

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Однофакторный дисперсионный анализ
1. Решение задач однофакторного дисперсионного анализа
Дисперсионный анализ позволяет исследовать различие между группами данных, определять, носят ли эти расхождения случайный характер или вызваны конкретными обстоятельствами. Например, если продажи фирмы в одном из регионов снизились, то с помощью дисперсионного анализа можно выяснить, случайно ли снижение оборотов в этом регионе по сравнению с остальными, и при необходимости произвести организационные изменения. При выполнении эксперимента в разных условиях дисперсионный анализ поможет определить, насколько влияют внешние факторы на измерения, или отклонения носят случайный характер. Если на производстве для улучшения качества продукции изменяют режим процессов, то дисперсионный анализ позволяет оценить результаты воздействия данного фактора.
На этом примере мы покажем, как выполнять дисперсионный анализ экспериментальных данных.
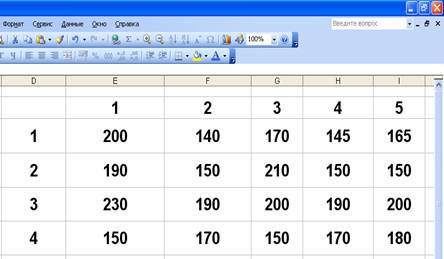
Задание 1. Имеются четыре партии сырья для текстильной промышленности. Из каждой партии отобрано по пять образцов и проведены испытания на определение величины разрывной нагрузки. Результаты испытаний приведены в таблице.

Необходимо выяснить, существенно ли влияние различных партий сырья на величину разрывной нагрузки. Данная задача сводится к проверке выдвигаемой нулевой гипотезы Н0:. а1= а2=…= аm о равенстве математических ожиданий, осуществляемой в дисперсионном анализе. т. е. нужно проверить гипотезу о том, что на уровне значимости α = 0,05 (с надежностью 0,95) различие между партиями сырья не оказывает существенное влияние на величину разрывной нагрузки.
Порядок работы
|
 >•Откройте табличный процессор Microsoft Excel. Щелкните мышью на ярлыке Лист2 (Sheet2), чтобы перейти на другой рабочий лист.
>•Откройте табличный процессор Microsoft Excel. Щелкните мышью на ярлыке Лист2 (Sheet2), чтобы перейти на другой рабочий лист.
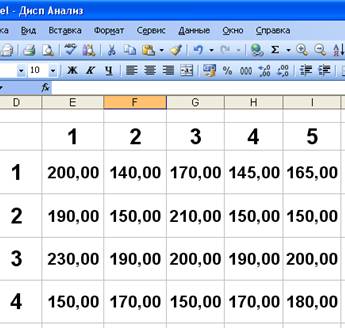
>• Введите данные для дисперсионного анализа, изображенные на рис.1.
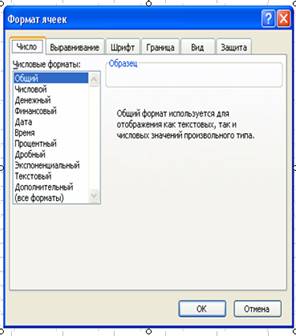
>•Преобразуйте данные в числовой формат. Для этого выберите команду меню Формат • Ячейки. На экранe появится окно формат ячеек (Рис.2). Выберите Числовой формат и введенные данные преобразуются к виду, показанному на рис. 3
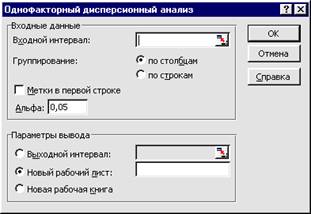
>•Выберите команду меню Сервис • Анализ данных (Тоо1s * Dаtа Апа1уsis). На экранe появится окно Анализ данных (Dаtа Апа1уsis) (Рис.4).
>• Щелкните мышью на строке Однофакторный дисперсионный анализ (Аnоvа: Single Factor) в списке Инструменты анализа (Апа1уsis Тоо1s).
>• Нажмите кнопку ОК, чтобы закрыть окно Анализ данных (Dаtа Апа1уsis). На экране появится окно Однофакторный дисперсионный анализ для проведения дисперсионного анализа данных (Рис.5).
|
|
>• Щелкните мышью в поле Входной интервал. Выделите диапазон ячеек E3::I6, данные в котором нужно проанализировать. В поле Входной интервал (Input Range) группы элементов управления Входные данные, (Input) появится указанный диапазон.
|

|
>• Установите флажок Метки в первой строке (Labels in Firts Rom) в группе элементов управления Входные данные (Input), если первый столбец выделенного диапазона данных содержит названия строк.
>• В поле ввода Альфа (А1рhа) группы элементов управления Входные данные по умолчанию отображается величина 0,05, которая связана с вероятностью возникновения ошибки в дисперсионном анализе.
>• Если в группе элементов управления Параметры вывода (Input options) не установлен переключатель Новый рабочий лист (Nev Worksheet Ply), то установите его, чтобы результаты дисперсионного анализа были помещены на новый рабочий лист
> Нажмите кнопку ОК, чтобы закрыть окно Однофакторный дисперсионный анализ (Аnоvа: Single Factor). На новом рабочем листе появятся результаты дисперсионного анализа (Рис. 6).
|
Рис.6 |

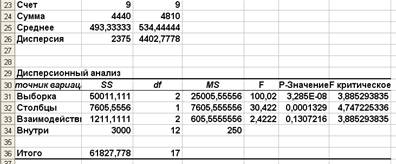
В диапазоне ячеек А4:Е6 расположены результаты описательной статистики. В строке 4 находятся названия параметров, в строках статистические значения, вычисленные по партиям.
В столбце Счет (Соunt) расположены количества измерений, в столбце Сумма - суммы величин, в столбце Среднее (Аvегаgе) - средние арифметические значения, в столбце Дисперсия (Vаriаnсе) - дисперсии.
Полученные результаты показывают, что наибольшая средняя разрывная нагрузка в партии №3, а наибольшая дисперсия разрывной нагрузки –в партии №1.
В диапазоне ячеек А11:G16 отображается информация, касающаяся существенности расхождений между группами данных. В строке 12 находятся названия параметров дисперсионного анализа, в строке 13 - результаты межгрупповой обработки, в строке 14 - результаты внутригрупповой обработки, а в строке 16 – суммы значений упоминавшихся двух строк.
В столбце SS (Qi) расположены величины варьирования, т. е. суммы квадратов по всем отклонениям. Варьирование, как и дисперсия, характеризует разброс данных. По таблице можно заметить, что межгрупповой разброс разрывной нагрузки существенно выше величины внутригруппового варьирования.
В столбце df (k) находятся значения чисел степеней свободы. Данные числа указывают на количество независимых отклонений, по которым будет вычисляться дисперсия. Например, межгрупповое число степеней свободы равняется разности количеству групп данных и единицы. Чем больше число степеней свободы, тем выше надежность дисперсионных параметров. Данные степеней свобод в таблице показывают, что для внутригрупповых результатов надежность выше, чем для межгрупповых параметров.
В столбце MS (S2) расположены величины дисперсии, которые определяются отношением варьирования и числа степеней свобод. Дисперсия характеризует степень разброса данных, но в отличие от величины варьирования, не имеет прямой тенденции увеличиваться с ростом числа степеней свобод. Из таблицы видно, что межгрупповая дисперсия значительно больше внутригрупповой дисперсии.
В столбце F находится, значение F-статистики, вычисляемое отношением межгрупповой и внутригрупповой дисперсий.
В столбце F критическое (F crit) расположено F-критическое значение, рассчитываемое по числу степеней свободы и величине Альфа (А1рhа). F-статистика и F-критическое значение используют критерий Фишера-Снедекора.
Если F-статистика больше F-критического значения, то можно утверждать, что различия между группами данных носят неслучайный характер. т. е. на уровне значимости α = 0,05 (с надежностью 0,95) нулевая гипотеза отвергается и принимается альтернативная: различие между партиями сырья оказывает существенное влияние на величину разрывной нагрузки.
В столбце Р-значение (Р-value) находится значение вероятности того, что расхождение между группами случайно. Так как в таблице данная вероятность очень мала, то отклонение между группами носит неслучайный характер.
2. Решение задач двухфакторного дисперсионного анализ без повторений
Microsoft Excel располагает функцией Anova: Двухфакторный дисперсионный анализ без повторений (Two-Factor Without Replication), которая используется для выявления факта влияния контролируемых факторов А и В на результативный признак на основе выборочных данных, причем каждому уровню факторов А и В соответствует только одна выборка. Для вызова этой функции необходимо на панели меню выбрать команду Сервис –Анализ данных. На экране раскроется окно Анализ данных, в котором следует выбрать значение Двухфакторный дисперсионный анализ без повторений и щелкнуть на кнопке ОК. В результате на экране раскроется диалоговое окно, показанное на рисунке 1.
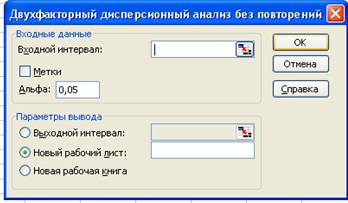 В диалоговом окне задаются следующие параметры.
В диалоговом окне задаются следующие параметры.
1. В поле Input Range вводится ссылка на диапазон ячеек, содержащий анализируемые данные.
|
3. В поле Aльфа вводится принятый уровень значимости α, соответствующий вероятности возникновения ошибки первого рода.
4. Переключатель в группе Output options может быть установлен в одно из трех положений: Output Range (Выходной диапазон), New Worksheet Ply (Новый рабочий лист) или New Workbook (Новая рабочая книга).
Пример.
Рассмотрим использование функции Двухфакторный дисперсионный анализ без повторений (Anova: Two-Factor Without Replication) на следующем примере.
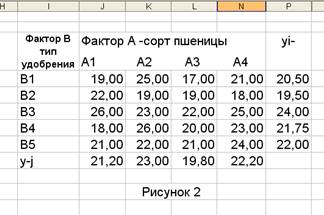
На рисунке. 2 представлены данные об урожайности (ц/га) четырех сортов пшеницы (четыре уровня фактора А), достигнутой при использовании пяти типов удобрений (пять уровней фактора В). Данные получены на 20 участках одинакового размера и аналогичного почвенного покрова. Необходимо определить, влияет ли сорт и тип удобрения на урожайность пшеницы.
Результаты двухфакторного дисперсионного анализа с помощью функции Двухфакторный дисперсионный анализ без повторений представлены на рисунке 3.
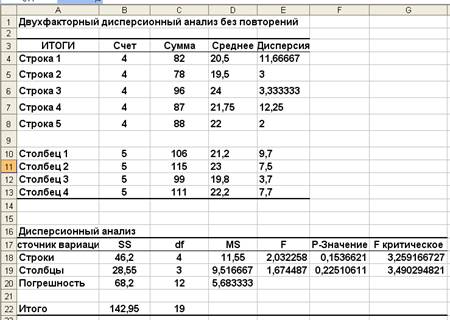 Как видно по результатам, расчетное значение величины F-статистики для фактора А (тип удобрения) FА=l,67, а критическая область образуется правосторонним интервалом (3,49; +∞). Так как FА=l,67 не попадает в критическую область, гипотезу НА: a1 = a2 + ••• = ak принимаем, т. е. считаем, что в этом эксперименте тип удобрения не оказал влияния на урожайность.
Как видно по результатам, расчетное значение величины F-статистики для фактора А (тип удобрения) FА=l,67, а критическая область образуется правосторонним интервалом (3,49; +∞). Так как FА=l,67 не попадает в критическую область, гипотезу НА: a1 = a2 + ••• = ak принимаем, т. е. считаем, что в этом эксперименте тип удобрения не оказал влияния на урожайность.
|
Так как FВ =2,03 не попадает в критическую область, гипотезу НВ: b1 = b2 = ... = bm
также принимаем, т. е. считаем, что в данном эксперименте сорт пшеницы также не оказал влияния на урожайность.
2. Двухфакторный дисперсионный анализ c повторениями
Microsoft Excel располагает функцией Anova: Двухфакторный дисперсионный анализ с повторениями (Two-Factor With Replication), которая также используется для выявления факта влияния контролируемых факторов А и В на результативный признак на основе выборочных данных, однако каждому уровню одного из факторов А (или В) соответствует более одной выборки данных.
Рассмотрим использование функции Двухфакторный дисперсионный анализ с повторениями на следующем примере.
Пример 2. В таблице. 6 приведены суточные привесы (г) собранных для исследования 18 поросят в зависимости от метода удержания поросят (фактор А) и качества их кормления (фактор В).

Необходимо оценить существенность (достоверность) влияния каждого фактора и их взаимодействия на суточный привес поросят.
|
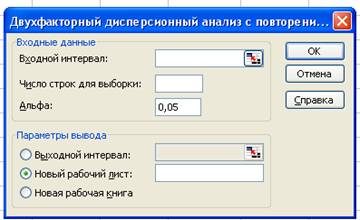
Для вызова необходимой функции необходимо на панели меню выбрать команду Сервис –Анализ данных (Tools-Data Analysis). На экране раскроется диалоговое окно Анализ данных (Data Analysis), в котором следует выбрать значение Anova: Двухфакторный дисперсионный анализ с повторениями (Two-Factor With Replication)и щелкнуть на кнопке ОК. В результате на экране раскроется диалоговое окно Двухфакторный дисперсионный анализ с повторениями, показанное на рисунке 5.
|
|
В этом диалоговом окне задаются следующие параметры.
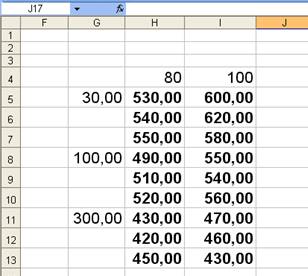
1. В поле Входной интервал (Input Range) вводится ссылка на диапазон ячеек, содержащий анализируемые данные. Необходимо выделить ячейки от G 4 до I 13.
2. В поле Число строк для выборки (Rows per sample) определяется число выборок, которое приходится на каждый уровень одного из факторов. Каждый уровень фактора должен содержать одно и то же количество выборок (строк таблицы). В нашем случае число строк равно трем.
3. В поле Альфа (Alpha) вводится принятое значение уровня значимости α, которое равно вероятности возникновения ошибки первого рода.
4. Переключатель в группе Output options может быть установлен в одно из трех положений: Output Range (Выходной интервал), New Worksheet Ply (Новый рабочий лист) или New Workbook (Новая рабочая книга).
Результаты двухфакторного дисперсионного анализа с помощью функции Двухфакторный дисперсионный анализ сповторениями представлены на рисунке 6.
|

Очевидно, данные факторы имеют фиксированные уровни, т. е. мы находимся в рамках модели I. Поэтому для проверки существенности влияния факторов А, В и их взаимодействия АВ необходимо найти отношения
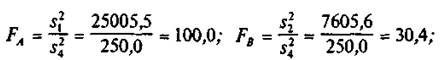
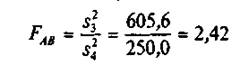
и сравнить их с табличными значениями соответственно 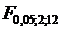 :=3,88;
:=3,88; 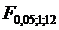 =: =4,75; =3,88. Так как
=: =4,75; =3,88. Так как 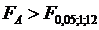 и
и 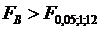 то влияние метода содержания поросят (фактора А) и качества их кормления (фактора В) является существенным. В силу того что
то влияние метода содержания поросят (фактора А) и качества их кормления (фактора В) является существенным. В силу того что ![]() взаимодействие указанных факторов незначимо (на 5%-ном уровне).
взаимодействие указанных факторов незначимо (на 5%-ном уровне).
Задание на дом
1. В течение шести лет использовались пять различных технологий по выращиванию сельскохозяйственной культуры. Данные по эксперименту (в ц/га) приведены в таблице:
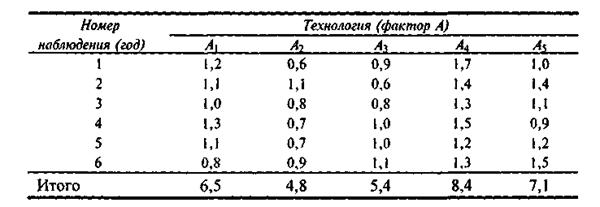
Необходимо на уровне значимости α = 0,05 установить влияние различных технологий на урожайность культуры.
2. На заводе установлено четыре линии по выпуску облицовочной плитки. С каждой линии случайным образом в течение смены отобрано по 10 плиток и сделаны замеры их толщины (мм). Отклонения от номинального размера приведены в таблице:

Требуется на уровне значимости α = 0,05 установить зависимость выпуска качественных плиток от линии выпуска (фактора А).
3. Имеются следующие данные об урожайности четырех сортов пшеницы на выделенных пяти участках земли (блоках):

Требуется на уровне значимости а = 0,05 установить влияние на урожайность сорта пшеницы (фактора А) и участков земли — блоков (фактора В).
4. На четырех предприятиях В1, В2, В3, В4 проверялись три технологии производства А1, А2, А3 однотипных изделий. Данные о производительности труда в условных единицах приведены в таблице:
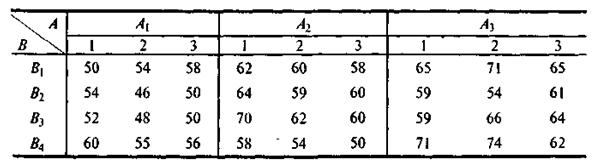
Требуется на уровне значимости α = 0,05 установить влияние на производительность труда технологий (фактора А) и предприятий (фактора В).
