

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
теория вероятностей
Основными объектами исследования теории вероятностей являются случайное событие, которое может произойти или не произойти в результате определенного комплекса условий, называемого испытанием (опытом, экспериментом), и вероятность случайного события (мера возможности его наступления).
Пусть W – множество элементов w, которые мы будем называть элементарными событиями, а F – множество подмножеств из W. Элементы множества F будем называть случайными событиями (или просто – событиями), а W – пространством элементарных событий.
Аксиома 1. F является алгеброй множеств (система F подмножеств множества W называется алгеброй, если W Î F, объединение, пересечение и разность двух множеств системы принадлежат этой системе).
Аксиома 2. Каждому множеству A из F поставлено в соответствие неотрицательное действительное число P(A). Это число называется вероятностью события A.
Аксиома 3. P(W) = 1.
Аксиома 4. Если A и B не пересекаются, то P(AÈB) = P(A) + P(B).
Если A = W, то в результате испытания событие А обязательно должно произойти (А называется достоверным событием).
Если A = Æ, то событие А не может произойти (и называется невозможным).
Определенная системой аксиом вероятность обладает свойствами:
1. Вероятность достоверного события равна 1 (P(W) =1).
2. Вероятность невозможного события равна 0 (P(Æ) = 0).
3. Вероятность случайного события есть неотрицательное число, заключенное между 0 и 1: 0 £ P(A) £ 1.
Если можно определить n – общее число равновозможных исходов, и m – число исходов, благоприятных для события А, то вероятность события А есть отношение числа благоприятных исходов к общему числу равновозможных исходов, т. е. Р(А) = m/n.[1]
Операции над событиями
Дополнение события А есть событие ![]() , состоящее в ненаступлении события А.
, состоящее в ненаступлении события А.
Объединение событий – А È В – событие, которое заключается в наступлении хотя бы одного из событий (А или В).
Пересечение событий А и В – событие АÇВ (также АВ), которое заключается в одновременной реализации событий А и В.
Разность событий A и B – событие A \ B, которое состоится, если событие A произойдет, а событие B не произойдет.
Если АÇВ = Æ, то события А и В называются несовместными. В противном случае они называются совместными.
![]() 1. Сумма вероятностей противоположных событий равна 1: P(A) + P(А ) = 1.
1. Сумма вероятностей противоположных событий равна 1: P(A) + P(А ) = 1.
2. Вероятность объединения двух совместных событий равна сумме вероятностей этих событий без вероятности их совместного появления
P(AÈB) = P(A) + P(B) – P(AÇB).
Условная вероятность. Независимые события
Если P(A)>0, то
PA(B) = ![]() называют условной вероятностью события B при условии A.
называют условной вероятностью события B при условии A.
Другое обозначение PA(B) – P(B/А).
Смысл условной вероятности в том, что получение добавочной информации может изменить значение вероятности тех или иных результатов испытания. Наличие определенной информации о результате испытания означает, что вместо всего множества исходов надо брать его часть.
Два события называются независимыми, если появление одного из них не меняет вероятности наступления другого, т. е. если P(B) = PA(B) и P(A) = PB(A).
Если события A и B независимы, то вероятность их одновременного осуществления равна произведению их вероятностей: P(AÇB)=P(A)×P(B).[2]
Вероятность совместного появления двух событий равна произведению вероятности одного из них на условную вероятность другого, вычисленную в предположении, что первое событие уже наступило: P(AÇB) = P(A) PA(B). n
Пример.
В одном сосуде 3 белых и 5 черных шаров. В другом – 7 белых и 6 черных. Достаем по одному шару из каждого сосуда. Какова вероятность вынуть два белых шара?
Решение
Вероятность вынуть белый шар из первого сосуда равна 3/8 (всего 8 шаров, из них 3 белых). Вероятность вынуть белый шар из второго сосуда – 7/13.
Поскольку шары вынимаются из сосудов независимо, то вероятность одновременно вынуть белый шар из первого и белый шар из второго сосудов равна произведению этих вероятностей – 3/8 × 7/13=21/104. n
Формула полной вероятности. Формула Байеса
Теорема о полной вероятности: Если событие A может произойти только при условии появления одного из событий H1, ..., Hn, образующих разбиение пространства элементарных событий, то вероятность события A равна сумме произведений вероятностей каждого из этих событий на соответствующие условные вероятности события A: 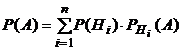 n
n
События Н1, ..., Нn называют гипотезами.
Пример.
Организация приобрела 20 компьютеров у первой фирмы, 30 – у второй и 50 – у третьей. Вероятность того, что в течение года компьютер придется ремонтировать, составляет 0,01 для поставки первой фирмы, 0,03 – для второй и 0,05 – для третьей. Какова вероятность, что компьютер потребует ремонта в течение года?
Решение
Пусть Н1 – компьютер приобретен у первой фирмы, Н2 – у второй, Н3 – у третьей. А – компьютер пришлось ремонтировать.
По формуле полной вероятности:
![]()
Р(Н1)= 20/(20+30+50)=0,2.
Р(Н2)= 30/(20+30+50)=0,3.
Р(Н3)= 50/(20+30+50)=0,5.
По условию:
![]() – вероятность того, что компьютер потребовал ремонта, если он был приобретен у первой фирмы = 0,01.
– вероятность того, что компьютер потребовал ремонта, если он был приобретен у первой фирмы = 0,01.
![]() – вероятность того, что компьютер потребовал ремонта, если он был приобретен у второй фирмы = 0,03.
– вероятность того, что компьютер потребовал ремонта, если он был приобретен у второй фирмы = 0,03.
![]() – вероятность того, что компьютер потребовал ремонта, если он был приобретен у третьей фирмы = 0,05.
– вероятность того, что компьютер потребовал ремонта, если он был приобретен у третьей фирмы = 0,05.
Значит, Р(А) = 0,2×0,01+0,3×0,03+0,5×0,05 = 0,002+0,009+0,025=0,036. n
Формула Байеса: 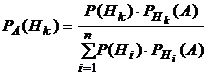
Смысл этой формулы заключается в следующем.
Если существуют попарно исключающие друг друга гипотезы Н1, ..., Нn, охватывающие все возможные случаи, и если известны вероятности события А при каждой из этих гипотез, то по этой формуле можно найти вероятность справедливости гипотезы Нk при условии, что произошло событие А. Таким образом, наступление события A дает нам новую информацию, благодаря которой можно найти условные вероятности гипотез (PA(Нk), k=1, 2, …, n). Такой подход, позволяющий проверять и корректировать после испытания выдвинутые предварительно гипотезы, называется байесовским.
Пример.
Если в условиях предыдущего Примера компьютер потребовал ремонта, то какова вероятность, что он был приобретен у третьей фирмы?
Решение
Пусть, как и в Примере, Н1 – компьютер приобретен у первой фирмы, Н2 – у второй, Н3 – у третьей. А – компьютер пришлось ремонтировать.
Запишем формулу Байеса применительно к нашей задаче:
P(Н3/А)= P(Н3) ×P (A/Н3) / (P (Н1)×P (A/ Н1)+ P(Н2)×P (A/Н2) + P (Н3)×P (A/Н3))
Подставим в эту формулу вычисленные в Примере значения вероятностей: Р(Н1), Р(Н2), Р(Н3), P (A/Н1), P (A/Н2), P (A/Н3):
P(Н3/А)=0,5×0,05/(0,2×0,01+0,3×0,03+0,5×0,05)=0,025/(0,002+0,009+0,025)=0,025/0,036» 0,694.n
Случайные величины
Случайная величина (далее СВ) – числовая функция, определенная на пространстве элементарных событий. СВ полностью определяется своим законом распределения, т. е. правилом, устанавливающим связь между возможными значениями СВ и соответствующими им вероятностями.
Функция распределения случайной величины X есть FX (x) – вероятность наступления события {X < x}: FX(x)=P{X <x}.
Функция распределения обладает следующими свойствами:
1. 0£ FX(x) £1, -¥ < х < ¥
2. FX(x) – неубывающая функция на всей оси, т. е. FX(x2) ³ FX(x1), если x2 > x1.
3. ![]() = 0.
= 0.
4. ![]() = 1.
= 1.
5. Вероятность того, что СВ X примет значение, заключенное в интервале [a, b) равно приращению функции распределения на этом интервале:
P(a £ X < b) = F(b) – F(a)
6. Если все возможные значения СВ X принадлежат интервалу (a, b), то:
FX (x) = 0 при х £ a; FX (x) = 1 при х ³ b
Дискретная СВ – СВ, принимающая отдельные, изолированные возможные значения с ненулевыми вероятностями.
Число возможных значений дискретной СВ может быть конечным или бесконечным.
Пример.
Рассмотрим условия Примера 5.1. Пусть X – число очков, выпавших на верхней грани. Тогда X(wi) = i. X – это случайная величина. Ее функция распределения определяется следующим образом:
FX (x) = 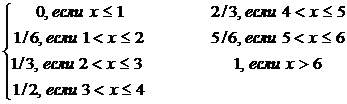
Случайную величину, принимающую вещественные значения, называют непрерывной, если ее функция распределения непрерывна и дифференцируема всюду, кроме, быть может, конечного числа точек.
Непрерывная СВ может принимать все значения из некоторого конечного или бесконечного промежутка. Число возможных значений непрерывной СВ бесконечно.
Пример.
Являются ли функции, графики которых приведены на рис., функциями распределения? Пояснить.
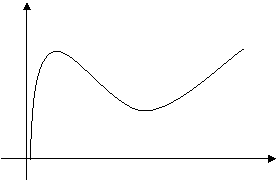 |
 |
а. б.
Решение
а. Данная функция не является функцией распределения, поскольку она не является неубывающей.
б. Данная функция не является функцией распределения, поскольку все значения функции распределения должны находиться в диапазоне от 0 до 1. n
Плотность распределения вероятностей
Плотностью распределения вероятностей (плотностью вероятности или плотностью) непрерывной случайной величины называется производная ее функции распределения: p(x) = F¢(x)
Соответственно, функция распределения является первообразной для плотности вероятности: 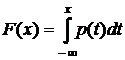 .
.
Свойства плотности распределения вероятностей:
1. Плотность вероятности – неотрицательная функция (p(x) ³ 0).
2. Несобственный интеграл от плотности вероятности в пределах
от -¥ до ¥ равен 1: 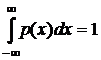 .
.
Пример.
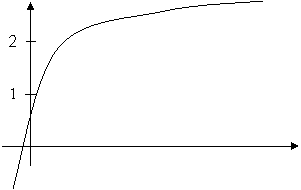
Может ли данная функция быть плотностью распределения вероятностей случайной величины? Обосновать. Построить график функции распределения.
Пусть дана функция 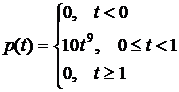
Решение
Данная функция по определению неотрицательна на всей числовой оси.
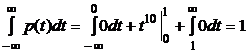 , следовательно, эта функция может быть плотностью распределения вероятностей.
, следовательно, эта функция может быть плотностью распределения вероятностей.
Найдем функцию распределения F(x). По определению, .
Значит, 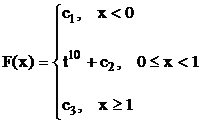 .
.
При этом постоянные с1, с2 и с3 находятся из условий:
1. F (-¥)=0,
2. F (¥)=1,
3. F (x) неубывающая функция на всей оси,
4. F (x) непрерывна на всей оси.
Значит, с1 = с2 = 0 и с3=1.
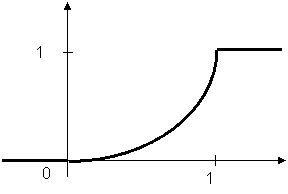 |
График функции распределения приведен на рис. 5.4.
Рис. 5.4.
Характеристики распределения СВ
Для решения многих задач не обязательно иметь полную информацию о случайной величине, доставляемую ее распределением. В большинстве случаев достаточно знания лишь отдельных характеристик этого распределения. Основными характеристиками служат математическое ожидание и дисперсия.
Математическое ожидание
Математическое ожидание (обозначается буквой М) характеризует среднее значение случайной величины.
Математическое ожидание дискретной СВ X, значения которой x1,x2,... имеют вероятности соответственно p1, p2, ..., есть сумма произведений значений СВ на их вероятности: МX = ![]() .
.
Математическое ожидание непрерывной СВ X есть определенный интеграл МX = 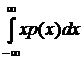 .
.
Пусть a – константа (постоянная), X, Y – случайные величины.
Свойства МО:
1. М a = a (Математическое ожидание постоянной величины равно этой постоянной).
2. М(X+Y)=МX+МY (Математическое ожидание суммы случайных величин равно сумме их математических ожиданий).
3. М(аX) = аМX (Математическое ожидание произведения случайной величины на постоянную равно произведению этой постоянной на математическое ожидание случайной величины).
Дисперсия
Дисперсия (обозначается буквой D) характеризует разброс значений случайной величины относительно ее математического ожидания.
Дисперсия DX случайной величины X определяется по формуле
DX=М(X – МX)2 .
Для вычисления дисперсии чаще используется формула DX=МX2 – (МX)2
Свойства дисперсии:
1. D(а)= 0. (Дисперсия постоянной равна 0).
2. D(X + а)= D(X)
3. D(аX )= а2D(X ).
Наряду с дисперсией для оценки степени разброса значений случайной величины относительно среднего значения применяется характеристика, называемая средним квадратическим отклонением и равная корню квадратному из дисперсии: ![]() .
.
Пример 5.13.
Найти математическое ожидание и дисперсию случайной величины, заданной следующим образом:
xk | 1 | 4 | 10 | 20 |
pk | 1/4 | 1/8 | 1/2 | 1/8 |
Решение
Найдем МО. По определению, МX = ![]()
МX = 1× 1/4 + 4× 1/8 + 10× 1/2 + 20× 1/8 =1/4 + 1/2 + 5 + 5/2 = 8,25
Найдем дисперсию. Воспользуемся формулой DX = МX2 – (МX)2
DX = (1×1/4 + 16×1/8 + 100×1/2 + 400×1/8) – (8,25)2 = 0,25+2+50+50-68,0625 = 34,1875.n
Основные законы распределения
Нормальный закон распределения
Нормальный закон распределения наиболее часто встречается на практике. Главная его особенность состоит в том, что он является предельным законом, к которому приближаются некоторые другие законы распределения.
Нормальное распределение[3] – распределение непрерывной случайной величины, плотность которого ![]() .
.
Если X – СВ, имеющая нормальное распределение с параметрами a и s, то МX = a и DX=s2.
График плотности нормального распределения называют нормальной кривой (кривой Гаусса). Эта кривая симметрична относительно вертикальной оси, проходящей через точку x=a, и имеет в этой точке единственный максимум, равный 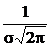 . С уменьшением s кривая становится все более островершинной. Изменение a при неизменном s приводит к смещению кривой по оси абсцисс. (Графики плотности нормального распределения при различных параметрах см. на рис. 5.10).
. С уменьшением s кривая становится все более островершинной. Изменение a при неизменном s приводит к смещению кривой по оси абсцисс. (Графики плотности нормального распределения при различных параметрах см. на рис. 5.10).
При a=0 и s=1 нормальную кривую называют нормированной.
Нормированная СВ – СВ X*, связанная с исходной СВ X линейным преобразованием: X*=(X - МX)/![]() .
.
Обозначают нормированную СВ – N(0,1).
Плотность нормированной СВ определяется по формуле ![]() .
.
Поскольку непосредственное вычисление функции распределения случайной величины, имеющей нормальное распределение, затруднено (ее выражение содержит «неберущийся» интеграл), для ее нахождения используются табличные значения функции Лапласа[4] – 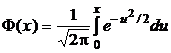 .
.
Заметим, что таблицы построены лишь для положительных х и для х=0. Для отрицательных значений х следует использовать нечетность функции Ф(х) (Ф(-х) = - Ф(х)). При x>5 можно принять Ф(х)=0,5.
При этом функция распределения (FN) СВ, распределенной по нормальному закону с параметрами 0 и 1, выражается через функцию Лапласа следующим образом: ![]() .
.
Геометрически функция Лапласа представляет собой площадь под стандартной нормальной кривой на отрезке [0, x].
Графики нормированной нормальной кривой и функции распределения нормированной СВ см. на рис. 5.11.
Нормированная нормальная кривая | Функция распределения нормированной СВ |
|
|
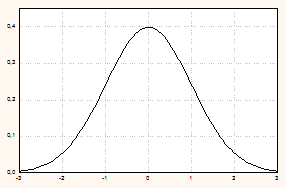
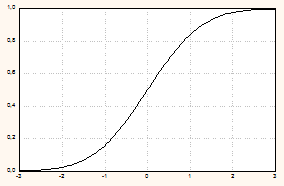
Рис. 5.11.
Распределение хи-квадрат
Распределение c2 (хи-квадрат) с n степенями свободы – распределение суммы квадратов n независимых СВ, имеющих одинаковое нормальное распределение с нулевым математическим ожиданием и единичной дисперсией.![]() , где X1, X2,…, Xn – N(0,1).
, где X1, X2,…, Xn – N(0,1).
Математическое ожидание и дисперсия равны, соответственно, n и 2n.
Распределение c2 непрерывно, сосредоточено на (0,¥). Плотность его – 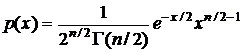 , где n – целое положительное число (число степеней свободы), Г – гамма-функция, определяется по формуле
, где n – целое положительное число (число степеней свободы), Г – гамма-функция, определяется по формуле 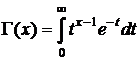 .
.
Используется в статистических критериях. При n > 30 распределение c2 очень близко к нормальному.
Распределение Стьюдента
Распределение Стьюдента (t-распределение) с n степенями свободы – распределение СВ 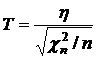 , где h – СВ, имеющая нормальное распределение с нулевым математическим ожиданием и единичной дисперсией (N(0,1)), а
, где h – СВ, имеющая нормальное распределение с нулевым математическим ожиданием и единичной дисперсией (N(0,1)), а ![]() – СВ, имеющая распределение c2 с n степенями свободы.
– СВ, имеющая распределение c2 с n степенями свободы.
Математическое ожидание равно 0 , дисперсия – n/(n-2), (n>2).
Используется в статистических критериях.
При увеличении n распределение Стьюдента приближается к нормальному распределению с нулевым математическим ожиданием и единичной дисперсией (N(0,1)).
Распределение Фишера-Снедекора
Распределение Фишера-Снедекора (F-распределение) с m и n степенями свободы – распределение СВ 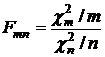 , где
, где ![]() и
и ![]() – СВ, имеющие распределение c2 с m и n степенями свободы соответственно.
– СВ, имеющие распределение c2 с m и n степенями свободы соответственно.
Математическое ожидание равно n/(n-2) (n>2),
дисперсия – 2n2(m+n-2)/m(n-2)2(n-4), (n>4).
Используется в статистических критериях.
математическая статистика
Математическая статистика – раздел математики, посвященный математическим методам сбора, систематизации, обработки и интерпретации статистических данных (результатов наблюдений), а также использованию их для научных и практических выводов.
Основные понятия математической статистики
Генеральная совокупность – это совокупность объектов, обладающих признаками, распределение которых в данной генеральной совокупности изучается статистическими методами.
Выборка – множество объектов, отобранное случайным образом из генеральной совокупности.
Все задачи математической статистики сводятся к тому, чтобы по выборочным данным сделать обоснованные выводы о закономерностях, которым подчинена генеральная совокупность, и оценить степень надежности этих выводов.
Для решения практических задач важны не сами объекты, а лишь те их признаки, распределение которых изучается в данной задаче. Поэтому можно рассматривать генеральную совокупность как случайную величину X с функцией распределения FX(x), а выборку объема n – как результат n наблюдений над данной случайной величиной.
Пусть (х1, х2, ..., хn) – выборка из генеральной совокупности с функцией распределения F(x). Тогда n – объем выборки.
Наблюдаемые значения х1, х2, ..., хn случайной величины – варианты, а каждое значение – варианта.
Последовательность вариант, записанная в возрастающем порядке – вариационный ряд.
Частота – число, показывающее, сколько раз встречается в выборке то или иное значение.
Относительная частота – отношение частоты к объему выборки.
Статистический ряд – перечень вариант и соответствующих им частот.
Полигон частот – ломаная, отрезки которой соединяют точки (x1, n1), (x2, n2), … (xk, nk), где ni – частота варианты xi.
Пример.
Пусть дана выборка: 3, 6, 1, 3, 5, 6, 2, 3 (например, это могут быть номера месяцев рождения присутствующих в классе).
Построим вариационный ряд: 1, 2, 3, 3, 3, 5, 6, 6
Статистический ряд – значения и соответствующие частоты:
xi | 1 | 2 | 3 | 5 | 6 |
ni | 1 | 1 | 3 | 1 | 2 |
Построим полигон частот: ось абсцисс – варианты xi, ось ординат – соответствующие частоты ni. Полученные точки соединим ломаной (см. рис. 6.1).
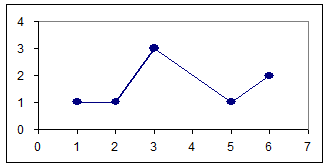 n
n
Рис. 6.1.
Для решения многих практических задач достаточно знать не весь вариационный ряд, а его сводные характеристики, например, характеристики центральной тенденции и изменчивости (вариации).
Мода (M0) – варианта, имеющая наибольшую частоту.
Медиана (me) – значение признака, приходящееся на середину вариационного ряда: если n=2k+1, то me=xk+1, [5]
если n=2k, то me=(xk + xk+1)/2.
Выборочная средняя ![]() – среднее арифметическое значение выборочной совокупности:
– среднее арифметическое значение выборочной совокупности: ![]() = (x1+x2+… +xn)/n
= (x1+x2+… +xn)/n
Выборочная дисперсия – среднее арифметическое квадратов отклонения наблюдаемых значений от их среднего значения: 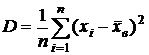
С целью упрощения вычислений представим дисперсию в виде 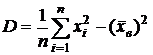 .
.
Выборочная дисперсия служит смещенной оценкой генеральной дисперсии, т. е. математическое ожидание выборочной дисперсии не равно генеральной дисперсии. Поэтому часто рассматривается исправленная дисперсия, которая является несмещенной оценкой генеральной дисперсии.
Исправленная дисперсия (обозначается s2) вычисляется по формуле
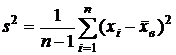 .
.
Аналогично функции распределения случайной величины для выборок вводится понятие функции распределения выборки или эмпирической функции распределения (т. е. функции распределения, полученной опытным путем).
Эмпирическая функция распределения в точке х есть доля элементов выборки, меньших х: 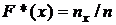 , где nx – число вариант, меньших х; n – объем выборки.
, где nx – число вариант, меньших х; n – объем выборки.
Пример
Пусть дана выборка: 3, 6, 1, 3, 5, 6, 2, 3. Найти моду, медиану, среднее и дисперсию выборки. Построить график эмпирической функции распределения.
Решение
Вариационный ряд: 1, 2, 3, 3, 5, 6, 6.
Статистический ряд:
Значение | 1 | 2 | 3 | 5 | 6 |
частота | 1 | 1 | 3 | 1 | 2 |
Мода – значение, имеющее наибольшую частоту – 3.
Медиана – значение в середине вариационного ряда. Поскольку число членов ряда четно, то медиана – среднее арифметическое средних соседних элементов (в нашем случае – четвертого и пятого), т. е. тоже 3.
Среднее (сумма всех значений, деленная на число элементов) – (1+2+3+3+3+5+6+6)/8 = 29/8 = 3,625.
Выборочная дисперсия (смещенная оценка): Dв =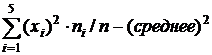
Несмещенная оценка выборочной дисперсии: Dнесм=![]() .
.
Dв = (1×1+4×1+9×3+25×1+36×2)/8 – (3,625)2 » 16,,141 » 2,984.
График эмпирической функции распределения приведен на рис. 6.2.
проверка статистических гипотез
Выдвинутую гипотезу о законе распределения случайной величины (его виде и параметрах) называют нулевой (основной) и обозначают H0.
Гипотезу, которая противоречит нулевой, называют конкурирующей (альтернативной).
Проверка статистической гипотезы означает проверку соответствия характеристик выборки некоторым теоретическим (предполагаемым) значениям этих характеристик.
Проверяются следствия, логически вытекающие из содержания гипотезы.
Пусть событие А таково, что вероятность его наступления при гипотезе Н0, меньше e. Если в эксперименте произошло событие А, то отвергаем гипотезу Н0 на уровне значимости e.
При проверке гипотезы возможны ошибки двух видов: ошибка первого рода заключается в том, что мы отвергаем гипотезу, когда она верна, а ошибка второго рода – принимаем гипотезу, когда она неверна. Вероятность ошибки первого рода называется уровнем значимости.
Пример 6.3.
Известно, что шарик сделан либо из пробки, либо из камня. Гипотеза H0: шарик сделан из пробки. Гипотеза H1: шарик сделан из камня. Погружаем шарик в воду. Пусть событие А: «шарик тонет в воде». Если шарик сделан из пробки, то вероятность этого события ничтожно мала. Если шарик утонул (событие А произошло), то гипотезу H0 отвергаем.
Статистический критерий (правило, по которому гипотеза принимается или отвергается) устанавливает на принятом уровне значимости ее согласие или несогласие с данными наблюдений.
Для построения события А используются специальные функции от наблюдаемых значений, которые называют статистиками. Статистика строится таким образом, чтобы ее распределение при нулевой гипотезе и при альтернативе как можно больше различались. Распределения статистик хорошо известны, а их значения вычисляются по характеристикам выборки. Событие А состоит в том, что вычисленное значение статистики больше некоторого известного, «табличного» значения.
Критическая область – совокупность значений статистики, при которых нулевую гипотезу отвергают.
Критические точки – точки, отделяющие критическую область от области принятия гипотезы
Можно предложить следующую схему статистической проверки гипотез (см. рис. 6.4):
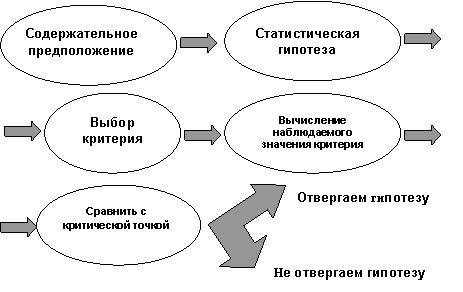 |
Рис. 6.4.
Пример
Приведены результаты психологического теста (в баллах) для 22 женщин:
25, 52, 44, 54, 44, 12, 47, 12, 20, 47, 13, 49, 11, 76, 41, 68, 60, 28, 42, 23, 39, 17
и 19 мужчин:
50, 38, 21, 80, 42, 88, 57, 67, 57, 25, 90, 67, 12, 22, 81, 63, 35, 35, 37.
Зависят ли результаты тестирования от пола?
Содержательное предположение: результаты тестирования от пола не зависят. Статистическая гипотеза: распределение результатов тестирования в группе женщин не отличается от распределения результатов тестирования в группе мужчин. Но если эти распределения не различаются, значит, их средние и дисперсии также не различимы. Таким образом, имеем две статистические гипотезы: гипотезу о равенстве средних и гипотезу о равенстве дисперсий.
Следующие критерии справедливы для выборок из нормальных генеральных совокупностей.
Критерий Стьюдента применяется для сравнения средних двух нормальных генеральных совокупностей, дисперсии которых одинаковы, но неизвестны.
При заданном уровне значимости проверяется нулевая гипотеза о равенстве математических ожиданий (генеральных средних) двух нормальных совокупностей с одинаковыми, но неизвестными дисперсиями при альтернативе их неравенства.
Правило проверки нулевой гипотезы:
1. Вычислить наблюдаемое значения критерия:
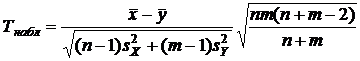 ,
,
где n и m – объемы выборок, ![]() и
и ![]() – выборочные средние, а
– выборочные средние, а ![]() и
и ![]() – исправленные дисперсии.
– исправленные дисперсии.
В условиях Примера 6.4 n = 22, m = 19, ![]() » 37,45;
» 37,45; ![]() » 50,89;
» 50,89; ![]() » 362,83;
» 362,83; ![]() » 569,77; Тнабл » - 2.
» 569,77; Тнабл » - 2.
2. По таблице критических точек распределения Стьюдента, по заданному уровню значимости и числу степеней свободы k=n+m-2 найти критическую точку (двустороннюю) – t.
В условиях Примера 6.4 k= 39; по таблицам для уровня значимости 0,1 и 39степеней свободы находим t = 1,68.
3. Если |Тнабл| > t, нулевую гипотезу отвергают на данном уровне значимости. В противном случае нулевая гипотеза не противоречит имеющимся наблюдениям, т. е. нет оснований отвергнуть гипотезу. n
В условиях Примера 6.4 |-2|>1,68, следовательно, гипотезу о равенстве средних отвергаем на уровне значимости 0,1.
Критерий Фишера-Снедекора используется для проверки при данном уровне значимости g нулевой гипотезы о равенстве генеральных дисперсий (т. е. дисперсий генеральных совокупностей) при конкурирующей гипотезе неравенства этих дисперсий.
Правило проверки нулевой гипотезы:
1. Вычислить наблюдаемое значение критерия – отношение большей по величине исправленной дисперсии (см. стр. ) к меньшей: Fнабл = s12/s22
В условиях Примера 6.4 s22 = ![]() » 362,83; s12 =
» 362,83; s12 = ![]() » 569,77; Fнабл » 1,57.
» 569,77; Fнабл » 1,57.
2. Найти число степеней свободы исправленных дисперсий:
k1= n1 - 1 (большая) (n1 – объем выборки, имеющей большую исправленную дисперсию)
k2 = n2 - 1 (меньшая) (n2 – объем выборки, имеющей меньшую исправленную дисперсию).
В условиях Примера 6.4 k1= 18, k2= 21.
3. По таблице критических точек распределения Фишера-Снедекора по уровню значимости g/2 (вдвое меньше требуемого в условии уровня значимости g) и числам степеней свободы k1 и k2 найти Fкр – критическую точку.
Положим g=0,1. В условиях Примера 6.4 Fкр = число между 2,15 и 2,09.
4. Если Fнабл<Fкр – нет оснований отвергать нулевую гипотезу. Если Fнабл>Fкр – нулевую гипотезу отвергают. n
В условиях Примера 6.4 Fнабл<Fкр (1,57 < 2,09). Значит, нет оснований отвергать гипотезу о равенстве дисперсий.
Элементы теории случайных процессов
Основные понятия
Случайный процесс – это функциональное всюду определенное отображение, областью отправления которого является пространство элементарных событий W, а областью прибытия множество действительных функций, аргумент которых рассматривается как время.
Случайный процесс можно записать в виде X(t, w) – функции времени t и элементарного события wÎ W, появляющегося в результате испытания.
Математическим ожиданием случайного процесса X(t) называется неслучайная функция mx(t), которая при любом значении переменной t равна математическому ожиданию соответствующего сечения этого случайного процесса, т. е. mx(t)=M[X(t)].
Марковские процессы
Случайный процесс X(t) называется процессом с дискретными состояниями S1, S2, S3, … , если
в любой момент времени (за исключением счетного числа моментов перехода из состояния в состояние) случайный процесс находится в одном и только в одном из состояний S1, S2, S3, …;
переход из одного состояния в другое состояние происходит мгновенно (скачком);
нахождение процесса в любом из этих состояний в течение какого-то промежутка времени означает, что он принимает на этом промежутке постоянное, фиксированное для каждого из состояний значение.
Случайный процесс X(t) называется марковским, если для любого момента времени t0 вероятностные характеристики процесса в будущем
(t > t0) зависят только от его состояния в данный момент и не зависят от значений процесса в прошлом (t < t0), т. е. от того, когда и как процесс пришел в это состояние.
Пример. Случайный процесс X(t), значения которого соответствуют показаниям счетчика такси, является марковским. Действительно, если в момент времени t0 на счетчике была сумма S0, то вероятность того, что на счетчике в момент времени t > t0 будет показана некоторая сумма S, не зависит от того, как изменялись показания счетчика до момента времени t0 . ■
На практике в ряде случаев предысторией рассматриваемых процессов пренебрегают и для простоты считают их марковскими.
Потоком событий называется последовательность однородных событий, следующих одно за другим в случайные моменты времени.
Поток событий можно описать случайным процессом X(t) с дискретными состояниями S1, S2, S3, …, зафиксировав некоторый момент времени t0 и определив, что процесс в момент времени t (t > t0) находится в состоянии Si и принимает значение X(t)=i, если на интервале (t0;t) произошло ровно i событий описываемого потока. Аналогично можно описать случайный процесс при значениях переменной t < t0 .
Среднее число событий поступающих в единичный интервал времени (частота появления событий) называется интенсивностью потока.
Поток событий называется потоком без последействия, если число событий, попадающих в произвольный интервал времени τ1 не зависит от числа событий попадающих на любой другой не пересекающийся с ним интервал времени τ2.
Случайный процесс, описывающий поток событий без последействия, является марковским.
Поток событий называется стационарным, если его вероятностные характеристики не зависят от времени.
Марковский процесс с конечным числом состояний имеет стационарный режим, если его ориентированный граф является сильно связным, то есть существует путь из любой его вершины в любую другую.
Стационарная (финальная) вероятность характеризует долю времени, которую проводит в соответствующем состоянии случайный процесс в стационарном режиме.
Потоки финальных вероятностей, входящих в любое состояние и выходящих из него, совпадают.
Потоки финальных вероятностей, входящих в любое сечение графа состояний и выходящих из него, совпадают.
Сечением ориентированного графа называют линию, проходящую через множество его дуг, после удаления которых ориентированный граф распадается на несвязные между собой подграфы. Сечения, для которых составляются уравнения, должны пересекать все дуги графа состояний.
Зная финальные вероятности, можно определить стационарные характеристики случайного процесса: математическое ожидание, дисперсию и другие.
Пример. Найти стационарные вероятности и стационарное математическое ожидание для марковского процесса, заданного графом. Считать, что находясь в состоянии Si, случайный процесс сохраняет значение X(t)=i. Значения интенсивностей перехода приведены в табл.
Значения интенсивностей перехода
λ12 | λ21 | λ23 | Λ34 | λ41 | λ43 |
4 | 2 | 2 | 1 | 1 | 2 |
Составим граф состояний процесса, поместив в их вершины значения случайного процесса, которые он принимает в соответствующем состоянии (см. рис.).
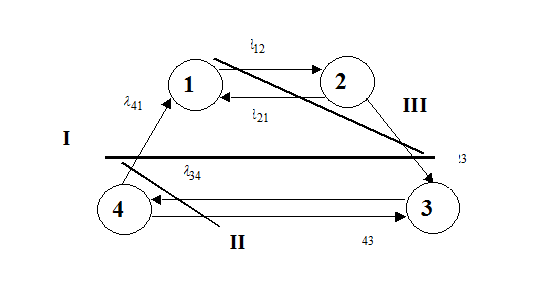 Рис. 7.3.
Рис. 7.3.
Составим уравнения сохранения потоков финальных вероятностей для сечений I-III, показанных на рис. 7.3, и дополним их условием нормировки.
λ41 p4= λ23 p2
λ34 p3= (λ41 +λ43 )p4
λ12 p1= (λ21 +λ23 )p2
p1+p2 +p3+p4= 1
Подставляя численные значения интенсивностей перехода, получим
p4= 2p2
p3= (1+2)p4
4 p1= (2+2)p2
p1+p2 +p3+p4= 1
Откуда
p4 = 2p2= 2p1
p3 = 3p4= 6p1
p2 = p1
p1 (1+1+6+2)= 1
Из условия нормировки получаем p1 = 0,1.
Тогда p2 = 0,1; p3 = 0,6; p4 = 0,2.
Математическое ожидание случайного процесса в стационарном режиме постоянно и равно 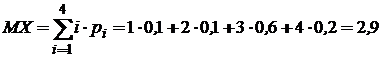 .■
.■
[1] Это классическое определение вероятности.– Прим. авт.
[2] Эта формула часто используется в качестве определения независимых событий. – Прим. авт.
[3] Термин «нормальное распределение» принадлежит К. Пирсону. Ранее: гауссовское распределение, распределение Гаусса-Лапласа. – Прим. авт.
[4] Заметим, что в некоторых таблицах приведены значения функции. 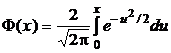 – Прим. авт.
– Прим. авт.
[5] Номер элемента – это его место в вариационном ряду. – Прим. авт.
