
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
ВЕДЕНИЕ
Два класса ЭВМ. Принцип действия ЭВМ.
Первая механическая вычислительная машина была изобретена 1893г. английским ученым Бебиджем. Эта машина реализована в 50-х годах и является экспонатом лондонского музея вычислительной техники. Она выполняет 1000 оп/сек. Существуют 2 класса ЭВМ: аналоговые и цифровые.
Преимуществом аналоговых ЭВМ является: высокая точность обработки информации. Недостатком - большие размеры, малая скорость обработки информации.
Информация - это сведения о тех или иных явлениях природы, событиях в общественной жизни и технических аспектах.
Современная ЭВМ может обрабатывать два класса информации: дискретную и непрерывную. К свойствам ЭВМ относятся:
- автоматизация вычислительного процесса на основе программного управления;
- очень высокая скорость выполнения логических и арифметических операций;
- возможность хранения большого количества данных;
- широкий круг решаемых задач.
Классическая схема ЭВМ показана на рисунке1.
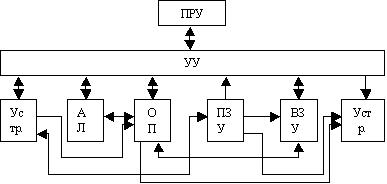
Рисунок 1
где ПРУ - пульт ручного управления.
УУ - устройство управления. Служит для управления внешними, по отношению к себе, устройствами.
Уввод - устройство ввода (сетевая карта, дисководы, сканер). Служат для передачи внешних данных.
АЛУ - арифметико-логическое устройство. Служит для выполнения арифметических и логических операций. В любом классе ЭВМ выполняется только одна операция - сложение. УУ и АЛУ образуют процессор.
ОП - оперативная память. Служит для временного хранения информации, которая в данный момент времени обрабатывается процессором.
ПЗУ - постоянное запоминающее устройство. BIOS (Basic Input Output System) - базовая система ввода - вывода. Содержит в себе инструкции, необходимые для организации ввода - вывода информации.
ВЗУ - внешнее запоминающее устройство. Служит для долговременного хранения информации.
УВыв - устройство вывода (монитор, принтер, графопостроитель, зв. карта).
ЭВМ общего назначения. Малые ЭВМ. Микро ЭВМ. Микропроцессоры
ЭВМ общего назначения
Блок-схема ЭВМ общего назначения показана на рисунке 2.
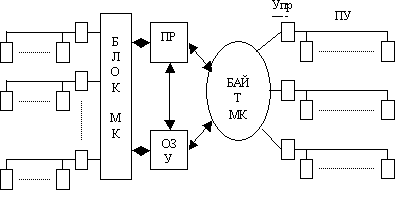
Рисунок 2
Селекторный и блок-мультиплексный канал может одновременно обмениваться информацией со всеми подключенными к нему периферийными устройствами.
Байт-мультиплексный канал может обмениваться информацией с одним периферийным устройством на каждой линии.
Процессор обрабатывает информацию со скоростью примерно 10 млн. оп/сек. Длина машинного слова составляет 32 бита, а время доступа к памяти 1мк. сек.
Малые ЭВМ.
Малые ЭВМ имеют открытую архитектуру, т. е. взаимозаменяемые блоки.
Структурная схема малой ЭВМ показана на рисунке 3.
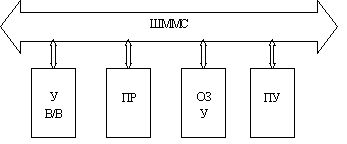
Рисунок 3
ШММС - шина межмодульной связи. Состоит из шин: адреса, данных, управления.
Шина данных является двунаправленной, причем обмен информацией в ту или в другую сторону по двум направлениям одновременно. Такой способ обмена информацией называется дуплексным.
Шина адреса является двунаправленной, но обмен информацией происходит с разделением времени. Такой способ обмена информацией называется полудуплексным
Шина управления является однонаправленной. Такой способ обмена информацией называется симплексным.
В первых поколениях малых ЭВМ шина данных была 8 битной, в современных 64бита. Время доступа к памяти составляетн. сек. Скорость обработки информации составляет миллионов оп/сек. Малые ЭВМ не используются в системах реального времени.
Микро-ЭВМ.
Это специализированные ЭВМ, использующиеся в системах реального времени. Время реакции МЭВМ на внешний сигнал 1 - 2 н сек. Объём ОЗУ - 64 кБит. Микро-ЭВМ имеет структуру малой ЭВМ.
Мини ЭВМ.
Это ЭВМ реализована на 1 кристалле. Она представляет собой законченный модуль, управляемый на уровне машинных кодов.
Микропроцессоры.
Это устройства выполнены на нескольких кристаллах, каждый из которых выполняет функцию одного узла процессора.
Раздел 1. Архитектура электронно-вычислительных машин.
Тема 1.1. Принцип построения процессора.

Рисунок 1
Как показано на рисунке 1, центральный процессор большинства ЭВМ с фон неймановской архитектурой содержит устройство управления, арифметико-логическое устройство и группу регистров.
Устройство управления (УУ) управляет и координирует работу всех элементов центрального процессора, управляет процессом обмена информацией с другими блоками ЭВМ.
Арифметико-логическое устройство (АЛУ) (или операционный блок) предназначено для выполнения арифметических и логических операций над двоичными числами.
Регистры центрального процессора, как и ячейки оперативной памяти, представляют собой узлы для запоминания и хранения двоичных чисел, однако они, размещаясь в самом центральном процессоре, выполняют свои важные специфические функции.
Регистры могут быть сгруппированы следующим образом:
1. Регистры общего назначения (РОН). Это восемь 32 битных регистра, которые могут произвольно использоваться программистами.
2. Регистры сегментов (РС). Данные регистры содержат селекторы сегментов, соответствующих различным формам доступа к памяти.
Например, существуют специальные сегментные регистры для доступа к пространству кода и пространству стека. Шесть сегментных регистров определяют, какие сегменты памяти доступны в каждый определенный момент времени.
3. Регистр состояния (регистр системных флагов) и управляющие регистры (РС и УР). Данные регистры определяют и позволяют изменять состояние процессора i486.
Регистры общего назначения.
Регистрами общего назначения называются 32 битные регистры EAX, EBX, ECX, EDX, EBP, ESP, ESI и EDI. Данные регистры используются для хранения операндов логических и арифметических команд. Кроме того, они могут использоваться для хранения операндов при вычислении адресов (кроме регистра ESP, который не может быть использован как индексный операнд). Имена указанных регистров наследованы от имен регистров общего назначения процессора 8086 AX, BX, CX, DX, BP, SP, SI и DI. В Таблице 1 показано, как можно адресовать младшие 16 бит регистров общего назначения процессора i486, используя имена регистров процессора 8086.
Каждый байт 16 битных регистров AX, BX, CX и DX также имеет свое имя. Байты этих регистров называются AH, BH, CH и DH (старшие байты) и AL, BL, CL и DL (младшие байты).
8 БИТ | 16 БИТ | 32 БИТА |
AL AHBL BH CL CH DL DH | AX BX CX DXSI DI BP SP | EAX EBX ECX EDX ESI EDI EBP ESP |
Таблица 1 Имена регистров
Регистры общего назначения
31бит 32бита
AH | AL | AX | EAX | ||
DH | DL | DX | EDX | ||
CH | CL | CX | ECX | ||
BH | BL | BX | EBX | ||
BP | EBP | ||||
SI | ESI | ||||
DI | EDI | ||||
SP | ESP |
Регистры сегментов
15 0
CS |
SS |
DS |
ES |
FS |
GS |
Регистр состояния (регистр системных флагов) и управляющий регистр (указатель команд):
31 0
EFLAGS |
EIP |
Все регистры общего назначения могут использоваться для адресных вычислений и для получения результатов большинства арифметических и логических операций. Однако, некоторые команды используют фиксированные регистры для хранения операндов. Например, команды обработки строк используют в качестве операндов содержимое регистров ECX, ESI и EDI. Использование фиксированных регистров для некоторых операций позволяет более компактно кодировать набор команд. Следующие команды используют фиксированные регистры: умножение и деление с двойной точностью, ввод/вывод, обработка строк, перекодирование, цикл, сдвиг и циклический сдвиг, операции со стеком.
Регистры сегментов
Сегментирование позволяет разработчикам систем выбирать различные модели организации памяти.
Регистры сегментов содержат 16 разрядные селекторы сегментов, которые указывают на таблицу распределения памяти. Данная таблица содержит базовые адреса сегментов и другую информацию, регламентирующую доступ к памяти. При использовании плоской (несегментированной) модели все сегменты отображаются в единое пространство физической памяти.
В каждый момент времени непосредственно доступны не более 6 и сегментов. Их селекторы содержатся в регистрах CS, DS, SS, ES, FS и GS. Каждый регистр ассоциируется с сегментом, который соответствует одному из возможных типов доступа к памяти (коды, данные или стек).
Каждый регистр указывает на конкретный сегмент, используемый программой и имеющий определенный тип доступа.
Остальные сегменты могут быть использованы после загрузки соответствующих селекторов в сегментные регистры.
Сегмент, содержащий последовательность исполняемых команд, называется сегментом кода. Селектор этого сегмента содержится в регистре CS. Процессор i486 выбирает команды из этого сегмента, используя содержимое счетчика команд (регистр EIP) как относительный адрес внутри сегмента. Содержимое регистра CS изменяется в результате выполнения межсегментных команд управления потоком (CALL, IRET и JMP), прерываний и исключений.
Вызовы подпрограмм, записи параметров и активизация процедур обычно требует области памяти, резервируемой под стек. Все операции со стеком используют регистр SS при обращении к стеку. В отличие от регистра CS, регистр SS может быть загружен явно с помощью команды программы.
Остальные четыре регистра являются регистрами сегментов данных (DS, ES, FS и CS), каждый из которых используется текущей исполняемой программой. Доступ к четырем раздельным областям данных имеет целью повысить эффективность программ и безопасность доступа при обращении к различным типам структур данных. Например, имеет смысл разнести по разным сегментам собственные данные программного модуля, данные полученные из модуля более высокого уровня, динамически создаваемые структуры данных и данные, разделяемые текущим модулем с другими модулями. Механизм сегментации позволяет ограничить разрушения неправильно работающей неправильно работающей в следствии ошибки программы только теми сегментами, которые выделены текущей программе. Операнды, расположенные внутри сегмента данных адресуются указанием их смещения непосредственно внутри команды или в регистре общего назначения.
В некоторых случаях (при сложной структуре данных) может возникнуть необходимость иметь доступ более чем к четырем сегментам данных. Доступ к дополнительным сегментам осуществляется путем перезагрузки регистров DS, ES, FS и GS прикладной программой в процессе выполнения. Загрузка нужного сегментного регистра должна происходить до обращения к данным соответствующего сегмента.
При использовании регистров сегментов, с каждым выбранным сегментом связывается базовый адрес. При адресации единицы данных внутри сегмента, к базовому адресу сегмента добавляется 32 разрядный относительный адрес. Если сегмент выбран загрузкой селектора сегмента в регистр сегмента, то командам манипуляции данными нужен только этот относительный адрес.
Шина в вычислительной системе — это среда, через которую компоненты ЭВМ связываются друг с другом, т. е. это соответствующим образом выполненные линии связи. Большинство ЭВМ имеют шинную структуру, что позволяет существенно сократить общее число линий связи между блоками ЭВМ. Как показано на рис.1.3, шина ЭВМ функционально делится на три группы: адресную шину, шину данных и шину управления. Адресная шина переносит информацию о том, где искать инструкции (команды) или данные в памяти ЭВМ; шина данных переносит эти данные или инструкции для центрального процессора; шина управления обеспечивает передачу сигналов управления между процессором и подключенными к ЭВМ устройствами.
Тема 1.2. Структурная схема процессора, временные диаграммы, параметры.
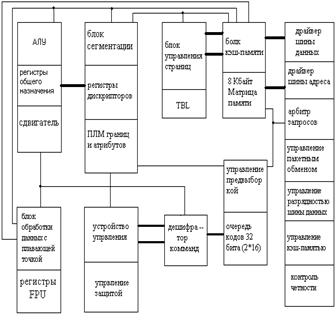
Объединяя более, чем 3.1 миллион транзисторов на одной кремниевой подложке, 32-разрядный Pentium процессор характеризуется высокой производительностью с тактовой частотой 60 и 66 МГц. Его суперскалярная архитектура использует усовершенствованные способы проектирования, которые позволяют выполнять более, чем одну команду за один период тактовой частоты, в результате чего Pentium в состоянии выполнять огромное количество PC-совместимого программного обеспечения быстрее, чем любой другой микропроцессор. Кроме существующих наработок программного обеспечения, высокопроизводительный арифметический блок с плавающей запятой Pentium процессора обеспечивает увеличение вычислительной мощности до необходимой для использования недоступных ранее технических и научных приложений, первоначально предназначенных для платформ рабочих станций. Также, как локальные и глобальные сети продолжают вытеснять устаревшие иерархические сети, управляемые большими ЭВМ, преимущества мультипроцессорности и гибкость операционной системы Pentium процессора - идеал для Хост-компьютера для современных приложений клиент-серверов, применяемых в промышленности.
Поскольку Pentium процессор способен достигать уровня производительности равного или более высокого, чем современные рабочие станции высокого уровня, он обладает преимуществами, которых лишены обычные рабочие станции: полная совместимость с более, чемпрограммных приложений со стоимостью миллиарды долларов, которые были написаны под архитектуру фирмы INTEL. В дополнение, Pentium процессор позволяет использовать все основные операционные системы, которые доступны современным настольным персональным компьютерам, рабочим станциям и серверам, включая UNIX, Windows-NT, OS/2, Solaris и NEXTstep.
Pentium процессор. Технические нововведения.
Многочисленные нововведения - характерная особенность Pentium процессора в виде уникального сочетания высокой производительности, совместимости, интеграции данных и наращиваемости. Это включает:
- Суперскалярную архитектуру;
- Раздельное кэширование программного кода и данных;
- Блок предсказания правильного адреса перехода;
- Высокопроизводительный блок вычислений с плавающей запятой;
- Расширенную 64-битовую шину данных;
- Поддержку многопроцессорного режима работы;
- Средства задания размера страницы памяти;
- Средства обнаружения ошибок и функциональной избыточности;
- Управление производительностью;
- Наращиваемость с помощью Intel OverDrive процессора.
Суперскалярная архитектура Pentium процессора представляет собой совместимую только с INTEL двухконвейерную индустриальную архитектуру, позволяющую процессору достигать новых уровней производительности посредством выполнения более, чем одной команды за один период тактовой частоты. Термин "суперскалярная" обозначает микропроцессорную архитектуру, которая содержит более одного вычислительного блока. Эти вычислительные блоки, или конвейеры, являются узлами, где происходят все основные процессы обработки данных и команд.
Появление суперскалярной архитектуры Pentium процессора представляет собой естественное развитие предыдущего семейства процессоров с 32-битовой архитектурой фирмы INTEL. Например, процессор Intel486 способен выполнять несколько своих команд за один период тактовой частоты, однако предыдущие семейства процессоров фирмы INTEL требовали множество циклов тактовой частоты для выполнения одной команды.
Возможность выполнять множество команд за один период тактовой частоты существует благодаря тому, что Pentium процессор имеет два конвейера, которые могут выполнять две инструкции одновременно. Так же, как и Intel486 с одним конвейером, двойной конвейер Pentium процессора выполняет простую команду за пять этапов: предварительная подготовка, первое декодирование (декодирование команды), второе декодирование (генерация адреса), выполнение и обратная выгрузка. Это позволяет нескольким командам находиться в различных стадиях выполнения, увеличивая тем самым вычислительную производительность.
Каждый конвейер имеет свое арифметическо-логическое устройство (ALU), совокупность устройств генерации адреса и интерфейс кэширования данных. Так же как и процессор Intel486, Pentium процессор использует аппаратное выполнение команд, заменяющее множество микрокоманд, используемых в предыдущих семействах микропроцессоров. Эти инструкции включают загрузки, запоминания и простые операции АЛУ, которые могут выполняться аппаратными средствами процессора, без использования микрокода. Это повышает производительность без затрагивания совместимости. В случае выполнения более сложных команд, для дополнительного ускорения производительности выполнения расширенного микрокода Pentium процессора для выполнения команд используются обе конвейера суперскалярной архитектуры.
В результате этих архитектурных нововведений, по сравнению с предыдущими микропроцессорами, значительно большее количество команд может быть выполнено за одно и то же время.
Раздельное кэширование программного кода и данных.
Другое революционное важнейшее усовершенствование, реализованное в Pentium процессоре, это введение раздельного кэширования. Кэширование увеличивает производительность посредством активизации места временного хранения для часто используемого программного кода и данных, получаемых из быстрой памяти, заменяя по возможности обращение к внешней системной памяти для некоторых команд. Процессор Intel486, например, содержит один 8-KB блок встроенной кэш-памяти, используемой одновременно для кэширования программного кода и данных.
Проектировщики фирмы INTEL обошли это ограничение использованием дополнительного контура, выполненного на 3.1 миллионах транзисторов Pentium процессора (для сравнения, Intel486 содержит 1.2 миллиона транзисторов) создающих раздельное внутреннее кэширование программного кода и данных. Это улучшает производительность посредством исключения конфликтов на шине и делает двойное кэширование доступным чаще, чем это было возможно ранее. Например, во время фазы предварительной подготовки, используется код команды, полученный из КЭШа команд. В случае наличия одного блока кэш-памяти, возможен конфликт между процессом предварительной подготовки команды и доступом к данным. Выполнение раздельного кэширования для команд и данных исключает такие конфликты, давая возможность обеим командам выполняться одновременно. Кэш-память программного кода и данных Pentium процессора содержит по 8 KB информации каждая, и каждая организована как набор двухканального ассоциативного КЭШа - предназначенная для записи только предварительно просмотренного специфицированного 32-байтного сегмента, причем быстрее, чем внешний кэш. Все эти особенности расширения производительности потребовали использования 64-битовой внутренней шины данных, которая обеспечивает возможность двойного кэширования и суперскалярной конвейерной обработки одновременно с загрузкой следующих данных. Кэш данных имеет два интерфейса, по одному для каждого из конвейеров, что позволяет ему обеспечивать данными две отдельные инструкции в течение одного машинного цикла. После того, как данные достаются из КЭШа, они записываются в главную память в режиме обратной записи. Такая техника кэширования дает лучшую производительность, чем простое кэширование с непосредственной записью, при котором процессор записывает данные одновременно в кэш и основную память. Тем не менее, Pentium процессор способен динамически конфигурироваться для поддержки кэширования с непосредственной записью.
Таким образом, кэширование данных использует два различных великолепных решения: кэш с обратной записью и алгоритм, названный MESI (модификация, исключение, распределение, освобождение) протокол. Кэш с обратной записью позволяет записывать в кэш без обращения к основной памяти в отличие от используемого до этого непосредственного простого кэширования.
Эти решения увеличивают производительность посредством использования преобразованной шины и предупредительного исключения самого узкого места в системе. В свою очередь MESI-протокол позволяет данным в кэш-памяти и внешней памяти совпадать - великолепное решение в усовершенствованных мультипроцессорных системах, где различные процессоры могут использовать для работы одни и те же данные.
Рекомендуемый объем общей кэш-памяти для настольных систем, основанных на Pentium процессоре, равен 128-256 K, а для серверов - 256 K и выше.
Высокопроизводительный блок вычислений с плавающей запятой. Нарастающая волна 32-разрядных программных приложений включает много интенсивно вычисляющих, графически ориентированных программ, которые занимают много процессорных ресурсов на выполнение операций с плавающей запятой, обеспечивающих математические вычисления. Поскольку требования к персональным компьютерам со стороны программного обеспечения по вычислениям с плавающей запятой постоянно возрастают, удовлетворить эти потребности могут усовершенствования в микропроцессорной технологии. Процессор Intel486 DX, например, был первым микропроцессором, интегрированным на одной подложке с математическим сопроцессором. Предыдущие семейства процессоров фирмы INTEL, при необходимости использования вычислений с плавающей запятой, использовали внешний математический сопроцессор.
Pentium процессор позволяет выполнять математические вычисления на более высоком уровне благодаря использованию усовершенствованного встроенного блока вычислений с плавающей запятой, который включает восьми тактовый конвейер и аппаратно реализованные основные математические функции. Четырех тактовые конвейерные команды вычислений с плавающей запятой дополняют четырех тактовую целочисленную конвейеризацию. Большая часть команд вычислений с плавающей запятой могут выполняться в одном целочисленном конвейере, после чего подаются в конвейер вычислений с плавающей запятой. Обычные функции вычислений с плавающей запятой, такие как сложение, умножение и деление, реализованы аппаратно с целью ускорения вычислений.
В результате этих инноваций, Pentium процессор выполняет команды вычислений с плавающей запятой в пять раз быстрее, чем 33-МГц Intel486 DX, оптимизируя их для высокоскоростных численных вычислений, являющихся неотъемлемой частью таких усовершенствованных видеоприложений, как CAD и 3D-графика.
Pentium процессор на тактовой частоте 66 МГц работает как "числодробилка" с рейтингом 64.5 по тесту SPECint92, практически не уступая RISC-процессору Alpha компании Digital, но с тактовой частотой вдвое более высокой.
Общая производительность Pentium процессора превосходит в 6 раз 25 МГц Intel486 SX и в 2.6 раз - 66 МГц Intel486 DX2.
Индекс по рейтингу iCOMP для 66 МГц Pentium процессора, который выполняет 112 миллионов операций в секунду, составляет 567. Индекс по iCOMP (Intel COmparative Microprocessor Peformance) выполняет относительное сравнение производительности 32-битовых процессоров фирмы INTEL.
Расширенная 64-битовая шина данных.
Pentium процессор снаружи представляет собой 32-битовое устройство. Внешняя шина данных к памяти является 64-битовой, удваивая количество данных, передаваемых в течение одного шинного цикла. Pentium процессор поддерживает несколько типов шинных циклов, включая пакетный режим, в течение которого происходит порция данных из 256 бит в кэш данных и в течение одного шинного цикла.
Шина данных является главной магистралью, которая передает информацию между процессором и подсистемой памяти. Благодаря этой 64-битовой шине данных, Pentium процессор существенно повышает скорость передачи по сравнению с процессором Intel486 DX - 528 MB/сек для 66 МГц, по сравнению со 160 MB/сек для 50 МГц процессора Intel486 DX. Эта расширенная шина данных способствует высокоскоростным вычислениям благодаря поддержке одновременной подпитки командами и данными процессорного блока суперскалярных вычислений, благодаря чему достигается еще большая общая производительность Pentium процессора по сравнению с процессором Intel486 DX.
В общем, имея более широкую шину данных, Pentium процессор обеспечивает конвейеризацию шинных циклов, что способствует увеличению пропускной способности шины. Конвейеризация шинных циклов позволяет второму циклу стартовать раньше завершения выполнения первого цикла. Это дает подсистеме памяти больше времени для декодирования адреса, что позволяет использовать более медленные и менее дорогостоящие компоненты памяти, уменьшая в результате общую стоимость системы. Ускорение процессов чтения и записи, параллелилизм адреса и данных, а также декодирование в течение одного цикла - все вместе позволяет улучшить пропускную способность и повышает возможности системы.
Тема 1.3. Регистры управления памятью и адресацией.
Управляющие регистры CR0, CR1, CR2 и CR3. В большинстве систем загрузка управляющих регистров из прикладных программ невозможна (хотя в незащищенных системах такая загрузка разрешается). Прикладные программы имеют возможность считывать эти регистры для определения наличия математического сопроцессора. Некоторые разновидности команды MOV позволяют загружать управляющие регистры из регистров общего назначения, и наоборот. Например,
MOV EAX, CR0
MOV CR3, EBX
Регистр CR0 содержит системные управляющие флаги, которые управляют режимами или указывают на состояние процессора в целом, а не относительно выполнения конкретных задач. Программа не должна пытаться изменить состояние каких-либо битов в зарезервированных позициях. Эти зарезервированные биты всегда должны устанавливаться в то состояние, которое они имели ранее при считывании

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 |
