

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
4 Определение, отличительные особенности и архитектура СППР
Общая характеристика
Назначение систем поддержки принятия решений (СППР) -– облегчить принятие пользователями наиболее эффективных решений на основе той информации, которая накапливается системой и тех методов ее обработки и представления, которые в систему заложены. В той или иной степени эти функции реализуются любой информационной системой, однако в СППР они являются определяющими.
Чрезвычайно четкое описание классического представления СППР содержится в статье В. Львова [51], поэтому дальнейшее изложение построено, во многом, на ее основе, с привлечением ряда других источников, указанных в Библиографии.
В зависимости от конкретного назначения СППР делят на две категории:
· оперативные, предназначенные для немедленного реагирования на текущую ситуацию,
· стратегические - основанные на анализе большого количества информации из разных источников с привлечением сведений, содержащихся в системах, аккумулирующих опыт решения проблем.
СППР первого типа получили название Информационных Систем Руководства (Executive Information Systems, ИСР). По сути, они представляют собой конечные наборы отчетов, построенные на основании данных из информационной системы, в идеале адекватно отражающей в режиме реального времени все аспекты функционирования объекта. Для ИСР характерны следующие основные черты:
- отчеты, как правило, базируются на стандартных запросах; число последних относительно невелико; ИСР представляет отчеты в максимально удобном виде, включающем, наряду с таблицами, деловую графику, мультимедийные возможности и т. п.;
СППР второго типа предполагают достаточно глубокую проработку данных, специально преобразованных так, чтобы их было удобно использовать в ходе процесса принятия решений. Неотъемлемым компонентом СППР этого уровня являются правила принятия решений, которые на основе агрегированных данных подсказывают пользователю выводы и придают системе черты искусственного интеллекта.
На ранних стадиях развития качество решений в СППР обеспечивалось тем, что данные выбираются непосредственно из информационной системы управления, которая адекватно отражает состояние объекта на данный момент времени. Ранние версии СППР второго типа в качестве исходных использовали также относительно небольшой объем агрегированных данных, поддающихся проверке на достоверность, полноту, непротиворечивость и адекватность.
Однако с увеличением времени эксплуатации СППР накапливается большой объем исторических данных, возникает потребность в из ретроспективном анализе; кроме того, расширяются масштабы системы. Все это приводит к тому, что оперирование непосредственно с детальной базой данных делает время отклика недопустимо большим и затрудняет составление пользователями нефиксированных запросов, тогда как это является характерной потребностью при обдумывании сложных решений.
Решение было найдено и сформулировано в виде концепции Хранилища Данных (Data Warehouse, ХД), которое выполняло бы функции предварительной подготовки и хранения данных для СППР на основе детальной информации.
4. 2 Технология разработки и внедрения Хранилища Данных. OLAP
Первой фазой разработки ХД является системный анализ объекта принятия решений. Например, в практике СППР для бизнеса известно два подхода к такому анализу. Первый ориентируется на описание бизнес-процессов, протекающих на предприятии, которое моделируется набором взаимосвязанных функциональных элементов. Второй подход основан на первичном анализе бизнес-событий. При проектировании СППР на основе ХД именно он обеспечивает наибольшую эффективность:
- позволяет гибко модифицировать бизнес-процессы, ставя их в зависимость от бизнес-событий; интегрирует данные, которые при анализе бизнес-процессов остаются скрытыми в алгоритмах обработки данных; объединяет управляющие и информационные потоки; наглядно показывает, какая именно информация нужна при обработке бизнес-события и в каком виде она представляется.
Иными словами, бизнес-событие является более устойчивым и более тесно связанным с информационными и управляющими потоками понятием, чем бизнес-процесс.
Через анализ бизнес-событий необходимо перейти к анализу данных. При этом должна быть собрана информация об используемых внешних данных и их источниках; о форматах данных, периодичности и форме их поступления; о внутренних информационных системах объекта, обслуживаемого СППР, их функциях и алгоритмах обработки данных, используемых при наступлении бизнес-событий. Такой анализ, как правило, производится при проектировании любой информационной системы. Особенность анализа данных при проектировании СППР на состоит в необходимости создания моделей представления информации. То, что в обычных информационных системах является вторичным понятием, а именно состав и форма отображаемых данных, в СППР приобретает особую важность, так как нужно выявить все без исключения признаки, требуемые для принятия решений.
Модель представления данных является организационно-функциональным срезом модели системы, а при ее разработке последовательно изучаются:
- распределение пользователей системы: географическое, организационное, функциональное; доступ к данным: объем данных, необходимый для анализа, уровень агрегированности данных, источники данных (внешние или внутренние), описание информации, совместно используемой различными функциональными группами пользователей; аналитические характеристики системы: измерения данных, основные отчеты, последовательность преобразования аналитической информации, степень предопределенности анализа, существующие или находящиеся в стадии разработки средства анализа.
При проектировании обычной информационной системы, как правило, строго выдерживается последовательность процессов: бизнес-анализ, концептуальная модель данных, физическая модель данных, структура интерфейса и т. п. Возврат на предыдущий уровень происходит редко и считается отклонением от нормального хода выполнения проекта. В случае СППР на основе ХД нормальным считается итерационный, а иногда и параллельный, характер моделирования, при котором возврат на предыдущую стадию - обычное явление. Это связано с необходимостью выделения всех требуемых данных для произвольных запросов (ad-hoc), для чего следует составить исчерпывающий перечень необходимых данных и построить схему их связей через бизнес-события. При этом из общего массива выделяется значимая информация и выясняется потребность в дополнительных источниках данных для принятия решений.
Итак, по результатам анализа бизнес-процессов и структур данных отбирается действительно значимая для принятия решений информация с учетом неопределенности будущих запросов. Следующий шаг связан с пониманием того, в каком виде и на каких аппаратных и программных платформах размещать структуру данных СППР на основе ХД.
В самом простом варианте для Хранилищ Данных используется реляционная СУБД (Oracle, Informix, Sybase и т. п.). Тогда самой сложной задачей становится выполнение запросов ad-hoc, поскольку невозможно заранее оптимизировать структуру БД так, чтобы все запросы работали эффективно.
Однако практика принятия решений показала, что существует зависимость между частотой запросов и степенью агрегированности данных, с которыми запросы оперируют, а именно чем более агрегированными являются данные, тем чаще запрос выполняется. Другими словами, круг пользователей, работающих с обобщенными данными, шире, чем тот, для которого нужны детальные данные. Это наблюдение легло в основу подхода к поиску и выборке данных, называемого Оперативной Аналитической Обработкой (On-line Analytical Processing, OLAP).
OLAP – это информационная технология, которая предоставляет руководителям различного уровня возможность получения необходимой информации для принятия управленческих, финансовых и кадровых решений ([48]).
OLAP-системы построены на двух базовых принципах:
- все данные, необходимые для принятия решений, предварительно агрегированы на всех соответствующих уровнях и организованы так, чтобы обеспечить максимально быстрый доступ к ним; язык манипулирования данными основан на использовании бизнес-понятий.
В основе концепции OLAP лежит принцип многомерного представления данных. Первое четкое определение OLAP предложено в 1993 году (E. F.Codd) в статье, опубликованной при поддержке Arbor Software (теперь - Hyperion Software). Статья включала следующие 12 правил (Таблица 24 ).
Таблица 24.
Двенадцать правил Кодда оценки программных
продуктов класса OLAP
1 | Многомерное концептуальное представление данных (Multi-Dimensional Conceptual View) | Концептуальное представление модели данных в продукте OLAP должно быть многомерным по своей природе, то есть позволять аналитикам выполнять интуитивные операции "анализа вдоль и поперек" ("slice and dice"), вращения (rotate) и размещения (pivot) направлений консолидации. |
2 | Прозрачность (Transparency) | Пользователь не должен знать о том, какие конкретные средства используются для хранения и обработки данных, как данные организованы и откуда берутся. |
3 | Доступность (Accessibility) | Аналитик должен иметь возможность выполнять анализ в рамках общей концептуальной схемы, но при этом данные могут оставаться под управлением оставшихся от старого наследства СУБД, будучи при этом привязанными к общей аналитической модели. То есть инструментарий OLAP должен накладывать свою логическую схему на физические массивы данных, выполняя все преобразования, требующиеся для обеспечения единого, согласованного и целостного взгляда пользователя на информацию. |
4 | Устойчивая производительность (Consistent Reporting Performance) | С увеличением числа измерений и размеров базы данных аналитики не должны столкнуться с каким бы то ни было уменьшением производительности. Устойчивая производительность необходима для поддержания простоты использования и свободы от усложнений, которые требуются для доведения OLAP до конечного пользователя. |
5 | Клиент - серверная архитектура (Client-Server Architecture) | Большая часть данных, требующих оперативной аналитической обработки, хранится в мэйнфреймовых системах, а извлекается с персональных компьютеров. Поэтому одним из требований является способность продуктов OLAP работать в среде клиент-сервер. Главной идеей здесь является то, что серверный компонент инструмента OLAP должен быть достаточно интеллектуальным и обладать способностью строить общую концептуальную схему на основе обобщения и консолидации различных логических и физических схем корпоративных баз данных для обеспечения эффекта прозрачности. |
6 | Равноправие измерений (Generic Dimensionality) | Все измерения данных должны быть равноправны. Дополнительные характеристики могут быть предоставлены отдельным измерениям, но поскольку все они симметричны, данная дополнительная функциональность может быть предоставлена любому измерению. Базовая структура данных, формулы и форматы отчетов не должны опираться на какое-то одно измерение. |
7 | Динамическая обработка разреженных матриц (Dynamic Sparse Matrix Handling) | Инструмент OLAP должен обеспечивать оптимальную обработку разреженных матриц. Скорость доступа должна сохраняться вне зависимости от расположения ячеек данных и быть постоянной величиной для моделей, имеющих разное число измерений и различную разреженность данных. |
8 | Поддержка многопользовательского режима (Multi-User Support) | Зачастую несколько аналитиков имеют необходимость работать одновременно с одной аналитической моделью или создавать различные модели на основе одних корпоративных данных. Инструмент OLAP должен предоставлять им конкурентный доступ, обеспечивать целостность и защиту данных. |
9 | Неограниченная поддержка кроссмерных операций (Unrestricted Cross-dimensional Operations) | Вычисления и манипуляция данными по любому числу измерений не должны запрещать или ограничивать любые отношения между ячейками данных. Преобразования, требующие произвольного определения, должны задаваться на функционально полном формульном языке. |
10 | Интуитивное манипулирование данными (Intuitive Data Manipulation) | Переориентация направлений консолидации, детализация данных в колонках и строках, агрегация и другие манипуляции, свойственные структуре иерархии направлений консолидации, должны выполняться в максимально удобном, естественном и комфортном пользовательском интерфейсе. |
11 | Гибкий механизм генерации отчетов (Flexible Reporting) | Должны поддерживаться различные способы визуализации данных, то есть отчеты должны представляться в любой возможной ориентации. |
12 | Неограниченное количество измерений и уровней агрегации (Unlimited Dimensions and Aggregation Levels) | Настоятельно рекомендуется допущение в каждом серьезном OLAP инструменте как минимум пятнадцати, а лучше двадцати, измерений в аналитической модели. Более того, каждое из этих измерений должно допускать практически неограниченное количество определенных пользователем уровней агрегации по любому направлению консолидации. |
рассмотрел недостатки реляционной модели, в первую очередь указав на невозможность "объединять, просматривать и анализировать данные с точки зрения множественности измерений, то есть самым понятным для корпоративных аналитиков способом", и определил общие требования к системам OLAP, расширяющим функциональность реляционных СУБД и включающим многомерный анализ как одну из своих характеристик.
В 1995 году на основе требований, изложенных Коддом, был сформулирован так называемый тест FASMI (Fast Analysis of Shared Multidimensional Information - быстрый анализ разделяемой многомерной информации), включающий следующие требования к приложениям для многомерного анализа:
· предоставление пользователю результатов анализа за приемлемое время (обычно не более 5 с), пусть даже ценой менее детального анализа;
· возможность осуществления любого логического и статистического анализа, характерного для данного приложения, и его сохранения в доступном для конечного пользователя виде;
· многопользовательский доступ к данным с поддержкой соответствующих механизмов блокировок и средств авторизованного доступа;
· многомерное концептуальное представление данных, включая полную поддержку для иерархий и множественных иерархий (это - ключевое требование OLAP);
· возможность обращаться к любой нужной информации независимо от ее объема и места хранения.
В [49] приведен обзор ряда распространенных программных продуктов анализа данных (см. Табл.25 ) и показано, что ни один из них не удовлетворяет полностью этим требованиям. Одно из основных требований - прямую, без посредников-программистов работу с такими системами конечных пользователей, ни один из упомянутых продуктов не обеспечивает.
Таблица 25.
Анализ выполнения требований Кодда для ряда программных продуктов анализа данных
Критерии по E. Codd | Crystal Report | Report Smith | Quick Report | Oracle Discoverer & Express | Hyperion Wired for OLAP | SAS | CalliGraph |
1 | Нет | Нет | Нет | Да | Да | Да | Да |
2 | Нет | Нет | Нет | Да | Да | Да | Да |
3 | Нет | Нет | Нет | Да | Да | Да | Да |
4 | Нет | Нет | Нет | Нет данных | Нет данных | Да | Да |
5 | Да | Да | Да | Да | Да | Да | Да |
6 | Нет | Нет | Нет | Да | Да | Да | Да |
7 | Нет | Нет | Нет | Нет данных | Нет данных | Да | Да |
8 | Нет | Нет | Нет | Да | Да | Да | Да |
9 | Нет | Нет | Нет | Да | Да | Да | Да |
10 | Нет | Нет | Нет | Нет | Нет | Нет | Да |
11 | Нет | Нет | Нет | Нет | Нет | Нет | Да |
12 | Нет | Нет | Нет | Нет данных | Нет данных | Да | Да |
В таблице приведены характеристики еще одного генератора документов – CalliGraphv, котрый относится к классу СППР. Помимо вполне естественных в настоящее время атрибутов ("Клиент-Серверная" архитектура, работа с любыми БД через стандартный ODBC, привычный пользовательский интерфейс типа MS Office, деловая графика, интеграция с MS Office и т. д.), CalliGraph полностью удовлетворяет всем 12-ти классификационным требованиям, предъявляемым к OLAP - продуктам. Принципиальное отличие CalliGraph от других указанных в таблице систем состоит в том, что он изначально создавался как средство для конечного пользователя, не обремененного даже минимальными знаниями программирования. В диалоге с генератором, пользователь сам конструирует именно тот отчет, который ему требуется и, что немаловажно, который он способен понять "здесь и сейчас".
В CalliGraph. реализована основная идея OLAP - идея многомерной модели данных, которая полностью совместима с моделью человеческого мышления, многомерного по определению, поэтому и процесс анализа в многомерной модели максимально приближен к реальности человеческого мышления.
В основе OLAP лежит понятие гиперкуба, или многомерного куба данных, в ячейках которого хранятся анализируемые (числовые) данные, например объемы продаж. Измерения представляют собой совокупности значений других данных, скажем названий товаров и названий месяцев года. В простейшем случае двумерного куба (квадрата) мы получаем таблицу, показывающую значения уровней продаж по товарам и месяцам. Дальнейшее усложнение модели данных может идти по нескольким направлениям:
- увеличение числа измерений - данные о продажах не только по месяцам и товарам, но и по регионам. В этом случае куб становится трехмерным; усложнение содержимого ячейки - например нас может интересовать не только уровень продаж, но и, скажем, чистая прибыль или остаток на складе. В этом случае в ячейке будет несколько значений; введение иерархии в пределах одного измерения - общее понятие ВРЕМЯ естественным образом связано с иерархией значений: год состоит из кварталов, квартал из месяцев и т. д.
Речь пока идет не о физической структуре хранения, а лишь о логической модели данных. Другими словами, определяется лишь пользовательский интерфейс модели данных. В рамках этого интерфейса вводятся следующие базовые операции:
- поворот; проекция. При проекции значения в ячейках, лежащих на оси проекции, суммируются по некоторому предопределенному закону; раскрытие (drill-down). Одно из значений измерения заменяется совокупностью значений из следующего уровня иерархии измерения; соответственно заменяются значения в ячейках гиперкуба; свертка (roll-up/drill-up). Операция, обратная раскрытию; сечение (slice-and-dice).
В зависимости от ответа на вопрос, существует ли гиперкуб как отдельная физическая структура или лишь как виртуальная модель данных, различают системы:
· MOLAP (Multidimensional OLAP),
· ROLAP (Relational OLAP).
В MOLAP гиперкуб реализуется как отдельная база данных специальной нереляционной структуры, обеспечивающая максимально эффективный по скорости доступ к данным, но требующая дополнительного ресурса памяти. MOLAP-системы весьма чувствительны к объемам хранимых данных. Поэтому данные из хранилища сначала помещаются в специальную многомерную базу (Multidimensional Data Base, MDB), а затем эффективно обрабатываются OLAP-сервером.
Для систем ROLAP гиперкуб - это лишь пользовательский интерфейс, который эмулируется на обычной реляционной СУБД. В этой структуре можно хранить очень большие объемы данных, однако ее недостаток заключается в низкой и неодинаковой эффективности OLAP - операций. Опыт эксплуатации ROLAP-продуктов показал, что они больше подходят на роль интеллектуальных генераторов отчетов, чем действительно оперативных средств анализа. Они применяются в таких областях, как розничная торговля, телекоммуникации, финансы, где количество данных велико, а высокой эффективности запросов не требуется.
При определении программно-технологической архитектуры Хранилища следует иметь в виду, что система принятия решения, на какие бы визуальные средства представления она ни опиралась, должна предоставить пользователю возможность детализации информации. Руководитель предприятия, получив интегрированное представление данных и/или выводы, сделанные на его основе, может затребовать более детальные сведения, уточняющие источник данных или причины выводов. С точки зрения проектировщика СППР, это означает, что необходимо обеспечить взаимодействие СППР не только с Хранилищем Данных, но и в некоторых случаях с транзакционной системой.
4.3 Витрины Данных
Идея Витрины Данных (Data Mart) возникла, когда стало очевидно, что разработка корпоративного хранилища - долгий и дорогостоящий процесс. Это обусловлено как организационными, так и техническими причинами:
- информационная структура реальной компании, как правило, очень сложна, и руководство зачастую плохо понимает суть происходящих в компании бизнес-процессов; технология принятия решений ориентирована на существующие технические возможности и с трудом поддается изменениям; может возникнуть необходимость в частичном изменении организационной структуры компании; требуются значительные инвестиции до того, как проект начнет окупаться; как правило, требуется значительная модификация существующей технической базы; освоение новых технологий и программных продуктов специалистами компании может потребовать много времени; на этапе разработки бывает трудно наладить взаимодействие между разработчиками и будущими пользователями Хранилища.
В совокупности это приводит к тому, что разработка и внедрение корпоративного хранилища требуют значительных усилий по анализу деятельности компании и переориентации ее на новые технологии. Витрины Данных возникли в результате попыток смягчить трудности разработки и внедрения Хранилищ.
Под Витриной Данных понимается специализированное Хранилище, обслуживающее одно из направлений деятельности компании, например учет запасов или маркетинг. Важно, что происходящие здесь бизнес-процессы, во-первых, относительно изучены и, во-вторых, не столь сложны, как процессы в масштабах всей компании. Количество сотрудников, вовлеченных в конкретную деятельность, также невелико (рекомендуется, чтобы Витрина обслуживала не более 10-15 человек). При этих условиях удается с использованием современных технологий развернуть Витрину подразделения за 3-4 месяца. Необходимо отметить, что успех небольшого проекта (стоимость которого невелика по сравнению со стоимостью разработки корпоративного Хранилища), во-первых, способствует продвижению новой технологии и, во-вторых, приводит к быстрой окупаемости затрат.
Первые же попытки внедрения Витрин Данных оказались настолько успешными, что вокруг новой технологии начался настоящий бум. Предлагалось вообще отказаться от реализации корпоративного Хранилища и заменить его совокупностью Витрин Данных. Однако вскоре выяснилось, что с ростом числа Витрин растет сложность их взаимодействия, поскольку сделать витрины полностью независимыми не удается. Сейчас принята точка зрения, в соответствии с которой разработка корпоративного Хранилища должна идти параллельно с разработкой и внедрением Витрин Данных.
При построении схемы взаимодействия корпоративного Хранилища и Витрин Данных в рамках создания СППР рекомендуется определить некоторую специальную структуру для хранения исторических данных и дополнительно развернуть ряд Витрин, заполняемых данными из этой структуры. Тем самым удается разделить два процесса: накопление исторических данных и их анализ.
4.4 Хранилище Метаданных (Репозитарий)
Принципиальное отличие Системы Поддержки Принятия Решений на основе Хранилищ Данных от обычной информационной системы состоит в обязательном наличии в СППР метаданных. В общем случае метаданные помещаются в централизованно управляемый Репозитарий, в который включается информация о структуре данных Хранилища, структурах данных, импортируемых из различных источников, о самих источниках, методах загрузки и агрегирования данных, сведения о средствах доступа, а также бизнес-правилах оценки и представления информации. Там же содержится информация о структуре бизнес-понятий. Так, например, клиенты могут подразделяться на кредитоспособных и некредитоспособных, на имеющих или не имеющих льготы, они могут быть сгруппированы по возрастному признаку, по местам проживания и т. п. Как следствие, появляются новые бизнес-понятия: ПОСТОЯННЫЙ КЛИЕНТ, ПЕРСПЕКТИВНЫЙ КЛИЕНТ и т. п. Некоторые бизнес-понятия (соответствующие измерениям в Хранилище Данных) образуют иерархии, например ТОВАР может включать ПРОДУКТЫ ПИТАНИЯ и ЛЕКАРСТВЕННЫЕ ПРЕПАРАТЫ, которые, в свою очередь, подразделяются на группы продуктов и лекарств и т. д.
Широко известны Репозитарии, входящие в состав популярных CASE-средств. Все они, однако, решают частные задачи, работая с ограниченным набором метаданных, и предназначены, в основном, для облегчения труда профессионалов - проектировщиков, разработчиков и администраторов информационных систем. Репозитарий метаданных СППР на основе ХД предназначен не только для профессионалов, но и для пользователей, которым он служит в качестве поддержки при формировании запросов. Более того, развитая система управления метаданными должна обеспечивать возможность управления бизнес-понятиями со стороны пользователей, которые могут изменять содержание метаданных и образовывать новые понятия по мере развития бизнеса. Тем самым репозитарий превращается из факультативного инструмента в обязательный компонент СППР и ХД.
Разработка системы управления метаданными включает следующие этапы:
- анализ процессов возникновения, изменения и использования метаданных; проектирование структуры хранения метаданных (например, в составе реляционной базы данных); организация прав доступа к метаданным; блокировка и разрешение конфликтов при совместном использовании метаданных (что очень часто возникает при изменении общих бизнес-понятий в рамках структурного подразделения); разделение метаданных между Витринами Данных; согласование метаданных ХД с Репозиториями CASE-средств, применяемых при проектировании и разработке Хранилищ; реализации пользовательского интерфейса с Репозитарием.
Опыт реализации систем управления метаданными показывает, что основная трудность состоит не в программной реализации, а в определении содержания конкретных метаданных и методики работы с ними, в практическом внедрении Репозитория. Кроме того, если подходить к проектированию итерационно, последовательно переходя от разработки соответствующих бумажных форм и методик к созданию CASE-модели метаданных, от централизованной к распределенной модели, используя в качестве системы для хранения метаданных промышленную реляционную СУБД, можно значительно упростить задачу.
4.5 Интеллектуальный анализ данных
Интеллектуальный анализ данных (ИАД) обычно определяют как метод поддержки принятия решений, основанный на анализе зависимостей между данными. В рамках такой общей формулировки обычный анализ отчетов, построенных по базе данных, также может рассматриваться как разновидность ИАД. Чтобы перейти к рассмотрению более продвинутых технологий ИАД, посмотрим, как можно автоматизировать поиск зависимостей между данными.
Существует два подхода. В первом случае пользователь сам выдвигает гипотезы относительно зависимостей между данными. Фактически традиционные технологии анализа развивали именно этот подход. Действительно, гипотеза приводила к построению отчета, анализ отчета к выдвижению новой гипотезы и т. д. Это справедливо и в том случае, когда пользователь применяет такие развитые средства, как OLAP, поскольку процесс поиска по-прежнему полностью контролируется человеком. Во многих системах ИАД в этом процессе автоматизирована проверка достоверности гипотез, что позволяет оценить вероятность тех или иных зависимостей в базе данных. Типичным примером может служить, такой вывод: вероятность того, что рост продаж продукта А обусловлен ростом продаж продукта В, составляет 0,75.
Второй подход основывается на том, что зависимости между данными ищутся автоматически. Количество продуктов, выполняющих автоматический поиск зависимостей, говорит о растущем интересе производителей и потребителей к системам именно такого типа. Сообщается о резком росте прибылей клиентов за счет верно найденной, заранее неизвестной зависимости. Упоминается пример сети британских универсамов, где ИАД применялся при анализе убытков от хищений товаров в торговых залах. Было обнаружено, что к наибольшим убыткам приводят хищения мелких "сопутствующих" товаров: ручек, батареек и т. п. Простой перенос прилавков с этими товарами ближе к расчетным узлам позволил снизить убытки на 1000%.
Процессы ИАД подразделяются на три большие группы: поиск зависимостей (discovery), прогнозирование (predictive modelling) и анализ аномалий (forensic analysis). Поиск зависимостей состоит в просмотре базы данных с целью автоматического выявления зависимостей. Проблема здесь заключается в отборе действительно важных зависимостей из огромного числа существующих в БД. Прогнозирование предполагает, что пользователь может предъявить системе записи с незаполненными полями и запросить недостающие значения. Система сама анализирует содержимое базы и делает правдоподобное предсказание относительно этих значений. Анализ аномалий - это процесс поиска подозрительных данных, сильно отклоняющихся от устойчивых зависимостей.
В системах ИАД применяется чрезвычайно широкий спектр математических, логических и статистических методов: от анализа деревьев решений (Business Objects) до нейронных сетей (NeoVista). Пока трудно говорить о перспективности или предпочтительности тех или иных методов. Технология ИАД сейчас находится в начале пути, и практического материала для каких-либо рекомендаций или обобщений явно недостаточно.
4.6 Архитектура СППР
Архитектура систем поддержки принятия решений подробно описана в [46]. Как указано в этом материале, на сегодняшний день можно выделить четыре наиболее популярных типа архитектур систем поддержки принятия решений:
1. Функциональная СППР.
2. Независимые витрины данных.
3. Двухуровневое хранилище данных.
4. Трехуровневое хранилище данных.
Функциональная СППР
Функциональная СППР (Рисунок 1) является наиболее простой с архитектурной точки зрения. Такие системы часто встречаются на практике, в особенности в организациях с невысоким уровнем аналитической культуры и недостаточно развитой информационной инфраструктурой.

Рис. 47. Функциональная СППР
Характерной чертой функциональной СППР является то, что анализ осуществляется с использованием данных из оперативных систем.
Преимущества:
- Быстрое внедрение за счет отсутствия этапа перегрузки данных в специализированную систему Минимальные затраты за счет использования одной платформы
Недостатки:
- Единственный источник данных, потенциально сужающий круг вопросов, на которые может ответить система Оперативные системы характеризуются очень низким качеством данных с точки зрения их роли в поддержке принятия стратегических решений. В силу отсутствия этапа очистки данных, данные функциональной СППР, как правило, обладают невысоким качеством Большая нагрузка на оперативную систему. Сложные запросы могут привести к остановке работы оперативной системы, что весьма нежелательно
СППР с использованием независимых витрин данных
Независимые витрины данных (Рисунок 2) часто появляются в организации исторически и встречаются в крупных организациях с большим количеством независимых подразделений, зачастую имеющих свои собственные отделы информационных технологий.
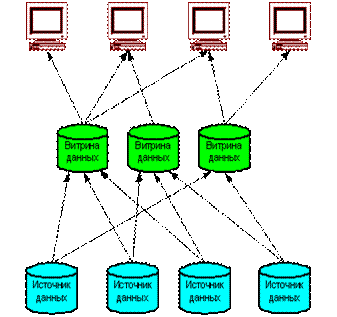
Рис. 48 Независимые витрины данных
Преимущества:
- Витрины данных можно внедрять достаточно быстро Витрины проектируются для ответов на конкретный ряд вопросов Данные в витрине оптимизированы для использования определенными группами пользователей, что облегчает процедуры их наполнения, а также способствует повышению производительности
Недостатки:
- Данные хранятся многократно в различных витринах данных. Это приводит к дублированию данных и, как следствие, к увеличению расходов на хранение и потенциальным проблемам, связанным с необходимостью поддержания непротиворечивости данных Потенциально очень сложный процесс наполнения витрин данных при большом количестве источников данных Данные не консолидируются на уровне предприятия, таким образом, отсутствует единая картина бизнеса
СППР на основе двухуровневого хранилища данных
Двухуровневое хранилище данных (Рисунок 3) строится централизованно для предоставления информации в рамках компании. Для поддержки такой архитектуры необходима выделенная команда профессионалов в области хранилищ данных.
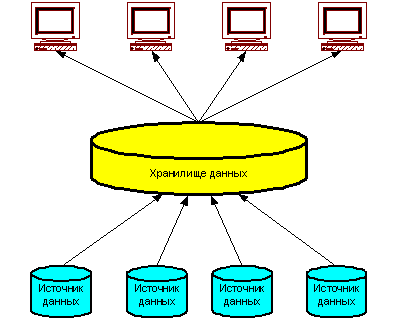
Рис. 49 Двухуровневое хранилище данных
Это означает, что вся организация должна согласовать все определения и процессы преобразования данных.
Преимущества:
- Данные хранятся в единственном экземпляре Минимальные затраты на хранение данных Отсутствуют проблемы, связанные с синхронизацией нескольких копий данных Данные консолидируются на уровне предприятия, что позволяет иметь единую картину бизнеса
Недостатки:
- Данные не структурируются для поддержки потребностей отдельных пользователей или групп пользователей Возможны проблемы с производительностью системы Возможны трудности с разграничением прав пользователей на доступ к данным
СППР на основе трёхуровневого хранилища данных
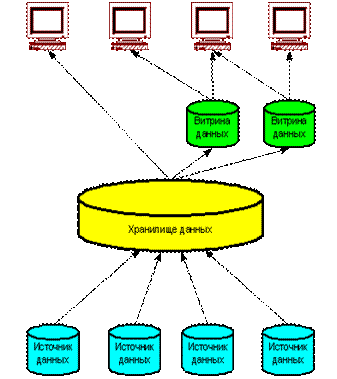
Рис. 50 Трёхуровневое хранилище данных
Хранилище данных представляет собой единый централизованный источник корпоративной информации. Витрины данных представляют подмножества данных из хранилища, организованные для решения задач отдельных подразделений компании. Конечные пользователи имеют возможность доступа к детальным данным хранилища, в случае если данных в витрине недостаточно, а также для получения более полной картины состояния бизнеса.
Преимущества:
- Создание и наполнение витрин данных упрощено, поскольку наполнение происходит из единого стандартизованного надежного источника очищенных нормализованных данных Витрины данных синхронизированы и совместимы с корпоративным представлением. Имеется корпоративная модель данных. Существует возможность сравнительно лёгкого расширения хранилища и добавления новых витрин данных Гарантированная производительность
Недостатки:
- Существует избыточность данных, ведущая к росту требований на хранение данных Требуется согласованность с принятой архитектурой многих областей с потенциально различными требованиями (например, скорость внедрения иногда конкурирует с требованиями следовать архитектурному подходу)
