
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
А. А. ДАВЫДОВ, С. В. СИНИЦЫН
Московский инженерно-физический институт (государственный университет)
ВЕРИФИКАЦИЯ ИЗМЕНЯЕМЫХ И РАСШИРЯЕМЫХ СИСТЕМ
Рассмотрены проблемы верификации систем, развиваемых в рамках итерационного жизненного цикла, в том числе распределенных систем, расширяемых в процессе эксплуатации. Дается описание подхода к определению подмножества компонент системы, подвергаемых повторной верификации, достаточного для оценки надежности системы в целом, и прогноза сложности работ по ее верификации.
Современные программные комплексы обычно развиваются в рамках итерационного жизненного цикла. Регулярное изменение внешних условий и изменение потребностей пользователя приводят к изменениям требований к системам. Реализация новых требований вызывает необходимость регулярно верифицировать внесенные изменения, и проверять работоспособность неизмененных его частей. Для решения подобных задач используется подход регрессионного анализа [1], когда проверяется лишь новый функционал, добавленный или измененный на очередной итерации, и часть старых компонентов, подверженных влиянию внесенных изменений.
При разработке высоко критичного программного обеспечения, корректность регрессионного анализа особенно актуальна. Требования к верификации подобных систем регламентированы отраслевыми стандартами (например, DO-178B [2]). Повторное тестирование всей системы, согласно требованиям этих стандартов, длительная и дорогостоящая процедура, но цена ошибки в случае выбора слишком малой ее части может оказаться значительно больше.
В условиях промышленной разработки проекта значительное число создаваемых документов, порождаемых в процессе разработки, контролируются процессом конфигурационного управления [3]. Для регрессионного анализа доступны документы требований и исходные коды от всех итераций, и наборы тестов от всех предыдущих итераций. В случае развитого конфигурационного управления присутствуют документы, описывающие каждое вносимое изменение, позволяющие определить версии артефактов до и после внесения каждого изменения. При этом обеспечивается трассируемость между всеми вышеперечисленными артефактами.
Таким образом, можно представить процесс регрессионного анализа изменения следующим образом:
− определение измененных артефактов;
− определение тестов, покрывающих эти артефакты;
− выявление явно не измененных артефактов, но связанных с измененными, так что поведение системы в части, описываемой этими документами, могло измениться;
− регрессионный анализ выявленных артефактов, в том числе выявление артефактов, связанных уже с ними.
Первые два пункта, очевидно, решаются сравнением версий и анализом трассировки. Последние два представляют проблему. В общем случае, все компоненты системы так или иначе связаны. То есть можно рассматривать множество артефактов как некоторую сеть, в которой замыкание некоторого подмножества вершин на основе отношения трассировок или иной другой информации (например, дерева вызовов процедур или диаграммы классов) приведет к выделению всей сети целиком. Поэтому, окончательное решение в определении, какие компоненты подвергаются влиянию внесенных изменений, требующему повторной верификации, остается за человеком, выполняющим анализ.
Пусть Tn+1 есть некоторое множество артефактов проекта, полученное по итогам очередной итерации из Tn – множество артефактов полученных в предыдущей итерации. Здесь под артефактом подразумевается не обязательно элемент конфигурационного управления, а вполне возможно более мелкие структурные элементы, которые могут быть идентифицированы. Пусть также DT – множество изменений (измененных артефактов) от Tn к Tn+1 и Pn – множество тестовых процедур для исходной версии. Анализу подвергается каждый артефакт tiÎDT. При этом для каждого измененного элемента определяется те процедуры pijÎPn, работа которых зависит от него. То есть, такие процедуры, в работе которых используются или проверяются параметры системы, определяемые измененными артефактами.
Каждая выявленная процедура подвергается дополнительному анализу с целью определить, соответствует ли она новой системе, и если не соответствует, то добавляется во множество процедур, которые необходимо обновить. Кроме этого, во множество процедур, вовлекаемых в регрессионное тестирование, добавляются тесты, которые необходимо просто выполнить для проверки DT. После этого определяются связные артефакты tijÎ(TnÈTn+1), то есть элементы системы, функционирование которых зависит от результата измененного.
Для каждого выявленного элемента проводят аналогичный анализ тестовых процедур и анализ связных с ним элементов. Если анализируемое изменение не влияет на результат работы данного артефакта, то связные с ним разделы далее не анализируются. Общий вид дерева анализа артефактов проекта представлен на рис. 1.
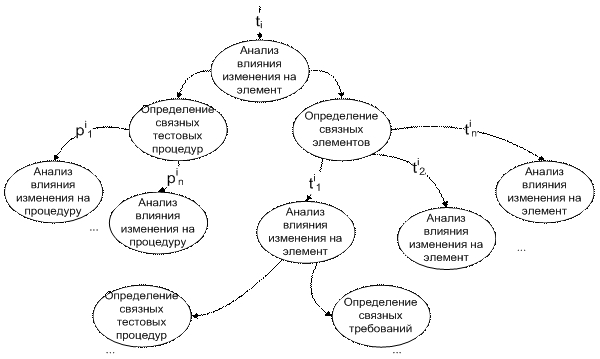
Рис. 1. Последовательность действий при анализе изменения требования
Допустим, что при проведении анализа, имеется некоторое количество достоверных результатов, полученных при анализе на предыдущих итерациях. Если предположить, что после внесения изменений на данной итерации степень взаимного влияния компонент изменилась незначительно, то, используя старые результаты, можно попробовать спрогнозировать глубину вышеописанного процесса анализа влияния изменений.
Из практики известно, что область, вовлекаемая в повторную верификацию по текущим изменениям, обычно не меньше областей вовлеченных ранее по итогам анализа меньших изменений и не больше областей вовлеченных ранее по итогам больших изменений. Для формализации этого предположения, введем некоторые обозначения. Пусть артефакты проекта образуют некоторую сеть G в общем случае как с направленными так и не направленными связями. То есть:
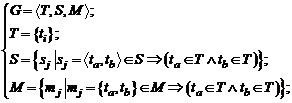 (1)
(1)
где T – множество артефактов проекта, введенное выше; S – дуги, отображающие потоки данных между элементами; M – ребра отображающие ссылки между элементами.
Пусть Ga и Gb – сети вида (1), то есть ![]() и
и 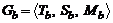 . Тогда определим операции над ними:
. Тогда определим операции над ними:
![]() , (2)
, (2)
![]() . (3)
. (3)
Пусть x – некоторый результат анализа, то есть известны модель данных проекта, актуальная на момент анализа G, набор анализируемых изменений DT, а также выявленная область влияния этих изменений Gres (подсеть G):
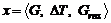 . (4)
. (4)
Тогда обозначим соответствующие проекции x как G(x), DT(x) и Gres(x), а множество всех доступных результатов анализа по итогам предыдущих итераций как X = {x}.
С точки зрения предложенной эвристики, для прогноза распространения влияния некоторых изменений DT, интерес представляют два подмножества X, результаты анализов изменений включающих анализируемые и включаемые в них:
![]() (5)
(5)
![]() (6)
(6)
Для каждого элемента модели G актуальных данных проекта введем параметр α, равный количеству попаданий под влияние меньших изменений. Для вычисления этого параметра необходимо подсчитать, для скольких x Î Xinc элемент включается в подсеть G Ç Gres(x). И параметр β, равный количеству непопаданий под влияние больших изменений. То есть, для скольких x Î Xexc элемент не включается в подсеть G Ç Gres(x).
На основе этих параметров можно ввести частоты включения и невключения в область влияния, что позволит получить величины, не зависящие от мощности множества X, и в дальнейшем оперировать ими:
− частота включения в область влияния:
![]() , (7)
, (7)
− частота невключения в область влияния:
![]() . (8)
. (8)
С помощью этих частот можно сформулировать вышеописанное предположение следующим образом: степень влияния изменений DT на произвольный элемент модели G уменьшается при уменьшении ninc или увеличении nexc, посчитанных для этого элемента. Для любого проекта с учетом конкретной интерпретации элементов модели G и статистики накопленной в проекте можно попробовать вычислить пороговые значения ninc и nexc, с их помощью оценить снизу и сверху область влияния анализируемого изменения.
Кроме этого, область анализа естественным образом ограничивается достижимостью узлов сети G, то есть для анализа представляет интерес только некоторая подсеть сети G, элементы которой достижимы хотя бы из одного из элемента множества DT.
При апробации идеи в реальном проекте разработки бортовой системы, для построения модели рассматривались следующие элементы и связи между ними:
− тестовые процедуры (скрипты) − инструкции по исполнению набора тестовых примеров и оценке результатов;
− параграфы требований − части требований, описание некоторой функциональности, которую целесообразно рассматривать обособлено.
− трассируемость процедуры на параграф: наличие в скрипте идентификатора параграфа;
− трассируемость процедуры на выход параграфа: использование в скрипте параметра, описанного в соответствующем параграфе.
Рассмотренные выше элементы были объединены в сеть G', аналог модели (1):
![]() , (9)
, (9)
где R – множество параграфов требований; P – множество тестовых скриптов; S – множество именованных дуг между вершинами типа R, отображающих потоки данных между разделами требований; O – множество именованных дуг от вершин типа R к вершинам типа P, отображающих трассировку скриптов на выходные данные параграфов; M – множество ребер между вершинами типа R, отображающих ссылки меду требованиями; T – множество дуг от вершин типа R к вершинам типа P, отображающих трассировку скриптов на параграфы.
Дополнительный анализ привел к необходимости изменить эту модель. С целью уменьшения количества одноименных дуг, и для решения проблемы отображения на модели входных или чисто параметров системы был введен новый тип вершин, отображающий параметры, а именованные дуги заменены тремя типами неименованных:
![]() , (10)
, (10)
где R '= R; I ' – множество вершин нового типа, определяемое следующим образом:
![]() ;
;
P' = P – множество тестовых скриптов; S1' – множество новых дуг определяемое как:
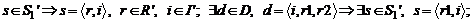
S2' – множество новых дуг определяемое как:
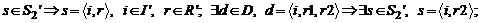
S3' – множество новых дуг определяемое как:
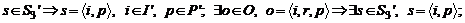
M' = M; T' = T.
Качество оформления проектной документации в проекте, на котором происходил эксперимент, позволило полностью автоматизировать процесс извлечения необходимых данных. В общем случае, при разработке модели конкретного проекта необходимо учитывать качество оформления имеющейся документации. Для проектов на ранних стадиях жизненного цикла возможно соответствующим образом задавать требования на оформление документации.
Вышеизложенный подход реализован в инструментальной системе, которая позволяет строить модель G'' исходной и конечной версий анализируемого проекта и локализовать изменения в требованиях. Дополнительно система позволяет сохранять результаты регрессионного анализа и производить на их основе расчет частот ninc и nexc. Эти значения используются при принятии решения по поводу каждого отдельного элемента модели.
Кроме этого, в системе реализован модуль поддержки планирования трудоемкости работ по верификации. Система осуществляет расчет общей трудоемкости работ на основе результатов регрессионного анализа всех изменений в новой версии проекта. В расчете участвуют как PERT-оценки [4], выставленные инженерами каждой тестовой процедуре при анализе, так и статистика достоверности оценок, выставляемых каждым участником проекта. Реализована возможность автоматического распределения работ между участниками проекта с целью минимизации PERT-ожидания с учетом ограничения на PERT-дисперсию прогноза трудоемкости.
Основная цель проведенных испытаний – накопление статистических данных для исследования алгоритмов прогноза области распространения влияния изменения, в том числе уточнение свойств частот ninc и nexc, методов определения их порогового значения. При этом контроль качества тестирования, проводился с помощью сбора и анализа покрытия кода.
СПИСОК ЛИТЕРАТУРЫ
1. Д. Искусство тестирования программ / ; пер. с англ. М.: Финансы и статистика, 1982.
2. Software Consideration in Airborne System and Equipment Certification RTCA DO-178B December 1, 1992.
3. Scott E. D, Stanley G. S. Successful Software Development 2nd. – Prentice Hall PTR, 2000.
4. Управление проектами: Практическое руководство / , ; пер. с англ. М.: Дело и Сервис, 2003.
