
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
А. В. КОРШАКОВ
Российский научный центр «Курчатовский институт», Москва
*****@***ru.
ПРОЦЕДУРА ПОСТРОЕНИЯ ПРОСТРАНСТВА ПОНЯТИЙ
КАК ЧАСТЬ СИСТЕМЫ МАШИННОГО ПЕРЕВОДА
Аннотация
В работе описывается попытка создания алгоритма, который, в будущем, при использовании его как составной части системы машинного перевода, позволит математически точно дистанцировать различные вариации смысла синонимичных понятий в рамках контекста лингвистического высказывания. При переводе с одного человеческого языка на другой подобная процедура избавит «редактора» текста от необходимости выбирать нужное слово из набора, предоставляемого простым «дословным» машинным переводчиком.
Введение. В современном мире, с его постоянно растущими телекоммуникационными системами потребности человека в общении постоянно возрастают. Интернет-, информационные, и компьютерные технологии, стремительно входя в жизнь человека, обнаружили ряд проблем, связанных с интерпретацией компьютером человеческих команд и концепцией «человеко-машинного интерфейса».
В подобных условиях кажется важным создание системы машинного перевода, способной переводить крупные потоки данных с одного языка на другой, безотносительно к «внутренней структуре» этих языков, с «минимальным искажением» смысла поступающих данных.
При решении прикладных задач подобного рода, необходимо, чтобы конкретное программное обеспечение было способно математически точно дистанцировать смысл понятий переводов, поступающих на вход слов в рамках фигурирующего контекста.
Эта работа представляет собой попытку опробовать версию алгоритма, способного решать подобные задачи внутри смыслового корпуса человеческих языков. В совокупности с алгоритмами и способами обработки языковой информации, рассмотренными в статьях [1-4], в будущем, возможно, удастся получить полноценную машину смысловой интерпретации.
Исходные данные. Для решения поставленной задачи, в первом приближении, в качестве исходных данных исследуются смысловые понятия человеческих языков, а именно, глаголы, т. е. костяк речи, относящийся к выражению мысли об образе действий с различными объектами.
В работе рассматриваются переводы глаголов английского языка на языки индоевропейской группы. Среди этих языков русский, болгарский, немецкий, латышский, французский, греческий, и ряд других. Переводы сведены в таблицу – прямоугольную матрицу, номера столбцов которой, соответствуют английским глаголам, а номера строк – глаголам в соответствующих языках, расположенных подряд, и, первоначально не упорядоченных как-либо. Ячейки таблицы заполнены нулями и единицами. Нуль обозначает, что данный иностранный глагол не является переводом английского глагола, стоящего в этом столбце, а единица указывает на наличие такого перевода. Стоит оговориться, что не существует иного способа получения подобных данных, чем «вручную», хотя очень помогает наличие электронных многоязычных словарей.
Для дальнейшего изложения, необходимо определить несколько понятий. Во-первых, это «объём слова» V. Объем - сумма всех элементов одного столбца матрицы исходных данных. Эта величина показывает насколько часто данное слово, в нашем случае – английский глагол, имеет переводы на другие языки. Естественно наибольший объём имеют слова, относящиеся к наиболее простым и «обиходным» действиям.
Второй величиной является «расстояние между глаголами». Эта величина равна сумме всех единиц, совпадающих в столбцах двух глаголов. Мы полагаем, что такая величина отражает расстояние между «смыслами» переводов. Перерабатывая, таким образом, матрицу исходных данных, можно составить «матрицу расстояний». Эта матрица квадратная и содержит в своих элементах расстояния между смыслами глаголов английского языка, соответствующих i-му номеру строки и j-му номеру столбца, охватывая их роль в передаче информации внутри конкретного языка. Расстояние указывает, насколько вероятно при допущении ошибки – неспособность субъекта в данный момент воспроизвести нужное слово в нужном месте, заменить его «родственным». Соответственно, чем «дальше» рассматриваемое слово от исходного, тем эта вероятность ниже.
Слова, не имеющие общих переводов, считались бесконечно удалёнными, и, в соответствующих ячейках матрицы расстояний, помещалось значение, принятое за бесконечность.
Вообще говоря, для лучшего представления пространственных отношений между смысловыми понятиями в некоем абстрактном «смысловом» пространстве, удобно представлять каждое понятие как некое объёмное тело, в общем случае произвольной формы. Тогда всё смысловое пространство можно представить заполненным этими телами, образующими кластеры. Отдельные тела могут смыкаться или даже взаимно проникать. Можно представить и некоторые незаполненные части пространства понятий.
В первом приближении мы полагали примерно сферическую форму тел-понятий, тогда можно ввести в рассмотрение понятие расстояния между ними.
Для этого были предприняты следующие действия.
Во-первых, матрица расстояний была отнормирована на значения объемов слов, между которыми, собственно, и вычисляется расстояние.
Во-вторых, для перевода данных в «континуальное пространство» к каждому элементу матрицы была применена операция логарифмирования. Таким образом, матрица расстояний между понятиями далее «матрица расстояний» приняла вид:
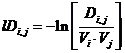 , (1)
, (1)
где lDi,j – матрица расстояний, Di,j – исходная матрица расстояний, Vi – объём i-го слова, Vj – объём j-го слова. Эта матрица очень важна и играет ключевую роль в дальнейших расчётах. Она содержит данные о расстояниях между смыслами глаголов. На её основании можно размещать глаголы-понятия в смысловом пространстве, присваивая каждому объекту некие координаты.
Постановка и методы решения задачи. После всего сказанного, мы имеем набор, вообще говоря, N-мерных объёмных тел, расположенных в N-мерном пространстве, о которых известно только расстояния между их «геометрическими» центрами. Необходимо найти координаты центров этих тел.
Для решения зададимся соответствующей системой координат. В данной работе была выбрана декартова 4-мерная система координат, причём предполагалось, что 4-я координата будет принимать значения малые, по сравнению с первыми 3-мя (а в отдельных «стабильных» случаях вообще принимать только 0-е значения), неся, таким образом, информацию о флуктуациях системы. Практика оправдала такой выбор.
Далее, в декартовых координатах расстояние между 2 точками, применительно к логарифмической матрице расстояний равно:
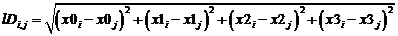 . (2)
. (2)
Это система нелинейных уравнений, которая после рассмотрения более чем 4 точек становится переопределённой. Её решением и будут искомые координаты.
Система решалась методом простой итерации в классическом виде:
![]() . (3)
. (3)
Форма F(x) немедленно следует из (2)) с некоторыми модификациями. А именно: для ускорения сходимости к решению использовалась модификация Зейделя – использование в k+1 итерации для m-й координаты k+1-го приближения m-1-й, посчитанного при решении предыдущего уравнения системы.
Для поиска решения переопределённой системы использовались дополнительные соображения, связанные со способом выбора уравнений для решения в каждом конкретном шаге процесса, связанным с добавлением в рассмотрение нового слова (не путать с самим итерационным процессом метода простой итерации). В системе всегда присутствовало уравнение, отвечающее расстоянию от, слова, называемого «главным». Это слово выбирается экспериментатором, исходя из предположения, что именно оно образует наиболее устойчивый кластер (упаковку объектов-понятий, несущих похожую смысловую нагрузку, в плотную группу, со значениями координат, дающими минимальные погрешности). Набор конкретных главных слов определялся в ходе эксперимента.
Некоторые уравнения, определяющие слова, бесконечно удалённые от центра данного смыслового кластера (центра тела главного слова) давали в ходе расчётов либо «отрицательные подкоренные выражения», либо бесконечное значение одной из их координат. Таким образом, слова, не связанные с данным «кластеризующим» центром выталкивались из кластера и/или выстреливались на бесконечность самой системой, отвергаясь из рассмотрения. Однако отвергались не абсолютно, и при добавлении в кластер нового слова, из еще не обсчитанного списка, предъявлялись системе вновь, в надежде, что только что добавленное слово стабилизирует решение. И иногда действительно встречались слова, которые могли присутствовать в кластере только в случае присутствия своего «соседа» - например слова Drag и Haul. Слова, высылаемые системой на бесконечность, всегда оказывались чуждыми по смыслу данной выборке или кластеру, – например, из выборки Destroy на бесконечность всегда уходило слово Connect. В условиях подтверждения экспериментами подобная трактовка фактов нестабильности решения кажется верной.
После выбора уравнений, критичных для решения, запускался итерационный процесс, который продолжался при постоянном контроле сходимости к стабильному решению.
О сходимости процесса стоит сказать следующее. Согласно теории метода простой итерации процесс сходится со скоростью геометрической прогрессии при выполнении условия:
![]() , при
, при ![]() , (4)
, (4)
поскольку в выборе начального приближения, рационально рассуждая, мы ограничены величинами матрицы расстояний, метод сходиться, так как для данных чисел неравенство (4) выполнялось всегда. На практике, как правило, удавалось достичь стабильного решения на 15-20 итерации (максимум), после которых решение считалось найденным.
Простейшие понятийные агрегации в смысловом пространстве. Продемонстрируем описываемые образования на двух примерах. Это кластеры из семейства Destroy и Drag. В первый входят следующие глаголы: Break Destroy, Wreck, Shatter, Crush, Smash, во второй: Drag, Pull, Draw, Trail, Tug, Haul. На рис. 1 и 2 показаны семейства кривых погрешностей при выборах того или иного слова в качестве главного или кластерообразующего для выборок Destroy и Drag соответственно. На рис. 3 и 4 показаны структура кластеров Destroy и Drag (4-я флюктуирующая координата для этих случаев всегда равна 0 – кластеры стабильны).
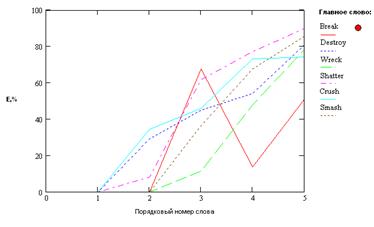
Рис. 1
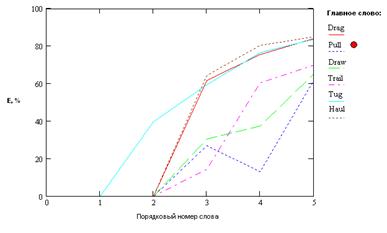
Рис. 2
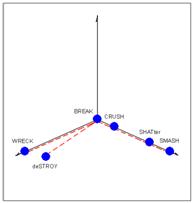
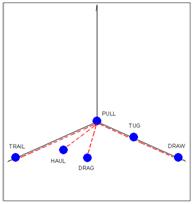
Рис. 3 Рис. 4
Выводы. Любопытным феноменом является то, что большинство наиболее стабильных кластеров (но не все и тех, что удалось исследовать) умещаются всего лишь в два измерения (рис. 4, 5), то есть точки-слова такого образования принадлежат одной плоскости. Вначале же предполагалось, что слова будут распределяться, по крайней мере, в 4-мерном пространстве. При этом применяемая нами сейчас математика при расчете расстояний точно работает лишь «локально» – в пределах размеров стабильных кластеров, форма которых носит плоскостной или квази-плоскостной характер. При попытке выйти за границы стабильного образования, и охватить взором более-менее протяжённые области смыслового пространства, наблюдается потеря точности. Подобное явление, как мы полагаем, связано со сложностью и существенной нелинейностью связей между понятиями при рассмотрении «глобальной» перспективы. Не следует думать, что трудности при решении задачи установления «глобального порядка» кластеров непреодолимы. Когда форма большинства важных кластеров будет установлена достаточно точно, составить из них упорядоченную структуру, вероятно, будет вполне возможно.
При изучении вопросов сходимости было замечено явление «осцилляций», состоящее в том, что для определённых слов, при добавлении их в систему, на стадии расчёта координат, их координаты принимают поочерёдно 2 набора значений, не стабилизируясь и демонстрируя устойчивый цикл. Геометрически это явление может быть объяснено добавлением новой точки к симметричной фигуре и построении на их основе новой симметричной фигуры. (Если в 3-мерном пространстве поставить точку на некотором расстоянии от равностороннего треугольника так, что из этой точки на центр тяжести треугольника падает перпендикуляр, то неважно, с какой стороны от плоскости треугольника ставить точку, результат будет один – пирамида.) С другой стороны, это явление может говорить о том, что данное слово неустойчиво в данном кластере, и «стабилизировать» его положение или, напротив, вытолкнуть из кластера может следующее добавленное слово, которое изначально является более близким к центру, чем осциллирующее. Если удастся определить и собрать полную выборку для какого-либо понятия то координаты слов, её составляющих, примут свои окончательные значения в локальном смысле, и добавление новых слов станет невозможным (они просто будут исторгаться из кластера). После этого возникнет задача построения «мозаики» из хорошо сформировавшихся кластеров.
Скорее всего, более подходящей машиной для реализации вышеописанной процедуры, обладающей более гибкими свойствами и большей мощностью ассоциации, как способностью «стягивать» похожие тела-понятия в кластеры, будет некий нейросетевой алгоритм. Уже сейчас видно, что подобная машина должна иметь следующую структуру. В связке должны работать две сети: сеть ассоциативной памяти, реализующая функцию извлечения из памяти понятий по принципу общей близости к заданному («ключевому») слову, (фактически эта сеть должна помнить матрицу расстояний), и сеть, фактически, решающая «задачу коммивояжера» - сеть, собственно упаковывающая тела-понятия в кластер, и вычисляющая их координаты и форму, из условия минимизации ошибок относительно матрицы расстояний. После того, как «динамический» кластер сформирован в ответ на заданное понятие (т. е. «ключевое» слово или слово, которое нужно перевести в данный момент) для дальнейшей интерпретации в контексте, например, «следующего» слова высказывания, нужно использовать координаты этих двух кластеров и понятий, их составляющих, для определения наиболее подходящего перевода. (С учётом пространственной ориентации вектора, проведённого из точки кластера «следующего» слова в точку кластера «ключевого» слова относительно формы и расположения кластеров). Идеальным кандидатом на роль сетей, способных выполнить данные задачи являются нейронные сети Хопфилда, возможно с некоторыми модификациями.
Существенной проблемой, однако, остаётся выбор ключевого слова для «динамического» кластера. А также выбор слова, относительно которого следует начинать переводить всё высказывание. Но решению этих проблем может помочь статистический анализ, и нейросетевая предобработка для выделения во входящем высказывании значимых слов по позиционному признаку.
Однако для поисковых исследований, связанных с предварительным картированием пространства понятий, и тем более, его локальных кластеров более подходит простой алгоритм с возможность быстро его модифицировать для проверки тех или иных гипотез.
Подобные плоские образования, несомненно, хранятся в нейронных сетях коры речевого центра головного мозга.
В этих направлениях планируется вести дальнейшую работу.
В заключение мы хотели бы поблагодарить за предоставление таблицы исходных данных, с использованием которой это исследование стало возможным.
Список литературы
1. , Фонологическое картирование пространства понятий. Нейроинформатика 2004. Труды VI Всероссийской научно-технической конференции, Часть 2, с. 11-17.
2. , , Естественно упорядоченный алфавит индоевропейских языков. Там же, с. 18-24.
3. Vvedensky V. L., Korshakov A. V., Visualization of the Basic Language Thesaurus. Proc. VII International Conf. «Cognitive Modelling in Linguistics», Varna 2004, p. 308-313.
4. , Самореплецируемый элемент памяти на фонологические примитивы речи в нервной системе человека. Нейроинформатика 2005. Труды VI Всероссийской научно-технической конференции, Часть 2, с. 217-277.
