
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
УДК 681.3:62-192
© О. В. Абрамов, 2013
ТЕХНОЛОГИЯ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛЕНИЙ В ЗАДАЧАХ
РАСЧЕТА И ОБЕСПЕЧЕНИЯ ПАРАМЕТРИЧЕСКОЙ НАДЕЖНОСТИ
В. – д-р техн. наук, зав. отделом «Проблемы надежности и качества» (ИАПУ ДВО РАН), e-mail: *****@
Рассматривается задача оптимального проектирования аналоговых технических устройств и систем с учетом закономерностей случайных вариаций их параметров и требований надежности. Предложены алгоритмы статистического анализа и параметрической оптимизации по стохастическим критериям, основанные на технологии параллельных и распределенных вычислений.
Проблема оптимального параметрического синтеза (ОПС) технических устройств и систем с учетом стохастических закономерностей изменения их параметров и требований надежности связана с необходимостью решения задач высокой вычислительной сложности. Суть ОПС состоит в поиске таких начальных (номинальных) значений параметров элементов системы (внутренних параметров), при которых обеспечивается максимальная вероятность выполнения условий работоспособности в течение заданного времени эксплуатации. При этом предполагается, что структура (топология) проектируемой системы и ее математическая модель известны [1].
Стохастический характер критерия оптимальности, многомерность пространства поиска, необходимость решения задачи глобальной оптимизации заставляют искать пути создания эффективных численных методов решения задач ОПС. Одним из наиболее радикальных путей решения задач высокой вычислительной сложности является распараллеливание процесса поиска решения. Идея создания эффективных параллельных методов многовариантного анализа и поисковой оптимизации, ориентированных на решение задач ОПС по критериям надежности, рассматривается в данной работе.
Программную среду для решения задач ОПС можно представить в виде набора взаимосвязанных программно-алгоритмических модулей.
1. Модуль ввода описания проектируемой системы в вычислительную среду.
2. Модуль преобразования описания системы в математическую модель, связывающую выходные параметры системы с параметрами ее элементов и возмущениями.
3. Модуль детерминированного анализа. Для выбранной структуры (топологии) и заданных значений внутренних параметров xном=(x1ном, ..., xnном) здесь происходит вычисление значений выходных параметров системы y={yj}mj=1, yj=Fj(x1, …, xn ) и проверка выполнения условий работоспособности, которые задаются в техническом задании в виде допустимых пределов изменения выходных параметров.
4. Модуль статистического анализа. Он включает в себя алгоритмические и программные средства генерации случайных процессов изменения внутренних параметров X(t) и вычисления целевой функции (вероятности выполнения условий работоспособности в течение заданного времени эксплуатации) методом статистических испытаний (Монте-Карло).
5. Модуль оптимизации, включающий в себя набор алгоритмических и программных средств поиска номинальных значений параметров элементов системы xном=(x1ном, ..., xnном), доставляющих максимум целевой функции.
Эффективным средством преодоления вычислительной трудоемкости (временных затрат) решения задач оптимального параметрического синтеза, как отмечалось выше, может стать использование современных технологий параллельных и распределенных вычислений.
При создании параллельной (распределенной) программной среды, ориентированной на решение задач оптимального параметрического синтеза необходимо решить, по крайней мере, две основные задачи.
Первая из них заключается в распределении операций используемого алгоритма между процессорами и установлении нового (по сравнению с последовательным алгоритмом) порядка их выполнения. Основная проблема, возникающая при решении этой задачи, состоит в сохранении порядка выполнения информационно-связных операций – выполнении условий сохранения зависимостей алгоритма.
Вторая задача заключается в распределении данных алгоритма между процессорами и установлении схемы обмена данными при выполнении параллельного алгоритма. Основная проблема, возникающая при решении задачи, состоит в необходимости устанавливать в определенный момент времени местоположение требуемого для выполнения операции данного и дополнять вычислительный алгоритм новыми операциями передачи и приема данных. При этом следует учитывать, что реализация коммуникаций в распределенной вычислительной среде (на параллельном компьютере с распределенной памятью) требует значительных временных затрат. Поскольку целью использования распределенной вычислительной среды является уменьшение времени решения задачи параметрического синтеза, то при распараллеливании алгоритма необходимо стремиться к уменьшению коммуникационных затрат на его реализацию.
Один из очевидных подходов к распределению данных и минимизации коммуникационных затрат заключается в разбиении алгоритма на блоки независимых вычислений [2]. В этом случае распределение данных осуществляется в соответствии с распределением операций, которые эти данные используют, поэтому все процессоры вычислительной системы могут работать независимо один от другого, не нуждаясь в обмене данными. Очевидно, такой подход упрощает проблему распределения данных между процессорами и устраняет проблему обмена данными, однако не всегда алгоритм допускает декомпозицию на независимые части.
Другой подход заключается в получении блочных версий алгоритма, т. е. разбиении специальным образом пространства итераций гнезд циклов. Целью такого разбиения является увеличение пакета передаваемых данных и уменьшение частоты коммуникаций. Подход направлен на минимизацию накладных расходов на обмены данными, не затрагивая проблемы размещения массивов данных.
Существует также подход, заключающийся в установлении фиксированного (определенного до начала выполнения программы и не меняющегося в процессе ее выполнения) размещения данных по процессорам вычислительной системы [3].
При программной реализации параллельных алгоритмов представляется целесообразным использование возможностей как современных многопроцессорных вычислительных систем, так и распределенных многомашинных комплексов, связанных локальной сетью. Главным критерием качества распараллеливания вычислений является сокращение общего времени решения задачи. Возможности для распараллеливания вычислений ограничиваются не только числом имеющихся процессоров, но и особенностями вычислительного алгоритма, который может оказаться принципиально последовательным. В задачах ОПС целесообразно использовать модель передачи сообщений и, так называемая, master-slave парадигма параллельного программирования. Один из процессоров назначается главным (master), он производит динамическую балансировку загрузки, рассылает задания остальным подчиненным процессорам (slave), формирует результаты. Распараллеливание базируется на декомпозиции последовательного алгоритма вычислений, а в качестве единицы параллелизма выступает задача однократного расчета модели системы (моделирования системы).
Можно предложить несколько вариантов стратегии ОПС с использованием технологии параллельных вычислений.
В основе первой из стратегий лежит идея создания параллельных методов расчета целевой функции и оптимизации.
Параллельный алгоритм расчета (оценки) параметрической надежности является модификацией метода статистических испытаний (Монте-Карло). С помощью специальной подпрограммы-генератора случайных реализаций моделируются реализации случайного процесса изменения параметров исследуемой технической системы. Число моделируемых реализаций N определяется необходимой точностью оценки вероятности безотказной работы. Общее число реализаций делится на k пакетов, равное числу процессоров (клиентов) вычислительной сети, которые рассылаются по узлам вычислительной сети. Для каждой из реализаций производится проверка выполнения условий работоспособности в течение заданного времени T.
Оценка вероятности безотказной работы рассчитывается по формуле:
 ,
,
где nxj – количество "хороших" реализаций в j-том пакете (для которых условия работоспособности выполняются), N – требуемое число испытаний.
Использование параллельных вычислений в методе статистических испытаний (метод Монте-Карло) является вполне логичным, поскольку идея параллелизма – повторения некоторого типового процесса с различными наборами данных – заложена в самой структуре метода. Интуитивно понятно, что использование k независимых процессоров и распределение между ними независимых испытаний, уменьшит трудоемкость статистического моделирования почти в k раз, поскольку затраты на заключительное суммирование и осреднение результатов практически несущественны.
Простейшим из прямых методов поисковой оптимизации, обладающих свойством потенциального параллелелизма, является метод сканирования. Этот метод заключается в последовательном переборе значений номиналов параметров из множества допустимых, при этом запоминается наибольшее значение целевой функции и вектор номиналов, приведший к этому значению. В соответствии с алгоритмом это состояние заменяется другим только в случае, если новое значение целевой функции окажется больше, чем значение, хранимое в памяти. Особенность и преимущество метода сканирования заключается в независимости поиска от вида и характера целевой функции, а также в том, что этот метод всегда позволяет найти глобальный экстремум.
В простейшем случае решение задачи сводится к полному перебору элементов множества возможных значений номиналов внутренних параметров, для каждого из которых осуществляется расчет соответствующей целевой функции. Учитывая цикличность процедуры вычисления целевой функции, несложно применить параллелизм по данным.
Другая возможная стратегия ОПС основана на построении области допустимых значений внутренних параметров (области работоспособности) Dx.
Привлекательность этой стратегии в определенной мере связана с возможностью декомпозиции общей задачи ОПС на две подзадачи.
Первая из них состоит в построении, анализе и аппроксимации области Dx. Это задача высокой вычислительной трудоемкости, поскольку ее решение связано с необходимостью многократного вычисления значений выходных параметров системы (обращения к модулю детерминированного анализа).
Вторая подзадача включает вычисление целевой функции и нахождение оптимальных значений номиналов параметров. Получение решений в этом случае не связано с необходимостью обращения к модулю детерминированного анализа, что значительно уменьшает трудоемкость параметрического синтеза.
Таким образом, при использовании стратегии ОПС, основанной на построении областей работоспособности, решение поставленной задачи осуществляется в два этап, первый из которых можно считать подготовительным (построение области Dx), а второй – основным. Эффективность каждого из этапов обеспечивается на основе использования технологии параллельных или распределенных вычислений [4].
Работа выполнена при финансовой поддержке гранта ДВО РАН 12-I-ОЭММПУ-01 в рамках Программы фундаментальных исследований Отделения энергетики, машиностроения, механики и процессов управления РАН № 14 «Анализ и оптимизация функционирования систем многоуровневого, интеллектуального и децентрализованного управления в условиях неопределенности».
Библиографические ссылки
1. В. Методы и алгоритмы параметрического синтеза стохастических систем. //Проблемы управления, № 4, 2006. С. 3-8.
2. Shang W., Fortes J. A. Independent partitioning of algorithms with uniform dependencies // IEEE Trans. on Computers, 1992, 41, № 2. P. 190-206.
3. В., А. Согласованное получение конвейерного параллелизма и распределение операций и данных между процессорами //Программирование, 32, № 3, 2006. С. 54-65.
4. В., , Б., В. Параллельные алгоритмы построения области работоспособности. //Информатика и системы управления, № 2, 2004. С. 121-133.
УДК 519.711.3
© А. А. Анищенко, 2013
ОБ ЭФФЕКТИВНОСТИ ВВЕДЕНИЯ
ДОПОЛНИТЕЛЬНЫХ УРОВНЕЙ ОБСЛУЖИВАНИЯ
В ЛОГИЧЕСКИХ ИЕРАРХИЧЕСКИХ СТРУКТУРАХ
А. – соиск. каф. «Теории вероятности и математической статистики» (РУДН), e-mail: *****@***ru
Проводится сравнение средних времен обслуживания заявки в одноуровневой логической иерархической структуре и в аналогичной структуре с дополнительным уровнем обслуживающих приборов, сжимающих исходный поток. В результате сравнения приводится неравенство, задающее множество коэффициентов сжатия для дополнительных приборов, позволяющих уменьшить среднее время обслуживания одной заявки. Входящий поток Пуассоновский, дисциплина обслуживания экспоненциальная.
Логическая иерархическая структура – очень распространённая форма организации различных систем (системы хранения и обработки информации, системы управления, распределённые системы и др.) Быстродействие таких систем всегда является одним из важнейших факторов эффективной работы. В данной работе предлагается анализ метода повышения скорости работы таких систем путём добавления в структуру дополнительного уровня обслуживающих устройств, сжимающих входящий поток данных.
Структура 1.
Рассматривается некоторая логическая иерархическая структура (ЛИС), которую можно представить в виде ориентированного дерева 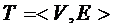 ,
, ![]() , состоящего только из центральной вершины
, состоящего только из центральной вершины ![]() и
и ![]() листьев
листьев ![]() , являющихся её сыновьями. Дуги дерева ориентированы к центру (рис.1).
, являющихся её сыновьями. Дуги дерева ориентированы к центру (рис.1).

Рис. 1. ЛИС единичной высоты
В данной структуре предполагается, что от листьев к корневой вершине идут потоки информации (заявок) с интенсивностями 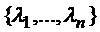 соответственно и
соответственно и 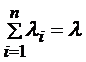 . Все эти потоки обслуживаются в корневой вершине с интенсивностью
. Все эти потоки обслуживаются в корневой вершине с интенсивностью ![]() .
.
Поток информации от листьев к корню Пуассоновский с интенсивностью ![]() , и каждый лист фактически представляет собой множество источников информации.
, и каждый лист фактически представляет собой множество источников информации.
Обслуживание в корневой вершине (приборе) также Пуассоновское с интенсивностью ![]() .
.
Тогда описанную ЛИС можно считать системой массового обслуживания ![]() . Необходимым и достаточным условием существования стационарного состояния такой системы является условие Карлина и Мак Грегора
. Необходимым и достаточным условием существования стационарного состояния такой системы является условие Карлина и Мак Грегора 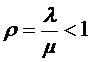 [1].
[1].
Стационарное среднее время пребывания заявки в системе ![]() складывается из среднего времени ожидания начала обслуживания
складывается из среднего времени ожидания начала обслуживания ![]() и среднего времени обслуживания на приборе
и среднего времени обслуживания на приборе ![]() :
: 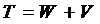 .
.
Для СМО ![]()
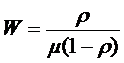 ,
, 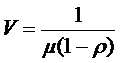 [1].
[1].
Тогда
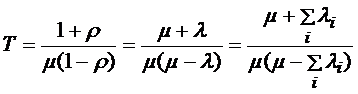 (1)
(1)
Структура 2.
Для сравнения рассматривается ЛИС высоты 2, такая что «на пути» от каждого из листьев к корневой вершине в структуре 1. находится ещё по одному узлу (промежуточному прибору, ПП). Роль промежуточных приборов следующая: пусть от ![]() -го листа к
-го листа к ![]() -му ПП идёт поток заявок с интенсивностью
-му ПП идёт поток заявок с интенсивностью ![]() , тогда этот поток заявок обрабатывается на ПП (по Пуассоновскому закону) с некоторой интенсивностью
, тогда этот поток заявок обрабатывается на ПП (по Пуассоновскому закону) с некоторой интенсивностью![]() , и из ПП выходит «сжатый поток»
, и из ПП выходит «сжатый поток» 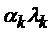 ,
, ![]() . Здесь
. Здесь ![]() – коэффициент сжатия
– коэффициент сжатия ![]() -го ПП (рис.2).
-го ПП (рис.2).
Чтобы вычислить стационарное среднее время нахождения заявки в такой системе ![]() , необходимо разделить её условно на 2 части: I часть – листья и их отцы (ПП), II часть – ПП и центральная вершина.
, необходимо разделить её условно на 2 части: I часть – листья и их отцы (ПП), II часть – ПП и центральная вершина.
В такой системе среднее время обслуживания одной заявки ![]() в стационарном режиме будет состоять из среднего времени нахождения заявки в I части
в стационарном режиме будет состоять из среднего времени нахождения заявки в I части ![]() и среднего времени во II части
и среднего времени во II части ![]() . В свою очередь
. В свою очередь ![]() складывается из среднего времени ожидания начала обслуживания на ПП
складывается из среднего времени ожидания начала обслуживания на ПП ![]() и среднего времени обслуживания на ПП
и среднего времени обслуживания на ПП ![]() , а
, а ![]() – из среднего времени ожидания начала обслуживания на приборе
– из среднего времени ожидания начала обслуживания на приборе ![]() и среднего времени обслуживания на приборе
и среднего времени обслуживания на приборе ![]() .
.
![]()
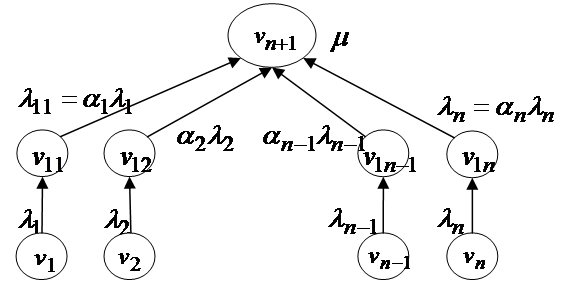

Рис. 2. ЛИС высоты 2
Аналогично системе 1. необходимыми и достаточными условиями существования стационарного режима в системе 2. будет
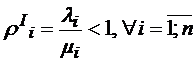 и
и 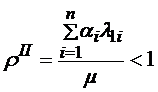 .
.
Тогда
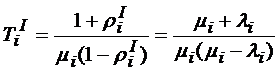 ,
, 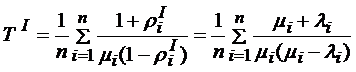 .
.
и 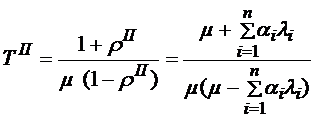 .
.
Так как ![]() , то
, то
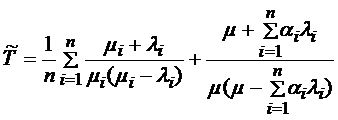 . (2)
. (2)
Таким образом, сравнивая (1) и (2), можно вычислить какая система позволяет обслужить заявку в среднем за меньшее время (в стационарном состоянии).
Кроме того, можно вычислить диапазон для 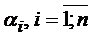 такой, чтобы добавление дополнительных промежуточных приборов уменьшило среднее время обслуживания заявки в системе. Для этого необходимо вычислить
такой, чтобы добавление дополнительных промежуточных приборов уменьшило среднее время обслуживания заявки в системе. Для этого необходимо вычислить ![]() из неравенства:
из неравенства:
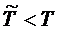 (3)
(3)
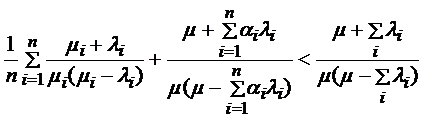 ;
;
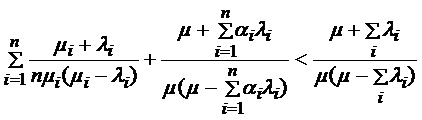 ;
;
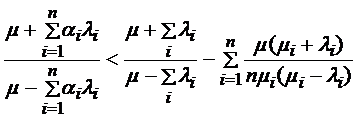 .
.
Для упрощения расчётов можно ввести обозначение 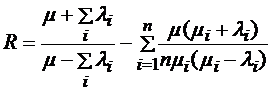 . Так как логично, что
. Так как логично, что 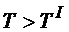 (из условия неравенства (3)), то
(из условия неравенства (3)), то 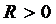 .
.
Тогда 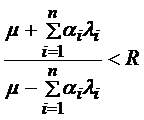 ,
, 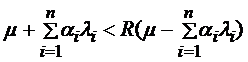 , (
, (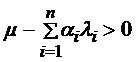 )
)
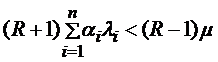
Отсюда
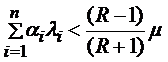 (4)
(4)
Из формулы (4) можно, например, графически получить множество значений для ![]() , при которых использование ПП является эффективным с точки зрения времени обслуживания, и структура системы, изображенная на рис.2 более эффективна по времени, чем структура системы 1.
, при которых использование ПП является эффективным с точки зрения времени обслуживания, и структура системы, изображенная на рис.2 более эффективна по времени, чем структура системы 1.
Кроме того, вводя различные зависимости (например, зависимость ![]() от
от 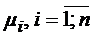 или зависимость от стоимостей промежуточных приборов), можно выбрать значения коэффициентов сжатия входящего потока для ПП , оптимальные в смысле заданных зависимостей.
или зависимость от стоимостей промежуточных приборов), можно выбрать значения коэффициентов сжатия входящего потока для ПП , оптимальные в смысле заданных зависимостей.
Библиографические ссылки
1. , Теория массового обслуживания: Учебник – М. Изд-во РУДН, 1995г. – 529 с.
УДК 681.5:519.248
© М. Ф. Аноп, Я. В. Катуева, 2013
ПАРАЛЛЕЛЬНЫЕ АЛГОРИТМЫ ОПТИМИЗАЦИИ НАДЕЖНОСТИ ПО ПОСТЕПЕННЫМ ОТКАЗАМ
ДЛЯ ДИСКРЕТНОГО МНОЖЕСТВА НОМИНАЛОВ
Ф. – асп. (ИАПУ ДВО РАН), e-mail: *****@; В. – канд. техн. наук, ст. науч. сотр. (ИАПУ ДВО РАН), e-mail: *****@
Рассматривается задача параметрического синтеза аналоговых систем и устройств по критерию надежности по постепенным отказам для дискретного множества номиналов. Предлагаются различные алгоритмы перебора множества номиналов с использованием параллельных вычислений.
В общем виде задача оптимального параметрического синтеза технических устройств и систем с учетом деградации параметров и требований надежности состоит в поиске таких номинальных значений параметров элементов системы, при которых обеспечивается максимальная вероятность выполнения условий работоспособности в течение заданного времени эксплуатации. При этом предполагается, что структура (топология) проектируемой системы и ее математическая модель известны [1].
При проектировании сложной аналоговой радиоэлектронной аппаратуры функции, описывающие проектируемую систему, задаются при помощи имитационной модели типа «чёрного ящика» с использованием программных пакетов моделирования электрических цепей. Это обстоятельство не позволяет получить оптимальное решение с помощью классических методов дифференциального и вариационного исчисления. Для решения задачи оптимизации надежности по постепенным отказам приходится использовать поисковые методы.
Номиналы промышленно выпускаемых радиодеталей (сопротивление резисторов, ёмкость конденсаторов, индуктивность небольших катушек индуктивности) не являются произвольными. Это связано с тем, что номиналы параметров большинства типовых электро-радиоэлементов (резисторов, конденсаторов, катушек индуктивности, операционных усилителей и др.) регламентированы техническими условиями или стандартами. Поэтому при разработке типовой аппаратуры массового потребления, номинальные значения параметров схемных элементов должны принадлежать ряду стандартных значений, регламентированных техническими условиями или ГОСТами. В этом случае предпочтительнее искать оптимальный вектор номиналов параметров на дискретном множестве номиналов, соответствующих стандартным значениям.
Поиск решения в этом случае сводится к полному перебору элементов множества возможных значений номиналов внутренних параметров, в каждой точке которого необходимо найти значение целевой функции. Уменьшение времени решения задачи для дискретного множества номиналов может быть достигнуто за счет распараллеливания алгоритма поиска экстремума и исключения из множества поиска номиналов, заведомо не содержащих оптимальных решений.
Пусть процесс решения можно осуществить с использованием k процессов. Множество всех возможных значений номиналов параметров разбивается на непересекающиеся подмножества, при этом каждому j-му процессу назначается своё подмножество исходных данных. Таким образом, каждый j-й процесс осуществляет расчет целевой функции для всех элементов соответствующего подмножества и находит оптимальные векторы номиналов параметров для своей подобласти. Результаты передаются главному процессу, который производит выбор оптимального вектора номиналов по всей области поиска.
Особенности вычисления целевой функции с использованием методов статистических испытаний и критических сечений [1], а также отсутствие необходимости ее вычисления для номиналов, находящихся вне области работоспособности, могут приводить к серьезной разбалансировке параллельного вычислительного процесса. Поэтому предлагается искать решение задачи оптимального параметрического синтеза не на всем множестве возможных номиналов параметров, а только для тех его представителей, в которых выполняются условия работоспособности.
Для более эффективного использования параллельных вычислительных мощностей предлагается разбиение множества номиналов на большое количество небольших блоков так, что каждый вычислительный процесс по факту завершения работы с одним блоком запрашивает у главного процесса следующий из списка доступных.
В докладе приводятся сравнительные характеристики предложенных параллельных алгоритмов.
Работа выполнена при поддержке гранта ДВО РАН -В-03-025.
Библиографические ссылки
1. В. Параметрический синтез стохастических систем с учетом требований надежности. – М.: Наука. 1992.
УДК 004.383.3:621.376.9 + 613.614:613.693
© , Н. Э. Косых, , 2013
применение принципов облачных вычислений
при создании специализированной телемедицинской сети для анализа медицинских изображений
– канд физ-мат. наук, ст. науч. сотр. лаб. мед. информатики (ВЦ ДВО РАН), e-mail: *****@***ru; Э. – д-р мед. наук, гл. науч. сотр. лаб. мед. информатики (ВЦ ДВО РАН), проф., завкафедрой онкологии (ДВГМУ), e-mail: kosyh. *****@***ru; В. – асп. (ВЦ ДВО РАН), e-mail: *****@***com; З.– канд тех. наук, зав. лаб. мед. информатики (ВЦ ДВО РАН), e-mail: savin. *****@***ru
Изложены принципы организации облачных вычислений в задачах автоматизированной компьютерной диагностики по данным сцинтиграфии, основанной на принципах распознавания образов и обладающая функциями группового экспертного анализа медицинских изображений.
На рубеже тысячелетий произошел стремительный рывок в разработке средств компьютерного моделирования для задач фундаментальной и прикладной биомедицины. Национальный институт здоровья (NIH) США способствует финансированию экспериментов, консолидированные объемы данных которых лежат в пределах от сотен терабайт до десятков петабайт [11]. Исследования в области биоинформатики, геномики, протеомики и математической биологии требуют интенсивных вычислений более сотен петафлоп/сек [9]. Например, вычисления, необходимые в задачах генной инженерии только для одного гена, требуют приблизительно 800 персональных компьютеров на протяжении года [10]. По данным Oxford Said Business School, еще в 2010 г. объем всей Интернет-информации составлял уже более 11 тыс. петабайт [5]. В последнее десятилетие прошлого века получила все большее распространение идеология «грид-вычислений» (grid computing), которая представляет собой выделение вычислительных ресурсов и ресурсов хранения из общего множества автономных систем, как правило, для фундаментальных научных работ и ресурсоемких научных приложений [8]. Наиболее известной в сфере биомедицины является World Community Grid, поддерживающая исследования, связанные с генетикой человека, а также с различными тяжёлыми заболеваниями [10].
В России создание и внедрение медицинских информационных систем (МИС) осуществляют различные ведомства, последнее время координацию разработок ведет Ассоциация Развития Медицинских Информационных Технологий (АРМИТ) [7]. МИС можно разделить по среде, в которой они работают, т. е. по назначению и функциональному наполнению, и по технологии, на которой они построены. По назначению МИС можно разделить на ИС, ориентированные на работу в амбулаторно-поликлинической сети; ИС, ориентированные на работу в стоматологических клиниках; ИС, ориентированные на работу в стационарах [9]. Третий раздел этой классификации включает в себя обширный перечень разнородных систем, куда входят как специфические программы работы с оборудованием, например, сложным УЗИ-сканером, томографом и т. п., так и программы учета и контроля работы отделений стационара. По применяемой технологии МИС можно разделить также на три группы: а) Файл-серверные системы; б) клиент-серверные системы; в) системы, ориентированные на работу в WEB.
Файл-серверные системы – это простейшая и наименее масштабируемая технология реализации программных систем. Основное отличие ее заключается в том, что данные, хранимые и обрабатываемые такой системой, хранятся в виде файлов на локальном компьютере или файлом сервере локальной сети, причем программа получает доступ к этим файлам непосредственно. Это приводит к тому, что для нормальной работы программы требуется полный доступ к файлам с информацией, сложно и ненадежно организована совместная одновременная работа пользователей с различных компьютеров, безопасность и разделение доступа к данным фактически отсутствуют, надежность и отказоустойчивость такой системы низка. Несмотря на описанные недостатки, например, на Дальнем Востоке России по-прежнему в большинстве ЛПУ работают подобные системы [4]. Это связано с тем, что такие системы были созданы достаточно давно, когда применение более совершенных технологий было ограничено как квалификацией разработчиков таких систем, так и объемами бюджетов ЛПУ на информационные технологии и, как следствие, мощностью компьютерного парка. Клиент-серверные системы используют более совершенную технологию хранения данных. В этой архитектуре хранение данных осуществляется в специальной программе – системе управления базой данных (СУБД). Примерами таких систем может быть, например, СУБД Oracle Database, Microsoft SQL Server, IBM DB2 UDB, MySQL, PostgreDB [3,5]. В такой архитектуре становится возможным надежно ограничить доступ к данным у различных пользователей, защитить данных от порчи и кражи, организовать надежную многопользовательскую работу, до максимума повысить живучесть и отказоустойчивость системы в целом. Такая МИС может послужить ядром для создания базы телемедицины или единого хранилища данных в масштабах населенного пункта. Системы, ориентированные на работу в WEB, т. е. такие, где пользователь получает доступ к функционалу системы через web-браузер, например Internet Explorer, Opera, Mozilla FireFox и т. п. Неоценимое преимущество этих систем – предоставление рабочего места любому авторизованному пользователю из любой точки. Особенно эффективными такие системы становятся при встраивании в единый информационный портал учреждения, либо же могут послужить ядром для создания такого портала [4]. Описание эффективности портальных систем не входит в рамки этой статьи, хотя мы считаем, что перспективы и преимущества портальных решений недооценены в медицинской информатике [9].
Все современные МИС являются сугубо клиническими и не предназначены для широкого пользователя информационных медицинских услуг. Наиболее адекватной идеологии пользовательской е-медицины оказалась концепция облачных вычислений (cloud computing) [6] как дальнейшая эволюция того же принципа объединения базовых ресурсов для предоставления доступа к web-сервисам, приложениям и ресурсам системы хранения.
Несмотря на колоссальный интерес к концепции cloud computing (СС), в отрасли до сих пор не существует общепринятых стандартов и методов обеспечения гарантированного качества обслуживания. Перспективы вычислений «в сетевом облаке» (СС) вызывает большой интерес во всем мире: новая концепция позволяет предоставлять сервисы по запросу, что способствует снижению расходов. Кроме того, такой подход позволяет снизить сложность информационных систем, а также повысить их масштабируемость и доступность [8]. Новая модель предоставляет поставщикам управляемых услуг широкие и увлекательные возможности. Однако в данной области до сих пор нет устоявшейся терминологии, а модели предоставления услуг в процессе своего распространения продолжают изменяться. Многие потенциальные клиенты не знают, нужны ли им новые услуги, а поставщики услуг не имеют представления, как лучше интегрировать «облачную» архитектуру и как лучше строить ее маркетинг [3,9]. Безопасность, качество услуг, высокая доступность, совместимость, мобильность сервисов и некоторые другие характеристики сетей считаются критически важными для успешного предоставления услуг СС.
С тех пор, как была создана сеть общедоступного Интернета, в мире появилось множество сетевых концепций, разработанных для корпоративных заказчиков и индивидуальных пользователей. В последние годы все шире распространяется концепция СС, в соответствии с которой сетевые и вычислительные ресурсы, а также ресурсы системы хранения должны предоставляться каждому человеку по запросу, примерно как электричество. Подход СС должен демократизировать доступ к ресурсам и давать пользователям возможность эффективно приобретать столько услуг, сколько им необходимо (в рамках доступного бюджета). Стали говорить о превращении сети в «четвертую коммунальную службу» в дополнение к водопроводу, электричеству и телефонной связи [6]. Концепция СС становится все более популярной, поскольку позволяет снизить совокупную стоимость владения, обладает высокой масштабируемостью, обеспечивает получение заказчиком конкурентных преимуществ, сокращает сложность сетевых услуг для заказчиков и предоставляет быстрый и простой доступ к услугам, несмотря на отсутствие устоявшейся инфраструктуры и стандартов. Многие услуги уже сегодня предоставляются через «сетевое облако», дополняющее инфраструктуру оператора и его заказчиков [10, 11].

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
