
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
МОСКОВСКИЙ ГОСУДАРСТВЕННЫЙ ИНСТИТУ РАДИОТЕХНИКИ ЭЛЕКТРОНИКИ И АВТОМАТИКИ (ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ)
Гербовая печать института «РАЗРЕШАЮ
НА ДЕПОНИРОВАНИЕ»
Проректор по научной работе
_______________
УДК 004.942
ИССЛЕДОВАНИЕ И РЕГУЛИРОВАНИЕ КОНТЕНТА ВИКИ-СИСТЕМ
Автор ____________________
подпись
Москва 2008г
Оглавление
Введение. 3
1. Информационный морфизм трехуровневого консорциума и микропорталов в его составе. 3
2. Пертинентность и релевантность. 7
3. Критерии и эшелоны выдачи: семантическая релевантность и пертинентность 9
4. Полнота и точность поиска вики-системы: соотношения и близость пертинентности и релевантности. 15
Заключение. 18
Список используемой литературы.. 18
Введение
В Высшей школе РФ в современных условиях появляются новые возможности использования (в том числе средствами Интернет) для доступа к информационному полю, организации связи между субъектами образовательного процесса.
В основном строительство информационных портальных библиотек информационного обеспечения на уровне отрасли, регионов и отдельно взятых ВУЗов в настоящее время сформировано. Вместе с тем в развитии указанной деятельности задачей сегодняшнего дня является строительство порталов персонифицированного информационного обслуживания многочисленных конечных пользователей – участников учебно-творческого процесса. В основе такого подхода группирование информационного обеспечения на уровне основного звена образования ВУЗа, то есть кафедры. Таким образом, речь идет о многоуровневом портальном обеспечении образовательной индустрии от отрасли, ВУЗа, факультета до кафедры и взаимодействующих с ней многочисленных персонифицированных пользователей. Такая система информационной поддержки многоуровневого портального обеспечения образовательной деятельности предполагает многомодульное инвариантное контентное наполнение, позволяющее обеспечивать мультисервисное мультиагентное обслуживание в различных предметных областях, объединенных учебными планами и программами по направлениям подготовки и специальностям профессионального образования.
Автором предлагаются и реализуются методы и технологии упорядочения контента многоуровневых порталов поддержки образовательной деятельности кафедры технического ВУЗа семантических и технологических показателей и характеристик, что позволяет улучшить баланс показателей качества и нагруженности систем, а так же упростить управления ими что не мало важно в реализации индустриальных образовательных технологий.
1. Информационный морфизм трехуровневого консорциума и микропорталов в его составе
Принципиальным положением, по мнению автора, является определение в качестве главенствующего принципа центральной оценивающей и регулирующей эффективность портала функции в виде информационного морфизма в сочетании с оценкой интегральной информационной нагруженности системы.
Согласно многочисленным научным публикациям и онтологическим соглашениям морфизм представляет собой класс эквивалентности. Морфизм как теоретическое представление системности информационных средств является яркой составляющей современной синергетической науки. В качестве основной гипотезируется следующая позиция: информационный морфизм – это гомоморфизм свободного моноида в информационном поле, генерируемого из сообщества морфологических, иногда и синтаксических, схожеств и признаков, способных к кластеризации. В теории идеальный морфизм - это событие, длина или размер морфизма – это время объекта или время с точки зрения самого объекта. информационный морфизм (взаимодействие), представляющий протяженный во времени процесс взаимозависимого изменения параметров состояния информационного объекта и информационного пространства.
В процессе этого взаимодействия в ИС объект-источник не всегда теряет (испытывает эмиссию) некоторое количество информации при передаче ее другому объекту, в то время как другой объект-получатель всегда приобретает некое новое добавочное количество информации (происходит его ремиссия). Совокупный объем информации, а также их суммарная энтропия при этом обмене неизбежно возрастают, а совокупная система расширяется. Процесс этот асимметричен.
Отсюда информационному пространству присущи следующие свойства:
- наличие информационных морфизмов, которым присуще информационное межсистемное взаимодействие; информационный морфизм возможен только при определенном взаимном соответствии свойств и качеств системных объектов обмена информацией; информационный морфизм приводит к изменению свойств и качеств объектов обмена информацией; информационный морфизм приводит к переходу объектов обмена информацией только в свойственные им возможные ("чистые") состояния, что есть проявление эмерджентности морфизма.
В соответствии с принципом эмерджентности новый носитель знаний возникает как результат действия положительной обратной связи, имеющей место между различными иерархическими уровнями информационного восприятия в процессе обмена информацией.
С точки зрения синергетики носитель информации возникает в результате самопроизвольного нарушения существующей симметрии информационного морфизма в точке бифуркации, как следствие синергетического развития информационного объекта. Возникающие носители могут обладать или не обладать устойчивостью по отношению к информационной среде. При появлении устойчивого носителя может происходить фиксация возникшего типа носителя в случае возможного его использования по отношению к информационной структуре более высокого порядка.
Отсюда вероятностная модель информационного морфизма V между двумя объектами А и В в образовательной информационной среде определяется следующим образом:
Vi = Ci / Ea + k Eb,
где Ci - относительное количество информации вида I в дуплексном (самый общий случай информационного обмена между объектами А и В) информационном пространстве;
Ea и Eb - относительные (долевые) распределения информации в потоках в направлениях от А к В и от В к А;
k - сложный коэффициент, в первом приближении равный натуральному числу е в степени произведения: - L (Gai - Gbi), где L - коэффициент Лагранжа, Gai и Gbi - характеристические коэффициенты информационных потоков в направлениях от А к В и от В к А.
Модель позволяет отследить основные закономерности информационного морфизма. Показателем упорядоченности в модели является информационная энтропия взаимодействующих объектов, что является классикой семантико-энтропийных оценок. Более того, согласно , понятие энтропии является в теории информации основным.
Вычисление энтропии Нв(а) двух объектов обмена информацией А и В осуществляется следующим образом:
- определяется число информационных морфизмов Iq(a) между объектами А и В ( в дуплексном режиме информационного обмена). Здесь q отображает категорию структурированных упорядоченных подмножеств знаний. Для оценки величины Iq(a) удобно воспользоваться матрицей Александера или любой иной моделью сравнений в морфологическом анализе информационного наполнения систем. аналогично определяется число Inoq(a), характеризующее число модулей хаотических, неупорядоченных знаний, придающих системе стохастичность. Здесь noq отображает категорию хаотических, неупорядоченных знаний.
В частном предельном случае можно полагать состояние информационного объекта А условно упорядоченным по отношению к объекту В (например, проектируя объект В в сравнении с эталонным прототипом А, допустим, проектируя собственный образовательный портал в сравнении с эталонным Федеральным порталом "Российское образование"). Тогда информационную энтропию взаимодействующей интегрированной системы А-В можно интерпретировать как меру хаотичности или как меру отклонения структуры состояния одного объекта от другого. Изменение этого отклонения вследствие тех или иных проектных действий, эмиссии\ремиссии объекта В (объект А - условно статичен), дрейфа энтальпии объектов А и В или вследствие любых иных причин приводит к появлению негэнтропии комплексной системы А-В, величина которой наглядно свидетельствует об изменении эмерджентности системы (по Хартли коэффициента эмерджентности ИС). Здесь под негэнтропией понимается изменение энтропии системы взаимодействующих объектов А и В.
В соответствии с принципом максимума информационной энтропии Джеймса наиболее вероятным состоянием информационной среды системы А-В будет то состояние, когда информационная энтропия максимальна. В открытых Интернет-пространствах это именно так. В корпоративных замкнутых средах такой тезис спорен. В распределенных информационных корпоративных средах энтропия весьма высока при очень большом количестве модулей, образующих информационную структуру, а число информационных морфизмов Iq между объектами, наоборот, мало. Минимум этого числа есть предельный ограничитель устойчивости состояния информационной среды системы с позиций ее релевантности. В проектной деятельности достаточно эффективным средством преодоления этого опасного минимума является технология информационной накачки. Технология представляет собой структурное сопряжение, возникающее в результате рекуррентных информационных морфизмов двух или большего числа информационных систем. Именно такая технология часто используется для быстрого эффективного контентного наполнения создаваемых новых информационных образовательных порталов, в которые закачиваются модули уже существующих положительно себя зарекомендовавших образовательных порталов, сайтов и библиотек.
Необходимо также иметь ввиду, что энтропия (в самом общем случае - обобщенная энтропия) обладает свойством иерархической аддитивности. Это очень важно с тех позиций, что семантико-энтропийная характеристика, как генеральная характеристика качества ИС, возможна только при соблюдении трех взаимосвязанных условий:
- обеспечение принципа эргодичности функционирования ИС (при монотонном без разрывов второго рода изменении энтропии); обеспечение принципа соответствия; обеспечение принципа аддитивности.
При переходе из одной иерархии в другую первые два принципа в общем случае не подвержены ломке, однако аддитивность прежней иерархии нарушается, но в новой иерархии возникает новое равновесное состояние системы, позволяющее считать аддитивность восстановленной. Поэтому уточненный для больших систем принцип энтропийной аддитивности формулируется как принцип иерархической аддитивности. Особые сложности возникают в случае исследования и проектирования динамических ИС, которым свойственны нелинейные процессы, сопровождающие изменения и развитие ИС. Нелинейность прежде всего означает не сохранение принципа аддитивности в процессе развития, что обуславливает необходимость четкого очертания временных и иных количественных рамок в оценке энтропии ИС и делает уместным введение терминов "динамическая иерархическая аддитивность" и "условная динамическая энтропия ИС в контурах (перечень подсистем и уровней в сиюминутной инфологической модели ИС)". Это, по мнению автора, может стать новым направлением в теории ИС, открывающим пути создания обобщенной математической модели больших и сверхбольших ИС. Продолжение аналитических исследований в этой области знаний актуально еще и потому, что выше было уже показано, что свойства аддитивности и эргодичности, в частности из-за внедрения в них актуальных на сегодня технологий ВИКИ и макромедиа, неизбежно дрейфуют в сторону диссипативных и нелинейных динамических проявлений функционала этих систем, что рано или поздно нивелирует валидность проектных действий и разрушит запланированный полный жизненный цикл систем.
2. Пертинентность и релевантность
Функция информационной системы состоит в выделении из поискового массива таких документов, которые содержат информацию, удовлетворяющую информационную потребность пользователя. Но информационная потребность выражается в информационном запросе, формулировка которого может лишь более или менее приблизительно выражать действительную информационную потребность. («Мысль изреченная есть ложь»). Информационный запрос представляется поисковой системе в виде поискового образа запроса (ПОЗ), т. е. формализованного перечня терминов. Кроме того задаётся формальный критерий соответствия (КС) документа запросу. Поисковый образ запроса вместе с критерием соответствия составляют поисковое предписание: ПП = ПОЗ + КС. Информационная система в ответ на запрос, выполняя поисковое предписание, выдаёт некоторую совокупность документов. (См. рис. 1.).
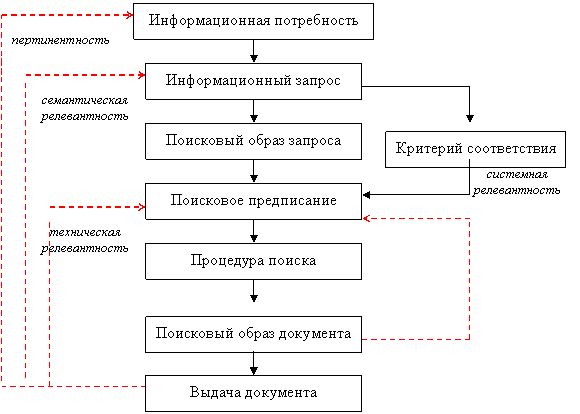 |
Рис. 1. Соотношение информационной потребности и документной выдачи
Не все документы в выдаче удовлетворяют информационной потребности. Как правило, они лишь формально соответствуют поисковому предписанию. Документы, действительно соответствующие потребности пользователя, являются пертинентными. А сама информационная потребность представляет собой весьма сложное психическое явление, и проблема повышения степени пертинентности выдачи оказывается не только трудной для достижения, но её даже трудно чётко поставить как практическую задачу. Определить соответствие выдачи документированному запросу проще. Документы, соответствующие запросу, называются релевантными. Однако суждение о релевантности будет зависеть от того, кто это суждение выносит. Если автор запроса, то он будет оценивать не столько релевантность, сколько пертинентность, в той мере, в которой ему удастся ознакомиться с документом. Если же релевантность будет оценивать работник системы, то он сможет объективно учитывать только формальное вхождение элементов поискового предписания в документ, не задаваясь вопросом о соответствии запроса потребности пользователя («Каков запрос, таков и ответ»). Но именно последняя характеристика определяет эффективность самой системы. Следовательно, надо различать релевантность в самом широком понимании и семантическую релевантность (соответствие смыслу, а не форме запроса).
В случае исследования вики-системы (вики-система – это информационная система, построенная с использованием wiki-технологий. Wiki-технология - это технология построения веб-сайта, которая позволяет посетителям участвовать в редактировании его содержимого - исправлении ошибок, добавлении новых материалов, без необходимости использования специальных программ, регистрации на сервере и знания HTML.) для организации выдачи документов система должна уметь оценивать релевантность априори, до выдачи, чтобы выдать именно релевантные документы, поскольку назначение вики-системы поддерживать учебный процесс, где ошибки недопустимы. Для определения качества работы системы оценку релевантности выданных документов производят апостериори, после выдачи. Конечно, апостериорная релевантность сильно зависит от априорной, но эти характеристики различны по своей природе. Так, при автоматическом поиске система не имеет ничего, кроме поискового предписания и поисковых образов документов. Это значит, что система может устанавливать соответствие только этих объектов, что влечёт введение ещё одного параметра – системной релевантности. При всей важности этого параметра применительно к настоящему исследованию найдено целесообразным все-таки ограничиться только оценкой семантической релевантности, поскольку системное обустройство википедий отличает их от портального обустройства множеством точек входа и свободой действий множества модераторов-пользователей. В результате этого эмерджентность википедий является трудно регулируемым параметром, а единая для всех пользователей семантика является важнейшим условием.
3. Критерии и эшелоны выдачи: семантическая релевантность и пертинентность
Весьма распространённый критерий релевантности (в том числе семантической) состоит в требовании полного совпадения поискового образа документа с поисковым предписанием. Но этот критерий применим только к ограниченным видам запросов, например к поиску по полному библиографическому описанию, или к поиску всех документов в некотором тематическом классе по принятой классификации знаний. А в реальных поисковых системах при всестороннем координатном индексировании вероятность полного совпадения предписания с поисковым образом документа крайне низка. Поэтому необходимо как-то оценивать не абсолютную, а относительную релевантность – степень релевантности – на основе частичного совпадения поискового предписания с поисковым образом документа. При этом система должна выдавать документ, если степень его релевантности запросу превзошёл некоторый достаточно высокий порог. Методов вычисления степени системной релевантности было предложено довольно много, и многие из них имеют весьма изощрённый характер в попытке по формальным признаками промоделировать человеческое восприятие сходства и различия смысла текстов. Рассмотрим некоторые из них.
Начнём с простых оценок. Степень релевантности можно оценивать отношением числа дескрипторов запроса, найденных в документе, А к общему числу N дескрипторов в запросе: R1 = А/N. Требование полного совпадения запроса с документом соответствует R1 = 1 и A = N = M, где М – полное число дескрипторов в поисковом образе документа. В практических поисковых системах порог релевантности задают установлением допустимой разницы (d) между общим числом дескрипторов в запросе N и числом их, найденных в документе. Величина R1 = (N–d)/N при этом меньше 1. Отсутствие в документе некоторых дескрипторов запроса означает, что в этом документе дана неполная информация на запрос, но имеются достаточно полезные сведения. Если поиск на полное совпадение даёт неудовлетворительный результат, проводят поиск на совпадение всех, кроме одного дескриптора запроса (d = 1), кроме двух (d = 2) и т. д. Если же запрос состоит всего из одного термина, то можно вести поиск только на полное совпадение. Присутствие в документе дескрипторов, отсутствующих в запросе, обычно не учитывается при поиске, но оно может означать, что не весь документ важен для пользователя, и это снижает степень его фактической релевантности.
Последнее соображение учитывается в более сложном случае, когда за критерий релевантности принимается величина R2 = А/М – отношение числа найденных дескрипторов в документе к числу всех дескрипторов в поисковом образе документа. Требование полного совпадения документа с запросом здесь также соответствует R2 = 1, а при частичном совпадении значение R2 находится в пределах от 1 до 0. Как показала практика, для систем с таким критерием релевантности удовлетворительная выдача наблюдается при установлении порога выдачи в интервале от R2=0,25 до R2 = 0,4. Очевидно, что R2 зависит от принятой глубины и разносторонности индексирования документов, от среднего числа М дескрипторов в поисковом образе документа. При многословном поисковом образе документа и запрос также должен быть многословным. Если М = 10, то поиск по одному понятию никогда не даст R2 > 0,1 и система ничего не выдаст. В запрос придётся добавлять новые термины, как бы объясняя системе свою потребность. Если в предыдущем случае для увеличения количества выданных документов нужно удалять дескрипторы из запроса, то при критерии R2 наоборот следует запрос расширять.
Эти два описанных критерия релевантности можно усложнить учётом значимости дескрипторов для документа и для запроса, если этим дескрипторам в процессе индексирования присвоены весовые коэффициенты. Пусть в документе совпали дескрипторы № 1, 2, 3, …, k. Пусть этим дескрипторам пользователь присвоил веса n1, n2, n3, …, nk, а в документе они имеют веса m1, m2, m3, …, mk. Тогда в качестве критерия релевантности можно принять сумму произведений этих весовых коэффициентов: m1n1+ m2n2 + m3n3 + …+ mknk, или как кратко пишут математики:
k
∑ mi ni (1)
i=1
Однако для того чтобы релевантность не зависела от масштабов присвоения коэффициентов, эту величину следует взять относительно общей суммы всех коэффициентов дескрипторов в запросе ∑ ni и в документе ∑ mi:
![]() k k k
k k k
R3 = (∑ mi ni) ( ∑ mi · ∑ ni ) , (2)
i=1 i=1 i=1
где в знаменателе суммы берутся по всем дескрипторам поискового образа документа (ПОД) и поискового образа запроса (ПОЗ) соответственно.
Для учёта того, что наличие в поисковых образах документа и запроса свидетельствует об определённой степени рассогласования тематики документа и информационной потребности пользователя, в формулу критерия выдачи следует ввести члены, уменьшающие его при наличии несовпадающих терминов:
![]() k k k
k k k
R4 = (∑ mi ni — ∑ mk · ∑ nk ) ( ∑ mi · ∑ ni ) , (3)
i=1 i=1 i=1 ПОД ПОЗ
где индексами k обозначаются веса дескрипторов документа mk, которые не находят соответствия в запросе и веса дескрипторов запроса nk, которые не находят соответствия в документе. Величина R3 всегда находится в пределах от 0 до 1, а R4 изменяется от +1 до –1. Естественной границей релевантности можно считать R4 = 0, т. е. суммарный вес отсутствующих дескрипторов не превосходит суммарный вес совпадающих дескрипторов.
Снижение релевантности может также выражаться не путём вычитания весов несовпадающих дескрипторов, а путём деления суммы весов совпадающих на сумму весов несовпадающих дескрипторов. При этом для исследования викепидии формула может быть упрощена, так как контент по информатике более или менее однороден в семантическом отношении.
Тогда указанная формула автоматически приобретает форму, не зависящую от масштабов присвоения весов и глубины индексирования:
![]() k
k
R5 = (∑ mi ni) ( ∑ mk · ∑ nk ) . (4)
i=1 ПОД ПОЗ
Величина R5 может быть как меньше, так и больше 1. Значение R5 = 1 является естественной границей релевантности.
Представление формулы для расчета релевантности википедий в таком несколько минимизированном виде является одним из результатов проводимого исследования.
От конкретной формулы расчёта релевантности, принятой в информационной системе, эффективность поиска зависит в сильной степени. Подкрепим эту мысль примером.
Ещё в 50-х годах прошлого века была реализована изощрённая процедура расчета релевантности, при которой для каждого термина запроса просматривался весь имеющийся массив документов (ПОД) и подсчитывалась частота совместной встречаемости данного термина со всеми другими. Далее для каждого термина составлялся упорядоченный список (профиль) терминов совместно встречающихся чаще, чем в среднем (связанные термины). Далее из всех профилей терминов запроса выбираются общие для всех них. С отобранными терминами процедура повторяется. На основе частоты совместной встречаемости терминов этого списка вычисляется их вес (чем больше связанность, тем выше вес). Наконец на основе этих весов рассчитывался показатель релевантности аналогичный R3.
Подобные сложные расчёты статистики распределения терминов в документах имеют назначение как-то выявить смысловые связи слов. Однако возникает вопрос: «Зачем заставлять машину выяснять то, что человеку ясно заранее?». Смысловые связи слов можно прямо заложить в машину в виде информационно-поискового тезауруса, о чём мы уже говорили. Эта идея, в нашей стране, впервые была реализована в практической информационно-поисковой системе , и [1], в ИПС «Пусто–непусто», разработанной ВИНИТИ и внедрённой в ЦНТИ «Информэлектро».
Такое, довольно странное название системы «Пусто–непусто» обусловлено принятым в ней критерием релевантности. Он определялся соотношением наполненности четырёх множеств:
М1 - множество дескрипторов, совпадающих в ПОД и ПОЗ;
М2 - множество дескрипторов ПОД, родовых для дескрипторов ПОЗ.
М3 - множество дескрипторов ПОД, видовых для дескрипторов ПОЗ;
М4 - множество дескрипторов ПОД, не связанных с дескрипторами ПОЗ (поискового образа запроса).
По соотношению пустоты и наполненности этих множеств можно ранжировать и выбирать конкретный критерий выдачи документов. Наиболее вероятна релевантность документа, если все его дескрипторы совпадают с запросом:
М1 | М2 | М3 | М4 |
совпадающие | Родовые | Видовые | посторонние |
+ | 0 | 0 | 0 |
Столь же вероятна релевантность, если в документе есть также видовые дескрипторы (может быть наряду с родовыми):
+ | 0 | 0 | 0 |
+ | + | 0 | 0 |
Эти документы составляют первый эшелон выдачи. Если же в документе есть только видовые дескрипторы, то это может значить, что в нём идет речь только о части понятий, интересующих пользователя. Документы с заполненным только М3
0 | 0 | + | 0 |
составят второй эшелон выдачи.
В том случае, когда в документе представлены обобщающие (родовые) понятия, это может означать, что речь там идёт об общих вещах, а конкретно интересующее пользователя понятие упоминается только как частность. Документы с заполненным М2 составляют третью очередь выдачи.
+ | + | 0 | 0 |
0 | + | 0 | 0 |
0 | + | + | 0 |
Документы, содержащие посторонние дескрипторы (М4 ≠ 0) в той системе решено было не выдавать вовсе, хотя и они могли содержать полезную информацию.
Общая таблица эшелонов выдачи такова:
Эшелон | М1 | М2 | М3 | М4 |
Совпадающие | родовые | видовые | Посторонние | |
+ | 0 | 0 | 0 | |
Первый | + | 0 | 0 | 0 |
+ | + | 0 | 0 | |
Второй | 0 | 0 | + | 0 |
+ | + | 0 | 0 | |
Третий | 0 | + | 0 | 0 |
0 | + | + | 0 |
Важно в этом примере не то, какой именно был выбран показатель соответствия, а то, что для его определения использованы знания логических связей понятий, заложенные в систему и представляющие там некоторую модель предметной области, в которой действует система. Наличие такой модели является необходимым условием интеллектуального подхода системы к своей задаче. На пути развития этой идеи прогнозируется дальнейший прогресс в разработке автоматизированных систем вообще, и информационных систем в частности.
Характерной особенностью системы «Пусто-непусто» является эшелонированная выдача: сначала выдаётся документ с наивысшей релевантностью, а затем документы в порядке снижения вычисленного для них критерия релевантности. Это стало стандартом для современных информационных систем; они не отсекают документы с малой степенью релевантности, а предлагают пользователю сначала получить высокорелевантные документы и продолжать знакомство с выдачей, пока он не удовлетворить информационную потребность или пока не обнаружит, что в последующих документах нет пертинентной информации. При этом пользователь как бы сам устанавливает требуемый критерий релевантности в процессе диалога с системой.
Не имея необходимости приводить здесь аналогичные выкладки для расчета пертинентности ввиду полнейшей аналогии с расчетом релевантности можно сразу же констатировать, что окончательная формула расчета пертинентности вики-системы выглядит точно также как и усеченная формула для релевантности семантически однородных викепедий.
Результатом раздела 3 представленной статьи является предъявление минимизированного формуляра для расчета семантической релевантности и пертинентности однородных семантических систем, каковыми являются узкопрофильные вики-системы, в частности, вики-система «информатика».
4. Полнота и точность поиска вики-системы: соотношения и близость пертинентности и релевантности
Эффективность системы для заказчика в самом общем случае определяется как её техническим качеством, так и экономическим – стоимостью, в обратно пропорциональной зависимости. Здесь же выносится на обсуждение вопрос об эффективности исключительно в синергетическом аспекте.
Степень эффективности может быть определена сравнением реальной действующей системы с идеальной моделью. Идеальная модель может быть определена (как это было сделано основоположником научно-технической информатики К. Муэрсом) так: Это система, которая из документального фонда выдаёт ровно те и все те документы, которые бы отобрал сам пользователь, если бы он мог внимательно прочитать каждый из них. В этом определении, казалось бы абсолютно ясном, при внимательном обсуждении оказывается не ясным главное слово: «Что значит отобрал бы»? Отбирают документ для того, чтобы ознакомиться с ним. Но если пользователь «их внимательно прочитал», то значит он их уже всех «отобрал». А если считают, что «отбор» имеет целью получение полезной для дела информации, то это зависит от конкретного дела, и заранее определено быть не может. Это сильно снижает ценность определения эффективности систем, которое как раз и нужно определять прежде «дела», когда идёт речь о приобретении, внедрении или разработке системы. «До дела» можно определить только эффективность относительно технической релевантности, а «в ходе дела» пользователь судит о системе по её реальной пертинентности, которая заведомо ниже.
Так или иначе, соотношение множества реально выданных документов Мр с множеством идеальной выдачи Ми характеризуется следующими подмножествами (см. рис. 15.2):
А – документы, реально выданные системой и входящие в желаемую выдачу
А = Мр ∩ Ми
В – документы, выданные системой, не входящие в желаемую выдачу
В = Мр ∩ Ø Ми
С – документы, не выданные системой, но входящие в желаемую выдачу
С = Ø Мр ∩ Ми
D – документы, не входящие ни в реальную, ни в желаемую выдачу
D = Ø Мр ∩ Ø Ми
(Знак Ø здесь означает дополнение множества до полного объёма документов и читается как отрицание «не»).
В идеальном случае Мр= Ми = А, В = С = Д = 0
Реальный случай может характеризоваться соотношением числа документов в этих множествах. na - число документов во множестве А, nb - число документов в В, nc - число документов в С, nd - число документов в D.
Наиболее используемые в портальном строительстве два отношения, а именно:
- Коэффициент точности Т = na/(na+nb) - отношение числа релевантных документов в выдаче к общему объёму выдачи.
- Коэффициент полноты П = na/(na+nc) - отношение числа релевантных документов в выдаче к общему числу релевантных документов в массиве.
Множество В, содержащее документы выдачи, не соответствующие запросу, называется шумом (информационный шум). Относительное количество шумовых документов в выдаче Ш = nb/(na+nb) называется коэффициентом шума. Ш + Т = 1.
Множество С, содержащее релевантные документы, не выданные пользователю, называется потерями. Отношение числа «потерянных» документов nc к общему числу релевантных документов в массиве может быть названо коэффициентом потерь, или коэффициентом молчания М = nс/(na+nc).
Коэффициенты потерь и шума не являются самостоятельными показателями эффективности поиска. Они однозначно связаны с коэффициентами полноты и точности: Ш = 1 – Т, М = 1 – П .
Очевидно, что чем выше коэффициенты полноты и точности, тем эффективность поиска выше. При работе с какой-либо информационной системой мы можем получать в разных случаях выдачи с разными значениями этих показателей. На один запрос система может ответить лучше, на другой – хуже. В случае, когда в выдаче окажутся все релевантные документы поискового массива и в ней не будет ни одного шумового документа, полнота и точность достигают своего наивысшего значения равного 1. В противоположном случае, когда в выдаче не будет ни одного релевантного документа, а выданные документы окажутся шумовыми, коэффициенты П и Т будут равны 0. В остальных случаях значения коэффициентов полноты и точности находятся в диапазоне от 0 до 1. Но конкретные величины П и Т в каждом акте поиска могут быть различными. Поэтому по одному поиску нельзя судить об эффективности системы в целом. Для этого вычисляют среднее арифметическое показателей П и Т для большого числа поисков по типичным запросам. Такие усреднённые коэффициенты П и Т колеблются между 0 и 1, никогда не достигая своих предельных значений. Коэффициент полноты П характеризует вероятность того, что некоторый релевантный документ в массиве будет выдан в ответ на запрос. Коэффициент точности Т характеризует вероятность того, что некоторый документ в выдаче окажется релевантным. Часто величину коэффициентов выражают в процентах, умножая их расчётные относительные величины на 100.
Следует заметить, что полнота и точность поиска зависит не только от системы, но и от типа запросов. По одним типам запросов система может проводить поиск лучше, а по другим – хуже. Также эффективность может зависеть от представления о реальной потребности в получении той или иной информации. Так что при указании характеристик системы следует указывать условия проведения испытаний и характер запросов, на основании которых эти характеристики были вычислены.
Полнота и точность являются независимыми характеристиками информационной системы. Невозможно найти метод расчёта коэффициента П по заданному Т и наоборот. Тем не менее, существует эмпирически выявленные ограничения на эти показатели у практически работающих систем. Если система плохо сконструирована, то её полнота и точность могут быть как угодно малыми; здесь никакого ограничения нет. Если же искусственно сформировать такую систему, которая будет содержать только документы, релевантные относительно всех запросов определённого типа, и которая будет грубо выдавать весь свой массив в ответ на каждый запрос, то мы обнаружим в этом случае стопроцентную полноту и точность: П = Т = 1. Но в практически интересных случаях такое положение не возможно. Ни полнота, ни точность реальной информационной системы никогда не достигают 100%. Более того, если в имеющейся информационной системе путём изменения условий её работы или критерия выдачи стараемся повысить один из этих показателей, то другой неизбежно падает. Это наглядно видно в случае эшелонирования выдачи. Если мы ограничиваем выдачу первым эшелоном, содержащим документы с наибольшим априорным показателем релевантности, то среди них действительно окажется достаточно много реально релевантных и достаточно мало фактически шумовых документов, т. е. точность Т будет высокой. Но в этом эшелоне не будет ряда документов с меньшим показателем релевантности, но реально полезные пользователю. Попытка получить эти документы, приняв в выдачу следующие эшелоны документов, приведёт к повышению полноты П, но при этом в выдачу попадёт много низко релевантных документов, которые пользователем будут отсеяны как шумовые, т. е. снизится показатель точности Т.
Заключение
Показано, что точность, полнота и шум – существенные и общепринятые показатели порталов. Вместе с тем, было также выявлено, что используемый в их определении математический аппарат множеств не только достаточно сложен, но базируется на непременном правиле достаточно высокой выраженной эмерджентности и эргодичности систем. Если второе условие хотя бы вероятно, то первое явно нарушается из-за наличия множества точек входа в википедию и бесконечных перестроек контента пользователями по своим многим точкам входа. В результате этого от применения показателей точности, полноты и шума в случаях многоуровневых википедий в настоящем исследовании приходится с сожалением отказаться.
Вместе с тем, синергетическая релевантность и пертинентность применительно к синергетическим системам, каковыми являются вики-системы узкопрофильного типа являются достаточным, ясным, удобным для регулирования их обобщенным показателем. Это же относится и к системам с выраженными действиями по конфигурациям в их контентах, направленных на разбиение контента по информационным контейнерам и уровням.
Следовательно, синергетическая релевантность и пертинентность в сопоставлении с энтропийными характристиками являются наиболее приемлимыми регуляторами синергетических википедий. На наш взгляд это является новым и достаточно принципиальным выводом настоящего исследования.
