


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Государственный университет – Высшая школа экономики
Факультет Государственного и муниципального управления
Домашнее задание по курсу «Эконометрика»
На тему:
Построение функций спроса на основные виды товаров и услуг
Студентки III курса
Группа 392
Москва – 2006
Часть I
Упражнение 1
1. Построенная регрессия VID на переменные PVID и DPI выглядит следующим образом:
a b1 b2
VID = 75, 86 – 0,636 PVID + 0, 01 DPI (здесь и далее см. Приложение1)
2. Проверка значимости каждого из коэффициентов регрессии по отдельности (95% уровень значимости):
− a значим, поскольку, во-первых, 0 не входит в доверительный интервал при 95% уровне значимости [38,68667; 113,0246], а во вторых, значение t-статистики (4,15) выходит за границы табличного (tтабл=2,03…(k=33, a=0,05)), то есть гипотеза H0 о незначимости коэффициента отвергается
− b1 значим, поскольку, во-первых, 0 не входит в доверительный интервал при 95% уровне значимости [-0,83; -0,44], а во вторых, значение t-статистики (-6,6) выходит за границы табличного (tтабл=2,03…(k=33, a=0,05)), то есть гипотеза H0 о незначимости коэффициента отвергается
− b2 значим, поскольку, во-первых, 0 не входит в доверительный интервал при 95% уровне значимости [0,006; 0,014], а во вторых, значение t-статистики (5,105) выходит за границы табличного (tтабл=2,03…(k=33, a=0,05)), то есть гипотеза H0 о незначимости коэффициента отвергается
3. Проверка адекватности регрессии в целом (95% уровень значимости)
− во-первых, все p-value достаточно маленькие, что указывает на то, что регрессия адекватна
− Н0 : b1= b2=0
На : b12+ b22 ≠0
Сопоставляем имеющуюся F-статистику с табличной: Fтабл=3,29 (m=2, n=33),что существенно меньше 124, 53. Следовательно, гипотеза H0 отвергается, и можно сделать вывод об адекватности модели.
4. Построение 95% доверительных интервалов для коэффициентов наклона
Как видно из п.2, доверительным интервалом для b1 будет интервал [-0,83; -0,44], а для b2 - интервал [0,006; 0,014]. Формальное построение будет выглядеть следующим образом:
− для b1: 0,05=p{– 0,,03*0,096≤ α ≤ -0,636+2,03*0,096}=p{-0,83≤ α ≤ -0,44}
− для b2:0,05=p{0, 01-2,03*0,002≤ α ≤0, 01+ 2,03*0,002}=p{0,006 ≤ α ≤ 0,014}
5. Экономическая интерпретация
Поскольку все коэффициенты регрессии значимы, то можно утверждать, что расходы на видео и аудио продукцию, компьютерное оборудование и музыкальные инструменты снизятся на 0, 6 п. при увеличении на 1п. номинального индекса цен на данный вид продукции и увеличится на 0, 01 п. при увеличении личного располагаемого дохода на 1п., что не противоречит здравому смыслу, так как при увеличении цен спрос, и, соответственно, расходы на товар снижаются, а при увеличении личного располагаемого дохода расходы на такую продукцию возрастают не сильно, так как она все же достаточно дорога.
Упражнение 2
1. Построенная регрессия LNVID на переменные LNPVID и LNDPI выглядит следующим образом:
a b1 b2
LNVID = -10,7 – 1,79 LNPVID + 2,7 LNDPI (здесь и далее см. Приложение 2)
2. Проверка значимости каждого из коэффициентов регрессии по отдельности (95% уровень значимости):
− a значим, поскольку, во-первых, 0 не входит в доверительный интервал при 95% уровне значимости [ -13,1; -8,3], а во вторых, значение t-статистики (-9,17) выходит за границы табличного (tтабл=2,03…(k=34, a=0,05)), то есть гипотеза H0 о незначимости коэффициента отвергается
− b1 значим, поскольку, во-первых, 0 не входит в доверительный интервал при 95% уровне значимости [-2,1; -1,5], а во вторых, значение t-статистики (-12,14) выходит за границы табличного (tтабл=2,03…(k=34, a=0,05)), то есть гипотеза H0 о незначимости коэффициента отвергается
− b2 значим, поскольку, во-первых, 0 не входит в доверительный интервал при 95% уровне значимости [2,6; 2,9], а во вторых, значение t-статистики (39,7) выходит за границы табличного (tтабл=2,03…(k=34, a=0,05)), то есть гипотеза H0 о незначимости коэффициента отвергается
3. Проверка адекватности регрессии в целом (95% уровень значимости)
− во-первых, все p-value достаточно маленькие, что указывает на то, что регрессия адекватна
− Н0 : b1= b2=0
На : b12+ b22 ≠0
Сопоставляем имеющуюся F-статистику с табличной: Fтабл=3,29 (m=2, n=33)..,что существенно меньше 2139,3. Следовательно, гипотеза H0 отвергается, и можно сделать вывод об адекватности модели.
4. Экономическая интерпретация
Проведенный анализ линейной в логарифмах модели показывает, что если номинальный индекс цен на видео и аудио продукцию, компьютерное оборудование и музыкальные инструменты вырастет на 1%, то расходы на эту продукцию снизятся на 1,79%. Если же личный располагаемый доход вырастет на 1%, то расходы на этот вид продукции вырастут на 2,7%. Такая динамика в изменении расходов свидетельствует о том, что видео и аудио продукция, компьютерное оборудование и музыкальные инструменты являются нормальным товаром и товаром роскоши.
Упражнение 3
1. Построенная регрессия LNVID на переменные LNPVID и LNDPI выглядит следующим образом:
a b1 b2
LNVID = 0,497 – 0,0091 PVID + 0,000996DPI (здесь и далее см. Приложение 3)
2. Проверка значимости каждого из коэффициентов регрессии по отдельности (95% уровень значимости):
− a значим, поскольку, во-первых, 0 не входит в доверительный интервал при 95% уровне значимости [ 0,237; 0,756], а во вторых, значение t-статистики выходит за границы табличного (tтабл=2,03…(k=34, a=0,05)), то есть гипотеза H0 о незначимости коэффициента отвергается
− b1 значим, поскольку, во-первых, 0 не входит в доверительный интервал при 95% уровне значимости [-0,01;-0,007], а во вторых, значение t-статистики выходит за границы табличного (tтабл=2,03…(k=34, a=0,05)), то есть гипотеза H0 о незначимости коэффициента отвергается
− b2 значим, поскольку, во-первых, 0 не входит в доверительный интервал при 95% уровне значимости [0,00097;0,001], а во вторых, значение t-статистики выходит за границы табличного (tтабл=2,03…(k=34, a=0,05)), то есть гипотеза H0 о незначимости коэффициента отвергается
3. Проверка адекватности регрессии в целом (95% уровень значимости)
− p-value достаточно маленькие, что указывает на то, что регрессия адекватна
− Н0 : b1= b2=0
На : b12+ b22 ≠0
Сопоставляем имеющуюся F-статистику с табличной: Fтабл=3,29 (m=2, n=33)..,,что существенно меньше 143,84. Следовательно, гипотеза H0 отвергается, и можно сделать вывод об адекватности модели.
4. Экономическая интерпретация
В данном случае проведенный анализ полулинейной модели показывает, что при увеличении номинального индекса цен на видео и аудио продукцию, компьютерное оборудование и музыкальные инструменты на 1 единицу, расходы на данный вид продукции снижаются на 0,91%, а при увеличении личного располагаемого дохода на 1 единицу расходы на данный вид продукции увеличатся на 0,0996%.
Упражнение 4
Тест Бокса-Кокса позволяет выбрать лучшую между линейной и полулинейной моделью. Следовательно, сравниваемые регрессии будут выглядеть следующим образом:
VID = 75, 86 – 0,636 PVID + 0, 01 DPI ; R2=0,88 (см. Приложение1)
LNVID = 0,497 – 0,0091 PVID + 0,000996DPI; R2=0,998 (см. Приложение3)
H0: между моделями нет разницы
Ha: модель с большим R2 лучше
Для того, чтобы иметь возможность сравнить две выбранные регрессии, необходимо провести преобразование Зарембки.
− вычислим геометрическое среднее элементов VID (взяв экспоненту от среднего значения LNVID) =11,04
− пересчитаем наблюдения VID, поделив их на среднее геометрическое
− оценим регрессию для линейной модели с использованием пересчитанного VID, а для полулинейной модели с использованием LN (пересчитанный VID)
− проверим гипотезы с помощью критерия χ2
χ2 = 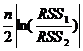
RSS1 = 16,33 (см. Приложение 4а), RSS2= 0,097 (см. Приложение 4b), n=36
χ2=92,27; χ2табл= 3,84 (k=1, a=0,05)
Поскольку найденный χ2 выходит за границы табличного, гипотеза о равенстве между моделями отвергается. Следовательно, нужно выбирать модель с большим R2.
Таким образом, выбранная регрессия – полулинейная модель:
LNVID = 0,497 – 0,0091 PVID + 0,000996DPI
Упражнение 5
Среди представленных товаров и услуг заменителями для видео и аудио продукции, компьютерного оборудования и музыкальных инструментов могут служить развлечения (театры, кино и т. д.), книги и карты, печатные издания и другой отдых.
С учетом заменяющих товаров регрессия выглядит следующим образом (см. Приложение 5a):
a b1 b2 b3 b4 b5 b6
VID = 58, 37 – 0, 267 PVID – 0,02 DPI + 0, 71 PADM– 1,96 PBOOK+ 2,64 PMAGS – 0,107 PREC
1. Проверка значимости каждого из коэффициентов по отдельности:
− a значим, поскольку, во-первых, 0 не входит в доверительный интервал при 95% уровне значимости, а во вторых, значение t-статистики выходит за границы табличного (tтабл=2,03…(k=34, a=0,05))
− b1 значим, поскольку, во-первых, 0 не входит в доверительный интервал при 95% уровне значимости, а во вторых, значение t-статистики выходит за границы табличного (tтабл=2,03…(k=34, a=0,05))
− b2 значим, поскольку, во-первых, 0 не входит в доверительный интервал при 95% уровне значимости [ 0,237; 0,756], а во вторых, значение t-статистики выходит за границы табличного (tтабл=2,03…(k=34, a=0,05))
− b3 не значим, поскольку, во-первых, 0 входит в доверительный интервал при 95% уровне значимости, а во вторых, значение t-статистики не выходит за границы табличного (tтабл=2,03…(k=34, a=0,05))
− b4 значим, поскольку, во-первых, 0 не входит в доверительный интервал при 95% уровне значимости, а во вторых, значение t-статистики выходит за границы табличного (tтабл=2,03…(k=34, a=0,05))
− b5 значим, поскольку, во-первых, 0 не входит в доверительный интервал при 95% уровне значимости, а во вторых, значение t-статистики выходит за границы табличного (tтабл=2,03…(k=34, a=0,05))
− b6 не значим, поскольку, во-первых, 0 входит в доверительный интервал при 95% уровне значимости, а во вторых, значение t-статистики не выходит за границы табличного (tтабл=2,03…(k=34, a=0,05))
2. Проверка адекватности регрессии в целом (95% уровень значимости):
− p-value небольшие, что указывает на то, что регрессия адекватна
− Н0 : b1 = b2 = b3 = b4 = b5 = b6 =0
На : b12+ b22+ b32+ b42 + b52+ b62 ≠0
Сопоставляем имеющуюся F-статистику с табличной: Fтабл=2,43 (m=6, n=29).,что существенно меньше 231,39. Следовательно, гипотеза H0 отвергается, и можно сделать вывод об адекватности модели.
3. Вычисление показателя воздействия коэффициента регрессии (коэффициент возрастания дисперсии) для каждого фактора (VIF =![]() ), где
), где ![]() — коэффициент детерминации при оценивании методом наименьших квадратов модели линейной регрессии
— коэффициент детерминации при оценивании методом наименьших квадратов модели линейной регрессии ![]() -ой объясняющей переменной на остальные объясняющие переменные (см. Приложения 5b-5g)
-ой объясняющей переменной на остальные объясняющие переменные (см. Приложения 5b-5g)
VIF1 = 15,83
VIF2 = 28,08
VIF3 = 1106,85
VIF4 = 851,4
VIF5 = 3964,91
VIF6 = 4070,28
Такие большие значения VIF-ов указывают на возможное наличие мультиколлинеарности. Подтверждением этого факта служит также достаточно высокий R2 (0,98 – см. Приложение 5а) при двух незначимых коэффициентах (2 из 6 – это относительно много). Еще одним доказательством наличия мультиколлинеарности в модели служит неправильный с экономической точки зрения коэффициент при личном располагаемом доходе: очевидно, что он должен быть не меньше, а больше нуля, поскольку как было показано выше видео и аудио продукция, компьютерное оборудование и музыкальные инструменты являются нормальным товаром, а, значит, расходы на них должны расти, а не уменьшаться с ростом личного располагаемого дохода. Кроме того, при изменении исходных статистических данных (изъятии группы наблюдений за последние 2 года), можно увидеть неустойчивость оценок МНК: коэффициент при PMAGS изменился с 2,64 до -0,07. (см. Приложение 5h)
В качестве метода борьбы с мультиколлинеарностью выберем изъятие из регрессии незначимых факторов. Но прежде воспользуемся теоремой о корне из r, которая утверждает, что если в регрессии существует r-незначимых факторов, и | t | - статистика меньше корня из этого числа, то при удалении этой группы переменных R2adj может увеличиться. Проверим теорему на выбранных факторах:
− два незначимых коэффициента => ![]() =
=![]() =1,4
=1,4
− для PADM | t | = 1,02 < 1,4
− для PREC | t | =0,07 < 1,4
Таким образом, условие теоремы выполнено. Попробуем удалить из регрессии оба незначимых фактора. Несмотря не достаточно высокое значение, R2adj ухудшился по сравнению с неограниченной моделью (с 0,9753 до 0,9749). (см. Приложение 5i) Ухудшение R2 adj свидетельствует о том, что не следует удалять эти факторы вместе.
Попробуем удалить незначимые факторы по отдельности. При удалении из уравнения регрессии номинального индекса цен на развлечения, R2 adj также немного ухудшается (с 0,9753 до 0,97527) (см. Приложение 5j). При удалении номинального индекса цен на другой отдых R2 adj улучшается (с 0,9753 до 0,976), что означает частичное избавление от проблемы мультиколлинеарности.(см. Приложение 5k)
Таким образом, методом удаления незначимых факторов можно лишь частично справится с моделью мультиколлинеарности. Другим вариантом борьбы с мультиколлинеарностью может быть выбор другой модели. При выборе полулинейной в логарифмах модели несмотря на достаточно высокий R2 adj (0,991) появляется слишком много незначимых факторов (5 из 6), что указывает не на решение, а на усугубление проблемы мультиколлинеарности (см. Приложение 5l)
При выборе полулинейной модели R2 adj увеличивается (с 0,9753 до 0,998). В то же время, несмотря на такие же незначимые факторы, как в линейной модели, коэффициент при личном располагаемом доходе стал соответствовать экономическому смыслу, что свидетельствует о частичном решении проблемы мультиколлинеарности. ( см. Приложение 5m)
Проведенный анализ позволяет сделать выбор в пользу полулинейной модели с двумя незначимыми факторами. Новое уравнение регрессии будет следующим:
VID = 0,72 – 0, 0,01 PVID + 0,001DPI - 0, 01 PADM– 0,02 PBOOK+ 0,04 PMAGS – 0,01 PREC
Упражнение 6
6.1 Необходимая регрессия имеет вид:
LNVID = -10,7 – 1,79 LNPVID + 2,7 LNDPI
Проверим гипотезу о равенстве нулю суммы коэффициентов перед переменными LNPVID и LNDPI.
Н0 : b1+ b2=0
На : b1+ b2 ≠0
Вычисляем t-статистику: ![]()
D (LNPVID) = 0,024
D (LNDPI) = 0,11 =>
cov (LNPVID; LNDPI) = 0,095911
=> t = (-1,79+2,7)/0,479=1,89
Количество степеней свободы = 36 – 2 – 1 = 33, t-статистика =2,% уровень значимости). Следовательно, гипотеза не отвергается.
6.2 Проверим гипотезу о равенстве коэффициентов при товарах – заменителях одновременно.
a b1 b2 b3 b4 b5 b6
VID = 58, 37 – 0, 267 PVID – 0,02 DPI + 0, 71 PADM– 1,96 PBOOK+ 2,64 PMAGS – 0,107 PREC
Н0 : b3 = b4= b5= b6=0 RSSUR = 348,056
На : b32 = b42 = b52= b62 ≠0
Введем ограничения в модель (см. Приложение 1):
VID = 75, 86 – 0,636 PVID + 0, 01 DPI RSSR = 1990,23
Посчитаем F - статистику:
F=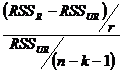 => F = ((1990,231,0556)/ 4)/( 348,0556/(36-6-1))= 34,21
=> F = ((1990,231,0556)/ 4)/( 348,0556/(36-6-1))= 34,21
Fтабл = 2,7 => гипотеза отвергается. Как было показано в Упражнении 5, регрессия улучшится при удалении одного фактора: номинального индекса цен на другой отдых (PREC).
Упражнение 7
Построенные регрессии для и гг выглядят следующим образом:
− гг
VID = -13,47 + 0,03PVID +0,006DPI ; RSS1=1,64 (см. Приложение 6а)
− гг
VID = 387,62 -1,57PVID – 0,036DPI ; RSS2=485,016 (см. Приложение 6b)
Для того, чтобы решить объединять ли эти две группы или оценивать как отдельные, необходимо провести тест Чоу.
Запишем регрессию и сумму квадратов остатков объединенной группы (см. Упражнение 1):VID = 75, 86 – 0,636 PVID + 0, 01 DPI ; RSSобщ=1990,232
2. Оценим F-статистику и сопоставим ее с табличной (95% уровень значимости):
F = 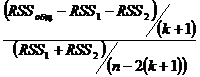
F = ((1990,,6,016)/(3))/(( 1,64 + 485,016)/(36-6)) = 30,896
Fтабл= 2,92 => гипотеза о единой зависимости для двух временных интервалов отвергается, то есть расходы анализируемый вид продукции зависели от временного периода, а значит, при построении регрессии разбивка данных на две группы приносит существенное улучшение.
Упражнение 8
Рассмотрим ошибки спецификации модели. Исходная регрессия имеет вид:
a b1 b2
VID = 75, 86 – 0,636 PVID + 0, 01 DPI (см. Приложение 1)
Оценим смещение в ограниченных моделях:
VID = 157,44 – 0,996 PVID (см. Приложение 7а)Оценка смещения: b1*cov(PVID; DPI)/D(PVID)
cov (PVID; DPI)= -13490,1 ; D(PVID) = 385,766 =>
смещение = (0,01* (-13490,10))/ 385,766 = - 0,3497
Причиной смещения является невключение такой существенной переменной как личный располагаемый доход. При анализе расходов на видео, аудио продукцию, компьютерное оборудование и музыкальные инструменты (как, в принципе и других расходов), нельзя забывать про личный располагаемый доход, так как его размер и динамика напрямую влияет на потребление, а в особенности, на потребление товаров роскоши, к которым относится рассматриваемая группа товаров.
VID = - 41,19 + 0, 019 DPIОценка смещения: b2*cov(DPI; PVID)/D(DPI)
cov (DPI; PVID)= -13490,1 ; D(DPI) = 7=>
смещение = (-0,636* (-13490,10))/ 7= 0,0089
Причиной смещения стало невключение существенной переменной номинального индекса цен на рассматриваемую группу товаров. Эти фактором нельзя пренебрегать, поскольку изменение номинального индекса цен влияет на желание и возможность потребителей делать расходы на определенный вид продукции, когда же эта продукция (как рассматриваемая группа) достаточно дорога, то это влияние возрастает.
Упражнение 9
Регрессия для проведения теста Рамсея выглядит следующим образом:
VID = 75, 86 – 0,636 PVID + 0, 01 DPI (см. Приложение 1); RSSR = 1990,23
Оценим уравнение регрессии с квадратом оценок зависимой переменной:
VID = -27,06 + 0,12 PVID + 0, 005 DPI + 0,016 ![]() (см. Приложение 8а)
(см. Приложение 8а)
m=2 => проверяем значимость ![]() по t-статистике (t =22,26922, что очевидно больше табличного значения). Поскольку коэффициент значим, добавляем еще один нелинейный член.
по t-статистике (t =22,26922, что очевидно больше табличного значения). Поскольку коэффициент значим, добавляем еще один нелинейный член.
Оценим уравнение регрессии с кубом оценок зависимой переменной:
VID = -23,86 + 0,087 PVID + 0, 006 DPI + 0,009 ![]() + 0,0001
+ 0,0001![]() ; RSSUR = 80,08
; RSSUR = 80,08
(см. Приложение 8b)
Посчитаем F-статистику: F = 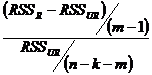 = > F = 347, 03
= > F = 347, 03
Следовательно, коэффициент при добавленном члене значим и нужно добавлять еще нелинейную степень оценок зависимой переменной.
На практике обычно не добавляют степень нелинейного члена старше трех. Тем не менее, рискнем все же добавить ![]() . Все равно, коэффициент при нелинейном члене остается значимым
. Все равно, коэффициент при нелинейном члене остается значимым ![]() , но вдобавок становятся незначимыми три из значимых прежде фактора. (см. Приложение 8c)
, но вдобавок становятся незначимыми три из значимых прежде фактора. (см. Приложение 8c)
Следовательно, в целом можно сделать вывод, что спецификация модели не была выбрана правильно. Скорее всего, были упущены существенные переменные.
Часть II
Упражнение 10
а) тест Уайта
− VID = 75, 86 – 0,636 PVID + 0, 01 DPI ;
е2 = 1451,19 – 29,94 PVID + 0, 49 DPI + 0,13 PVID2 - 0,00005 DPI2 – 0,0018 PVID*DPI
R2 = 0,559078
H0: гомоскедастичность
HА: гетероскедастичность
χ2 =nR2 => χ2= 36*0,56 =20,16
χ2табл (q=5, a=0,05) = 11,07 гипотеза отвергается но приa=0,001 20,517 Гипотеза не отвергается, значит гомоскедастичность.
Коррекция на гетероскедастичность:
Поскольку значение стандартного отклонения по наблюдениям неизвестно, можно предположить, что стандартное отклонения случайного члена в наблюдениях и пропорционально личному располагаемому доходу наблюдения и.
Коррекция с точностью как в голдфилде.
− LNVID = -10,7 – 1,79 LNPVID + 2,7 LNDPI ;
− R2 =0,270823 =0,27*36=9,72 Гомоскедастичность
− LNVID = 0,497 – 0,0091 PVID + 0,000996DPI;
− R2 = 0,137801 = *36 =4,96 Гомоскедастичность
б) тест Голдфилда-Квандта
− VID = 75, 86 – 0,636 PVID + 0, 01 DPI
Упорядочиваем данные по той переменной, относительно которой есть тест на гетероскедастичность. Подозрения на личный располагаемый доход (тк график)
Поскольку n1=n2, то F = ![]() = 466,75 Степ свободы = 9;9 5% = 3,18 Гипотеза отвергается
= 466,75 Степ свободы = 9;9 5% = 3,18 Гипотеза отвергается
Гетероскедастичность
Коррекция: для получения эффективных оценок необходимо преобразование данных, то есть необходимо все разделить на личный располагаемый доход и-тый
где свободный член?
− LNVID = -10,7 – 1,79 LNPVID + 2,7 LNDPI
F=0,56 Гомоскедастичность
− LNVID = 0,497 – 0,0091 PVID + 0,000996DPI
F= 0,82 Гомоскедастичность
Упражнение 11
Проверка на автокорреляцию тестом Дарбина –Уотсона.
Нулевая гипотеза – корреляция отсутствует
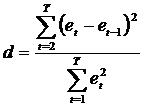
− VID = 75, 86 – 0,636 PVID + 0, 01 DPI
d = 0,177399
Положительная автокорреляция, тк меньше dL=1,35
− LNVID = -10,7 – 1,79 LNPVID + 2,7 LNDPI
d = 0,283708
Положительная автокорреляция, тк меньше dL=1,35
Итеративная процедура Кокрена-Оркутта
1. для 1го уравнения
VID = 75, 86 – 0,636 PVID + 0, 01 DPI
2. для 2 уравнения
LNVID = -10,7 – 1,79 LNPVID + 2,7 LNDPI
