
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
- определяется кодом операции команды;
- является следующим по порядку адресом;
- является адресом перехода.
Первый случай имеет место только один раз в каждом цикле команды, сразу же вслед за ее выборкой. Как уже отмечалось ранее, каждой команде из системы команд ВМ соответствует «своя» микропрограмма в памяти микропрограмм, поэтому первое действие, которое нужно произвести после выборки команды, — преобразовать код операции в адрес первой М К соответствующей микропрограммы. Это может быть выполнено с помощью аппаратного преобразователя кода операции (см. Рис. 6.8). Такой преобразователь обычно реализуется в виде специального ЗУ, хранящего начальные адреса микропрограмм в ПМП. Для указания того, как должен вычисляться адрес следующей МК в микрокоманде, может быть выделено специальное однобитовое поле. Единица в этом поле означает, что Амк должен быть сформирован на основании кода операции. Подобная МК обычно располагается
в конце микропрограммы этапа выборки или в микропрограмме анализа кода операции.
Дальнейшая очередность выполнения микрокоманд микропрограммы может быть задана путем указания в каждой МК адреса следующей микрокоманды (принудительная адресация) либо путем автоматического увеличения на единицу адреса текущей МК {естественная адресация) [21].
В обоих случаях необходимо предусмотреть ситуацию, когда адрес следующей микрокоманды зависит от состояния осведомительных сигналов - ситуацию перехода. Для указания того, какое условие должно быть проверено, в МК вводится поле условия перехода (УП). Поле УП определяет номер i осведомительного сигнала xi, значение которого анализируется при формировании адреса следующей микрокоманды. Если поле УП = 0, то никакие условия не проверяются и Амк либо берется из адресной части микрокоманды (при принудительной адресации), либо формируется путем прибавления единицы к адресу текущей микрокоманды. Если ![]() , то Амк = А + xi, В результате этого осуществляется условный переход: при хi = 0 к микрокоманде с адресом Амк = Л, а при xi = 1 — к микрокоманде с адресом Амк = А + 1. Описанный порядок формирования адреса показан на рис. 6.12 и имеет место в случае принудительной адресации с одним адресом.
, то Амк = А + xi, В результате этого осуществляется условный переход: при хi = 0 к микрокоманде с адресом Амк = Л, а при xi = 1 — к микрокоманде с адресом Амк = А + 1. Описанный порядок формирования адреса показан на рис. 6.12 и имеет место в случае принудительной адресации с одним адресом.
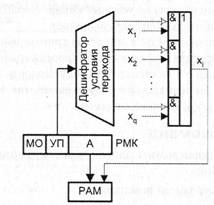
Рис. 6.12. Условные переходы при принудительной адресации микрокоманд
Рассмотренный способ позволяет в каждой команде учесть состояние только одного из осведомительных сигналов. Более гибкий подход реализован в ряде ВМ фирмы IBM. В нем адреса микрокоманды разбиваются на две составляющие. Старшие п разрядов обычно остаются неизменными. В процессе выполнения микрокоманды эти разряды просто копируются из адресной части МК в аналогичные позиции РАМ, определяя блок из 2n микрокоманд в памяти микропрограмм. Остальные (младшие) k разрядов РАМ устанавливаются в 1 или 0 в зависимости от того, проверка каких осведомительных сигналов была задана в поле УП и в каком состоянии эти сигналы находятся. Такой метод позволяет в одной микрокоманде сформировать 2k вариантов перехода.
Теперь рассмотрим возможные способы реализации принудительной и естественной адресации. Известные подходы сводятся к трем типовым вариантам [75]:
- два адресных поля;
- одно адресное поле;
- переменный формат.
Два первых метода представляют принудительную адресацию, а третий — естественную адресацию микрокоманд.
Простейшим вариантом является включение в микрокоманду двух адресных полей (рис-6.13).

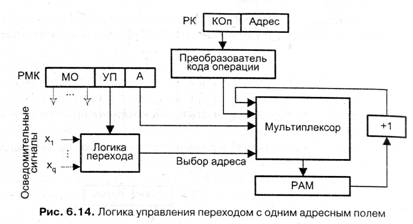
С помощью мультиплексора в регистр адреса микрокоманды (РАМ) может быть загружен либо адрес, определяемый кодом операции выполняемой команды, либо содержимое одного из адресных полей микрокоманды. Выбор источника адреса осуществляется сигналом «Выбор адреса», вырабатываемым логикой перехода, на основании состояния осведомительных сигналов и поля УП микрокоманды. Если УП = 0 или УП = i, но хi= 0, то в РАМ заносится адрес А1 либо адрес, полученный из кода операции. В противном случае в РАМ переписывается адрес А2.
Более распространен вариант принудительной адресации с одним адресным Полем, который уже был показан на рис. 6.12. Здесь в адресной части МК указан адрес следующей микрокоманды, который в случае условного перехода может быть Модифицирован. Возможен и иной подход, в чем-то близкий естественной адресации, когда в адресной части МК задается лишь адрес возможного перехода (Рис. 6.14). При естественном следовании микрокоманд адрес очередной МК формируется путем прибавления единицы к адресу текущей микрокоманды.
Главное достоинство принудительной адресации — высокая универсальность и быстродействие. Здесь изменение участка микропрограммы не затрагивает остальных микрокоманд, а совмещение в одной МК условного перехода с формированием сигналов управления уменьшает общее время выполнения микропрограммы.
Основной недостаток принудительной адресации — повышенные требования к емкости памяти для хранения адресов МК:
![]()
где Rуп — разрядность поля УП; L — общее количество осведомительных сигналов.
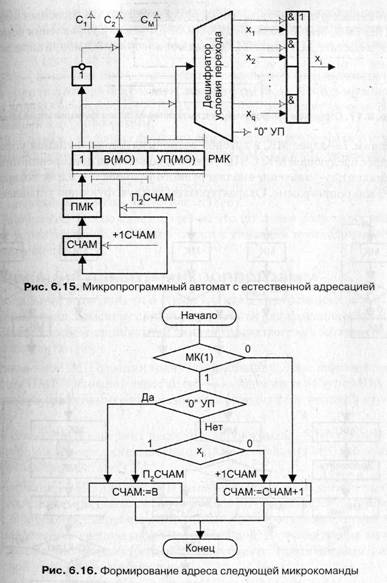
При естественной адресации отпадает необходимость во введении адресной части в каждую МК. Подразумевается, что микрокоманды следуют в естественном порядке и процесс адресации реализуется счетчиком адреса микрокоманды (СЧАМ). Значение СЧ AM увеличивается на единицу после чтения очередной МК.
Однако после выполнения МК с адресом А может потребоваться переход к МК с адресом . Пере ход может быть безусловным или зависеть от текущего значения xi (если xi = 1, то Амк = А + 1; если xi = 0, то Амк = В). Для реализации условных и безусловных переходов используются специальные управляющие микрокоманды, состоящие только из двух полей: адресного поля В и поля УП, выделяющего номер условия перехода. Алгоритм выполнения управляющей МК:
![]()
Таким образом, при естественной адресации должны применяться МК двух типов: управляющие и операционные. Операционная микрокоманда содержит только микрооперационную часть и не имеет адресной части. Тип МК задается ее первым разрядом: если МК(1) = 1, то это управляющая микрокоманда.
Структура МПА с естественной адресацией показана на рис. 6.15. Выдача сигналов управления С1,..., Сm стробируется сигналом МК(1), принимающим единое значение при выполнении операционной МК. Дешифратор условия переход стробируется сигналом МК(1), который равен 1 при обработке управляющей микрокоманды. Адрес следующей МК образуется на счетчике СЧАМ при выполнении микрооперации +1СЧАМ: СЧАМ := СЧАМ + 1 или П2СЧАМ: СЧАМ := В. Формирование адреса следующей МК описывается микропрограммой на рис. 6.16.
Достоинство естественной адресации — экономия памяти микропрограмм; а основной недостаток состоит в том, что для любого перехода требуется полный тактовый период, в то время как при принудительной адресации переход выполняется одновременно с формированием управляющих сигналов без дополнительных обращений к управляющей памяти.
Кроме того, при сильно разветвленных микропрограммах требуются большие дополнительные затраты памяти:
![]()
Рассмотренные способы адресации аппаратно реализует формирователь адреса микрокоманды ФАМ (см. рис. 6.8). ФАМ является механизмом управления последовательностью выполнения микрокоманд. Возрастание сложности микропрограммного обеспечения современных ВМ предопределяет необходимость расширения функциональных возможностей ФАМ.
Набор базовых функций управления, реализуемых ФАМ, включает в себя: ПРИРАЩЕНИЕ, ПЕРЕХОД, ВЫЗОВ, ВОЗВРАТ, ЦИКЛ [9,32]. Функции управления кодируются полем ФУ в составе МК (рис. 6.17) и задают алгоритмы выбора адреса очередной МК.
МО | УП | ФУ | А |
Рис. 6.17. Структура микрокоманды с выделенным полем функции управления
Обозначим: i — адрес МК, в которой размещена данная функция управления; АМК — адрес следующей МК; СЧЦ — счетчик количества повторений микропрограммы (циклов); Xj — значение анализируемого условия; а — адрес возврата к вызывающей микропрограмме. Охарактеризуем каждую функцию управления.
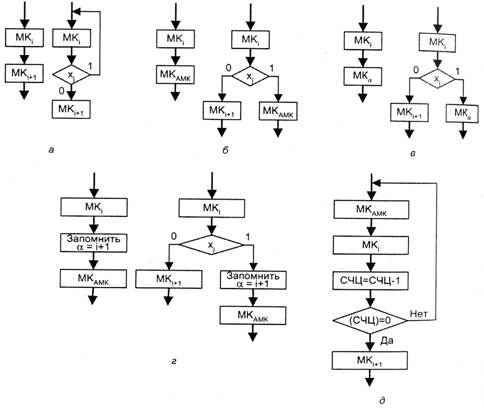
Рис. 6.18. Набор базовых функций управления микрокоманд: а — ПРИРАЩЕНИЕ, б — ПЕРЕХОД; в — ВОЗВРАТ;г - ВЫЗОВ; д — ЦИКЛ
ПРИРАЩЕНИЕ — обеспечивает переход к МК, записанной по адресу i + 1, а условная функция ПРИРАЩЕНИЕ — многократное повторение одной и той же МК, записанной по адресу i (рис. 6.18, а).
ПЕРЕХОД — обеспечивает переход к последовательности микрокоманд с начальным адресом АМК. В случае условного перехода управление передается по адресу АМК при единичном значении условия хj в противном случае выполняется МК пo адресу i + 1, рис 6.18, б).
ВОЗВРАТ — позволяет после выполнения микропрограммы автоматически вернуться в ту точку, откуда она была вызвана (рис. 6.18, в). Использование условной функции ВОЗВРАТ позволяет вернуться к основной микропрограмме из различных точек внешней микропрограммы.
ВЫЗОВ — одна из основных функций, так как позволяет перейти к исполнению другой микропрограммы с начальным адресом АМК (с сохранением адреса точки перехода), как показано на рис. 6.18, г.
ЦИКЛ — передает управление многократно исполняемому участку микропрограммы с начальным адресом АМК (рис. 6.18, д).
Таким образом, можно сделать вывод, что по своим возможностям базовые функции управления микрокоманд близки к командам переходов программного уровня управления.
Организация памяти микропрограмм
Функциональные возможности и структура микропрограммных автоматов в значительной степени зависят от организации памяти для хранения микропрограмм. Основные способы организации памяти микропрограмм можно свести к следующим вариантам [3].
1. Каждое слово ПМП содержит одну микрокоманду. Это наиболее простая организация ПМП. Основной недостаток — в каждом такте работы МГЛА требуется обращение к памяти микропрограмм, что приводит к снижению быстродействия МПА.
2. Одно слово ПМП содержит несколько микрокоманд. В результате осуществляется одновременное считывание из ПМП нескольких МК, что позволяет повысить быстродействие УУ.
3. Сегментация ПМП, при которой память разделяется на сегменты, состоящие из 2q соседних слов, при этом адрес слова АМК разделяется на два поля: S и А. Поле S определяет адрес сегмента, а поле А — адрес слова в сегменте. Адрес S устанавливается специальной микрокомандой. В последующих микрокомандах указывается только адрес слова А в сегменте. Таким образом, разрядность адресной части МК уменьшается.
4. Двухуровневая память (рис. 6.19). Первый уровень — микропамять, хранящая микрокоманды. Второй уровень — нанопамять, содержащая нанокоманды.
МК выбирается из микропамяти и служит для адресации слова нанопамяти, которое включает в себя необходимые сигналы управления. После выполнения микроопераций из микропамяти выбирается следующая МК. Иначе говоря, нанопамять реализует функцию шифратора управляющих сигналов (см. рис. 6.9, е). Двухуровневая память рассматривается как способ для уменьшения необходимой емкости ПМП, ее использование целесообразно только при многократном повторении микрокоманд в микропрограмме.
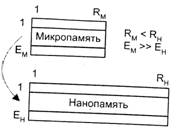
Рис.6.19. Двухуровневая организация памяти МПА.
Запоминающие устройства микропрограмм
Память микропрограмм может быть реализована запоминающими устройствам различных типов. В зависимости от типа применяемого ЗУ различают МПА со статическим и динамическим микропрограммированием [28]. В первом случаев качестве ПМП используется постоянное ЗУ (ПЗУ) или программируемая логическая матрица (ПЛМ), во втором — оперативное ЗУ.
Динамическое микропрограммирование в отличие от статического позволяет оперативно модифицировать микропрограммы УУ, меняя тем самым функциональные свойства ВМ. Основное препятствие на пути широкого использования динамического микропрограммирования — энергозависимость и относительно невысокое быстродействие ОЗУ.
В УУ со статическим микропрограммированием более распространены ПЛМ. Программируемая логическая матрица является разновидностью ПЗУ, в котором программируются не только данные, но и адреса, благодаря чему на ПЛМ можно реализовать как память микропрограмм, так и формирователь адреса следующей микрокоманды.
ПЗУ содержит полный дешифратор с и разрядным входом (адресом) и 2п выходами. Напротив, ПЛМ имеет неполный дешифратор, количество выходов в котором меньше, чем 2п, поэтому в ПЛМ некоторые адреса вообще не инициируют действий, тогда как другие адреса могут оказаться неразличимыми. Таким образом, возможна выборка одного слова с помощью двух или более адресов или же выборка нескольких слов с помощью одного адреса, что эквивалентно реализации функции «ИЛИ» от выбранных слов.
В структуре ПЛМ (рис. 6.20) выделяют три части [21]:
• буфер Б, формирующий парафазные значения ![]() входных переменных
входных переменных 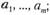
* «И»-матрицу адресов, на выходе которой вырабатываются значения термов ![]()
* «ИЛИ»-матрицу данных, на выходе которой формируются сигналы, представляющие значения выходных переменных с1 ..., сm. Матрица адресов содержит 2т входных цепей (горизонтальные линии) и jm-входовых элементов «И»' каждый из входов которых (вертикальные линии) может соединяться с входной цепью в точках, обозначенных крестиком. Аналогично строится матрица данных, в которой крестиками обозначены возможные соединения входных' цепей матрицы с nj-входовыми элементами «ИЛИ».
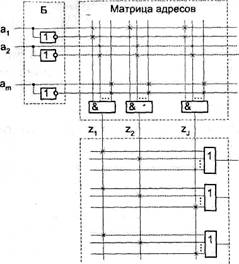
Рис.6.20. Структура программируемой логической матрицы
Соединения в ПЛМ обеспечивают однонаправленную передачу сигналов: в матрице «И» — из любой горизонтальной цепи в вертикальную, а в матрице «ИЛИ» — из любой вертикальной цепи в горизонтальную. Такие соединения осуществляются за счет диодов или транзисторов.
Процесс установления соединений между горизонтальными и вертикальными цепями матриц называется программированием ПЛМ (программированием адресов и данных соответственно). Различают ПЛМ с масочным и электрическим программированием, а также перепрограммируемые логические матрицы. В ПЛМ Первого типа информация заносится посредством подключения диодов или транзисторов к цепям за счет металлизации соответствующих участков матриц, выполняемой через маску (шаблон). В ПЛМ с электрическим программированием либо устанавливаются нужные соединения (путем пробоя слоя диэлектрика, (р-п)-перехода), либо уничтожаются ненужные соединения (благодаря выжиганию плавких перемычек). Перепрограммируемые ПЛМ позволяют многократно переписывать информацию. При этом стирание информации производится ультрафиолетовым излучением, а запись — электрическим током.
ПЛМ более экономны по затратам, чем ПЗУ, в трех случаях:
*при выдаче нулевого кода;
*при формировании значения функции «логическое ИЛИ» от нескольких слов;
*при записи одного и того же слова по нескольким адресам.
Чтобы иметь возможность выдать нулевой код из ПЗУ, необходимо обеспечь предварительную запись нуля в определенную ячейку. В ПЛМ для этого достаточно обращения по незапрограммированному адресу.
Во втором случае в ПЗУ опять должна задействоваться дополнительная ячейка. Для хранения кода, специально запрограммированного как логическое «ИЛИ»
от нескольких слов. В ПЛМ один адрес может относиться к нескольким словам, которые на выходе матрицы данных объединяются по схеме «ИЛИ».
В третьем случае в ПЗУ требуется многократная запись одного слова по всем указанным адресам. Применительно к ПЛМ это означает, что какое-то слово в матрице данных имеет адрес вида 010ХХ, где XX — разряды с безразличным значением (цепи соответствующих разрядов буфера не подключены к вертикальным цепям матрицы адресов).
Минимизация количества слов памяти микропрограмм
Общая задача оптимизации емкости памяти микропрограмм достаточно сложна и поэтому обычно решается в два этапа. На первом этапе минимизируется количество слов микропрограммы (количество микрокоманд), на втором этапе — разрядность микрокоманды.
Сначала рассмотрим один из возможных подходов, действующих при разбиении линейной микропрограммы на минимальное количество микрокоманд [3].
Обозначим через li — множество операндов микрооперации уi, Оi — множество результатов микрооперации yi. Сигналы управления (СУ) микроопераций yi и yj нельзя объединить в одну микрокоманду, если имеет место один из трех случаев пересечения по данным:
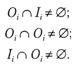
При этом говорят, что yi и yj - находятся в отношении wg зависимости по данным: ![]() . Графически отношение wg отображается графом зависимости по данным (ГЗД), вершины которого соответствуют микрооперациям. Дуга (yi, yj ) в ГЗД показывает, что микрооперации yi и yj находятся в отношении wg. Пример ГЗД приведен на рис. 6.21.
. Графически отношение wg отображается графом зависимости по данным (ГЗД), вершины которого соответствуют микрооперациям. Дуга (yi, yj ) в ГЗД показывает, что микрооперации yi и yj находятся в отношении wg. Пример ГЗД приведен на рис. 6.21.
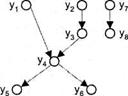
Рис. 6.21. Граф зависимости по данным
Если две микрооперации yi, yj используют один и тот же функциональный узел ВМ, то говорят, что они находятся в отношении структурной несовместимостиwс, то есть yj wc у Сигналы управления двух микроопераций можно объедим в одну микрокоманду, если они структурно совместимы и не находятся в отношении зависимости по данным:
yi,, yj Ì МК, если (уi, wc, yj) & (уi, wc, yj)≠Æ
Пусть между микрооперациями yv..., уа рассматриваемого ГЗД существует следующая структурная несовместимость:
![]()
Минимальное количество микрокоманд в микропрограмме будет определяться длиной критического пути в графе ГЗД, то есть пути, длина которого максимальна.
На первом шаге алгоритма формируется начальное распределение (HP), состоящее из блоков Bv..., Вм, где М— длина критического пути ГЗД. Каждый блок Bt является «заготовкой» микрокоманды Yi в него включаются СУ тех микроопераций которые могут выполняться не ранее, чем по микрокоманде Уi. Начальное распределение для нашего примера показано в табл. 6.1.
Таблица 6.1. Основные распределения микроопераций
Блок | Распределение МО | Блок | ПКР | ||
HP | ПР | КР | |||
B1 | У1 У2 У7 | У2 | У2 | B1 | У2 |
В2 | Уз, У8 | У 1 Уз | Уз | В2 | У3 |
Вз | У4 | У4 У7 | У4 | Вз | У4 |
B4 | У5 У6 | У5, У6, У 8 | У5, У6 | B41 | У5 |
B42 | У6 |
Так как y1 y2, у7 независимы по данным от других микроопераций, то они могут выполняться в блоке В1. Микрооперация у3 зависит по данным от у2, а y8 — от у7, поэтому микрооперации y3 и у8 могут выполняться не ранее, чем в блоке В2. Основной принцип построения HP: СУ микрооперации уп должен помещаться в блок Bi если в блоке Bi-1 находится СУ такой микрооперации ут, что ут wgyn. Полученное HP (см. табл. 6.1) содержит четыре блока, что равно длине максимального пути в ГЗД (см. рис. 6.21), и определяет минимально возможное количество МК в микропрограмме. На втором шаге алгоритма формируется повторное распределение (ПР), определяющее максимальный по номеру блок Вг в котором еще в состоянии выполняться микрооперация уп. Если HP формируется прохождением графа сверху вниз, то ПР — проходом по ГЗД снизу вверх. Так, y8 может выполняться в самом последнем блоке ПР (см. табл. 6.1), поскольку ни одна из микроопераций не зависит по ДЭДным от y8. Длина ПР также равна длине максимального пути в ГЗД.
Исходя из HP и ПР, формируется критическое распределение (КР). В КР входят СУ критических микроопераций, то есть таких, которые находятся в блоках с одинаковыми номерами как в HP, так и в ПР. Так, СУ у2 находится в блоке Bt HP и в блоке В1 ПР, следовательно, это критическая микрооперация критическим носятся также микрооперации у3, у4, у5, у6 (см. табл. 6.1). Кроме того, критическое распределение содержит четыре блока и является основой для формирования набора микрокоманд.
Так как КР было сформировано без учета структурной несовместимости между критическими микрооперациями, оно должно быть проверено на ее наличие.
Блок, содержащий СУ структурно несовместимых микроопераций, «расщепляется» на подблоки, внутри которых нет структурной несовместимости. Тем самым формируется проверенное критическое распределение (ПКР). В нашем случае существует структурная несовместимость между у5 и у6, поэтому блок В входящий в КР, необходимо разделить на два подблока В41 и В42 (см. табл. 6.1).
На последнем шаге алгоритма путем размещения оставшихся СУ некритических микроопераций по блокам ПКР формируется окончательный набор микрокоманд (НМК). Каждый блок и подблок ПКР соответствует одной микрокоманд результирующего НМК. В нашем примере нужно распределить СУ микроопераций yv у, у8. Для этого имеется следующее правило: в ПКР ищется самый первый по номеру блок, в который можно включить СУ микрооперации уп, из последовательности блоков Вн, ..., Вк, где Вн — блок HP и Вк — блок ПР, содержащие СУ данной микрооперации. Если размещаемый СУ у„ не может быть включен ни в один из этих блоков из-за структурной несовместимости с уже размещенными в них СУ микроопераций, то он помещается в специально формируемый блок B'K(i= 1t2, ) В табл. 6.2 показано применение этого правила для окончательного формирования НМК. Так, СУ микрооперации у1 должен быть включен в микрокоманду У1 или в микрокоманду У2. СУ микрооперации у, включается в МК У,, так как он структурно совместим с СУ микрооперации у2 е У,. СУ микрооперации у7 должен быть включен в одну из микрокоманд У„ У2, Y3, однако его нельзя включить в У, из-за структурной несовместимости с СУ микрооперации у2. Нельзя его поместить и в микрокоманду У, вследствие структурной несовместимости с у3. Поэтому СУ у7 войдет в микрокоманду У3.

Последней размещается СУ микрооперации, и сначала может показаться, что он должен быть включен в МК У2, но при этом нарушается ограничение, которое накладывается зависимостью по данным: у7 wgys. Поэтому СУ уа не может войти в МК, предшествующую микрокоманде У3, которая содержит СУ микрооперации у7. Для исключения подобных ошибок следует корректировать HP после каждого распределения СУ микрооперации в МК У,. Коррекция заключается в перемещении всех СУ микроопераций уп, зависящих по данным от распределении СУ микрооперации, в блок В1HP, где номер блока равен: i =j + 1. Следовательно, СУ микрооперации уа после распределения у7 можно включить то в МК У, (см. табл. 6.2).
Минимизация разрядности микрокоманды
Пусть записанная в ПМП микропрограмма содержит т микрокоманд У, Ym. На множестве {у1,..., уп} всех микроопераций, чьи СУ входят в эти МК, задается отношение несовместимости wc , такое что:
![]()
Таким образом, несовместимыми являются микрооперации, СУ которых не встречаются вместе ни в одной микрокоманде микропрограммы. Класс несовместимости (КН) С, с У— множество МО, все элементы которого попарно несовместимы. Максимальный класс несовместимости (МКН) — это такой класс, в который нельзя добавить ни одной микрооперации без нарушения отношения несовместимости wc.
Задача минимизации разрядности микрокоманды формулируется в [3] следующим образом: найти множество классов несовместимости C;|,..., С,- } такое, что
![]()
где С-, — количество микроопераций в классе несовместимости, а выражение int(log2(w + 1)) определяет минимальную разрядность поля ПМП, необходимую для кодирования п микроопераций и признака их отсутствия в конкретной МК. Параметр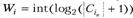 называют ценой класса С,.
называют ценой класса С,.
Решение ищется на множестве МКН. Для заданного в табл. 6.3 примера микропрограммы получается следующий набор МКН:
C1={ y1, y 7, y11}, C2={ y2, y 7, y11}, C3={ y3, y 7, y10 },C4={ y4, y 7, y10 }, C5={ y4, y 9 },
C6={ y5, y 7, y10, y11},C7={ y5, y 8}, C8={ y5, y 9,y11 },C9={ y6, y 7, y10, y11 }, C10={ y6, y 9,y11}
. Таблица 6.3. Набор микрокоманд
Микрокоманда | СУ микроопераций |
Y1 | y1, y2, y3, y4,y5,y6 |
Y2 | y3, y7,y8,y9 |
Y3 | y1, y2, y8, y9,y10 |
Y4 | y4,y8,y11 |
Y5 | y6, y8 |
По набору МКН строится таблица покрытий, в столбце уп которой записываются все МКН, в которые входит СУ микрооперации у. В табл. 6.4 имеются СУ коопераций у1 у2, у3, у8, входящих только в один МКН. Такие микрооперации называют различающими микрооперациями, а соответствующие им МКН — существенными МКН.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
