустойчивость (живучесть) топологической структуры КС. 44
43. Определение путей и разрезов на графе(пример). 45
44. Граничные оценки показателей связности. 46
45. Двухсторонние граничные оценки Эзари-Прошана для вероятности связанности двухполюсного графа 49
46-47. Структура магистрально-модульных КС, особенности построения структур магистральных КС и их отличие от других типов комп сетей. 50
48. Приведите определение реберного графа и постойте граф L(G) неориентированного графа ![]() 51
51
49. Приведите общее выражение для переключающей матрицы. 51
50. Дайте определение реберного графа и постойте граф L(G) , если граф G представляется как граф ![]() 51
51
51. Построить коммутатор по схеме сети косвенного двоичного n-куба (сеть Клоса). 52
52. Совместное исследование параллельных КС и алгоритмов. 53
53. Диаграммы Ферре и инверсии в бинарных последовательностях. 54
1. Классификация параллельных КС по структурно-функциональным признакам.
По-видимому, самой ранней и наиболее известной является классификация архитектур вычислительных систем, предложенная в 1966 году М. Флинном. Классификация базируется на понятии потока.
Классификация по Флинну:
- Вычислительная система с одним потоком команд и данных (однопроцессорная ЭВМ — SISD, Single Instruction stream over a Single Data stream). Вычислительная система с общим потоком команд (SIMD, Single Instruction, Multiple Data — одиночный поток команд и множественный поток данных). Вычислительная система со множественным потоком команд и одиночным потоком данных (MISD, Multiple Instruction Single Data — конвейерная ЭВМ). Вычислительная система со множественным потоком команд и данных (MIMD, Multiple Instruction Multiple Data)
К минусам можно отнести, что слишком много ВС попадает в класс MIMD.
Пытаясь систематизировать машины внутри класса MIMD Р. Хокли получил иерархическую структуру.
Основная идея: Множественный поток команд может быть обработан 2 способами:
Одним конвейерным устройством, работающем в режиме разделения времени. Каждый поток обрабатывается собственным устройством.Классификация по Р. Хокли:
 MIMD Конвейерные устройства С собственным устройством для каждого потока MIMD компьютеры в которых в которых возможна связь каждого вычислителя с каждым (с переключателями) MIMD компьютеры у которых возможна связь только с ближайшими. С общей памятью с распределенной памятью регулярные решетки гиперкубы иерархические структуры изменяющиеся конфигурации
MIMD Конвейерные устройства С собственным устройством для каждого потока MIMD компьютеры в которых в которых возможна связь каждого вычислителя с каждым (с переключателями) MIMD компьютеры у которых возможна связь только с ближайшими. С общей памятью с распределенной памятью регулярные решетки гиперкубы иерархические структуры изменяющиеся конфигурации Среди MIMD-компьютеров с переключателями выделяются те, в которых вся память распределена между процессорами.
Если память – разделяемый ресурс, доступный для всех процессоров через переключатели, то MIMD-машина является системой с общей памятью. В соответствии с конфигурацией переключателя различают:
- простой переключатель многокаскадный переключатель общая шина
Многие современные компьютерные системы имеют как общую разделяемую память, так и распределенную, такие системы Хокли рассматривал как гибридные MIMD-системы с переключателями.
Если рассматривать MIMD-системы с сетевой структурой (8, 9, 10, 11), то все они имеют распределенную память, а дальнейшая классификация может проводиться в соответствии с топологией сети.
Классификация Шнайдера
В 1988 году Л. Шнайдер (L. Snyder) предложил новый подход к описанию архитектур параллельных вычислительных систем, попадающих в класс SIMD систематики Флинна. Основная идея заключается в выделении этапов выборки и непосредственно исполнения в потоках команд и данных. Именно разделение потоков на адреса и их содержимое позволяет описать такие ранее "неудобные" для классификации архитектуры, как компьютеры с длинным командным словом, систолические массивы и целый ряд других.
Классификация Скилликорна
Классификация Скилликорна (1989) была очередным расширением классификации Флинна. Архитектура любого компьютера в классификации Скилликорна рассматривается в виде комбинации четырёх абстрактных компонентов:
- процессоров команд (Instruction Processor — интерпретатор команд, может отсутствовать в системе), процессоров данных (Data Processor — преобразователь данных), иерархии памяти (Instruction Memory, Data Memory — память программ и данных), переключателей (связывающих процессоры и память).
Переключатели бывают четырёх типов — «1-1» (связывают пару устройств), «n-n» (связывает каждое устройство из одного множества устройств с соответствующим ему устройством из другого множества, то есть фиксирует попарную связь), «n x n» (связь любого устройства одного множества с любым устройством другого множества). Классификация Скилликорна основывается на следующих восьми характеристиках:
- Количество процессоров команд IP Число ЗУ команд IM Тип переключателя между IP и IM Количество процессоров данных DP Число ЗУ данных DM Тип переключателя между DP и DM Тип переключателя между IP и DP Тип переключателя между DP и DP
Классификация Фенга
В 1972 году Фенг предложил классифицировать вычислительные систем на основе двух простых характеристик. Первая — число n бит в машинном слове, обрабатываемых параллельно при выполнении машинных инструкций. Практически во всех современных компьютерах это число совпадает с длиной машинного слова. Вторая характеристика равна числу слов m, обрабатываемых одновременно данной ВС. Немного изменив терминологию, функционирование ВС можно представить как параллельную обработку m битовых слоёв, на каждом из которых независимо преобразуются n бит. Каждую вычислительную систему можно описать парой чисел (n, m). Произведение P = n x m определяет интегральную характеристику потенциала параллельности архитектуры, которую Фенг назвал максимальной степенью параллелизма ВС.
Таким образом все КС MIMD можно разделить на 4 класса:
- Разрядно-последовательные, пословно-последовательные n=m=1, т. е. в каждый момент времени такая система обрабатывает только 1 двоичный разряд. Разрядно-параллельные последовательно-последовательные n>1, m=1. Разрядно-последовательные, пословно-параллельные n=1, m>1 (обычно КС этого класса состоят из большого числа одноразрядных процессоров, причем каждый процессор может независимо от остальных обрабатывать свои данные). Разрядно-параллельные, пословно параллельные n>1, m>1.
Плюс: введен единый числовой метрик для различных типов КС, с помощью которого можно сравнивать разные КС.
Минус: опираясь на данную классификацию сложно представить себе специфику той или иной КС (Не учитываются конструкторские особенности)
Классификация Хендлера
В основу классификации В. Хендлер закладывает явное описание возможностей параллельной и конвейерной обработки информации вычислительной системой. При этом он намеренно не рассматривает различные способы связи между процессорами и блоками памяти и считает, что коммуникационная сеть может быть нужным образом сконфигурирована и будет способна выдержать предполагаемую нагрузку.
Предложенная классификация базируется на различии между тремя уровнями обработки данных в процессе выполнения программ:
- уровень выполнения программы - опираясь на счетчик команд и некоторые другие регистры, устройство управления (УУ) производит выборку и дешифрацию команд программы; уровень выполнения команд - арифметико-логическое устройство компьютера (АЛУ) исполняет команду, выданную ему устройством управления; уровень битовой обработки - все элементарные логические схемы процессора (ЭЛС) разбиваются на группы, необходимые для выполнения операций над одним двоичным разрядом.
Таким образом, подобная схема выделения уровней предполагает, что вычислительная система включает какое-то число процессоров каждый со своим устройством управления. Каждое устройство управления связано с несколькими арифметико-логическими устройствами, исполняющими одну и ту же операцию в каждый конкретный момент времени. Наконец, каждое АЛУ объединяет несколько элементарных логических схем, ассоциированных с обработкой одного двоичного разряда (число ЭЛС есть ничто иное, как длина машинного слова).
Если на какое-то время не рассматривать возможность конвейеризации, то число устройств управления k, число арифметико-логических устройств d в каждом устройстве управления и число элементарных логических схем w в каждом АЛУ составят тройку для описания данной вычислительной системы C: t(C)= (k, d, w)
2. Классификация параллельных КС по функциональным возможностям КС с точки зрения пользователя.
Здесь про мультикомпьютеры и прочую Лабуду (см ниже)
3. Проведите сравнительный анализ классификаций компьютерных систем.
Имеется множество различных классификаций параллельных КС.
В качестве основных признаков классификаций, характеризующих структуру и функционирование ВС с точки зрения параллельности работы системы, чаще всего используют следующие характеристики:
- тип потока команд тип потока данных способ обработки данных тип коммуникационной среды степень однородности компонент системы степень согласованности режима работы устройств
По способу обработки данных ВС делятся на системы с пословной и поразрядной обработкой. В системах с пословной обработкой все разряды каждого слова обрабатываются процессором последовательно (слово за словом). В системах с поразрядной обработкой одноименные разряды большого числа слов обрабатываются одним процессором, но параллельно (Ассоциативные системы).
Примерами возможных классификаций являются классификации по Флину, Хокли, Шнайдеру, Скилликорну, Фенгу, Хендлеру и множество других. Нельзя выделить какую-то одну систему классификаций потому, что они подразделяют ВС, основываясь на разных принципах.
4. Мультикомпьютеры, кластеры и симметричные мультипроцессоры - общая характеристика, схемы построения, особенности каждой из систем, области применения.
Мультикомпьютеры.
Мультикомпьютеры – совокупность объединенных сетью отдельных вычислительных модулей, каждый из которых управляется своей ОС (например, серии SP1I6M). Узлы мультикомпьютеров обычно не имеют общих структур и связаны лишь сетью. Узлы обладают высокой степенью автономности и могут состоять из отдельных компонентов, в том числе и кластеров, SMP-, SPM-, DSM-, MPP–систем.
Для распределенной ОС мультикомпьютер выглядит как виртуальный однопроцессорный ресурс. Взаимодействие процессоров реализуется с помощью явно заданных операций связи между вычислителями. Обычно в мультикомпьютере реализуется согласованный сетевой протокол, и не существует единой очереди выполняющихся процессов, хотя известны и другие примеры.
Кластеры.
Кластер – набор компонентов, рассматриваемый операционной системой, системным ПО, приложениями и пользователями как единая система.
Кластеры получили широкое распространение из-за высокого уровня производительности при относительно низких затратах. Высокая производительность объясняется отсутствием совместно используемой оперативной памяти и наличием в каждом узле копии общей ОС или собственной ОС для неоднородных кластеров. Специализированное ПО производит контроль правильности работы узлов кластера. При отказе узла кластера его ресурсы (дисковое пространство, задание и т. д.) переназначаются другим узлам.
По сути, кластер образуется из отдельных полноценных узлов, включающих процессоры, память, подсистему ввода-вывода, ОС и т. д. При объединении компьютеров в кластер чаще всего поддерживается прямая связь между узлами посредством коммуникационной сети. Технология такой сети может варьироваться от простейшей (Ethernet) до сложных специализированных вариантов, обеспечивающих высокую скорость обмена. Возможно параллельное использование нескольких независимых сетей в рамках одного кластера.
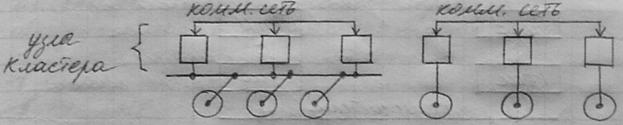
На рисунке изображены 2 типичные структуры кластеров: архитектура с разделяемыми дисками (слева) и архитектура без разделения дисков.
В архитектуре с разделением дисков все узлы кластера имеют доступ ко всем дискам. В архитектуре без разделения дисков, несмотря на то, что поддерживается целостный образ ресурса, каждый узел имеет собственную оперативную память и диски; в таких системах общей является только коммуникационная сеть.
С точки зрения повышения производительности кластер является хорошо масштабируемой ВС. Однако отсутствие общей разделяемой памяти (а иногда и единого адресного пространства) обуславливает большие накладные расходы, связанные с обменом сообщениями между узлами.
Наибольший эффект кластеры дают при вычислениях в рамках хорошо структурированных научных приложениях. С точки зрения удобства масштабирования кластерные архитектуры допускают практически неограниченное наращивание числа узлов. Для управления кластером используются специальные инструменты для поддержания единого образа ресурса, в частности, система пакетной обработки.
Симметричные мультипроцессоры.
Симметричный мультипроцессор (относится к классу SMP-систем) состоит из нескольких десятков процессоров, причем все процессоры разделяют общую память и объединены коммуникационной системой.
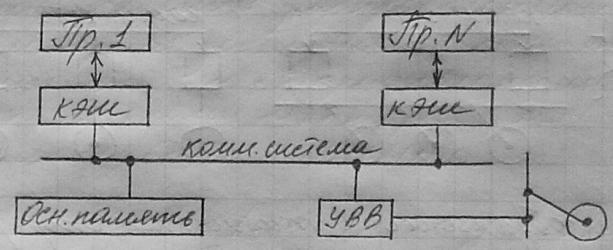
Существуют варианты SMP-архитектур с одной или несколькими системными шинами (например, Cray 6400 имел 4 системные шины). Также существуют SMP-архитектуры со специальными коммутаторами для связи процессоров, памяти и подсистемы ввода-вывода. Пропускная способность коммуникационной системы достаточна для поддержания быстрого доступа к памяти. У отдельных процессоров имеются свои уровни кеш-памяти. Достаточный объем кеша и сравнительно небольшое количество процессоров позволяет удовлетворять обращения к основной памяти. Это легло в основу названия таких архитектур - UMA-архитектуры.
UMA (Uniform Memory Access, однородный доступ к памяти).
В UMA-архитектурах имеется единственная ОС, а ПО работает с единым адресным пространством. При этом возникает сложная проблема сохранения когерентности данных (согласованного извлечения содержимого кешей и основной памяти). Если модифицируется одна из копий данных, остальные копии должны либо также модифицироваться, било объявляться недостоверными. Отсюда – 2 альтернативных подхода к поддержанию когерентности разделяемых данных:
1) запись с обновлением данных
2) запись с аннулированием данных
В SMP-системах обычно реализуется шинный протокол наблюдения. Происходит прослушивание шины всеми процессорами с целью обнаружения операций записи в те ячейки памяти, копии содержимого которых содержатся в кеше данного процессора. Производительность систем с общей памятью, в т. ч. SMP, зависит от принятой модели согласованности памяти, определяющей, в каком порядке процессоры наблюдают последовательность операций записи-чтения.
Передача данных между кешами различных процессоров в SMP-системах выполняется значительно быстрее, чем обмен данными между узлами кластера или мультикомпьютера. Поэтому SMP-система хорошо масштабируется с ростом производительности при обработке большого числа коротких транзакций (например, банковские операции).
Сохранение когерентности требует специальных аппаратных средств быстрой модификации копий данных. Однако, если следовать строгой модели согласованности, когда каждая операция записи возвращает последнее записанное значение, то происходит неизбежное падение производительности. Главная сложность построения SMP-систем - сильная связанность процессоров и наличие единой ОС, разделяемой всеми процессорами.
5. Системы с распределенной и разделяемой памятью, массово-параллельные системы - общая характеристика, схема построения, особенности каждой из систем, области применения.
DSM-системы (Distributed Shared Memory) – системы с распределенной и разделяемой памятью; память таких узлов разделена физически, но адресуется в рамках единого адресного пространства. DSM-системы могут быть реализованы различными способами. Общим для разных реализаций является тот факт, что узел может состоять из нескольких процессоров и иметь SMP-архитектуру. Также в DSM-системах поддерживается общее адресное пространство, но при этом память является распределенной по узлам и время доступа к памяти зависит от месторасположения данных, поэтому некоторые DSM-системы получили название NUMA.
NUMA – Non-Uniform memory Acess (Architecture) – Неоднородный доступ (архитектура) к памяти.
Частный случай NUMA–архитектуры - cc-NUMA.
cc-NUMA – Cache Coherent NUMA, архитектура NUMA с кеш-когерентным доступом.
Архитектура cc-NUMA:
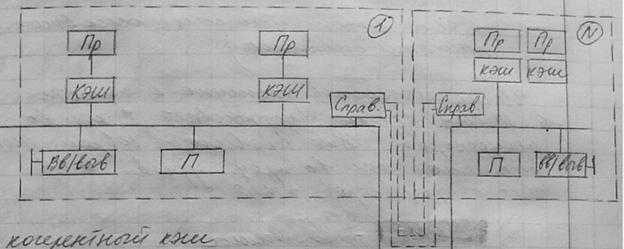
Механизм работы кеша каждого узла увязан с доступом к локальной памяти каждого удаленного узла.
Существует справочная память, в которой содержится информация о том, в каких именно кешах находится нужный блок данных; например, узел 1 обращается к ячейке памяти с адресом А основной памяти, не являющейся локальным адресом узла 1. Тогда справочник узла 1 анализирует информацию (адрес А) и определяет, что данные по адресу А находятся в узле N. В этом случае этот справочник отправляет адрес А в справочник узла N. Узел N выбирает информацию оп адресу А.
В отличие от шинного протокола наблюдения, где при записи нового значения в кеш сообщение о модификации передается во все узлы, справочник распознает адрес и обращается только к тому узлу, где содержится данный адрес.
Преимущество архитектуры: простота.
Недостаток архитектуры: объем аппаратной реализации (пропорционален основной памяти системы).
Иерархичность доступа к памяти в NUMA-архитектурах сдерживает рост количества процессоров. Как правило, в современных NUMA-системах количество процессорных узлов не превышает 64, а число процессоров – 128.
Массово-параллельные системы (МПС).
Отличительной особенностью массово-параллельных систем является большое число процессорных узлов. Узлы обычно состоят из 1 или нескольких процессоров, локальной памяти и нескольких устройство ввода-вывода.
В массово-параллельных системах реализуется архитектура без разделения ресурсов. В каждом узле работает своя копия ОС, а узлы объединяются коммуникационной системой.
Если узел управляется своей собственной ОС и имеет уникальное адресное пространство памяти, то не потребуется никаких аппаратных средств для обеспечения когерентности (согласованности).
Когерентность в случае МПС обеспечивается программными средствами на основе техники обмена сообщениями. Также МПС можно отнести к мультикомпьютерам.
В МПС с разделяемой распределенной памятью возможна как аппаратная, так и программная поддержка (???). Такую разновидность МПС можно отнести к классу NUMA.
6. Структура, достоинства и недостатки UMA-, NUMA- и ccNUMA-систем
UMA (заход на UMA через SMP)
Симметричный мультипроцессор (SMP-система) состоит из нескольких десятков процессоров, причем все процессоры разделяют общую память и объединены коммуникационной системой.
Существуют варианты SMP-архитектур с одной или несколькими системными шинами (например, Cray 6400 имел 4 системные шины). Также существуют SMP-архитектуры со специальными коммутаторами для связи процессоров, памяти и подсистемы ввода-вывода. Пропускная способность коммуникационной системы достаточна для поддержания быстрого доступа к памяти. У отдельных процессоров имеются свои уровни кеш-памяти. Достаточный объем кеша и сравнительно небольшое количество процессоров позволяет удовлетворять обращения к основной памяти. Это легло в основу названия таких архитектура: UMA-архитектуры.
UMA (Uniform Memory Access, однородный доступ к памяти).
В UMA-архитектурах имеется единственная ОС, а ПО работает с единым адресным пространством. При этом возникает сложная проблема сохранения когерентности данных (согласованного извлечения содержимого кешей и основной памяти). Если модифицируется одна из копий данных, остальные копии должны либо также модифицироваться, било объявляться недостоверными. Отсюда – 2 альтернативных подхода к поддержанию когерентности разделяемых данных:
1) запись с обновлением данных
2) запись с аннулированием данных
В SMP-системах обычно реализуется шинный протокол наблюдения. Происходит прослушивание шины всеми процессорами с целью обнаружения операций записи в те ячейки памяти, копии содержимого которых содержатся в кеше данного процессора. Производительность систем с общей памятью, в т. ч. SMP, зависит от принятой модели согласованности памяти, определяющей, в каком порядке процессоры наблюдают последовательность операций записи-чтения.
Передача данных между кешами различных процессоров в SMP-системах выполняется значительно быстрее, чем обмен данными между узлами кластера или мультикомпьютера. Поэтому SMP-система хорошо масштабируется с ростом производительности при обработке большого числа коротких транзакций (например, банковские операции).
Сохранение когерентности требует специальных аппаратных средств быстрой модификации копий данных. Однако, если следовать строгой модели согласованности, когда каждая операция записи возвращает последнее записанное значение, то происходит неизбежное падение производительности. Главная сложность построения SMP-систем - сильная связанность процессоров и наличие единой ОС, разделяемой всеми процессорами.
NUMA (заход через DSM-системы)
DSM-системы (Distributed Shared Memory) – системы с распределенной и разделяемой памятью; память таких узлов разделена физически, но адресуется в рамках единого адресного пространства. DSM-системы могут быть реализованы различными способами. Общим для разных реализаций является тот факт, что узел может состоять из нескольких процессоров и иметь SMP-архитектуру. Также в DSM-системах поддерживается общее адресное пространство, но при этом память является распределенной по узлам и время доступа к памяти зависит от месторасположения данных, поэтому некоторые DSM-системы получили название NUMA.
NUMA – Non-Uniform memory Acess (Architecture) – Неоднородный доступ (архитектура) к памяти.
cc-NUMA
Частным случаем NUMA–архитектуры является cc-NUMA
cc-NUMA – Cache Coherent NUMA, архитектура NUMA с кеш-когерентным доступом.
Архитектура cc-NUMA:
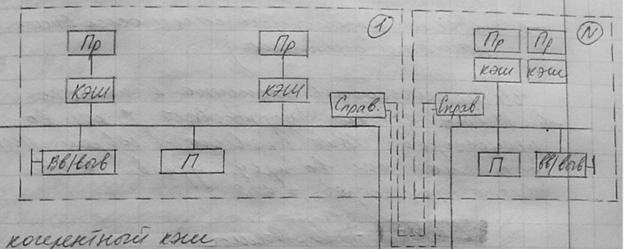
Механизм работы кеша каждого узла увязан с доступом к локальной памяти каждого удаленного узла.
Существует справочная память, в которой содержится информация о том, в каких именно кешах находится нужный блок данных; например, узел 1 обращается к ячейке памяти с адресом А основной памяти, не являющейся локальным адресом узла 1. Тогда справочник узла 1 анализирует информацию (адрес А) и определяет, что данные по адресу А находятся в узле N. В этом случае этот справочник отправляет адрес А в справочник узла N. Узел N выбирает информацию оп адресу А.
В отличие от шинного протокола наблюдения, где при записи нового значения в кеш сообщение о модификации передается во все узлы, справочник распознает адрес и обращается только к тому узлу, где содержится данный адрес.
Преимущество архитектуры: простота.
Недостаток архитектуры: объем аппаратной реализации (пропорционален основной памяти системы).
Иерархичность доступа к памяти в NUMA-архитектурах сдерживает рост количества процессоров. Как правило, в современных NUMA-системах количество процессорных узлов не превышает 64, а число процессоров – 128.
Масштабируемая архитектура. Что понимается под словами «масштабируемость кластера»?
Масштабируемая архитектура вычислительной сети – архитектура, позволяющая наращивать количество вычислителей без коренной перестройки топологии или замены имеющегося оборудования. При этом производительность сети должна расти с увеличением количества вычислителей.
Все существующие многопроцессорные архитектуры являются в некотором смысле масштабируемыми. При этом чем выше степень связности модулей многопроцессорной ВС, тем сложнее выполняется масштабирование, но тем быстрее осуществляется обмен данными между узлами.
Широчайшее распространение кластерных многопроцессорных систем в первую очередь объясняется слабой связностью его вычислительных узлов и унифицированной технологией коммутационной сети, эту связь обеспечивающей (Ethernet и т. д.). Кластер является наиболее масштабируемой многопроцессорной системой на сегодняшний день (если не считать вычислений, распределенных по территориальной или глобальной сети), обеспечивая при этом высочайшую производительность для задач, допускающих крупноблочное распараллеливание (научные вычислительные задачу, задачи трехмерной визуализации и др.). При этом кластер показывает сравнительно слабую производительность при мелкоблочном распараллеливании задач.
Архитектуры S2MP и NUMA-flex как развитие архитектуры ccNUMA
S2MP - системы.
Дальнейшее развитие архитектуры cc-NUMA, преодолевающее ограничение на масштабируемость, получило название S2MP.

Одним из узких мест, сдерживающих число процессорных узлов, является пропускная способность шин оперативной памяти.
В архитектуре S2MP процессорные узлы объединены сетью, образуемой средой межсоединений и маршрутизаторами.
Для поддержания когерентности кешей в S2MP-архитектуре используется протокол справочника (как в cc-NUMA).
Использование в этих системах программируемых маршрутизаторов позволяет реализовывать системы с различной топологией (и, естественно, различным числом процессорных узлов).
В S2MP Origin 2000, например, топологией является гиперкуб с числом процессорных элементов, равным 512.
Архитектура NUMA-flex.
Архитектура NUMA-flex во многом является наследницей S2MP.
Более высокая степень готовности обеспечивается технологией так называемого разделения, которая позаимствована у кластеров.
Каждый узел архитектуры NUMA-flex представляет собой независимый сервер и для связи с другими узлами использует инфраструктуру архитектуры S2MP.
В каждом узле может работать своя версия ОС (например, в Origin 2000 это Irix).
Специальные аппаратные средства осуществляют контроль и изолирование ошибок, возникающих в одном из узлов, и не дают ошибке распространиться на другие узлы.
7. Основные понятия теории моделирования параллельных КС. Методы моделирования параллельных КС.
Моделирование – замена исходного объекта образом или другим объектом ( моделью ) и изучение свойств оригинала путем исследования свойств модели.
Условия для существования пользы от моделирования:
Модель обеспечивает оригинальное отображение свойств оригинала, существенных с точки зрения исследуемых операций. Модель позволяет устранить проблемы присущие проведению испытаний на реальных объектахВ зависимости от способа модели делятся:
1. Физические – реальное воплощение( макет )
2. Математические – формализованное описание на некотором язык.
8. Задачи моделирования параллельных КС.
Определение цели моделирования. Разработка концептуальной модели. Формализация модели. Программная реализация Планирование проведения эксперимента Реализация плана эксперимента Анализ результатов моделирования9. Приведите основные принципы моделирования.
Принципы моделирования:
Принцип информационной достаточности. ( при полном недостатке информации о модели ее моделирование не имеет смысла, есть некоторые пороговый уровень информации, при котором моделирование возможно ). Принцип осуществимости( модель должна обеспечивать адекватные результаты ) Принцип множественности модели. ( Создаваемая модель должна отражать те свойства реальных объектов, которые влияют на выбранный показатель эффективности, каждая модель отражает лишь некоторые, выбранные стороны реального объекта, для составления полной картины необходимо использовать несколько моделей ) Принцип агрегирования. ( сложную систему можно представить как совокупность простых ) Принцип параметризации. ( В ряде случаев моделируемая система имеет подсистемы, характеризуемые определенным параметром )10. Моделирование параллельных процессов. Применение аппарата сетей Петри. Подклассы и расширение сетей Петри.
Почти любая КС имеет в своём составе параллельно работающие элементы, такие элементы могут взаимодействовать, либо работать независимо. Способы взаимодействия подсистем определяет вид параллельных процессов в системе. Вид процесса влияет на способ моделирования.
Реализация параллельных процессов в КС
Процессы могут быть истинно параллельны только в многопроцессорных ВС Многие процессы используют одни и те же ресурсы В КС существует 2 вида процессов – родительский и дочерний. 3 подхода:- На основе взаимного исключения (монопольный захват ресурса одним процессом ) На основе синхронизации по сигналам (обмен сигналами между процессами обозначающими события ) На основе синхронизации по сообщениям (обмен информацией между процессами )
Средство моделирования изначально ориетировано на параллельную работу процессов.
Сети Петри – инструмент исследования систем, теория сетей Петри делает возможным моделирование системы – представление её виде сетей Петри. Применяемость сетей Петри исключительно для моделирования.
Модель представляется в математических терминах того, что считают корректным описанием системы. Как правило модель имеет математическую основу. Возможно несколько путей практического применения сетей Петри при проектировании и анализе. В одном из подходов сети Петри – вспомогательный инструмент для анализа. В результате анализа модели проявляются изъяны и ошибки. Можно предложить более радикальный подход, в котором весь процесс проектирования и определения характеристик проводится с помощью сетей Петри.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
